C++进阶篇1---继承
一、继承的概念和定义
1.1概念
继承机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称为派生类。继承呈现了面向对象程序设计的层次结构,体现了又简单到复杂的认知过程。
下面写一个继承给大家见识一下
class Person {
public:
void Print()
{
cout << "姓名:" << name << endl;
cout << "年龄:" << age << endl;
}
protected:
string name="zhangsan";
int age=18;
};
//这里简单说一下,Student继承Person,将它的成员函数和成员变量都继承下来了
//后面会详细讲解继承的细节
class Student:public Person {
protected:
string stu_id;
};
int main()
{
Person p;
Student s;
p.Print();
s.Print();
return 0;
}
1.2继承的定义
1.2.1定义格式
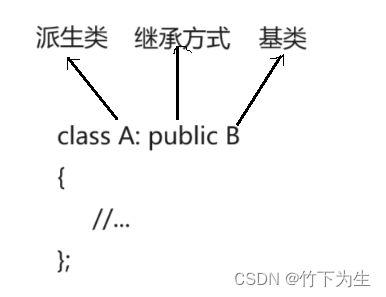
(这里的派生类和基类就是子类和父类,它有好几种说法,大家认识就行)
1.2.2继承方式
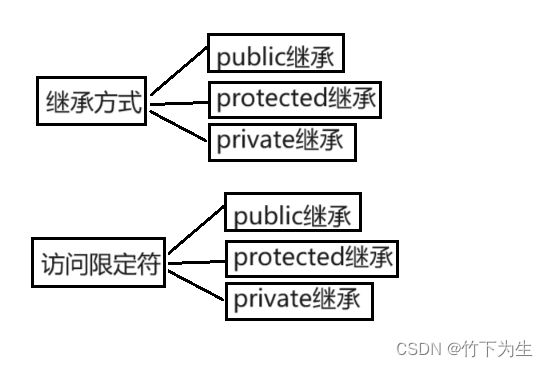
1.2.3继承基类成员访问方式 (成员包括成员函数和成员变量)
| 类成员/继承方式 | public | protected | private |
| 基类的public成员 | 派生类的public成员 | 派生类的protested成员 | 派生类的proivate成员 |
| 基类的protected成员 | 派生类的protested成员 | 派生类的protested成员 | 派生类的proivate成员 |
| 基类的private成员 | 派生类中不可见 | 派生类中不可见 | 派生类中不可见 |
总结:
1.基类中的private成员无论哪种继承方式继承,在派生类中都不可见,注意:不可见的意思是继承了,但是派生类中不能访问,当然类外也不能访问
2.基类中的public和protested成员在派生类中的访问方式= Min(成员在基类的访问限定符,继承方式) (public > protected > private)
3.使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,建议写出继承方式
4.在实际运用中一般使用都是public继承,几乎很少使用protetced/private继承,也不提倡使用protetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里面使用,实际中扩展维护性不强
5.这里提一下protected:基类private成员在派生类中是不能被访问,如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。所以保护成员限定符是因继承才出现的
//下面简单用public继承方式演示一下继承机制
//大家可以以下面代码为模板测试一下其他的继承方式
class A {
public:
int _a1;
protected:
int _a2;
private:
int _a3;
};
class B :public A{
public:
void Print() {
cout << _a1 << endl;
cout << _a2 << endl;
cout << _a3 << endl;//父类中的private成员在子类中不可见
}
};二、基类和派生类对象赋值转换
- 派生类对象可以赋值给 基类的对象 / 基类的指针 / 基类的引用。这里有个形象的说法叫切片 或者切割。寓意把派生类中父类那部分切来赋值过去。
- 基类对象不能赋值给派生类对象。
- 基类的指针或者引用可以通过强制类型转换赋值给派生类的指针或者引用。但是必须是基类 的指针是指向派生类对象时才是安全的。这里基类如果是多态类型,可以使用RTTI(这里会在多态篇讲,可以暂不理会,现在只要记住前两点就行)
//演示一下第一点
void test()
{
int a = 1;
//我们都知道当发生类型转换的时候,会产生临时对象,如下
double d = a;
//double& rd = a;
const double& ra = a;//因为临时对象具有常性,所以得用const修饰
cout << &ra << endl;
cout << &a << endl;
//但是下面的代码能正常运行,为什么呢?
