【Linux】缓冲区及重定向相关概念
目录
前言
一、缓冲区
1、什么是缓冲区
2、为什么要有缓冲区
3、缓冲区在哪里
4、关于缓冲区的认识
5、缓冲区的模拟实现
二、重定向的模拟实现
完整代码
总结
前言
作为C/C++程序员,我们经常能够看到缓冲区的概念,那么什么是缓冲区及缓冲区在哪里的问题困扰了我们很长时间,下面介绍缓冲区及重定向的相关概念
一、缓冲区
1、什么是缓冲区
所谓的缓冲区通俗一点解释就是一块内存空间,但是这块空间由谁来提供?
用户?操作系统?C标准库?
这里我们按下不表,等到下面验证缓冲区在哪里这个问题时说明
2、为什么要有缓冲区
操作系统对于文件的写入是有两种模式可以参考的
1、写透模式WT
2、写回模式WB
这两种模式所带来的代价是不一样的。我们举一个小例子
假如你要将你的书送给偏远山区的小朋友,你可能会亲自到偏远山区将书送给小朋友。
这种操作的成本较高,也比较慢——这就是所谓的写透模式,系统接口将数据亲自刷新到磁盘
你还有一种选择,你可以将书放到邮局,通过快递的方式将书本送给小朋友,这种操作快速,成本极低,你只要送到邮局就可以了——这种模式叫做写回模式。
我们操作系统所采用的模式就是写回模式,这里的邮局就是缓冲区。假如你调用系统接口write写一些数据到文件,你只要写入到缓冲区就可以返回了,这样可以提高整机的效率,不过最主要的是为了提高用户的响应速度。
那么我们知道了为什么要有缓冲区,那么缓冲区的刷新策略是什么呢?
我们还是参考邮局的例子,现实生活中邮局发送快递的策略无非就三种
1、有一个就发送一个
2、等到某一货架摆满就发送
3、等仓库摆满发送
这三种正好对应我们的缓冲区的刷新策略
在正常情况下缓冲区的刷新策略为:
1、立即刷新
2、行刷新(遇到'\n'就将'\n'及之前的数据全部刷新)
3、满刷新(全缓冲,等到缓冲区满了再刷新)
不过也有特殊情况
1、用户强制刷新(ffush)
2、进程退出
所以缓冲区的刷新策略是由一般情况 + 特殊情况 构成
3、缓冲区在哪里
在说明缓冲区在哪里之前,我们先来看一个例子
#include
#include
#include
int main()
{
//C语言提供的接口
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
const char* s1 = "hello fputs\n";
fputs(s1, stdout);
//OS提供的接口
const char* s2 = "hello write\n";
write(1, s2, strlen(s2));
return 0;
} 这就是一个最普通的使用C标准库和系统接口打印字符串到显示器的代码
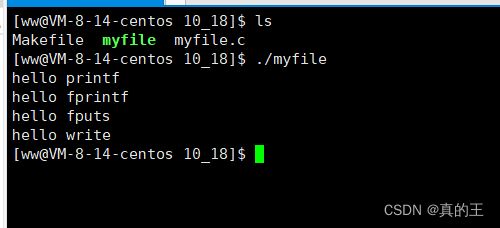
我们发现他没有什么稀奇的,然后我们将打印的内容输出重定向到log.txt这个文件中
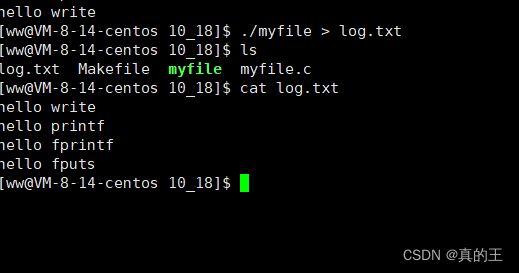
这也没有什么问题,跟我们预想的一样,但是如果我们在原本代码的基础上,在最后一行添加fork()之后呢?它会出现什么现象呢?

我们发现现象与不加fork一样,那么我们输出重定向到log.txt中呢?
