git的基本使用及原理
git的基本使用及原理
- 一、前言
- 二、git开发步骤
-
-
- 一般场景流程
- 命令行实现
-
-
- 1. 检出代码
- 2. 开发新功能
- 3. 添加进index
- 4. 暂存工作进度
- 5. 切换到其他分支
- 6. 回来继续开发
- 7. 提交代码
- 8. 推送远程分支
- 9. 测试并修改bug
- 10. 把代码合并到master
-
- idea操作
-
-
- 1. 检出代码
- 2. 创建分支
- 3. 修改代码后,在左边commit栏自动会出现你修改的文件
- 4. 暂存
- 5. 切换到其他紧急处理分支
- 6. 切换回来,恢复工作进度
- 7. 提交代码
- 8. 推送远程分支
- 9. 之后就重复上面的操作直到完成自己的开发任务
- 10. 合并到master
-
-
- 三、git原理
-
- git的存储结构
-
-
- 思路一:提交一次就存储一套代码
- 思路二:记录每个文件的增量提交记录
- 其实git选择了更加聪明的存储方式
-
- git核心概念原理
- git存储的三种数据类型
-
-
- 1. commit
- 2. tree
- 3. blob
- 4. tag
-
- git安装目录说明
-
-
- 1. objects:文件实体库。
- 2. refs:引用文件
- 4. index:暂存区
-
- 四、附录
-
- 初学者可能会遇到的坑1
- 初学者可能会遇到的坑2
- 关于git可能的疑惑
- 关于版本管理工具的使用约定
- 其他命令
- 关于版本管理工具的选择
- 参考及系列教程链接
一、前言
分支管理——git给开发人员最大的礼物。
关于“分支”这个词,我们似乎并不陌生,就是一套包含历史变更记录的代码的。但在svn时代,它表现的形式是 一个分支=一个目录。尽管管理员可以人为的给这些目录赋予上下级关系并且注明版本名,但他们在我们心里就是”一个一个并列的目录“。结果就是我们的工作空间里分了好多目录,如果管理不当,就会出现东一个西一个。开发完这个任务,要开发下一个任务的bug时就要用IDE换一个工作空间。
