Linux性能优化 - CPU优化
目录
1.性能统计信息
1.1.平均负载率
1.2.上下文切换
1.3.CPU使用率
1.3.1.CPU使用率过高怎么办
2.linux性能工具
2.1.CPU性能指标
2.2.根据工具查指标
3.性能调优策略
3.1.应用程序优化
3.2.系统优化
1.性能统计信息
每一种系统级Linux性能工具都提供了不同的方式来提取相似的统计结果。虽然没有工具能显示全部的信息,但是有些工具显示的是相同的统计信息。
1.1.平均负载率
平均负载是指单位时间内,系统处于 可运行状态 和 不可中断状态 的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
可运行状态的进程
是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。
不可中断状态的进程
是正处于内核态关键流程中的进程,并且这些流程是不可打断的, 比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态 (Uninterruptible Sleep,也为 Disk Sleep)的进程。
(比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。 所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。 )
uptime命令
uptime查看系统负载是执行uptime来了解系统的负载情况。
[root@centos7-1 ~]# uptime
16:01:25 up 15 min, 1 user, load average: 0.00, 0.02, 0.05
[root@centos7-1 ~]#16:01:25 // 当前时间
up 15 min // 系统运行时间
1 user // 正在登录用户数
load average: 0.00, 0.02, 0.05 //三个数字呢,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载- 如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
- 如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。
- 如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就 得分析调查是哪里导致的问题,并要想办法优化了。
平均负载为多少时合理
平均负载最理想的情况是等于 CPU 个数。所以在评判平均负载时,首先要知道系统有几个 CPU,这可以通过 top 命令或者从文件 /proc/cpuinfo 中读取:
# 关于 grep 和 wc 的用法请查询它们的手册或者网络搜索
[root@centos7-1 ~]# grep 'model name' /proc/cpuinfo | wc -l
1当平均负载比 CPU 个数还大的时候,系统已经出现了过载。在观察负载数据时,有三个时间点的数据,因此都要看。三个不同时间间隔的平均值,其实给我们提供了,分析系统负载趋势的数据来源,让我们能更全面、更立体地理解目前的负载状况。
举个例子
假设我们在一个单 CPU 系统上看到平均负载为 1.88,0.70,6.76, 那么说明在过去 1 分钟内,系统有 188% 的超载,而在 15 分钟内,有 676% 的超载,从整体趋势来看,系统的负载在降低
当平均负载高于 CPU 数量 70% 的时候,你就应该分析排查负载高的问题了(70% 这个数字并不是绝对的,最推荐的方法)。
平均负载和cpu使用率关系
我们经常容易把平均负载和 CPU 使用率混淆,来区分一下。然平均负载代表的是活跃进程数,那平均负载高了,不就意味着 CPU 使用率高吗?
我们还是要回到平均负载的含义上来,平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,平均负载不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而CPU使用率,是单位时间内CPU繁忙情况的统计,跟平均负载并不一定完全对应。比如
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
1.2.上下文切换
如何理解上下文切换
Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行,这是通过频繁的上下文切换、将CPU轮流分配给不同任务从而实现的。
每个进程运行时,CPU都需要知道进程已经运行到了哪里以及当前的各种状态,因此系统事先设置好 CPU 寄存器和程序计数器。
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务,而保存下来的上下文, 会存储在系统内核中,并在任务重新调度执行时再次加载进来 。
根据 Tsuna 的测试报告,每次上下文切换都需要几十纳秒到到微秒的CPU时间,因此如果进程上下文切换次数过多,就会导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间,实际上有效的CPU运行时间大大减少(可以认为上下文切换对用户来说是在做无用功)。
上下文切换的时机
- 根据调度策略,将CPU时间划片为对应的时间片,当时间片耗尽,就需要进行上下文切换
- 进程在系统资源不足,会在获取到足够资源之前进程挂起
- 进程通过sleep函数将自己挂起
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行,也就是被抢占
- 当发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序
上下文切换分类
- 进程和线程是Linux最常见的任务
- 硬件通过触发信号,会导致中断处理程序的调用,也是一种常见的任务。
所以,根据任务的不同,CPU 的上下文切换可以分为不同的场景
- 进程上下文切换
- 线程上下文切换
- 中断上下文切换
系统调用
Linux 按照特权等级划分进程的运行空间
- 内核空间(Ring 0):具有最高权限,可以直接访问所有资源
- 用户空间(Ring 3):只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源
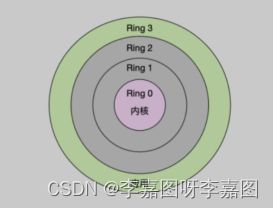 Linux运行空间
Linux运行空间
进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。 从用户态到内核态的转变,需要通过系统调用来完成。
系统调用举例:
当我们查看文件内容时, 需要多次系统调用来完成:
- 首先调用 open() 打开文件,
- 然后调用 read() 读取文件内容,
- 并调用 write() 将内容写到标准输出,
- 最后再调用 close() 关闭文件。
系统调用的过程如何进行 CPU 上下文的切换?
