Chapter 5. The Stack
Chapter 5. The Stack
Introduction
A Real-World Analogy
Stacks in x86 and x86-64 Architectures
What Is a Stack Frame?
How Does the Stack Work?
Referencing and Modifying Data on the Stack
Viewing the Raw Stack in a Debugger
Examining the Raw Stack in Detail
Conclusion
第5章堆栈
介绍
一个真实的类比
在x86和x86-64架构中堆叠
什么是堆栈框架?
堆栈如何工作?
在堆栈上引用和修改数据
在调试器中查看原始堆栈
详细检查原始堆栈
结论
5.1. Introduction
The stack is one of the most important and fundamental parts of a computer’s architecture. It is something that many computer users may have heard of but likely don’t know much about what it is used for or how it works. Many software problems can involve the stack, so it is important to have a working knowledge to troubleshoot effectively. Let’s start out by defining the term stack. The definition taken directly from Dictionary.com is
堆栈是计算机架构中最重要和最基本的部分之一。 许多计算机用户可能听说过堆栈,但可能不太了解它的用途或工作原理。许多软件问题都可能涉及堆栈,因此有必要学习堆栈的知识来解决问题。我们首先定义术语堆栈。 直接从Dictionary.com获取的定义是
stack(stak)
n.
1. A large, usually conical pile of straw or fodder arranged for outdoor storage.
1. 一个大的,通常是圆锥形的稻草或饲料堆,用于室外存放。
2. An orderly pile, especially one arranged in layers. See Synonyms at heap.
2. 一堆有序的堆,尤指排列成一层的堆。 请参阅堆中的同义词。
3. Computer Science. A section of memory and its associated registers used for temporary storage of information in which the item most recently stored is the first to be retrieved.
3.计算机科学。 一段存储器及其相关寄存器用于临时存储信息,其中最近存储的项目是首先被检索的。
4. A group of three rifles supporting each other, butt downward and forming a cone.
- A chimney or flue.
- A group of chimneys arranged together.
4. 一组三支相互支撑的步枪,向下翘起并形成一个圆锥体。
a)烟囱或烟道。
b)一组烟囱排列在一起。
5. A vertical exhaust pipe, as on a ship or locomotive.
5. 一条垂直排气管,如在船上或机车上。
6. An extensive arrangement of bookshelves. Often used in the plural.
6. 书架的广泛安排。 通常使用其复数形式。
7. stacks The area of a library in which most of the books are shelved.
7. 堆栈图书馆的大部分书籍都被搁置的区域。
8. A stackup.
8. 叠加
9. An English measure of coal or cut wood, equal to 108 cubic feet (3.06 cubic meters).
9. 煤炭或切割木材的英制尺寸,等于108立方英尺(3.06立方米)。
10. Informal. A large quantity: a stack of work to do.
10. 非正式的。 大量:一堆工作要做。
Of course, 3) is the definition that we’re looking for in the context of this book. That definition is very accurate and should lay out a great starting point for readers who aren’t familiar with what a stack is or what it is used for. Stacks exist and are integral for program execution on most major architectures, but the layout and exact functionality of them vary on certain architectures. The basic idea, though, is the same: As a program calls functions and uses storage local to those functions, data gets pushed or placed onto the stack. As the program returns from the functions, the data is popped or removed from the stack. In the sense of data storage, the heap can be thought of as opposite to the stack. Data storage in the heap does not need to be local to any particular function. This is an important difference to understand. Heaps are discussed in more detail in the “Heap Segment” section of Chapter 3, “The /proc Filesystem.”
当然,3)是我们在本书中寻找的定义。该定义非常准确,应该为不熟悉堆栈或其用途的读者提供一个很好的起点。堆栈在大多数主要体系结构上都存在并且是程序执行不可缺少的部分,但是它们的布局和确切功能在某些体系结构上有所不同。然而,基本思想是一样的:当一个程序调用函数并使用这些函数的本地存储时,数据被压入堆栈。 当程序从函数返回时,数据将从堆栈弹出。在数据存储的意义上,堆可以被认为与栈相反。堆中的数据存储不需要是任何特定功能的本地存储。这是一个重要的区别理解。堆在第3章“/ proc文件系统”的“堆段”一节中有更详细的讨论。
5.2. A Real-World Analogy
To help understand the purpose and functionality of a program stack, a real-world analogy is useful. Consider Joe who likes to explore new places, but once he gets to his destination he is always afraid that he’ll forget how to get back home. To prevent this, Joe devises a plan that he calls his “travel stack.” The only supplies he needs are several pieces of paper, a pencil, and a box to hold the paper. When he leaves his apartment, he writes down “My apartment” on a piece of paper and places it in the empty box. As he walks and sees landmarks or things of interest, he writes them down on another piece of paper and places that piece of paper onto the forming pile in the box. So for example, the first landmark he passed was a hot dog stand on the sidewalk, so he wrote down “Bob’s Hot Dog Stand” on a piece of paper and placed it in the box. He did the same thing for several more landmarks:
Tim’s Coffee Shop
Large statue of Linus Torvalds
George’s Auto Body Shop
Penguin Park
He finally made it to his destination—the bookstore where he could purchase a good Linux book such as this one! So now that he’s at the bookstore, he wants to make sure he makes it home safely with his new purchase. To do this, he simply pulls the first piece of paper out of the box and reads it. “Penguin Park” is written on the top piece of paper, so he walks toward it. When he reaches it, he discards the piece of paper and gets the next piece from the box. It reads “George’s Auto Body Shop,” so Joe walks toward it next. He continues this process until he reaches his apartment where he can begin learning fabulous things about Linux!
This example is exactly how a computer uses a stack to execute a program. In a computer, Joe would be the CPU, the box would be the program stack, the pieces of paper would be the stack frames, and the landmarks written on the paper would be the function return addresses.
The stack is a crucial part of program execution. Each stack frame, which will be discussed in more detail later, corresponds to a single instance of a function and stores variables and data local to that instance of the function. This concept allows function recursion to work because each time the function is executed, a stack frame for it is created and placed onto the stack with its own copy of the variables, which could be very different from the previous execution instance of the very same function. If a recursive function was executed 10 times, there would be 10 stack frames, and as execution finishes, the associated stack frame is removed and execution moves on to the next frame.
5.2。一个真实的类比
为了帮助理解程序堆栈的目的和功能,真实世界的类比是有用的。考虑乔喜欢探索新地方,但一旦他到达目的地,他总是担心他会忘记如何回家。为了防止这种情况,乔设计了一个他称之为“旅行套餐”的计划。他需要的只有几张纸,一支铅笔和一个纸盒。当他离开他的公寓时,他在一张纸上写下“我的公寓”,并将其放在空箱子里。当他走过并看到地标或感兴趣的东西时,他将它们写在另一张纸上,并将那张纸放在盒子中的成型桩上。例如,他通过的第一个地标是人行道上的热狗站,所以他在一张纸上写下了“鲍勃的热狗站”,并将它放在箱子里。他为更多的地标做了同样的事情:
蒂姆的咖啡店
莱纳斯·托沃兹大雕像
乔治的汽车车身商店
企鹅公园
他终于到达了他的目的地 - 他可以购买一本好书籍的书店,比如这本书!所以,现在他在书店,他想确保他在购买新产品时能够安全到家。要做到这一点,他只需将第一张纸从包装盒中取出并读取即可。“企鹅公园”写在最上面的一张纸上,所以他走向它。当他到达它时,他丢弃了这张纸,从盒子里拿出了下一张。上面写着“乔治的汽车车身商店”,所以乔接着走向它。他继续这个过程直到他到达他的公寓,在那里他可以开始学习有关Linux的神话般的事情!
这个例子就是计算机如何使用堆栈来执行程序。在计算机中,Joe是CPU,盒子是程序堆栈,纸张是堆栈帧,写在纸上的地标是函数返回地址。
堆栈是程序执行的关键部分。将在后面更详细讨论的每个堆栈帧对应于函数的单个实例,并存储该函数实例的本地的变量和数据。这个概念允许函数递归工作,因为每次执行该函数时,都会创建一个堆栈框架并将其放置到堆栈中,并使用自己的变量副本,这可能与以前的相同函数的执行实例非常不同。如果递归函数执行了10次,则会有10个堆栈帧,并且在执行结束时,关联的堆栈帧被移除并且执行移至下一帧。
5.3. Stacks in x86 and x86-64 Architectures
x86 和 x86-64 体系结构中的堆栈
Considering the most popular Linux architecture is x86 (also referred to as i386) and because x86-64 is very similar and quickly gaining in popularity, this section focuses on them. Stacks on these architectures are said to grow “down” because they start at a high memory address and grow toward low memory addresses. See section “/proc/
Figure 5.1. Example of Stack Growing Down.
考虑到最受欢迎的 Linux 体系结构是 x86 (也称为 i386), 因为 x86-64 非常相似, 而且很快就获得了普及, 本节将重点介绍它们。据说这些架构上的堆栈向下增长, 因为它们从高内存地址开始, 向低内存地址扩展。有关进程地址空间的详细信息, 请参阅3章 "/proc/
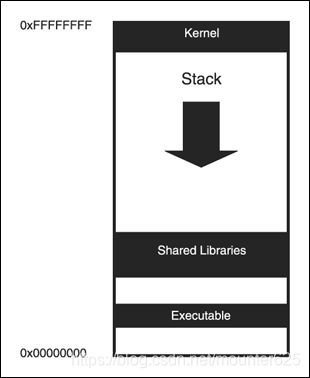
So now that we know conceptually where the stack resides and how it works, let’s find out where it really is and how it really works. The exact location will vary by architecture, but it will also vary by distribution. This is because some distributions include various patches and changes to the kernel source that modify the process address space. On SUSE 9.0 Professional and SLES 8 distributions running on x86 hardware, the stack segment starts at 0xc0000000 as shown in this very simple /proc/
现在我们知道了堆栈驻留的位置以及它的工作原理, 让我们找出它真正的位置以及它的工作原理。确切的位置会因架构而异, 但也会因发行版而异。这是因为某些发行版包含了修改进程地址空间的内核的各种补丁和更改。在 x86 硬件上运行的 SUSE 9.0 professional和 SLES 8 distribution, 堆栈段从0xc0000000 开始, 如这个非常简单/proc/
08048000-08049000 r-xp 00000000 03:08 293559 /u/dbehman/book/working/foo
08049000-0804a000 rw-p 00000000 03:08 293559 /u/dbehman/book/working/foo
40000000-40018000 r-xp 00000000 03:08 6664 /lib/ld-2.3.2.so
40018000-40019000 rw-p 00017000 03:08 6664 /lib/ld-2.3.2.so
40019000-4001b000 rw-p 00000000 00:00 0
40028000-40154000 r-xp 00000000 03:08 6661 /lib/i686/libc.so.6
40154000-40159000 rw-p 0012c000 03:08 6661 /lib/i686/libc.so.6
40159000-4015b000 rw-p 00000000 00:00 0
bfffe000-c0000000 rwxp fffff000 00:00 0
Remember, the stack grows down toward smaller addresses, thus the reason why 0xc0000000 is the end value in the stack address range of 0xbfffe000 - 0xc0000000.
Now to prove to ourselves that this range is in fact the stack segment, let’s write a small program that simply declares a local variable and then prints out that variable’s address.
请记住, 堆栈向较小的地址增长, 因此0xc0000000 是 0xbfffe000 - 0xc0000000 堆栈地址范围中的最终值的原因。现在我们自己证明这个范围实际上是堆栈段, 让我们编写一个小程序, 简单地声明一个局部变量, 然后打印出该变量的地址。
Note: Local variables are also referred to as stack variables given that the storage for them is obtained from the stack segment.
注意: 由于本地变量是从堆栈段获得的, 所以也称为堆栈变量。
The source code for the program is as follows:
该程序的源代码如下所示:
#include
int main( void )
{
int stackVar = 3;
char szCommand[64];
printf( "Address of stackVar is 0x%x\n\n", &stackVar );
sprintf( szCommand, "cat /proc/%d/maps", getpid() );
system( szCommand );
return 0;
}
Compiling and running this program gives this output:
编译和运行此程序将提供以下输出:
penguin> ./stack
Address of stackVar is 0xbffff2dc
08048000-08049000 r-xp 00000000 03:08 293568 /u/dbehman/book/code/stack
08049000-0804a000 rw-p 00000000 03:08 293568 /u/dbehman/book/code/stack
40000000-40018000 r-xp 00000000 03:08 6664 /lib/ld-2.3.2.so
40018000-40019000 rw-p 00017000 03:08 6664 /lib/ld-2.3.2.so
40019000-4001b000 rw-p 00000000 00:00 0
40028000-40154000 r-xp 00000000 03:08 6661 /lib/i686/libc.so.6
40154000-40159000 rw-p 0012c000 03:08 6661 /lib/i686/libc.so.6
40159000-4015b000 rw-p 00000000 00:00 0
bfffe000-c0000000 rwxp fffff000 00:00 0
As we can see, 0xbffff2dc does indeed fall within 0xbfffe000 and 0xc0000000. Examining this further, since there was only one stack variable in our very simple program example, what is on the stack in between 0xc0000000 and 0xbffff2dc?
