Spark
1. Spark概述
1.1 什么是Spark回顾:Hadoop主要解决,海量数据的存储和海量数据的分析计算。 Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。 |
||||||||||||||||
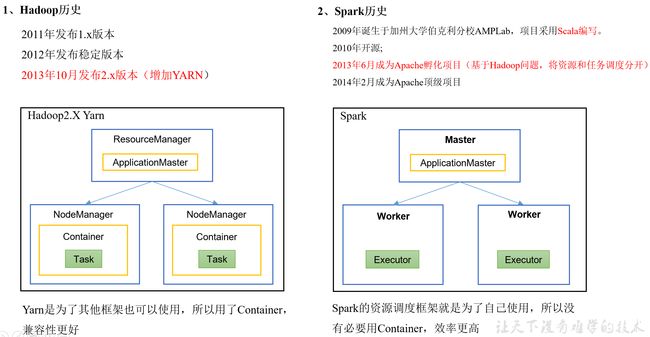
1.2 Hadoop与Spark历史
|
||||||||||||||||
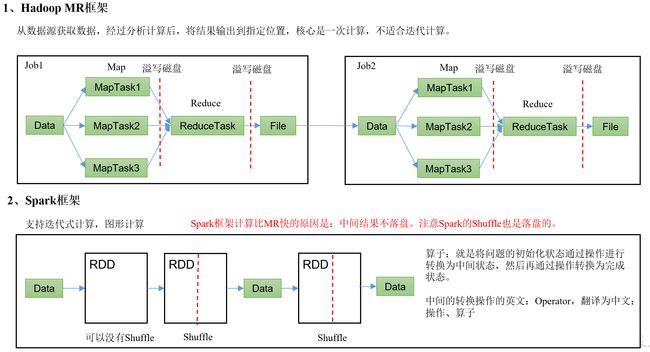
1.3 Hadoop与Spark框架对比
|
||||||||||||||||
1.4 Spark内置模块
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。 Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。 Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。 Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。 Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。 集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。 Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。 |
||||||||||||||||
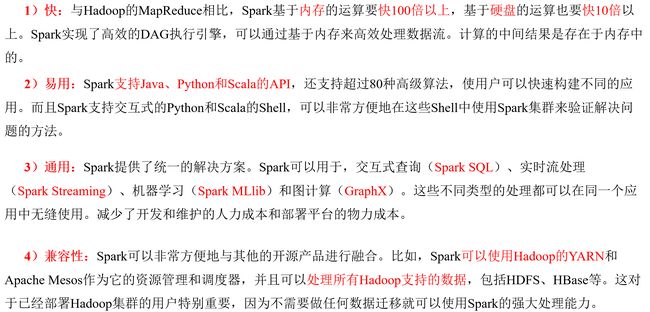
1.5 Spark特点
|
||||||||||||||||
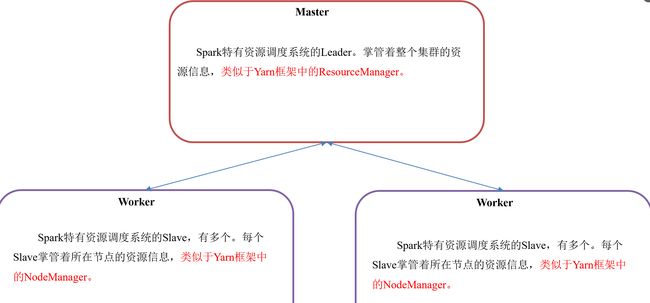
1.6 Master和Worker集群资源管理
Master和Worker是Spark的守护进程、集群资源管理者,即Spark在特定模式(Standalone)下正常运行必须要有的后台常驻进程。 |
||||||||||||||||
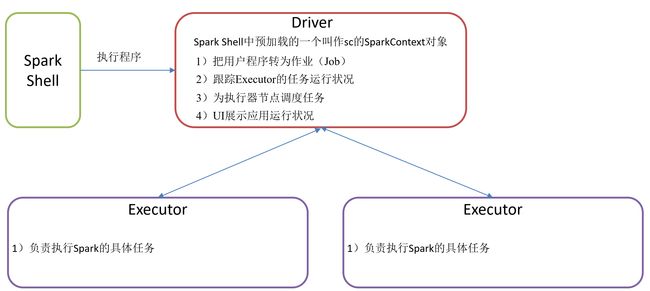
1.7 Driver和Executor任务的管理者
Driver和Executor是临时程序,当有具体任务提交到Spark集群才会开启的程序。 |
||||||||||||||||
1.8 几种模式对比
1.9 端口号总结1)Spark查看当前Spark-shell运行任务情况端口号:4040 2)Spark Master内部通信服务端口号:7077 (类比于yarn的8032(RM和NM的内部通信)端口) 3)Spark Standalone模式Master Web端口号:8080(类比于Hadoop YARN任务运行情况查看端口号:8088) 4)Spark历史服务器端口号:18080 (类比于Hadoop历史服务器端口号:19888) |

2. Spark运行模式及安装部署