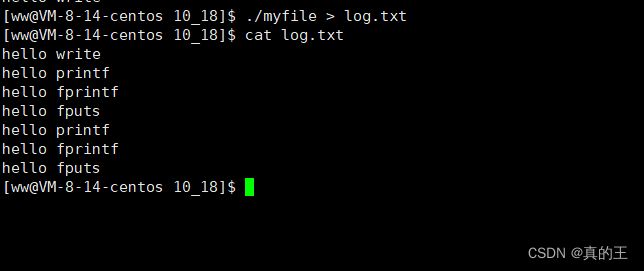
奇怪的事情发生了,好像log.txt中的内容与我们之前想象的不同
我们仔细观察log.txt中的内容,所有的C语言接口都打印了两次,而系统调用只打印了一次
也就是说fork之后,在显示器上无论是系统调用还是C接口都只打印一次,而输出重定向到文件中,C接口打印了两次,系统调用打印了一次
这个现象特别的奇怪,但是要解决这个问题还需要我们别的知识。
4、关于缓冲区的认识
我们所常见的行缓冲的设备文件:显示器
全缓冲设备文件:磁盘文件
虽然不同的外设可能缓冲区的刷新策略不同,但是它们都倾向于全缓冲
缓冲区满了才刷新,这样就需要更少次的I/O操作,更少次的外设访问,从而能够提高效率
因为和外部设备I/O的时候,数据量的大小不是主要矛盾,和外设预备I/O的过程是最耗费时间的。
因为根据冯诺依曼架构,CPU的运算速度是非常快的,外设的速度是非常慢的,因此所有的外设倾向于全缓冲。
而出现的其它刷新策略是结合具体情况所做的妥协
例如为什么显示器是行缓冲?
如果显示器是全缓冲,那么只有将显示器的缓冲区全部写满才会刷新,我们才能够从显示器上看到信息,这个过程是缓慢的,显示器是要给用户去看的,它一方面要照顾效率,一方面要照顾用户体验,而人习惯于一行一行的读取信息,所以显示器是行刷新,但是在极端情况我们可以自定义规则。正如我们前面写过的进度条,因为没有了'\n'就需要我们每次手动刷新缓冲区。
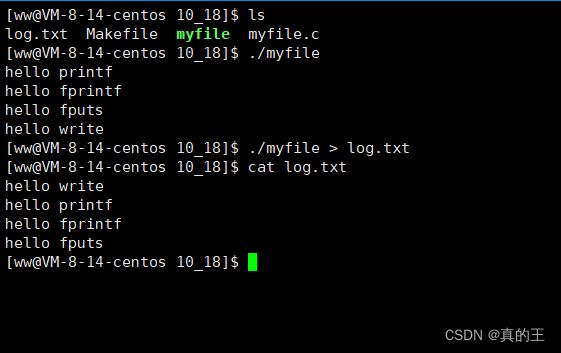
这时我们在回到之前的例子,同一个程序,向显示器打印输出4行文本,向普通文件(磁盘上)打印的时候就变成了7行。
我们可以确认的一点是打印的相关代码以及执行完毕,并且代码只执行了一次。
但是函数已经执行完了,并不代表数据已经刷新了,出现了两次一定是有人拷贝了一份。缓冲区的数据也是进程的数据。
曾经我们所谈的缓冲区一定不是OS所提供的,如果是OS所提供的,那么我们上面的代码,打印出的现象应该是一样的。
所以缓冲区是C标准库所提供的。
并且因为显示器是行刷新策略,我们前面打印的所有字符串都带有'\n',所以在打印时缓冲区就已经刷新了,fork之后父子缓冲区内部都是空的所以不会发生写时拷贝。
而重定向到普通文件时,因为普通文件的刷新策略是全刷新,所以fork之后,父子的缓冲区是相同的并且都有数据,而当父进程结束时,它会刷新它的缓冲区,这时就构成了父子进程数据的写时拷贝,这就出现了两份数据,因为父进程退出,刷新缓冲区,将缓冲区的内容刷新到文件中,子进程退出也刷新缓冲区将缓冲区的内容刷新到与父进程相同的文件中,所以log.txt中C接口就会打印两遍,而write是系统接口,并没有缓冲区的概念,所以只打印一次。
我们前面所说的缓冲区都是用户级缓冲区,既然有用户级缓冲区,那么必然也会有内核级缓冲区。
内核级缓冲区我们就先不谈。
我们再回顾一下调用过程
假如有一个进程调用fputs,那么它就会将数据写到C标准库中的缓冲区中,fputs函数写到缓冲区就返回了。这个过程与其说是写入操作倒不如说是拷贝操作。写入到C标准库中的缓冲区之后,C标准库会定期调用write系统接口将C标准库中的缓冲区定期写到OS中,我们可以不用关心什么时候写什么时候刷新,并且这个刷新是刷入到内核缓冲区,并没有刷新到磁盘中,OS再定期刷新到磁盘中。而如果我们调用系统接口write,就没有用户级缓冲区的概念了,直接写到内核缓冲区中,并且不会发生写时拷贝。
而我们只要稍微变动一下上面的代码,输出重定向时就不会出现上述情况了
那么C标准库给我们提供的用户级缓冲区到底在哪里?