正如我们所看到的, 0xbffff2dc 确实落在0xbfffe000 和0xc0000000之间。进一步检查这一点, 因为在我们非常简单的程序示例中只有一个堆栈变量, 0xc0000000 和0xbffff2dc 之间的堆栈中有什么?
Figure 5.2. Stack space.

The answer to this question is in the standard ELF specification, which is implemented in the kernel source file fs/elf_binfmt.c. Basically, what happens is that beginning with the terminating NULL byte at 0xbffffffb and working down toward lower addresses, the kernel copies the following information into this area:
这个问题的答案是在标准 ELF 规范中, 它是在内核源文件 fs/elf_binfmt.c 中实现的。基本上, 从在0xbffffffb NULL 字节开始,向下到较低内存地址, 内核将以下信息复制到该区域:
the pathname specified to exec()
指定给 exec() 的路径名
the full process environment
全部过程环境
all argv strings
argc
the auxiliary vector
We could verify this by enhancing our simple program, which displays the address of a stack variable, to also dump the locations of some of the information just listed. The enhanced code is as follows:
我们可以通过增强我们的简单程序来验证这一点, 来显示堆栈变量的地址, 还能转储刚刚列出的某些信息的位置。增强的代码如下所示:
#include
extern char **environ;
int main( int argc, char *argv[] )
{
int stackVar = 3;
char szCommand[64];
printf( "Address of stackVar is 0x%x\n", &stackVar );
printf( "Address of argc is 0x%x\n", &argc );
printf( "Address of argv is 0x%x\n", argv );
printf( "Address of environ is 0x%x\n", environ );
printf( "Address of argv[0] is 0x%x\n", argv[0] );
printf( "Address of *environ is 0x%x\n\n", *environ );
sprintf( szCommand, "cat /proc/%d/maps", getpid() );
system( szCommand );
return 0;
}
Compiling and running this enhanced program gives the following output:
编译并运行此增强程序将提供以下输出:
penguin> ./stack2
Address of stackVar is 0xbffff2dc
Address of argc is 0xbffff2f0
Address of argv is 0xbffff334
Address of environ is 0xbffff33c
Address of argv[0] is 0xbffff4d5
Address of *environ is 0xbffff4de
08048000-08049000 r-xp 00000000 03:08 188004 /u/dbehman/book/code/stack2
08049000-0804a000 rw-p 00000000 03:08 188004 /u/dbehman/book/code/stack2
40000000-40018000 r-xp 00000000 03:08 6664 /lib/ld-2.3.2.so
40018000-40019000 rw-p 00017000 03:08 6664 /lib/ld-2.3.2.so
40019000-4001b000 rw-p 00000000 00:00 0
40028000-40154000 r-xp 00000000 03:08 6661 /lib/i686/libc.so.6
40154000-40159000 rw-p 0012c000 03:08 6661 /lib/i686/libc.so.6
40159000-4015b000 rw-p 00000000 00:00 0
bfffe000-c0000000 rwxp fffff000 00:00 0
From the first few lines of output, we can now see some of the things that lie between the top of the stack and the program’s first stack frame.
从最初的几行输出中, 我们现在可以看到位于堆栈顶部和程序的第一个堆栈帧之间的一些东西。
It’s also important to note that with C applications, main() isn’t really the first function to be executed. Functions that get executed before main() include __libc_start_main(), _start(), and __libc_csu_init().
同样重要的是, 在 C 应用程序中, main () 实际上并不是要执行的第一个函数。在 main () 之前执行的函数包括 __libc_start_main ()、_start () 和 __libc_csu_init ()。
5.4. What Is a Stack Frame?
A single stack frame can be thought of as a contiguous address range, usually relatively small, in the stack segment that contains everything local to a particular function. Every function (except special cases such as inline or static functions) has a stack frame. More specifically, every individual execution of a function has an associated stack frame. The stack frame holds all local variables for that function as well as parameters that are passed to other functions that are called during execution. Consider the source code from stack3.c:
单个栈帧可以被认为是一个连续的地址范围, 通常相对较小, 位于包含特定函数本地的所有内容的栈段中。每个函数 (除了特殊情况,如inline或static函数) 都有栈帧。更具体地说, 每个函数的在执行时都有一个关联的栈帧。栈帧保存该函数的所有局部变量以及传递给执行期间调用的其他函数的参数。参考 stack3.c 源代码:
Code View: Scroll / Show All
#include
void function3( int *passedByReference )
{
int dummy = '\0';
printf( "My pid is %d; Press
dummy = fgetc( stdin );
*passedByReference = 9;
}
void function2( char *paramString )
{
int localInt = 1;
function3( &localInt );
printf( "Value of localInt = %d\n", localInt );
}
void function1( int paramInt )
{
char localString[] = "This is a string.";
function2( localString );
}
int main( void )
{
int stackVar = 3;
function1( stackVar );
return 0;
}
There’s a lot going on in the example, but for now we’re most interested in the fact that running this program will cause main() to call function1(), which calls function2(), which then calls function3(). function3() then displays its PID and waits for the user to hit ENTER to continue. Also pay attention to the local variables that are declared in each function. When we run this program and let it pause in function3(), we can visualize the stack frames by what is shown in Figure 5.3:
这个例子中有很多事情, 但是现在我们最感兴趣的是, 运行这个程序会导致 main () 调用 function1 (), 调用 function2 (), 然后调用 function3 ()。function3 () 然后显示其 PID, 等待用户点击 ENTER 继续。还要注意每个函数中声明的局部变量。当我们运行此程序并让它在 function3 () 中暂停时, 我们可以通过图5.3 中显示的内容来可视化堆栈帧:
Figure 5.3. Functions and stack frames.

This conceptual view can be viewed practically in gdb by compiling and running stack.c and then running the stack program under gdb with a breakpoint set in function3(). Once the breakpoint is hit, enter the command backtrace (synonymous with bt and where) to display the stack frames. The output will look like the following:
通过编译和运行堆栈, 可以在 gdb 中实际查看此概念视图, 然后在 gdb 下运行堆栈程序, 并在 function3 () 中设置断点。中断断点后, 输入命令回溯 (与 bt 和 where 的同义词) 以显示堆栈帧。输出将如下所示:
Code View: Scroll / Show All
penguin> gdb stack3
GNU gdb 5.3.92
Copyright 2003 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and
you are welcome to change it and/or distribute copies of it under
certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for
details.
This GDB was configured as "i586-suse-linux"...
(gdb) break function3
Breakpoint 1 at 0x80483d2: file stack3.c, line 5.
(gdb) run
Starting program: /home/dbehman/book/code/stack3
Breakpoint 1, function3 (passedByReference=0xbffff284) at stack3.c:5
5 int dummy = '\0';
(gdb) backtrace
#0 function3 (passedByReference=0xbffff284) at stack3.c:5
#1 0x0804842d in function2 (paramString=0xbffff2a0 "This is a
string.")
at stack3.c:16
#2 0x08048481 in function1 (paramInt=3) at stack3.c:24
#3 0x080484a8 in main () at stack3.c:31
(gdb)
For more information on the various GDB commands used to view and manipulate stacks, see Chapter 6, “The GNU Debugger (GDB).”
有关用于查看和操作堆栈的各种 GDB 命令的详细信息, 请参阅第6章 "GNU 调试器 (GDB)"。
5.5. How Does the Stack Work?
The stack’s functionality is implemented at many different levels of a computer including low-level processor instructions. On x86 for example, the pop and push instructions are specifically for placing data on and removing data from the stack respectively. Most architectures also supply dedicated registers to use for manipulating and managing the stack. On x86 and x86-64, the bp and sp registers (for “base pointer” and “stack pointer”—see following sections) are used. They are named slightly differently for each architecture in that a prefix is used to indicate the size of the register. For x86, the prefix letter “e” is used to indicate a size of 32-bit, and for x86-64 the prefix letter of “r” is used to indicate a size of 64-bit.
栈的功能在计算机的许多不同级别实现, 其中包括低级处理器指令。例如, 在 x86 上, pop 和push指令专门用于分别在栈上放置数据和从中删除数据。大多数体系结构还提供用于操作和管理栈的专用寄存器。在 x86 和 x86-64 上, 使用 bp 和 sp 寄存器 (用于 "基本指针" 和 "栈指针"-请参见以下部分)。对于每个体系结构, 它们的命名略有不同, 因为前缀用于表示寄存器的大小。对于 x86, 前缀字母 "e" 用于表示32位的大小, 对于 x86-64, "r" 的前缀字母用于指示大小为64位。
5.5.1. The BP and SP Registers
The bp, or base pointer (also referred to as frame pointer) register is used to hold the address of the beginning or base of the current frame. The purpose of this is so that a common reference point for all local stack variables can be used. In other words, stack variables are referenced by the bp register plus an offset. When working in a particular stack frame, the value of this register will never change. Each stack frame has its own unique bp value.
bp 或基指针 (也称为帧指针) 寄存器用于保存当前帧的开头或底部的地址。这样做的目的是为了可以使用所有本地栈变量的公共引用点。换言之, 栈变量由 bp 寄存器引用, 外加一个偏移量。在特定栈帧中工作时, 此寄存器的值永远不会改变。每个栈帧都有其独特的 bp 值。
The sp, or stack pointer register is used to hold the address of the end of the stack. A program’s assembly instructions will modify its value when new space is needed in the current stack frame for local variables. Because the sp is always the end of the stack, when a new frame is created, its value is used to set the new frame’s bp value. The best way to understand exactly how these two registers work is to examine the assembly instructions involved in starting a new function and allocating stack variables within it. Consider the following source code:
sp 或栈指针寄存器用于保存栈末尾的地址。当当前栈帧中的局部变量需要新空间时, 程序的汇编指令将修改其值。由于 sp 始终是栈的末尾, 因此在创建新栈帧时, 它的值用于设置新栈帧的 bp 值。了解这两个寄存器的工作方式的最好方法是检查启动新函数时所涉及的汇编指令, 并在其中分配栈变量。请考虑以下源代码:
#include
void function1( int param )
{
int localVar = 99;
}
int main( void )
{
int stackVar = 3;
function1( stackVar );
return 0;
}
Compiling this code with the -S switch will produce the following assembly listing:
使用-S选项编译此代码将生成以下汇编程序:
Code View: Scroll / Show All
.file "stack4.c"
.text
.globl function1
.type function1, @function
function1:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $99, -4(%ebp)
leave
ret
.size function1, .-function1
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
andl $-16, %esp
movl $0, %eax
subl %eax, %esp
movl $3, -4(%ebp)
subl $12, %esp
pushl -4(%ebp)
call function1
addl $16, %esp
movl $0, %eax
leave
ret
.size main, .-main
.ident "GCC: (GNU) 3.3.1 (SuSE Linux)"
Note: Because the source program was very simple, this assembly listing is also quite simple. Without any prior knowledge of or experience with assembly listings, you should be able to easily look at this listing and pick out the beginning of the two functions, function1 and main.
注: 由于源程序非常简单, 此汇编程序也相当简单。即使没有对汇编程序的任何事先了解或经验, 您应该也能够轻松地查看此汇编程序, 并挑选出 function1 和 main 两个函数的起始点。
In function1, the first instruction pushl %ebp saves the value of the base pointer from the previous frame on the stack. The next instruction movl %esp, %ebp copies the value of the stack pointer into the base pointer register. Recall that the stack pointer, esp in this example, always points to the top of the stack. The next instruction subl $4, %esp subtracts 4 from the current value stored in the stack pointer register. This effectively opens up storage in the newly created stack frame for 4 bytes. This is the space needed for the local variable localVar, which is indeed 4 bytes in size (an int). These three instructions combined form what’s commonly referred to as the function prologue. The function prologue is code added to the beginning of every function that is compiled by gcc and most, if not all, compilers. It is responsible for defining and preparing a new stack frame for upcoming function execution.
