NeurIPS 2023 | AD-PT:首个大规模点云自动驾驶预训练方案
概要
自动驾驶领域的一个长期愿景是,感知模型能够从大规模点云数据集中学习获得统一的表征,从而在不同任务或基准数据集中取得令人满意的结果。之前自监督预训练的工作遵循的范式是,在同一基准数据集上进行预训练和微调,这很难实现预训练权重的性能可扩展性和跨数据集应用。在本文中,作者提出要解决预训练网络的泛化性问题,需要从数据层面和算法层面分别考虑。为此,作者将点云预训练任务表述为一个半监督问题,利用少量有标签和大量无标签的的点云数据来生成统一的骨干表征。首先,作者通过类别感知的伪标签生成器和基于多样性的数据处理器构建了一个具有多样化数据分布的大规模预训练点云数据集;同时,将预训练和下游微调阶段关注类别不同的问题看做一个开集问题并提出了未知实例学习头,使网络从构建的多样化的预训练数据集中学习可泛化的表征。
作者利用AD-PT预训练好的权重初始化多种检测器包括PV-RCNN++,PV-RCNN,CenterPoint,SECOND,并在多个数据集(Waymo,nuScenes,KITTI)上进行微调。实验结果表明,AD-PT解耦了与自动驾驶的预训练过程和下游微调任务,在多个下游数据集上都取得了明显的性能提升。

论文题目:
AD-PT: Autonomous Driving Pre-Training with Large-scale Point Cloud Dataset
论文地址:
https://arxiv.org/abs/2306.00612
代码地址:
https://github.com/PJLab-ADG/3DTrans
动机
虽然3D检测器可以帮助自动驾驶汽车识别周围环境,但现有的基准模型很难推广到新的域(如不同的传感器设置或未见过的城市)。自动驾驶领域的长期愿景是训练出场景通用的预训练模型,该模型可泛化到不同的下游数据集。为实现这一目标,研究人员开始研究自监督预训练(SS-PT)。
但是,如图所示,应该指出的是,上述 SS-PT 与所需的自动驾驶预训练(AD-PT)范式之间存在重要区别。SS-PT 旨在从单个无标注数据集中学习,为同一数据集生成合适的表征。而 AD-PT 则希望从尽可能多并有多样性的数据中学习统一的表征,以便将学习到的特征提取能力更好地转移到各种下游数据集中。因此,SS-PT 通常只有在测试数据和预训练数据取样于同一数据集时才会表现出色,而 AD-PT 在不同数据集上具有更好的泛化性能。并且随着预训练数据集数量的增加,性能也会不断提高。
 图1:不同训练范式的对比
图1:不同训练范式的对比
因此,本文的重点是实现 AD 预训练,这种预训练可以很容易地应用于不同的基线模型和基准数据集。通过大量实验,作者认为要实现真正的 AD-PT,需要解决两个关键问题:1)如何建立一个统一的、数据分布多样的 AD 数据集;以及 2) 如何通过设计有效的预训练方法,从这样一个多样化的数据集中学习可泛化的表征。
基于上述分析,为了实现 AD-PT 模式,作者提出了基于多样性的预训练数据准备程序和未知感知实例学习的预训练过程,以加强提取特征的代表性。相比于过去的预训练方法,AD-PT提供了一种更加统一的方法,即一旦生成预训练的权重,就可以直接加载到多个感知基线和基准中。
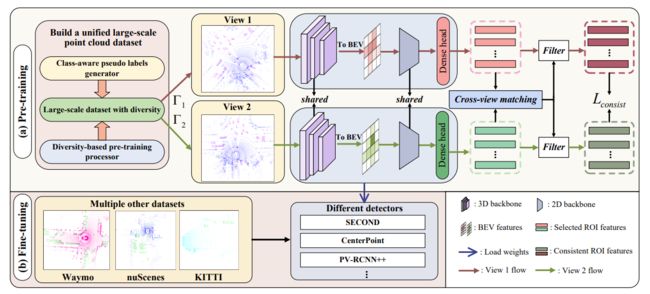 图2 AD-PT框架图
图2 AD-PT框架图
AD-PT框架如图2所示,主要包括大规模点云数据集准备程序和以自动驾驶为重点的统一表示学习程序。作者首先设计了一个类感知伪标签生成器来生成伪标签。之后,为了获得更多样化的样本,提出了一种基于多样性的预训练数据处理器。最后,为了在这些伪标签数据上进行预训练,以学习它们的通用表征,作者设计了一种带有一致性损失的未知感知实例学习方法。
方法
大规模点云数据集准备

1. 类别感知伪标签生成器
-
类别感知伪标签生成。作者发现,不同基线模型对不同类别具有不同的感知能力。例如,基于中心的倾向于更好地检测小范围目标(如行人),而基于锚点的方法则在其他类别中表现更好。最终,作者利用不同模型标注不同类别。
-
半监督学习。作者进一步利用半监督学习方法来提高伪标签的准确性。在文章中,作者使用 MeanTeacher 来进一步提高分类检测能力。最终,在 ONCE 验证集上的准确率大大超越了Benchmark上的记录。
-
伪标签阈值。为避免标注大量假阳性实例,作者设置了一个相对较高的阈值。这样也带了了一个问题,即与 ONCE 标注数据相比,一些预测分数相对较低的困难样本没有被标注。
最终的性能如下表所示:

2. 基于多样性的预训练数据处理器
- 数据线束多样化。为了获得线束多样化的数据,作者使用range image作为中间变量,对点云数据进行上采样和下采样。具体来说,给定一个有 n 个线束的激光雷达点云(如 ONCE 数据集有 40 个线束),每个环有 m 个点,range image 可通过下式求得:


- 具有更多 RoI 多样性: 不同地点采集的物体大小的分布不一致。为了克服这一问题,作者通过随机重缩放每个物体的长度、宽度和高度来获得多样性更强的实例帮助预训练。

在大规模点云数据集下学习统一表征
通过使用上述方法获得统一的预训练数据集,可以提高场景级和实例级的多样性。然而,伪标注数据集只有有限的类别标签,此外,如之前所述,为了获得准确的伪标注,作者设置了较高的置信度阈值,这可能会不可避免地忽略一些较难的实例。这些被忽略的实例在预训练数据集中可能并不重要,但在下游数据集中可能被视为感兴趣的类别(例如,nuScenes 数据集中的 “barrier”),在预训练过程中会被抑制。
为了缓解这一问题,作者将预训练视为一个开集学习问题,将对象性得分相对较高的背景区域视为未知实例。这些实例在预训练阶段被忽略,但可能对下游任务至关重要。对象性得分是从区域建议网络(RPN)中获得的。然而,由于这些未知实例包含大量的背景区域,因此在预训练阶段直接将这些实例作为前景实例处理是不合适的,会导致主干网络激活大量的背景区域。
为了克服这一问题,作者利用双分支头作为委员会来发现哪些区域可以有效地作为前景实例。具体来说,通过对双分支对象性分数大于一定阈值的bounding boxes进行基于距离的匹配,并将一致性强的区域在训练过程中当做前景。双分支一致性特征可以由下面公式获得:

实验
实验设置
-
预训练数据集。我们利用ONCE数据集,ONCE由大量无标注数据和少量代标注数据组成,包含许多场景和天气条件。在进行预训练时,我们将Car,Pedestrian和Cyclist合并为一个统一的类别。我们的主要结果是基于 ONCE 的100K数据进行,并使用更大量的数据(500K,1M)来验证预训练的可扩展性。
-
微调数据集。我们在Waymo,nuScenes和KITTI上进行了少量数据以及全量数据的实验。
实验结果
这里只展示了主要实验结果,更多结果请参考我们的论文。
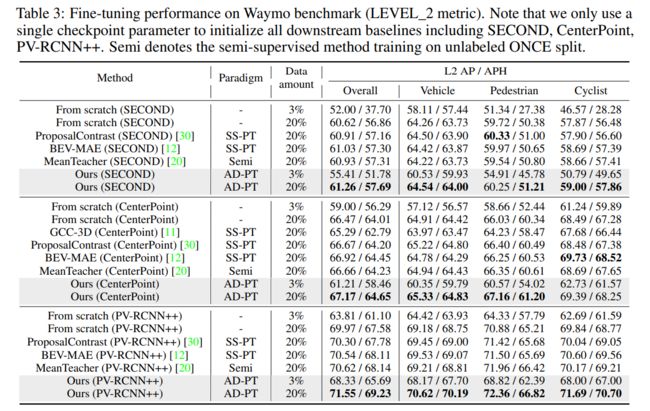 Waymo上的实验结果
Waymo上的实验结果
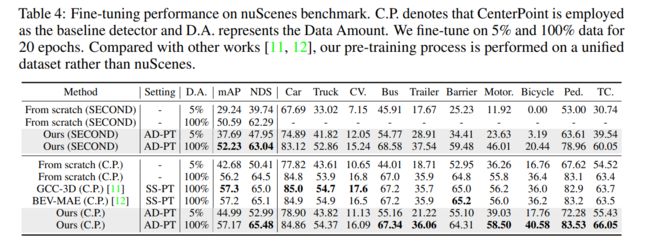 在nuScenes上的实验结果
在nuScenes上的实验结果
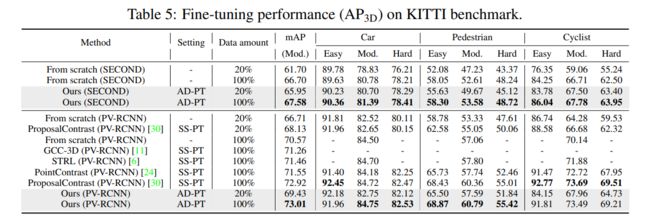 在KITTI上的结果
在KITTI上的结果
 增加预训练数据量的结果
增加预训练数据量的结果
总结
在这项工作中,作者提出了 AD-PT 范式,旨在在统一的数据集上进行预训练,训练出泛化性强且表征能力强的骨干网络,从而提升在多个下游数据集上的性能。通过所提出的数据准备流程以及未知实例学习头,分别从数据集算法层面提升模型的泛化能力。在多个基准数据集上的实验表明,AD-PT的预训练权重可以加载到多种检测器中,并且取得性能的提升。
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区