论文阅读 Memory Enhanced Global-Local Aggregation for Video Object Detection
Memory Enhanced Global-Local Aggregation for Video Object Detection
Abstract
人类如何识别视频中的物体?由于单一帧的质量低下,仅仅利用一帧图像内的信息可能很难让人们在这一帧中识别被遮挡的物体。我们认为人们识别视频中的物体有两个重要线索:全局语义信息和本地定位信息。最近,许多方法采用自注意机制,以增强关键帧中的特征,使用全局语义信息或本地定位信息之一。在本文中,我们介绍了一种记忆增强的全局-本地聚合(MEGA)网络,这是首批全面考虑全局和本地信息的尝试之一。此外,借助一种新颖且精心设计的长程记忆(LRM)模块,我们提出的MEGA可以使关键帧访问比以往任何方法都多得多的内容。通过这两个信息源的增强,我们的方法在ImageNet VID数据集上实现了最先进的性能。
1. Introduction
在视频中检测对象与在静态图像中检测它们的区别在于信息存在于时间维度。当孤立的帧可能受到问题,如运动模糊、遮挡或失焦时,人们自然会从整个视频中寻找线索来识别对象。
当人们不确定一个物体的身份时,他们会寻找与当前物体具有高语义相似性的其他帧中的显著物体,并将它们一起分配。我们将这种线索称为全局语义信息,因为视频中的每一帧都可以作为参考。但如果我们不确定对象是否存在,例如在黑暗中行走的黑猫,仅仅依靠语义信息无法告诉我们它的位置,因为该实例的存在在关键帧中尚未得到确认。如果提供了附近帧的信息,这个问题可以得到缓解。通过计算附近帧之间的差异来获得的运动等信息,我们可以在关键帧中定位对象。我们将这个信息源称为本地定位信息。总之,人们主要使用这两种信息源来识别对象。
因此,借鉴人类的这一思想,增强视频对象检测方法以利用整个视频内的信息是直接的,如图1(a)所示。然而,由于整个视频中存在大量的边界框,要借助整个视频中的信息来增强是不可行的。这激发了我们在效率和准确性之间取得平衡的同时执行近似的动机。近期解决视频对象检测问题的方法可以看作是不同近似方法,可以分为两个主要类别:本地聚合方法和全局聚合方法。
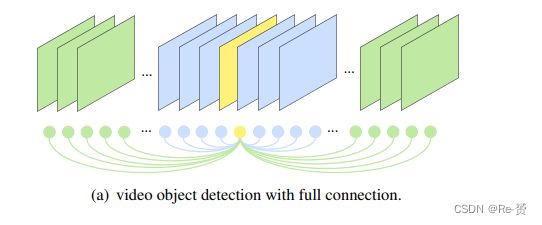
像[36, 9, 27, 1, 7]等方法考虑在短的局部范围内利用语义和定位信息,如图1(b)所示。另一方面,[30, 6, 23]只考虑了边界框之间的语义影响,如图1©所示。不幸的是,这些方法中没有一个综合考虑了本地和全局信息,这被称为无效问题。

近期工作中存在的另一个问题是聚合的帧数,也就是关键帧可以从中收集信息的数量。在以往的最先进方法中,仅选择20-30个参考帧,仅持续1-2秒,用于特征聚合。这也在图1(b)和1©中有所说明。我们认为在这种规模上的聚合大小是对本地影响或全局影响的不足够近似,更不用说图1(a)了。
在本文中,我们提出了记忆增强的全局-本地聚合(MEGA)来克服上述无效和不足够问题。具体而言,MEGA通过有效地聚合全局和本地信息来增强关键帧的候选框特征。
MEGA被实例化为一个多阶段结构。在第一阶段,MEGA旨在通过将全局和本地信息聚合到关键帧来解决无效问题。然而,正如图1(d)的上半部分所示,可用内容仍然相当有限。因此,在第二阶段,我们引入了一个新颖的长程记忆(LRM)模块,使关键帧能够访问比以往任何方法都多得多的内容。特别是,我们不是为当前的关键帧从头开始计算特征,而是重复使用在以前帧的检测过程中获得的预先计算的特征。这些预先计算的特征被缓存在LRM中,并在当前帧和以前帧之间建立了一个递归连接。请注意,与传统记忆不同,这些缓存的特征首先通过全局信息进行增强,这意味着当前关键帧不仅能够在本地获取更多信息,还能够在全局范围内获取更多信息。聚合大小如图1(d)的下半部分所示。引入LRM后,解决不足问题迈出了重要的一步,同时保持了简单和快速。