在 function1 中, 第一个指令 pushl %ebp 将基指针的值从栈上的上一个帧中保存。下一条指令 movl %esp,%ebp 将栈指针的值复制到基指针寄存器中。请记住, 此示例中的栈指针始终指向堆栈顶部。下一个指令 subl $ 4,%esp 从存储在栈指针寄存器中的当前值减去4。这有效地在新创建的栈帧中打开了4字节的存储。这是局部变量 localVar 所需的空间, 它确实是大小的4个字节 (int)。这三指令组合形成了通常称为函数的序言。函数序言是添加到由 gcc 和大多数 (如果不是全部) 编译器编译的每个函数的开头的代码。它负责定义和准备新的栈帧, 以用于即将执行的函数。
Along with a function prologue is an associated function epilogue. In the assembly code shown for the preceding function1(), the epilogue consists of the leave and ret instructions. The epilogue is effectively the reverse of the prologue. It is hard to tell this because those unfamiliar with the x86 instruction set will not know that the leave instruction is actually a high-level instruction equivalent to these instructions:
跟函数的序言相对应的是一个函数的结语。在为前面的 function1 () 显示的汇编代码中, 结语由leave和 ret 指令组成。结语实际上是序言的反面。很难说这一点, 因为那些不熟悉 x86 指令集的人将不知道假指令实际上是与这些指令等效的高级指令:
movl %ebp, %esp
popl %ebp
Comparing these two instructions to the first two instructions in the prologue, we can see that they are in fact the mirror image of each other. The function epilogue code is completed by the ret instruction, which transfers program control to the address located at the end of the stack.
The function prologue and epilogue are extremely important contributors to the proper execution and isolation of individual function calls. They make up what’s commonly referred to as the function or procedure calling conventions. We will discuss the remaining details of the calling conventions, but first a special note is required regarding the prologue and epilogue.
将这两个指令与序言中的前两个指令进行比较, 我们可以看到它们实际上是彼此的镜像。函数结语代码由 ret 指令完成, 它将程序控制转移到位于栈末尾的地址。函数的序言和结语是对单个函数调用的正确执行和隔离的非常重要的贡献。它们构成了通常称为函数或过程调用约定的内容。我们将讨论调用约定的其余细节, 但首先需要对序言和结语进行特别说明。
5.5.1.1. Special Case: gcc’s -fomit-frame-pointer Compile Option
Some architectures support gcc’s -fomit-frame-pointer compile option, which is used to avoid the need for the function prologue and epilogue, thus freeing up the frame pointer register to be used for other purposes. This optimization is done at the cost of the ability to debug the application because certain debugging tools and techniques rely on the frame pointer being present. SUSE 9.0 Professional and SLES 8 on the x86-64 architecture have been compiled with the -fomit-frame-pointer option enabled, which could improve performance in certain areas of the operating system. GDB is able to handle this properly, but other debugging techniques might have difficulties such as using a homegrown stack traceback function. It is also important to note that when using gcc 3.3.x with the -O1 or greater optimization level, the -fomit-frame-pointer flag is automatically turned on for the x86-64 architecture. If omitting the frame pointer is not desired but optimization is, be sure to compile your program with something like the following:
有些体系结构支持 gcc 的-fomit-frame-pointer编译选项, 它用于避免函数的序言和结语, 从而释放了用于其他目的的帧指针寄存器。此优化是以调试应用程序的能力为代价的, 因为某些调试工具和技术依赖于帧指针。基于x86-64 体系结构的SUSE 9.0 专业版和 SLES 8 在编译时, -fomit-frame-pointer选项启用, 这可以提高操作系统在某些领域的性能。GDB 能够正确处理这一问题, 但是其他调试技术可能会遇到一些困难, 例如使用本地的栈回溯功能。还要注意的是, 当使用 gcc 3.3.x (-O1 或更高的优化级别) 时, -fomit-frame-pointer标志会自动打开以用于 x86-64 体系结构。如果不想省略帧指针, 但需要优化, 请按照下面的命令编译您的程序:
gcc -o myexe myexe.c -O1 -fno-omit-frame-pointer
5.5.2. Function Calling Conventions
When you strip away all the peripherals, storage, sound, and video devices, computers are relatively simple machines. The “guts” of a computer basically consist of two main things: the CPU and RAM. RAM stores the instructions that run on the CPU, but given that the CPU is really just a huge maze of logic gates, there is a need for intermediate storage areas that are very close to the CPU and still fast enough to feed it as quickly as it can process the instructions. These intermediate storage areas are the system’s registers and are integral parts of a computer system.
Most systems have only a very small number of registers, and some of these registers have a dedicated purpose and so cannot simply be used at will. Because every function that executes has access to and can manipulate the exact same registers, there must be a set of rules that govern how registers are used between function calls. The function caller and function callee must know exactly what to expect from the registers and how to properly use them without clobbering one another. This set of rules is called the function or procedure calling conventions. They are architecture-specific and very important to know and understand for all software developers.
当您去掉所有外设、存储、声音和视频设备时, 计算机是相对简单的机器。计算机的 "内核" 基本上由两个部分组成: CPU 和 RAM。RAM 存储了运行在 cpu 上的指令, 但是考虑到 cpu 实际上只是一个巨大的逻辑门迷宫, 需要非常接近 CPU而且仍然足够快的中间存储区域 以满足其处理指令的速度。这些中间存储区域是系统的寄存器, 是计算机系统的组成部分。大多数系统只有很少数量的寄存器, 有些寄存器有专门的用途, 因此不能随意使用。由于每个执行的函数都可以访问和操作完全相同的寄存器, 因此必须有一组规则来控制在函数调用之间如何使用寄存器。函数调用方和被调用方必须确切知道要从寄存器中得到什么这组规则称为函数或过程调用约定。它们是特定于体系结构的,所有软件开发人员都需要了解。。
The purpose of this section is to give an overview of the basics of the calling conventions and should not be considered an exhaustive reference. The calling conventions are quite a bit more detailed than what is presented here— for example, what to do when structures contain various data classification types, how to properly align data, and so on. For more detailed information, it is recommended to download and read the calling convention sections from the architecture’s Application Binary Interface (ABI) specification document. The ABI is basically a blueprint for how software interacts with an architecture, so there is great value in reading these documents. The links are:
本节的目的是概述调用约定的基本知识, 不应将其视为详尽的介绍。调用约定文档比此处介绍的更详细一些, 例如, 结构包含各种数据分类类型时,该怎么办,如何正确地对齐数据等,。更详细的信息, 建议下载并阅读体系结构的Application Binary Interface (ABI) 规范文档-调用约定。ABI 基本上是软件与体系结构交互的规范, 因此这些文档有很大的价值。链接有:
x86 ABI - http://www.caldera.com/developers/devspecs/abi386-4.pdf
x86-64 ABI - http://www.x86-64.org/documentation/abi.pdf
Again, the following sections will give an overview of the calling conventions on x86 and x86-64, which will provide a great base understanding.
同样, 以下各节将概述 x86 和 x86-64 的调用约定, 这将提供对x86和x86_64很好的基础理解。
5.5.2.1. x86 Architecture
We have already discussed what a function must do at the very beginning of its execution (prologue) and at the very end (epilogue), which are important parts of the calling conventions. Now we must learn the rules for calling a function. For example, if function1 calls function2 with five parameters, how does function2 know where to find these parameters and what to do with them?
我们已经讨论了函数在其执行的开始 (序言) 和结尾 (结语) 中必须做什么, 这是调用约定的重要部分。现在我们必须学习调用函数的规则。例如, 如果 function1 调用了具有五个参数的 function2, function2 如何知道在哪里找到这些参数以及如何处理它们?
The answer to this is actually quite simple. The calling function simply pushes the function arguments onto the stack starting with the right-most parameter and working toward the left. This is illustrated in the following diagram.
答案其实很简单。调用函数简单地将函数参数推送到栈上, 从最右边的参数开始, 然后向左工作。下图说明了这一点。
Figure 5.4. Illustration of calling conventions on x86.
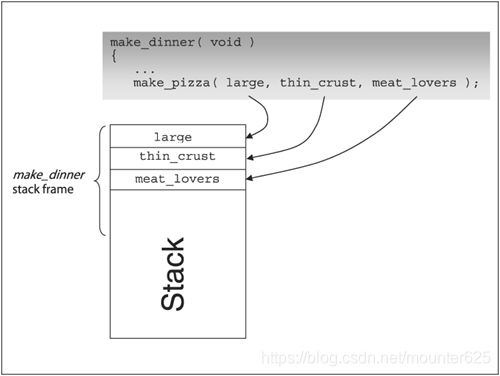
Also as shown, the arguments are all pushed onto the stack in the calling function’s stack frame.
Let’s consider the following program, pizza.c, to illustrate how this really works.
如图所示, 参数都被推入调用函数的栈帧中的栈上。让我们考虑下面的程序, pizza.c。
Code View: Scroll / Show All
#define pizza 1
#define large 2
#define thin_crust 6
#define meat_lovers 9
int make_pizza( int size, int crust_type, int specialty )
{
int return_value = 0;
/* Do stuff */
return return_value;
}
int make_dinner( int meal_type )
{
int return_value = 0;
return_value = make_pizza( large, thin_crust, meat_lovers );
return return_value;
}
int main( void )
{
int return_value = 0;
return_value = make_dinner( pizza );
return return_value;
}
To really see the calling conventions in action, we need to look at the assembly listing for this program. Recall that creating an assembly listing can be done with the following command assuming our program is called pizza.c:
要真正看到操作中的调用约定, 我们需要查看该程序的汇编程序。回想一下, 创建汇编程序可以通过以下命令完成: 假设我们的程序叫pizza. c:
gcc -S pizza.c
This will produce pizza.s, which is shown here:
Code View: Scroll / Show All
.file "pizza.c"
.text
.globl make_pizza
.type make_pizza, @function
make_pizza:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $0, -4(%ebp)
movl -4(%ebp), %eax
leave
ret
.size make_pizza, .-make_pizza
.globl make_dinner
.type make_dinner, @function
make_dinner:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl $0, -4(%ebp)
subl $4, %esp
pushl $9
pushl $6
pushl $2
call make_pizza
addl $16, %esp
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
leave
ret
.size make_dinner, .-make_dinner
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
andl $-16, %esp
movl $0, %eax
subl %eax, %esp
movl $0, -4(%ebp)
subl $12, %esp
pushl $1
call make_dinner
addl $16, %esp
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
leave
ret
.size main, .-main
.ident "GCC: (GNU) 3.3.1 (SuSE Linux)"
Recall that a C function name, such as make_dinner in our example, will always appear in the assembly listing as a label,—or as make_dinner: in the previous listing, for example. This function contains the instructions of interest that clearly illustrate the x86 calling conventions. In particular, note these instructions:
回想一下, 在我们的示例中, C 函数名称 (如 make_dinner) 将始终显示在汇编程序中作为标签, 或作为 make_dinner: 例如, 在上一个汇编程序中。此函数包含明确说明 x86 调用约定的相关说明。特别是, 请注意以下说明:
pushl $9
pushl $6
pushl $2
call make_pizza
Note: In Linux assembly, any instruction argument prefixed with “$” is a constant, which means that the value prefixed is the actual value used.
注意: 在 Linux 汇编程序中, 任何以 "$" 为前缀的指令参数都是常量, 这意味着值前缀是所使用的实际值。
Looking back at pizza.c, we see the following macro definitions:
回头看pizza.c, 我们看到以下宏定义:
#define large 2
#define thin_crust 6
#define meat_lovers 9
So we can now clearly see that the calling conventions have been followed, and our function parameters were pushed onto the stack starting with meat_lovers and followed by thin_crust and then large.
因此, 我们现在可以清楚地看到, 调用约定已被遵循, 我们的功能参数被推到栈上开始的 meat_lovers, 其次是 thin_crust, 最后large.
5.5.2.1.1. Return Value
Another important aspect of calling conventions to know and understand is how a function’s return value is passed back to the calling function. In pizza.c just shown, the call to make_pizza is
了解和理解调用约定的另一个重要方面是函数的返回值如何传递回调用函数。在pizza. c 中显示, 调用 make_pizza 是
return_value = make_pizza( large, thin_crust, meat_lovers );
This means that we want the return value of the function call to be stored in the return_value variable, which is local to the calling function. The x86 calling conventions state that the %eax register is used to store the function return value between function calls. This is illustrated in the previous assembly listing. At the very end of the make_pizza function, we see the following instructions:
这意味着, 我们希望函数调用的返回值存储在调用函数的 return_value 变量中。x86 调用约定声明%eax 寄存器用于在函数调用之间存储函数返回值。这在上一个程序集列表中进行了说明。在 make_pizza 函数的末尾, 我们看到以下说明:
movl -4(%ebp), %eax
leave
ret
We now know that leave and ret make up the function epilogue and notice immediately before that, a move instruction is done to move the value stored at the address %ebp contains offset by 4 bytes into the %eax register. If we look back through the assembly for the make_pizza function, we will see that -4 (%ebp) does in fact represent the return_value stack variable.
