15. 设计模式之分离原则:如何将复杂问题拆分成小问题?
一、为什么用关注点分离原则拆分复杂问题
关注点分离原则是一个帮助我们将复杂问题拆分成小问题的好方法。
什么是关注点?简单来说,在计算机科学中,关注点是能对程序代码产生影响的一组特定信息。比如,在面向对象编程中将关注点描述为对象,在面向函数编程中将关注点描述为函数,在架构设计中将模块、组件、框架描述为关注点,等等。
其实,在前面的文章里,我们也或多或少涉及了关注点分离原则的具体实践。比如,在分层架构中按照服务类型来划分层,层就被作为一个关注点。再比如,在类或方法的编码实现中按职责分离,就是将职责作为一个关注点。
那么,为什么应该使用关注点分离原则来拆分复杂问题?关注点分离原则到底说了些什么?它带给我们哪些启示?如何正确使用好这个原则?
实际上,设计模式正是对关注点进行了有效分离才得以有效指导编程实践,所以为了在后续学习中帮助你更高效地理解设计模式,接下来我们就带着以上问题来一探究竟。
从编码实现的角度看,使用关注点分离来拆分复杂问题有两大好处。
第一,你破坏其他用户正在使用的现有功能的可能性会变小。 实际上,你可能遇见的绝大多数软件开发项目都过于复杂难懂,不仅修改一次影响多处,而且维护时也不知道哪些地方该改、哪些地方不该改,更别提什么高扩展性的代码了。不仅理解起来费劲,而且无论是在架构设计还是编码实现上,扩展性都很差。而当你分离了不同的关注点后,就可以避免不必要关注点的功能修改,因为与必须修改的代码相比,由不修改的代码而导致系统中断的可能性更小,也就是我们常说的不修改就不会引入 Bug。
第二,关注点分离能帮助你适应人类的短期记忆限制。 这在一些计算机早期研究的论文中便有提及过。就像我们看一篇文章一样,我们的短期记忆总是只能记住最近阅读过的简单问题,而对于一些复杂问题很快就会忘记。尽管现在信息的存储和查询效率远远高于过去,但是你在编程中依然无法理解那种过于庞大而复杂的问题,只有将不同关注点拆分出来,才能更好地去解决各个问题。
所以说,使用关注点分离来拆分复杂问题很有实践的价值。
二、两个视角下的关注点分离
关注点分离(Separation of Concerns,简称 SoC)是将计算机程序分隔为不同部分的设计原则。最早出现在 1974 年,那时它只是针对如何深入研究一门课程而提出的一种思考方法。
关注点分离原则的原理很简单,就是:先将复杂问题做合理的分解,再分别仔细研究程序上特定问题的侧面(关注点),最后解决得出的接口,再合成整体的解决思路。
除了狭义上程序特定的关注点外,在广义上同样可以找到很多关注点,比如,我们很容易找到的关注点就是影响我们常用的软件设计的两个思考视角,也就是架构设计视角和编码实现视角。
1. 架构设计视角
架构设计视角下的关注点分离侧重于整个系统内组件之间的边界划分,比如,层与层、模块与模块、服务与服务等。
通常我们都知道,局部的分离不代表整体的分离,因为模块与模块之间依然需要通信,一旦没有某种策略来限制相互通信的耦合度,架构稍不注意就会演变为大泥球式的架构。比如,我们常用 MVC 分层策略来做架构上的关注点分离。二者对比如下图所示:
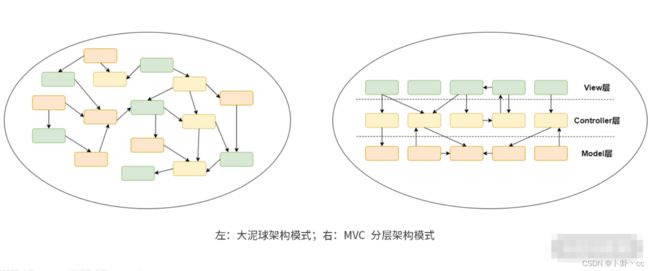
你会发现,在图中右侧的 MVC 架构中,我们将相关的主题聚合在某一层,这样便不再难以理解了。也就是,将层作为关注点来进行分离,通过解决每一个层的问题来实现整体问题的解决。
