搞懂高可用:MySQL 双主复制,为啥不建议用?
背景
playbook工具集 dbops 支持以下系统或架构下部署 MySQL,有人好奇,为什么不支持 master-master 架构呢?

因为master-master 不是我认可的一种生产使用级别数据库架构,所以我不打算制作它。如果你依然想部署 master-master 架构,很简单,你只需要使用两台机器利用 dbops 部署 master-slave 架构后,手动建立反向复制链路即可,简单地说,就是在从库上执行一个 change master to 到主库的语句。
为什么会有双主这种架构?
大体上双主架构方案有两种玩法:
-
双主单写
-
双主双写
1. 双主单写(相对推荐)
首先,我要介绍的是双主单写,这是许多人选择双主方案的常见玩法。虽然单写,主从复制只有一端会进行写操作,但为什么还要建立双向复制呢?这是因为它简单且方便!
很多采用双主单写方案的人实际上是使用一种称为”keepalived + 双主”的技术方案,其中 keepalived 软件会持续检测两端的 mysqld 是否存活。如果挂载了虚拟 IP(VIP)的那个主服务器出现故障,keepalived 会将 VIP 转移到另一个主服务器上。应用程序通过 VIP 连接数据库,从而保证了单点写入。在底层,双向复制始终保持开启,这样在 VIP 进行切换时,无需考虑主从切换,数据始终保持双向复制,保证数据一致。

实际上,”keepalived + 双主”和”keepalived + 主从”的架构差异并不明显。如果你能确保在”双主”架构中只允许单点写入,这种架构和”keepalived + 主从”一样,是完全没有问题的。然而,”双主”架构的特性,也就是从库同时也是主库这一件事,可能带来一些问题。比如:
-
主从角色判断问题。我的备份脚本通过 show slave status 命令来判断哪个是从库,只在从库上进行备份。现在的情况是,两个节点的 show slave status 都有输出,导致两个节点都被备份。这就需要我重构备份脚本,加入判断哪个节点持有 VIP 的逻辑来辅助判断,只备份非 VIP 节点。这只是个注意事项,不算大问题。
-
备库有误操作写入脏数据风险。在进行运维操作时,如果登录到备库,需要特别小心。虽然可以设置 super_read_only 来防止误操作写入数据库,但如果 super_read_only 出于某种原因被关闭了,就可能误写入数据,并且这些数据还会复制到当前的主库。这种问题在主从架构中不会发生。你可能认为这种误操作不太可能发生,但我的经验告诉我,只要存在可能,就必然发生。因此,我并不推荐使用主主复制,主从复制已经足够满足需求。
-
脑裂发生后数据处理雪上加霜。在”keepalived + 主从”架构或其他主从架构如 MHA 中,我们通常会在故障转移后调用脚本,断开主从复制链接,万一发生脑裂,两个数据库会成为独立的分区,不会相互同步数据。而在”keepalived + 双主”架构中,我们通常不会处理双向复制链路。如果在脑裂后网络恢复,两个数据库的数据会互相同步,导致数据混乱和丢失。脑裂后的数据恢复本身就已经十分困难,现在情况变得更糟糕。
2.双主双写
双主双写的架构,应用配置 round-robin-with-fallback 的 jdbc 连接,简单地说,就是应用程序配置能检测 failover 基于轮询的负载均衡访问策略,两个 master 都会写入,这称之为写入扩展,每台分担一半的读写流量。
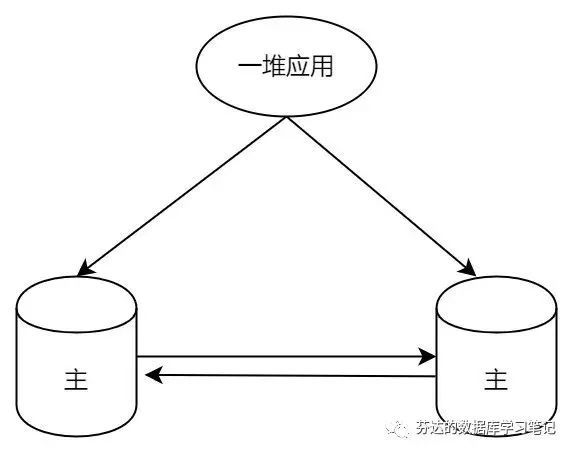
这简直是灾难!这完美地命中了双主双写方案“更新丢失”的坑!