当分支越来越多,简直是灾难,无论是服务器上还是本地都混乱不堪。多年之后,可能还会出现分支找不到的问题。
用了git,你将感受到工作空间前所未有的”清爽“,工作空间永远”只有一套代码“,开发完一个任务,简单的切换一下分支,就可以去开发另外一个分支的任务,轻松实现“原地变身”。
二、git开发步骤
一般场景流程
- 检出代码(类似svn的checkout)
- 1-1. 克隆某个分支b
- 1-2. 在分支b基础上创建新的分支b_new
- 在新分支b_new上开发功能
- 开发一点(还不是完整的一块功能),add进暂存区;再开发一点(还没完成),add进暂存区;。。。
- 功能还未完成,此时有其他紧急任务需要马上处理,保存一下暂存区的内容【注意git只会暂存add进暂存区index的内容,不在暂存区的不受git管理】
- 切换分支到马上处理的分支。。。
- 切换回b_new继续开发
- 一小块功能终于完成了(单元自测也完成了),提交版本库。
- 在此之前,远程共享仓库里还没有我们创建的分支b_new,现在把本地版本库里的b_new推送到远程版本库。
- 整个功能模块都已经完成并推送到远程。测试人员测试该分支,我们继续在该分支上修改bug
- 合并代码到master【这一步可能会由管理员操作】
命令行实现
找一个空目录作为自己的工作空间和本地版本库的位置,在该目录打开gitg命令行工具
1. 检出代码
1-1. git clone 远程版本库地址
1-2. git checkout -b b_new【等价于两个步骤:创建分支git branch b_new; 切换分支git chekcout b_new】
2. 开发新功能
3. 添加进index
git add 文件名 或者 git add .(把所有更改的文件添加进暂存区,但一般不建议这么做,因为并不是所有文件我们都希望提交)
4. 暂存工作进度
git stash save "暂存说明"
5. 切换到其他分支
git checkout other_branch