我们现在知道, leave和 ret 组成的函数的结语。注意, 在这之前, 执行move指令, 将存储在地址%ebp 偏移量为4字节的值移动到%eax 寄存器中。如果我们回顾一下汇编程序的 make_pizza 函数, 我们将看到-4 (%ebp) 实际上表示 return_value 栈变量。
So now at this point, the %eax register contains the return value just before the function returns to its caller, so let’s now look at what happens back in the calling function. In our example, that function is make_dinner:
所以现在在这一点上,%eax 寄存器在函数返回给调用方之前包含返回值, 所以现在让我们来看一下调用函数中返回的内容。在我们的示例中, 该函数是 make_dinner 的:
call make_pizza
addl $16, %esp
movl %eax, -4(%ebp)
Immediately after the call to make_pizza we can see that the stack is shrunk by 16 bytes by adding 16 to the %esp register. We then see that the value from the %eax register is moved to a stack variable specified by -4 (%ebp), which turns out to be the return_value variable.
在对 make_pizza 的调用之后, 我们可以看到堆栈的收缩为16字节, 通过将16添加到%esp 寄存器。然后, 我们看到%eax 寄存器中的值被移动到由-4 (%ebp) 指定的栈变量中, 它原来是 return_value 变量。
5.5.2.2. x86-64 Architecture
The calling conventions for x86-64 are a bit more complex than for x86. The primary difference is that rather than all the functions’ arguments being pushed on the stack before a function call as is done on x86, x86-64 makes use of some of the general purpose registers first. The reason for this is that the x86-64 architecture provides a few more general purpose registers than x86, and using them rather than pushing the arguments onto the stack that resides on much slower RAM is a very large performance gain.
x86-64 的调用约定比 x86 更复杂一些。主要的区别在于, 在函数调用之前在栈上推送的所有函数参数, 而不是在 x86 上执行之前, x86-64 首先使用一些通用寄存器。原因是 x86-64 体系结构提供了比 x86 更通用的寄存器, 使用它们而不是将参数推送到栈上, 驻留在速度较慢的 RAM 上,这是一个非常大的性能提升。
Function parameters are also handled differently depending on their data type classification. The main classification, referred to as INTEGER, is any integral data type that can fit into one of the general purpose registers (GPR). Because the GPRs on x86-64 are all 64-bit, this covers the majority of data types passed as function arguments. The calling convention that is used for this data classification is (arguments—from left to right—are assigned to the following GPRs)
函数参数的处理方式也不同, 具体取决于它们的数据类型。主分类 (称为整数) 是可放入任何通用寄存器 (GPR) 的整数类型。因为 x86-64 上的 GPRs 都是64位的, 所以它涵盖了作为函数参数传递的大多数数据类型。用于此数据分类的调用约定是 (从左向右的参数) 分配给以下 GPRs:
%rdi
%rsi
%rdx
%rcx
%r8
%r9
Remaining arguments are pushed onto the stack as on x86.
To illustrate this, consider a modified pizza.c program:
剩余参数按 x86 推送到堆栈上。为了说明这一点, 请考虑修改后的pizza. c 程序:
Code View: Scroll / Show All
#define pizza 50
#define large 51
#define thin_crust 52
#define cheese 1
#define pepperoni 2
#define onions 3
#define peppers 4
#define mushrooms 5
#define sausage 6
#define pineapple 7
#define bacon 8
#define ham 9
int make_pizza( int size, int crust_type, int topping1, int topping2,int topping3, int topping4, int topping5,int topping6, int topping7, int topping8,int topping9 )
{
int return_value = 0;
/* Do stuff */
return return_value;
}
int make_dinner( int meal_type )
{
int return_value = 0;
return_value = make_pizza( large, thin_crust, cheese, pepperoni,onions, peppers, mushrooms, sausage,pineapple, bacon, ham );
return return_value;
}
int main( void )
{
int return_value = 0;
return_value = make_dinner( pizza );
return return_value;
}
Again, we produce the assembly listing for this program with the command:
同样, 我们使用以下命令为该程序生成汇编程序:
gcc -S pizza.c
The assembly listing produced is:
Code View: Scroll / Show All
.file "pizza.c"
.text
.globl make_pizza
.type make_pizza,@function
make_pizza:
.LFB1:
pushq %rbp
.LCFI0:
movq %rsp, %rbp
.LCFI1:
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl %edx, -12(%rbp)
movl %ecx, -16(%rbp)
movl %r8d, -20(%rbp)
movl %r9d, -24(%rbp)
movl $0, -28(%rbp)
movl -28(%rbp), %eax
leave
ret
.LFE1:
.Lfe1:
.size make_pizza,.Lfe1-make_pizza
.globl make_dinner
.type make_dinner,@function
make_dinner:
.LFB2:
pushq %rbp
.LCFI2:
movq %rsp, %rbp
.LCFI3:
subq $48, %rsp
.LCFI4:
movl %edi, -4(%rbp)
movl $0, -8(%rbp)
movl $9, 32(%rsp)
movl $8, 24(%rsp)
movl $7, 16(%rsp)
movl $6, 8(%rsp)
movl $5, (%rsp)
movl $4, %r9d
movl $3, %r8d
movl $2, %ecx
movl $1, %edx
movl $52, %esi
movl $51, %edi
call make_pizza
movl %eax, -8(%rbp)
movl -8(%rbp), %eax
leave
ret
.LFE2:
.Lfe2:
.size make_dinner,.Lfe2-make_dinner
.globl main
.type main,@function
main:
.LFB3:
pushq %rbp
.LCFI5:
movq %rsp, %rbp
.LCFI6:
subq $16, %rsp
.LCFI7:
movl $0, -4(%rbp)
movl $50, %edi
call make_dinner
movl %eax, -4(%rbp)
movl -4(%rbp), %eax
leave
ret
.LFE3:
.Lfe3:
.size main,.Lfe3-main
.section .eh_frame,"aw",@progbits
—8<— SNIPPED UNIMPORTANT INFO —8<—
The instructions we’re most interested in are the ones that come before the call to make_pizza in the make_dinner function. Specifically, they are
我们最感兴趣的是那些在 make_dinner 函数中调用 make_pizza 的指令。具体地说, 它们是
movl $9, 32(%rsp)
movl $8, 24(%rsp)
movl $7, 16(%rsp)
movl $6, 8(%rsp)
movl $5, (%rsp)
movl $4, %r9d
movl $3, %r8d
movl $2, %ecx
movl $1, %edx
movl $52, %esi
movl $51, %edi
call make_pizza
We can look at this graphically in Figure 5.5.
我们可以在图5.5 中以图形的形式来查看这一点。
Figure 5.5. Illustration of calling conventions on x86-64.
图5.5。x86-64 调用约定的说明。

As you can see, the six general purpose registers are used up with six left-most function arguments. The remaining five function arguments are pushed onto the stack. Note, however, that the last five arguments are not pushed onto the stack as they are on x86; rather they are moved directly to the addresses in memory referenced by %rsp.
正如您所看到的, 六个通用寄存器保存了从左到右六个函数参数。其余的五函数参数被推送到栈上。但是, 请注意, 最后五个参数不会被推送到栈上,,就像它们在 x86 上一样。相反, 它们直接移动到%rsp 保存的内存地址中。
5.5.2.2.1. Return Value
The convention used to handle the function return value is very similar to x86. The data is first classified to determine the method used to handle the return. For the INTEGER data classification, the %rax register is first used. If it is unavailable at the time of return, the %rdx register can be used instead. There are other possibilities for different return scenarios, but the general idea remains the same. For all the details, it is recommended to refer to the x86-64 ABI.
用于处理函数返回值的约定与 x86 非常相似。首先对数据进行分类, 以确定用于处理返回的方法。对于整数数据, 首先使用%rax 寄存器。如果不可用, 则改用%rdx 寄存器。对于不同的返回方案, 还有其他可能性, 但总体思路仍然相同。对于所有细节, 建议参考 x86-64 ABI。
5.6. Referencing and Modifying Data on the Stack
We’ve seen by now that the stack is crucial for proper and flexible program execution. We’ve also seen that the stack really isn’t as complex as it first may seem to be. This section will explain how data is stored on the stack and how it is manipulated.
我们现在已经看到, 栈对于正确和灵活的程序执行至关重要。我们还看到, 栈实际上并不像它最初看起来那么复杂。本节将解释数据如何存储在栈上以及如何操作。
Recall our simple C program from the earlier section, “The BP and SP Registers,” where we declare a simple stack variable like this:
从前面的部分 "BP 和 SP 寄存器" 中调用简单的 C 程序, 我们声明一个简单的栈变量, 如下所述:
int localVar = 99;
Recall further that the assembly produced for this area of the program consisted of these three instructions, which make up the function prolog:
进一步回顾为程序的这个区域生产的汇编程序包括了这三个指令, 构成函数序言:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
The subl instruction effectively increases the size of the stack by 4 bytes–keep in mind that the stack grows down toward lower addresses on x86. Because we know that the function in question only declares one local variable, int localVar, we know that this space is created for it. Therefore, at this point we could define the memory location holding localVar’s value as whatever the register esp holds. This method does not work very well, however, because the value of esp will change as more local variables are declared. The correct method is to reference ebp (the base or frame pointer) instead. We can see that this is done, in fact, by looking at the next instruction in the assembly listing from our small program:
subl 指令有效地增加了堆栈的大小 4 bytes–考虑到栈在x86上向下增长。因为我们知道这个函数只声明一个局部变量, int localVar, 我们知道这个空间是为它创建的。因此, 在这一点上, 我们可以定义的内存地址保存 localVar 的价, 无论寄存器 esp 是否保存。但是, 此方法工作得不太好, 因为当声明了更多的局部变量时 esp 的值会发生变化。正确的方法是引用 ebp (基或帧指针) 代替。我们可以看到, 事实上, 这是通过查看从我们的小程序的汇编程序的下一条指令:
movl $99, -4(%ebp)
This instruction is taking care of assigning the value 99 to localVar, or as it’s referred to in assembly, -4 (%ebp) which essentially means “the value stored in ebp offset by -4 bytes.” Note that some assembly outputs, for example objdump -d
此指令负责将值99分配给 localVar, 或者它在汇编程序-4 (%ebp) 中引用, 这实质上意味着 "存储在 ebp 偏移量-4 字节的值。请注意, 某些汇编输出 (例如 objdump -d
movl $0x63,0xfffffffc(%ebp)
When it is known in which offset relative to the frame pointer a particular variable is stored, you can see other places that variable is referenced through an assembly listing of the same function.
Let us quickly look at how this reflects on the term “pass by reference.” To summarize, when passing a parameter to a C function where it is desired to change the value of a parameter within the called function, the programmer must be sure to pass the address of the parameter rather than the value of it. Understanding how the stack works can solidify this rule in one’s mind. Recall function3 from the stack.c source code, which is declared as:
当已知特定变量存储在相对于帧指针的偏移量时, 可以看到同一函数的汇编程序中其他地方对该变量的引用。让我们快速看看这是如何反映 "通过引用" 一词。总结一下, 当将参数传递给 C 函数时, 需要在调用函数中更改参数的值时, 程序员必须确保传递参数的地址而不是它的值。了解栈的工作原理可以在头脑中巩固这一规则。回想stack.c中function3源代码, 声明为:
void function3( int *passedByReference )
Also bear in mind that a call to this function is made in function2, which passes the address of the local variable localInt to it:
还要记住, 对此函数的调用是在 function2 中进行的, 它将局部变量 localInt 的地址传递给它:
function3( &localInt );
The assembly just prior to and including the call to function3 looks like this:
前面的汇编程序和包括对 function3 的调用如下所示:
leal -4(%ebp), %eax
pushl %eax
call function3
The key instruction in this sequence is the leal, or load effective address of the frame pointer offset by 4 bytes and store that address into the eax register. The address stored in the eax register is then pushed onto the stack in preparation for the call to function3. Now when function3 executes, it will know exactly where the storage for localInt is on the stack and will be able to modify it directly as it does in this example.