在单机 MySQL 架构中,当我们需要更新一行数据时,系统会为该行加上 X 锁,以防止其他事务对其进行修改。这时,任何尝试修改该行的其他事务都将被阻塞,直到当前事务释放锁。
然而,在双主架构中,两个主节点是独立运作的。每个节点的 MySQL 实例只能管理和控制自己的锁,它们不能感知或者干预对方的锁状态。这意味着当两个节点同时尝试更新同一行数据时,它们可能会各自在本地实例中成功地加上 X 锁并进行更新,无视对方可能正在进行的同样的操作。这就可能引发数据不一致的问题。
假设我们有两个主节点,左节点和右节点。如果左节点试图更新一行数据,它会在自己的 MySQL 实例中为该行加上 X 锁。而右节点对此一无所知,所以如果它此时也试图更新同一行数据,会在自己的 MySQL 实例中加上 X 锁,而不会遇到任何阻塞。之后,左节点和右节点都可以正常地完成更新和提交操作。
然而,问题在于,这一行最终会被更新成什么值呢?这是未知的。因为两个节点都完成了各自的更新操作,但通过主从复制到另外一个节点后结果可能会不一致,这个和更新操作的先后顺序,网络的快慢都有关系。举个例子,如果我们的数据只有一列,那么最终的状态可能会有四种不同的情况。
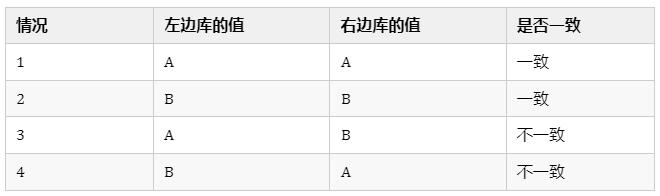
双主双写的架构方案就完全不能用吗,如何解决呢?
解决办法 1: 隔开自增键,按行写入(不推荐)
有人认为两个主库设置不一样的自增键可以解决:
auto_increment_offset = 1 # 主库为1,从库为2auto_increment_increment = 3 # 自增步长
这种方法确实可以解决插入表数据时的冲突问题,但我之前提到的更新丢失问题它并不能解决。难道我们的数据库永远不需要执行 update 操作吗?
可能有人会问,为什么在 MGR (MySQL Group Replication) 多主架构中,这个问题似乎不存在呢?这是因为 MGR 是官方发布的分布式集群系统,它是集群的概念。当提交数据时,所有节点会进行冲突检测和共识达成过程。每个节点都会对修改进行校验,然后达成共识,选择多数节点认可的值进行提交,而回滚掉少数节点认为的值。这样,通过多数派决策,MGR 能够保证数据的一致性。
问题还不止于此,如果在双主中的左节点做 DML 操作的同时,右节点做 DDL 也会有问题。因为他没有办法利用到 MySQL 的元数据锁来防止表结构被变更。这个问题连 MGR 多主模式也没有解决,这也是很多人也不建议 MGR 多主模式的原因。
解决办法 2: 按表或按库写入(相对推荐)
左边的 master 只写某些表,右边的 master 只写另外的那些表。当然了这也说明了左边的某些表和右边的那些表是完全没有业务关联的,不需要做 join 操作的,那为何不拆为库呢?这样对应用程序的设置会更友善。
那如果都分开库了,那为什么不直接拆实例呢?拆分为 3306、3306 实例,例如如下架构:图片拆实例后,多实例混合部署,两个实例的主库可以各放在一台主机上,这就完美实现了资源的高效使用,同时新增了新的优点,就是实例变更可以不影响另外一个实例。例如 3306 实例要做变更,需要停库操作,那么 3307 实例是可以不停库的。真香啊!