6. 回来继续开发
6-1. 切换回来 git checkout b_new
6-2. 查看一下暂存列表 git stash list
能看到 stash@{0}: On master: 2020.11.24 b_new进度保存
6-3. git stash pop stash@{0}【根据注释 对照列表找到自己想要还原的内容】
7. 提交代码
git commit -m "注释说明”【注意:commit这一步不像svn那样可以部分提交,而是把所有暂存区的内容整体提交,因为在添加暂存区的时候就已经让我们做出了选择】
8. 推送远程分支
git push origin b_new
9. 测试并修改bug
git add xxx;
git commit -m "xxx";
git push b_new;
10. 把代码合并到master
10-1. 切换到master:git checkout master
10-2. 合并代码: git merge b_new【如果有冲突,需要手动处理】
10-3. 把master推送到远程:git push origin master
idea操作
1. 检出代码
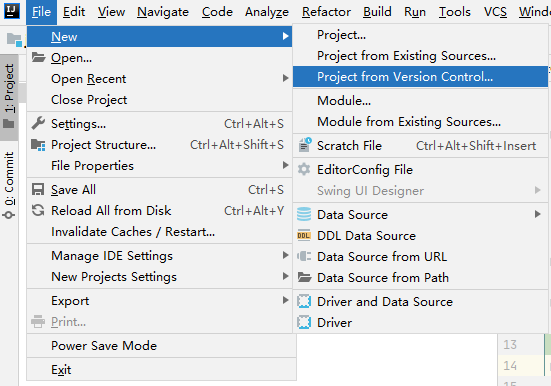
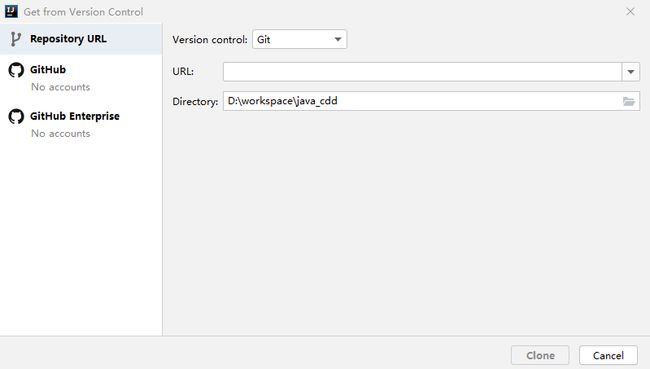
这一步我一般习惯使用命令去完成,然后在idea里导入代码,idea会自动识别并关联git。
2. 创建分支
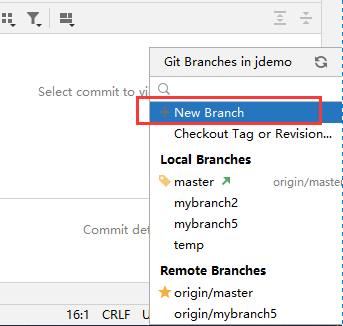

3. 修改代码后,在左边commit栏自动会出现你修改的文件
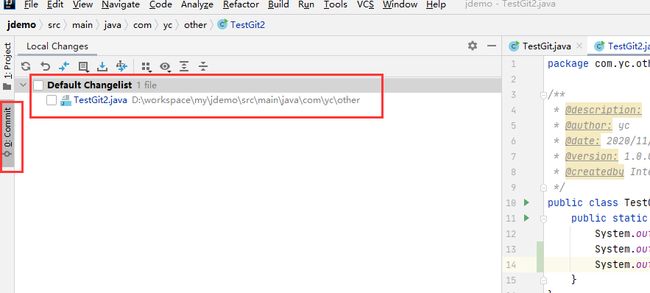
4. 暂存
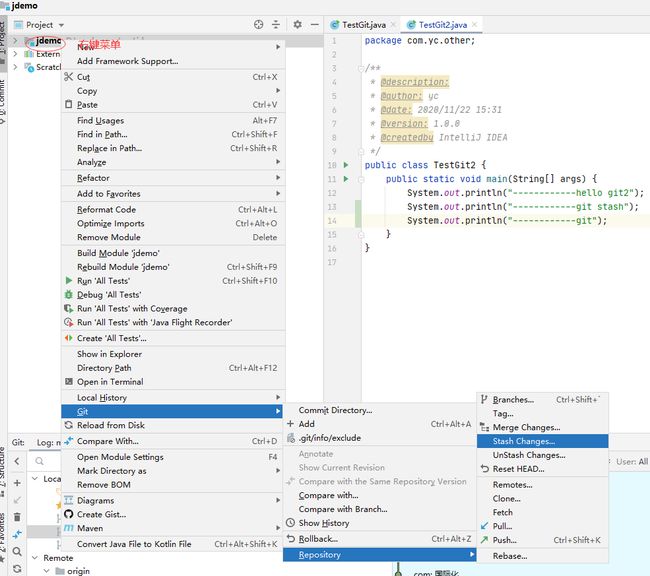
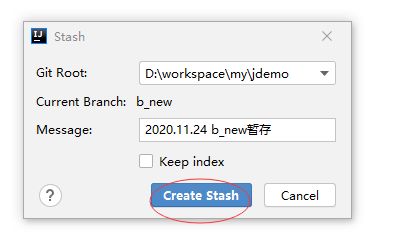
确保changeList已经空
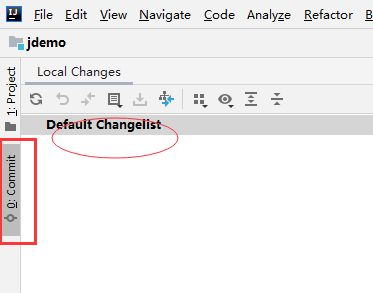
