自然语言处理
1. 自然语言处理任务
1.1. 语言的特点
- 词汇量大、特征多、类别多;
- 语义信息丰富且隐晦,同义词、近义词、反语等;
- 语言之间有差异性。
1.2. 自然语言处理 vs 语音识别
- 语音识别是把声学信号和文字进行相互转换;
- 自然语言处理更多是对文本进行处理,属于一个应用领域,主要任务包括文本分类、关键词提取、机器翻译、阅读理解等。
1.3. 传统自然语言处理的思想
- 自然语言处理的本质是计算一句话是正常表达的概率;
- 对一句话的研究首先需要分词——中文分词用jieba库;
- 贝叶斯公式:
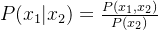 ,进一步推导可得:
,进一步推导可得: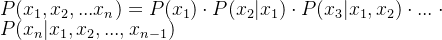 ,在自然语言处理任务中,事件之间的顺序不能随便变换,例如:P(我借你钱) ≠ P(你借我钱) ;
,在自然语言处理任务中,事件之间的顺序不能随便变换,例如:P(我借你钱) ≠ P(你借我钱) ; - 但是在实际任务中,一个词出现的概率往往很小,概率的累乘很容易让结果非常接近0,因此需要马尔可夫的思想进行优化。一阶马尔可夫性指,一个事件发生的概率只与其上一个事件有关,因此将自然语言处理问题近似一阶马尔可夫问题,即:
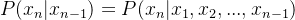 ,这在真实问题中并不严格,但可以进行近似假设;
,这在真实问题中并不严格,但可以进行近似假设; - 但马尔可夫模型也有其局限性,例如:
- 实际问题中的语言未必满足马尔可夫性;
- 单个词语出现的概率不仅与之前的词,也与后面的词有关;
- 很难处理近义词问题。
2. 词向量 Word2Vec
2.1. 神经网络的引入
- 为了解决马尔可夫模型的局限性,可以使用神经网络拟合每个位置出现一个词的概率,网络的输入是该位置前后的词;
- 神经网络只能输入向量,因此需要对每个词进行独热编码,编码成向量即可输入;
- 但这种方法会带来稀疏问题,输入的每个词是一个长度为N的稀疏向量,而输出也是长度为N的概率向量,N对应词汇库的长度,是个很大的数,权重矩阵尺寸也就很大,资源严重浪费;
- 同时该方法也没有考虑到上下文词与该位置词的距离/位置关系。
2.2. 解决方案
- 为了解决独热编码的稀疏性,可以进一步将其embedding为稠密向量,因此可以将每个词的独热码输入神经网络,训练出的词向量,这个过程叫Word2Vec;
- 为了解决输出向量太长的问题,可以将输出层改为霍夫曼树(Huffman Tree)判断结构,即先找到词汇表中词频最大的词A,第一个输出层先判断结果为A或非A,如果为非A则进入下一层,判断结果为词频次大的B或非B,若为非B则进入下一层,……,通过多次二分类简化了多分类的超大尺寸参数矩阵;
- 对于输出层的改进也有一种方法是负采样 Negative sampling (NS),是从词汇表中随机采样一些词(根据词频优先采样高的)作为负样本,网络仅输出正负样本的概率,并进行梯度计算和参数更新。
2.3. Word2Vec模型
- 连续词袋模型 continues bag of words (CBOW):
- 基于相邻的词更相似的假设而来。设滑窗的窗口为
 (例图中为2),词汇表总词数为
(例图中为2),词汇表总词数为 ,则在目标词前后各取个相邻的词;
,则在目标词前后各取个相邻的词; - 首先将这个
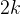 个词的独热向量分别输入神经网络,得到个
个词的独热向量分别输入神经网络,得到个 维稠密向量,这些就是个词现在的词向量,其中经过的网络参数矩阵为一个
维稠密向量,这些就是个词现在的词向量,其中经过的网络参数矩阵为一个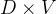 的投影矩阵,即为所有词embedding的词向量,其与每个词的独热编码相乘即可得到对应一列即为该词的词向量;
的投影矩阵,即为所有词embedding的词向量,其与每个词的独热编码相乘即可得到对应一列即为该词的词向量; - 第二步将个稠密向量相加后再输入一层神经网络,经过Softmax函数后输出一个维向量,其每个元素为词汇表对应位置词的概率,即利用上下文各个词的词向量预测中间词,与真实这个词的独热向量计算损失,让网络得到训练,最终训练得到的第一层投影矩阵便是所有词的词向量;
