谷粒商城开发踩坑及部分知识点大总结
谷粒商城开发BUG踩坑及部分知识点大总结
基本上bug的出现位置和时间线都能够匹配
如果对你有帮助的话就点个赞哈
2022.6.28
-
github设置ssh免密登陆,以下代码在
git bash上面输入ssh-keygen -t rsa -C "[email protected]"邮箱号为自己在github上注册的账号cat ~/.ssh/id_rsa.pub将整个公钥复制到github上面去git config --global http.sslVerify "false"设置免ssl验证,以免后期在idea上push时报错
-
docker挂载mysql镜像
docker run -p 3306:3306 --name mysql -v /root/piggyMall/data/mysql/log:/var/log/mysql -v /root/piggyMall/data/mysql/data:/var/lib/mysql -v /root/piggyMall/data/mysql/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7注意打开服务器对应端口的防火墙
在conf文件夹下添加my.cnf,内容是:[client] default-character-set = utf8 [mysql] default-character-set = utf8 [mysqld] init_connect='SET collation_connection = utf8_unicode_ci' init_connect='SET NAMES utf8' character-set-server=utf8 collation-server=utf8_unicode_ci skip-character-set-client-handshake skip-name-resolve -
docker挂载redis镜像
docker run -it --name redis -p 6379:6379 --restart=always -v /root/piggyMall/data/redis/redis.conf:/etc/redis/redis.conf -v /root/piggyMall/data/redis/data:/data redis bashredis.conf内容可以参考redis.conf初始内容
-
快速开发流程
将所有的共同依赖放入common包里面,所有其余的包都依赖这个包
其次,可以使用逆向工程来对数据库中各表的基本bean、controller等来进行逆向生成,避免写大量的代码来增大工程难度
-
nacos docker 配置
nacos的镜像集成了vim等功能因此可以不挂载卷
application.property的配置,先移到交通的文件夹下
# spring server.servlet.contextPath=${SERVER_SERVLET_CONTEXTPATH:/nacos} server.contextPath=/nacos server.port=${NACOS_APPLICATION_PORT:8848} spring.datasource.platform=${SPRING_DATASOURCE_PLATFORM:""} nacos.cmdb.dumpTaskInterval=3600 nacos.cmdb.eventTaskInterval=10 nacos.cmdb.labelTaskInterval=300 nacos.cmdb.loadDataAtStart=false db.num=${MYSQL_DATABASE_NUM:1} db.url.0=jdbc:mysql://${MYSQL_SERVICE_HOST:43.142.118.35}:${MYSQL_SERVICE_PORT:3306}/${MYSQL_SERVICE_DB_NAME:nacos_config}?${MYSQL_SERVICE_DB_PARAM:characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useSSL=false} db.url.1=jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT:3306}/${MYSQL_SERVICE_DB_NAME}?${MYSQL_SERVICE_DB_PARAM:characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useSSL=false} db.user=${MYSQL_SERVICE_USER:root} db.password=${MYSQL_SERVICE_PASSWORD:123456} ### The auth system to use, currently only 'nacos' is supported: nacos.core.auth.system.type=${NACOS_AUTH_SYSTEM_TYPE:nacos} ### The token expiration in seconds: nacos.core.auth.default.token.expire.seconds=${NACOS_AUTH_TOKEN_EXPIRE_SECONDS:18000} ### The default token: nacos.core.auth.default.token.secret.key=${NACOS_AUTH_TOKEN:SecretKey012345678901234567890123456789012345678901234567890123456789} ### Turn on/off caching of auth information. By turning on this switch, the update of auth information would have a 15 seconds delay. nacos.core.auth.caching.enabled=${NACOS_AUTH_CACHE_ENABLE:false} nacos.core.auth.enable.userAgentAuthWhite=${NACOS_AUTH_USER_AGENT_AUTH_WHITE_ENABLE:false} nacos.core.auth.server.identity.key=${NACOS_AUTH_IDENTITY_KEY:serverIdentity} nacos.core.auth.server.identity.value=${NACOS_AUTH_IDENTITY_VALUE:security} server.tomcat.accesslog.enabled=${TOMCAT_ACCESSLOG_ENABLED:false} server.tomcat.accesslog.pattern=%h %l %u %t "%r" %s %b %D # default current work dir server.tomcat.basedir= ## spring security config ### turn off security nacos.security.ignore.urls=${NACOS_SECURITY_IGNORE_URLS:/,/error,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.ico,/console-fe/public/**,/v1/auth/**,/v1/console/health/**,/actuator/**,/v1/console/server/**} # metrics for elastic search management.metrics.export.elastic.enabled=false management.metrics.export.influx.enabled=false nacos.naming.distro.taskDispatchThreadCount=10 nacos.naming.distro.taskDispatchPeriod=200 nacos.naming.distro.batchSyncKeyCount=1000 nacos.naming.distro.initDataRatio=0.9 nacos.naming.distro.syncRetryDelay=5000 nacos.naming.data.warmup=true
2022.6.29