5. 切换到其他紧急处理分支
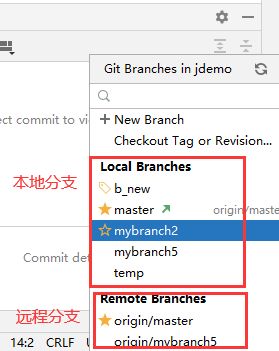
6. 切换回来,恢复工作进度
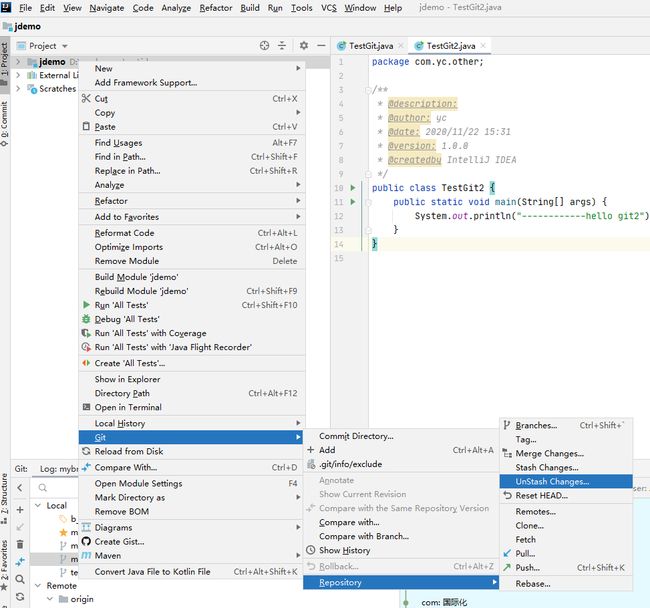
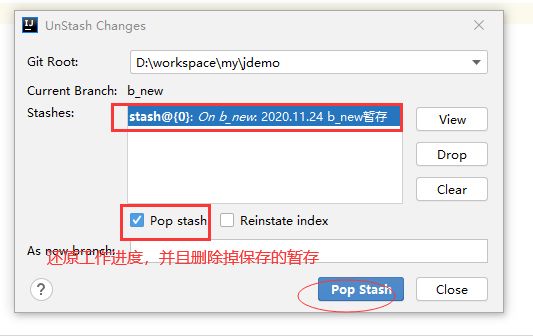
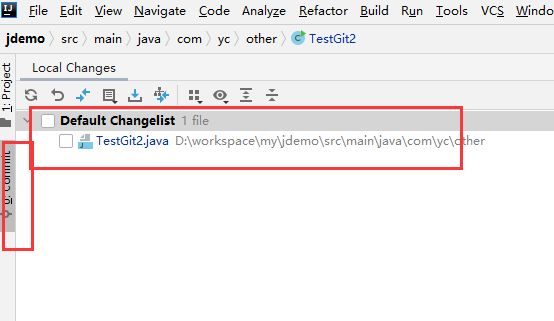
7. 提交代码
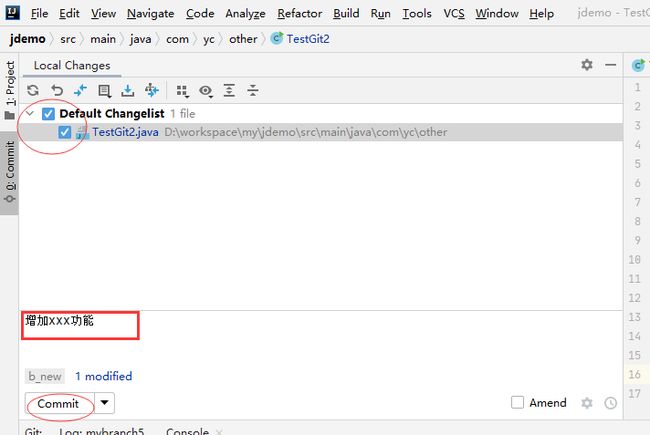

commit之后,暂存区里又一次恢复干净
8. 推送远程分支
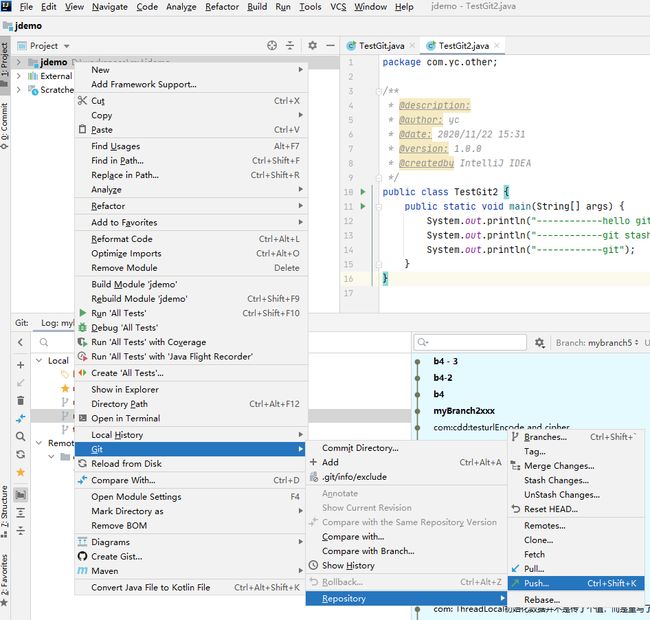
或
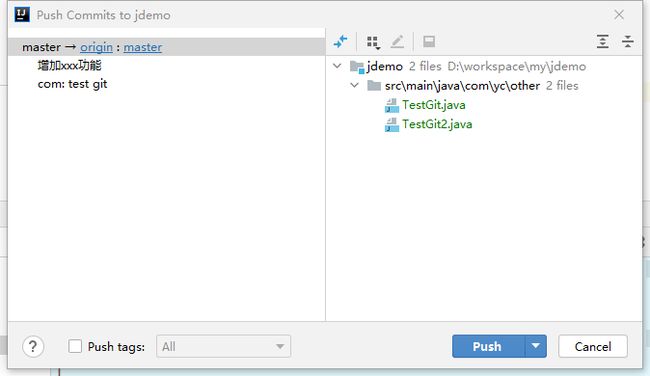
使用右上角的快捷按钮
弹出确认框,这里可以双击文件确认推送的内容

不过一般我们可能会习惯把commit和push“二合一”
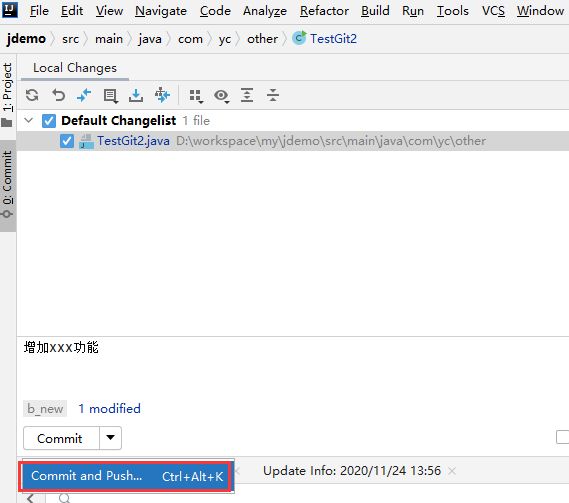
9. 之后就重复上面的操作直到完成自己的开发任务
–>-->–>-->–>-如果你是刚使用git的新手,至此,你的任务已经完成,后面的事情不需要你去做了。因为涉及到合并master,如果你不清楚明白的知道在做什么,最好由其他有经验的人去做–>-->–>-->–>-->–>--
10. 合并到master
切换到master
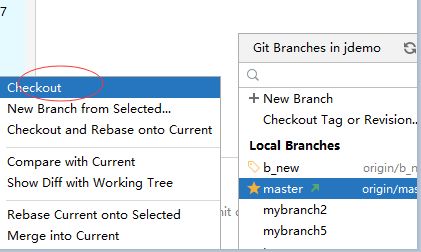
把b_new分支合并过来
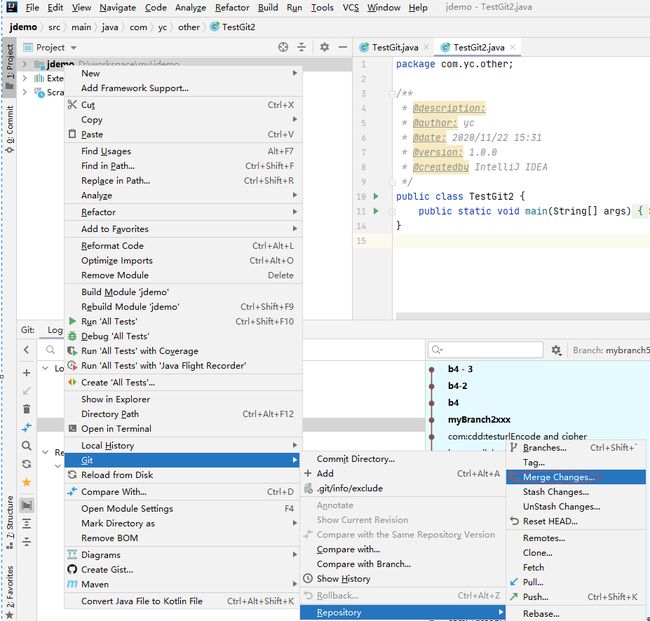
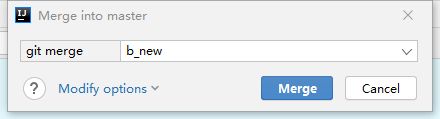
合并完成后,把master合并完的内容推送到远程。注意:这个合并是直接合到本地master版本库的,所以在ChangeList是没有东西的,下一步只剩下push
三、git原理
git的存储结构
git这么好的东西,底层是如何实现的呢?