| 部署Spark集群大体上分为两种模式:单机模式与集群模式 大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。 下面详细列举了Spark目前支持的部署模式。 (1)Local模式:在本地部署单个Spark服务 (2)Standalone模式:Spark自带的任务调度模式。(国内常用) (3)YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内最常用) (4)Mesos模式:Spark使用Mesos平台进行资源与任务的调度。(国内很少用) |
2.1 Spark安装
(1)scala环境搭建 解压、改名 [root@kb129 install]# tar -xvf ./scala-2.12.10.tgz -C ../soft/ [root@kb129 soft]# mv ./scala-2.12.10/ scala212 配置环境变量 [root@kb129 soft]# vim /etc/profile #SCALA_HOME [root@kb129 soft]# source /etc/profile
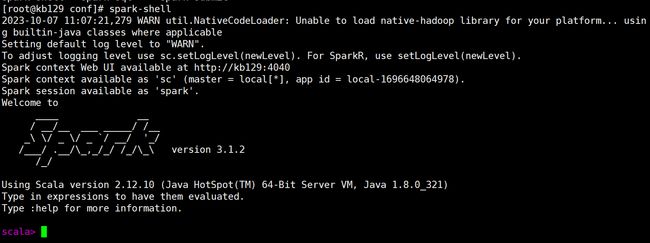
(2)spark安装部署 解压、改名 [root@kb129 install]# tar -xvf ./spark-3.1.2-bin-hadoop3.2.tgz -C ../soft/ [root@kb129 soft]# mv ./spark-3.1.2-bin-hadoop3.2/ spark312 拷贝配置文件,编辑 [root@kb129 conf]# cp spark-env.sh.template spark-env.sh [root@kb129 conf]# cp workers.template workers 配置环境变量 [root@kb129 conf]# vim /etc/profile #SPARK_HOME export SPARK_HOME=/opt/soft/spark312 export PATH=$SPARK_HOME/bin:$PATH [root@kb129 conf]# source /etc/profile 编辑配置文件 [root@kb129 conf]# vim ./workers
[root@kb129 conf]# vim ./spark-env.sh 末尾追加 export SCALA_HOME=/opt/soft/scala212 export JAVA_HOME=/opt/soft/jdk180 export SPARK_HOME=/opt/soft/spark312 export HADOOP_HOME=/opt/soft/hadoop313 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_MASTER_IP=192.168.142.129 export SPARK_DRIVER_MEMORY=2G export SPARK_EXECUTOR_MEMORY=2G export SPARK_LOCAL_DIRS=/opt/soft/spark312 spark-shell启动 [root@kb129 conf]# spark-shell