- CPU 寄存器里原来用户态的指令位置,需要先保存起来
- 为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置
- 最后才是跳转到内核态运行内核任务
- 系统调用结束后,CPU 寄存器需要恢复原来保存的用户态
- 然后再切换回用户空间,继续运行进程
系统调用和进程上下文切换的不同
- 进程上下文切换:从一个进程切换到另一个进程运行
- 系统调用:一直是同一个进程在运行
- 系统调用过程通常称为特权模式切换,而不是上下文切换
- 系统调用过程中, CPU 上下文切换是无法避免的
进程上下文切换
在 Linux 中,进程是由内核来管理和调度进程的,切换只能发生在内核态,进程的上下文不仅包括了 虚拟内存 、 栈 、 全局变量 等用户空间的资源,还包括了 内核堆栈 、 寄存器 等内核空间的资源。
进程上下文切换:
- 在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来【保存上下文】
- 而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈【加载上下文】
 上下文切换
上下文切换
什么时候会切换进程上下文
- 顾名思义,只有在进程切换时才需要切换上下文
- 换句话说,只有在进程调度时才需要切换上下文
CPU 如何挑选进程来运行?
- Linux 为每个 CPU 都维护了一个等待队列
- 将活跃进程(正在运行和正在等待 CPU 的进程)按照优先级和等待 CPU 的时间排序
- 然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行
进程上下文切换如何影响系统性能
每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。
线程上下文切换
线程是调度的基本单位,而进程则是资源拥有的基本单位。 所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
线程的上下文切换其实就可以分为两种情况:
1). 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上 下文切换是一样。
2). 前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时, 虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
中断上下文切换
硬件通过触发信号,向CPU发送中断信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核, 内核通过这些参数进行中断处理。 中断处理会打断进程的正常调度和执行,而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行
例如,A进程启动写磁盘操作,A进程睡眠后B进程在运行,当磁盘写完后磁盘中断信号打断的是B进程,在中断处理时会唤醒A进程。
进程上下文 VS 中断上下文
- 内核可以处于两种上下文:进程上下文和中断上下文。
- 即便中断过程打断了 一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源
- 中断上下文,只包括内核态中断服务程序执行所必需的状态,包括CPU 寄存器、内核堆栈、硬件中断参数
- 中断上下文不会和进程上下文切换同时发生
- 对同一个 CPU 来说,中断处理比进程拥有更高的优先级
- 由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束
耗资源程度
- 跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能
- 当发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题
1.3.CPU使用率
CPU使用率
用什么指标来描述系统的 CPU 性能呢 ? 不是平均负载,也不是CPU上下文切换,而是另一个更直观的指标CPU使用率 ,CPU 使用率是单位时间内 CPU 使用情况的统计,以百分比的方式展示。
节拍率的概念
为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiw ies 记录了开机以来的节拍数。每发生一次时间中断,Jiw ies 的值就加 1。
1)查看系统节拍率
不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值。
[root@centos7-2 ~]# grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=10002)用户节拍率
正因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是 1/100 秒。这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ。
USER_HZ=100CPU使用率公式
CPU使用率,就是除了空闲时间外的其他时间占总CPU时间的百分比,用公式来表示就是
 cpu使用率计算公式
cpu使用率计算公式
根据这个公式,我们就可以从 /proc/stat 中的数据,很容易地计算出 CPU 使用率。当然,也可以用每一个场景的 CPU 时间,除以总的 CPU 时间,计算出每个场景的 CPU 使用率。
性能工具是如何计算CPU使用率的
事实上,为了计算机CPU使用率,性能能工具一般都会间隔一段时间(比如 3 秒)的两次值,做差后,再计算出这段时间的平均CPU使用率
 cpu平均使用率公式
cpu平均使用率公式
性能分析工具给出的都是间隔一段时间的平均CPU使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证他们用的是相同的间隔时间
