论文阅读:Seeing in Extra Darkness Using a Deep-Red Flash
论文阅读:Seeing in Extra Darkness Using a Deep-Red Flash
今天介绍的这篇文章是 2021 年 ICCV 的一篇 oral 文章,主要是为了解决极暗光下的成像问题,通过一个深红的闪光灯补光。实现了暗光下很好的成像效果,整篇文章基本没有任何公式,所用到的网络也比较简单,但最后成了一篇顶会的 Oral 文章,可能主要创新在于软硬件结合吧。
Abstract
本篇文章提出了一种新的闪光灯技术,利用一个深红波段的闪光灯进行补光,文章作者说,他们主要观察到在明亮环境下,人眼由视锥细胞主导成像感知,在暗光环境下,人眼主要由视杆细胞主导成像感知。人眼的视杆细胞对波长大于 620nm 的红外光谱并不敏感,然而相机 sensor 依然有感应。文章作者提出了一种新的调制策略,通过 CNN 网络实现图像引导的滤波,将一张有噪的 RGB 图像与一张闪光拍摄的图像进行融合。同时,文章将这个融合网络,进一步扩展到了视频重建,文章作者搭建了硬件原型,在不同的静态和动态场景都进行了验证,实验结果,证明这种新型闪光灯技术可以取得很好的成像效果,尤其是在暗光环境下。
Introduction
暗光成像是手机摄影中的一个重要特性,为了提升手机暗光成像的能力,现有的方法也做了多种尝试,从对 sensor 的改造,比如将 RGGB 的贝尔模式替换成了 RYYB 的贝尔模式,到后端算法的设计,比如利用多帧曝光技术。
基于闪光灯的摄影技术,同样也有非常悠久的历史,而且一般来说会获得更好的效果,尤其是在非常暗的环境下还有复杂运动的时候,这种时候,多帧融合的方式可能会存在配准对齐失效的问题。不过,闪光摄影技术也有一些弊端,一个是闪光灯发出的光随着距离的增加,衰减地很快,所以闪光灯一般能照射的有效距离不会太远;此外,闪光灯在闪光的一瞬间,对人眼会造成一个很强的炫目,在暗光环境下,这种强烈的闪光也会造成很不舒适的光污染,对暗视觉下的人眼系统造成损伤。如果利用不可见光波段比如近红外或者近紫外的闪光灯,可以一定程度上避免这个问题,不过目前的相机 sensor 一般对近红外或者近紫外没有光谱响应,需要进行定制化的设计。另外一个问题,RGB 域的图像与不可见光波段的图像域,由于物质对不同光谱的反射特性不一样的原因,可能存在一定的差异。这个对跨模态的图像配准与图像融合都存在一定的挑战。
1.1 Human Visual System
接下来,文章对人眼视觉系统做了分析,人眼的视网膜负责人眼对环境光的响应,视网膜上包含两种感光细胞,一种是视锥细胞,一种是视杆细胞,视锥细胞主要负责人眼对明亮环境以及颜色的感知,视锥细胞对 550nm 波长的光谱响应最强烈,视杆细胞主要负责人眼对暗光环境以及亮度的感知,视杆细胞对 500nm 波长的光谱响应最强烈,视杆细胞对长波长的光谱不敏感,视杆细胞对500nm 波长的光谱响应强度是对 650nm 波长的光谱响应强度的 3 倍。视锥细胞与视杆细胞的组合,形成了对中等光强环境的光谱响应。环境由明亮转为黑暗的时候,人眼需要一个更长的时间来适应,反过来,环境由暗转为明亮的时候,人眼的适应时间会更短。
1.2 Deep-Red Flash
文章作者接下来就提出用深红波段的闪光灯来实现暗光下的摄影,与常见的白光闪光灯比,可以感受到的光照强度会更低,对人眼的刺激会更小,而且夜晚视觉会也能够保存。与不可见波段的闪光灯技术相比,普通的相机 sensor 对深红波段是可以直接响应吸收的,不需要另外再对 sensor 定制,另外,深红波段也属于可见光范围内,与 RGB 图像可以更好地融合。
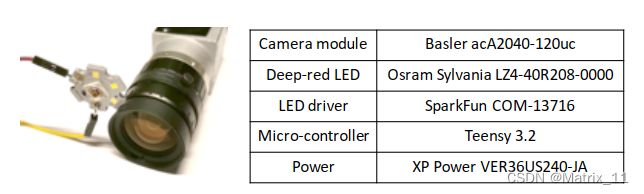
Camera and Flash Module
接下来,文章介绍了整个系统的硬件原型,从图中可以看到,一个可以发射深红波段的闪光灯放置在一个 Camear 旁边,LED 闪光灯通过信号触发,以便闪光灯与拍照能够同步。
