算法训练Day29 回溯算法专题 | LeetCode491.递增子序列(处处都像子集II,但是又不同);46.全排列(不用startIndex啦);47.全排列II(去重逻辑)
前言:
算法训练系列是做《代码随想录》一刷,个人的学习笔记和详细的解题思路,总共会有60篇博客来记录,计划用60天的时间刷完。
内容包括了面试常见的10类题目,分别是:数组,链表,哈希表,字符串,栈与队列,二叉树,回溯算法,贪心算法,动态规划,单调栈。
博客记录结构上分为 思路,代码实现,复杂度分析,思考和收获,四个方面。
如果这个系列的博客可以帮助到读者,就是我最大的开心啦,一起LeetCode一起进步呀;)
目录
LeetCode491.递增子序列
1. 思路
2. 代码实现
3. 复杂度分析
4. 思考与收获
LeetCode46.全排列
1. 思路
2. 代码实现
3. 复杂度分析
4. 思考与收获
LeetCode47.全排列II
1. 思路
2. 代码实现
3. 复杂度分析
4. 思考与收获
LeetCode491.递增子序列
链接:491. 递增子序列 - 力扣(LeetCode)
1. 思路
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。这又是子集,又是去重,是不是不由自主的想起了刚刚讲过的**90.子集II (opens new window)**。就是因为太像了,更要注意差别所在;
本题和大家刚刚做过的90.子集II非常像,但是又很不一样,很容易掉坑里!区别在哪里呢?
在**90.子集II (opens new window)**中我们是通过排序,再加一个标记数组来达到去重的目的。而本题求自增子序列,是不能对原数组经行排序的,排完序的数组都是自增子序列了。所以不能使用之前的去重逻辑!
本题给出的示例,还是一个有序数组 [4, 6, 7, 7],这更容易误导大家按照排序的思路去做了。为了有鲜明的对比,我用[4, 7, 6, 7]这个数组来举例,抽象为树形结构如图:
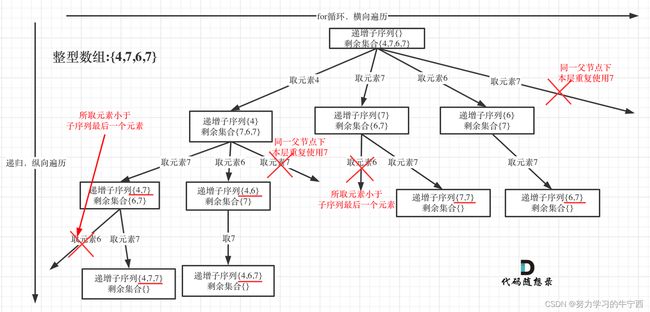
根据树形结构的分析,我们知道,我们要做的是树层上的去重,树枝上的元素的数值是可以重复的;
既然不可以用之前的used数组的去重逻辑了,那本题应该如何去重呢?
可以用一个集合set来记录本层已经使用过的元素,在进入下层递归之前,都判断一下,该元素是否在本层已经出现过;
2. 代码实现
2.1 递归函数参数
本题求子序列,很明显一个元素不能重复使用,所以需要startIndex,调整下一层递归的起始位置;
class Solution:
def __init__(self):
self.result = []
self.path = []
def findSubsequences(self, nums: List[int]) -> List[List[int]]:
'''
本题求自增子序列,所以不能改变原数组顺序
'''
self.backtracking(nums, 0)
return self.result
def backtracking(self, nums: List[int], start_index: int):
2.2 终止条件
本题其实类似求子集问题,也是要遍历树形结构找每一个节点,所以和**回溯算法:求子集问题! (opens new window)**一样,可以不加终止条件,startIndex每次都会加1,并不会无限递归;但本题收集结果有所不同,题目要求递增子序列大小至少为2,所以代码如下:
def backtracking(self, nums: List[int], start_index: int):
# 收集结果,同78.子集,仍要置于终止条件之前
if len(self.path) >= 2:
# 本题要求所有的节点
self.paths.append(self.path[:])
# Base Case(可忽略)
if start_index == len(nums):
return
2.3 单层搜索逻辑

在图中可以看出:
- 同一父节点下的同层上使用过的元素就不能在使用了
- 如果所选元素小于子序列的最后一个元素,则跳过该元素
那么单层搜索代码如下:
# 单层递归逻辑
# 深度遍历中每一层都会有一个新的usage_list用于记录本层元素是否重复使用
usage_list = set()
# 同层横向遍历
for i in range(start_index, len(nums)):
# 若当前元素值小于前一个时(非递增)或者曾用过,跳入下一循环
if (self.path and nums[i] < self.path[-1]) or nums[i] in usage_list:
continue
usage_list.add(nums[i])
self.path.append(nums[i])
self.backtracking(nums, i+1)
self.path.pop()
一些细节:
- 对于已经习惯写回溯的同学,看到递归函数上面的
uset.insert(nums[i]);,下面却没有对应的pop之类的操作,应该很不习惯吧,这也是需要注意的点,unordered_set是记录本层元素是否重复使用,新的一层uset都会重新定义(清空),所以要知道uset只负责本层;uset; - 在判断nums[i] < self.path[-1]之前,要先判断path数组不为空,不然可能会报错;
- nums[i] < self.path[-1]中是小于号,因为实例中[4,7,7]也是OK的,说明等于的情况是OK的;
- 判断continue or break : 如树形结构所示,分支砍掉之后还可以继续往后,而不是让循环直接break,所以应该用continue;
