回溯算法专题练习
回溯算法
vector<vector<T>> res;
vector<T> path;
void backtrack(未探索区域, res, path):
if 未探索区域满足结束条件:
res.push_back(path)
return;
for 选择 未探索区域当前可能的选择:
if 当前选择符合要求:
path.push_back(当前选择)
backtrack(新的未探索区域, res, path)
path.pop_back()
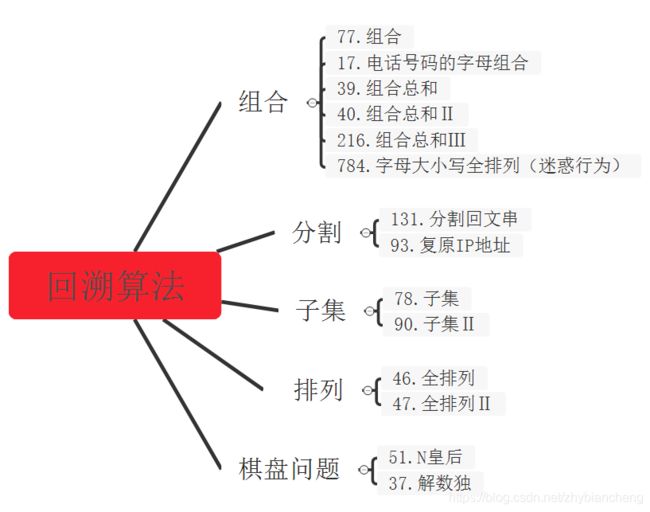
文章目录
- 回溯算法
-
- 组合
-
- 组合
-
- (回溯1)
- (回溯2)
- (控制搜索位置->剪枝1)
- (控制搜索位置->剪枝2)
- 电话号码的字母组合
-
- (回溯1)
- (回溯2)
- 组合总和
-
- (回溯)
- (排序+判断->剪枝)
- 组合总和Ⅱ
-
- (回溯 + 预判和->剪枝 + 特判重复元素->剪枝)
- (回溯 + 哈希表去重)
- 组合总和Ⅲ
-
- (回溯 + 控制范围->剪枝)
- 分割
-
- *分割回文串
-
- (回溯)
- 复原IP地址
-
- (回溯)
- 子集(全组合)
-
- 子集
-
- (回溯1选择位置)
- (二进制枚举)
- (回溯2选择数字)
- (枚举)
- 子集Ⅱ
-
- (回溯+下标判断去重)
- (回溯+哈希表去重)
- (二进制枚举+哈希表去重)
- 字母全排列(子集问题)
-
- (回溯)
- 排列
-
- 全排列
-
- (回溯)
- 全排列Ⅱ
-
- (回溯+哈希表去重)
- (回溯+下标判重)
- 去重问题总结
- 棋盘问题
-
- N皇后
-
- (回溯+循环判断)
- (回溯+数学判断)
- 解数独
-
- (穷举回溯)
- (循环回溯)
组合
题目要求:从[1 … n] 中选出所有k个数的组合, 不能有重复的组合
组合
首先想到的暴力解法应该是用for循环解决,k等于多少就用几层for循环,一个一个枚举就可以了。但是如果k=100总不能写100层循环吧。所以这里想到用dfs回溯解决。这样dfs递归的深度就是for循环的层数。
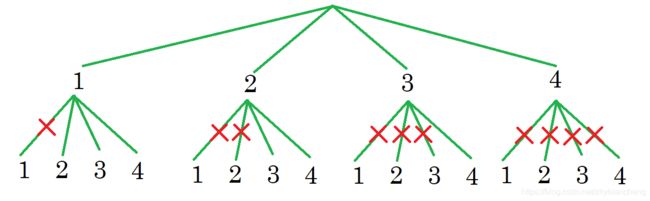
每一个递归(dfs)都对应这一个递归搜索数。这道题目从1开始枚举,一直枚举到n。要注意的是这是一道枚举组合的题目,也就是说任意两个不相同的数字可以并只能组成一对。这也就意味着枚举的时候是不能回头的(这就类似于for循环的时候第一层循环从1开始,第二层循环从i + 1开始….)。所以在dfs的时候就需要用一个start变量标记一下当前枚举到哪个位置上了,然后从这个位置从前往后再枚举。直到枚举的数量到达k的时候就将这一个结果放入答案中。其中判断结果的数量是否达到k有两种方法,一种是path.size() == k,一种是让k的含义变成还需要再枚举k个数,然后dfs的时候传递k - 1,最后再k==0(还需要枚举0个数)的时候将结果放入答案中。
(回溯1)
class Solution {
public:
void dfs(int n, int k, vector<vector<int>>& ans, vector<int>& path, int start) {
if (path.size() == k) {// 当数组中的数已经到上限k
ans.push_back(path);
return;
}
for (int i = start; i <= n; i ++) {
row.push_back(i);
dfs(n, k, ans, path, i + 1);
path.pop_back();
}
}
vector<vector<int>> combine(int n, int k) {
vector<vector<int>> ans;
vector<int> path;
dfs(n, k, ans, row, 1);
return ans;
}
};
(回溯2)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(int n, int k, int start) {
if (k == 0) {// 注意这里用k == 0来判断个数已满
ans.push_back(path);
return ;
}
for (int i = start; i <= n; i ++) {
path.push_back(i);
dfs(n, k - 1, i + 1);
path.pop_back();
}
}
vector<vector<int>> combine(int n, int k) {
dfs(n, k, 1);
return ans;
}
};
当k = 4,n = 6的时候,枚举到start == 4其实是没有必要去枚举的因为4后面就只有3个数无论怎么选都不可能组合成数量为4的组合。所以我们发现start这个枚举数字的起点也是有范围的start <= n - 还要枚举的数字数量 + 1->start <= n - (k - path.size()) + 1。这种把明显没有必要枚举直接通过判断减少循环的方式叫做剪枝。
举一个k = 6, n = 6的栗子(比较极端)
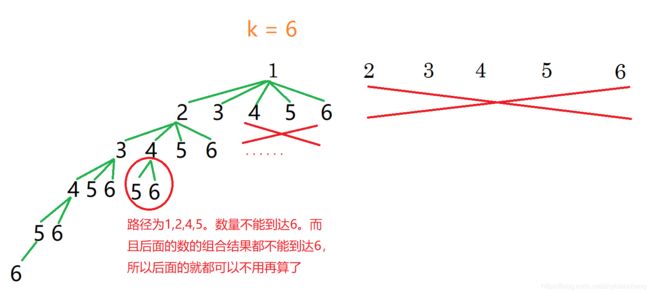
(控制搜索位置->剪枝1)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(int n, int k, int start) {
if (path.size() == k) {
ans.push_back(path);
return;
}
for (int i = start; i <= n - (k - path.size()) + 1; i ++) {// 搜索的最大起点是n - (k - path.size()) + 1
path.push_back(i);
dfs(n, k, i + 1);
path.pop_back();
}
}
vector<vector<int>> combine(int n, int k) {
dfs(n, k, 1);
return ans;
}
};
(控制搜索位置->剪枝2)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(int n, int k, int start) {
if (k == 0) {
ans.push_back(path);
return;
}
for (int i = start; i <= n - k + 1; i ++) {
path.push_back(i);
dfs(n, k - 1, i + 1);
path.pop_back();
}
}
vector<vector<int>> combine(int n, int k) {
dfs(n, k, 1);
return ans;
}
};
电话号码的字母组合
(回溯1)
class Solution {
public:
vector<string> ans;
string path;
// 电话键对应的字母
const string teleAlp[10] = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
void dfs(string& digits, int start, vector<string>& tele) {
if (digits.size() == path.size()) {
ans.push_back(path);
return;
}
// 递归组合字母