思路一:提交一次就存储一套代码
这是最简单粗暴的想法,占空间是一定的,当然简单有简单的好处,算法结构简单也会让软件更不容易出问题。我们知道git号称每次提交都对整个项目树产生一个唯一的hash1编码,莫非git真的使用的这么简单粗暴的存储方式?
思路二:记录每个文件的增量提交记录
比如文件a,第一次是234,第二次提交的是增加了56 变成23456,那么就记录“+ 56",这样存储一定是最省空间的,但同时造成的软件复杂度,可能会让git变得不可用:比如我存储的是个图片,中间对该图片进行了美化(修改的是一些二进制数据)。
其实git选择了更加聪明的存储方式
兼具节省空间和"全量保存”:
git的存储内容分为两部分:实体文件库 + 索引树
实体文件库就是存真实的文件,比如 hello.java , cc.jpg。
索引树是一颗树形结构的数据结构,叶子节点上不是文件,而是文件的索引,该索引指的位置就是 实体问价库的位置。说到这里,你是否恍然大悟,下面简单示意一下大致原理:
- 一个项目叫demo,项目目录里只有一个文件README.txt,文件目录结构如下
demo- README.txt
实体文件库里就存了一个文件(1代表文件的索引)
| 索引 | 文件 |
|---|---|
| 1 | README.txt |
索引树的结构就是(tree1是索引树的版本号)
------tree1------
demo
- 1
- 第二次提交一个新文件hello.java, 项目结构变成
demo- README.txt
- hello.java
实体文件库就会增加一个文件
| 索引 | 文件 |
|---|---|
| 1 | README.txt |
| 2 | hello.java |
索引树的结构(注意tree1还在,现在是增加了一棵树tree2,这样我们才有回退版本的可能)
------tree1------
- demo
- 1
------tree2------
- demo
- 1
- 2
- 第三次提交是更新了hello.java这个文件,项目结构没变(只是hello.java这个文件内容变了)
- demo
- README.txt
- hello.java
此时实体文件库就会增加一个文件(实际上git在存储文件库的时候并不会使用文件原始名字存储,这里只是为了让读者能清晰的看到实际存储的文件)
| 索引 | 文件 |
|---|---|
| 1 | README.txt |
| 2 | hello.java |
| 3 | hello.java |
索引树的结构(注意tree1,tree2还在,现在是增加了一棵树tree3)
------tree1------
- demo
- 1
------tree2------
- demo
- 1
- 2
------tree3------
- demo
- 1
- 3
当然,实际的存储结构会做很多优化,从而比示意的要复杂的多,最终得以让git实现版本分支管理的前提下,达到占用空间最小,存取速度最快的效果。
git核心概念原理
有了上面的存储结构的铺垫,再去理解git核心概念原理就容易些,看下面这张常见的基本原理图。
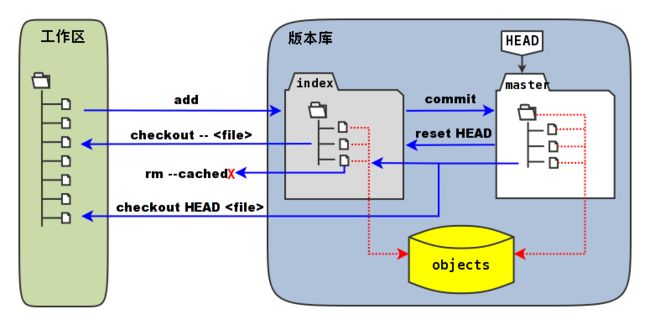
- 工作区:就是我们当前看到的代码
- 版本库:一般在项目代码根目录,有个.git的目录
- object: 就是上面我们说的实体文件库,放在.git/objects里
- master: 其中一个比较特殊的引用,就是某个commit ID,在.git/refs目录中
- HEAD: 一个指针,表示当前要操作的节点(如果此时commit,就是以该节点往下接节点,一般指向分支的头节点,这样分支的节点就一个一个往下接去了)
- 分支:这里没有表示出来的一个重要概念,就是一条“索引树链条”,和文件实体库放在一起都在.git/objects下
git存储的三种数据类型
Git存储使用的是一个内容寻址的文件系统,其核心部分是一个简单的键值对(key-value)数据库,当向数据库中插入任意类型的内容,它会返回一个40位十六进制的SHA-1哈希值用作索引。
在版本库中,Git维护的数据结构有:以下4种对象及索引,并通过保存commitID有向无环图的log日志来维护与管理项目的修订版本和历史信息。
下面是git的三种重要的数据类型的关系图
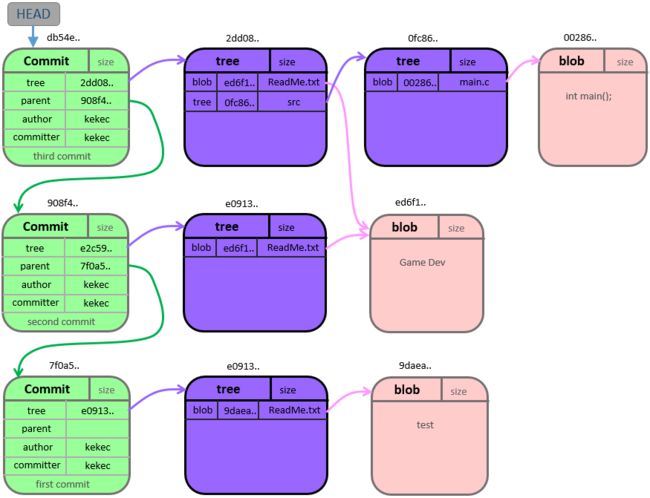
1. commit
每次提交,都会产生一个commit,commit中记录了上一个节点的commit ID,作者,指向一个版本的目录tree对象。
可以使用命令 git cat-file -p xxxx
2. tree
表示1个目录,记录着目录里所有文件blob哈希值、文件名子目录名及其他元数据。通过递归引用其他目录树,从而建立一个包含文件和子目录的完整层次结构。我们每次提交记录,就会产生一个新的版本,对应的关键信息就是这棵树,由于只是一颗tree信息,虽然看起来像是“复制”了整个项目,但占用空间并不大,通过这棵树,git得以给每个版本的整个项目生成一个唯一的hash值,从而保证历史不被篡改。
3. blob
保存某个文件的某个版本的数据。一个文件只要有改动,就会产生一个新的blob对象存储该文件。而不改动的文件,会一直被每个版本的tree引用,从而节省了大量存储文件的空间。注意:只要做了add操作,文件就会被存储进来,所以某些体积很大,但肯定不需要版本控制的(最典型的就是编译完的包),一定添加到.gitignore里,否则你一个不小心,git仓库就变大好多(当然,git有像java一样的gc操作,可以定期清理掉这种没有人引用的垃圾数据)
4. tag
分为轻量标签和附注标签。轻量标签实际上是一个特定提交的引用,附注标签是存储在git中的一个完整可被校验的对象(保存在.git/refs/tags中),还包含打标签者的名字、e-mail、日志、注释等信息
git安装目录说明
git是大名鼎鼎的Linux之父的又一杰作,Linux的一个特点就是“一切皆文件”,git当然也会延续Linux的特点,git给我们带来方便的同时必然也带来了很多新的概念,这些概念并不是空洞的的理论,而是能看得见摸得着的文件,下面我去对应一下加深一下理解
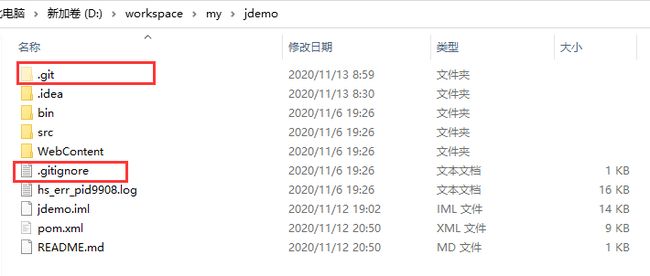
这是项目jdemo根目录下的文件目录,其中有两个是git添加的
.git : git本地库目录,是个隐藏目录,也是git的核心目录
.gitignore: 这个并不是必需的,是个隐藏文件,用于在提交时忽略一些文件,即使这些文件变更了,也会被忽略提交
下面主要看.git的内容
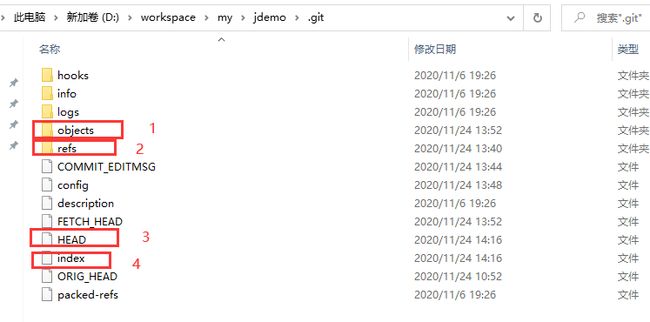
里面内容很多,先看圈中的几个涉及重要概念的文件及目录
1. objects:文件实体库。
但不要认为这里存的只有文件本身,实际上这里面包含了git的所有存储数据,包括索引树。就像数据库的数据库文件,里面包含数据库结构和一条条的数据记录。
如果你打开这个目录,会看到时这个样子

这是里面的文件
由于都是二进制文件,无法直接解读里面的内容,但可以使用工具命令
git cat-file -t xxxx来查看对象的数据类型(commit/tree/blob/tag)
git cat-file -p xxxx来查看对象的属性信息
git show xxxx来查看对象的内容
2. refs:引用文件
刚才看了git实际存储数据的文件,可以发现存储结构很复杂,而且文件名也不容易记,而我们在使用的过程中面对的分支名并没有这么复杂,一般都是 master、分支1,分支2,,,,什么的,那么这些名字和实际的数据是怎么对应的呢,就在refs目录,这个目录里的数据就很简单了,而且是明文字符串