2.4 整体代码实现
# 回溯算法 子集问题的变种
# time:O(2^N);space:O(N)
class Solution(object):
# 定义全局变量
def __init__(self):
self.path = []
self.result = []
# 本题求递增子序列,
# 所以说不能按照前面排序+used数组去重了
def findSubsequences(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
self.backtracking(nums,0)
return self.result
def backtracking(self,nums,startIndex):
# Base Case(可忽略)
'''
if start_index == len(nums):
return
'''
# 收集结果,同78.子集,仍要置于终止条件之前
if len(self.path) >= 2:
self.result.append(self.path[:])
# 单层搜索逻辑
# 每一层都会有一个全新的checkList用于记录本层元素是否重复使用
checkList = set()
# 同层循环遍历
for i in range(startIndex,len(nums)):
# 若当前元素值小于前一个时(非递增)或者曾用过,跳入下一循环
if (len(self.path) != 0 and nums[i] < self.path[-1]) or nums[i] in checkList:
continue
checkList.add(nums[i])
self.path.append(nums[i])
self.backtracking(nums,i+1)
self.path.pop()
3. 复杂度分析
-
时间复杂度:O(2^n)
因为每一个元素的状态无外乎取与不取,所以时间复杂度为O(2^n)
-
空间复杂度:O(n)
递归深度为n,所以系统栈所用空间为O(n),每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为O(n)
4. 思考与收获
-
程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且每次重新定义set,insert的时候其底层的符号表也要做相应的扩充,也是费事的;其实在去重逻辑上面是可以进一步优化的,**其实用数组来做哈希,效率就高了很多,**注意题目中说了,数值范围[-100,100],所以完全可以用数组来做哈希,代码如下:(只有加粗的地方改变了)
class Solution(object): # 定义全局变量 def __init__(self): self.path = [] self.result = [] # 本题求递增子序列, # 所以说不能按照前面排序+used数组去重了 def findSubsequences(self, nums): """ :type nums: List[int] :rtype: List[List[int]] """ self.backtracking(nums,0) return self.result def backtracking(self,nums,startIndex): # Base Case(可忽略) #if start_index == len(nums): # return # 收集结果,同78.子集,仍要置于终止条件之前 if len(self.path) >= 2: self.result.append(self.path[:]) # 单层搜索逻辑 # 每一层都会有一个全新的checkList用于记录本层元素是否重复使用 # 使用列表去重,题中取值范围[-100, 100] **checkList = [0]*201** # 同层循环遍历 for i in range(startIndex,len(nums)): # 若当前元素值小于前一个时(非递增)或者曾用过,跳入下一循环 if (len(self.path) != 0 and nums[i] < self.path[-1]) or **checkList[nums[i]+100]==1:** continue **checkList[nums[i]+100] = 1** self.path.append(nums[i]) self.backtracking(nums,i+1) self.path.pop()这份代码在leetcode上提交,要比版本一耗时要好的多。
所以正如在哈希表:总结篇!(每逢总结必经典) (opens new window)中说的那样,数组,set,map都可以做哈希表,而且数组干的活,map和set都能干,但如果数值范围小的话能用数组尽量用数组;
-
本题题解清一色都说是深度优先搜索,但我更倾向于说它用回溯法,而且本题我也是完全使用回溯法的逻辑来分析的。相信大家在本题中处处都能看到是**回溯算法:求子集问题(二) (opens new window)**的身影,但处处又都是陷阱。对于养成思维定式或者套模板套嗨了的同学,这道题起到了很好的警醒作用。更重要的是拓展了大家的思路!
Reference: 代码随想录 (programmercarl.com)
本题学习时间:60分钟。
LeetCode46.全排列
链接:46. 全排列 - 力扣(LeetCode)
1. 思路
因为本题题意说明,这个序列没有重复的数字,所以说我们不用考虑去重;
做到本题的时候,关于回溯算法,已经完成了组合问题,分割问题以及子集问题的学习,现在进入回溯算法中排列问题的学习;
排列和组合的区别?