同样,现在流行的微服务架构也是采用水平分离的策略来达到服务与服务之间关注点分离的目的,如下图所示:
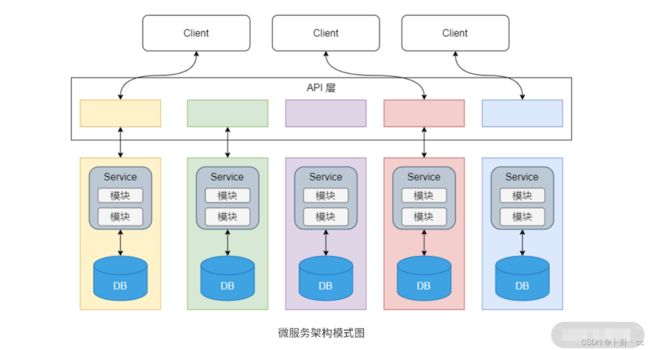
虽说每个微服务的关注点可能完全不同,但通过统一的 API 层来进行通信就不会影响它们之间的相互配合。
总之,通过上面的两个例子你可以看到:架构设计视角下的关注点分离更重视组件之间的分离,并通过一定的通信策略来保证架构内各个组件间的相互引用。
2. 编码实现视角
编码实现视角下的关注点分离主要侧重于某个具体类或方法间的边界划分,估计这里你立马会想到职责分离,没错,职责分离就是一种编码实现视角下关注点分离的优秀实践。比如,下面的代码实现(找出 3 个年龄大于 35 岁的员工的名字),就是基于操作职责相似性来进行关注点分离的,使用的是 Lambda 表达式。
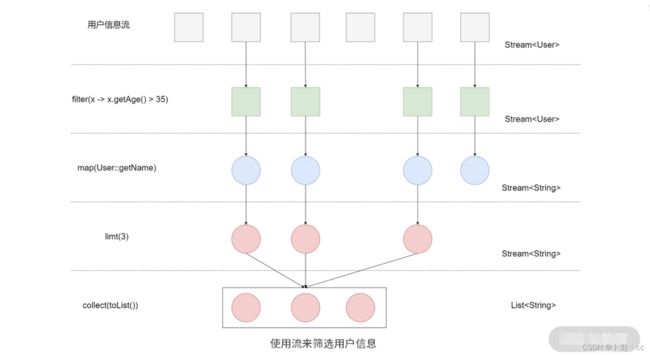
如图中所示,我们的关注点现在变成了数据流上的操作步骤(过滤、映射、限制等),我们读取每一个用户信息数据后,都会经过相同的步骤来处理,这样不仅利于理解每一个步骤操作的具体含义,也更符合我们的思考习惯。
再比如,算法中基于任务职责相似性来进行关注点的分离,如下图所示:
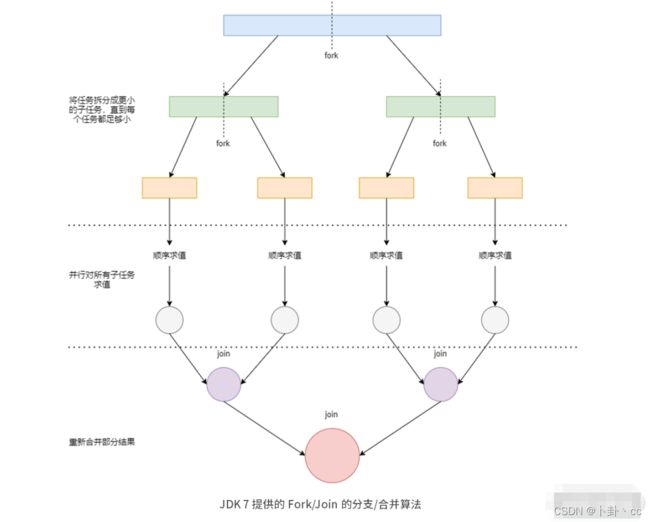
从图中可以清晰地看到,一个任务先被 Fork(拆分职责)为更小的任务,然后开始并行对所有子任务进行求值操作(计算职责,可以在多线程下并行处理),接着提供一个等待点进行 Join(合并职责),最终合并得到期望的值。
你会发现,关注点分离能非常有效地将复杂的问题拆分为小问题去解决,而且我们能够清晰地知道不同职责需要关注的是什么、不需要关注什么。
通过上面的讲解,想必你也很容易发现,虽然架构设计和编码实现中的关注点各有不同,但是对关注点进行分离后获得的效果却是一样的。一方面,我们能清楚地知道代码或架构在每一个阶段或步骤中在做什么以及它们自身关注的范围是什么;另一方面,对于拆分后的问题我们也能快速理解与分析。
除此之外,从不同的视角去分析本身也是一种关注点的分离,我们能够不局限于单一的视角,而是通过更细分的领域去思考,这更能帮助我们解决复杂问题。
三、如何实现关注点分离
了解完架构设计和编码实现这两个视角后,接下来我们就开始学习如何正确实现关注点分离的方法。
无论是架构设计,还是程序设计,好的系统总是在不断地寻找可以分离的关注点。比如,网络 OSI 七层模型就是一个关注点分离的经典应用,那它是怎么做的呢?OSI 七层模型将网络传输分为七层,每一个层只关注于自己需要完成的事情,层与层之间通过自下而上的数据通信方式进行交互。
好的架构必须使每个关注点相互分离,也就是说系统中的一部分发生了改变,并不会影响到其他部分。这主要体现在这三个方面:①即使需要改变,也能够清晰地识别出哪些部分需要改变;②如果需要扩展架构,尽量做到影响最小化;③已经可以工作的部分还都将继续工作。
除了快速识别出不变和变化的部分外,在实际实施过程中,还需要一些具体的的技巧来帮助你实现关注点分离。那就是:
-
在架构设计上,做到策略和机制分离;
-
在编码实现上,做到使用和创建分离。
技巧一:在架构设计上,做到策略和机制分离
在架构设计时,我们面对的是不同的系统、服务、类库、框架、组件等元素,要想做到关注点分离,除了将关注点从代码上移到更高的抽象层次以外,还需要做到策略和机制分离。
-