for (int i = start; i < tele.size(); i ++) {
string digit = tele[i];
for (int j = 0; j < digit.size(); j ++) {
path += digit[j];
dfs(digits, i + 1, tele);
path.pop_back();
}
}
}
vector<string> letterCombinations(string digits) {
if (digits.empty()) return ans;
// 将数字映射成对应的电话字母
vector<string> tele;
for (int i = 0; i < digits.size(); i ++) {
tele.push_back(teleAlp[digits[i] - '0']);
}
dfs(digits, 0, tele);// 0表示遍历到第0个字母了
return ans;
}
};
这道题目和上面组合的题目很相似,但是不完全一样。
相似点:
1)都是组合问题,将整体中的部分抽离出来组合在一起,相同的字母不会有重复。
不同点:
1)第一道题目“组合“是将自身的一整段拆解成不同的分段然后递归,但是电话号码是在不同的字符串之间的组合递归。左移第一道题目可以从前往后直接遍历就是递归的顺序,但是不同的字符串之间就需要首先找到字符串然后将不同的字符串中的字符用递归拆解出来。
思路1:首先将电话键转换成对应的字符串,然后可以将字符串都放到一个vector中,这样就可以变成一个整体了,最后照着第一道题目做一遍就可以了。
(回溯2)
class Solution {
public:
vector<string> ans;
string path;
// 电话键对应的字母
const string teleAlp[10] = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
void dfs(string& digits, int index, vector<string>& tele) {
if (digits.size() == path.size()) {
ans.push_back(path);
return;
}
// 递归组合字母
string digit = tele[index];
for (int i = 0; i < digit.size(); i ++) {
path += digit[i];
dfs(digits, index + 1, tele);
path.pop_back();
}
}
vector<string> letterCombinations(string digits) {
if (digits.empty()) return ans;
// 将数字映射成对应的电话字母
vector<string> tele;
for (int i = 0; i < digits.size(); i ++) {
tele.push_back(teleAlp[digits[i] - '0']);
}
dfs(digits, 0, tele);// 0表示遍历到第0个字母了
return ans;
}
};
还有一种方式就是让递归中带一个参数index来遍历tele中的单词。
组合总和
题目要求:给定一个无重复元素的数组和一个目标数,在数组中找出所有可以是的数字相加等于目标数的数字。数字组合中不能有重复的组合。
(回溯)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& candidates, int target, int sum, int start) {
if (sum >= target) {
if (sum == target) {
ans.push_back(path);
}
return;
}
for (int i = start; i < candidates.size(); i ++) {
path.push_back(candidates[i]);
dfs(candidates, target, sum + candidates[i], i);// i是开始搜索位置的起点,不是i+1
path.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
dfs(candidates, target, 0, 0);
return ans;
}
};
这题可以通过加一个变量sum,将数组中的值加到sum上,然后和target比较,如果sum>target这种答案不成立就直接返回。如果sum==target说明这条路线是成立的,所以将path放入答案中。但是还有一个很重要的变量start,先来看看如果没有start答案是什么。假设candidates = [2,3,6,7], target = 7,得出的答案是[2,2,3],[2,3,2],[3,2,2],[7],其实答案也是成立的,但是会有重复的组合答案。要想解决这个重复的问题,其实就是想让数字递归到下一个数字的时候,上一个数字不会再算进来了(比如递归到3的时候,就不要再将2算进来了)。这就需要使用“组合问题”的套路,就是使用一个start变量来控制循环递归不会“回头“。但是这个start和前面几个题目不一样,因为组合出的sum可以有重复数字,所以start需要从i递归,而不是直接i + 1跳过了当前的数字。
(排序+判断->剪枝)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& candidates, int target, int sum, int start) {
if (sum >= target) {
if (sum == target) {
ans.push_back(path);
}
return;
}
for (int i = start; i < candidates.size(); i ++) {
if (sum + candidates[i] > target) break;
path.push_back(candidates[i]);
dfs(candidates, target, sum + candidates[i], i);
path.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
dfs(candidates, target, 0, 0);
return ans;
}
};
当sum在中间某一步过程中已经target就没有必要再算下去了。所以利用if (sum + candidates[i]) > sum break;直接跳过了。前面说了每一份递归都对应这一个递归搜索数,所以如果将数组先排序这样递归树的右边的sum更大,这样再使用上面的判断剪枝的效果可以更明显。所以这题最佳的剪枝方法就是排序+判断。
组合总和Ⅱ
题目要求:给定一个数组(可能有重复元素)和一个目标数,在数组总找出可以组合成目标数的数字组合,所以的数字只能有一次
(回溯 + 预判和->剪枝 + 特判重复元素->剪枝)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& candidates, int target, int sum, int start) {
if (target == sum) {
ans.push_back(path);
return;
}
for (int i = start; i < candidates.size(); i ++) {
// 预判一下sum的总和,如果>target可以直接跳过
if (target < candidates[i] + sum) break;