- 输出层可以通过Huffman Tree或NS方法改进。
- 基于相邻的词更相似的假设而来。设滑窗的窗口为
- Fasttext 模型:
- 与CBOW结构基本一致,但因其任务不是训练词向量,而是文本分类等下游任务,所以网络输出不是概率向量而是标签
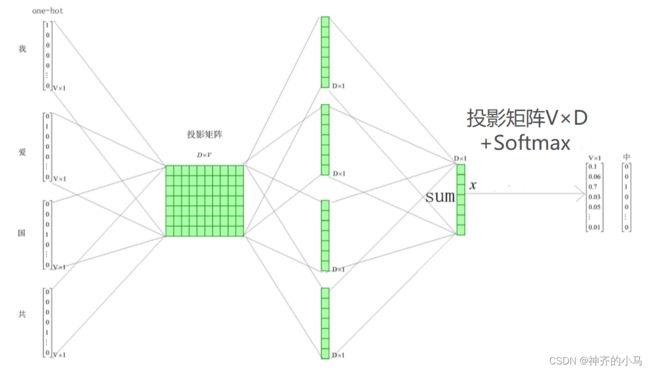
- Skip-gram 模型:
- 与CBOW类似,不过思路改为用一个中心词输入来预测周围个词的概率;
- 先将中心词的独热向量输入第一层网络,第一层网络权重矩阵同样是所有词的词向量,因此相乘得到中心词的词向量,再通过第二层网络得到概率向量,与真实的个词的独热向量计算损失,训练网络得到词向量。
- 与CBOW类似,不过思路改为用一个中心词输入来预测周围
- 两种模型比较,CBOW是利用一个词的损失同步更新个词,Skip-gram是利用个词的损失信息更新一个词,后者的学习更加有效;
- 词向量维度一般不用太高,常见128;
- 在Fasttext工具包做NLP任务时可以选择不同的词向量训练模型,实际工作中常用skip-gram + NS;
- 在部分NLP任务中会遇到一些新的词,不在最初构建的vocabulary中,称为OOV问题(Out of vocabulary),面对该问题,fasttext的处理方法是,将这个新词以长度n拆分成为若干子词,称为n-gram,例如“阿里巴巴” (2-gram)--> “阿里”、“里巴”、“巴巴”,如这些子词都不在vocabulary中,则将它们加入vocabulary训练词向量,否则如果子词在vocabulary中,例如“阿里公司” 可由 “阿里”和“公司”两个子词组成,且“阿里”和“公司”都在vocabulary中已有词向量,则“阿里公司”的词向量是由其两个子词的词向量相加直接得到;
- 当词汇数量太多,难以训练时,可以对其索引值进行桶归类,例如有500W个词,可以设置1W个桶,将每个词的索引对桶数1W求余得到桶索引,并放入对应桶内,对每个桶训练一个词向量,桶内词共享。这种方法牺牲了模型性能,换取资源上的优化,资源不足时可以采用。
3. 循环神经网络模型 (Recurrent Neural Network,RNN)
3.1. 循环神经网络的提出
- 传统机器学习模型的困境:
- 以文本分类任务为例,假设我们需要判断一个句子中所有词是否是一个地址,例如 “我” “住在” “土豆” “社区”,如果使用传统机器学习模型(逻辑回归、决策树、LSTM等),将大量词的向量输入模型进行训练,每个样本的输出计算是独立的,没有对上下文进行学习,则大概率会将 “土豆” 判定为非地址,然而为了方便后续任务,我们需要获得 “土豆社区” 这个完整地址名,因此需要对上下文样本进行联合学习;
- 传统词向量模型的困境:
- 词向量可以对语言进行表示学习,获得含有语义的稠密向量,但是对于一词多义现象,一个向量很难表达不同的意思,因此应该结合上下文信息来学习一个词更加可靠的语义信息;
- 解决方案:通过神经网络训练模型时,可以将上一个词的信息以某种映射传入下一个词的计算中,这样可以同时考虑这个词和上文的信息,便有了循环神经网络,网络中的每个词输入共享参数矩阵W、U、V,实现了时间上的参数共享(类似于CNN是空间上的参数共享);同时每个词接收了上文的语义后也会输出一个向量可以作为词向量和上文语义共同学习的特征。

- 缺陷:
- 由于每个词都需要上文的信息,所以必须等待前文计算结束才可以计算自己的输出,这样的串行计算使得模型无法并行训练,效率低下;
- 在反向传播计算梯度时,梯度需要从最后一个样本一路传播回第一个样本,深度非常高,加上参数共享造成了传播过程中会有相同参数反复运算,高次方的运算很容易带来严重的梯度爆炸或梯度消失问题。
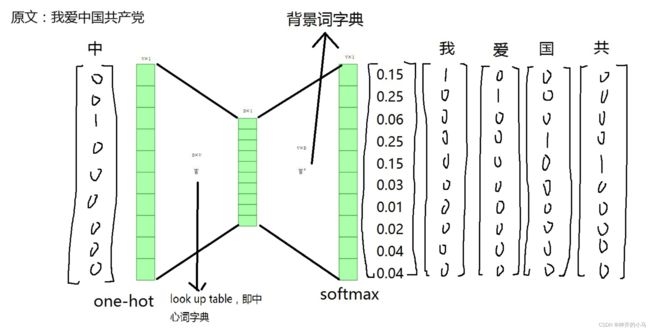
3.2. 长短时记忆网络 (Long Short-Term Memory,LSTM)
- 通过门来控制前文信息传递过程中长距离信息和短距离信息的利用程度,很大程度解决了梯度爆炸或梯度消失的问题
- 计算公式如下(用处不大了,有空看看就好):
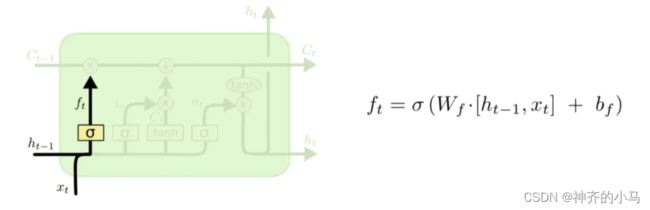