由于MEGA借助LRM的巨大聚合规模,我们在ImageNet VID数据集上实现了85.4%的mAP,这是迄今为止报道的最佳结果。
2. Related Work
略过
3. Method
在本节中,我们将详细介绍如何设计MEGA,使整个架构能够充分利用全局和本地信息。具体来说,MEGA首先将选定的全局特征聚合到本地特征中,然后,这些全局增强的本地特征与一个新颖的长程记忆(LRM)模块一起将更长的全局和本地信息内容聚合到关键帧中以实现更好的检测。概述如图2(b)所示。

3.1. Preliminary
视频对象检测的目标是为视频的每一帧 {It}Tt=1 提供检测结果。假设要检测的当前帧是Ik,Bt = {bit}表示由RPN在每一帧 It 生成的候选边界框。相邻帧 {It}k+τt=k−τ中的所有候选框被分组在一起形成局部池,即L = {Bt}k+τt=k−τ。对于全局特征,我们随机洗牌有序索引序列{1, . . . , T}以获得一个洗牌后的索引序列S,然后我们依次选择Tg帧并将它们中的所有边界框分组以形成全局池。可以表示为G = {BSi }k+Tg−1i=k。最后,引入了一种新颖的长程记忆模块M,用于存储在先前帧的检测过程中产生的中间特征,以使关键帧能够利用缓存信息,从而具有建模长期全局和本地依赖性的能力。我们的最终目标是在借助L、G和M的帮助下为关键帧中的所有候选框Bk提供分类和回归结果。
此外,我们用其语义特征fi和定位特征gi来表示每个框bi。gi表示空间信息(即高度、宽度、中心位置)和时间信息(即帧编号)。
Relation Module 我们选择用于挖掘边界框之间关系的操作是[15]中引入的关系模块。给定一组边界框B = {bi},对象关系模块被设计为通过计算M个头的语义特征的加权和来增强每个框bi,其中M表示头的数量。从技术上讲,bi的第m个关系特征计算如下:

其中WmV是一个线性变换矩阵。关系权重ωm,∗ij表示通过语义特征 f 和可能的定位特征 g 来测量bi和bj之间的影响。这里∗ ∈ {L, N}表示定位特征g是否纳入ω中,其中L表示纳入,N表示不纳入。由于在时间维度上两个远距离的边界框之间的定位特征是多余的,可能会损害整体性能,因此我们设计了无定位信息版本,督促关系模块只关注语义特征。需要注意的是,我们的定位特征中还包含了时间信息,以区分来自不同帧的边界框的影响。这个时间信息以与[5]中一样的相对方式纳入到ω中。
最后,通过连接所有M个关系特征及其原始特征,我们获得了输出的增强特征:

其中∗ ∈ {L, N},意思与之前相同。生成增强特征之后,我们另外附加一个非线性变换函数h(·),实现为一个全连接层和其后的ReLU激活函数。
此外,我们可以扩展关系模块,以建模两组边界框之间的关系。为了方便起见,我们使用符号f∗rm(B, P)来表示所有增强提案特征的集合,即{f∗rm(bi, P)},这意味着B中的所有边界框都通过P中的边界框的特征进行增强。
3.2. Memory Enhanced Global-Local Aggregation
Global-Local Aggregation for ineffective problem
首先,我们将详细介绍如何设计网络,将全局和本地特征聚合在一起以解决无效问题,即分别考虑全局或本地信息。我们将这个架构称为基本模型,并在图2(a)中表示出来。
具体来说,首先将来自G的全局特征聚合到 L中。更新函数可以表示为:

其中Ng(·)是由堆叠的 locationfree relation modules 组成的函数,Lg表示经过该函数后的最终全局增强版本的L。由于我们的目标是充分利用全局特征来增强本地特征的潜力,我们迭代地进行关系推理,使用Ng关系模块来更好地描述G和L之间的关系。具体而言,第k个关系模块中的计算过程如下:

其中fNrm(·)表示location-free关系模块,定义如Eq (2),Lg,0 = L表示第一个关系模块的输入。后续的关系模块以前一个关系模块的输出作为输入。最后,第Ng个关系模块的输出被作为Lg。
在全局特征被聚合到本地特征之后,我们寻求利用底层的语义和定位信息来进一步增强它们。为了实现这一点,采用了一系列Nl基于位置的关系模块。技术上,总体的函数可以总结如下:

其中Ll 表示 local pool的最终增强版本。我们将Nl(·)的整个过程分解如下。第k个关系模块中的计算流程与Ng(·)中的对应部分类似:

其中fLrm(·)表示基于位置的关系模块,我们采用Lg,即L的全局增强版本,作为第一个基于位置的关系模块的输入。Ll,Nl 被视为最终enhanced pool Ll 的输出。完成最终更新后,属于关键帧的Ll 中的所有边界框特征将被提取,并通过传统的RCNN头部进行传播,以产生分类和回归结果。这些提取的特征被表示为C。
Long Range Memory for insufficient problem
在基本模型中,一个单帧能够聚合总共Tg个全局特征帧和Tl个本地特征帧,如图2(a)所示,这是解决无效问题的一大步。然而,不足问题,即关键帧聚合的帧的数量太小的问题,直到现在仍然没有解决。如果有无限的内存和计算资源,可以通过增加Tg和Tl的值来解决这个问题,使它接近视频的长度。然而,在实际应用中,这是不可行的,因为资源是有限的。
那么,如何在保持计算成本可承受的情况下解决不足问题呢?受[5]中引入的循环机制的启发,我们设计了一个名为“长程记忆”(LRM)的新模块来实现这个目标。总之,LRM使基本模型能够充分利用预先计算的特征,从更长的全局和本地内容中获取信息。我们将这个经过增强的内存版本命名为MEGA。有关MEGA的工作原理的概述,请参阅图2(b)。
为了了解基本模型的缺陷,假设Ik−1和 Ik 是两个连续的帧。当我们将检测过程从Ik−1切换到 Ik时,我们丢弃了Ik−1上的所有中间特征。因此,Ik上的检测过程无法利用 Ik−1 的检测过程的任何优势,尽管它们在时间维度上是连续的。每当我们移动到新的帧时,都需要从头开始重新计算。这激发了我们的灵感,即要记住预先计算的特征,以便当前帧可以利用历史中的更多信息。在实践中,除了利用相邻帧{It}k+τt=k−τ,大小为Tm的长期记忆M还会额外提供Tm帧信息的特征,即在相邻帧之前的{It}k−τ−1t=k−τ−Tm,以帮助在Ik上进行检测。
具体而言,在完成Ik−1的检测过程后,与在基本模型中丢弃在检测过程中计算的所有特征不同,这时会将Ik−τ−1的中间特征缓存在长期记忆M中。这意味着,由于我们在Eq(5)中定义的本地聚合函数Nl(·)由一组Nl关系模块的堆叠组成,而 Ll,i, i ∈{0, Nl} 是经过第i个关系模块增强后的特征(i=0表示输入),我们将提取并存储 Ik−τ−1 的所有级别特征,即Ll,ik−τ−1,i ∈{0, Nl}在M中。具体来说,M有Nl+1个级别,其中Mi缓存Ll,ik−τ−1。每当为新帧完成检测过程时,与这个新帧相邻帧的第一帧对应的特征将被添加到M中。
通过引入M并重复使用其中缓存的这些预先计算的特征,我们可以增强本地聚合阶段,以便在Ik和后续帧上检测时融合M中的信息。本地聚合的增强版本可以总结为:

与Nl(·)类似,NEl(·)也是建立在一组Nl基于位置的关系模块之上,同时考虑了M的影响:

[·, ·]表示两个信息池的连接。与标准的更新函数相比,关键区别在于参考池的形成。与基本模型一样,在最终更新完成后,将提取C,并通过传统的RCNN头部进行传播,以给出当前关键帧的分类和回归结果。MEGA的详细推断过程如算法1所示。

To what extent does LRM address the ineffective and insufficient approximation problem?
通过附加尺寸为Tm的长期记忆M,特征数量的直接增加是显而易见的。但视野的增加远远超出了这个数字。请注意,由于我们增强的本地stage有Nl堆栈,由于M引入的递归连接,关键帧可以在我们每次迭代关系推理时从额外的Tm帧中收集信息,如图2(b)所示。最后,最重要的是,由于每一帧的缓存特征首先由不同的全局特征集增强,长期记忆不仅在本地增加了聚合大小,还在globally 增加了聚合大小。总之,具有Nl级增强的本地聚合阶段的模型可以从完全Nl×Tm+Tl的本地参考帧和Nl×Tm+Tg的全局参考帧中收集信息,其中Tl,Tg,Tm分别表示本地池,全局池和内存的大小。这对于基本模型中的Tl和Tg是一个巨大的飞跃。通过这种巨大的增大的聚合规模,我们认为我们的模型更好地解决了无效和不足的问题,同时不会显着增加运行时间。这在第4节的表1中的卓越实验结果进一步得到了证实。
4. Experiments
4.1. Dataset and Evaluation Setup
我们在ImageNet VID数据集上评估了我们提出的方法。ImageNet VID数据集是一个用于视频目标检测任务的大规模基准数据集,包括3,862个训练集视频和555个验证集视频。该数据集包含30个目标类别。我们在验证集上评估我们的方法,并使用均值平均精度(mAP)作为评估指标。
4.2. Network Architecture
Feature Extractor 我们主要使用ResNet-101和ResNeXt-101作为特征提取器。我们通过将最后一个卷积阶段(conv5)的第一个卷积块的步幅从2改为1来增大特征图的分辨率。为了保持感受野的大小,这些卷积层的膨胀率被设置为2。
Detection Network 我们使用Faster R-CNN 作为我们的检测模块。RPN头部添加在conv4阶段的顶部。在RPN中,锚点具有3个长宽比{1:2, 1:1, 2:1}和4个尺度{642, 1282, 2562, 5122},每个空间位置共产生12个锚点。在训练和推理过程中,为每个帧生成N = 300个候选框,NMS阈值为0.7 IoU。生成框后,我们应用RoI-Align 和在conv5阶段之后的一个1024-D全连接层,为每个框提取RoI特征。
MEGA 在训练和推理阶段,本地时间窗口大小设置为Tl = 25(τ = 12)。需要注意的是,实际上关键帧两侧的时间跨度可能不同。为了提高效率,我们不保留RPN为每个本地参考帧生成的所有候选框,而是选择具有最高物体性分数的80个候选框。在本地聚合阶段的后续堆栈中,候选框的数量进一步减少到20个。至于全局参考帧,我们总共选择了Tg = 10帧和每帧最高物体性分数的80个proposals。Long Range Memory的大小Tm设置为25。
至于全局和本地聚合阶段,关系模块的数量分别设置为Ng = 1和Nl = 3。对于每个关系模块,超参数设置与[15]相同。
4.3. Implementation Details && 4.4. Main Results && 4.5. Ablation Study
略过
5. Conclusion
In this work, we present Memory Enhance Global-Local Aggregation Network (MEGA), which takes a joint view of both global and local information aggregation to solve video object detection. Particularly, we first thoroughly analyze the ineffecitve and insufficient problems existed in recent methods. Then we propose to solve these problems in a two-stage manner, in the first stage we aggregate global features into local features towards solving the ineffective problem. Afterwards, a novel Long Range Memory is introduced to solve the insufficient problem. Experiments conducted on ImageNet VID dataset validate the effectiveness of our method.