此汇编程序中的关键指令是 leal, 或者将帧指针偏移量的有效地址偏移(减去)4字节, 并将该偏移后的地址存储到 eax 寄存器中。然后, 将存储在 eax 寄存器中的地址推送到栈上, 准备调用 function3。现在, 当 function3 执行时, 它将确切地知道 localInt 的存储在栈上的位置, 并且可以像在本例中那样直接修改它。
5.7. Viewing the Raw Stack in a Debugger
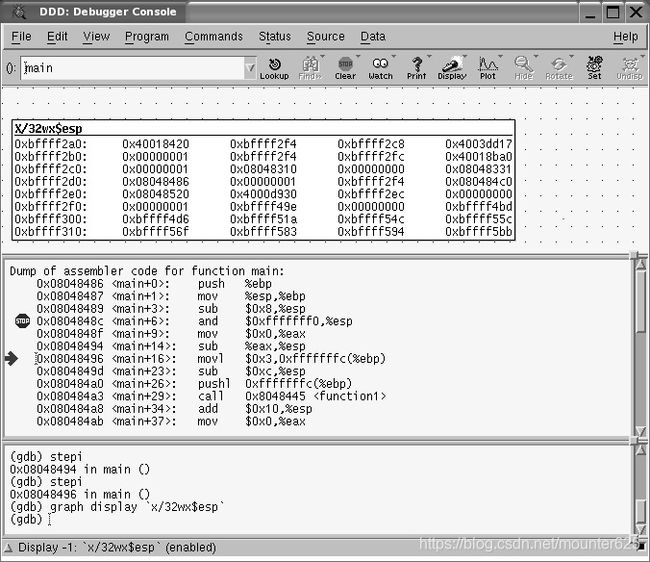
When debugging real problems in a production environment, the compiled binaries will likely not contain debugging information, and recompiling the source code with the -g debug flag is not an option. In these cases, finding the cause of the problem will require some skill and some knowledge of the program at the machine language level. One of the most important things to watch in these cases is the raw stack. Examining the stack while following through assembly instructions can be crucial to finding the nastiest of software bugs. The easiest way to watch the raw stack is to use DDD (see section “Data Display Debugger” in Chapter 6, “The GNU Debugger (GDB)” for more information). The nice thing about DDD is that the Data Display window will highlight changes made to anything being displayed in it after each instruction. With this, you can see exactly how each instruction does or does not affect the stack. Figure 5.6 shows a DDD session of the program created from the stack.c source code used earlier in this chapter. For quick reference, the source code is as follows:
在调试生产环境中的实际问题时, 已编译的二进制文件可能不包含调试信息, 并且使用-g 调试标志重新编译源代码不是一个选择。在这些情况下, 找出问题的原因将需要在机器语言水平的一些技能和知识。在这些情况下, 最重要的事情是原始堆栈。通过汇编程序指令检查堆栈可能对查找最糟糕的软件 bug 至关重要。监视原始栈的最简单方法是使用 DDD (请参阅第6章 "GNU 调试器 (GDB)" 中的 "数据显示调试器") 以了解更多信息。关于 DDD 的好处在于, "数据显示" 窗口将突出显示在每次指令之后, 对其进行的任何操作所做的更改。通过此操作, 您可以准确地看到每个指令是否影响栈。图5.6 显示了从栈创建的程序的 DDD 会话stack. c 源代码..。
Figure 5.6. stack.c in a DDD session, part 1.
Code View: Scroll / Show All
#include
void function3( int *passedByReference )
{
int dummy = '\0';
printf("My pid is %d; Press
dummy = fgetc( stdin );
*passedByReference = 9;
}
void function2( char *paramString )
{
int localInt = 1;
function3( &localInt );
printf( "Value of localInt = %d\n", localInt );
}
void function1( int paramInt )
{
char localString[] = "This is a string.";
function2( localString );
}
int main( void )
{
int stackVar = 3;
function1( stackVar );
return 0;
}
A breakpoint was set in main before running. Notice how the “stop sign” is on the instruction line:
在运行前, 在 main 中设置了断点。注意 "stop sign" 在汇编指令行中:
0x0804848c
rather than the very first instruction line in main(). This is because the three instructions before main+6 are the standard function prologue instructions, and GDB executes them automatically.
Also notice that three stepi commands were issued along with the command graph display ‘x/32wx$esp’, which produces a data display showing the top 32 words in hex on the stack. Recall that the esp register always points to the top (lowest address for x86 based architecture) of the stack.
不是在main () 中的第一个指令行。这是因为在 main+6 之前的三个指令是标准函数的序言指令, GDB 会自动执行它们。还注意到, 三个 stepi 命令与命令图形显示 "x/32 wx $ esp" 一起发出, 它产生一个数据显示, 显示栈上十六进制的前32个字。回想一下, esp 寄存器总是指向栈的顶部 ( x86 的体系结构的最低地址)。
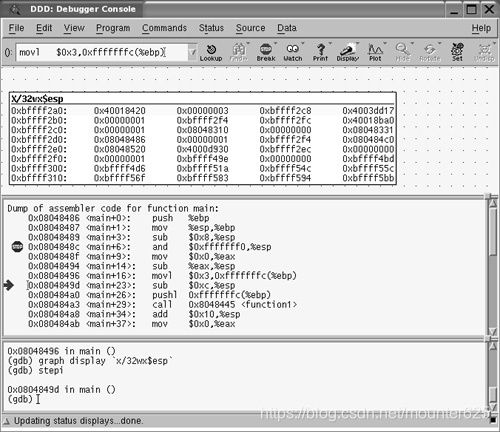
Notice that the arrow points to the next instruction to be executed, which is movl $0x3,0xfffffffc(%ebp). As was discussed in the “Referencing and Modifying Data on the Stack” section, we know that the destination address is on the stack given that it is an offset of the base pointer. Figure 5.7 shows the DDD session after the next “stepi” instruction is issued. Notice how the first line in the data display of the stack is highlighted showing us that a value in there has changed. We can also see that our value of 3 has been copied onto the stack at address 0xbffff2a4.
请注意, 箭头指向要执行的下一个指令, 它是 movl $ 0x3,0xfffffffc (%ebp)。正如在 "在堆栈上引用和修改数据" 一节中讨论的那样, 我们知道目标地址在栈上, 因为它是基指针的偏移量。图5.7 显示了下一个 "stepi" 指令发出后的 DDD 会话。请注意, 高亮显示栈数据中的第一行, 以显示其中的值已更改。我们还可以看到, 我们的值3已被复制到栈上的地址0xbffff2a4。
Figure 5.7. stack.c in a DDD session, part 2.
5.8. Examining the Raw Stack in Detail
Now that we know all the registers and instructions involved with the stack and how to display it in a debugger, let’s examine the raw stack in detail. For this section, let’s again use stack.c from prior sections as our example. To get some interesting data on the stack, let’s compile and run stack3.c and set a breakpoint in function3. When we’re stopped in function3, let’s display our stack using the command graph display ‘x/48wx$esp’.
现在我们知道了栈所涉及的所有寄存器和指令以及如何在调试程序中显示它, 让我们详细检查原始栈。对于本节, 让我们再次使用前面的部分stack. c 作为我们的例子。要获取栈上的一些有趣的数据, 让我们编译并运行 stack3.c, 并在 function3 中设置断点。当我们停在 function3时, 让我们使用命令图形' x/48 wx $ esp '显示我们的栈。
Tip: When you find that you’re typing similar lengthy commands over and over, it may be time to create a GDB user-defined function. To do this and to ensure it is usable when you restart GDB/DDD, add the following lines to your $HOME/.gdbinit file:
提示: 当您发现您在多次键入类似冗长的命令时, 可能是创建 GDB 用户定义函数的时候了。为此, 并确保在重新启动 GDB/DDD 时可用, 请将以下行添加到 $HOME gdbinit 文件中:
define rawstack
graph display 'x/48wx$esp'
end
document rawstack
Display the top 48 hex words on the stack (requires
DDD).
end
Now whenever you type rawstack, the raw stack will be displayed in the data display window of DDD.
现在, 每当您键入 rawstack 时, 原始堆栈将显示在 DDD 的数据显示窗口中。
Figure 5.8 shows our initial DDD session after executing the instruction that sets the value of our stack variable dummy to ’\0’. We can see that the line in DDD’s data display of the stack that holds the value of dummy has been highlighted to show that something changed after running the last instruction.
图5.8 显示了我们的首次 DDD 会话, 执行指令后, 将栈变量的值设置为 "\ 0"。我们可以看到, 在 DDD 的数据显示栈中保留值的行被突出显示, 以表明在运行最后一个指令后发生了变化。
Figure 5.8. DDD showing the raw stack.
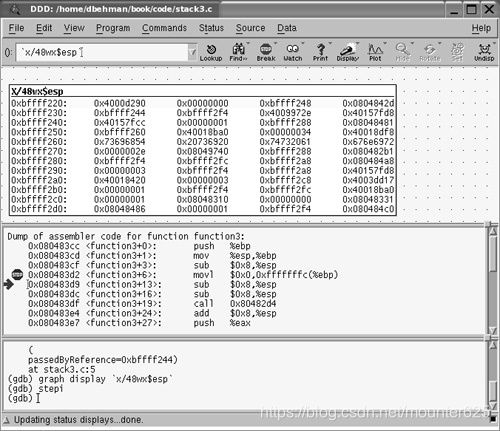
This tells us just from quickly looking at the display of our stack that the address of dummy is 0xbffff224. But why doesn’t esp point to the address of dummy, which is the only thing on our stack thus far? Looking at function3’s prolog, we see the instruction:
通过快速查看我们的栈显示,我们可以知道 ,内存地址是0xbffff224。但是, 为什么 esp 不指向内存地址, 这是目前为止,我们的栈显示的唯一的东西?看 function3的序言, 我们看到的指令:
0x080483cf
which opens eight bytes of space on the stack. The only stack variable in function3 is “dummy”, which is only four bytes wide. So why the extra four bytes of garbage? The answer lies in the fact that an unaligned stack on the x86 architecture can negatively affect performance. GCC is taking this into account at the cost of wasted space on the stack. Notice that there is a call to printf() and a call to fgetc() in function3. If you remove these calls from stack3.c, recompile, and examine function3’s prologue again, you’ll see that the sub instruction moves the esp register by 4 instead of 8. This is because GCC knows about the entire program’s memory usage and therefore doesn’t have to worry about external function calls. When there are external function calls, GCC assumes the worst and takes precautions to properly align the stack.
它在堆栈上打开八字节的空间。function3 中唯一的堆栈变量是 "dummy", 它的宽度只有四个字节。那么, 为什么要额外申请四个字节?答案在于, x86 体系结构上的栈没有对齐会对性能产生负面影响。GCC 正在考虑这个问题, 代价是浪费栈上的空间。请注意, 在 function3 中调用 printf () 和 fgetc ()。如果从 stack3.c 中删除这些调用, 重新编译并再次检查 function3的序言, 您将看到 sub 指令将 esp 寄存器移动4而不是8。这是因为 GCC 知道整个程序的内存使用情况, 因此不必担心外部函数调用。当有外部函数调用时, GCC 假定最坏的情况, 并采取正确的预防措施对齐堆栈。
Tip: GCC’s default stack aligning behavior can be overridden with the -mpreferred-stack-boundary=NUM parameter, where NUM will be the power that 2 is raised to for calculating the boundary value. NUM’s default value is 4, which means the default boundary is 16 bytes.
提示: GCC 的默认栈对齐行为可以用 -mpreferred-stack-boundary=NUM 参数来替代, 其中 NUM 将是为计算边界值而计算的2的幂。NUM 的默认值为 4, 表示默认边界为16字节。
So now that we know what the top two values on our stack are, let’s look at the third word, which is address 0xbffff228 and contains the value 0xbffff248. The value should also set off red lights. We’ve learned in previous sections that an executable gets mapped to 0x08048000 in the process address space, so it’s a pretty good guess that this address is pointing to an instruction in the executable. We can use the debugger to help our investigation. Since we think it’s an instruction, let’s try to disassemble the function that contains this address.
因此, 既然我们知道了我们的栈上的前两个值是什么, 让我们来看看第三个字, 这是地址 0xbffff228, 包含值0xbffff248。该值还应设置红色指示灯。我们在前几节中了解到, 可执行文件将映射到进程地址空间中的 0x08048000, 因此很好地猜测此地址指向可执行文件中的指令。我们可以使用调试器来帮助我们进行调查。因为我们认为这是一个指令, 让我们尝试拆卸包含这个地址的函数。
(gdb) disas 0x0804842d
Dump of assembler code for function function2:
0x08048414
0x08048415
0x08048417
0x0804841a
0x08048421
0x08048424
0x08048427
0x08048428
0x0804842d
0x08048430
0x08048433
0x08048436
0x0804843b
0x08048440
0x08048443
0x08048444
End of assembler dump.
(gdb)
Looking at the instruction that immediately precedes the instruction at 0x0804842d, we see the instruction used to call function3. So now we know that value 0x0804842d is the return instruction pointer. The call assembly instruction itself is responsible for pushing this value onto the stack. At the end of a function, the ret instruction is used to send execution back to the instruction immediately following the call instruction.
看一下在0x0804842d 指令前面的指令, 我们看到了用来调用 function3 的指令。所以现在我们知道值0x0804842d 是返回指令指针。调用汇编程序指令本身负责将此值推送到栈上。在函数的末尾, 使用 ret 指令将执行发送回紧接调用指令之后的指令。
Looking further in the stack, at the address 0xbffff230, we see the value 0xbffff244. The value certainly looks like a stack address; looking at that address, we see 0x00000001. This is certainly curious and looks like it could be function2’s localInt stack variable. Using the debugger to help us, we see:
在堆栈中进一步查找, 在地址0xbffff230 中, 我们看到了值0xbffff244。该值看起来像一个堆栈地址;查看那个地址, 我们看到了0x00000001。这显然很奇怪, 看起来它可能是 function2的 localInt 栈变量。调试器可以帮助我们, 我们看到:
(gdb) frame 1
#1 0x0804842d in function2 (paramString=0xbffff260 "This is a string.")
at stack3.c:16
(gdb) print &localInt
$1 = (int *) 0xbffff244
(gdb)
So the value stored at 0xbffff230 seems to be a pointer to a stack variable. Looking at function2’s source code, we see that we call function3 with the address of localInt! This makes perfect sense because function parameters are pushed onto the stack immediately before a call to a function, and we can see this in function2’s assembly:
因此, 存储在0xbffff230 上的值似乎是指向栈变量的指针。查看function2的源代码, 我们看到我们用 localInt 的地址来称呼 function3!这很有意义, 因为函数参数在调用函数之前立即推送到栈上, 我们可以在 function2 汇编程序中看到这一点:
leal -4(%ebp), %eax
pushl %eax
call function3
This assembly sequence loads the effective address (the lea instruction) of our stack variable localInt (referenced by -4(%ebp) in assembly) into the eax register. This address then gets pushed onto the stack, and function3 is then called.
此汇编程序加载我们的栈变量 localInt (在汇编程序中引用 -4 (%ebp))的有效地址 (lea 指令) 到 eax 寄存器中。然后, 该地址被推送到栈上, 然后调用 function3。
The values stored at addresses 0xbffff234, 0xbffff238, 0xbffff23c, and 0xbffff40 are all garbage because of stack alignment. We know this by looking at the two subl instructions used to move the stack pointer in function2.
由于栈对齐方式, 存储在地址0xbffff234、0xbffff238、0xbffff23c 和0xbffff40 上的值都是无用的。通过查看用于在 function2 中移动堆栈指针的两个 subl 指令来了解这一点。
We already know that localInt is stored at 0xbffff244, so let’s now look at 0xbffff248. The value stored here is 0xbffff288, which again looks like a stack address. It’s very likely a base pointer. We now know that a return instruction address follows a base pointer on the stack, so let’s first look at the next word in the stack at address 0xbffff24c. Here we see the value 0x08048481, which definitely does look like an executable instruction address. Using the debugger, we see:
我们已经知道 localInt 存储在 0xbffff244, 所以现在让我们来看看0xbffff248。这里存储的值是 0xbffff288, 它看起来又像一个栈地址。它很可能是一个基指针。现在, 我们知道返回的指令地址与栈上的基指针相关, 所以让我们先看一下栈中地址0xbffff24c 的下一个字。在这里, 我们看到的值 0x08048481, 这绝对看起来像一个可执行的指令地址。使用调试器, 我们看到:
Code View: Scroll / Show All
(gdb) disas 0x08048481
Dump of assembler code for function function1:
0x08048445
0x08048446
0x08048448
0x0804844b
0x08048450
0x08048453
0x08048458
0x0804845b
0x08048460
0x08048463
0x08048468
0x0804846b
0x08048471
0x08048475
0x08048478
0x0804847b
0x0804847c
0x08048481
0x08048484
0x08048485
End of assembler dump.
(gdb)
Indeed, the instruction preceding 0x08048481 is a call to function2, so we can confirm that the stack address 0xbffff248 does indeed hold a base pointer.
实际上, 前面的指令0x08048481 是调用function2, 因此我们可以确认栈地址0xbffff248 确实保存基指针。
The analysis of a raw stack can continue in this fashion all the way through to the beginning of a function. Armed with the assembly and the source code, any stack analysis can be done fairly easily. Even without the source code, stack analysis is possible. The next section will build on the patterns observed here to create a homegrown stack traceback very similar to what GDB’s “backtrace” shows.
对原始栈的分析可以一直以这种方式贯穿到函数的开头。有了汇编程序和源代码, 任何栈分析都可以相当容易地完成。即使没有源代码, 堆栈分析也是可能的。下一部分将建立在这里观察到的模式, 以创建一个本地的栈回溯非常类似于 GDB 的 "backtrace" 显示。
5.8.1. Homegrown Stack Traceback Function
One of the most important pieces of information to know when debugging a problem is the path of execution taken to get to the current point. A big part of this is examining the stack traceback output from GDB using the backtrace command. Very often, however, running the program under GDB or attaching to it is not possible because access to the machine is not available. This is where a homegrown stack traceback function is extremely useful to problem determination. The function can be called at any point throughout the program’s execution life; it can be called when a recoverable error is detected, when a non-recoverable error such as a segv is detected, or when code and execution analysis is needed. For GNU/Linux, two ways of accomplishing this will be discussed as certain environments may be limited in what can be used.
调试问题时要知道的最重要的信息之一是到达当前点所采用的执行路径。其中很大一部分是使用backtrace命令检查 GDB 的栈回溯输出。然而, 通常情况下, 在 GDB 下运行程序或附加到它是不可能的, 因为无法访问机器。本地的栈回溯功能对问题确定非常有用。该功能可以在整个程序的生命周期中的任何时候调用;当检测到不可恢复的错误 (如检测到 segv) 或需要代码和执行分析时, 可以调用该功能。对于 GNU/Linux, 将讨论两种实现方法, 因为某些环境可能会被限制使用。
5.8.1.1. Using GLIBC’s backtrace()
GLIBC includes several functions that can be used to display a stack from within a running program. The main function is called backtrace() and has this prototype:
GLIBC 包括几个可用于在运行中的程序中显示堆栈的函数。主函数称为backtrace() 并具有此函数声明:
int backtrace (void **BUFFER, int SIZE)
SIZE determines the maximum number of frames backtrace will “walk” through, and BUFFER is an array of void pointers wherein backtrace will store the return instruction pointer. To convert the return instruction address pointers into more meaningful information, the function backtrace_symbols() is provided. Its prototype is:
SIZE确定backtrace将 "遍历" 的最大帧数, 而BUFFER是空指针的数组, 其中backtrace将存储返回指令指针。为了将返回指令地址指针转换为更有意义的信息, 提供了函数 backtrace_symbols ()。其函数声明是:
char ** backtrace_symbols (void *const *BUFFER, int SIZE)
The parameters are the same as those of the backtrace() function. An array of strings will be returned. The number of strings will be SIZE, and the memory for the strings is allocated within backtrace_symbols(). It is up to the caller to free the memory used by the array of strings. The following is a sample program that makes use of these APIs.
这些参数与backtrace () 函数相同,将返回字符串数组。字符串的数量将是SIZE, 并且字符串的内存在 backtrace_symbols () 内分配。由调用方来释放字符串数组所使用的内存。下面是一个使用这些 API 的示例程序。
Code View: Scroll / Show All
#include
#include
void print_gnu_backtrace( void )
{
void *frame_addrs[16];
char **frame_strings;
size_t backtrace_size;
int i;
backtrace_size = backtrace( frame_addrs, 16 );
frame_strings = backtrace_symbols( frame_addrs, backtrace_size );
for ( i = 0; i < backtrace_size; i++ )
{
printf( "%d: [0x%x] %s\n", i, frame_addrs[i], frame_strings[i]);
}
free( frame_strings );
}
int foo( void )
{
print_gnu_backtrace();
return 0;
}
int bar( void )
{
foo();
return 0;
}
int boo( void )
{
bar();
return 0;
}
int baz( void )
{
boo();
return 0;
}
int main( void )
{
baz();
return 0;
}
Compiling and running this program produces the following:
编译和运行此程序将生成以下内容:
penguin> gcc -o bt_gnu backtrace_gnu.c
penguin> ./bt_gnu
0: [0x8048410] ./bt_gnu(backtrace_symbols+0xe4) [0x8048410]
1: [0x8048485] ./bt_gnu(backtrace_symbols+0x159) [0x8048485]
2: [0x8048497] ./bt_gnu(backtrace_symbols+0x16b) [0x8048497]
3: [0x80484a9] ./bt_gnu(backtrace_symbols+0x17d) [0x80484a9]
4: [0x80484bb] ./bt_gnu(backtrace_symbols+0x18f) [0x80484bb]
5: [0x80484d7] ./bt_gnu(backtrace_symbols+0x1ab) [0x80484d7]
6: [0x4003dd17] /lib/i686/libc.so.6(__libc_start_main+0xc7) [0x4003dd17]
7: [0x8048361] ./bt_gnu(backtrace_symbols+0x35) [0x8048361]
Wait a second! Why do all the function names appear to be backtrace_symbols except for __libc_start_main? The answer lies in the fact that symbol names in a shared library are exported; whereas, the static symbols in the executable are not. So in this case, the shared library libc contains the exported function __libc_start_main, but all other symbols are static to the executable and do not appear in the dynamic symbol table. A workaround exists for this problem, which tells the linker to export all symbols to the dynamic symbol table. To use this workaround, recompile the program with the -rdynamic parameter (see the end of this section for more information).
等一下!除了 __libc_start_main 之外, 为什么所有的函数名看起来都是 backtrace_symbols 的?答案在于共享库中的符号名被导出; 但是, 可执行文件中的静态符号没有被导出。因此, 在这种情况下, 共享库 libc 包含导出的函数 __libc_start_main, 但所有其他符号都是静态的, 并且不会出现在动态符号表中。对此问题的变通方法, 它告诉链接器将所有符号导出到动态符号表中。要使用此变通办法, 请用 -rdynamic 参数重新编译程序 (有关详细信息, 请参阅本节末尾)。
penguin> gcc -o bt_gnu backtrace_gnu.c -rdynamic
penguin> ./bt_gnu
0: [0x8048730] ./bt_gnu(print_gnu_backtrace+0x14) [0x8048730]
1: [0x80487a5] ./bt_gnu(foo+0xb) [0x80487a5]
2: [0x80487b7] ./bt_gnu(bar+0xb) [0x80487b7]
3: [0x80487c9] ./bt_gnu(boo+0xb) [0x80487c9]
4: [0x80487db] ./bt_gnu(baz+0xb) [0x80487db]
5: [0x80487f7] ./bt_gnu(main+0x15) [0x80487f7]
6: [0x4003dd17] /lib/i686/libc.so.6(libc_start_main+0xc7) [0x4003dd17]
7: [0x8048681] ./bt_gnu(backtrace_symbols+0x31) [0x8048681]
As you can see, this works much better. However, frame 7 doesn’t appear to be correct. If we look at this executable under a debugger, we will find that the return instruction pointer 0x8048681 is in the _start function. This function is fundamental to the execution of programs on Linux and cannot be made dynamic, so this explains why the backtrace function still displays the incorrect name for this symbol. To avoid confusion, the for loop in our print_gnu_backtrace function could be modified to never display the frame containing __libc_start_main nor the following frame, which would be the frame for _start.