机制是指各种软件要素之间的结构关系和运行方式。可以理解为实现某个功能所需要的基础操作和通用结构。在代码中相对稳定,表现形式有:通用算法、流程、数据结构等可以起到不可变作用的部分。
-
策略是指可以实现软件发布目标的编码方案集合。在代码中相对不稳定,表现形式有:业务逻辑、接口实现。
实际上,策略和机制分离的本质就是进行标准化,也就是制定一套标准(提供机制),让使用者按照标准使用它(不同策略)。这样通过机制统一起来后,你就不用担心自己的实现不同而无法和别人完成配合了。
比如,Dubbo 框架就是为微服务架构模式下的不同服务提供了一种良好的 RPC 通信机制,不管你是会员服务还是商品服务,哪怕使用的系统实现策略完全不同,但大家只要按照协议约定进行 RPC 调用即可完成服务的复用。
再比如,Spring 其实就是将创建 Bean 和管理 Bean 的生命周期做了抽象和封装,形成了一种统一的机制。至于你想要创建什么具体类型的对象以及如何使用对象(策略),它并不用关心。
所以说,在架构设计上,进行策略和机制的分离才能让关注点得到有效的分离,不然最后会因为关注点混杂过多,导致系统越来越无法修改和维护。
技巧二:在编码实现上,做到使用和创建分离
下面我再和你重点分析一个看似简单却直击本质的关注点分离,这也是一个经常使用却常常被忽略的关注点,重要性不亚于封装、多态和继承,即实体的实例化(创建)与实体间相互使用(使用)的分离。
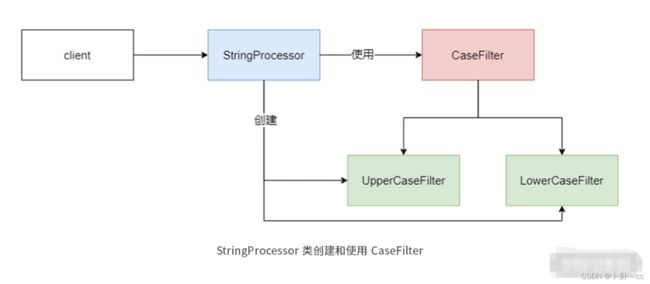
这里我们还从一个简单的例子开始,假定现在我们想要使用一个 StringProcessor 类来进行字符串相关的过滤处理操作,示意图如下:
其代码实现如下所示:
public class StringProcessor {
//使用大小写转换过滤器对象
private CaseFilter myFilter;
//构造函数
public StringProcessor() {
this.myFilter = new UpperCaseFilter();
}
//带过滤器名称的构造函数
public StringProcessor(String filterName) {
if ("up".equals(filterName)) {
this.myFilter = new UpperCaseFilter();
} else if ("low".equals(filterName)) {
this.myFilter = new LowerCaseFilter();
} else {
this.myFilter = new UpperCaseFilter();
}
}
//处理字符串的方法
public String process(String str) {
return myFilter.filter(str);
}
}
这段代码的大致逻辑是,我们使用一个 CaseFilter 接口,在 StringProcessor 类不带参数初始化时,创建 CaseFilter 接口的一个实现类 UpperCaseFilter。如果初始化带有过滤器名称时,就根据名称来选取对应的实现类。
这段代码看上去似乎没有太大问题,但是你仔细分析后就会发现,当我们有 20 个不同的过滤实现类的时候,带参数的初始化里就会出现 20 个 if-else,而且当我们想要在另外的类里使用 CaseFilter 接口时,同样需要实现 20 个 if-else 逻辑。更为严重的是,一旦这些过滤类发生修改或变化,还需要修改所有使用它们的类。