// 重复元素只计算第一个元素的path,其余重复的元素直接跳过
if (i != start && candidates[i] == candidates[i - 1]) continue;
// 回溯
path.push_back(candidates[i]);
dfs(candidates, target, sum + candidates[i], i + 1);
path.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
// 先排序方便去重
sort(candidates.begin(), candidates.end());
dfs(candidates, target, 0, 0);
return ans;
}
};
这道题目时尚到题目的升级版本
不同点:
1.39题中元素可以重复使用,本题的元素不可以重复使用了
2.39题的数组中没有重复元素(因为可以重复使用当前数所以也没有必要有重复元素了),本题可以有重复的元素
相同点:
1.解集不能有重复组合
所以这道题目的关键就是如何解决元素不可以重复还可以兼顾解集中没有重复的组合。
上一道题目利用一个start变量就可以让数字遍历的时候不可以使用前面已经使用过的元素(除了当前元素外),这样就可以避免有重复的组合了。本题也可以使用这种技巧,但是因为不可以使用重复元素,所以递归的时候需要传递i+1而不是i。
设置了start变量后还有一个问题就是还有重复的元素,如果重复元素和之前一样的递归就会有重复的元素(相当于将39题的可以重复使用的数,具体的罗列出来放到了循环中),所以需要跳过这些重复的数字,同时第一个重复元素需要正常计算。39题通过sort可以剪枝,但是本题不仅为了剪枝还需要通过sort是的重复的元素的相邻方便后面可以去重,然后通过if (i != start && candidates[i] == candidates[i - 1]) continue;`就可以直接跳过重复的元素递归了。
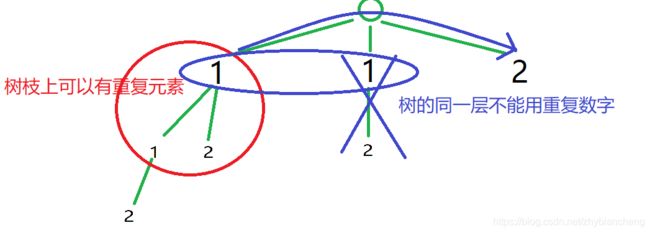
总结:在递归树的树枝上是可以有重复元素的,但是同一树层上不可以有重复元素了, 树枝上去重可以用unordered_set或者其他容器,但是树层上去重就需要用排序来解决了。
(回溯 + 哈希表去重)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& candidates, int target, int sum, int start) {
if (target == sum) {
ans.push_back(path);
return;
}
unordered_set<int> hash;
for (int i = start; i < candidates.size(); i ++) {
// 预判一下sum的总和,如果>target可以直接跳过
if (target < candidates[i] + sum) break;
// 重复元素只计算第一个元素的path,其余重复的元素直接跳过
if (hash.count(candidates[i])) continue;
// 回溯
hash.insert(candidates[i]);// 将当前元素放入哈希表中
path.push_back(candidates[i]);
dfs(candidates, target, sum + candidates[i], i + 1);
path.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
// 先排序方便去重
sort(candidates.begin(), candidates.end());
dfs(candidates, target, 0, 0);
return ans;
}
};
组合总和Ⅲ
题目要求:找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
(回溯 + 控制范围->剪枝)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(int k, int target, int sum, int start) {
// 剪枝
if (sum > target || path.size() > k) return ;
// 判断答案
if (sum == target && path.size() == k) {
ans.push_back(path);
return;
}
for (int i = start; i <= 9 - (k - path.size()) + 1; i ++) {
if (i > target) break;// 剪枝
// 回溯
path.push_back(i);
sum += i;
dfs(k, target, sum, i + 1);
sum -= i;
path.pop_back();
}
}
vector<vector<int>> combinationSum3(int k, int n) {
dfs(k, n, 0, 1);
return ans;
}
};
有了上面两道题目的基础这道题目其实已经不难了,这题既没有重复的元素,也不用排序(1到9天然排序),所以直接遍历递归就可以了,唯一要注意的地方就是if (i > n) break当i大于目标n的时候就可以直接break了。
三重剪枝:
1.sum > target剪枝,保证sum大的部分可以直接跳过
2.i > target剪枝,保证sum加上的数字一定比target小
3.i <= 9 - (k - path.size()) + 1剪枝保证了组合出来的一定有k个数。
分割
*分割回文串
(回溯)
class Solution {
public:
vector<vector<string>> ans;
vector<string> path;
bool isPali(string& s, int left, int right) {// 判断回文串
while (left < right) {
if (s[left] != s[right]) return false;
left ++;
right --;
}
return true;
}
void dfs(string& s, int start) {
if (start == s.size()) {
ans.push_back(path);
return;
}
// 用start来切割字符串,如果是回文串就放入path,如果不是就跳过
// 直到start切割完整个字符串,然后重新切割
for (int i = start; i < s.size(); i ++) {
if (!isPali(s, start, i)) continue;
path.push_back(s.substr(start, i - start + 1));
dfs(s, i + 1);
path.pop_back();
}
}
vector<vector<string>> partition(string s) {
dfs(s, 0);
return ans;
}
};
用start作为分割线,判断左边的分割下来的是否为回文串,如果是就判断右边的子串,如果不是就直接跳过。不用担心如果左边不是回文串,但右边是回文串,因为右边如果是回文串的话,一定包含在左边是回文串的递归中。
class Solution {
public:
vector<vector<string>> ans;
vector<string> path;
bool isPali(string& s, int left, int right) {// 判断回文串