正如你所看到的, 这工作得更好。但是, 帧7似乎不正确。如果我们在调试器下查看这个可执行文件, 我们会发现返回指令指针0x8048681 在 _start 函数中。此函数对 Linux 上的程序执行是至关重要的, 无法进行动态操作, 因此这解释了为什么backtrace仍然显示此符号的名称不正确。为了避免混淆, 我们的 print_gnu_backtrace 函数中的 for 循环可以被修改为永远不会显示包含 __libc_start_main 的帧, 也不会出现其后面的帧, 即_start帧。
5.8.1.1.1. The -rdynamic Switch
If you search through GCC and LD’s documentation for -rdynamic, you likely won’t find anything. GCC converts the -rdynamic switch into -export-dynamic, which gets passed to the linker. With this in mind, an alternative compile line for backtrace_gnu.c would be:
如果你在 GCC 和 LD 的文档中搜索 -rdynamic, 你可能找不到任何东西。GCC 将 -rdynamic 转换为-export-dynamic, 并将其传递给链接器。考虑到这一点, backtrace_gnu 的一个替代编译行是:
gcc -o bt_gnu backtrace_gnu.c -Wl,—export-dynamic
or simpler yet
gcc -o bt_gnu backtrace_gnu.c -Wl,-E
5.8.1.2. Manually “Walking the Stack”
Another method for implementing a stack backtrace function on the x86 architecture is to apply our knowledge of the raw layout of the stack to manually “walk” it frame by frame. As we find each frame and return instruction pointer, we can use the undocumented function dladdr found in the /usr/include/dlfcn.h header file to determine symbol names. Note that the same concepts discussed here can be applied on the x86_64 architecture. For this reason, the discussion will be focused on x86, followed by a discussion on getting this function working on x86_64.
The source code for a program, which demonstrates the manual stack walking, is as follows:
在 x86 体系结构上实现栈backtrace的另一种方法是根据我们对栈原始布局的了解, 手动 "遍历" 帧。当我们找到每个帧和返回指令指针时, 我们可以使用 dladdr(/usr/include/dlfcn.h定义)确定符号名称。请注意, 此处讨论的概念可以应用于 x86_64 体系结构。因此, 讨论将集中在 x86, 然后讨论如何在 x86_64 上工作。程序的源代码 (演示手动堆栈遍历) 如下所示:
Code View: Scroll / Show All
#define _GNU_SOURCE
#include
#include
void **getEBP( int dummy )
{
void **ebp = (void **)&dummy - 2;
return( ebp );
}
void print_walk_backtrace( void )
{
int dummy;
int frame = 0;
Dl_info dlip;
void **ebp = getEBP( dummy );
void **ret = NULL; /* return instruction pointer */
printf( "Stack backtrace:\n" );
while( *ebp )
{
ret = ebp + 1;
dladdr( *ret, &dlip );
printf( " Frame %d: [ebp=0x%08x] [ret=0x%08x] %s\n",
frame++, *ebp, *ret, dlip.dli_sname );
ebp = (void**)(*ebp); /* get the next frame pointer */
}
}
int foo( void )
{
print_walk_backtrace();
return 0;
}
int bar( void )
{
foo();
return 0;
}
int boo( void )
{
bar();
return 0;
}
int baz( void )
{
boo();
return 0;
}
int main( void )
{
baz();
return 0;
}
The first point of interest in this code is the #define _GNU_SOURCE. This is needed to enable GNU extensions, in particular, the use of the dladdr() function. Note this line must come before any #include lines.
此代码的第一个兴趣点是 #define _GNU_SOURCE。这是需要启用 GNU 扩展, 特别是使用 dladdr () 函数。注意此行必须在 #include 行之前出现。
The next line worth mentioning is the #include
值得一提的下一行是 #include
Next we see the function getEBP. This function, as the name says, is used to set a pointer directly to what the EBP register is pointing to in getEBP’s frame. When this is found, “walking the stack” is very easy. The term “walking the stack” refers to the iterative act of examining the frame pointer and dereferencing it to find the next frame pointer. This continues until dereferencing results in 0 or NULL. Figure 5.9 shows a data display of the raw stack for our stack3.c program. The base pointers are highlighted, and as you can see, dereferencing each one refers to the next one until 0x00000000.
接下来, 我们将看到函数 getEBP。顾名思义, 此函数用于将指针直接设置为 EBP 寄存器在 getEBP 帧中指向的内容。当发现这一点, "遍历栈" 是很容易的。"遍历栈" 一词是指检查帧指针并取消引用以查找下一个帧指针的迭代行为。这将持续进行, 直到取消引用为0或 NULL。图5.9 显示了 stack3.c 原始栈的数据显示。将突出显示基指针, 如您所见, 取消引用每个引用都指下一项, 直到0x00000000。
Figure 5.9. Walking the raw stack.
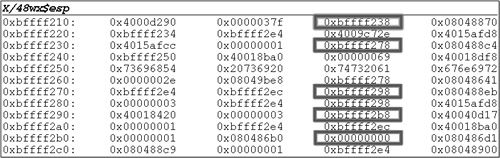
This concept of dereferencing pointers might set off alarms for the seasoned C programmer. We can easily use pointers in C to programmatically accomplish this for us. The key to walking the stack is being able to first reliably find the EBP on the stack. We can determine this by observing what happens during a function call on the x86 architecture:
Function parameters are pushed onto the stack.
The call instruction pushes the return instruction pointer onto the stack.
Execution is passed to the start of the callee function.
The function prologue pushes the value in the ebp register onto the stack.
The body of the function is executed.
这种取消引用指针的概念可能会为经验丰富的 C 程序员设置警报。我们可以轻松地使用 C 中的指针以编程方式为我们完成此任务。遍历栈的关键是能够首先可靠地找到栈上的 EBP。我们通过观察 x86 体系结构上函数调用过程中发生的情况来确定这一点:
函数参数被推送到栈上。
调用指令将返回指令指针推送到栈上。
执行被传递到被调用函数的开始处。
函数序言将 ebp 寄存器中的值推送到栈上。
执行该函数的主体部分。
The trick is to take the address of the passed-in parameter and use pointer arithmetic to subtract 2 from it. The 2 is used to move the pointer over the return instruction pointer and then to the start of the base pointer.
诀窍是取传入参数的地址, 并使用指针算术减去2。2用于将指针移到返回指令指针上, 然后移动到基指针的开始处。
Now we know it is pretty easy to get to get all the frame pointer values. However, displaying these to the user is not very informative; displaying the function names would be much better. This is where the use of the dladdr function becomes apparent. The trick now is to make use of the fact that the return instruction pointer is always next to the base pointer on the stack. Again using C pointer arithmetic, we can easily obtain the return instruction pointer and pass this into the dladdr function, which will fill a structure containing symbol information for that address. The structure definition and prototype for dladdr (taken from /usr/include/dlfcn.h on a SuSE 9.0 Professional system) is:
现在, 我们知道它是相当容易得到所有的帧指针值。但是, 向用户显示这些信息并不十分丰富;显示函数名称将会好得多。这就是需要 dladdr 函数的地方。现在的窍门是利用return指令指针始终位于栈上的base指针旁边的事实。再次使用 C 指针算法, 我们可以很容易地获得return指令指针, 并将其传递到 dladdr 函数中, dladdr将为该地址的结构体填充符号信息。dladdr 的结构定义和原型 (从 SuSE 9.0 专业版系统/usr/include/dlfcn.h中提取) 是:
#ifdef __USE_GNU
/* Structure containing information about object searched using
'dladdr'. */
typedef struct
{
__const char *dli_fname; /* File name of defining object. */
void *dli_fbase; /* Load address of that object. */
__const char *dli_sname; /* Name of nearest symbol. */
void *dli_saddr; /* Exact value of nearest symbol. */
} Dl_info;
/* Fill in *INFO with the following information about ADDRESS.
Returns 0 iff no shared object's segments contain that address. */
extern int dladdr (__const void *__address, Dl_info *__info) __THROW;
Looking at print_walk_backtrace, after getting the base pointer, the return instruction pointer is easily found using the following:
查看 print_walk_backtrace, 获取base指针后, 可以使用以下方法轻松找到return指令指针:
ret = ebp + 1;
After this is obtained, we can simply dereference ret and pass that into dladdrto have it determine the symbol name containing this address. After displaying the relevant information to the user, the next key in this function is to find the next frame pointer. This is done with this code:
在此之后, 我们可以简单地取消对 ret 的引用, 并将其传递到 dladdrto 中, 确定包含此地址的符号名称。在向用户显示相关信息后, 此函数中的下一个关键是查找下一帧指针。这是通过以下代码完成的:
ebp = (void**)(*ebp);
If the new value of ebp is not NULL, we perform the same steps again. If it is NULL, we know that we’ve hit the end of the stack, so we terminate the loop.
如果 ebp 的新值不是 NULL, 我们将再次执行相同的步骤。如果它是 NULL, 我们知道已经达到了栈的末尾, 所以我们终止循环。
Note that the same issue that prevented the proper symbol names from being displayed when using GLIBC’s backtrace function will affect this program. We must be sure to compile with the -rdynamic flag here as well. Compiling and running our manual stack walking program produces:
注意, 在使用 GLIBC 的backtrace功能时, 阻止显示正确的符号名称的相同问题将影响此程序。我们也一定要在这里用 -rdynamic 项编译。编译和运行我们的手动遍历栈程序产生如下错误:
penguin> gcc -o bt_walk backtrace_walk.c -rdynamic -g
/tmp/ccEiAjgE.o(.text+0x65): In function 'print_walk_backtrace':
/home/dbehman/book/code/backtrace_walk.c:23: undefined reference to
'dladdr'
collect2: ld returned 1 exit status
What happened? Note that this error is being produced by the linker and not GCC, so we compiled successfully but did not link properly. The linker was unable to find dladdr, which is a somewhat unusual function that isn’t used all the time. dladdr is in the family of functions used to manipulate dynamic libraries. The seasoned Unix programmer will know that these functions are provided in the libdl.so shared system library.
发生了什么事?注意, 此错误是由链接器而不是 GCC 生成的, 因此我们已成功编译, 但未正确链接。链接器找不到 dladdr, 这是一个有点不寻常的函数, 一直没有使用。dladdr 是用于操作动态库的函数。经验丰富的 Unix 程序员将知道这些函数是在 libdl.so 中提供的。
Note: If you’re not a seasoned Unix programmer, how could you find out what library dladdr was defined in? Use the nm(1) utility to dump the symbols from all system libraries and grep the output for the symbol we want - in this case, dladdr.
注意: 如果你不是一个经验丰富的 Unix 程序员, 你怎么能找到dladdr在什么库里定义?使用 nm (1) 实用程序从所有系统库中转储符号, 并对所需符号的输出进行 grep。在本例中为 dladdr。
penguin> nm -A /lib/*.so* | grep dladdr
/lib/libdl.so.2:00001680 T dladdr
/lib/libdl.so.2:000016b0 T dladdr1
Recompiling and running now produces:
重新编译和运行现在生成:
penguin> ./bt_walk
Stack backtrace:
Frame 0: [ebp=0xbffff2c8] [ret=0x08048755] print_walk_backtrace
Frame 1: [ebp=0xbffff2d8] [ret=0x08048795] foo
Frame 2: [ebp=0xbffff2e8] [ret=0x080487a7] bar
Frame 3: [ebp=0xbffff2f8] [ret=0x080487b9] boo
Frame 4: [ebp=0xbffff308] [ret=0x080487cb] baz
Frame 5: [ebp=0xbffff318] [ret=0x080487e7] main
Frame 6: [ebp=0xbffff338] [ret=0x40040d17] __libc_start_main
This is exactly the output we want! An advantage of using this method over GLIBC’s backtrace() is that the output is 100% configurable.
这正是我们想要的输出!在 GLIBC 的backtrace () 上使用此方法的优点是输出是100% 可配置的。
5.8.1.2.1. Modifying for x86-64
Because the x86-64 architecture is so similar to the x86 architecture, many of the same concepts apply there as well. The big difference however, is that the function calling conventions for x86-64 work differently than on x86. Rather than all function parameters being pushed on the stack as they are on x86, parameters are passed in a specified set of registers. What this means for our manual stack walking program is that our getEBP function must be modified accordingly. After examining the assembly instructions used in a function call such as getEBP, we can see that the function parameter gets copied from the register used to pass it onto the stack immediately after the frame pointer. We can then simply take the address of this parameter and add 1 to it to get the address of the previous frame pointer. The following code shows the modified getEBP, which has been renamed to getRBP considering all register names on x86-64 begin with R instead of E on x86. This is to distinguish them as 64-bit instead of 32-bit registers.