|



3. RDD概述
1.1 什么是RDDRDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。 代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。 |
1.2 RDD五大特性
|
| data 类型为RDD(分布式数据集)
RDD算子
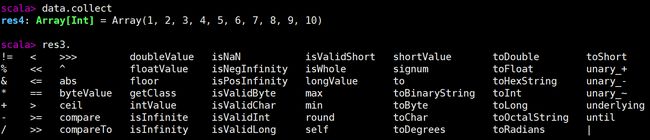
collect收集完装到数组中,数组函数如下
glom
repartition和coalesce的区别 两个都能调整分区数,但repartition的底层依然是调用了coalesce coalesce的语法: coalesce(num,shuffle=False) 默认不启动shuffle repartition的语法: repartition(num) 默认启动shuffle repartition中将shuffle改成了ture,且参数不可修改 因此,repartition常用于增加分区,coalesce常用于减小分区 关键就在于shuffle是否启动 重新分区的根本是通过hash取模后再分区,因此必须通过shuffle 分区数据重新分区时会出现1个分区数据分配到其他多个分区的情况,也就形成了「宽依赖」 减小分区的根本是将1个分区完整归类到另一个分区中,属于1对1的情况,也就形成「窄依赖」
创建RDD的第二种方式mkRDD
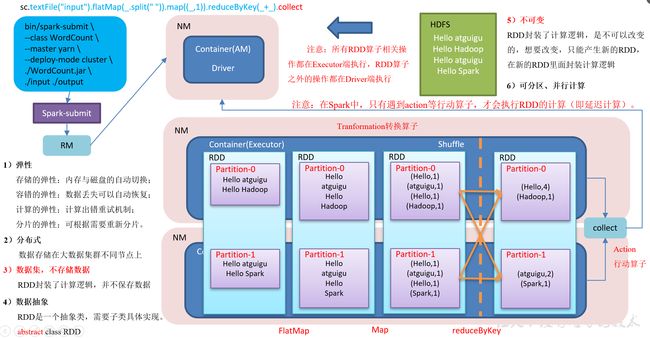
Spark wordcount案例 sc.textFile("hdfs://kb129:9000/kb23/tmp/*.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey(_+_).glom.collect
|
| WordCount工作流程及API
|
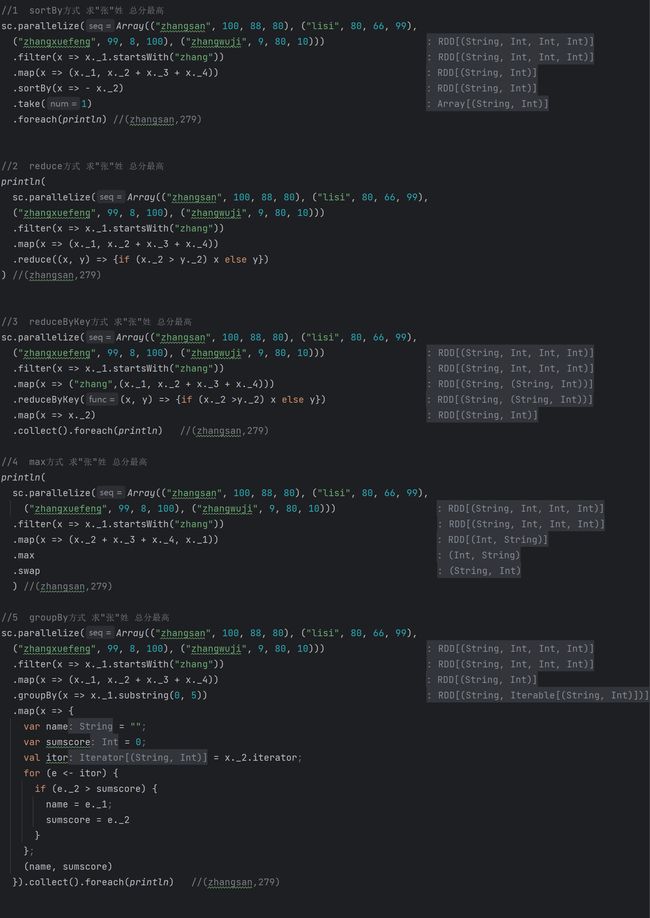
| RDD算子练习—求出“张”姓学生总分最高的学生姓名、总分
|
2.6 RDD依赖关系2.6.1 查看血缘关系RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。 2.6.3 窄依赖窄依赖表示每一个父RDD的Partition最多被子RDD的一个Partition使用(一对一or多对一),窄依赖我们形象的比喻为独生子女。
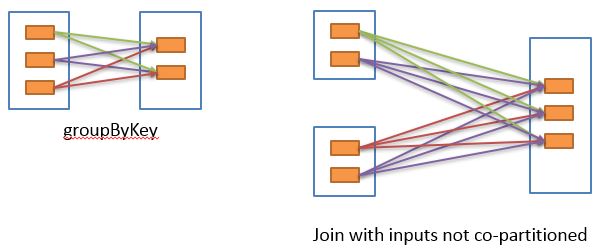
2.6.4 宽依赖宽依赖表示同一个父RDD的Partition被多个子RDD的Partition依赖(只能是一对多),会引起Shuffle,总结:宽依赖我们形象的比喻为超生。
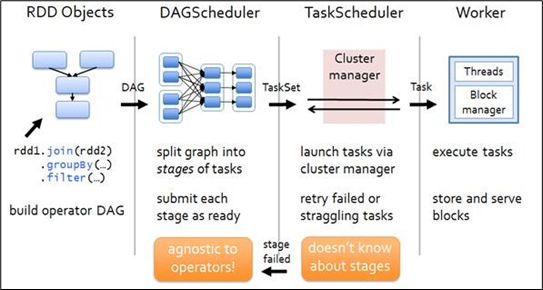