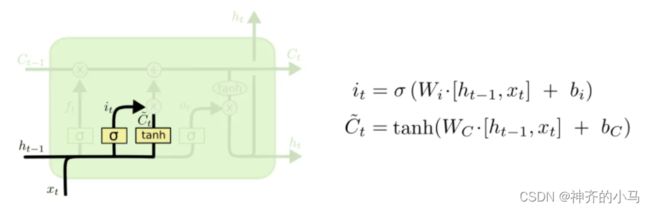
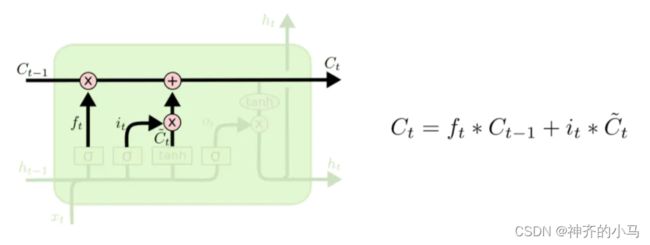
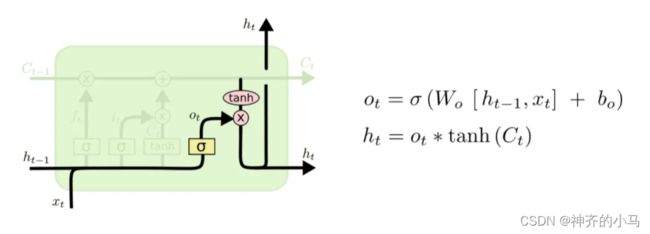
- LSTM变体:
- Bi-LSTM:同时进行从左到右和从右到左的信息传递,同时学习上下文信息;
3.3. TextCNN
- 使用卷积思想解决文本学习问题,卷积核尺寸通常为
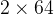 ,因其可以并行计算,计算和训练速度比RNN和LSTM快得多。
,因其可以并行计算,计算和训练速度比RNN和LSTM快得多。
4. 注意力机制 Attention
4.1. 为什么要考虑注意力
- 下图是一个经典的RNN应用于机器翻译的例子:
- 在这类seq2seq任务中,一个由RNN组成的Encoder将输入信息依次学习,传入同样由RNN组成的Decoder进行依次解码,每次也将上一步的输出加入考虑,该模型中的RNN单元也可以改进为LSTM单元;
- 然而这种模型一股脑学习了全部输入的信息,再传给Decoder进行输出时,对于输出的每一个词,所接收的输入词的信息是完全相同的,但实际任务中这样会造成输入输出之间的联系信息被丢失,例如 “我爱你” 翻译为 “I love you” ,“我” 和 “I” 之间有着直接联系,在输出 “I” 时理应更多考虑 “我” 这个词的信息,而上述模型无法做到这一点
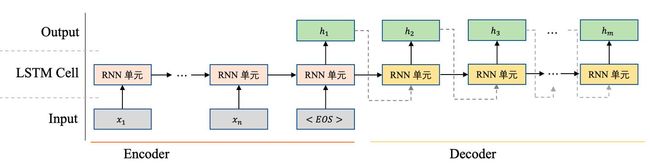
- 为了解决上述问题,可以引入一个权重,综合考虑所有学习到的信息并有所偏重地利用来计算输出,这个方法就是Attention,例如输出 “I” 时应当更多考虑 “我” 这个词,就给 “我” 这个词更大的权重,这个思路类似于人类在观察和思考时会更多注意一些有用信息,因此命名为注意力机制,Attention Mechanism。
4.2. 注意力机制的原理
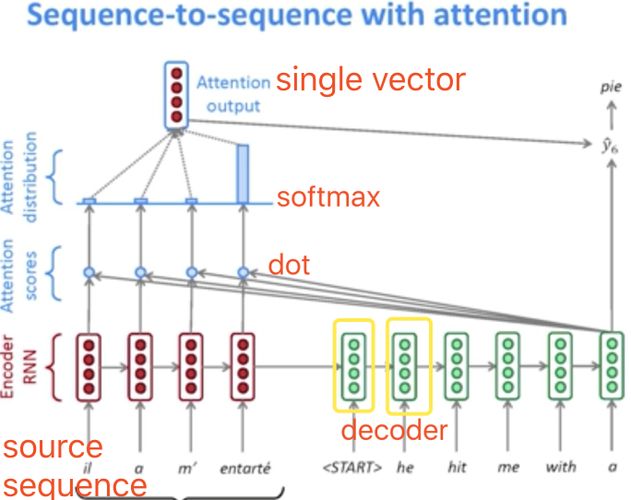
- 依然以机器翻译任务为例,之前提到的seq2seq模型会将Decoder输出的向量
 拿来计算最终结果,得到一个词,但此时可以不直接输出,而是将这个向量和Encoder中每个词的向量依次计算相似度,并得到一个相似度得分,这个相似度得分就是Attention的权重;
拿来计算最终结果,得到一个词,但此时可以不直接输出,而是将这个向量和Encoder中每个词的向量依次计算相似度,并得到一个相似度得分,这个相似度得分就是Attention的权重; - 也就是说原来的任务在输出 “I” 之前会和输入的 “我” “爱” “你” 依次比较相似度,发现与 “我” 这个词的相似度更高,就会得到更高的权重,经过Softmax归一化,再和每个词的信息加权累加,从而更多考虑 “我” 这个词的信息;
- 相似度计算函数有很多,最简单朴素的一种是求内积
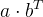 ;
;
4.3. Attention的标准化
- 对于句子中的任意一个词,有
 、、
、、 三个向量
三个向量
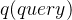 代表着这个词的需求信息,也就是它关注什么,每个位置的值越大代表越关注;
代表着这个词的需求信息,也就是它关注什么,每个位置的值越大代表越关注;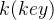 代表着这个词对应 的各项属性,每个位置的值越大代表越大程度满足 在这个位置的需求;
代表着这个词对应 的各项属性,每个位置的值越大代表越大程度满足 在这个位置的需求;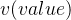 代表着这个词的特征,承载了这个词真正的信息。
代表着这个词的特征,承载了这个词真正的信息。
- 在Attention注意力机制中,每个词用其需求 去查询其余每个词的属性 ,得到每个词是否与其需求匹配,也就是求 和其余每个词 的相似度,算得与其余词的匹配得分,就是注意力得分,得分高的代表其匹配程度更高,在后续计算中有更高的权重;
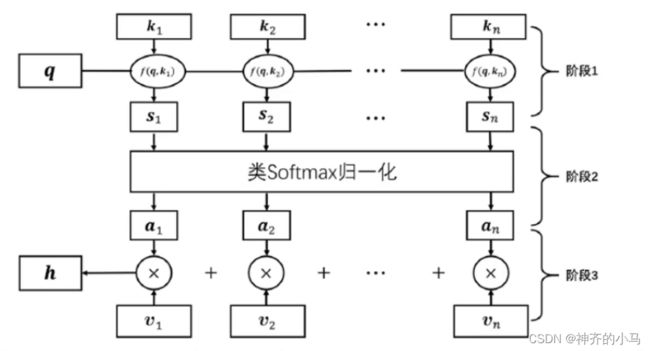
- 计算公式如下:

- 在4.2.中将 Decoder 中的输出作为Attention的 ,将 Encoder 中得到的每个词的信息同时作为 和 ; 。。。
- 在实际任务中, 和 不一定维度相同,当然维度不相同时其计算相似度的方法就不能用内积了,且输出的注意力得分向量需要与 同维;同一个词的 和 作为该词自身的属性和特征,是同维的且每个位置一一对应;
- 注意力机制的优势:
- 每个 独立计算其注意力机制的结果,这一特性使得Attention可以并行计算和训练;
- 每个 分别去查询其他词的 时,不受位置限制,因此可以自行学习长、短距离的上下文信息,极大地继承了LSTM的优点并基本上淘汰了以LSTM为代表的RNN类模型;
- 每个
- 注意力机制的缺点:
- 每个词都要和其他词进行计算,计算量大;
- 不受位置限制也会带来位置信息的丢失,可以在Attention输入中加入位置编码向量来解决这个问题。
4.4. 自注意力机制(Self-Attention)
- 注意力机制是一个很宽泛的概念,是一种思路,通过 、、 来寻找序列之间的联系信息,但从未规定 、、 怎么得来,以及相似度得分如何计算;
- 自注意力机制是一种特殊的注意力机制:
- 首先与其他注意力机制不同的是,其他注意力机制关注的可能是两个序列之间的注意力(例如前面提到的机器翻译,计算Encoder中每个输入的词与Decoder中每个输出的词的注意力),也可能是关注一个序列与其自身包含信息的注意力,而自注意力仅仅是后者,它关注一个序列(句子之类的)内部各个元素之间的联系,以更好地理解这个序列;
- 例如两个句子 “小明实在吃不下饭了因为他太饱了”,“小明实在吃不下饭了因为它太多了”,这两句的Ta指代不同的对象,因为出现在完全相同的位置,传统NLP模型很难学习到两个Ta的区别和信息,而自注意力机制可以计算两句中的Ta与其他部分的得分,得到 “他” 与 “小明” 更加相关,而 “它” 与 “饭” 更加相关;
- 注意力机制要求 和 是同源的(例如
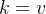 ,或 和 是从同一个输入得到的不同输出 ) ,而 没有要求,可以是一个数,一个向量或一个向量序列等等,针对特定任务进行定制;而自注意力机制对 做了要求,同一个词的 、、 需要都来源于这个词自身,是同源的(例如
,或 和 是从同一个输入得到的不同输出 ) ,而 没有要求,可以是一个数,一个向量或一个向量序列等等,针对特定任务进行定制;而自注意力机制对 做了要求,同一个词的 、、 需要都来源于这个词自身,是同源的(例如 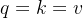 ,或 、 和 都是从同一个输入得到的不同输出 );
,或 、 和 都是从同一个输入得到的不同输出 ); 
- 自注意力机制为多种查询并行提供了便利,在一些任务中,每个词一个向量 是不够的,有时一个 和一个 也是不够的,而如何设计有用的多个 、、 成为了一大难题;自注意力机制限制同一个词的 、、 同源,可以设计多个注意力头并行计算,每个注意力头有着独立的 、、,分别关注不同的信息,得到的结果再通过神经网络汇总得到最终输出,这种机制称为多头自注意力机制。
4.5. 相似度计算方法

4.6. Transformer模型
- Transformer:由多层多头自注意力机制组成的模型,分为 Encoder 和 Decoder 部分,最初用于解决seq2seq问题,其中 Encoder 和 Decoder都是由多头自注意力机制组成,并使用了残差连接和层归一化的方法;
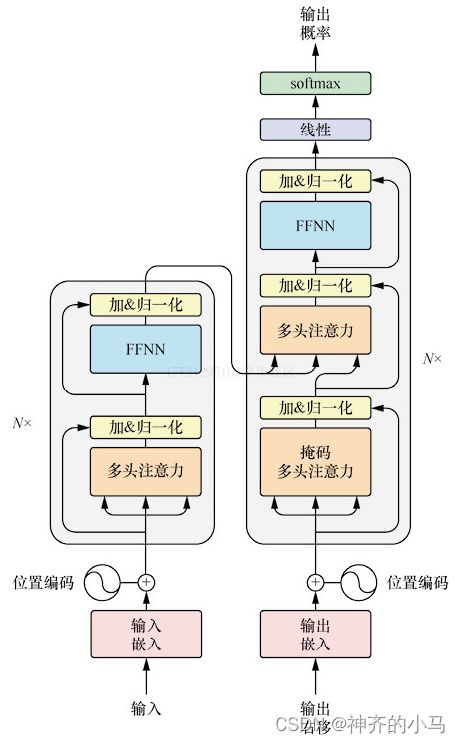
- 其中编码器由若干个编码块组成,每个编码块由多头自注意力机制+前馈神经网络,经由层归一化和残差连接组成,前馈神经网络是两层神经网络结构,激活函数为ReLU;
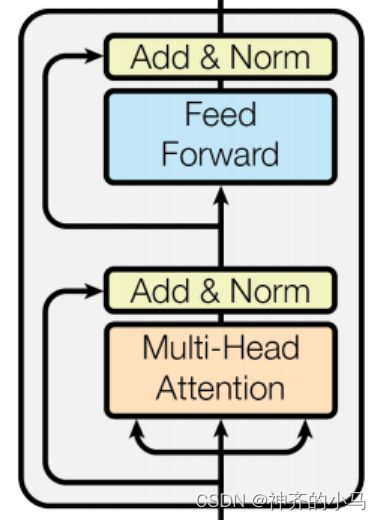
- 解码器由若干个解码块组成,与编码块不同的是,①解码块多了一层编码-解码交叉注意力层,该层的Q来自上一层解码器,而K和V来自最后一层编码器;②第一层注意力机制为掩码注意力,由于机器翻译任务输出的顺序性,每个位置的解码应当由之前的词影响,因此将之后的词掩码;