Mesopic Flash Reconstruction
这一部分是文章的算法部分,首先文章分析了如何从深红闪光灯下的图像提取引导信息,文章中用到的 sensor,通过光谱响应分析测定,对于 660nm 波长的深红光谱来说,sensor 的红色通道的响应强度是绿色通道的 4 倍,是蓝色通道响应强度的 10 倍。一个直观的策略是直接用红色通道的信息作为引导信息,不过文章作者发现,这种方式可得到的动态范围比较窄,对于红色物体来说,可能很快就达到饱和了,而对于蓝色物体来说,却无法获得足够的能量强度。
为了分析不同物体对这种深红闪光灯的光谱响应,文章作者用 1269 Munsell 色卡进行分析,这个色卡基本可以代表大多数的自然物体,文章考虑了色卡上的每个色块在理想光照情况下对 660nm 的光谱响应,文章中使用一个恒定的光源,同时色块垂直光源发出的入射光线。最后的统计结果如下图所示:

上图左边的图表示的是,相比使用单个红色通道,使用三通道的信息,可以获得更大的动态范围。右边的图是一个统计直方图,表明 80% 的自然物体,对深红波段的光谱响应大于 0.1,说明深红波段有广泛的适用性。
接下来介绍图像融合,有了前面的大量铺垫,这个图像融合反而是比较简单的一种方法,文章中就是用了一个 UNet 来实现这个融合操作,文章中就是直接将没有闪光灯时的 RGB 图像与有闪光灯时的 RGB 图像连接在一起,然后送入一个 UNet 网络,实现整个的融合。
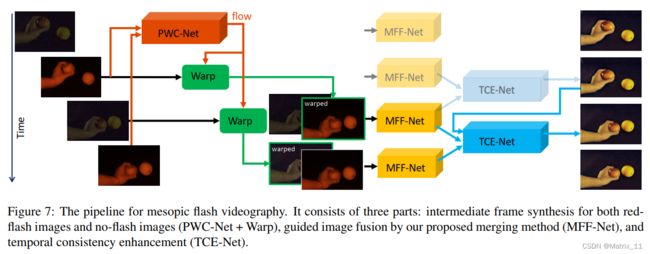
文章中,也介绍了如何对视频流进行操作,文章中提出了一种交叉采集图像,然后逐帧融合的方法,采集的时候,采集一帧有闪光的图像,然后再接一帧没有闪光的图像,这样交替地采集下去,为了实现时域的对齐,文章对 Flash-RGB 图像进行配准,因为常规的 RGB 图像噪声很大,很难配准对齐了。而 Flash-RGB 是通过深红闪光灯补光采集到的图像,所以图像的信噪比更好,更容易进行配准,通过 Flash-RGB 图像配准得到的位移向量场,文章中进行了拆分,一部分用于前一帧 Flash-RGB 图像的 warp,与当前帧的 No-Flash RGB 图像对齐融合,另外一部分用于当前帧的 No-Flash RGB 图像的 warp,与当前帧的 Flash-RGB 图像对齐融合,这样做,可以保证帧率不会减少。融合之后,还会再接一个时域平滑的网络,整体的算法框图如下所示:
Experiments
最后介绍一下实验部分,文章中在训练这个网络的时候,用的是仿真数据,文章中用的是 NYU v2 dataset,给定一张正常的 RGB 图像,通过给 RGB 图像加噪,来模拟暗光下的 RGB 图像,另外对 RGB 图像的三通道直接叠加,模拟深红闪光下的图像,不过为了更好的让网络学习如何利用这个引导信息,文章对模拟的深红图像进行了一个频率调制:
f ( x , y ) = α ⋅ sin ( 2 π T ( x − x ˉ ) 2 + ( y − y ˉ ) 2 ) + β f(x, y) = \alpha \cdot \sin(\frac{2 \pi}{T} \sqrt{(x - \bar{x})^2 + (y - \bar{y})^2}) + \beta f(x,y)=α⋅sin(T2π(x−xˉ)2+(y−yˉ)2)+β
其中, x ∈ { 1 , 2 , . . . , W } x \in \{1, 2, ..., W \} x∈{1,2,...,W}, y ∈ { 1 , 2 , . . . , H } y \in \{1, 2, ..., H \} y∈{1,2,...,H}, α \alpha α 是幅度, x ˉ , y ˉ \bar{x}, \bar{y} xˉ,yˉ 是相位偏移, T T T 是周期, β \beta β 表示垂直偏移。
最后是一些效果样例的展示:

