4.3 划分子网和构造超网
思维导图:


4.3.1 划分子网
**4.3 划分子网和构造超网笔记:**
---
**4.3.1 划分子网**
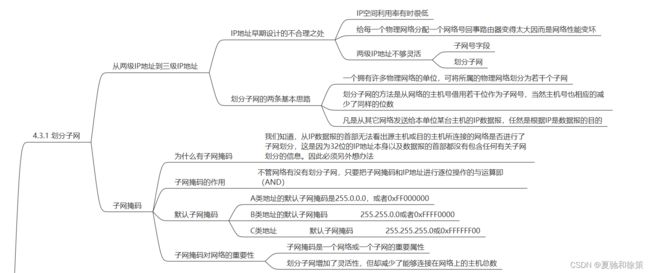
**1. 两级IP地址到三级IP地址的转变:**
**关键点:**
- **问题背景:** 早期的ARPANET对IP地址的设计存在不足:
1. IP地址空间利用率低。
2. 每个物理网络分配一个网络号会导致路由表过大,影响网络性能。
3. 两级IP地址不够灵活。
- **子网划分的意义:**
- 为了解决上述问题,从1985年起在IP地址中加入了“子网号字段”。
- 子网寻址方法提供了对IP地址空间更高效、更灵活的管理。
**基本概念:**
- **子网划分的基本思路:**
1. 一个单位可以将其多个物理网络划分为若干个子网。这是单位内部的事务,对外仍表现为一个网络。
2. 子网的划分是从原网络的主机号中借用若干位作为子网号,从而生成三级IP地址:网络号、子网号和主机号。
3. 对外部的网络,地址仍然是基于网络号的。但当数据报达到指定网络后,会根据子网号进行进一步的路由。
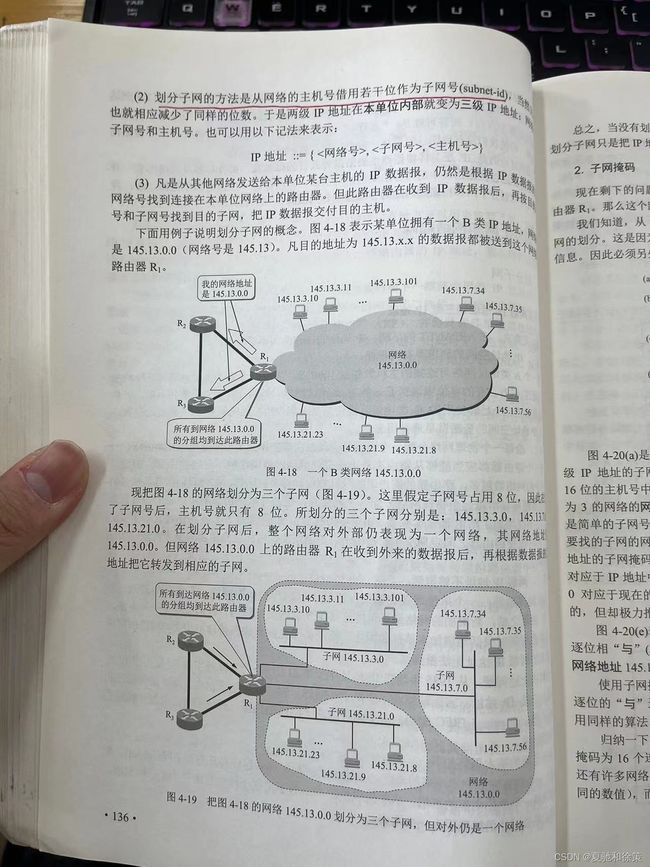
**例子说明:**
- **原始状态**:一个B类网络145.13.0.0,所有目标地址为145.13.x.x的数据报都送到这个网络的路由器。
- **划分子网后**:网络145.13.0.0被划分为三个子网:145.13.3.0, 145.13.7.0, 145.13.21.0。对外部网络仍然显示为145.13.0.0,但内部路由器会根据子网号进行进一步的路由。
**总结:**
- 当没有划分子网时,IP地址是两级结构。
- 划分子网后,IP地址变为三级结构。
- 子网划分只是对IP地址的主机号部分进行再划分,不改变原IP地址的网络号。
---
子网掩码(Subnet Mask)是IP网络中一个关键概念,它用于区分一个IP地址的网络部分和主机部分。以下是基于提供的内容对“子网掩码”这一节的简化和归纳:
---
### 子网掩码
#### 基本概念:
- 子网掩码用于将IP地址分为“网络地址”和“主机地址”两部分。
- 子网掩码与IP地址进行“与”运算(AND)可以得到网络地址。
#### 为何使用子网掩码?
1. IP数据报的首部不包含关于子网划分的信息,所以需要子网掩码来辅助。
2. 路由器可以通过子网掩码方便地从数据报中提取出子网的网络地址。
3. 使用子网掩码,路由器可以统一算法处理数据包,不必关心网络是否划分子网。
4. 标准规定所有网络都必须使用子网掩码,这简化了路由表的查找过程。
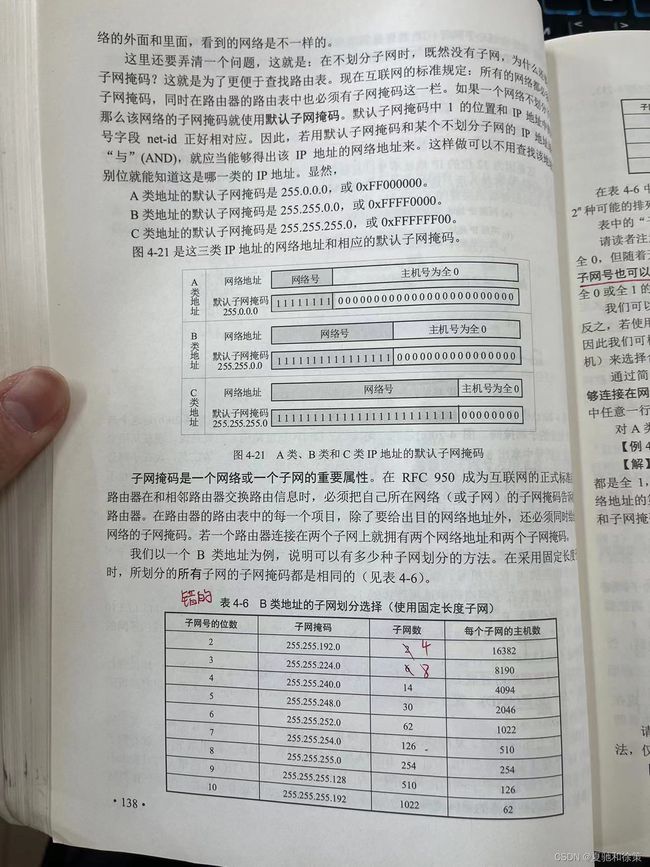
#### 子网掩码示例:
- 图4-20(a)显示了IP地址145.13.3.10的原始两级IP地址结构。
- 图4-20(b)显示了这个两级IP地址的子网掩码。
- 图4-20(c)和(d)展示了三级IP地址结构和其子网掩码。
- 通过子网掩码和IP地址逐位“与”运算,可以得到图4-20(e)所示的网络地址145.13.3.0。
#### 默认子网掩码:
- A类地址:255.0.0.0
- B类地址:255.255.0.0
- C类地址:255.255.255.0
#### 重要性:
- 子网掩码是网络或子网的关键属性。
- 路由器交换路由信息时必须提供子网掩码。
- 路由表中的每条记录都应包含子网掩码。
#### 子网划分示例:
- 表4-6展示了B类地址的子网划分选择和子网掩码。
---

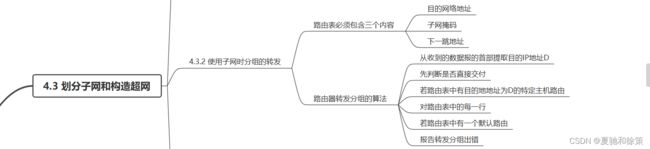
4.3.2 使用子网时分组的转发
当我们引入子网划分,分组的转发策略需要相应地进行改动。
*路由表内容:*
- 目的网络地址
- 子网掩码
- 下一跳地址
*分组转发算法:*
1. 提取数据报首部的目的IP地址D。
2. 判断是否为直接交付。
- 逐一检查与路由器直接相连的网络:使用各网络的子网掩码与D进行AND操作。若结果匹配相应的网络地址,直接交付分组并结束转发;否则,进入(3)。
3. 若路由表中有D的特定主机路由,将数据报传送给指明的下一跳路由器。否则,进入(4)。
4. 遍历路由表:使用每一行的子网掩码与D进行AND操作。若结果匹配该行的网络地址,将数据报传送给指明的下一跳路由器;否则,进入(5)。
5. 若存在默认路由,将数据报传送给指明的默认路由器;否则,进入(6)。
6. 报告转发分组出错。
**例4-4:** 一个包含三个子网和两个路由器的网络。源主机H₁想要向目的主机H₂发送分组,我们将讨论路由器R₁如何查找其路由表来转发这个分组。
网络结构如下:
- 主机H₁: IP地址为128.30.33.13,属于子网1(地址:128.30.33.0, 子网掩码:255.255.255.128)
- 主机H₂: IP地址为128.30.33.138,属于子网2(地址:128.30.33.128, 子网掩码:255.255.255.128)
路由器R₁的部分路由表如下:
- 128.30.33.0 | 255.255.255.128 | 接口0
- 128.30.33.128 | 255.255.255.128 | 接口1
- 128.30.36.0 | 255.255.255.0 | R₂
**解答:**
当H₁要发送到H₂的分组,其目标地址是128.30.33.138。首先,H₁会确定分组是在本地子网上直接交付还是通过路由器进行间接交付。通过AND操作,H₁确定H₂不在同一个子网上,因此将分组传送给默认路由器R₁。R₁在其路由表中逐行搜索匹配的网络地址。最终,R₁将该分组从接口1直接转发到H₂。
我对这一节的理解:
这一节主要讨论了在有子网划分的网络环境中,如何进行分组转发。我们可以从以下几个方面理解这一节的内容:
1. **子网的引入和意义**:子网允许一个IP地址范围内的网络被进一步分成更小的网络。这样做的好处是可以更高效地管理和使用IP地址,并根据组织或物理结构将网络逻辑地划分。
2. **路由表的重要性**:路由表是路由器用来确定如何转发数据包的关键工具。在子网环境中,路由表不仅包含目的网络地址和下一跳地址,还增加了子网掩码。子网掩码用于确定目标地址属于哪个子网。
3. **分组转发算法**:当路由器收到数据包时,它会根据算法来决定如何转发。这一节详细描述了这个算法,包括如何使用AND操作和子网掩码来检查数据包的目的地址,并决定是否直接交付、间接交付或者使用默认路由。
4. **直接交付与间接交付的区别**:直接交付意味着目的地址在与路由器直接连接的网络上;间接交付意味着数据包需要被转发到另一个路由器或网络。
5. **实例分析**:通过一个具体的网络拓扑和路由表,这一节展示了如何应用分组转发算法,从而加深了对算法的理解。
简而言之,这一节向我们展示了在具有子网的环境中,如何利用路由表和特定的算法来正确、高效地转发数据包。理解这些概念对于网络设计和故障排查非常关键。
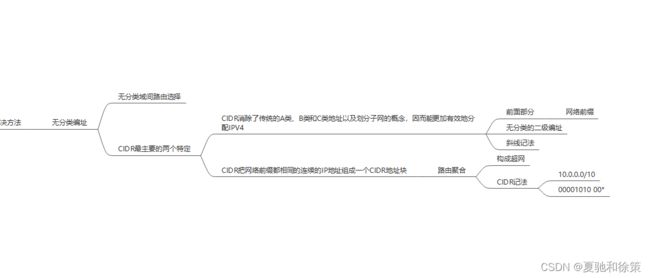
4.3.3 无分类编址CIDR(构造超网)
* **背景:**
* 1992年,互联网面临三大问题:
1. B类地址快被分配完。
2. 路由表项目数剧增。
3. IPv4地址空间将耗尽。
* **CIDR的引入:**
* 旨在解决前两个问题,而第三个问题由IPv6工作组解决。
* CIDR的思想基于VLSM(Variable Length Subnet Mask)。
* **CIDR的主要特点:**
1. **消除传统分类**:没有A、B、C类地址,取消子网概念。
* 32位IP地址分为“网络前缀”和“主机号”。
* 记法:`IP地址::={<网络前缀>,<主机号>}`
* 斜线记法:例如 `128.14.35.7/20`。
2. **CIDR地址块**:网络前缀相同的连续IP地址。
* 根据任何一个地址可以确定该地址块的范围。
* 例如,`128.14.35.7/20` 的地址范围是 `128.14.32.0` 到 `128.14.47.255`。
* **地址掩码**:
* 由1和0组成,1的个数表示网络前缀的长度。
* 虽然CIDR不使用子网,但地址掩码还可称为子网掩码。
* 斜线记法中,斜线后的数字表示地址掩码中1的个数。
* **CIDR与子网的关系**:
* CIDR不指定子网字段,但单位可以在其内部根据需求划分子网。
* **斜线记法的好处**:同时表示IP地址和其他信息,例如网络前缀长度、地址块大小等。
* **路由聚合(Route Aggregation)**:
* 利用CIDR地址块查找目的网络,大大减少了路由表中的项目数。
* 路由聚合也称为构成超网(supernetting)。
* **CIDR记法形式**:
* 例如:`10.0.0.0/10` 可简写为 `10/10`。
* 或使用星号*表示主机号。
* **表4-7**:展示了常用的CIDR地址块及其相关信息。
此节介绍了CIDR的背景、主要特点和各种记法。要理解其为什么出现,以及它是如何工作的,这有助于对IP地址分配和路由选择有更深入的了解。

为了使这个教材更容易理解和记忆,我们可以将它概括、格式化,并加入一些记忆提示或图示。
**CIDR笔记概括:**
1. **CIDR前缀长度与点分十进制:**
- `/21` -> `255.255.248.0` - 2K 地址数 - 相当于8个C类
- `/22` -> `255.255.252.0` - 1K 地址数 - 相当于4个C类
- `/23` -> `255.255.254.0` - 512地址数 - 相当于2个C类
- `/24` -> `255.255.255.0` - 256地址数 - 相当于1个C类
- `/25` -> `255.255.255.128` - 128地址数 - 相当于1/2个C类
- `/26` -> `255.255.255.192` - 64 地址数 - 相当于1/4个C类
- `/27` -> `255.255.255.224` - 32 地址数 - 相当于1/8个C类
2. **CIDR的核心概念:**
- CIDR地址块中的地址数是2的整数次幂。
- "构成超网"源于CIDR地址块包含多个C类地址。
- CIDR可以更有效地分配IPv4地址空间,提供分配灵活性。
3. **CIDR地址块划分例子:**
- ISP分配给大学地址块`206.0.68.0/22` (包括1024个IP地址)。
- 大学可以进一步划分这个地址块给不同的部门或系。
4. **地址聚合的概念:**
- 通过地址聚合,路由表可以被简化,减少项目数。
- 这就像邮递员投递到大学的收发室,再由收发室分发给各系。
5. **记忆提示:**
- 越长的CIDR前缀 = 越少的IP地址
- CIDR允许更细粒度的地址分配,不再局限于传统的A、B、C类地址划分。
6. **图解:**
- 当描述如何从ISP划分给大学,再到大学的各个系时,可以使用层次结构图或流程图。这样的视觉工具可以帮助读者快速把握核心概念。

2.最长前缀匹配笔记
**1. 什么是最长前缀匹配?**
- 当使用CIDR时,路由表中的项目可能会有不止一个匹配结果。
- 最长前缀匹配是选择具有最长网络前缀的路由。理由:网络前缀越长,地址块越小,路由越具体。
- 也被称为最长匹配或最佳匹配。
**2. 如何进行最长前缀匹配?**
- 使用AND操作比较目的IP地址与路由表中的掩码。
- 选择匹配中的最长前缀。
**3. 最长前缀匹配实例:**
- 假定存在两个路由项:206.0.68.0/22 (大学) 和 206.0.71.128/25 (四系)。
- 对于目的地址D=206.0.71.130:
- D与206.0.68.0/22匹配
- D与206.0.71.128/25匹配
- 由于206.0.71.128/25是更具体的匹配(前缀更长),数据报应转发至四系。
**4. CIDR与地理位置关联的优势:**
- IP地址与地理位置的关联可以大大压缩路由表的项目数。
- 例如,可将世界划分为地区并分配CIDR地址块:
- 194/7给欧洲
- 198/7给北美洲
- 200/7给中美洲和南美洲
- 202/7给亚洲和太平洋地区
- 这样的地址分配使IP地址与地理位置相关,简化了路由表查找。
**5. CIDR的局限性:**
- 在使用CIDR之前,IP地址并非基于地理位置分配。
- 收回并重新分配现有IP地址是困难的。
- 尽管CIDR存在局限性,它仍然延长了IP地址的使用寿命。
总结: 使用最长前缀匹配,路由决策可以更精确地根据网络前缀长度进行。而CIDR的引入可以更高效地使用IP地址空间,尽管重新分配地址的挑战依然存在。

3. 使用二叉线索查找路由表
**背景**
在CIDR实施后,路由查找中的最长前缀匹配需求使得整个查找过程更为复杂。当路由表的项数巨大时,如何优化路由查找时间就显得尤为重要。而传统的逐一查找方法效率较低,故有需求发展更为高效的查找方法。
**二叉线索(binary trie)简介**
- 它是一种树状数据结构,用于快速查询IP地址的路由。
- 由IP地址从左到右的位数来决定路径。
- 使用唯一前缀(前缀在所有IP地址中是唯一的)来构建。
**查找过程**
1. 检查IP地址最左侧的位:0表示向左,1表示向右。
2. 根据IP地址的每一位来决定下一个节点的位置。
3. 持续此过程直到到达叶子节点或没有匹配的路径。
**优化**
- **压缩技术**:例如,两个IP地址的前四位如果相同,可以直接跳过这四位,从第五位开始匹配,从而提高查找速度。
**注意点**
1. 二叉线索只提供了一种快速查找匹配的叶节点的方法。
2. 实际是否匹配,还需要与子网掩码进行逻辑“与”运算。
3. 尽管构建压缩的二叉线索可能会增加计算需求,但由于它可以提高每次查找的速度,因此这种额外的计算工作是有意义的。
**总结**
随着网络的发展,提高路由查找的速度和效率变得越来越重要。使用二叉线索等高效数据结构和查找算法,可以显著提高路由查找的性能,满足现代网络的需求。

我的理解:
理解“使用二叉线索查找路由表”这一段的核心概念,我们可以将其拆分为以下几个关键点:
1. **为什么需要新的查找方法**
- 使用CIDR(无类别域间路由)后,路由表中的地址不再简单地基于传统的类A、B、C分类,而是基于前缀长度。因此,需要寻找与给定地址最长的前缀匹配的路由条目,这使得查找变得复杂。
- 传统的逐个查找方法效率低下,特别是在大规模的路由表中。
2. **什么是二叉线索 (binary trie)**
- 二叉线索是一种树形数据结构,用于快速地在路由表中查找IP地址。
- 它使用IP地址从左到右的比特值来决定查找路径,从根节点逐层向下层延伸。
3. **唯一前缀的概念**
- 唯一前缀是在所有IP地址中只存在一次的前缀。
- 使用这些唯一前缀,可以构建一个简化和高效的二叉线索。
4. **查找流程**
- 从IP地址的最左边开始,按位进行查找。
- 0表示向左,1表示向右。
- 这种结构允许快速地确定一个IP地址是否在树中,以及它与哪个路由条目最匹配。
5. **优化查找:压缩技术**
- 如果多个IP地址的前几位都是相同的,那么在查找过程中,可以直接跳过这些位,从而提高查找效率。
6. **实际的匹配操作**
- 即使在二叉线索中找到了一个匹配的叶节点,实际的路由决策还需要进行进一步的检查。
- 需要与子网掩码进行逻辑“与”运算,以确定该地址是否真的与目标网络前缀匹配。
**简单概括**:
当网络路由表变得庞大和复杂时,我们需要更高效的查找算法。二叉线索提供了这样一个解决方案,它使用IP地址的比特值作为查找路径,从而实现快速、高效的查找。并且,通过一些优化技术,如压缩,查找速度可以进一步提高。




总结:
**划分子网 (Subnetting):**
1. **重点**:
- 子网划分是在组织内部将一个IP地址范围分为若干个更小的、逻辑上的子网络。
- 主要是通过修改子网掩码来实现,使得原始网络被划分为多个小的子网。
2. **难点**:
- 确定正确的子网掩码以满足组织的地址需求。
- 如何计算可用的子网数量和每个子网上的主机数量。
3. **易错点**:
- 忘记为网络地址和广播地址预留位置,因此可能会过度分配地址。
- 使用错误的子网掩码,导致子网过大或过小。
4. **技巧**:
- 使用二进制计算来确定可用的子网和每个子网的主机数量。
- 画出子网划分图表,帮助可视化每个子网的范围。
**构造超网 (Supernetting 或 CIDR, Classless Inter-Domain Routing):**
1. **重点**:
- 超网是将多个连续的IP地址范围合并成一个更大的、逻辑上的网络。
- 主要目标是减少路由表的大小和简化路由。
2. **难点**:
- 确定哪些网络可以被合并。
- 确保合并后的网络仍然能满足组织的地址需求。
3. **易错点**:
- 不正确地合并不连续的IP地址范围。
- 使用了不合适的子网掩码,导致超网范围不正确。
4. **技巧**:
- 使用CIDR记法,如 /22,来表示超网掩码。
- 在超网构造前,确保所有要合并的网络都是连续的。
**总结**:
划分子网和构造超网都是IP地址管理的关键概念。子网划分关注于将大网络分为小网络,而超网关注于将多个小网络组合成一个大网络。正确理解和应用这两个概念对于网络设计和路由优化至关重要。