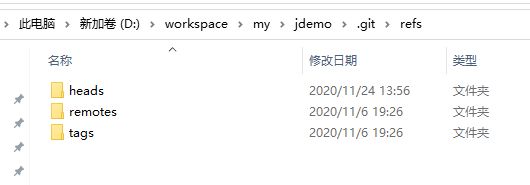
这三个目录分别对应我们本地的分支、远程分支、里程碑
。以本地分支为例
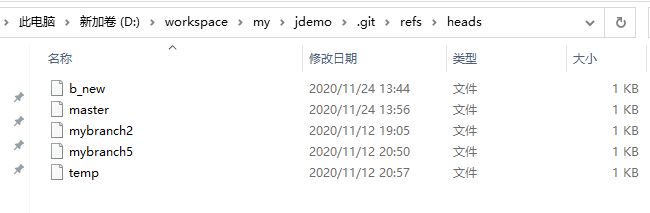
其中b_new就是我们创建的分支名字,文件里的内容就是该分支的“索引”
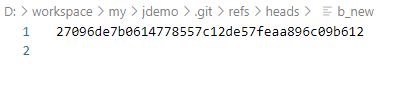
可以看到这是一串字符串,这个字符串就指向了某个提交节点。有个比较特殊的一个引用是HEAD,
就在.git根目录(.git\refs\remotes\origin里也有一个)
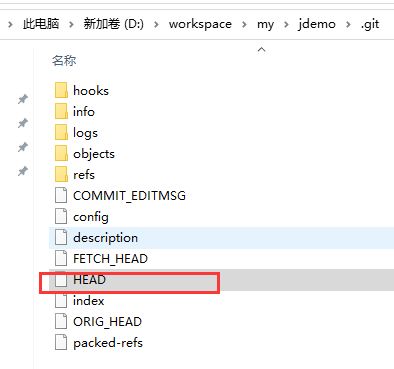
里面的内容是
ref: refs/heads/master
它指向另外一个引用(一般指向的就是master引用的位置),所以我们说:
Git 分支的本质:一个指向某一系列提交之首的指针或引用
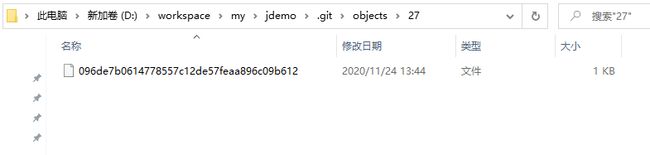
我们还可以通过这个字符串(引用)找到对应的存储文件,比如把上面b_new文件里的那个字符串引用拆成两部分,在objects里找
目录名为27,文件名为096de7b0614778557c12de57feaa896c09b612的文件,如图所示
使用命令看一下这是个什么类型的文件:git cat-file -t 096de7b0614778557c12de57feaa896c09b612

结果报错:fatal: Not a valid object name 096de7b0614778557c12de57feaa896c09b612
因为096de7b0614778557c12de57feaa896c09b612并不是对象的hash ID,要把目录名拼在一起,才是一个完整的40位hash值
27096de7b0614778557c12de57feaa896c09b612

可以看到该文件是一个commit类型的文件(从文件大小只有1k也能大致猜出来)
然后使用命令git cat-file -p 27096de7b0614778557c12de57feaa896c09b612看一下文件属性信息
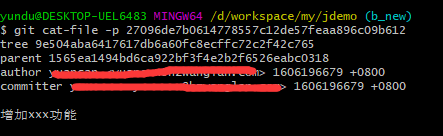
再使用命令git show 27096de7b0614778557c12de57feaa896c09b612查看文件内容
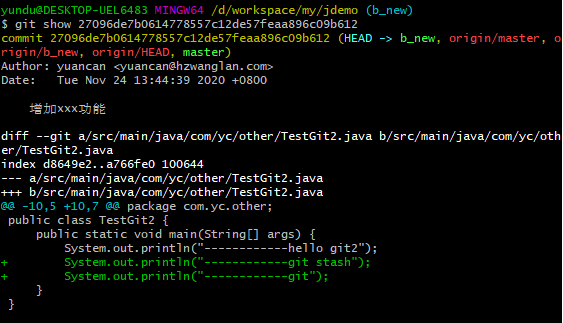
4. index:暂存区
对应的文件在

四、附录
初学者可能会遇到的坑1
当你修改的代码还没有commit的时候一定不要先使用idea的"update"功能更新代码(希望先处理一下冲突再提交)。两个原因:
- git是分布式版本管理工具,你本地的版本库和远程服务器上是并列的,commit是在往你本地提交,所以这个时候不用担心会冲突,即便冲突也是在push到远程分支的时候,git发现冲突会让你先merge一下
- idea的update很有可能会覆盖掉你未提交的代码。这个时候最保险的方式是先提交你的代码,然后再update,即便是冲突,无非是历史记录中多一个节点,东西不会丢。但有些龟毛的公司可能会要求你在commit之前必需先更新,因为他们觉得出现下面的这种提交记录不太好
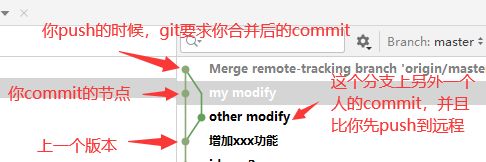
他们希望看到的是“直直的一条线”,出现冲突,自己本地提前消化掉。但网上查一查就会发现,很多人都会掉坑里:提交前点了idea的update,然后自己代码就被覆盖了。
初学者可能会遇到的坑2
当修改的代码还没有commit的时候,如果不清楚自己在做什么(对git特性理解不够透彻),不要切换分支。在切换之前要先用stash暂存该分支的工作进度,让ChangeList处于清空状态再切换分支。否则一个不留神,就把本该在这个分支提交的代码,提交的其他分支上去了。