while (left < right) {
if (s[left] != s[right]) return false;
left ++;
right --;
}
return true;
}
void dfs(string s) {
if (s.size() == 0) {
ans.push_back(path);
return;
}
// 枚举字符串的个数
// 将字符串一段一段切割下来,前半段子串判断是否为回文串,如果是再判断后半段
for (int i = 1; i <= s.size(); i ++) {
if (isPali(s, 0, i - 1)) {
path.push_back(s.substr(0, i));
dfs(s.substr(i));
path.pop_back();
}
}
}
vector<vector<string>> partition(string s) {
dfs(s);
return ans;
}
};
复原IP地址
(回溯)
class Solution {
public:
vector<string> ans;
bool isVail(string& s, int start, int end) {
// '.'可能是加在整个字符串的后面的,所以要判断一下start的位置
if (start > end) return false;
// 判断是否有前导0
if (s[start] == '0' && start != end) return false;
int num = 0;
// 将数字转换成数字判断是否>255
for (int i = start; i <= end; i ++) {
if (s[i] < '0' || s[i] > '9') return false;
num = num * 10 + (s[i] - '0');
if (num > 255) return false;
}
return true;
}
void dfs(string& s, int start, int point) {
// 当有3个小数点就完成了一次递归
if (point == 3) {
if (isVail(s, start, s.size() - 1)) {
ans.push_back(s);
}
return ;
}
// 字符串从start开始遍历,最多到start+3
for (int i = start; i < start + 3; i ++) {
// 判断[start,i]区间中数字是否合法
if (isVail(s, start, i)) {
// 如果数字合法就在合法数字的后面加上'.'
s.insert(s.begin() + i + 1, '.');
point ++;
// 递归'.'后面的字符串
dfs(s, i + 2, point);
point --;
// 撤销数字后面的'.'
s.erase(s.begin() + i + 1);
} else break;
}
}
vector<string> restoreIpAddresses(string s) {
dfs(s, 0, 0);
return ans;
}
};
遍历整个字符串,将数字抽离出来,因为IP地址数字最大为255所以只用每一个递归找出数只需要从前往后找3位数字即可。然后判断字符串的合法性,如果合法就在字符串后面加上‘.’否则就跳过,其中要注意的是,因为是在字符串后面一位加上“.”,所以要在字符串后面第二位开始递归下一个数字。isVail()函数就是判断字符串的合法性,有三种情况会返回false,1.’.’在整个字符串的最后 2.字符串有前导零 3.字符串转换为数字后>255。还有一点要注意的是,当小数点有3个的时候,需要返回答案之前需要对最后一个字符串进行检查。
子集(全组合)
子集
题目要求:一个没有重复元素的数组,返回数组的子集
(回溯1选择位置)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& nums, int start) {
if (start > nums.size()) return;
ans.push_back(path);
for (int i = start; i < nums.size(); i ++) {
path.push_back(nums[i]);
dfs(nums, i + 1);
path.pop_back();
}
}
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums, 0);
return ans;
}
};
子集问题的解法和组合问题也很像,子集可以说是不同数字的组合。另外因为子集的组合中不能有重复的组合所以要设置一个start来让递归数字的时候不会递归重复的数字。因为子集是整个集合的所有不同数字的组合,所以只有当start>nums.size()的时候才返回,并且将递归中所以的组合都放入答案中即可。
这样方式在选择位置,从哪个位置上开始选择数字,依次往后遍历选择。
(二进制枚举)
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> ans;
int len = 1 << nums.size(); // 1^(nums.size()) 1的nums.size()次方种情况
for (int i = 0; i < len; i ++) {
vector<int> path;
// 判断枚举的位置
for (int j = 0; j < nums.size(); j ++) {
if ((i >> j) & 1)
path.push_back(nums[j]);
}
ans.push_back(path);
}
return ans;
}
};
枚举位置还可以用非递归的方式,用二进制枚举不同的位置上的数。
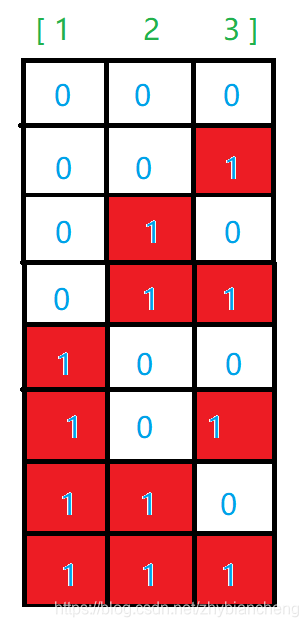
比如nums的数字的个数为3的时候,1表示选择,0表示不选择,有23种情况。所以就可以循环2num.size()次,每次判断数字上的数的二进制上的1的位置,即选中的数字。
(回溯2选择数字)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& nums, int index) {
if (index == nums.size()) {
ans.push_back(path);
return;
}
// 选择nums[index]
path.push_back(nums[index]);
dfs(nums, index + 1);
path.pop_back();
// 不选nums[index]
dfs(nums, index + 1);
}
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums, 0);
return ans;
}
};
第二种方法就是因为要枚举所有数字的组合,所以每个数字都有选择和不选择的机会,所以用一个变量index来遍历nums中的数字,每个递归中都有选该数字和不选该数字的两种选择。
(枚举)
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> ans;
ans.push_back(vector<int>());
for (int i = 0; i < nums.size(); i++) {
// 必须要先记录当前的ans中的个数,因为下面要给ans添加元素,用nums.size()回死循环
int size = ans.size();