B b;
A& rb = b;//因为这里的引用直接引用的是子类中继承的父类成员,没有产生临时变量
cout << &rb << endl;
cout << &b << endl;
A*pb=&b;//当然指针也是指向子类中的父类部分
}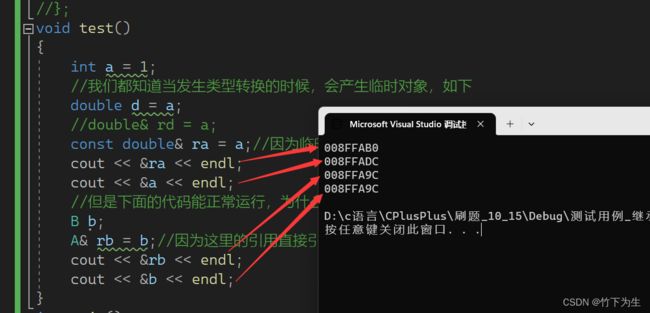
上面演示的就是父子类的赋值兼容规则
三、继承中的作用域
下面我写一段代码,大家来猜猜打印的结果是什么?
class A {
public:
void Print() {
cout << _a << endl;
}
protected:
int _a = 1;
};
class B :public A {
public:
void Print() {
cout << _a << endl;
cout << _b << endl;
}
private:
int _a = 2;
int _b = 3;
};
void test() {
A a;
a.Print();
B b;
b.Print();
b.A::Print();
}
int main()
{
test();
return 0;
}
你猜对了吗???(第一个打印结果大家应该都是对的,下面主要讲下面三个打印结果的由来)
我猜大部分人看了,都会觉得这代码有bug,编译会报错,但是代码其实没有任何问题,这里涉及到继承的作用域, 下面我们来分析一下上面的代码:
首先B继承A,所以A中的成员都被继承到B,而B中的一些成员和A中的重名了,我猜这里就有人认为一个类中怎么能有相同的成员呢,就觉得代码会报错,但是我们忽略了一点---只有在同一个作用域中出现这种情况才会报错,但这里其实是两个作用域,一个是父类的作用域,一个是子类的作用域,所以不会报错,并且优先访问子类中的成员,所以b.Print()的结果是2 3,而b.A::Print()很显然是再调用父类的成员函数,所以打印1
总结:
四、派生类的默认成员函数
6个默认成员函数大家还记得吧,帮大家回忆一下

- 派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。如果基类没有默认的构造函数,则必须在派生类构造函数的初始化列表阶段显示调用。
- 派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化。
- 派生类的operator=必须要调用基类的operator=完成基类的复制。
- 派生类的析构函数会在被调用完成后自动调用基类的析构函数清理基类成员。因为这样才能保证派生类对象先清理派生类成员再清理基类成员的顺序
- 派生类对象初始化先调用基类构造再调派生类构造
- 派生类对象析构清理先调用派生类析构再调基类的析构
- 因为后续一些场景析构函数需要构成重写,重写的条件之一是函数名相同(这个我会在多态篇会讲)。编译器会对析构函数名进行特殊处理,处理成destrutor(),所以父类析构函数不加virtual的情况下,子类析构函数和父类析构函数构成隐藏关系
class A {
public:
A(int a)
:_a(a)
{
cout << "A(int a)" << endl;
}
A(const A& x)
:_a(x._a)
{
cout << "A(const A& x)" << endl;
}
A& operator=(const A& x)
{
if (this != &x)
{
_a = x._a;
}
cout << "operator=(const A& x)" << endl;
return *this;
}
~A()
{
cout << "~A()" << endl;
}
protected:
int _a;
};
class B : public A{
public:
B(int x,int y)
:A(x)//如果A没有默认的构造函数,就需要显示调用,且先调用父类成员的构造
,_b(y)
{
cout << "B(int x,int y)" << endl;
}
B(const B& x)
:A(x)//且这里用到了"切片"(父子类的赋值兼容规则)
,_b(x._b)
{
cout << "B(const B& x)" << endl;
}
B& operator=(const B& x)
{
if (this != &x)
{
//这里要注意:operator=和父类中的构成隐藏关系,需要加类域
//且这里用到了"切片"(父子类的赋值兼容规则)
A::operator=(x);
_b = x._b;
}
cout << "operator=(const A& x)" << endl;
return *this;
}
//这里有两个坑:
//1.调用~A()函数要加域名,因为析构函数构成隐藏关系
//2.子类的析构函数不需要自己调用父类的析构,编辑器自动会在调完子类的析构之后调用父类的析构
~B()
{
cout << "~B()" << endl;
}
protected:
int _b;
};
void test()
{
B b(1,2);
cout << "---------" << endl;
B b1(b);
cout << "---------" << endl;
B b2(3, 4);
cout << "---------" << endl;
b1 = b2;
cout << "---------" << endl;
}

五、继承和友元
一句话:你父亲的朋友不一定是你的朋友,所以友元关系不能继承
class B;//这里要先声明一下B,不然A中的友元声明会找不到B,会报错
class A {
friend void Print(A a,B b);
private:
int _a=1;
};
class B :public A {
//friend void Print(A a, B b);
protected:
int _b=2;
};
void Print(A a,B b) {
cout << a._a << endl;
cout << b._b << endl;//报错
}
int main()
{
A a;
B b;
Print(a,b);
return 0;
}六、继承与静态成员
class A {
public:
A()
{
count++;
}
static int getNum(){
return count;
}
static int count;
};
int A::count = 0;
class B : public A {
};
int main()
{
A a1;
A a2;
B b1;
B b2;
cout << &A::count << endl;
cout << &B::count << endl;
cout << A::getNum() << endl;
return 0;
}
七、 复杂的菱形继承及菱形虚拟继承
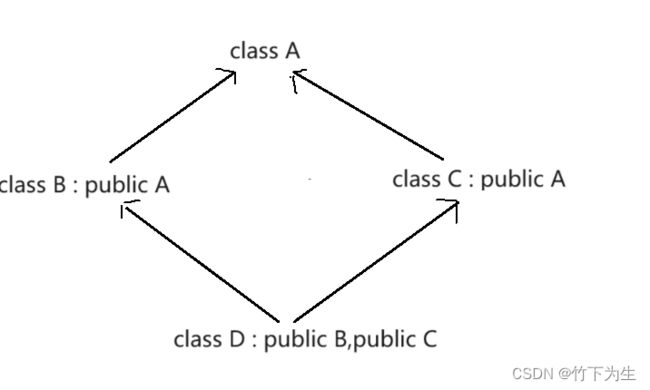
在写继承的时候,会出现上诉情况,(这里说一下,C++是支持多继承的),会发生什么问题?A类的成员被重复继承了,同时我们如果要直接访问A的成员,编辑器就会不知道我们访问的是哪个类中的成员(B、C中都有A),即代码出现了数据冗余和二义性,当然二义性可以通过域名消除,但是空间的浪费还是存在的,那怎么办呢?