-
向nacos注册服务
1. 首先在Application.yml文件中加入注册中心服务集群的IP地址和待注册服务的名字 cloud: nacos: discovery: server-addr: 127.0.0.1:8848 application: name: piggymall-member 2.开启注解 @EnableDiscoveryClient -
开启openfeign的测试和调用
1. 首先要将待调用的服务注册在nacos里面 2. 在需要调用远程服务的服务里配置feign包,专门用来配置远程调用类 在这个包内的类都要开启@FeignClient("piggymall-coupon"),其中括号里写的是nacos注册的服务名 @RequestMapping("/piggymallcoupon/coupon/member/list")调用远程服务的某个request要写其全路径 3. 开启@EnableFeignClients(basePackages = "com.samuelchen.piggy.piggymallmember.feign")注解 其中basepackeage就是本地微服务的feign包 4. 在本地微服务中调用feign服务时,将feign service自动注入,抽取返回类的数据。 ### bug:由于Spring Cloud Feign在Hoxton.M2 RELEASED版本之后不再使用Ribbon而是使用spring-cloud-loadbalancer 在common包中,pom文件要修改为: <dependency> <groupId>com.alibaba.cloudgroupId> <artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId> <exclusions> <exclusion> <groupId>com.netflix.ribbongroupId> <artifactId>ribbonartifactId> exclusion> exclusions> dependency> <dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-loadbalancerartifactId> <version>3.1.0version> dependency> -
nacos作为配置中心来统一管理配置
1. 引入依赖 2. 创建bootstrap.properties注入nacos配置中心的地址,这样才能拉取配置 spring.cloud.nacos.config.server-addr=127.0.0.1:8848 spring.application.name=piggymall-coupon 3.给配置中心创建一个配置文件,名字是piggymall-coupon.properties 4.给配置文件中添加配置 5.在用到配置文件的类里加上@RefreshScope动态刷新配置,@Value("${配置名称}")获取配置,如果与包内的application.properties冲突的话,优先使用配置中心的配置。 -
更换命名空间,在bootstrap.properties里面加入命名空间下的命名空间ID即可 spring.cloud.nacos.config.namespace=3d3c6750-3971-4a52-9038-15873f832589 命名空间可以基于环境进行隔离,也可以基于微服务来进行隔离 spring.cloud.nacos.config.group=xxxx 可以定义同一个命名空间的不同配置集分组,在特定的环境下使用特定的分组 将配置文件拆分成多个独立的配置文件,在配置中心统一管理,在bootstrap.properties中可以引入 spring.cloud.nacos.config.ext-config[0].data-id=datasource.yml spring.cloud.nacos.config.ext-config[0].group=dev spring.cloud.nacos.config.ext-config[0].refresh=true spring.cloud.nacos.config.ext-config[1].data-id=mybatis.yml spring.cloud.nacos.config.ext-config[1].group=dev spring.cloud.nacos.config.ext-config[1].refresh=true spring.cloud.nacos.config.ext-config[2].data-id=others.yml spring.cloud.nacos.config.ext-config[2].group=dev spring.cloud.nacos.config.ext-config[2].refresh=true ... 这些配置选项可以完善配置文件,配置中心有的用配置中心的,否则用本地文件中的 微服务任何配置文件都可以放在配置中心中,在bootstrap.properties说明 springboot中获取配置中心的配置的注解都可以从配置中心拉取
注意Spring包的版本, 版本保持一致可以省掉诸多bug!!!!!!!!!!!!!!
2022.7.3
-
想要在entity里面加入一个数据库中不存在的field,在使用了mybatis plus的基础上,需要在这个field上加一个注解
@TableField(exist = false) -
stream.filter()按条件过滤
stream.sorted()按条件排序,正向排序
collect(Collectors.toList()) 按条件整合成为list
-
如果gateway和待转发的微服务不在一个命名空间内就会报503,所以要将其至于一个命名空间内~
-
当浏览器调用一个协议、uri、端口三者有一者存在不同的uri的时候,这种请求称为跨域请求,对于跨域请求,浏览器先发送一个request method 为option的请求去服务器询问是否支持跨域请求,因此需要在服务区开启支持跨域请求的选项
@Configuration public class PiggyMallCorsConfiguration { @Bean public CorsWebFilter corsWebFilter() { UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource(); CorsConfiguration corsConfiguration = new CorsConfiguration(); corsConfiguration.addAllowedHeader("*"); corsConfiguration.addAllowedMethod("*"); corsConfiguration.addAllowedOrigin("*"); corsConfiguration.setAllowCredentials(true); source.registerCorsConfiguration("/**", corsConfiguration); return new CorsWebFilter(source); } }对于任意uri调用的跨域请求,允许任意请求头、方法、来源、携带cookie来跨域请求,这样就可以实现不同端口调用网关请求服务的功能。
2022.7.4
-
现在对数据库的删除大多数都不是直接删除数据,而是对数据进行逻辑删除,即在数据库中的某个表里面将标志位赋值
1. 配置mybatis-plus的yml文件 mybatis-plus: mapper-locations: classpath:/mapper/**/*.xml #映射xml配置文件 global-config: db-config: logic-delete-value: 1 logic-not-delete-value: 0 # 全局逻辑删除组件 2. 在待标记的表上的属性上加上注解,如果该表的规则和全局配置不相同,则可以在注解上面说明,如 @TableLogic(value = "1", delval = "0") private Integer showStatus; 3. 调用删除方法还是和之前是一样的方法,内部会自动识别
2022.7.5
-
使用nacos的配置中心进行统一管理报错时,检查配置中心文件名和bootstrap.yml是否一致
检查配置中心文件内变量名和@Value处是否一致,遇到@value找不到对于的值的时候,反复检查,nacos机制不会出问题!