- 位置编码更好地将文本词汇的位置信息嵌入词向量,位置编码的计算方法如下,每个词会计算得到一个长度为
 的向量,
的向量,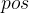 是这个单词在句子中的位置,
是这个单词在句子中的位置, 是位置向量的元素索引,因为
是位置向量的元素索引,因为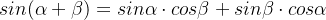 ,所以两个相距
,所以两个相距 的词可以相互线性表示,因此这里使用三角函数可以进一步引入句子词汇之间的相对位置;
的词可以相互线性表示,因此这里使用三角函数可以进一步引入句子词汇之间的相对位置; 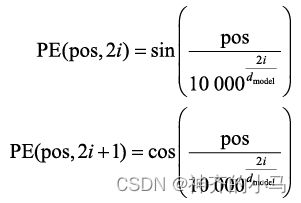
- Transformer的局限:
- Transformer虽然实现了更好的特征提取,避免长距离的信息遗忘,同时支持并行化计算,但完全抛弃传统CNN和RNN会导致局部特征重视不够,而且当距离长到一定程度,Transformer性能也会明显下降;
- 位置信息在NLP任务中非常重要,该模型位置信息的考虑还有待优化;
- 模型无法处理不定长输入,论文中采用的解决方法是将所有句子进行分段和末段补全,但每次输入一段会导致特征没有段与段的交流;
- 其中编码器由若干个编码块组成,每个编码块由多头自注意力机制+前馈神经网络,经由层归一化和残差连接组成,前馈神经网络是两层神经网络结构,激活函数为ReLU;
- Transformer-XL:针对Transformer的缺点进行了针对性改进;
- 绝对位置编码(Absolute Position Encoding,APE):Transformer中的分段处理让每个词的位置编码都是段内位置,例如一个句子被分为三段,每段的第一个词的位置编码向量都是一样的,而段与段也没有先后连接关系;
- 相对位置编码(Relative Position Encoding,RPE):完全抛弃绝对位置编码的思想,将位置信息全面用相对位置代替,例如 “I think I can run.” 中,第一个 “I” 相对第二个 “I” 的相对距离为下图的索引2,位置编码即为索引2对应的值,反过来第二个 “I” 相对第一个 “I” 的相对位置编码即为索引6对应的值,具体的值是一个所有句子共享的可学习参数,下图的值只是一个示例。这个编码值将训练两组,分别在计算
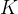 和时加入计算结果:
和时加入计算结果: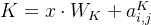 ,
,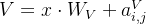 ;
; 
- 片段递归:Transformer-XL中,将该片段的特征和上一个片段的特征拼接在一起计算该片段的和(
 依然仅由本片段特征计算),并在解码器中以段为单位进行自回归输出(原始Transformer是以词为单位),通过这个方法将之前片段中的隐层特征进行递归,实现了段间信息交流以及提升了输出速率,缺点是需要大量显存来缓存前面片段的隐层特征;
依然仅由本片段特征计算),并在解码器中以段为单位进行自回归输出(原始Transformer是以词为单位),通过这个方法将之前片段中的隐层特征进行递归,实现了段间信息交流以及提升了输出速率,缺点是需要大量显存来缓存前面片段的隐层特征;
5. 大型预训练语言模型
5.1. 词向量的弊端
- 在Word2Vec模型中,无法考虑到上下文词的具体位置信息;
- 对于一词多义现象,以及语言中常见的比喻、反讽等使语义发生变化的场景,一个向量难以学习到准确且完整的信息。
5.2. 解决方案:预训练+微调的方法
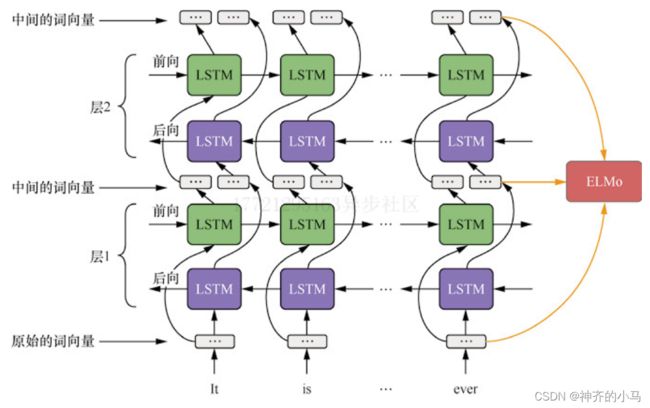
- 特征融合的预训练方法(Embedding from Language Model,ELMO):为了解决词向量的弊端,充分学习语义来满足下游任务,ELMO提出先用大量数据训练一种通用模型,为每个词学习到基本含义,再使用具体的下游任务的数据进行微调,让模型学习到更适合这个任务的信息,这种预训练+微调的方法得到广泛应用,此时的模型ELMO主要使用LSTM组成模型,为了解决一词多义问题(同一个词含义会根据上下文改变),ELMO将每一层LSTM提取出的词向量相加,来得到包含上下文信息的词向量;