具有宽依赖的transformations包括:sort、reduceByKey、groupByKey、join和调用rePartition函数的任何操作。 宽依赖对Spark去评估一个transformations有更加重要的影响,比如对性能的影响。 在不影响业务要求的情况下,要尽量避免使用有宽依赖的转换算子,因为有宽依赖,就一定会走shuffle,影响性能 2.6.5 Stage任务划分(面试重点)1)DAG有向无环图 DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG记录了RDD的转换过程和任务的阶段。
2)任务运行的整体流程
3)RDD任务切分中间分为:Application、Job、Stage和Task (1)Application:初始化一个SparkContext即生成一个Application; (2)Job:一个Action算子就会生成一个Job; (3)Stage:Stage等于宽依赖的个数加1; (4)Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。 注意:Application->Job->Stage->Task每一层都是1对n的关系。 |
2.3 Transformation转换算子(面试开发重点)RDD整体上分为Value类型、双Value类型和Key-Value类型 2.3.1 Value类型map()映射 mapPartitions()以分区为单位执行Map mapPartitionsWithIndex()带分区号 flatMap()扁平化 glom()分区转换数组 groupBy()分组 filter()过滤 sample()采样 distinct()去重 coalesce()合并分区 repartition()重新分区(执行Shuffle) sortBy()排序 pipe()调用脚本 2.3.2 双Value类型交互intersection()交集 union()并集不去重 subtract()差集 zip()拉链 2.3.3 Key-Value类型partitionBy()按照K重新分区 reduceByKey()按照K聚合V groupByKey()按照K重新分组 aggregateByKey()按照K处理分区内和分区间逻辑
foldByKey()分区内和分区间相同的aggregateByKey() combineByKey()转换结构后分区内和分区间操作
sortByKey()按照K进行排序 mapValues()只对V进行操作 join()等同于sql里的内连接,关联上的要,关联不上的舍弃 cogroup()类似于sql的全连接,但是在同一个RDD中对key聚合 |
2.4 Action行动算子行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。 2.4.1 reduce()聚合2.4.2 collect()以数组的形式返回数据集2.4.3 count()返回RDD中元素个数2.4.4 first()返回RDD中的第一个元素2.4.5 take()返回由RDD前n个元素组成的数组2.4.6 takeOrdered()返回该RDD排序后前n个元素组成的数组2.4.7 aggregate()案例2.4.8 fold()案例2.4.9 countByKey()统计每种key的个数2.4.10 save相关算子2.4.11 foreach(f)遍历RDD中每一个元素 |