2022.7.6
-
javax.validation.constraints包里面规定的注解和后端数据椒盐有关,在前段校验之后,后端也要进行校验,在entity传入的时候,加上@Valid注解来启用校验流程。 给校验的bean后面紧跟一个BingdingResult,就可以获取校验的结果。
-
定义一个统一的exception处理器,来统一处理后端校验抛出来的问题
@Slf4j @RestControllerAdvice(basePackages = "com.samuelchen.piggy.piggymallproduct.controller") // 开启基础包exception监听 public class PiggymallExceptionControllerAdvice { @ExceptionHandler(value= MethodArgumentNotValidException.class) //处理某一类具体的exception public R handleVaildException(MethodArgumentNotValidException e){ log.error("数据校验出现问题{},异常类型:{}",e.getMessage(),e.getClass()); BindingResult bindingResult = e.getBindingResult(); Map<String,String> errorMap = new HashMap<>(); bindingResult.getFieldErrors().forEach((fieldError)->{ errorMap.put(fieldError.getField(),fieldError.getDefaultMessage()); }); return R.error(BizCodeEnum.VAILD_EXCEPTION.getCode(), BizCodeEnum.VAILD_EXCEPTION.getMsg()).put("data",errorMap); } //BizCodeEnum是一个枚举类,专门用于处理错误代码 @ExceptionHandler(value = Throwable.class) public R handleException(Throwable throwable){ log.error("错误:",throwable); return R.error(BizCodeEnum.UNKNOW_EXCEPTION.getCode(),BizCodeEnum.UNKNOW_EXCEPTION.getMsg()); } }其中BizCodeEnum
package com.samuelchen.common.exception; /*** * 错误码和错误信息定义类 * 1. 错误码定义规则为5为数字 * 2. 前两位表示业务场景,最后三位表示错误码。例如:100001。10:通用 001:系统未知异常 * 3. 维护错误码后需要维护错误描述,将他们定义为枚举形式 * 错误码列表: * 10: 通用 * 001:参数格式校验 * 11: 商品 * 12: 订单 * 13: 购物车 * 14: 物流 * * */ public enum BizCodeEnum { UNKNOW_EXCEPTION(10000,"系统未知异常"), VAILD_EXCEPTION(10001,"参数格式校验失败"); private int code; private String msg; BizCodeEnum(int code, String msg) { this.code = code; this.msg = msg; } public int getCode() { return code; } public String getMsg() { return msg; } } -
分组校验(多场景的复杂校验)
1) @NotBlank(message = "品牌名必须提交",groups = {AddGroup.class,UpdateGroup.class}),给校验注解标注什么情况需要进行校验 2)用@Validated({AddGroup.class})来替代@Valid 3) 默认没有指定分组的校验注解@NotBlank,在分组校验情况@Validated({AddGroup.class})下不生效,只会在不指定group的@Validated下生效; -
自定义校验
1)、编写一个自定义的校验注解 2)、编写一个自定义的校验器 ConstraintValidator 3)、关联自定义的校验器和自定义的校验注解 @Documented @Constraint(validatedBy = { ListValueConstraintValidator.class【可以指定多个不同的校验器,适配不同类型的校验】 }) @Target({ METHOD, FIELD, ANNOTATION_TYPE, CONSTRUCTOR, PARAMETER, TYPE_USE }) @Retention(RUNTIME) public @interface ListValue { -
在级联查询的时候,对于值为空集合的属性应该避免向前段注入空属性,尽管后端依旧注入了这个属性,因此加入注解
@JsonInclude(JsonInclude.Include.NON_EMPTY)从而可以在返回json对象的时候忽略/删除某个属性的空值。
2022.7.7
-
对于复杂查询,在serviceImpl里面用querywrapper进行操作不如直接在mabatis里面的xml文件里直接书写逻辑
1. 在继承了baseMapper的接口中加入方法 void updateCategory(@Param("catlogId") Long catId, @Param("catlogName")String name); 用@Param标注方法可以在后面调用的时候更加方便 2. 在xml文件中写上对应的sql,id是上述方法名。update `piggymall_pms.pms_category_brand_relation` set catelog_name=#{catlogName} where catelog_id=#{catlogId} -
使用MP来配置xml文件的时候要注意XML文件的地址,在application.yml文件中要正确配置,不然会报错
Invalid bound statement (not found)mybatis-plus: mapper-locations: classpath:/piggymallproduct/*.xml -
VO值对象
接受页面传递来的数据,封装对象 将业务处理完成的对象,封装成页面所需要的数据
2022.7.8
-
pubsub报错的解决方法
1、npm install --save pubsub-js 2、在src下的main.js中引用: ① import PubSub from 'pubsub-js' ② Vue.prototype.PubSub = PubSub -
Controller的三层业务处理逻辑
1、Controller:处理请求,接受和校验数据 2、传递数据给对应的Service,其接受controller传来的数据,进行业务处理,controller不应该写过多的低层逻辑 3、Controller接受Service处理完的数据,封装页面指定的vo -