怎么查看CPU使用率
查看 CPU 使用率 top 、ps 和pidstat是最常用的性能分析工具 :
- top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。
- ps 则只显示了每个进程的资源使用情况。
- pidstat分析每个进程CPU使用情况
1.3.1.CPU使用率过高怎么办
分析思路
1、找到CPU使用率过高的进程
通过top、ps 、pidstat等工具
2、判断占用CPU高的到底是代码里的那个函数
perf 和 GDB
GDB(The GNU Project Debugger), 这个功能强大的程序调试利器 ,GDB 调试程序的过程会中断程序运行,这在线上环境往往是不允许的;
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题 ,使用 perf 分析 CPU 性能问题,perf两种用法
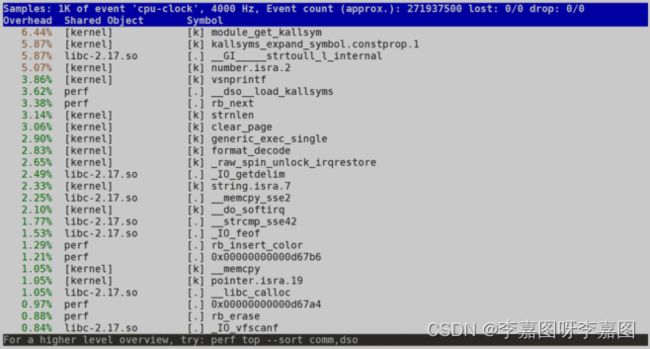
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
[root@centos7-2 ~]# perf top Samples: 724 of event 'cpu-clock', Event count (approx.): 125711088 Overhead Shared Object Symbol 45.11% [kernel] [k] generic_exec_single ...
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。比如这个例子中,perf 总共采集了1000个 CPU 时钟事件,而总事件数则为 271937500。 采样数需要特别注意,如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
- 第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
- 第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。
- 第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
- 第四列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要用 perf report 解析展示
perf record # 按 Ctrl+C 终止采样 [root@centos7-2 ~]# perf report Samples: 5K of event 'cpu-clock', Event count (approx.): 1332500000 Overhead Command Shared Object Symbol 97.15% swapper [kernel.kallsyms] [k] native_safe_halt 0.49% swapper [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore 0.36% vmtoolsd libvmtools.so.0.0.0 [.] Backdoor_InOut 0.34% swapper [kernel.kallsyms] [k] __do_softirq 0.17% swapper [kernel.kallsyms] [k] tick_nohz_idle_exit 0.13% swapper [kernel.kallsyms] [k] tick_nohz_idle_enter 0.13% vmtoolsd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore 0.11% kworker/0:1 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore 0.11% vmtoolsd libvmtools.so.0.0.0 [.] BackdoorHbOut 0.08% dockerd [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore 0.08% vmtoolsd [kernel.kallsyms] [k] __do_softirq 0.06% kworker/1:2 [kernel.kallsyms] [k] queue_delayed_work_on 0.06% vmtoolsd [kernel.kallsyms] [k] format_decode 0.04% irqbalance [kernel.kallsyms] [k] cap_mmap_file 0.04% kworker/0:0 [kernel.kallsyms] [k] ata_sff_pio_task 0.04% kworker/1:2 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore 0.04% mysqld mysqld [.] fts_optimize_words 0.04% swapper [kernel.kallsyms] [k] rcu_idle_exit 0.04% vmtoolsd libvmtools.so.0.0.0 [.] BackdoorHbIn 0.02% dockerd [kernel.kallsyms] [k] __do_softirq 0.02% in:imjournal rsyslogd [.] 0x0000000000016f90 0.02% irqbalance [kernel.kallsyms] [k] __fsnotify_parent 0.02% irqbalance [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore 0.02% irqbalance [kernel.kallsyms] [k] copy_user_generic_unrolled 0.02% irqbalance [kernel.kallsyms] [k] native_flush_tlb_single 0.02% irqbalance [kernel.kallsyms] [k] unmap_page_range Tip: For tracepoint events, try: perf report -s trace_fields