// 枚举ans中的所有元素,并在后面加上当前数字
for (int j = 0; j < size; j ++) {
auto t = ans[j];
t.push_back(nums[i]);
ans.push_back(t);
}
}
return ans;
}
};
枚举每一个数字,每次循环都是给每一个原有的集合后添加一个数字构成一个新的集合。
子集Ⅱ
题目要求:给定一个有重复元素的数组,返回数组的子集,子集中不能有重复的集合
(回溯+下标判断去重)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& nums, int start) {
if (start > nums.size()) return ;
ans.push_back(path);
for (int i = start; i < nums.size(); i ++) {
if (i != start && nums[i] == nums[i - 1]) continue;
path.push_back(nums[i]);
dfs(nums, i + 1);
path.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end());
dfs(nums, 0);
return ans;
}
};
这道题目类似组合问题Ⅲ,都是有重复元素但是不能有重复的组合,所以这道题目的解决方法也可以类似解决:将重复元素去重组合(树层去重,不是树枝去重)。先将数组排序,然后遍历的时候,只有重复元素的第一个数字可以进行递归,后面的重复元素直接跳过。
注意:排序+剪枝是常见的套路。
(回溯+哈希表去重)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& nums, int start) {
if (start > nums.size()) return ;
ans.push_back(path);
unordered_set<int> hash;
for (int i = start; i < nums.size(); i ++) {
// 用哈希表去重
if (hash.count(nums[i])) continue;
hash.insert(nums[i]);// 将数字放入哈希表中不用回溯,这样才可以树层去重
path.push_back(nums[i]);
dfs(nums, i + 1);
path.pop_back();
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end());
dfs(nums, 0);
return ans;
}
};
注意:哈希表去重的时候,在树的递归中需要同一层的数字不可以再被使用,所以在递归完成后不需要将哈希表中的元素去除,因为那样是树枝去重,而在地柜的过程中是可以使用重复元素的,只是在横向循环的时候不可以使用重复元素。
(二进制枚举+哈希表去重)
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
// 首先需要排序,这样就不会有[A,B],[B,A]这样的重复组合了
sort(nums.begin(), nums.end());
vector<vector<int>> ans;
set<vector<int>> hash;
// 二进制枚举
int len = 1 << nums.size();
for (int i = 0; i < len; i ++) {
vector<int> path;
for (int j = 0; j < nums.size(); j ++) {
if ((i >> j) & 1)
path.push_back(nums[j]);
}
hash.insert(path);
}
ans.assign(hash.begin(), hash.end());
return ans;
}
};
注意因为要用哈希表去重(这里只能用set不能用unordered_set)答案最后的答案要用vector返回,所以要用到assign函数,这个函数可以让不同容器之间赋值。(或者可以用哈希表初始化ans,vector)
字母全排列(子集问题)
(回溯)
class Solution {
public:
vector<string> ans;
void turn(string& s, int i) {// 大小写字母转换
if (s[i] <= 'z' && s[i] >= 'a') s[i] -= 32;
else s[i] += 32;
}
void dfs(string& s, int start) {
if (start > s.size()) return ;
ans.push_back(s);
for (int i = start; i < s.size(); i ++) {
if (!isalpha(s[i])) continue;
turn(s, i);// 大小写转换
dfs(s, i + 1);
turn(s, i);// 大小写转换
}
}
vector<string> letterCasePermutation(string s) {
dfs(s, 0);
return ans;
}
};
这题说是一个字母全排列的问题,但是实际上是一个字母全组合求子集的问题。因为这题不是将字符串的所有字符打乱了重新排列而是将字符串中的所有大小写转换一下而已,所以就可以看成将字符串中的所有字母抽出来,求出这些字母的大小写转换子集,所以就直接用一个start变量防止子集重复,然后递归即可。
这题比较考察抽象转化能力,即将在字符串上的大小写转换子集抽象成求子集问题。
排列
全排列
题目要求:给定一个没有重复数字的数组,返回所有可能的全排列
(回溯)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& nums, vector<bool>& vis) {
if (path.size() == nums.size()) {
ans.push_back(path);
return ;
}
for (int i = 0; i < nums.size(); i ++) {
if (!vis[i]) {// 如果当前遍历到的元素没有使用过
path.push_back(nums[i]);
vis[i] = true;// 标记当前的元素已经使用
dfs(nums, vis);
vis[i] = false;
path.pop_back();
}
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<bool> vis(nums.size(), false);
dfs(nums, vis);
return ans;
}
};
和组合问题不同的是像[1,2,3],[3,2,1]这样是同一个组合但是不同的排列,所以原来需要设置一个start变量防止出现之前出现过的数字,但是现在不用了,虽然可以出现以前出现过的数字,但是因为全排列是选取树的子集结点作为答案的,所以如果只是每一都遍历数组中的数,就会重复枚举数字本身,所以就需要用一个变量记录一下(可以是哈希表也可以是bool数组),在递归中一个递归的分治上不可以重复的枚举数字本身。
void dfs(vector<int>& nums, vector<bool>& vis, int index) {
if (index == nums.size()) {// 也可以用index表示当前选取到了第几层,这样就不用算path.size()消耗时间了
ans.push_back(path);
return ;
}
/*
...