- GPT系列:相比于ELMO,使用Transformer替代了LSTM,使模型拥有了更强的特征提取能力,但只使用了Transformer的Decoder部分,每次预测一个词时将后文Mask起来,根据上文单向学习到的信息进行预测,取得了非常好的效果,但模型参数量和数据量非常大;
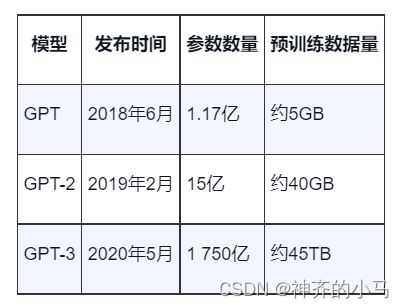
- 预训练的好处(相较于直接搞一个相同体量的大模型大数据,针对下游任务直接从0训练):
- 首先是模型收敛更快,LOSS比较好下降(因为预训练模型不用从头训练);
- 第二是模型性能相差不大的前提下,泛化能力更强
5.3. BERT模型——基于Transformer编码器的自编码预训练模型 (Bidirectional Encoder Representations from Transformers)
- BERT将多层Transformer组合起来成为一个参数量非常大的模型结构,通过(词向量+位置编码)=句向量的输入进行预训练,将训练数据进行随机Mask,掩盖掉一些词,将剩下的上下文输入模型来训练使其能正确输出预测空缺的词,即用完形填空的方法训练模型,相比于GPT的单向学习,BERT采用的是Transformer的Encoder部分进行双向学习,更好地可以学习到上下文的信息;
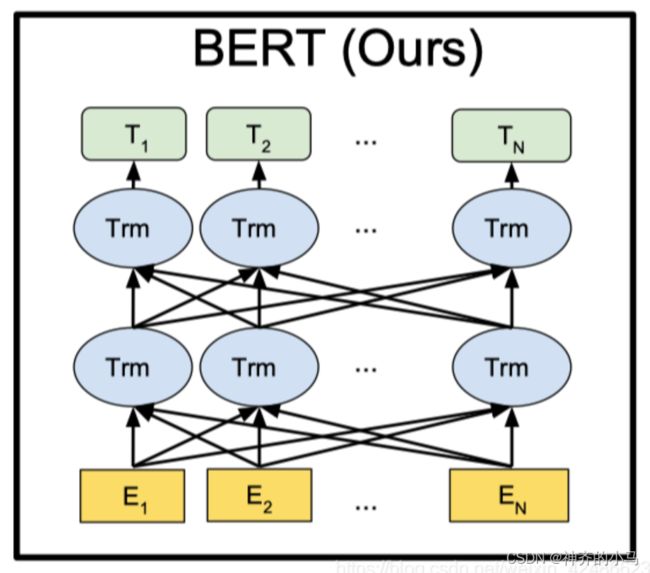
- BERT提供了两个版本的模型,基础版有12层Transformer块,多头自注意力头的个数为12个,隐层节点个数为768;复杂版有24层,16个头,1024个隐层节点;
- BERT的输入:

- 标志嵌入:首先将所有词拆分成公共子单元,例如 “playing” 会被拆分为 “play” 和 “# #ing” (中文则全部拆分为字即可),便于模型学习所有子单元的含义,再将每个子单元表示为向量(Word2Vec或独热编码);
- 分割嵌入:每个句子会有一个单独的分割嵌入向量,该向量隐含着句子与句子之间的联系,如一个句子是否是另一个句子的下文;
- 位置嵌入:每个词的位置信息;
- BERT训练:
- Masked LM:Bert模型会将训练数据中大约7%的字Mask,而在这些被Mask的字中有约80%数据是直接空缺,有约10%的数据会被随机修改为另一个字,要求模型进行修正,还有10%的字是保持完整输入数据;
- Masking的方法也有讲究,基于随机Masking的方法会存在一些问题,例如masking的是一个固有名词的一部分,如 [黑 * 江] ,那模型很容易猜到中间的字是 [龙] ,这样模型学不到东西,因此首先提出的改进方法是WWM(Whole word masking),字面意思就是一次masking一整个词;
- Phrase-Level&Entity-Level Masking:Phrase指连续的几个词,Phrase-Level Masking指一次masking连续的几个词;Entity指我们所关心的一些词,例如固有名词,将这些masking就是Entity-Level masking;
- SpanBert:一次masking一长段,长度随机选取,且长度与被选取的概率负相关;同时SpanBert的研究中还提出了一种新的训练方法SBO(Span Boundary Objective),将一段masking后不是做完形填空,而是只用空缺部分的左右各一个词来预测中间特定位置的一个词;
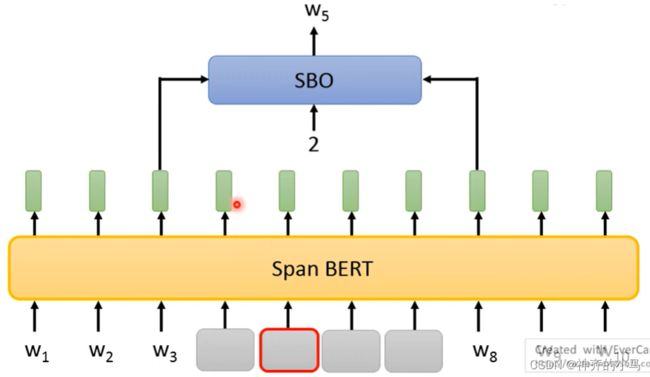
- Next Sentence Prediction(NSP):将两个句子输入BERT,判断是否是相连的两个句子(二分类);
- Masked LM:Bert模型会将训练数据中大约7%的字Mask,而在这些被Mask的字中有约80%数据是直接空缺,有约10%的数据会被随机修改为另一个字,要求模型进行修正,还有10%的字是保持完整输入数据;
- BERT验证:
- GLUE(General Language Understanding Evaluation):针对预训练模型的规范任务集,集合了自然语言处理中典型的九个下游任务,可以对一个预训练模型的通用性能进行测试和验证,该任务集也有中文版本;