[1,2] 和[2,1]是同一个组合,但是为两个排列,组合无序,排列有序;
相信这个排列问题就算是让你用for循环暴力把结果搜索出来,这个暴力也不是很好写,回溯算法实际上也是一种暴力搜索,那为什么是暴力搜索,效率这么低,我们还是要用它呢?因为一些问题,可以用暴力搜出来已经很不错了!
我以[1,2,3]为例,抽象成树形结构如下:

一些细节:
在组合问题中,我们用startIndex这个参数来保证 下一层递归从当前数的后一个开始取:
- 我们不取1,2 和2,1 这种重复的组合
- 并且不会重复取上一层已经取过的元素
但是在排列问题中,我们需要取1,2 和2,1 两个不一样的排列,并且不能重复取上一层已经取过的元素,所以我们不再使用startIndex这个参数去控制,而是用一个数组used去记录已经选择过的元素,每次到下一层遍历的时候,参考used数组中的值,就可以不重复取前面已经选择过的元素了,并且控制for循环从0开始取,就也能保证取到1,2 和2,1这两种不一样的组合;
2. 代码实现
2.1 确定递归函数的参数
首先排列是有序的,也就是说 [1,2] 和 [2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了;
但排列问题需要一个used数组,标记已经选择的元素,如图橘黄色部分所示:

代码如下:
class Solution:
def __init__(self):
self.path = []
self.paths = []
def permute(self, nums: List[int]) -> List[List[int]]:
'''
因为本题排列是有序的,这意味着同一层的元素可以重复使用,
但同一树枝上不能重复使用(usage_list)
所以处理排列问题每层都需要从头搜索,故不再使用start_index
'''
usage_list = [False] * len(nums)
self.backtracking(nums, usage_list)
return self.paths
def backtracking(self, nums: List[int], usage_list: List[bool]) -> None:
2.2 递归终止条件

可以看出叶子节点,就是收割结果的地方;那么什么时候,算是到达叶子节点呢?当收集元素的数组path的大小达到和nums数组一样大的时候,说明找到了一个全排列,也表示到达了叶子节点;
代码如下:
def backtracking(self, nums: List[int], usage_list: List[bool]) -> None:
# Base Case本题求叶子节点
if len(self.path) == len(nums):
self.paths.append(self.path[:])
return # 已经到了叶子节点,该取的都取了,可以return了
2.3 单层搜索逻辑
这里和组合问题、切割问题、子集问题最大的区别就是,for loop中不再使用startIndex了;
因为排列问题,每次都要从头开始搜索,例如元素1在[1,2]中已经使用过了,但是在[2,1]中还要再使用一次1;而used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次;
代码如下:
# 单层递归逻辑
for i in range(0, len(nums)): # 从头开始搜索
# 若遇到self.path里已收录的元素,跳过
if usage_list[i] == True:
continue
usage_list[i] = True
self.path.append(nums[i])
# 纵向传递使用信息,去重
self.backtracking(nums, usage_list)
self.path.pop()
usage_list[i] = False
细节:continue还是break,因为跳过那些元素之后,还要继续往后取,所以用continue;
2.4 整体代码实现
# 回溯算法 排列问题
# time: O(N!);space:O(N)
class Solution(object):
# 定义全局变量
def __init__(self):
self.path = []
self.result = []
def permute(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
# 因为本题排列是有序的,这意味着同一层的元素可以重复使用,
# 但同一树枝上不能重复使用(usage_list)
# 所以处理排列问题每层都需要从头搜索,故不再使用start_index
self.backtracking(nums,[0]*len(nums))
return self.result
def backtracking(self,nums,used):
# 终止条件 本题求叶子节点
if len(self.path) == len(nums):
self.result.append(self.path[:])
return
# 单层搜索逻辑
# 从头开始搜索
for i in range(0,len(nums)):
# 若遇到self.path里已收录的元素,跳过
if used[i] == 1:
continue
used[i] = 1
self.path.append(nums[i])
# 纵向传递使用信息,去重
self.backtracking(nums,used)
used[i] = 0
self.path.pop()
3. 复杂度分析
-
时间复杂度:O(n!)