*/
}
全排列Ⅱ
(回溯+哈希表去重)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& nums, vector<bool>& vis, int index) {
if (index == nums.size()) {
ans.push_back(path);
return;
}
unordered_set<int> hash;// 只在递归的这一层生效的哈希表去重,即堆树层的去重
for (int i = 0; i < nums.size(); i ++) {
if (vis[i] == true || hash.count(nums[i])) continue;
hash.insert(nums[i]);
path.push_back(nums[i]);
vis[i] = true;
dfs(nums, vis, index + 1);
vis[i] = false;
path.pop_back();
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(), nums.end());// 可以省略
vector<bool> vis(nums.size(), false);
dfs(nums, vis, 0);
return ans;
}
};
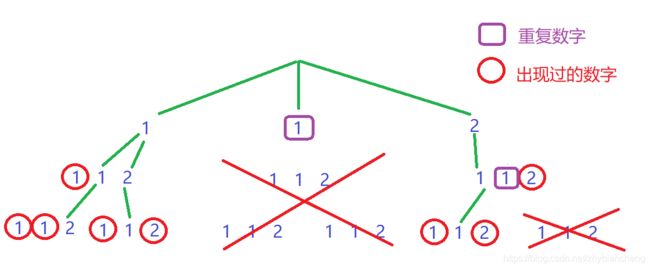
同一层的重复数字直接跳过,但是不是同一层的(递归)可以有重复数字,所以哈希表在递归中定义而不是函数传参。在递归过程中只有出现过的数字不能再出现。
(回溯+下标判重)
class Solution {
public:
vector<vector<int>> ans;
vector<int> path;
void dfs(vector<int>& nums, vector<bool>& vis, int index) {
if (index == nums.size()) {
ans.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i ++) {
// 如果是已经出现过的数字就跳过
if (vis[i] == true) continue;
// 如果不是第一个数字并且有重复且重复元素前面没有正在使用就跳过
if (i && nums[i] == nums[i - 1] && vis[i - 1] == false) continue;
path.push_back(nums[i]);
vis[i] = true;
dfs(nums, vis, index + 1);
vis[i] = false;
path.pop_back();
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(), nums.end());
vector<bool> vis(nums.size(), false);
dfs(nums, vis, 0);
return ans;
}
};
注意强调一点在去重前一定要对元素进行排序,而且这里的判重和之前的组合题目的判重有一点区别if (i && nums[i] == nums[i - 1] && vis[i - 1] == false) continue;多加了一个条件就是vid[i - 1] == false要求重复元素的前面一个数字没有使用过,这是因为组合问题有一个变量start来控制循环的时候天然的跳过了已经使用过的数字,这样就不会影响之后和本递归有关的递归,但是排列问题每次递归都要从0~nums.size()这样会在一次递归的过程中(树枝路径上)遇到重复的元素就也会跳过了,所以多加了一个条件vis[i - 1] == false就可以区分是树枝上的重复元素还是树层上的重复元素,在树枝上的的递归会因为之前使用过重复元素而不会跳过,但是在树层上的元素在循环遍历到第二个重复元素的时候会因为第一个重复元素没有使用过而直接跳过后面的重复元素。
补充:其实将false改成true也是可以通过的,即if (i && nums[i] == nums[i - 1] && vis[i - 1] == true) continue;。这样写会使原来在树层上去重的元素因为vis[i - 1]是false而不会去重,但是树枝上的重复元素就会去除,这样写的可读性和性能上都没有vis[i - 1] == false好,所以只要了解即可。
去重问题总结
通过了三道题目(组合总和Ⅱ,子集Ⅱ,全排列Ⅱ)的练习,通常对于重复的数字的组合,一般有两种方法解决:1.下标判重,2.哈希表判重
注意这三道题目在判重之前都需要堆数组进行排序(用哈希表去重可以不用sort,下标判重需要)。因为只有sort之后才可以让重复的元素相邻在一起,这样才可以判断是否需要跳过相邻的重复元素,如果重复元素不相邻就只能用unordered_set哈希表来记录同一层的递归中的重复元素。
分析两种方法和使用的注意事项:
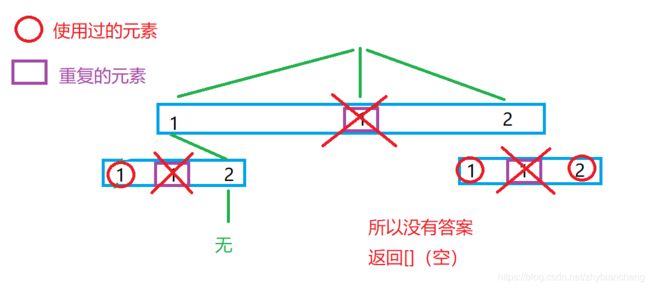
1)哈希表去重
使用注意:一定不可以将哈希表当做函数参数传参或者是定义在全局然后在函数里面hash.count(nums[i])之后再回溯hash.erase(nums[i]),这样就不是仅仅对于同一层的树层递归去重了,而是对树层和树枝的所有重复元素都去重。举个:对于 [1, 2, 2] 全排列
时间复杂度:因为哈希表在insert的时候要哈希映射等等一系列的复杂操作,所以时间消耗上会有一定的开销
空间复杂度:递归使用的系统栈是O(N)的,但是每一层都会有O(N)的空间给哈希表所以总共的空间复杂度为O(N2),这样的空间复杂度会陡然上升。
2)下标判重
if (i > 0 && nums[i] == nums[i - 1] && ?) continue;
下标判重不会有额外的开销尽管在传参的时候需要传一个nums但是也只有O(N)加上系统栈的O(N)总共还是O(N)的空间复杂度。
棋盘问题
N皇后
N皇后是典型的的回溯问题:游戏规则是每一行都需要放一个皇后但是所有的皇后都**不可以同行,同列,同对角线。**假设需要放4皇后我们就需要写4个循环分别枚举每一行上的皇后位置,来保证所有行的皇后都不相互冲突。但是如果放10个皇后再用10个循环就太累了吧。所以自然想到用“暴搜”-回溯。
根据刚才的逻辑可以递归每一行,然后每个递归中用循环枚举当前行上可以放皇后的位置。也就是如果是递归树的话,树层上横向枚举每一行的纵坐标,树枝上纵向枚举每一行。
当可以递归到最后一行时就将棋盘放入答案中。
其中还有一个关键点就是只有当房放皇后的位置不和其他的皇后冲突的时候才可以放皇后,否则就直接跳过。如果判断棋盘上皇后的冲突问题有基本的两种房方法:
1)循环遍历当前皇后所在位置的列,对角线。要注意的是这里可以剪枝:只需要遍历检查当前皇后位置的前面的行数,不用遍历后面的行数,因为后面默认还没有放皇后。