- BERT微调(fine-tune):
- 一种是固定预训练模型,仅调整下游模型;
- 一种是一起调整(往往效果更好),但这样预训练似乎就意义不大了,因此可以在预训练时,设置一层为Adapter层,当预训练时不会对Adapter层进行训练,在微调阶段才会调整该层,针对下游任务调整该Adapter层可以替代对预训练模型整体的微调;
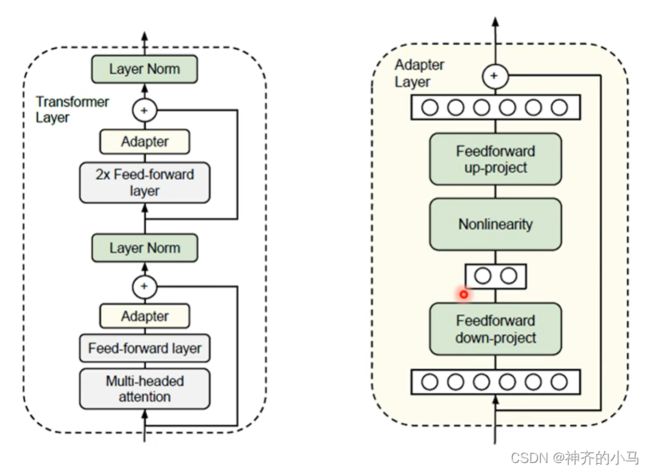
- 还有一种是不带Adapter层,但是可以将预训练模型的每一层隐向量拿出来,经过一层权重后相加,在下游任务中将这个权重与下游模型一起训练,也可以达到Adapter的效果;
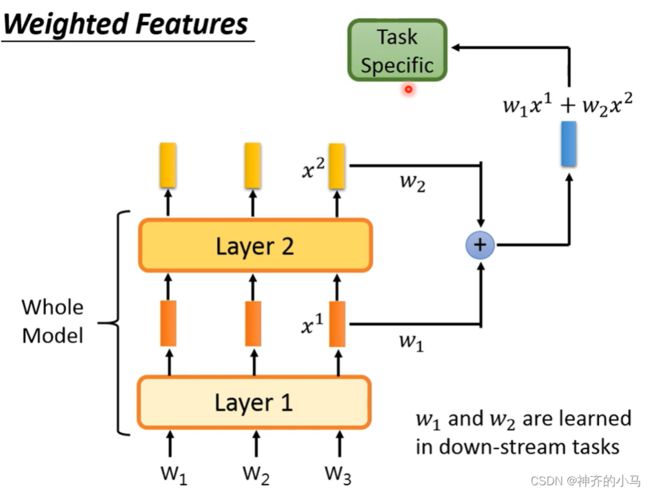
- 句子分类任务:用预训练模型Bert + 随机初始化的线性层,针对下游的句子分类任务微调线性层完成分类;

- 与输入同尺度输出的任务:例如位置标记等;
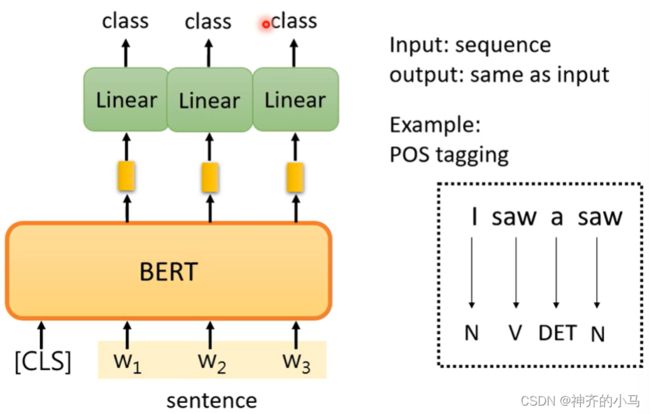
- NLI(Natural Language Inferencee):为模型输入一个前提和一个假设,模型来推断这个前提和假设是否冲突;
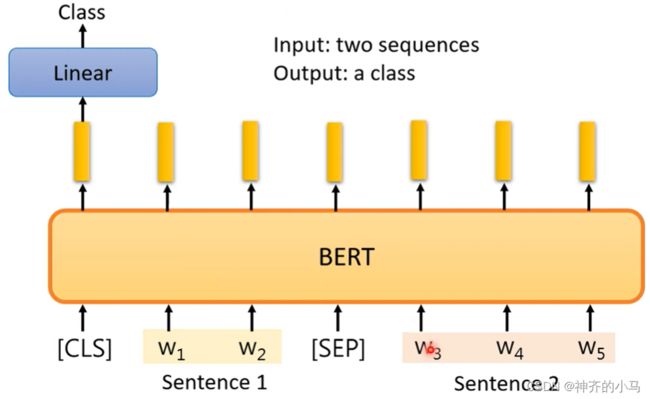
- 抽取问答系统(Extraction-based Question Answering):输入一篇文章和一个问题,需要模型做出回答,这个回答必须是文章中的原话,模型只需给出回答句在文章中的开始索引和结束索引(两个整数一小一大);在这个任务中,模型需要训练的是两个向量,分别代表着开始和结束的词向量,前向传播时需要将这两个向量和模型的输出逐个计算相似度,输出相似度最高的位置索引;
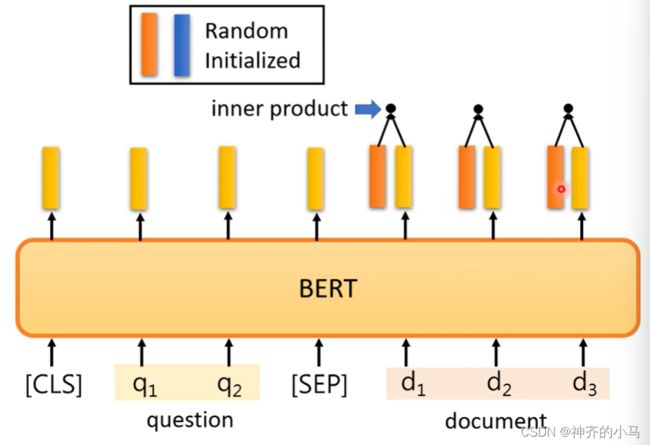
- Seq2seq任务:输入一个句子,输出另一个句子(或序列),例如翻译,可以先输入一个词语,输出这个词的翻译结果,再将第一个词的输出嵌入向量再拿过来输入模型,输出向量再得到第二个词的翻译结果,依次进行。
- 句子分类任务:用预训练模型Bert + 随机初始化的线性层,针对下游的句子分类任务微调线性层完成分类;
- BERT的变体:
- RoBERTa(A Robustly Optimized BERT Pretraining Approach):旨在充分发挥BERT模型的性能,是成熟版的BERT;
- 使用了动态masking;
- 训练过程中移除NSP任务;
- 使用更大的batch,更长的epoch,更多的数据;
- ALBERT(A Lite BERT):针对模型超大参数进行了改进,是更快的BERT;
- BERT输入词汇独热编码输出嵌入向量,这个转换矩阵参数量非常大(
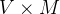 ,是词表长度,非常大),将其拆分为两个矩阵相乘(
,是词表长度,非常大),将其拆分为两个矩阵相乘(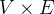 和
和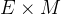 ,
, 小于
小于 );
); - 对大量堆叠的Transformer层,可以共享一部分参数;
- 提出使用句子顺序预测(Sentence Order Prediction,SOP)的方法代替模型训练中的NSP;
- BERT输入词汇独热编码输出嵌入向量,这个转换矩阵参数量非常大(
- MT-DNN:一个采用了BERT架构,并在不同的下游任务中使用多任务学习机制的模型(锁定预训练的特征提取层,独立训练若干个下游任务的模型);
- Multi-BERT 和 XLM:多种语言共同训练的BERT;
- RoBERTa(A Robustly Optimized BERT Pretraining Approach):旨在充分发挥BERT模型的性能,是成熟版的BERT;
5.4. GPT模型——基于Transformer解码器的自回归预训练模型
- 如果说BERT是完形填空,则GPT是用上文学习到的全部信息预测下一个词,是基于Transformer的解码器的单向学习模型,但这种单向预测的训练方法让GPT拥有了自回归式生成文本的能力。
