【C++】位图及其应用

write in front
所属专栏: C++学习
️博客主页:睿睿的博客主页
️代码仓库:VS2022_C语言仓库
您的点赞、关注、收藏、评论,是对我最大的激励和支持!!!
关注我,关注我,关注我,你们将会看到更多的优质内容!!
文章目录
- 前言
- 一.位图
-
- 1.一道面试题:
- 2.位图的概念:
- 3.位图的模拟实现:
- 3.位图的应用
- 二.位图的实际使用场景:
-
- 场景1:
- 场景2.
- 场景3:
- 三.库里面的bitset:
- 总结
前言
在前面我们简单介绍了哈希和哈希表的概念,并模拟实现了unordered_map和unordered_set,下面我们就来介绍一下哈希的应用
一.位图
我们先通过一个面试题来引入位图:
1.一道面试题:
【腾讯】给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
在这里最先想到了下面两种方法:
- 遍历,时间复杂度O(N)
- 排序(O(NlogN)),利用二分查找: O(logN)
- set来查询
上面的方法对于数据量少的数据还是可以解决的,但是对于40亿个整数,也就是160亿个字节还是不够存储的。我们知道,1G差不多就是10亿字节,如果存储在内存里面就需要16G,普通的电脑根本无从下手。而且,这道题问的是在不在的问题,这里就可以通过位图来解决这道题目。
2.位图的概念:
当面对海量数据时,我们一般的数据结构无法存储那么多的值,要对这些数据进行分析,我们就可以采用位图来对这些数据进行标记(不是存储)。位图适用于海量数据,数据无重复的场景,通常用来判断这个数据是否存在。位图采用的就是哈希里面的直接定址法:

对于整数,最大值也就是2^32 次方,所以这里我们只需要2^ 32次方个数字就可以表示完所有的整数,由于是在不在问题,每一个位置的1表示在,0表示不在即可。所以我们只需要2^32 个比特位即可,也就是2^29个字节,0.5G就可以完成这道面试题。
3.位图的模拟实现:
在我们的vs编译器下,是小端类型,存储是这样的:(低地址存低位)
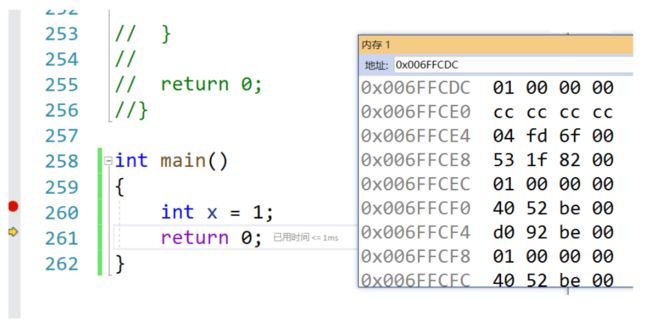
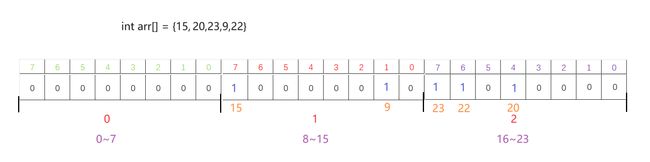
这里我们在讲解一下小端存储,在一个整形的内存里面,01 00 00 00,01是地址最低的一个字节,但是每一个字节里面存储的的顺序右和我们平常存的顺序是一样的,比如1是0000000001。举个例子:(左边是低地址)

在下面的操作里面,为了标记哪个位置是否存在,就要使用按位与和按位或的操作,从而要对1进行左移,但是在这里大家看到01 00 00 00就会觉得奇怪,为什么可以左移呢?其实左移的定义是往高位移动,只是平时我们写的时候习惯了高位在左边,低位在右边的形式。下面我举个例子:
00000000 00000000 00000000 00000001在内存里面是这样存的
00000001 00000000 00000000 00000000
如果我们对1左移10个位置,也就是
00000000 00000100 01000000 00000000
这里就是说编译器在进行左移的时候,先是每一个字节里面左移,左移完了发现还没到位就在下一个字节里面继续左移。其实编译器的左移和我们找位置找到的地方是一致的。
代码实现:
template<size_t N>
class bitset
{
public:
bitset()
{
_a.resize(N / 32 + 1, 0); //至多多开一个int 空间
}
void set(size_t x)
{
//先寻找在哪一个字节里面
size_t i = x / 32;
//在寻找在这个字节里面的哪个位置
size_t j = x % 32;
//1左移j个位置就是将那个位置置为1,其他位置置为0
_a[i] |= (1 << j);
}
void reset(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
//置0
_a[i] &= ~(1 << j);
}
bool test(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
return _a[i] & (1 << j);
}
private:
vector<int> _a;
};
这里采用vector来管理位集合的数据,int为4byte,占32个比特位
采用非类型模板参数,来表示要开多少个空间,N/32 + 1,这里防止开的空间不够,所有每次直接+1,至多多开一个整型空间
3.位图的应用
- 快速查找某个数据是否在一个集合中
- 排序 + 去重(计数排序)
- 求两个集合的交集、并集等(后面会讲到)
- 操作系统中磁盘块标记
二.位图的实际使用场景:
场景1:
给定100亿个整数,设计算法找到只出现一次的整数?
在这里我们就可以使用两个位图来解决,两个位图也就1G,也不算特别多。我们可以通过两个位图的同一位置的组合来判断出现过几次,比如第一个位图pos位置为0,第二个位图的pos位置为1,就说明其只出现过一次。
template<size_t N>
class twobitset
{
private:
BitSet<N> bt1;
BitSet<N> bt2;
public:
void set(size_t n)
{
size_t i = n / 32;
size_t j = n % 32;
//出现一次的
if (!bt1.test(n) && !bt2.test(n))
{
bt2.set(n);
}
//出现两次的
else if (!bt1.test(n) && bt2.test(n))
{
bt1.set(n);
}
}
bool is_once(size_t n)
{
return !bt1.test(n) && bt2.test(n);
}
};
}
void isOnce()
{
bitSet::twobitset<100> tbt;
int arr[] = { 1,2,3,3,44,6,6,4,4,6,3,1,9,6,8 ,3,22 };
for (auto e : arr)
{
tbt.set(e);
}
for (auto e : arr)
{
if (tbt.is_once(e))
cout << e << " ";
}cout << endl;
}
场景2.
1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
其实这里和上面的的两个位图是一样的,由于00 01 10 11可以表示出四种情况,我们用00表示没有,01表示出现一次,10表示出现两次,11表示两次以上即可:
template<size_t N>
class twobitset
{
public:
void set(size_t x)
{
if (!bt1.test(x) && !bt2.test(x))
{
//00 ->01
bt2.set(x);
}
else if (!bt1.test(x) && bt2.test(x))
{
//01->10
bt2.reset(x);
bt1.set(x);
}
else if (bt1.test(x) && !bt2.test(x))
{
//10->11
bt1.set(x);
bt2.set(x);
}
}
//00
//01
//11
bool lessTwo(size_t x)
{
if ((!bt1.test(x) && bt2.test(x)) || (bt1.test(x) && !bt2.test(x)))
{
bt1.reset(x);
bt2.reset(x);
return true;
}
return false;
}
private:
bitset<N> bt1;
bitset<N> bt2;
};
//模拟
void LessTwo()
{
bitSet::twobitset<10> bt;
int arr[] = { 1,1,2,2,3,3,5,5,5,9,7,7,7,8,8,8,8,1 };
for (auto e : arr)
{
bt.set(e);
}
for (auto e : arr)
{
if (bt.lessTwo(e))
{
cout << e << " ";
}
}cout << endl;
}
场景3:
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
这里有两种方法,其一就是装到两个位图里面比较即可,
其二就是将一个装到位图里面,另一个以文件的形式读取数据并且不断比较,相同的就取出来。但是这里存在重复的问题,所以每从位图里面找到一个交集,就将他reset去掉该位置的存在标记,这样就可以避免取到重复数据。
三.库里面的bitset:
其实库里面有位图的实现了,我们只需直接使用即可。bitset

总结
更新不易,辛苦各位小伙伴们动动小手,三连走一走 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
专栏订阅:
每日一题
C语言学习
算法
智力题
初阶数据结构
Linux学习
C++学习
更新不易,辛苦各位小伙伴们动动小手,三连走一走 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!