因为 x86-64 体系结构与 x86 体系结构非常相似, 所以许多相同的概念也适用于此。然而, 最大的不同之处在于, x86-64 的函数调用约定的工作方式不同于 x86。与 x86 上把所有函数参数推送到栈上相比, x86064的函数参数在一组指定的寄存器中传递。这意味着我们的手动遍历栈程序是我们的 getEBP 函数必须相应地修改。在检查函数调用 (如 getEBP) 中使用的汇编指令后, 我们可以看到函数参数从寄存器中复制, 在帧指针后立即将其传递到栈上。然后, 我们可以简单地获取此参数的地址, 并将其加1以获取上一个帧指针的地址。下面的代码显示修改后的 getEBP, 它已命名为 getRBP 考虑 x86-64 上的所有寄存器名称以 R 而不是 E 开始。这是为了区别他们..。
Code View: Scroll / Show All
void **getRBP( long dummy )
{
void **rbp = (void **)&dummy + 1;
return( rbp );
}
void print_walk_backtrace( void )
{
long dummy;
int frame = 0;
Dl_info dlip;
void **rbp = getRBP( dummy );
void *ret = *(rbp + 1);
void *save_rbp = *rbp;
printf( "Stack backtrace:\n" );
while( save_rbp )
{
dladdr( ret, &dlip );
printf( " Frame %d: [rbp=0x%016lx] [ret=0x%016lx] %s\n",
frame++, save_rbp, ret, dlip.dli_sname );
rbp = (void**)save_rbp;
save_rbp = *rbp;
ret = *(rbp + 1);
}
}
This code also shows the modified print_walk function. The main difference is that the RBP obtained from getRBP needed to be saved along with the return instruction pointer. The reason for this is because the function calls to printf and dladdr overwrite the top of the stack, thus rendering the initial values of the RBP, and return instruction pointer incorrect. Subsequent values remain untouched so the rest of the logic could remain pretty much intact. Other 64-bit specific changes were also made. Compiling and running the manual stack walking program with the functions modified for x86-64 yields:
此代码还显示修改后的 print_walk 函数。主要区别是从 getRBP 获得的RBP需要与return指令指针一起保存。之所以这样做是因为函数调用 printf 和 dladdr 覆盖栈的顶部, 从而改写RBP的初始值, 导致return指令指针不正确。其他的值保持不变, 所以其余的逻辑可以保持相当完整。另外还进行了与64位有关的更改。使用针对x86-64修改的函数编译和运行手动堆栈遍历程序:
Code View: Scroll / Show All
penguin> gcc -o bt_walk backtrace_walk_x86-64.c -ldl -rdynamic
penguin> ./bt_walk
Stack backtrace:
Frame 0: [rbp=0x0000007fbfffed20] [ret=0x000000004000080a] print_walk_backtrace
Frame 1: [rbp=0x0000007fbfffed30] [ret=0x00000000400008ae] foo
Frame 2: [rbp=0x0000007fbfffed40] [ret=0x00000000400008be] bar
Frame 3: [rbp=0x0000007fbfffed50] [ret=0x00000000400008ce] boo
Frame 4: [rbp=0x0000007fbfffed60] [ret=0x00000000400008de] baz
Frame 5: [rbp=0x0000007fbfffed70] [ret=0x00000000400008ee] main
Frame 6: [rbp=0x0000002a95669d50] [ret=0x0000002a95790017]
_libc_start_main
Take note with respect to compiling on x86-64—if we add the -O2 switch to tell GCC to optimize the code and run the program, we will see:
请注意关于编译x86-64,—如果我们添加了 -O2 选项, 告诉 GCC 优化代码并运行程序, 我们将看到:
penguin> gcc -o bt_walk backtrace_walk_x86-64.c -ldl -rdynamic -O2
penguin> ./bt_walk
Stack backtrace:
Memory fault
The reason for this is because on x86-64, GCC includes the -fomit-frame-pointer optimization option at the -O2 level. This instantly invalidates all of the assumptions we make based on the base pointer in our program. To correct this, we need to tell GCC not to omit the frame pointer:
原因是因为在 x86-64 上, GCC 在 O2 级别包括-fomit-frame-pointer优化选项。这立即使我们根据程序中的base指针所做的所有假设无效。为了纠正这一点, 我们需要告诉 GCC 不要省略帧指针:
penguin> gcc -o bt_walk backtrace_walk_x86-64.c -ldl -rdynamic -O2 -
fno-omit-frame-pointer
penguin> ./bt_walk
Stack backtrace:
Frame 0: [rbp=0x0000007fbfffed20] [ret=0x0000000040000857]
print_walk_backtrace
Frame 1: [rbp=0x0000007fbfffed30] [ret=0x00000000400008c9] foo
Frame 2: [rbp=0x0000007fbfffed40] [ret=0x00000000400008d9] bar
Frame 3: [rbp=0x0000007fbfffed50] [ret=0x00000000400008e9] boo
Frame 4: [rbp=0x0000007fbfffed60] [ret=0x00000000400008f9] baz
Frame 5: [rbp=0x0000007fbfffed70] [ret=0x0000000040000909] main
Frame 6: [rbp=0x0000002a95669d50] [ret=0x0000002a95790017]
__libc_start_main
5.8.1.3. Stack Corruption
A very common cause of abnormal program termination or other unexpected behavior is stack corruption. Often stack corruption bugs are caused by the now infamous buffer overrun problem, which many well-published computer viruses have used to hack computers on the Internet. Great care must be used by the programmer when working with buffers. The tips and techniques to use are important, but it is not the intention of this section to discuss them; rather, the intention is to illustrate what stack corruptions can do and how to debug them. Consider the following source code, which is a very simple illustration of a horrible buffer overrun coding flaw:
异常程序终止或其他意外行为的一个非常常见的原因是栈损坏。通常, 栈损坏 bug 是由现在臭名昭著的缓冲区溢出问题引起的, 许多计算机病毒在 Internet 上用缓冲区溢出入侵计算机。在使用缓冲区时, 程序员必须非常小心。使用的技巧和技术很重要, 但本节无意讨论它们;相反,本节的目的是说明栈损坏的危害以及如何调试它们。考虑下面的源代码, 这是一个非常简单的例子, 一个可怕的缓冲区溢出编码错误:
#include
int main ( int argc, char *argv[] )
{
int foo = 3;
int bar = 9;
char string[8];
strcpy( string, argv[1] );
printf( "foo = %d\n", foo );
printf( "bar = %d\n", bar );
return 0;
}
In fact, it hurt to write this code because it is so bad! To the inexperienced developer, however, this code could look very normal and legitimate—we want the user to specify a command-line argument of, say, one or two characters and store that value in our string for later use. However, when a user disregards our expectations and passes in a larger command-line parameter than we expect, all heck breaks loose. Let’s try this out:
事实上, 写这段代码很痛苦, 因为它太糟糕了!但是, 对于经验不足的开发人员来说, 此代码看起来非常正常和合法-我们希望用户指定一个或两个字符的命令行参数, 并将该值存储在字符串中以供以后使用。但是, 当用户忽略了我们的期望并传递了比我们预想的更大的命令行参数时, 所有这些都将中断。让我们尝试一下:
penguin> ./stack_corruption aaaaaaaaaaaa
foo = 0
bar = 1633771873
Ouch! How did foo and bar change from their assigned values of 3 and 9 respectively? The answer is: a buffer-overrun! To verify, using gdb to convert 1633771873 into hex reveals:
哎哟!foo 和 bar 是如何从各自的3和9的赋值中改变的?答案是: 缓冲区溢出!为了验证, 使用 gdb 将1633771873转换为十六进制显示:
(gdb) p /x 1633771873
$1 = 0x61616161
(gdb)
Of course, 0x61 is the ASCII representation of our evil letter a. But why is foo 0? This is because the strcpy() function copies the entire source string to the destination string (without any bounds checking) and adds a NULL terminating character with an ASCII hex value of 0x00.
当然, 0x61 是我们邪恶字母 a 的 ASCII 表示。但为什么 foo 0?这是因为 strcpy () 函数将整个源字符串复制到目标字符串 (不进行任何边界检查), 并添加一个具有 ASCII 十六进制值0x00 的 NULL 终止字符。
As you can see, the values we expected our foo and bar variables to be and the values they ended up to be after a simple (but very poorly used) strcpy call are very different, which can easily lead to very bad things happening in a program. Buffer overruns also often cause segmentation violation traps. Some of the memory in the stack that gets overwritten could be pointers, which after corruption, will very likely point to an unreadable area of memory. It’s also possible for the overrun to overwrite the function’s return address with a bad value—thus causing execution to jump to an invalid area of memory and trap. This is how hackers exploit buffer overruns.
正如你所看到的, 我们希望我们的 foo 和 bar 变量的值和他们最终的值,在一个简单 (但非常不常用) 的 strcpy 调用后,变得非常不同的, 在一个程序中这可能容易导致非常糟糕的事情发生。缓冲区溢出还经常导致segmentation violation traps。栈中某些被覆盖的内存可能是指针, 在损坏之后, 可能会指向无法读取的内存区域。溢出还可能用错误的值覆盖函数的返回地址, 从而导致执行跳转到内存和陷阱的不合法区域。这就是黑客利用缓冲区溢出的方式。
5.8.1.4. SIGILL Signals
Stack corruption can often lead to an illegal instruction signal, or SIGILL, being raised in your program. If the return address for a frame is overwritten by buffer overrun, execution will attempt to jump to that return instruction and continue executing instructions. This is where the SIGILL can occur. A SIGILL can also occur when the stack overflows or when the system encounters a problem executing a signal handler.
栈损坏通常会导致程序中引发非法指令或 SIGILL。如果帧的返回地址被缓冲区溢出覆盖, 则执行将尝试跳转到该return指令并继续执行指令。这就是 SIGILL 可能发生的地方。当栈溢出或系统遇到执行信号处理程序的问题时, 也会发生 SIGILL。
5.8.1.4.1. Signals and the Stack
Signals are an important resource provided by Unix-based operating systems, and Linux provides a full feature implementation of them. It is important to understand how a signal manipulates the user-land stack, but knowing the gory details is not necessary.
信号是基于 Unix 的操作系统提供的重要资源, Linux 提供了信号功能的完整实现。重要的是要了解一个信号如何操纵用户栈, 但知道血淋淋的细节是没有必要的。
Note: For this particular discussion, “stack” needs to be qualified as either “user” or “kernel” considering both modes have their own stack and are very different.
注: 对于这个特殊的讨论, "栈" 需要被限定为 "用户" 或 "内核", 这两种模式都有自己的栈, 它们是非常不同的。
A Linux application has the ability to define what to do when a particular signal is received either from the kernel or from another application. When the application is configured to execute a signal handler for a particular signal, the kernel must perform some intricate trickery to ensure that this functionality works properly.
Linux 应用程序可以定义从内核或其他应用程序接收特定信号时要执行的操作。当应用程序配置为为特定信号执行信号处理程序时, 内核必须执行一些复杂的操作, 以确保此功能正常工作。
Basically, when a process receives the signal sent to it, the following happens:
基本上, 当进程收到发送给它的信号时, 会发生以下情况:
The kernel copies its internal view of the process’ hardware context directly onto the user-land process’ stack.
内核将其进程的硬件上下文的内部视图,直接复制到用户进程堆栈上。
The kernel modifies the user-land process’ stack to force a call to sigreturn after the execution of the signal handler in user-mode completes.
内核修改用户进程栈, 以强制在用户模式中的信号处理程序执行完毕后调用 sigreturn。
The kernel forces the address of the signal handler that was defined by the application into the user-land process’ program counter register.
内核将应用程序定义的信号处理程序的地址强制复制到用户进程程序计数器寄存器中。
The kernel passes execution over to the user process.
内核将执行传递到用户进程。
The user process executes the signal handler.
用户进程执行信号处理程序。
The signal handler completes, and sigreturn is called as setup by the kernel.
信号处理程序完成, 如内核设置,sigreturn被调用。
sigreturn copies the hardware context that was saved on the user-land process’ stack back onto the kernel stack.
sigreturn 将保存在用户进程栈上的硬件上下文复制回内核栈上。
The user process’ stack is restored back to normal by removing the extra information copied to it by the kernel.
通过删除内核复制给它的额外信息, 用户进程栈恢复正常。
Execution continues at the point at which the signal was received.
在接收信号的点继续执行。
The main point to understand here is that when executing in a signal handler, the user-land process’ stack is modified by the kernel.
这里要理解的一点是, 在信号处理程序中执行时, 内核会修改用户进程栈。
5.9. Conclusion
The stack really is nothing more than a big chunk of memory that grows and shrinks as a program runs. Without a stack, programs would be extremely limited and probably a lot more complex. Understanding how the stack works is a huge step toward successfully troubleshooting some of the most difficult problems that an application on Linux can present you with.
在程序运行时, 栈实际上只不过是一大块内存, 它会随之增长和缩小。如果没有栈, 程序将非常有限, 也可能会更复杂。了解栈的工作原理,是迈向成功地解决 Linux 上的应用程序可以呈现给你的一些最困难问题的一大步。