这里就引入了虚拟继承,如下
//class A {
//public:
// int _a=1;
//};
//class B :public A {
//public:
// int _b=2;
//};
//class C :public A {
//public:
// int _c=3;
//};
//class D :public B, public C {
//public:
// void func() {
// //cout << _a << endl;//会引发二义性,得加类域
// cout << B::_a << endl;
// cout << C::_a << endl;
// }
// int _d=4;
//};
//虚拟继承
class A {
public:
int _a = 1;
};
class B :virtual public A {
public:
int _b = 2;
};
class C :virtual public A {
public:
int _c = 3;
};
class D :public B, public C {
public:
void func() {
//这里的三个_a是同一个
cout << _a << endl;
cout << B::_a << endl;
cout << C::_a << endl;
}
int _d = 4;
};虚拟继承的原理
1.没有使用虚拟继承
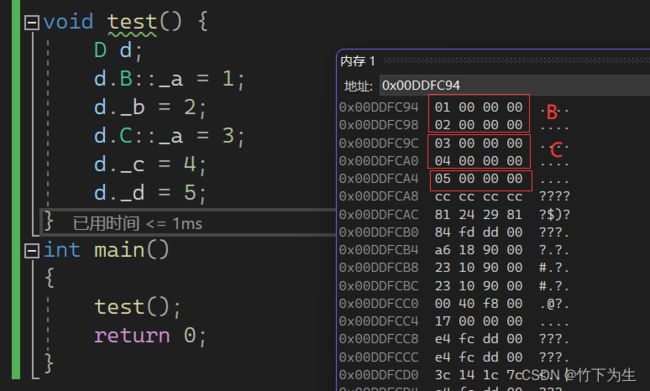
2.使用虚拟继承
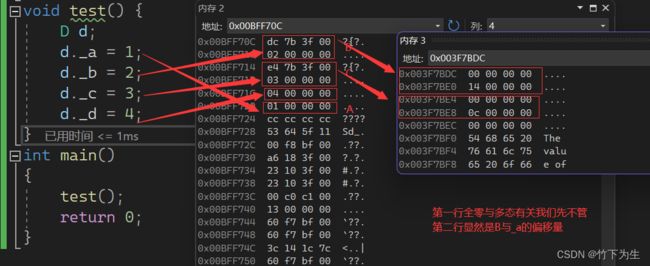
所以,这里是通过了B和C的两个指针,指向的一张表。这两个指针叫虚基表指针,这两个表叫虚基表。虚基表中存的偏移量。通过偏移量可以找到下面的A。
注意:不推荐使用菱形继承!!!
八、继承和组合
- public继承是一种is-a的关系。也就是说每个派生类对象都是一个基类对象。
- 组合是一种has-a的关系。假设B组合了A,每个B对象中都有一个A对象。
- 继承允许你根据基类的实现来定义派生类的实现。这种通过生成派生类的复用通常被称为白箱复用,即在继承方式中,基类的内部细节对子类可见 。继承一定程度破坏了基类的封装,基类的改变,对派生类有很大的影响。派生类和基类间的依赖关系很强,耦合度高。
- 对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组装或组合对象 来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为黑箱复 用,即对象的内部细节是不可见的。对象只以“黑箱”的形式出现。组合类之间没有很强的依赖关系,耦合度低。优先使用对象组合有助于你保持每个类被封装。
- 实际尽量多去用组合。组合的耦合度低,代码维护性好。不过继承也有用武之地的,有些关系就适合继承那就用继承,另外要实现多态,也必须要继承。类之间的关系可以用继承,可以用组合,就用组合。