我们在C语言中打开文件fopen会返回FILE类型的指针
我们前面说过FILE是一个结构体,它内部封装了fd,并且包含了该文件fd所对应的缓冲区结构
5、缓冲区的模拟实现
既然说了这么长时间的缓冲区,那么我们简单的模拟实现一下
我们前面说过缓冲区在FILE结构体中,并且它是一块空间,FILE结构体中还会有fd
所以我们现在只知道这么多,我们也暂时实现这么多
#define NUM 1024
struct MyFILE_
{
int fd;//文件标识符
char buffer[NUM];//缓冲区
int end;//缓冲区结尾
};
typedef struct MyFILE_ MyFILE; 接下来是实现fopen函数,我们定义了一个fopen_的函数,并且我们只要封装一下系统接口open就能够实现
MyFILE* fopen_(const char* pathname, const char* mode)
{
} 参数与返回值全部参考fopen
MyFILE* fopen_(const char* pathname, const char* mode)
{
assert(pathname);
assert(mode);
MyFILE* fp = NULL;
} 这是基本框架,我们要对每一个参数进行合法性检验,因为要打开一个文件就需要我们手动的创建一个MyFILE结构体。
接下来的工作就是分析我们传入的选项,mode
MyFILE* fopen_(const char* pathname, const char* mode)
{
assert(pathname);
assert(mode);
MyFILE* fp = NULL;
if(strcmp(mode, "r") == 0)
{
}
else if(strcmp(mode, "r+") == 0)
{
}
else if(strcmp(mode, "w") == 0)
{
}
else if(strcmp(mode, "w+") == 0)
{
}
else if(strcmp(mode, "a") == 0)
{
}
else if(strcmp(mode, "a+") == 0)
{
}
else
{
//传参错误
}
}
我们就以w方式举例子,因为其它选项与w类似
MyFILE* fopen_(const char* pathname, const char* mode)
{
assert(pathname);
assert(mode);
MyFILE* fp = NULL;
if(strcmp(mode, "r") == 0)
{
}
else if(strcmp(mode, "r+") == 0)
{
}
else if(strcmp(mode, "w") == 0)
{
umask(0);
int fd = open(pathname, O_CREAT | O_TRUNC | O_WRONLY, 0666);
if(fd >= 0)//打开成功
{
fp = (MyFILE*)malloc(sizeof(MyFILE));
memset(fp, 0, sizeof(MyFILE));
fp->fd = fd;
}
}
else if(strcmp(mode, "w+") == 0)
{
}
else if(strcmp(mode, "a") == 0)
{
}
else if(strcmp(mode, "a+") == 0)
{
}
else
{
//传参错误
}
return fp;
}
这就是最基本的fopen的简单实现
接下来是fputs函数的模拟实现,它的本质就是封装了系统调用write
void fptus_(const char* message, MyFILE* fp)
{
assert(message);
assert(fp);
strcpy(fp->buffer + fp->end, message);
fp->end += strlen(message);
if(fp->fd == 0)
{
}
else if(fp->fd == 1)
{
}
else if(fp->fd == 2)
{
}
else
{
//其他文件
}
} 这是fputs的基本框架,我们还是实现1,stdout
void fptus_(const char* message, MyFILE* fp)
{
assert(message);
assert(fp);
strcpy(fp->buffer + fp->end, message);
fp->end += strlen(message);
if(fp->fd == 0)
{
}
else if(fp->fd == 1)
{
//行刷新
if(fp->buffer[fp->end-1] == '\n')
{
write(fp->fd, fp->buffer, fp->end);
fp->end = 0;
}
}
else if(fp->fd == 2)
{
}
else
{
//其他文件
}
} 接下来是fflush的模拟实现,他就是将数据强制刷新
void fflush_(MyFILE* fp)
{
assert(fp);
if(fp->end != 0)
{
write(fp->fd, fp->buffer, fp->end);
syncfs(fp->fd);
fp->end = 0;
}
} 刷新缓冲区就是将buffer中的数据写入到文件中,如果不使用syncfs就只是把数据写入到内核中
使用了syncfs就是将数据写入到磁盘中。
最后一个就是fclose
void fclose_(MyFILE* fp)
{
assert(fp);
//关闭文件之前,先刷新缓冲区