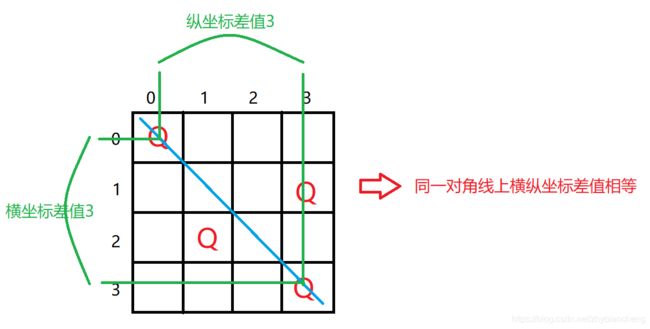
2)利用数学技巧,如果两个皇后在对角线上那么两个皇后的横纵坐标是相同的,所以可以再开一个空间vector记录当前行上的皇后的纵坐标,即(i, record(i))是棋盘上的皇后的坐标,(row, col)是当前皇后的坐标。
(回溯+循环判断)
class Solution {
public:
vector<vector<string>> ans;
bool isVail(vector<string>& board, int row, int col) {
// 检查:检查当前皇后前面的row就可以,不用检查后面的位置,因为还没有放皇后
// 检查行
for (int i = 0; i < row; i ++) {
if (board[i][col] == 'Q') return false;
}
// 检查正对角线
for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i --, j --) {
if (board[i][j] == 'Q') return false;
}
// 检查副对角线
for (int i = row - 1, j = col + 1; i >= 0 && j < board[0].size(); i --, j ++) {
if (board[i][j] == 'Q') return false;
}
return true;
}
void dfs(vector<string>& board, int row, int n) {
if (row == n) {
ans.push_back(board);
return ;
}
for (int col = 0; col < n; col ++) {
if (!isVail(board, row, col)) continue;
board[row][col] = 'Q';
dfs(board, row + 1, n);
board[row][col] = '.';
}
}
vector<vector<string>> solveNQueens(int n) {
vector<string> board(n, string(n, '.'));
dfs(board, 0, n);
return ans;
}
};
(回溯+数学判断)
class Solution {
public:
vector<vector<string>> ans;
bool isVail(vector<int>& rec, int row, int col) {
// i行上对应的皇后的位置为rec[i]
// 如果对角线上有皇后那么当前皇后的位置的横纵坐标和另一个皇后的横纵坐标差值相等
for (int i = 0; i < row; i ++) {
if (col == rec[i] || abs(i - row) == abs(col - rec[i])) return false;
}
return true;
}
void dfs(vector<string>& board, int row, int n, vector<int>& rec) {
if (row == n) {
ans.push_back(board);
return ;
}
for (int col = 0; col < n; col ++) {
if (!isVail(rec, row, col)) continue;
rec[row] = col;// 记录皇后的位置
board[row][col] = 'Q';
dfs(board, row + 1, n, rec);
board[row][col] = '.';
rec[row] = -1;// 还原皇后的位置
}
}
vector<vector<string>> solveNQueens(int n) {
vector<string> board(n, string(n, '.'));
vector<int> rec(n, -1);// 记录第i行的皇后的位置j,如果没有皇后就默认为-1
dfs(board, 0, n, rec);
return ans;
}
};
解数独
题目要求:返回一个填好的有效数独。
解数独问题看起来很像N皇后问题,但是要比N皇后问题复杂很多。N皇后只需要在每一行上放一个皇后即可,所以就可以用循环遍历枚举一行上的所有列位置,然后通过递归来枚举行数,直到遍历完整个棋盘。但是数独问题又添加了一个维度,即每一行上需要满,并且每一个位置上都要1到9,9种可能性。所以由原来的枚举一行上的列数变成枚举一个位置上的可能性,并且需要递归实现棋盘的行数和列数。
整理一下思路:在N皇后的基础上添加一个维度,所以需要循环枚举每个位置上的可能性(1~9),然后递归遍历棋盘上的所有位置(行和列)。
在整体思路的基础上还有3个需要观察的细节:
1)题目只要求返回一个有效的数独,所以只需要填好一个数独就可以返回了,不需要求解出所有的情况。所以可以将函数==**dfs()的返回值改成bool**==就可以实现了。因为当回溯递归if (dfs(board) == true) return true;条件实现的时候就可以不用再往下递归了,这样就可以保证当遇到第一个解的时候可以直接返回而不是继续往下递归搜索。
2)在枚举一个位置上的可能性的时候,需要判断该数字==是否可以使得数独成为有效数独==,如果不是有效的数独就直接跳过这种可能性继续枚举下一个可能性。这里给出3中判断的方式。第一种是判断整个棋盘是否为有效的数独,这样没有什么必要,因为只需要判断当前位置上的行列和子数独知否有效就可以了。所以给出2.1和2.2的版本。
3)最后要注意的是,如果一个位置上枚举完了9种可能性但是都没有成功就需要return false了,这样说明在原来的数独的基础上不可能形成有效的数独,所以要回溯到上一层的枚举。如果枚举完了所有的情况不返回false的话,结果就没有出口了,就会递归死循环或者程序执行错误。
判断数独是否有效
1.判断整个数独是否有效
bool isVail(vector<vector<char>>& board) {
bool rows[9][9] = {false};
bool cols[9][9] = {false};
bool boxs[9][9] = {false};
for (int i = 0; i < 9; i ++) {
for (int j = 0; j < 9; j ++) {
if (board[i][j] == '.') continue;
int num = board[i][j] - '1';
int index = i/3*3 + j/3;
if (rows[i][num] || cols[j][num] || boxs[index][num]) return false;