关于git可能的疑惑
我们知道git最终会产生一条版本树节点链条,结合我们开发的感觉,你可能会产生这样的想法:链条的前后节点是有“前后因果的延续”,比如节点1是 abc, 节点2是abcde, 是因为节点2在节点1的基础上增加de的结果。
但当我们合并的时候, 如果我们手动合并后的代码变化极大,另一个分支把当前我们的分支的特性全部抹除了,git是否会“感到困惑”,比如 我们的分支是abc, 合并完变成了123。git能接受这种合并结果吗? 其实这就是你想多了,要明白,git再智能,它也只是一个版本管理工具,它并不理解我们的代码内容,它其实也不关心 版本1 和版本2之间到底经历了什么蜿蜒曲折的变更过程。它只关心版本2是否能通过合并代码确定下来(它如果确定不了,就会让你手动合并),至于确定下来是什么样的结果 和上一版本差异由多大,它并不关心(版本差异大,对git来说无非就是存储的内容多了一点),通过前面关于git的存储结构的介绍,也能解答这个疑惑:git的存储是以文件为单位的。
关于版本管理工具的使用约定
一次提交一整块可用内容。也就是不要改两行代码,因为临时有其他事情,或者要下班了 就草草提交。这样做 就会让“版本分支管理” 退化成 “分支管理”,这个时候我们应该利用好前面说的stash暂存功能。
其他命令
- 帮助命令:git 命令 -help
- 升级版帮助命令(可以把本地安装的git软件中的帮助文档以在浏览器中打开):git 命令 -help
关于版本管理工具的选择
公司资料分为两种:代码,文档
这两种资料的管理目标并不一样,代码除了有中央共享协作的功能,一个很重要的目标就是清晰的版本和分支管理。
而文档资料对版本管理的要求并没有代码那么高,因为大家很少看一个word文档以往的提交变更记录。即使要控制版本,往往也是直接在文档的开头添加一个“版本变更说明表”。也就是我们更看重文档的结果,而不是中间“加一个逗号,去一个句号”这些繁琐而且很难“分块”的内容。文档资料虽然对历史版本的管理不像代码有那么高的要求,但也有自己独特的需求点:结构清晰 所见即所得 同时可以部分检出。
应对这两种需求 我觉的目前最好的工具:代码管理使用git,文档管理使用微软的TFS
git强大的版本分支管理能力上文已经讲述。现在讲一下TFS在文档管理的优势:
- 文档目录清晰明了,所见即所得。
TFS有自己的软件界面,就像svn的客户端那样,可以直接双击打开其中的文档。
软件使用一开始,TFS就要求你在自己的本地确定一个目录作为TFS的目录映射位置。这个时候我们都是直接把TFS的根目录,映射到自己本地的某个目录。之后该目录就不再变动。不会出现svn的“一大罪状:如果管理不当,本地检出的文档会东一个西一个,而且是孤零零零的没有什么上下级关系”。
当该文档被别人更新,你的软件界面也会显示该文档已经不是最新文档,只要右键更新一下即可。(当然TFS也可以可以像管理代码一样看每个文件的历史版本) - 可以按需部分检出。
在上面的描述中,你是否有疑问:直接从根目录映射,那意思是不是把所有文档下载到本地,因为这也是文档管理的一大痛点:即不想全部下载,又想保持清晰原样的目录结构。TFS很好的解决了这个问题:一开始的映射,只是映射一个根目录位置,并不会下载任何文档。只有你需要的时候右键检出,才会在本地相应的位置检出文档,检出的位置和服务上的目录上下级关系和服务器上的一样。这也就实现了“所见即所得“:无论是在软件界面上看,还是直接在本地看,文档的上下级关系都一样。这对大部分不怎么变更的文档尤其重要,往往我们用一段时间后,就会抛开TFS软件,直接看本地目录,因为我们常用的那几个文档,在什么位置,我们已经很清楚。
参考及系列教程链接
Git权威指南
官方中文文档
git在线模拟游戏
IDEA中Git的使用
Git原理与命令大全