这就是将使用和创建混在一起后的结果——你既创建它又在使用它,就好比你使用智能手机拍照前,还得学会如何开发拍照程序。
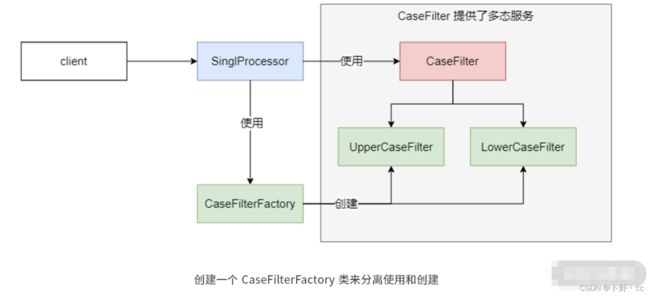
那将使用和创建分离,会带来一个什么样的效果呢?如下示意图:
其代码实现如下:
public class StringProcessor {
private CaseFilter myFilter; //接口
private String caseFilterName; //设置一个属性用于快速切换不同实现类
//空构造函数
public StringProcessor() {
this.myFilter = CaseFilterFactory.getFilter("");
}
//带参数的构造函数
public StringProcessor(String filterName) {
this.caseFilterName = filterName;
this.myFilter = CaseFilterFactory.getFilter(filterName);
}
//修改过滤器名称时,同时修改过滤器实现
public void setFilterName(String filterName) {
this.caseFilterName = filterName;
this.myFilter = CaseFilterFactory.getFilter(filterName);
}
//提供给外部使用的方法
public String process(String str) {
return myFilter.filter(str);
}
//测试类
public static void main(String[] args) {
StringProcessor stringProcessor = new StringProcessor();
stringProcessor.setFilterName("up");
System.out.println(stringProcessor.process("fdasfasdfdsaf-dsfasdfasdfadf"));
StringProcessor stringProcessor2 = new StringProcessor("low");
System.out.println(stringProcessor2.process("fdasfasdfdsaf-dsfasdfasdfadf"));
StringProcessor stringProcessor3 = new StringProcessor("low");
stringProcessor3.setFilterName("");
System.out.println(stringProcessor3.process("fdasfasdfdsaf-dsfasdfasdfadf"));
}
}
//过滤器接口
public interface CaseFilter {
String filter(String str);
}
//一种实现:替换字母s为xxx后,再全部字符小写
public class LowerCaseFilter implements CaseFilter {