else {
rows[i][num] = true;
cols[j][num] = true;
boxs[index][num] = true;
}
}
}
return true;
}
开3块空间将i和j映射到对应的行和列上,i/3*3 + j/3将子数独的二维数组映射到对应的行上(第几个数独就映射到第几行上)。将num填充到对应的行或者列上判断时候有重复的元素。

2.1判断该位置是否可以形成有效数独
bool isVail(vector<vector<char>> board, int r, int c, int ch) {
// 遍历列
for (int i = 0; i < 9; i ++) {
if (board[i][c] == ch) return false;
}
// 遍历行
for (int i = 0; i < 9; i ++) {
if (board[r][i] == ch) return false;
}
// 遍历子数独
int s1 = r/3*3;// 子数独的横坐标起点
int s2 = c/3*3;// 子数独的纵坐标起点
for (int i = s1; i < s1 + 3; i ++) {
for (int j = s2; j < s2 + 3; j ++) {
if (board[i][j] == ch) return false;
}
}
return true;
}
解释:遍历行和列就不说了,就是直接循环遍历即可。r/3*3和c/3*3是找到当前位置是位于哪一个子数独上,(r/3*3, c/3*3)是子数独的左上角的起点,然后遍历这个小的二维数组子数独。
2.2判断该位置是否可以形成有效数独
bool isVail(vector<vector<char>>& board, int r, int c, int ch) {
for (int i = 0; i < 9; i ++) {
// 枚举列
if (board[i][c] == ch) return false;
// 枚举行
if (board[r][i] == ch) return false;
// (r/3*3, c/3*3)是子数独的左上角的起点
// 用i/3累加到行数上和i%3累加到列数上
if (board[r/3*3 + i/3][c/3*3 + i%3] == ch) return false;
}
return true;
}
(r/3*3, c/3*3)是子数独的左上角的起点,r/3*3 + i/3是遍历子数独的行数,c/3*3 + j%3是遍历子数独的列数。
(穷举回溯)
class Solution {
public:
bool isVail(vector<vector<char>>& board, int r, int c, int ch) {
for (int i = 0; i < 9; i ++) {
// 枚举列
if (board[i][c] == ch) return false;
// 枚举行
if (board[r][i] == ch) return false;
// (r/3*3, c/3*3)是子数独的左上角的起点
// 用i/3累加到行数上和i%3累加到列数上
if (board[r/3*3 + i/3][c/3*3 + i%3] == ch) return false;
}
return true;
}
bool dfs(vector<vector<char>>& board, int row, int col) {// 在(row,col)上填充数字
// 这种写法也可以
//if (col == 9) {
// col = 0;
// row ++;
// if (row == 9) {
// return true;
// }
//}
// 如果一行的列数已经枚举完了就换下一行
if (col == 9) {
return dfs(board, row + 1, 0);
}
// 如果行数已经枚举完了并且可以形成一个有效的数独就返回true
if (row == 9) {
return true;
}
// 如果不是数字就枚举下一个位置
if (board[row][col] != '.') {
return dfs(board, row, col + 1);
}
// 在(row,col)的位置上枚举1到9
for (char ch = '1'; ch <= '9'; ch ++) {
// 如果(row,col)的行或列或对角线是ch就跳过
if (!isVail(board, row, col, ch)) continue;
board[row][col] = ch;
if (dfs(board, row, col + 1)) return true;// 如果发现有一个有效的数独就直接返回
board[row][col] = '.';
}
return false;
}
void solveSudoku(vector<vector<char>>& board) {
dfs(board, 0, 0);
}
};
从(0,0)枚举每遍历完一行就需要换到下一行。
(循环回溯)
class Solution {
public:
bool isVail(vector<vector<char>>& board, int r, int c, int ch) {
for (int i = 0; i < 9; i ++) {
// 枚举列
if (board[i][c] == ch) return false;
// 枚举行
if (board[r][i] == ch) return false;
// (r/3*3, c/3*3)是子数独的左上角的起点
// 用i/3累加到行数上和i%3累加到列数上
if (board[r/3*3 + i/3][c/3*3 + i%3] == ch) return false;
}
return true;
}
bool dfs(vector<vector<char>>& board) {
for (int i = 0; i < 9; i ++) {
for (int j = 0; j < 9; j ++) {
if (board[i][j] != '.') continue;
for (char ch = '1'; ch <= '9'; ch ++) {
if (!isVail(board, i, j, ch)) continue;
board[i][j] = ch;
if (dfs(board)) return true;
board[i][j] = '.';
}
return false;
}
}
return true;// 当棋盘全部遍历完就可以返回true
}
void solveSudoku(vector<vector<char>>& board) {
dfs(board);
}
};