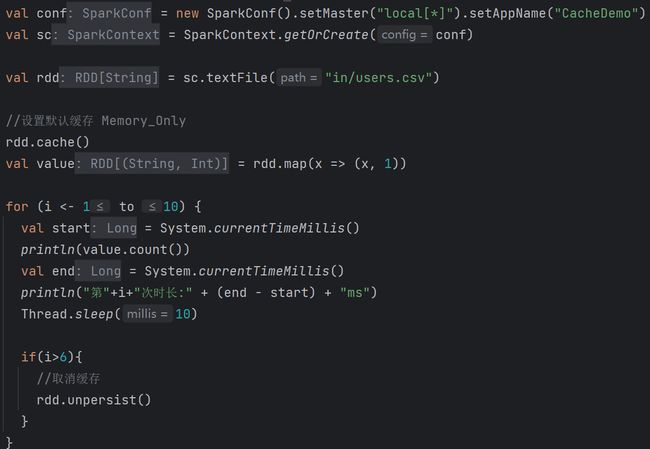
2.7 RDD持久化2.7.1 RDD Cache缓存RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。 3)自带缓存算子 Spark会自动对一些Shuffle操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点Shuffle失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist或cache。 2.7.2 RDD CheckPoint检查点1)检查点:是通过将RDD中间结果写入磁盘。 2)为什么要做检查点? 由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。 3)检查点存储路径:Checkpoint的数据通常是存储在HDFS等容错、高可用的文件系统 4)检查点数据存储格式为:二进制的文件 5)检查点切断血缘:在Checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移除。 6)检查点触发时间:对RDD进行Checkpoint操作并不会马上被执行,必须执行Action操作才能触发。但是检查点为了数据安全,会从血缘关系的最开始执行一遍。
2.7.3 缓存和检查点区别1)Cache缓存只是将数据保存起来,不切断血缘依赖。Checkpoint检查点切断血缘依赖。 2)Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。 3)建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。 4)如果使用完了缓存,可以通过unpersist()方法释放缓存
|











4. 广播变量
| 广播变量:分布式共享只读变量。 广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark Task操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来会很顺手。在多个Task并行操作中使用同一个变量,但是Spark会为每个Task任务分别发送。 1)使用广播变量步骤: (1)调用SparkContext.broadcast(广播变量)创建出一个广播对象,任何可序列化的类型都可以这么实现。 (2)通过广播变量.value,访问该对象的值。 (3)广播变量只会被发到各个节点一次,作为只读值处理(修改这个值不会影响到别的节点)。
|

5. 累加器