这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * ..... 1 = n!;
-
空间复杂度:O(n)
递归深度为n,所以系统栈所用空间为O(n),每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为O(n);
4. 思考与收获
-
优化:也可以不用额外的used数组,直接在for loop下面判断当前的元素是否在path中出现过就可以了;代码如下:
# 优化: 不用used数组 class Solution(object): # 定义全局变量 def __init__(self): self.path = [] self.result = [] def permute(self, nums): """ :type nums: List[int] :rtype: List[List[int]] """ # 因为本题排列是有序的,这意味着同一层的元素可以重复使用, # 但同一树枝上不能重复使用(usage_list) # 所以处理排列问题每层都需要从头搜索,故不再使用start_index self.backtracking(nums) return self.result def backtracking(self,nums): # 终止条件 本题求叶子节点 if len(self.path) == len(nums): self.result.append(self.path[:]) return # 单层搜索逻辑 # 从头开始搜索 for i in range(0,len(nums)): # 若遇到self.path里已收录的元素,跳过 if nums[i] in self.path: continue self.path.append(nums[i]) self.backtracking(nums) self.path.pop() -
排列问题的不同之处总结:
- 每层都是从0开始搜索而不是startIndex
- 需要used数组记录path里都放了哪些元素了
Reference: 代码随想录 (programmercarl.com)
本题学习时间:60分钟。
LeetCode47.全排列II
链接:47. 全排列 II - 力扣(LeetCode)
1. 思路
本题 就是我们讲过的 40.组合总和II 去重逻辑 和 46.全排列 的结合;
去重一定要对元素进行排序,这样我们才方便通过相邻的节点来判断是否重复使用了;我以示例中的 [1,1,2]为例 (为了方便举例,已经排序)抽象为一棵树,去重过程如图:

图中我们对同一树层,前一位(也就是nums[i-1])如果使用过,那么就进行去重。一般来说:组合问题和排列问题是在树形结构的叶子节点上收集结果,而子集问题就是取树上所有节点的结果。
在**46.全排列 (opens new window)中已经详解讲解了排列问题的写法,在40.组合总和II (opens new window)、90.子集II (opens new window)**中详细讲解的去重的写法,所以就不用回溯三部曲分析了,直接给出代码;
2. 代码实现
# 回溯算法 排列问题
# time:O(N!);space:O(N)
class Solution(object):
# 定义全局变量
def __init__(self):
self.path = []
self.result = []
def permuteUnique(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
nums.sort()
self.backtracking(nums,[0]*len(nums))
return self.result
def backtracking(self,nums,used):
# 终止条件
if len(self.path) == len(nums):
self.result.append(self.path[:])
return
# 单层递归逻辑
for i in range(0,len(nums)):
# 避免取到相同的元素 or 去重逻辑
if used[i] == 1 or ( i>0 and nums[i] == nums[i-1] and used[i-1]==0):
continue
used[i] = 1
self.path.append(nums[i])
self.backtracking(nums,used)
used[i] = 0
self.path.pop()
3. 复杂度分析
-
时间复杂度:O(n!)
这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * ..... 1 = n!;
-
空间复杂度:O(n)
递归深度为n,所以系统栈所用空间为O(n),每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为O(n);
4. 思考与收获
-
大家发现,去重最为关键的代码为:
if i>0 and nums[i] == nums[i-1] and used[i-1]==0: continue如果改成 used[i-1]==1, 竟然也是正确的,去重代码如下:
if i>0 and nums[i] == nums[i-1] and used[i-1]==1: continue这是为什么呢,就是上面我刚说的,如果要对树层中前一位去重,就用used[i-1]==0,如果要对树枝前一位去重用used[i-1]==1;
对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高;
用输入: [1,1,1] 来举一个例子:
树层上去重(used[i - 1] == false),的树形结构如下:

树枝上去重(used[i - 1] == true)的树型结构如下:
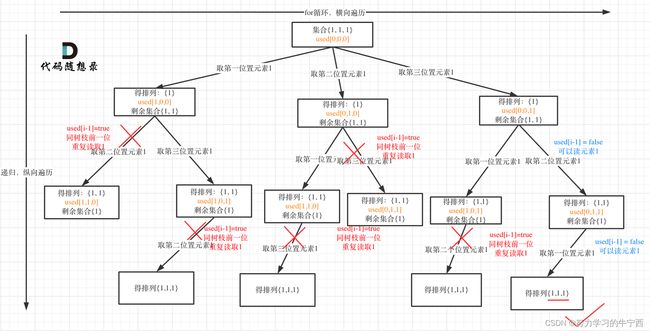
大家应该很清晰的看到,树层上对前一位去重非常彻底,效率很高,树枝上对前一位去重虽然最后可以得到答案,但是做了很多无用搜索;
理解这样为啥的原因就可以了,还是写成树层去重的效率更高;
Reference:代码随想录 (programmercarl.com)
本题学习时间:60分钟。
本篇学习所用时间为3小时,总结字数近10000字;本篇仍然是回溯算法专题,递增子序列属于是子集II的变种问题,看上去非常像,但是又有很大的不同;两道回溯算法中的排列问题,分别是有重复数字和无重复数字的情况,需要和之前学过的组合问题,分割问题以及子集问题作区分。(求推荐!)