entity在创建的时候,尽管没有指明@TableId标注的属性,在实例化并调用basemapper保存之后这个属性会被自动注入值。
2022.7.9
-
在开发初期不要配置中心和本地混用,不然连bug都找不到在哪报的
-
jackson: date-format: 用于配置时间在json中的格式
2022.7.10
-
优化业务逻辑:采购需求多选删除的时候如果没有选中后端会报错;如果已经分配率采购单,在后续新增采购需求的时候默认分配,这样不对。
-
员工接单postman
http://localhost:88/api/ware/purchase/received [1,3] -
员工采购完毕postman
http://localhost:88/api/ware/purchase/done { "id": 3, "items":[ {"itemId":7,"status":3,"reason":""}, {"itemId":9,"status":4,"reason":"无货"} ] } -
规格维护报404,直接console输入
use piggymall-admin; INSERT INTO sys_menu (menu_id, parent_id, name, url, perms, type, icon, order_num) VALUES (76, 41, '规格维护', 'product/attrupdate', '', 1, 'log', 0); -
启动ES镜像
docker run --name es -p 9200:9200 -p 9300:9300 --restart=always -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms256m -Xmx512m" -v /root/piggyMall/data/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /root/piggyMall/data/es/data:/usr/share/elasticsearch/data -v /root/piggyMall/data/es/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.4.2kibana安装在实验室服务器上了,云服务器内存不够了hh,详情查看CSDN
-
ES新增数据的时候,PUT请求必须在URL带上ID,POST可以不带ID,会自动生成,而PUT更新数据的时候必须带上ID。
-
POST操作会对比源文档数据,如果相同不会有什么操作,文档version不增加,而PUT操作总会将数据重新保存并且增加version版本:
带_update对比元数据如果一样就不进行version的任何操作,对于大并发更新就不带update,对于大并发查询偶尔更新,就需要带update来进行对比更新,重新计算分配规则。
-
ES只能删除索引(数据库)和文档(行),不能删除类型(表)
2022.7.11
-
docker 启动 nginx
docker run -p 80:80 --name nginx -v /root/piggyMall/data/nginx/html:/usr/share/nginx/html -v /root/piggyMall/data/nginx/logs:/var/log/nginx -v /root/piggyMall/data/nginx/conf:/etc/nginx --restart=always -d nginx docker update es --restart=alwaysdocker访问的静态文件都是在/usr/share/nginx/html目录下的,可以直接搜索得到
-
配置ik的扩展词库,只需要在nginx里面新建一个txt文档,上面输入想要新增的自定义词库,然后在es的plugin(/es/plugins/ik/config/IKAnalyzer.cfg.xml)里面配置扩展词库即可
IK Analyzer 扩展配置 http://43.142.118.35/es/fenci.txt -
SpringBoot找不到或无法加载主类 -> 对maven进行clean和重新install,处理报错
-
商品ES搜索建库
PUT product { "mappings": { "properties": { "skuId": { "type": "long" }, "spuId": { "type": "keyword" }, "skuTitle": { "type": "text", "analyzer": "ik_smart" }, "skuPrice": { "type": "keyword" }, "skuImg": { "type": "keyword", "index": false, "doc_values": false }, "saleCount": { "type": "long" }, "hasStock": { "type": "boolean" }, "hotScore": { "type": "long" }, "brandId": { "type": "long" }, "catalogId": { "type": "long" }, "brandName": { "type": "keyword", "index": false, "doc_values": false }, "brandImg": { "type": "keyword", "index": false, "doc_values": false }, "catalogName": { "type": "keyword", "index": false, "doc_values": false }, "attrs": { "type": "nested", "properties": { "attrId": { "type": "long" }, "attrName": { "type": "keyword", "index": false, "doc_values": false }, "attrValue": { "type": "keyword" } } } } } }
2022.7.12
-
lambda表达式提示变量错误:Variable used in lambda expression should be final or effectively final
为什么 Lambda 表达式(匿名类) 不能访问非 final 的局部变量呢? 因为实例变量存在堆中,而局部变量是在栈上分配,Lambda 表达(匿名类) 会在另一个线程中执行。如果在线程中要直接访问一个局部变量,可能线程执行时该局部变量已经被销毁了,而 final 类型的局部变量在 Lambda 表达式(匿名类) 中其实是局部变量的一个拷贝。 通俗点说就是,为了避免匿名子线程开始了之后,还没有执行到System.out.println("继承第" + i+ "颗龙珠");之前,父线程就把i的值改变了,这时候得到的结果就和我们预期的不一样了,而我们又需要不断改变i的值,解决方法其实很简单,就是要使得子线程里用到的值都不要发生变化嘛,再定义一个变量,将i的值赋给它,然后再线程里用到这个变量就行了。 -
如果一个项目引用了别的项目,要把所有包的maven依赖配好,两个项目的从属应该是兄弟关系。不然在运行起来的时候,springboot正常启动但是request接收不到。这时候可以用mvn的plugin来进行springboot的运行来debug。
2022.7.13
-
模板引擎
1. thymeleaf-starter:关闭缓存实时更新 spring:thymeleaf: cache: false 2. 静态资源都放在static文件夹下,页面放在templates文件夹下,默认会在这两个文件夹下寻找 3.引入devtools,实时刷新静态页面,ctrl+shift+f9org.springframework.boot spring-boot-devtools true -
nginx和网关的区别
nginx提供了一个外网的访问ip,这个公网ip就可以接受外部发来的请求,然后他再将接受到的请求,通过负载均衡等一系列策略来转发到网关,网关根据注册中心注册的服务器信息来选择调用哪一台服务器来响应请求,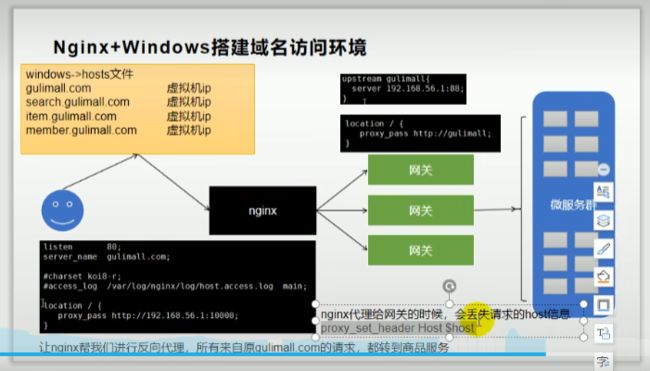
nginx是访问web服务的入口
-
压力测试用jmeter,jdk里面没有配jvisualvm的话可以在网上下载独立的第三方jvisualvm,在conf里面映射到本地的JDK父目录下即刻,下载GC的plugin来查看GC情况和堆空间。
-
nginx在代理的时候会丢掉一些请求头的信息,因此在配置的时候就要手动加上这些信息
proxy_set_header Host $host;
2022.7.14
-
nginx动静分离,映射静态资源的位置
location /static/ { alias C:/Users/SamuelChen/Desktop/nginx-1.22.0/html/static/product/; autoindex on; } -
哪些数据适合放到缓存里面
1. 即时性、数据一致性要求不高的数据 2. 访问量大但是更新频率不高的数据、读多写少的数据(物流信息等) -
redis的三大异常
1. 缓存穿透 当大量并发请求来访问一个数据库内不存在的信息时,由于查找不到Redis的信息,就将请求放给DB处理,导致DB接受的请求瞬间变大,从而导致DB崩溃 => 解决方案:将DB中不存在的信息也缓存在Redis中,value置为null,给一定的过期时间。 2. 缓存雪崩 当大量的请求在同一时间过期或者Redis故障导致无法访问,对于大并发请求会同时查DB,导致DB崩溃 => 因此在设置Redis的过期时间的时候,在统一的过期时间上要加一个浮动的随机时间,避免同时大量key过期; 或者在经过Redis查找DB的时候加锁,使得单线程查DB; 或者可以使用永不过期的备用key,在查不到主key的时候返回备用key的值,在更新主key的时候更新备用key; 对于Redis过期的解决方案则是搭建集群。 3. 缓存击穿 如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题 => 互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间; -
Redis的分布式锁
本地锁带来的问题 1. 在微服务模式下,如果本地加锁,那么只能锁住每一个微服务的线程,对于负载均衡到不同机器的情况依然会有较多的线程查询数据库; 2. 解决问题1的办法在于,将一个flag置于Redis中,以这个flag来当锁,这样就可以做到全局加锁。但是如果flag的过期时间小于业务完成的时间,当前线程就会删除后面拿到锁的线程的锁。 3. 解决问题2的方法在于,flag的值可以为UUID这种不重复的数值,这样就不会误删了。但是如果网络通信延迟高的情况下,查锁到删锁的这个过程中由于ping过高导致锁过期,那么依然会误删别人的锁。 4. 解决问题3的方法在于,可以用Redis内置支持的Lua脚本来实现查锁删锁的原子操作,这样可以保证全局统一的分布式锁,但是这样编码太麻烦了,因此要引入Redisson分布式锁来处理。
2022.7.15
-
Redisson
1. lock.lock()方法,没有指定锁的时间,因此锁会自动续期,如果业务超长,在运行期间每10秒会自动给锁续为一个新的30秒,不用担心因为业务长被删除。只要业务完成,就不会给当前锁续期,即使不手动解锁,锁默认在30秒之后会被删除。 2. lock()方法内可以指定一个时间,按照这个时间设置自动过期时间,但是不会自动续期。 3. 加读写锁的时候,只要拿到锁的名字相同,就是同一套读写锁。只要写锁还没被释放,那么读写功能均不管用; 只要读锁还没被释放,那么写功能不管用。 4. 处理缓存数据一致性问题:使用失效模式,缓存的所有数据都加上一个过期时间,数据过期的下一次触发主动更新;在读写数据的时候加上分布式的读写锁,对于经常更新并且要求实时性比较高的数据就直接查数据库,哪怕慢一些都可以,不要过度设计。 -
SpringCache
1. 每一个需便缓存的数据我们都来指定要收到幕个名字的缓存,【缓存的分区(按照业务类型分)】 2. Cacheable({"cotegory"}) 代表当前方法的结果需要缓存,如果缓存中有,方法不用调用:如果缓存中没有,会调用方法,最后将方法的结果收入缓存 默认行为 1)、如果缓存中有,方法不用调用。 2)、key默认自动生成:缓存的名字::SimpleKey[](自主生成的值) 3)、缓存的value的值,默认使用jdk序列化机制。将序列化后的数据存到redis: 4)、默认ttl时间-1, 即永不过期 3. 整合SpringCache简化缓存开发 1)、引入依赖 spring-boot-starter-cache spring-boot-starter-data-redis 2)、写配置 (1)、自动配置了哪些 CacheAuroConfiguration会导入RedisCacheConfiguration; 自动配好了缓存管理器RedisCacheManager (2)、配置使用redis作为缓存 spring.cache.type=redis 3)、测试使用缓存 @Cacheable: Triggers cache population,:触发将数据保存到缓存的操作 目 @CacheEvict: Triggers cache eviction,:触发将数据从缓存删除的操作 @CachePut: Updates the cache without interfering with the method execution,:不影响方法执行更新cache @Caching: Regroups multiple cache operations to be applied on a method,组合以上多个操作 @CacheConfig: Shares some common cache-related settings at class-LeveL,:在类级别共享缓存的相同配置 开启缓存功能@EnabLeCaching 只需要使用注解就能完成缓存操作 4)、原理: CacheAutoConfiguration -RedisCacheConfiguration-> 自动配置了RedisCacheManager->初始化所有的缓存->每个缓存决定使用什么配置 ->如果redisCacheConfiguration有就用已有的,设有就用默认配置 在yml文件中配置了这两个配置,那么存储在redis里面的就是一个单独的key key-prefix: CACHE_ use-key-prefix: true 但是不推荐这种方法,还是不要指定前缀,让它根据前缀划分文件夹 使用@Caching注解能在注解里面配置多个注解,用于删除多个缓存 @Caching(evict = @CacheEvict(value "category",key "'getLevellCategorys'"), @CacheEvict(value "category",key "'getCatalogJson'") ) 源码如下: public @interface Caching { Cacheable[] cacheable() default {}; CachePut[] put() default {}; CacheEvict[] evict() default {}; } 或者删除某一个分区 @CacheEvict(value "category", allEntries = true) -
Nginx配置proxy_pass转发的 / 路径问题
在nginx中配置proxy_pass时,如果是按照^~匹配路径时,要注意 `proxy_pass` 后的 `url` 最后的 `/` : 当加上了 `/`,相当于绝对根路径,则 nginx 不会把 location 中匹配的路径部分代理走 如果没有 `/`,相当于相对路径,则会把匹配的路径部分也给代理走 网关不采用host匹配机制,则不需要proxy_set_header Host $host; -
部署新的页面,使用模板引擎前要做的事情,否则首页无法渲染
1. pom文件新增org.springframework.boot spring-boot-starter-thymeleaf org.springframework.boot spring-boot-devtools true
2022.7.16
- ES聚合有bug,在ServiceImpl上,catalogName.keyword才能正常显示,其他的不需要加keyword,否则不显示。
2022.7.20
-
商品详情页的uri
http://localhost:88/item/18.html -
用户注册登录流程
1. get localhost:88/auth/register/send?phone= 1分钟内重复提交无效,获取到验证码code之后 2. post localhost:88/auth/register/register body:username,password,phone,第一步的code,验证不对不给通过 3.登录 post localhost:88/auth/login body:username,password
2022.7.21
-
在登录系统的时候,由于后端服务器调用了session.setAttribute,这个session默认是保存在微服务本地,以kv对的形式保存,并且会给客户端发一个JSESSIONID的cookie,这个cookie在对于跨域名的网页访问就会失效,因此需要考虑分布式session。
-
SpringSession原理
@EnableRedisHttpSession里面导入了@Import({RedisHttpSessionConfiguration.class})这个类 并且@EnableRedisHttpSession也是一个@Configuration RedisHttpSessionConfiguration在容器中添加了一个组件sessionRepository返回的类别是RedisOperationsSessionRepository类,使用redis来操作session的增删改查 RedisHttpSessionConfiguration的父类SpringHttpSessionConfiguration有一个bean,叫做sessionRepositoryFilter,这个filter中的doFilterInternal方法用于对原生的请求带来的session进行装饰,使得wrappedRequest代替原生request,使得wrappedRespond代替原生respond,以后的请求都调用的是warpper的getSession方法. S session = SessionRepositoryFilter.this.sessionRepository.findById(sessionId); 调用warper的getsession实现方法,如果session为空就从sessionRepository获取,而sessionRepository是RedisOperationsSessionRepository。
2022.7.22
-
设置微服务要用的线程池
1. 设置一个ConfigurationProperties用来在yml文件中配置 @ConfigurationProperties(prefix = "piggymall.threadpool") @Component @Data public class ThreadPoolConfigurationProperties { private Integer coreSize; private Integer maxSize; private Integer keepAliveTime; } 2.设置一个实现类,用于加载配置实例化线程池到容器中去 @Configuration public class MyThreadConf { @Bean public ThreadPoolExecutor threadPoolExecutor(ThreadPoolConfigurationProperties properties) { return new ThreadPoolExecutor(properties.getCoreSize(), properties.getMaxSize(), properties.getKeepAliveTime(), TimeUnit.SECONDS, new LinkedBlockingDeque<>(1000), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); } } 3.在yml文件中进行配置 piggymall: threadpool: core-size: 100 max-size: 300 keep-alive-time: 300 -
购物车API
1. get localhost:88/cart/getCart/checked 获取已经选中的商品的购物车 2. get localhost:88/cart/deleteItem?skuId 删除某件商品 3. get localhost:88/cart/checkItem?skuId= check= 选中或者不选中某件商品 4. get localhost:88/cart/countChange?skuId= count= 改变某件商品的数量 5. get localhost:88/cart/cartList 获取当前的购物车 /* 在登陆之后要调用一下这个方法才能将未登录时选购的同步过来 6. get localhost:88/cart/addToCart?skuId= count= 将一定量商品放入购物车 7. get localhost:88/cart/getCartItem?skuId= 获取已经选中的商品当前的数量及状态 -
配置了拦截器要放到MVCConfig里面去regist才能生效。
注意:posthandler需要dispatchServelet渲染ModelAndView在返回的时候才生效,因此在返回RestController的时候就不会进行处理,因此setCookie要在pre放行之前就做了,不然没用。
@Configuration public class MyWebMVCConfig implements WebMvcConfigurer { @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new CartInterceptor()).addPathPatterns("/**"); } }
2022.7.23
-
docker启动rabbitmq
docker run -d --hostname rabbitmq --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.10-management -
springboot集成RabbitMQ
1. 导入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> 2. 配置 rabbitmq: host: 43.152.118.35 port: 5672 virtual-host: / 3. 开启注解 @EnableRabbit -
order服务使用feign调用cart服务失败的原因
浏览器请求服务的时候会携带cookie,其中包含了认证信息,但是通过feign调用的时候,feign会新建一个request,里面默认是没有任何请求头和cookie的,因此cart拿不到信息就会默认没有登陆,因此就看不到cart服务内相关的信息。解决方案是加上一个feign的远程调用拦截器,在拦截器中加入当前服务的header,使得feign在调用之前就有header
-
异步任务服务调用失败的问题
原来main线程中的threadlocal中存放着request的请求头,在开启异步线程的时候由于线程池中的线程是新的,不包含主线程的head,因此在异步调用的时候就拿不到cookie,因此需要在runAsync中引入主线程的head到子线程中去。
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes(); CompletableFuture<Void> addressFuture = CompletableFuture.runAsync(() -> { RequestContextHolder.setRequestAttributes(requestAttributes); List<RecInfo> receiveInfo = memberFeignService.getAddressInfo(memberResVo.getId()); settleVo.setAddressList(receiveInfo); }, executor); -
保证提交订单的幂等性(幂等性,即1到n次方都为1,具有幂等性的操作无论执行多少次都是同样的结果,在那些修改数据导致每次数据都不一样或者那些增删数据每次数据的数量都不一样的操作上需要幂等性)
// 防止重复提交 String token = UUID.randomUUID().toString().replace("-", ""); redisTemplate.opsForValue().set(USER_ORDER_TOKEN_PREFIX + memberResVo.getId(), token, 30, TimeUnit.MINUTES); settleVo.setOrderToken(token);采用了防重令牌(防止表单重复提交),每个订单有一个全局唯一的令牌存储在redis,当提交的时候会从redis中取出来并且验证,验证成功之后立刻删除redis的数据,保证幂等性。
而验证令牌和删除令牌的过程中要保证原子性,因此需要用到redissession,编写lua脚本保证redis的原子性。
2022.7.25
-
生成订单号用的是雪花算法
雪花算法: 64位ID:一位标志位 + 41位毫秒级时间 + 5位机器ID + 12位该毫秒内的计数 每秒可以生成的ID数量达到26万个 -
如果一个类有多种构造器的排列组合可选,就可以在该类上加一个@build注解,使用建造者模式来调用该构造器的链式构造方法,灵活传参。
WareOrderTaskDetailEntity taskDetailEntity = WareOrderTaskDetailEntity.builder() .skuId(skuId) .skuName("") .skuNum(hasStock.getNum()) .taskId(wareOrderTaskEntity.getId()) .wareId(wareId) .lockStatus(1) .build();避免写一大堆的setXX方法
-
从添加购物车到结算提交订货单的流程和注意事项
1. 购物车和商品是两个单独的类,商品要包含其价格,skuid,标题图片等,以及是否被选中、数量以及原总价;购物车包含商品信息,总数量,全部商品总价,商品有多少种类的信息。 2. 加车的过程中用户可能是没登陆,也可能登录,登录与否都是同一个人的话,要加上一个唯一标识,抽象成一个类,这个类的对象存在threadlocal里面,方便拦截器确认身份。身份信息抽象成一个session存在redis里面,设置过期时间。 3. 当用户从未登录转成登录的时候,从redis读取唯一标识,把它合并到以用户id作为标识的redis缓存里,threadlocal要更新信息。 4. 用户对商品的操作都存在redis里面,避免对数据库频繁CRUD 5. 查询商品信息和它对应的属性的时候可以异步查询,使用completablefutue,开启线程池来查询。 6. 在提交购物车进入结算页面的时候,要通过session的cookie确认已经登录,通过feign调用cart的服务查询订单的时候,注意要把当前的请求头中的赋值给异步操作的线程,再配置feignConfig,使得feign在代理的时候吧异步线程中的cookies读取到自己的请求头中,再去代理服务。 7. 为了防止订单重复提交,需要redis缓存一个具有唯一标识符订单号,在提交付款的时候,使用redis的原生原子操作来比对并删除缓存的订单号做到幂等提交 8.设置不同的订单状态,如果重复提交、扣减库存失败、价格计算错误都要使订单验证不通过 9. 提交订单时后台要顺序完成:使用雪花算法创建一个唯一订单号,查询调用cart服务购物车里面的所有信息,对每种物品都构建一个订单项数据。对每一个订单项,使用feign调用商品服务查询spu、sku、积分信息,算出skuprice*items=总金额。将订单项合并成订单。在提交之前还需要对价格进行一次确认,结算运费。 10. 对于创建完成的订单要进入到库存服务,查询当前库存并且尝试锁库存,查询各个仓库,尝试锁库存,如果锁成功了进行下一步,否则抛出全局异常。 11. 对于锁库存成功的订单,在订单服务里面的数据库创建一个对应的订单,然后将redis的购物车清空,进行到下一步支付的流程中。 12. 9-11都要在同一个事务中完成,一旦有一个环节抛出异常,则全体回滚。 -
本地事务的问题
1. 远程服务假失败 远程服务成功,但是由于网络问题没有返回 导致:订单回滚,但是库存扣减 2. 远程服务调用完成,其他方法出现问题 已经执行的远程请求,不会回滚所以要采用分布式事务,引起本地事务失败的最大原因就是网络问题
-
Seata的使用
Seata控制分布式事务 1)、每一个微服务必须创建undo_Log 2)、安装事务协调器:seate-server 3)、整合 1、导入依赖 2、解压并启动seata-server: registry.conf:注册中心配置 修改 registry : nacos 3、所有想要用到分布式事务的微服务使用seata DataSourceProxy 代理自己的数据源 4、每个微服务,都必须导入 registry.conf file.conf vgroup_mapping.{application.name}-fescar-server-group = "default" 5、启动测试分布式事务 6、给分布式大事务的入口标注@GlobalTransactional 7、每一个远程的小事务用@Trabsactional
2022.7.26
-
延时队列的实现
将消息经由一个普通路由到一个队列里,设置队列的最大过期时间,当超过这个最大时间之后,消息会被自动转发到预先设置好的死信交换机里面,然后交换机会将死信发送到相应的队列里面去,这一套流程就可以实现延时队列。 -
URI和URL的区别:URL = 请求的服务器名和端口(域名) + URI(路径名)
-
解锁订单属于内部调用,无需登录,因此在order拦截器上要加一个缺口
最后一章:秒杀业务文字描述
-
定时任务配置
1、在Spring中表达式是6位组成,不允许第七位的年份 2、在周几的的位置,1-7代表周一到周日 3、定时任务不该阻塞。默认是阻塞的 1)、可以让业务以异步的方式,自己提交到线程池 CompletableFuture.runAsync(() -> { },execute); 2)、支持定时任务线程池;设置 TaskSchedulingProperties spring.task.scheduling.pool.size: 5 3)、让定时任务异步执行 异步任务 解决:使用异步任务 + 定时任务来完成定时任务不阻塞的功能 -
Spring里面自带一个线程池,可以配置这个线程池,使用的时候直接autowired就可以。
-
首先要扫描最近三天要上架的商品,在流量小的时候上架,因此需要安排一个定时任务
private String endTime() { LocalDate now = LocalDate.now(); LocalDate plus = now.plusDays(2); LocalTime max = LocalTime.MAX; LocalDateTime end = LocalDateTime.of(plus, max); //格式化时间 String endFormat = end.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")); return endFormat; } 用上述代码格式化时间,对时间戳进行查询。 Listlist = this.baseMapper.selectList(new QueryWrapper () .between("start_time", startTime(), endTime())); 查询数据库的表达式 分布式系统上架的时候用redission来加一个分布式锁,每次只允许一台服务器上架,如果已经有指定的物品被上架了,就不执行相应的方法。这样就保证了上架商品的幂等性。
-
用redis缓存三天内参与秒杀的场次编号作为key, value是本场秒杀全部商品的随机码信息,便于上架对应的场次的商品;并且对每个需要上架的商品也要进行redis缓存,缓存的对象要包括秒杀场次的信息以及商品信息,以及限量信息等。缓存的时候,key要用随机码,避免相同商品出现在不同场次,在秒杀的时候修改多个信息。随机码在value中的某个属性也要存储,便于核对。
-
秒杀库存扣减方式初始化
//5、使用库存作为分布式Redisson信号量(限流) // 使用库存作为分布式信号量 RSemaphore semaphore = redissonClient.getSemaphore(SKU_STOCK_SEMAPHORE + token); // 商品可以秒杀的数量作为信号量 semaphore.trySetPermits(seckillSkuVo.getSeckillCount());semaphore类似于JUC中的Semaphore,限定总量,取还在总量内部则被许可
RSemaphore semaphore = redissonClient.getSemaphore("semaphore"); semaphore.trySetPermits(1);//设置许可 semaphore.acquire();//获得一个许可 semaphore.release();//释放一个许可其源码实现表明,在执行操作的时候是通过while死循环来反复执行创造,直到操作完成才继续,而低层是通过lua脚本来在redis里面执行原子操作。
semaphore的目的是限流,防止卖超。
-
秒杀系统应该关注的问题
-
服务单一职责,秒杀系统挂掉不要影响别的系统
-
秒杀链接加密,防止恶意攻击或者链接暴露(随机码机制)
-
库存预热,不要每次秒杀都去查数据库扣库存,使用semaphore控制进来秒杀的请求(把库存放在缓存里)
-
动静分类,动态请求才打到后端服务集群
-
流量削峰,将流量分布到更大的时间段,使用输入验证码或者加车+结算可以拖时间
-
限流熔断降级,前端限流+后端限流,限制次数或总量,快速失败降级运行,熔断隔离防止雪崩
-
队列削峰,所有秒杀成功的请求进入消息队列,慢慢创建订单,扣减库存等。
-
-
秒杀流程
- 获取threadlocal观察是否用户已经登录
- 获取redis中存储的场次+商品信息的hashmap
- 查hashmap,看看是否能够用key查到对应的物品
- 如果查到了,就用
SeckillSkuRedisTo redisTo = JSON.parseObject(skuInfoValue, SeckillSkuRedisTo.class);实例化对象 - 获取当前时间是否在秒杀区间内
- 检验传入的随机码是否和对象的随机码一致,并且检查skuId是否一致
- 调用redistemplate查看Semaphore的数据检验秒杀的物品数量是否有充足库存,以及其在库存和限制的范围内
- 查看用户是否已经下过单了,如果没下过单,记录其秒杀的细节、如时间价格数量商品信息
- 尝试扣减Semaphore,如果成功了则创建订单信息发送到消息队列里面,包括订单号、秒杀场次、数量、价格、商品信息等,等待订单服务处理。
- 秒杀完成,订单服务监听消息队列,根据SeckillOrderTo创建订单,走之前的流程,保存订单和订单项,因为秒杀一次只能秒一个sku,所以订单和订单项都只要一个item。
不同的微服务可以共用一个消息队列,哪怕消息队列不是在本服务定义的也可以
-
熔断降级的异同点 (具体看八股,面试只说秒杀用了,不主动去提)
相同点: 1. 保证集群大部分服务的可用性和可靠性,防止崩溃,牺牲小我 2. 用户最终都是体验到某个功能不可用 不同点: 1. 熔断是被调用方故障,触发系统的主动规则 2. 降级是基于全局考虑,停止一些正常服务,释放资源,减小服务器压力,就比如秒杀的时候查数据库太慢了,就让服务返回redis缓存的数据,而不走后端。