| 累加器:分布式共享只写变量。(Executor和Executor之间不能读数据) 累加器用来把Executor端变量信息聚合到Driver端。在Driver中定义的一个变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行合并计算。 |
6.Spark优化
| 性能优化参考Spark性能优化指南——基础篇 - 美团技术团队 1. 数据压缩:使用压缩格式(如Snappy或Gzip)来减少数据在磁盘和网络传输中的大小,从而减少IO开销。 2. 数据分区:合理地对数据进行分区,以便在执行操作时能够充分利用并行性。可以使用repartition或coalesce方法来重新分区数据。 3. 广播变量:对于较小的数据集,可以将其广播到所有的工作节点上,以减少数据传输开销。 4. 内存管理:通过调整Spark的内存分配参数,如spark.executor.memory和spark.driver.memory,来优化内存使用。 5. 数据持久化:对于需要多次使用的数据集,可以使用persist或cache方法将其缓存到内存中,以避免重复计算。 6. 使用合适的数据结构和算法:根据具体的业务需求,选择合适的数据结构和算法,以提高计算效率。 7. 并行度设置:根据集群的规模和资源情况,适当调整并行度参数,如spark.default.parallelism和spark.sql.shuffle.partitions。 8. 数据倾斜处理:当某些键的数据量远远大于其他键时,可能会导致任务不均衡。可以使用一些技术,如repartition、join优化或使用自定义分区器来处理数据倾斜问题。 9. 使用DataFrame和Dataset:相比于RDD,DataFrame和Dataset提供了更高层次的抽象和优化,可以更好地利用Spark的优化功能。 10. 使用专门的优化工具:Spark提供了一些专门的优化工具,如Spark UI和Spark调优指南,可以帮助识别和解决性能瓶颈。 |
7. Spark SQL概述
8. Spark SQL编程
2.1 SparkSession新的起始点在老的版本中,SparkSQL提供两种SQL查询起始点:
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。 SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的。当我们使用spark-shell的时候,Spark框架会自动的创建一个名称叫做Spark的SparkSession,就像我们以前可以自动获取到一个sc来表示SparkContext。 |
2.2 DataFrameDataFrame是一种类似于以RDD的分布式数据集,类似于传统数据库中的二维表格。 2.2.1 创建DataFrame在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口,创建DataFrame有三种方式:
2.2.2 SQL风格语法SQL语法风格是指我们查询数据的时候使用SQL语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助。 视图:对特定表的数据的查询结果重复使用。View只能查询,不能修改和插入。 select * from t_user where age > 30 的查询结果可以存储在临时表(视图)v_user_age中,方便在后面重复使用。例如:select * from v_user_age