fflush_(fp);
close(fp->fd);//关闭文件
free(fp);//手动释放fp结构体
} 完整代码
#include
#include
#include
#include
#include
#include
#include
#include
#define NUM 1024
struct MyFILE_
{
int fd;//文件标识符
char buffer[NUM];//缓冲区
int end;//缓冲区结尾
};
typedef struct MyFILE_ MyFILE;
MyFILE* fopen_(const char* pathname, const char* mode)
{
assert(pathname);
assert(mode);
MyFILE* fp = NULL;
if(strcmp(mode, "r") == 0)
{
}
else if(strcmp(mode, "r+") == 0)
{
}
else if(strcmp(mode, "w") == 0)
{
umask(0);
int fd = open(pathname, O_CREAT | O_TRUNC | O_WRONLY, 0666);
if(fd >= 0)//打开成功
{
fp = (MyFILE*)malloc(sizeof(MyFILE));
memset(fp, 0, sizeof(MyFILE));
fp->fd = fd;
}
}
else if(strcmp(mode, "w+") == 0)
{
}
else if(strcmp(mode, "a") == 0)
{
}
else if(strcmp(mode, "a+") == 0)
{
}
else
{
//传参错误
}
return fp;
}
void fputs_(const char* message, MyFILE* fp)
{
assert(message);
assert(fp);
strcpy(fp->buffer + fp->end, message);
fp->end += strlen(message);
if(fp->fd == 0)
{
}
else if(fp->fd == 1)
{
//行刷新
if(fp->buffer[fp->end-1] == '\n')
{
write(fp->fd, fp->buffer, fp->end);
fp->end = 0;
}
}
else if(fp->fd == 2)
{
}
else
{
//其他文件
}
}
void fflush_(MyFILE* fp)
{
assert(fp);
if(fp->end != 0)
{
write(fp->fd, fp->buffer, fp->end);
syncfs(fp->fd);
fp->end = 0;
}
}
void fclose_(MyFILE* fp)
{
assert(fp);
//关闭文件之前,先刷新缓冲区
fflush_(fp);
close(fp->fd);//关闭文件
free(fp);//手动释放fp结构体
}
int main()
{
MyFILE* fp = fopen_("./log.txt", "w");
if(fp == NULL)
{
printf("open file fail\n");
return 1;
}
fputs_("hello world", fp);
fork();
return 0;
}
二、重定向的模拟实现
我们前面实现了minishell,但是它没有实现重定向,今天我们给它加上重定向功能
所谓重定向原理,我们前面已经说明过了,就是通过调整系统为每一个进程打开的三个文件stdin,stdout,stderr所对应下标的内容
这里使用dup2接口来实现。
我们所熟知的重定向无非就三种例如
cat < log.txt 输入重定向
ls -als > log.txt 输出重定向
ls -als >> log.txt 追加重定向
我们首先要做的就是将命令与重定向的文件及重定向命令分离
我们可以写一个Checkdir函数来分离上述字符串,并且确定是哪种重定向方式
char* CheckRedir(char* start)
{
assert(start);
char* end = start + strlen(start) - 1;
while(end >= start)
{
if(*end == '>')
{
if(*(end - 1) == '>')
{
redir_status = APPEND_REDIR;
*(end - 1) = '\0';
end++;
break;
}
redir_status = OUTPOT_REDIR;
*end = '\0';
end++;
break;
}
else if(*end == '<')
{
redir_status = INPUT_REDIR;
*end = '\0';
end++;
break;
}
else
{
end--;
}
}
if(end >= start)
{
return end;
}
return NULL;
}
接下来就是具体的重定向过程
int fd = -1;
switch(redir_status)
{
case INPUT_REDIR:
fd = open(sep, O_RDWR);
dup2(fd, 0);
break;
case OUTPOT_REDIR:
umask(0);
fd = open(sep, O_CREAT | O_TRUNC | O_WRONLY, 0666);
dup2(fd, 1);
break;
