部署k8s集群及报错完美解决方案
目录
- 部署环境
- 一、master操作
- 二、node01操作
- 三、Kubernetes部署容器化应用
- 四、其他报错解决
部署环境
| Linux版本 | CPU | MEM |
|---|---|---|
| CentOS7 | 双核 | 4G/node |
| master | node01 |
|---|---|
| 172.16.0.168 | 172.16.0.169 |
| 服务 | 版本 |
|---|---|
| Docker | 19.03.10 |
| k8s | 1.18.0 |
1、更改主机名
hostnamectl set-hostname master
hostnamectl set-hostname node01
2、添加对应域名解析
cat >> /etc/hosts << EOF
172.16.0.168 master
172.16.0.169 node01
EOF
3、防火墙,SElinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i ‘s/SELINUX=enforcing/SELINUX=disabled/’ /etc/selinux/config
4、 时间同步
timedatectl set-timezone Asia/Shanghai;timedatectl set-local-rtc 0
5、禁用swap
swapoff -a && sed -i ‘/swap/s/^/#/’ /etc/fstab
free -h 查看禁用效果
6、配置集群无密登录 master到node01,node02无密码
ssh-keygen -t rsa
ssh-copy-id root@node01
7、优化内核参数
[root@master ~]# modprobe br_netfilter
创建配置文件
cat > /etc/sysctl.d/kubernetes.conf << EOF
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
net.ipv4.tcp_tw_recycle = 0
vm.swappiness = 0
vm.overcommit_memory = 1
vm.panic_on_oom = 0
fs.inotify.max_user_instances = 8192
fs.inotify.max_user_watches = 1048576
fs.file-max = 52706963
fs.nr_open = 52706963
net.ipv6.conf.all.disable_ipv6 = 1
net.netfilter.nf_conntrack_max = 2310720
EOF
加载配置
sysctl -p /etc/sysctl.d/kubernetes.conf
注意:可能报错

解决:可能是 conntrack没有加载,lsmod |grep conntrack,查看不到信息,果然是
执行下面命令 重新加载
modprobe ip_conntrack即可
拷贝配置文件到节点
[root@master ~]# scp /etc/sysctl.d/kubernetes.conf node01:/etc/sysctl.d/
节点也要加载内核:
[root@node01 ~]# sysctl -p /etc/sysctl.d/kubernetes.conf
注意:docker、k8s的版本必须一样,master、node都要安装,否则,方法也需要调整。
提示:以下是本篇文章正文内容,下面案例可供参考
一、master操作
1、需要在各节点上准备kubernetes的yum源,这里推荐使用阿里云的yum源先来master节点上操作
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
2、配置docker加速器及更改docker默认Cgroup驱动(只在master操作)
提示:如果没做过镜像加速,需先创建/etc/docker目录
vim /etc/docker/daemon.json
{
“registry-mirrors”: [“https://1dmptu91.mirror.aliyuncs.com”],
“exec-opts”: [“native.cgroupdriver=systemd”]
}
重新加载内核以及重启docker
systemctl daemon-reload
systemctl restart docker
3、部署k8s组件
注意:master节点部署了kubectl、kubelet、kuberadm三个组件,当然在部署前要指定和k8s版本一致的组件版本。node节点只需部署kubelet-1.18.0 kubeadm-1.18.0即可
yum install kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
无论是master还是node节点必须开机自启kubelet
systemctl enable kubelet
4、kubeadm初始化
由于国内网络环境限制,我们不能直接从谷歌的镜像站下载镜像,有两种方法可以解决,第一种:需要我们手动从docker镜像站下载镜像,然后重新命名,也可以用脚本来实现。这里我们采用第二种:在初始化k8s的时候,指定镜像源为阿里云。
上传到服务器 k8s安装镜像包v1.18.0组件
进入解压目录,执行本地yum安装命令
cd /root/k8s-rpm && yum -y localinstall *
方法一:初始化时指定镜像仓库为阿里云
kubeadm init --kubernetes-version=v1.18.0 --image-repository registry.aliyuncs.com/google_containers --apiserver-advertise-address 172.16.0.168 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
方法二:将k8s集群状态配置问一个yaml文件,然后从yaml文件初始化
1)kubeadm config print init-defaults > kubeadm-config.yaml
vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 172.16.0.168 //改成masterIP
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.18.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
2)初始化集群
kubeadm init --config=kubeadm-config.yaml
报错:提示kubadm配置镜像下载,即便您手动导入下载好的也不认!(有时不用下面操作)
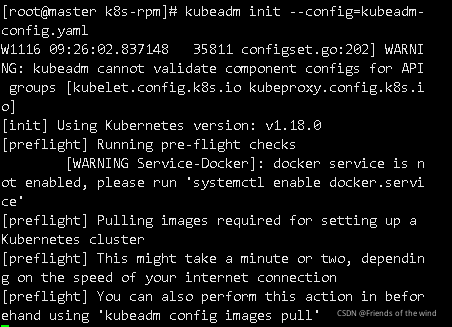
解决:
分析原因,部分主机命令只识别最新的镜像,导入的不是k8s官方的标签,不认,因此我们不仅导入,还要更改标签,重载内核,重启docker。
1)更改标签,以阿里云下载的为例
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.18.0 k8s.gcr.io/kube-apiserver:v1.18.20
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.18.0 k8s.gcr.io/kube-controller-manager:v1.18.20
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.18.0 k8s.gcr.io/kube-scheduler:v1.18.20
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.18.0 k8s.gcr.io/kube-proxy:v1.18.20
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2 k8s.gcr.io/pause:3.2
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.3-0 k8s.gcr.io/etcd:3.4.3-0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.7 k8s.gcr.io/coredns:1.6.7
2)删除原有镜像
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.18.0
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.18.0
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.18.0
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.18.0
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.7
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.3-0
3)重载内核,重启docker
5、成功入下图提示:红色标线,提示您下一步需要这些操作,以及下面有节点加入集群的命令