2.2.3 DSL风格语法DataFrame提供一个特定领域语言(domain-specific language,DSL)去管理结构化的数据,可以在Scala,Java,Python和R中使用DSL,使用DSL语法风格不必去创建临时视图了。
|
2.3 DataSetDataSet是具有强类型的数据集合,需要提供对应的类型信息。 2.3.1 创建DataSet(基本类型序列)使用基本类型的序列创建DataSet (1)将集合转换为DataSet scala> val ds = Seq(1,2,3,4,5,6).toDS ds: org.apache.spark.sql.Dataset[Int] = [value: int] (2)查看DataSet的值 scala> ds.show +-----+ |value| +-----+ | 1| | 2| | 3| | 4| | 5| | 6| +-----+ 2.3.2 创建DataSet(样例类序列)使用样例类序列创建DataSet (1)创建一个User的样例类 scala> case class User(name: String, age: Long) defined class User (2)将集合转换为DataSet scala> val caseClassDS = Seq(User("wangyuyan",18)).toDS() caseClassDS: org.apache.spark.sql.Dataset[User] = [name: string, age: bigint] (3)查看DataSet的值 scala> caseClassDS.show +---------+---+ | name|age| +---------+---+ |wangyuyan| 18| +---------+---+ 注意:在实际开发的时候,很少会把序列转换成DataSet,更多是通过RDD和DataFrame转换来得到DataSet |
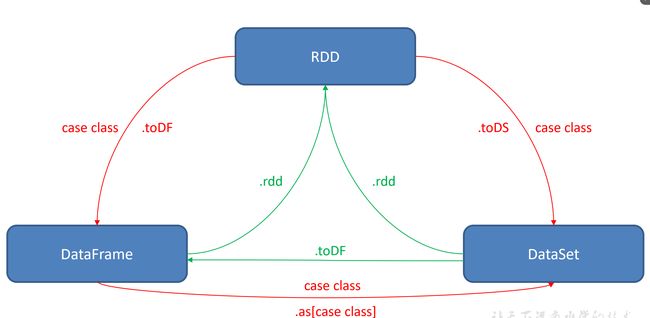
2.4 RDD、DataFrame、DataSet相互转换
|


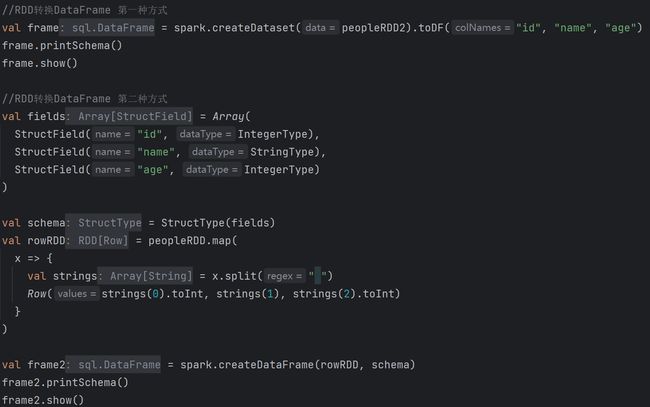
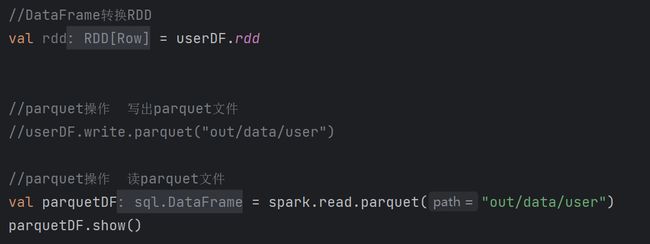
9. SparkSQL数据的加载与保存
3.1 加载数据1)加载数据通用方法 spark.read.load是加载数据的通用方法
|
3.2 保存数据1)保存数据通用方法 df.write.save是保存数据的通用方法
|
3.3 与MySQL交互(1)pom依赖
(2)API |