@Override
public String filter(String str) {
return str.replaceAll("s","xxx").toLowerCase();
}
}
//另一种实现:替换符号 - 为 # 后,再全部字符大写
public class UpperCaseFilter implements CaseFilter {
@Override
public String filter(String str) {
return str.replaceAll("-","#").toUpperCase();
}
}
//使用 工厂方法模式 实现
public class CaseFilterFactory {
public static CaseFilter getFilter(String name){
if ("up".equals(name)) {
return new UpperCaseFilter();
}
if ("low".equals(name)) {
return new LowerCaseFilter();
}
return new UpperCaseFilter();
}
}
这里我们用工厂模式进行了简单的重构,将 CaseFilter 的创建工作交给了 CaseFilterFactory,StringProcessor 只是使用了 CaseFilterFactory。虽然只是增加了一个创建的工厂类,但是使用和创建的关系发生了重要的改变。
当我们想要使用 CaseFilter 时,不用再经过 StringProcessor,而只需要使用 CaseFilterFactory 工厂类。另外,即便新增了过滤的子类,那么修改的范围也只是限于 CaseFilter 和 CaseFilterFactory 之间。
你发现没,虽然只是简单的改变,但是 StringProcessor 和 CaseFilter 就被完全解耦开了,而且 CaseFilter 还提供了更好的复用性。因为从职责上来分析,StringProcessor 和 CaseFilter 的确可以划分为一个职责,但就是不能很好地解耦,而换到使用的视角上后,就会发现有的类或方法你可能压根就不需要创建,只需要使用即可。
所以说,在编码实现中,除了使用职责分离外,还应该从使用和创建分离来做关注点分离,这样会帮助你发现一些隐蔽的耦合关系,进而实现更好的代码可扩展性。
四、总结
关注点分离原则本质上就是要将复杂问题拆分为小问题,通过解决小问题来解决大问题。
在架构设计视角下的关注点分离,能够帮助我们从具体的代码细节中抽离出来,关注上层组件之间的关系,从全局策略出发去优化整体。
在编码实现视角下的关注点分离,能够帮助我们回到细节中,找出修改代码影响的边界范围,更好地做到局部的优化。
关于如何使用关注点分离,只需要记住两个要点。
-
第一个要点是在架构上做到策略和机制分离,换句话说,就是标准化,比如,HTTP 协议、Spring 框架等。重点关注的是整体系统的清晰与稳定。
-
第二个要点是在编码实现上做到使用和创建的分离。创建不单单是指创建对象,更重要的是抽象和封装。就像一台精密的相机一样,使用很简单,但是创建是非常复杂的。
五、课后思考
在流行的微服务架构模式中,我们很容易把关注点放到每一个微服务中,做很多形式的分离,那是不是关注点分离得越多就越好呢?这样有没有什么副作用呢?为什么?