按照箭头提示做
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
6、添加网络组件(flannel),组件flannel可以通过https://github.com/coreos/flannel中获取
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
查看集群节点状态,未就绪状态

解决:
可能有多种原因
第一:缺少附件flannel,没有网络各Pod是无法通信的(节点和master都要安装)
执行kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
或者,quay-flannel.tar镜像包在每个节点及master都要导入
第二:节点未启动kubelet.service
查看服务状态,最好将其设置为开机自启

无法启动的原因有多种,遇到过docker没有启动,进而导致kubelet.service无法启动
第三:排除其他可能错误后,k8s部署复杂,可能需要稍等,重载内核,重启docker
我们能看到从notready到ready的变化

重要提示:
token 的过期时间是24小时
certificate-key 过期时间是2小时
加入node若是token过期,使用命令生成
kubeadm token create --print-join-command

二、node01操作
主节点的安装部署,然后个node节点的安装,和加入集群,这里注意,验证,node节点已经准备好了相关的镜像。
1、node节点仅需要两个镜像,可以手动先下载一下,或者从master节点同步
导出镜像:
docker save > pause.tar k8s.gcr.io/pause:3.2
docker save > kube-proxy.tar k8s.gcr.io/kube-proxy:v1.18.20
quay-flannel.tar
节点加入集群执行粘贴的命令:
![]()
提示如下:

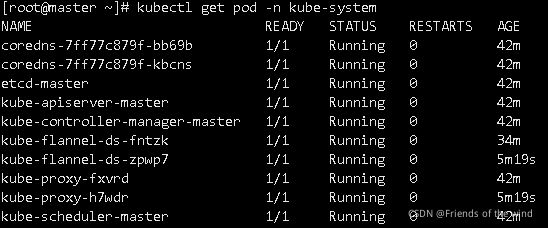
2、登录master执行命令查看:也是需要一点时间

查看组件完整且是running状态
三、Kubernetes部署容器化应用
部署一个Nginx
提示:在master提前导入或下载Nginx镜像
1)创建一个deployment资源对象,Pod控制器。
kubectl create deployment nginx --image=nginx
2)
kubectl expose deployment nginx --port=80 --type=NodePort
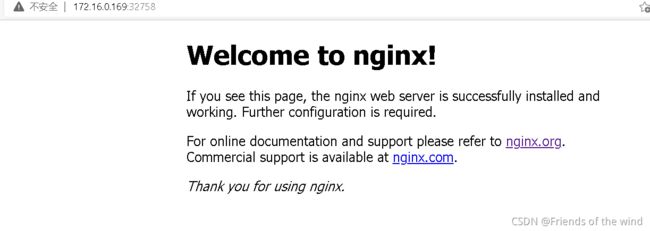
查看验证:
kubectl get pod,svc

访问地址:http://NodeIP:Port
注意:需要多等会,端口号是映射的容器内端口号

部署一个Tomcat
1)查看导入镜像名,注意:镜像名要复制完全,否则会,自动下载另一个版本
![]()
2)创建一个deployment资源对象,Pod控制器。
kubectl create deployment tomcat1 --image=hub.c.163.com/library/tomcat
3)Scheduler执行调度任务,将Pod分发到node上
kubectl expose deployment tomcat1 --port=8080 --type=NodePort
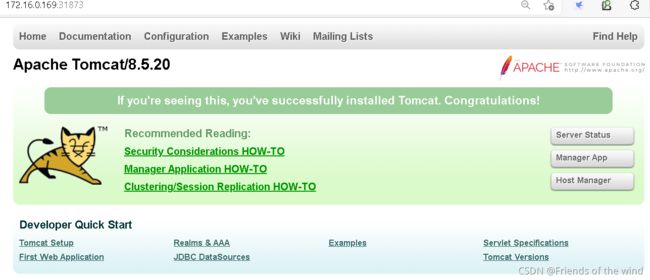
4)查看验证:
kubectl get pod,svc或下面命令

5)浏览器访问:http://NodeIP:Port
四、其他报错解决
到服务器172.16.0.168:6443的连接被拒绝-您指定了正确的主机或端口吗?

分析:master的IP与端口问题,可能是配置了错误的参数,检查6443端口是否开启,是否禁用swap?
命令:netstat -pnlt | grep 6443,没有返回值,证明端口没有开启。
什么原因造成端口无法开启?是否禁用swap

定位故障原因,虚拟内存未禁用,必须做,否则,无法开启服务,禁用swap,开启服务,解决