3.4 与Hive交互SparkSQL可以采用内嵌Hive,也可以采用外部Hive。企业开发中,通常采用外部Hive。 (1)交互准备 拷贝hive-site.xml至spark的conf目录下 [root@kb129 conf]# cp /opt/soft/hive312/conf/hive-site.xml ./ [root@kb129 conf]# vim ./hive-site.xml 追加配置
(2)启动hadoop和hive服务,成功连接上hive后,编写API
|



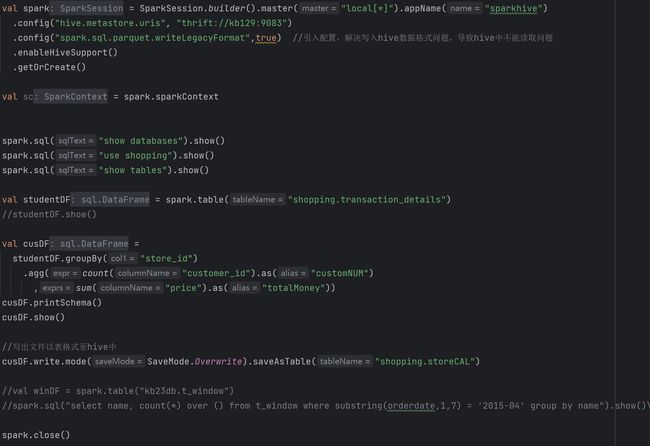
10.Spark数据分析及处理
| 用例1:数据清洗
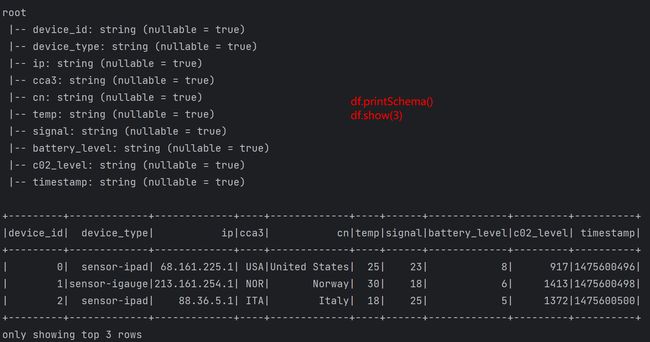
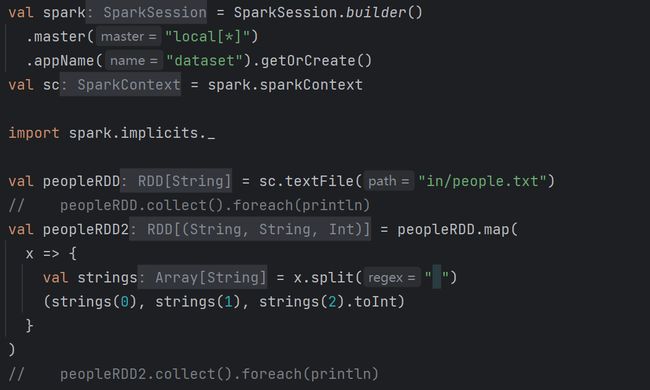
日志拆分字段: event_time url method status sip user_uip action_prepend action_client (1)创建DataFrame的两种方式
(2)数据清洗
(3)将数据写入MySQL中 1)创建JDBC工具类,配置连接及定义写入数据方式(Append或OverWrite)
2)写入代码
完整代码 (1)JdbcUtils (2)ETLDemo |



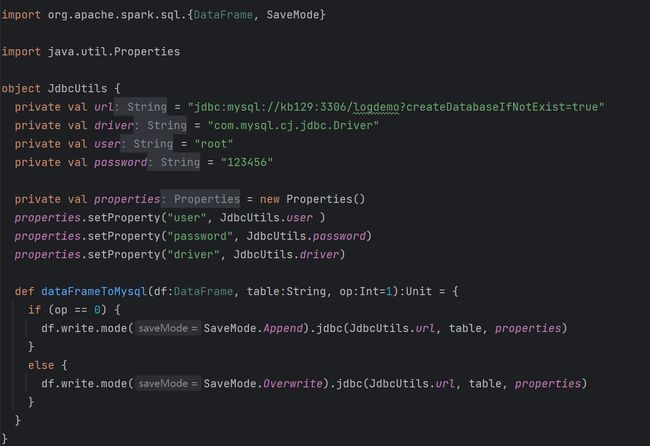

11. Spark高级操作之json复杂和嵌套数据结构的操作
| Json使用参考https://www.cnblogs.com/tomato0906/articles/7291178.html |
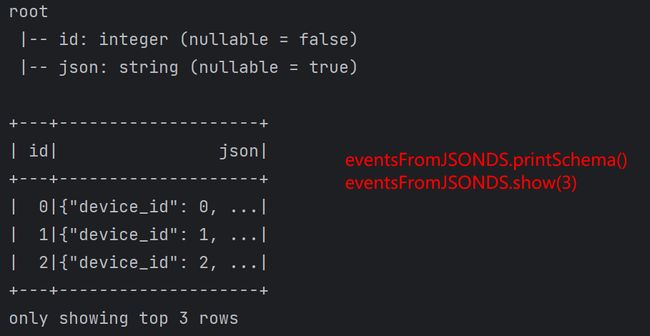
| 练习1—解析Json字符串及转DataFrame转JSON
|
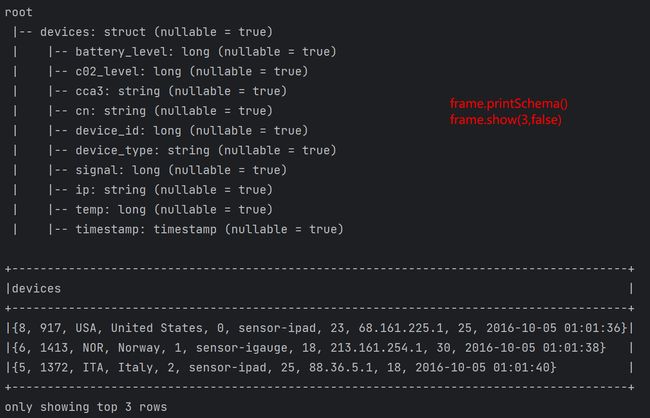
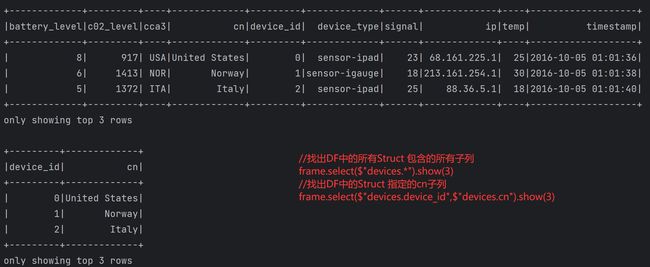
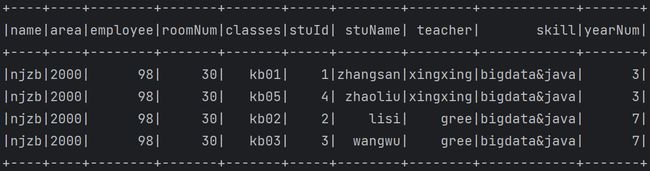
| 练习2---- 解析如下json {"name":"njzb","roomInfo":{"area":2000,"employee":98,"roomNum":30},"students":[{"classes":"kb01","stuId":"1","stuName":"zhangsan","teacher":"xingxing"},{"classes":"kb02","stuId":"2","stuName":"lisi","teacher":"gree"},{"classes":"kb03","stuId":"3","stuName":"wangwu","teacher":"gree"},{"classes":"kb05","stuId":"4","stuName":"zhaoliu","teacher":"xingxing"}],"teachers":[{"name":"gree","skill":"bigdata&java","yearNum":7},{"name":"xingxing","skill":"bigdata&java","yearNum":3}]}
|