case APPEND_REDIR:
umask(0);
fd = open(sep, O_CREAT | O_APPEND | O_WRONLY, 0666);
dup2(fd, 1);
break;
case NONE_REDIR:
break;
default:
printf("bug?\n");
break;
完整代码
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define NUM 1024
#define SIZE 32
#define SEP " "
#define INPUT_REDIR 1
#define OUTPOT_REDIR 2
#define APPEND_REDIR 3
#define NONE_REDIR 0
int redir_status;
char cmd_line[NUM];
char *g_argv[SIZE];
char g_myval[32];
extern char** environ;
char* CheckRedir(char* start)
{
assert(start);
char* end = start + strlen(start) - 1;
while(end >= start)
{
if(*end == '>')
{
if(*(end - 1) == '>')
{
redir_status = APPEND_REDIR;
*(end - 1) = '\0';
end++;
break;
}
redir_status = OUTPOT_REDIR;
*end = '\0';
end++;
break;
}
else if(*end == '<')
{
redir_status = INPUT_REDIR;
*end = '\0';
end++;
break;
}
else
{
end--;
}
}
if(end >= start)
{
return end;
}
return NULL;
}
int main()
{
//shell是一个死循环
while(1)
{
//打印提示信息
printf("[root@localhost myshell]# ");
//刷新缓冲区,因为没有\n
memset(cmd_line, '\0', sizeof cmd_line);
fflush(stdout);
if(fgets(cmd_line, sizeof cmd_line, stdin) == NULL)
{
continue;
}
cmd_line[strlen(cmd_line)-1] = '\0';
char* sep = CheckRedir(cmd_line);
size_t index = 1;
g_argv[0] = strtok(cmd_line, SEP);
if(strcmp(g_argv[0], "ls") == 0)
{
g_argv[index++] = "--color=auto";
}
if(strcmp(g_argv[0], "ll") == 0)
{
g_argv[0] = "ls";
g_argv[index++] = "-l";
g_argv[index++] = "--color=auto";
}
while(g_argv[index++] = strtok(NULL, SEP));//如果还对原串操作,就传入NULL
if(strcmp(g_argv[0], "export") == 0 && g_argv[1] != NULL)
{
strcpy(g_myval, g_argv[1]);
int ret = putenv(g_myval);
if(ret == 0) printf("export success\n");
continue;
}
if(strcmp(g_argv[0], "cd") == 0)
{
if(g_argv[1] != NULL)
{
chdir(g_argv[1]);
}
continue;
}
pid_t id = fork();//创建子进程
if(id < 0)
{
perror("fork");
exit(1);
}
else if(id == 0)
{
//子进程
printf("准备执行\n");
int fd = -1;
switch(redir_status)
{
case INPUT_REDIR:
fd = open(sep, O_RDWR);
dup2(fd, 0);
break;
case OUTPOT_REDIR:
umask(0);
fd = open(sep, O_CREAT | O_TRUNC | O_WRONLY, 0666);
dup2(fd, 1);
break;
case APPEND_REDIR:
umask(0);
fd = open(sep, O_CREAT | O_APPEND | O_WRONLY, 0666);
dup2(fd, 1);
break;
case NONE_REDIR:
break;
default:
printf("bug?\n");
break;
}
execvp(g_argv[0], g_argv);
//子进程能够运行到这里说明替换失败
exit(1);
}
else
{
//父进程
int status = 0;
pid_t res = waitpid(-1, &status, 0);//阻塞式等待
if(res > 0)//等待成功
{
printf("exit code: %d \n", WEXITSTATUS(status));
}
}
}
return 0;
}
总结
以上就是今天要讲的内容,本文是针对前面文章的补充。