所以,使用双主双写方案也是完全没有道理啊。
双活架构,由于复杂性,可能有一些方案会考虑跨机房之间的异步复制采用双向同步复制方案,只要规避好坑,严格地单元化拆分业务,我觉得可以接受。不在这篇文章讨论范围,我们只讨论本地高可用。
二、双主复制有可能导致复制回环
1.部署回环架构
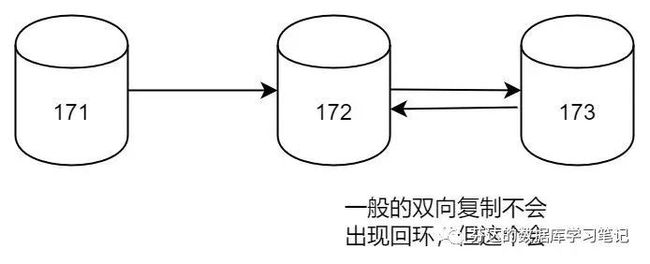
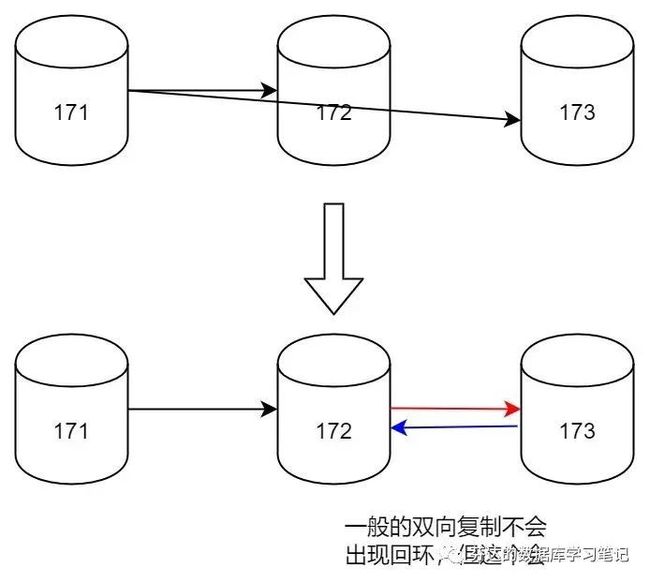
下面,我将使用 dbops 部署这个有坑的架构,并且模拟它如何出现复制回环,架构图如下(箭头方向代表数据流向):
实验步骤(不感兴趣的,可以快速跳过,直接看结论):
[root@192-168-199-175 playbooks]# pwd/usr/local/dbops/mysql_ansible/playbooks# vi ../inventory/hosts.ini[dbops_mysql]192.168.199.171 ansible_user=root ansible_ssh_pass="'gta@2015'"192.168.199.172 ansible_user=root ansible_ssh_pass="'gta@2015'"192.168.199.173 ansible_user=root ansible_ssh_pass="'gta@2015'"[root@192-168-199-175 playbooks]# vi vars/var_master_slave.yml# vars loading order: common_config -> this filemaster_ip: 192.168.199.171slave_ips:- 192.168.199.172- 192.168.199.173sub_nets: 1%[root@192-168-199-175 playbooks]# ansible-playbook master_slave.yml# playbook会做一些校验通过后,要求您确认信息是否正确,然后你手工输入"confirm"后正式运行
使用 dbops 快速部署好生产级别的一主两从。
如下图,上面部分是目前部署出来的一主两从,需要修改为下面的架构,需要执行两次 change master to 语句即可。
首先,我需要在 dbops server 上查看复制账号的账号名和密码
# 在dbops server上查看复制账号的账号名和密码[root@192-168-199-175 playbooks]# cat common_config.yml |grep rplemysql_rple_user: replmysql_rple_password: Repl@8888
然后,我登录 172 服务器,执行 change master to 173,让 173 是主,172 是从,建立图中蓝色箭头的数据流向。
[root@192-168-199-172 ~]# su mysql[root@192-168-199-172 ~]# db3306 # dbops的默认设定,提供的管理员免密快捷登录数据库的方式mysql> CHANGE MASTER TO MASTER_HOST='192.168.199.173', MASTER_PORT=3306, MASTER_USER='repl', MASTER_PASSWORD='Repl@8888', MASTER_AUTO_POSITION=1 for channel 'master173';mysql> start slave;
由于 172 既是 171 的从,也是 173 的从,是一种多源复制的架构,所以 change master to 时要指定一个 channel 名,以区分两个复制链路。
接着,我使用相同的方法,登录 173,执行 change master to 172,让 172 是主,173 是从,建立图中红色箭头的数据流向。
# su mysql# db3306 # dbops的默认设定,提供的管理员免密快捷登录数据库的方式mysql> stop slave;mysql> CHANGE MASTER TO MASTER_HOST='192.168.199.172', MASTER_PORT=3306, MASTER_USER='repl', MASTER_PASSWORD='Repl@8888', MASTER_AUTO_POSITION=1;mysql> start slave;
2.验证回环
架构我们部署好了,现在我们来模拟和验证复制回环。
现在 172 上,停掉它回放 173 的 sql 线程,让他只拷贝 binlog 但不回放 SQL。
mysql> stop slave sql_thread for channel 'master173';登录 171,建个 fander 库。
[root@192-168-199-171 ~]# su mysql[root@192-168-199-171 ~]# db3306 # dbops的默认设定,提供的管理员免密快捷登录数据库的方式mysql> create database fander;
