spring boot集成mongodb 分片解决大数据存储问题
由于项目中涉及到某张表存在超额大数据记录集成分片过程:
- 项目结构:
-
spring boot ---2.1.0.RELEASE
-
mongodb-plus-spring-boot-starter
-
- mongodb版本:3.0.6
首先下载Mongodb 这边使用的是windows版的,liunx版本网上有很多怎么分片配置,先把文件包拷贝几份
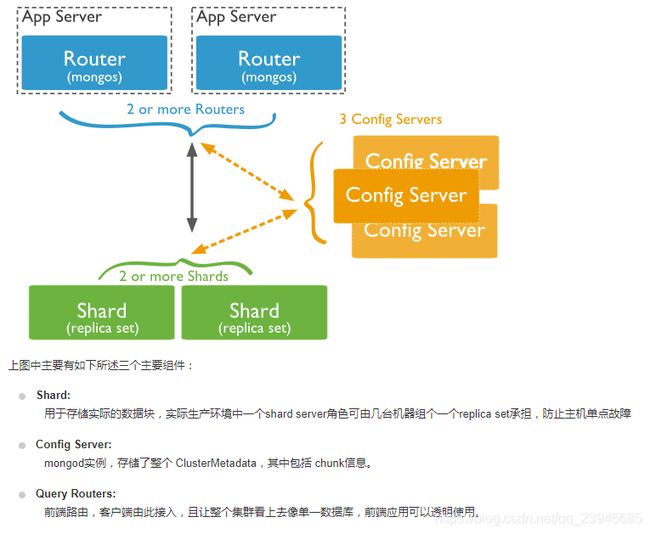
原理基本看图就能明白
具体实现:
- config.bat:
%cd%\mongodb-3.0.6-config\bin\mongod --dbpath=%cd%\mongodb-3.0.6-config\bin\datas\data --logpath=%cd%\mongodb-3.0.6-config\bin\datas\log\mongo.log --port 2222
pause- mongos.bat(configdb 配置为config配置):
%cd%\mongodb-3.0.6-mongos\bin\mongos --port 1111 --configdb 127.0.0.1:2222
pause其他shard均参照config.bat (shard1->127.0.0.1:3333,shard2->127.0.0.1:4444,shard3->127.0.0.1:5555)
先启动除mongos的mongdb,最后启动mongos
- cmd进入mongos的/bin目录-------
mongo 127.0.0.1:1111/admin- 连接上mongos
- 添加分片
依次将shard2,shard3添加进mongosdb.runCommand({addshard:"127.0.0.1:3333",allowLocal:true}) - 开启数据库分片
db.runCommand({"enablesharding","需要分片的数据库名"}) - 设置片键
片键是分片的关键,有范围分片,hashed分片(随机的分配),组合分片(组合分片是比较好的一种分片的选择,好的组合分片可以同时解决热点和随机读IO问题),标签分片(比如对于一些日志非查询文档,可以通过标签将其只插入到某个分片中)
这里选用的是组合分片
db.runCommand({"shardcollection":"xx数据库.xx数据表","key":{"字段":1,"字段":1}})至此已经完成全部的配置-----查看配置状态db.printShardingStatus()
- spring boot配置
- 我这里用的plus,可以在yml中配置连接数据,若用的spring-data-mongo可以忽略
-
spring: #数据库配置 data: mongodb: uri: mongodb://127.0.0.1:1111/ruian 这里配置的是mongos路由的路径就可以实现分片了 option: min-connection-per-host: 0 max-connection-per-host: 20000 threads-allowed-to-block-for-connection-multiplier: 20 server-selection-timeout: 30000 max-wait-time: 120000 max-connection-idle-time: 0 max-connection-life-time: 0 connect-timeout: 10000 socket-timeout: 0 socket-keep-alive: false ssl-enabled: false ssl-invalid-host-name-allowed: false always-use-m-beans: false heartbeat-socket-timeout: 20000 heartbeat-connect-timeout: 20000 min-heartbeat-frequency: 500 heartbeat-frequency: 10000 local-threshold: 15再代码中循环插入数据,在分片表中就可以看到实际效果
- 配置中遇到的坑:
在添加片的时候,如果mongodb里面存在数据库则会出现添加失败
启动mongs路由的时候会出现 I SHARDING [Balancer] distributed lock 'balancer/PC
201611240804:1111:1557995632:41' unlocked.暂时不知道原因,但是不影响使用
所有分片的集合在片键上都必须建索引,这是MongoDB自动执行的,所以如果选择某个字段作为片键但是基本不在这个字段做查询那么等于浪费了一个索引,而增加一个索引总是会使得插入操作变慢。
唯一索引问题 如果集群在_id上进行了分片,则无法再在其他字段上建立唯一索引
哈希索引支持使用任何单个字段包括内嵌文档,但是不能使用复合的字段,因此创建哈希索引的时候也只能指定一个字段
小基数片键:如果某个片键一共只有N个值,那最多只能有N个数据块,也最多只有个N个分片。则随着数据量的增大会出现非常大的但不可分割的chunk。如果打算使用小基数片键的原因是需要在那个字段上进行大量的查询,请使用组合片键,并确保第二个字段有非常多的不同值。
递增的片键:使用递增的分片的好处是数据的“局部性”,使得将最新产生的数据放在一起,对于大部分应用来说访问新的数据比访问老的数据更频繁,这就使得被访问的数据尽快能的都放在内存中,提升读的性能。这类的片键比如时间戳、日期、ObjectId、自增的主键(比如从sqlserver中导入的数据)。但是这样会导致新的文档总是被插入到“最后”一个分片(块)上去,这种片键创造了一个单一且不可分散的热点,不具有写分散性。
随机片键:随机片键(比如MD5)最终会使数据块均匀分布在各个分片上,一般观点会以为这是一个很好的选择,解决了递增片键不具有写分散的问题,但是正因为是随机性会导致每次读取都可能访问不同的块,导致不断将数据从硬盘读到内存中,磁盘IO通常会很慢。
组合片键:一个理想的片键是同时拥有递增片键和随即片键的优点,这点很难做到关键是要理解自己的数据然后做出平衡。
片键一旦生成就无法修改,创建需谨慎。