2.linux性能工具
2.1.CPU性能指标
从 CPU 的性能指标出发。也就是说,当要查看某个性能指标时,要清楚知道哪些工具可以做到。
根据不同的性能指标,对提供指标的性能工具进行分类和理解。这样,在实际排查性能问题时,你就可以清楚知道,什么工具可以提供你想要的指标。
|
性能指标
|
工具
|
说明 |
|---|---|---|
|
平均负载
|
uptime
top
|
uptime 使用最简单 ;
top 提供了更安全的指标
|
|
系统整体 CPU 使
用率
|
vmstat
mpstat
top
sar
/proc/stat
|
top 、 vmstat 、 mpstat 只可以动态查看,
而 sar 还可以记录历史数据
/proc/stat 是其他性能工具数据来源
|
|
进程 CPU 使用率
|
top
pidstat
ps
htop
atop
|
top 和 ps 可以按 CPU 使用率给进程排序 ,
而 pidstat 只显示实际用了 CPU 的进程
htop 和 atop 以不同颜色显示更直观
|
|
系统上下文切换
|
vmstat
|
除了上下文切换次数还提供运行状态和不可中断状态进程的
数量
|
|
进程上下文切换
|
pidstat
|
使用时注意加上 -w 选项
|
|
软中断
|
top
/proc/soxirqs
mpstat
|
top 提供软中断 CPU 使用率
而 /proc/soxirqs 和 mpstat 提供了各种软中断在每个 CPU 上的
运行次数
|
|
硬中断
|
vmstat
/proc/interrupts
|
vmstat 提供了总的中断次数
而 /proc/interrupts 提供了各种中断在每个 CPU 上的积累次数
|
|
CPU 个数
|
/proc/cpuinfo
lscpu
|
lscpu 更直观查看
|
|
事件剖析
|
pref
execsnoop
|
perf 可以用来分析 CPU 的缓存及内核调用链
execsnoop 用来监控短时进程
|
2.2.根据工具查指标
第二个维度,从工具出发。也就是当你已经安装了某个工具后,要知道这个工具能提供哪些指标。
具体到每个工具的使用方法,一般都支持丰富的配置选项。这些配置选项并不用背下来。你只要知道有哪些工具、以及这些工具的基本功能是什么就够了。真正要用到的时候, 通过 man 命令,查它们的使用手册就可以了 。
|
性能工具
|
CPU 性能指标
|
|---|---|
|
uptime
|
平均负载
|
| top |
平均负载、运行队列、整体的 CPU 使用率及每个进程的状态和 CPU 使用率
|
| htop |
top 增强版、可以以不同的颜色区分不同类型的进程
|
| atop |
CPU 、内存、磁盘和网络等各种资源的全面监控
|
| vmstat |
系统整体的 CPU 使用率、上下文切换次数、中断次数、还包括处于运行 和不可中断状态的进程数
|
| mpstat |
每个 CPU 使用率和软中断次数
|
| pidstat |
进程和线程的 CPU 使用率、中断上下文切换次数
|
| /proc/sofirqs |
软中断类型和每个 CPU 上的累计中断次数
|
|
/proc/interrupts
|
硬中断类型和每个 CPU 上的累计中断次数
|
| ps |
每个进程的状态和 CPU 使用率
|
| pstree |
进程的父子关系
|
| dstat |
系统整体的 CPU 使用率
|
| sar |
系统整体的 CPU 使用率 , 包括可配置的历史数据
|
| starces |
进程的系统调用
|
| perf |
CPU 性能事件剖析 , 如调用链分析 ,CPU 缓存 ,CPU 调度
|
| execsnoop |
监控进程
|
3.性能调优策略
CPU 优从 应用程序 和 系统 的角度,分别来看看如何才能降低 CPU 使用率,提高 CPU 的并行处理能力。
3.1.应用程序优化
首先,从应用程序的角度来说,降低 CPU 使用率的最好方法当然是,排除所有不必要的工作,只保留最核心的逻辑。比如减少循环的层次、减少递归、减少动态内存分配等等。
编译器优化:很多编译器都会提供优化选项,适当开启它们,在编译阶段你就可以获得 编译器的帮助,来提升性能。
算法优化:使用复杂度更低的算法,可以显著加快处理速度
异步处理:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序 的并发处理能力。比如,把轮询替换为事件通知,就可以避免轮询耗费 CPU 的问题。
多线程代替多进程:相对于进程的上下文切换,线程的上下文切换并不切换进程地址空间,因此可以降低上下文切换的成本。
善用缓存:经常访问的数据或者计算过程中的步骤,可以放到内存中缓存起来,这样在 下次用时就能直接从内存中获取,加快程序的处理速度。
3.2.系统优化
从系统的角度来说,优化 CPU 的运行,一方面要充分利用 CPU 缓存的本地性,加速缓存访问;另一方面,就是要控制进程的 CPU 使用情况,减少进程间的相互影响。
CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题。
CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU。
优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_aw inity,就可以把中断处理过程自动负载均衡到多个 CPU 上。