登录 172 和 173,都能看到 fander 库同步过来的。
mysql> show databases;+--------------------+| Database |+--------------------+| fander || information_schema || mysql || performance_schema || sys |+--------------------+5 rows in set (0.00 sec)
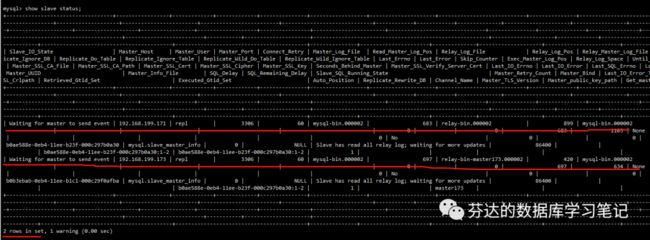
我们查看 172 上回放 173 方向同步过来的 relay log,能发现他确实把 create database fander 语句又回环过来了。GTID 编号为 ‘b0ae588e-0eb4-11ee-b23f-000c297b0a30:3’。
# 172[mysql@192-168-199-172 3306]$ pwd/database/mysql/log/relaylog/3306[mysql@192-168-199-172 3306]$ lltotal 24-rw-r----- 1 mysql mysql 204 Jun 19 23:20 relay-bin.000001-rw-r----- 1 mysql mysql 1090 Jun 19 23:53 relay-bin.000002-rw-r----- 1 mysql mysql 102 Jun 19 23:20 relay-bin.index-rw-r----- 1 mysql mysql 214 Jun 19 23:47 relay-bin-master173.000001-rw-r----- 1 mysql mysql 618 Jun 19 23:53 relay-bin-master173.000002-rw-r----- 1 mysql mysql 122 Jun 19 23:47 relay-bin-master173.index[mysql@192-168-199-172 3306]$ mysqlbinlog -vvv relay-bin-master173.000002 |grep fander#git编号: 'b0ae588e-0eb4-11ee-b23f-000c297b0a30:3'create database fander
请问这个 GTID ‘b0ae588e-0eb4-11ee-b23f-000c297b0a30:3’ 会重复应用,导致复制报错吗?
答案是不会。因为 GTID 的原理是, 他不会执行他标记已经执行过的 GTID,’b0ae588e-0eb4-11ee-b23f-000c297b0a30:3’ 在我启动 sql_thread for channel ‘master173’ 之前就已经标记执行过了,所以这个回环过来的 SQL 是不会执行的。
但如果我不是 GTID 模式的复制而是传统复制呢?那就会执行了!由于 database fander 已经存在,所以重复执行的结果就是复制报错,或者数据不一致了。
虽然在 GTID 模式下,不会重复执行 SQL,但存在一个问题,那就是回环问题。这导致了一些本不应该传输的 binlog 重复传输,使得网络流量翻倍。这是为什么呢?
3.出现回环的原因
要理解这个问题,我们需要先了解 MySQL 是如何防止复制回环的。其实,防止复制回环主要靠的是每个 MySQL 服务器都有的一个唯一的 server_id。在复制过程中,每个二进制日志事件都被标记为产生该事件的 server_id。当复制服务器接收到新的二进制日志事件时,它会检查该事件的 server_id。如果 server_id 与复制服务器自身的 server_id 相同,那么复制服务器就知道这个事件是它自己生成的,因此会忽略它,不会拷贝它。就是通过这种方式,MySQL 成功地防止了复制回环的发生。
在本案例中,我们有三个 MySQL 服务器,假设他们的 server_id 分别为 171、172、173。
当服务器 171 生成了一个二进制日志事件(binlog event),这个事件被标记为 server_id 为 171。然后,这个事件被复制到了服务器 172,因为服务器 172 的 server_id 与事件的 server_id 不同,所以它接受了这个事件。然后,服务器 172 将这个事件传递给了服务器 173,服务器 173 也接受了这个事件,因为它的 server_id 与事件的 server_id 不同。
然而,问题出现在当服务器 173 将这个事件再传回给服务器 172 时。服务器 172 看到这个事件的 server_id 还是 171,与它自己的 server_id 依然不同,所以它依然会接受这个事件。好在我们使用了 GTID 模式,服务器 172 虽然拷贝了 binlog 过来,但会知道它已经应用过这个事件,因此它不会再次应用这个事件,从而避免了可能的数据不一致问题。所以,虽然事件被多次传输,但是使用 GTID 可以防止事件被多次应用,从而避免了数据不一致问题。