- GPT的模型参数量更胜于Bert,导致即使是 pretrain + fine-tuning 的方法也非常困难,但GPT拥有更加接近人类的学习方式,类似于考试中特殊题型,题目会给出题目介绍,答题格式,以及范例,我们就可以根据这些信息迅速掌握一种没见过的题型的答题规范,GPT也可以通过一些提示和范例学习到下游任务(本质上还是生成式文本任务,根据上文补全下文),这种方式称为 Few-shot Learning ,这个方法没有梯度下降更新参数,这一类方法称为 “In-context” Learning ,其中包括 Few-shot Learning 、One-shot Learning 、Zero-shot Learning 等。


-
GPT家族
- GPT-1(2018):
- 奠定了预训练+微调的范式;
- 奠定了GPT系列模型的基座(transformer deocoder + 自回归);
- GPT-2(2019):
- 模型扩大到10亿,预训练数据也很多;
- 不微调就可以运行各种nlp任务;
- 将所有NLP任务统一为单词预测(文本生成)问题;
- 但是效果一般;
- GPT-3(2020):
- 模型扩大到千亿;
- 涌现出In-context learning能力、指令遵循能力、简单推理的能力;
- 被认为是范式从PLM到LLM迁移的革命;
- GPT-3.5(2021):
- 通过增加github代码数据,提升了复杂推理、链式思考能力;
- 使用基于人类反馈的强化学习算法(RLHF)对齐人类偏好;
- 指令微调,大大提高LLM遵循指令的能力;
- ChatGPT(2022)
- 以对话形式训练GPT-3.5,以chatbot形式出现;
- 几乎无所不能(海量知识储备、数学推理、精准多轮对话、和人类价值观对齐);
- 几个月火遍全世界,改写了AI历史;
- GPT-4(2023)
- 多模态输入(文本、图片同时输入);
- 比ChatGPT的涌现能力更强;
- 花了6个月进行对齐微调;
- GPT-1(2018):
-
GPT-3.5微调
- 微调分类:
- Instruction Tuning(指令微调):提升模型遵循人类指令执行任务的能力
- Alignment Tuning(对齐微调): 保持模型和人类的价值观或偏好对齐
- Efficient Tuning(效率微调):只更新部分参数,减小完整微调的成本
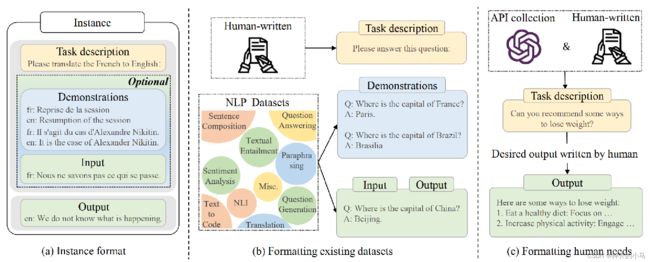
- 指令微调(样本格式:表示已有数据,人工手写的数据):
- 指令微调对解锁LLM的能力至关重要;
- 使用了指令微调的小模型的效果有可能会超过未微调的大模型;(关于GPT4大小的猜测?)
- 指令微调使LLM可以处理未见过的任务(训练集里面未出现此任务的指令及问答对儿);
- 指令微调使LLM可以克服以下弱点:
- 重复生成或者重复问题;
- 补全问题,而不是回答问题;
- 指令微调可以泛化到跨语言任务上;(问题用中文、答案回英文)
-
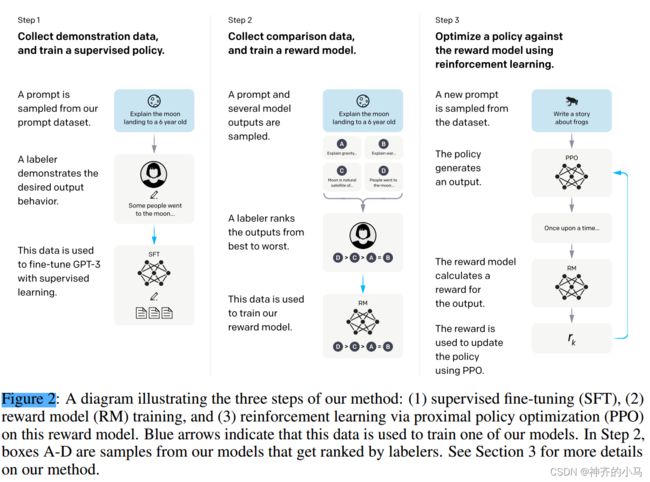
对齐微调——RLHF算法:
-
标准:有用性,一定是在帮用户解决问题;诚实性,知道自己的能力边界、不撒谎;无害性,不应该攻击或歧视、应该拒绝违法或犯罪请求;
-
三要素:
-
需要对齐的预训练模型;
-
基于人类反馈学习的奖励模型;
-
模型输出一个反应人类偏好的数值;
-
奖励模型一般是LM的较小版本,如6B的GPT3;
-
-
一个强化学习算法;(PPO)
-
-
- 效率微调:
- LoRA被广泛应用到开源LLM(如LLaMA、BLOOM)上
- Low-Rank Adaption(LoRA) 在每个linear层,对训练参数施加低秩约束。
- 一般的参数更新为:W = W + ∆W,LoRA:
- 首先冻结原始矩阵W(大模型的W维数很高);
- 然后用两个分解后的矩阵A、B去近似∆W,
- 其中: A∈R^m∗k B∈R^n∗k ∆W=A∙B^T k≪min(m,n)
- GPT-3.5相较于GPT-3进行的微调:首次提出RLHF算法(基于人类反馈的强化学习)来微调LLM(GPT3),作为ChatGPT的前身,在指令微调、对齐微调(生成安全性)方面表现出色,证明了较小规模的模型在经过微调后在特定任务上性能可能优于较大规模模型。
- 微调分类: