Causal Attention论文详解
1. 背景介绍
Causal Attention论文是一篇因果推断(causal inference)和注意力(attention)结合的一篇文章,主要用在视觉和文本结合的领域,如VQA(Visual Question Answering)视觉问答。
VQA(Visual Question Answering)视觉问答的一个基本流程如下,对输入图进行self-attn编程得到K和V的向量,从文本得到Q的向量进行Attn计算,得到填空的结果(riding)。这个过程可以看成是一个因果推断的过程,对应的示意图如下X->Z->Y,X是输入,Z是模型过程,Y是输出,箭头表示相互依赖的关系。
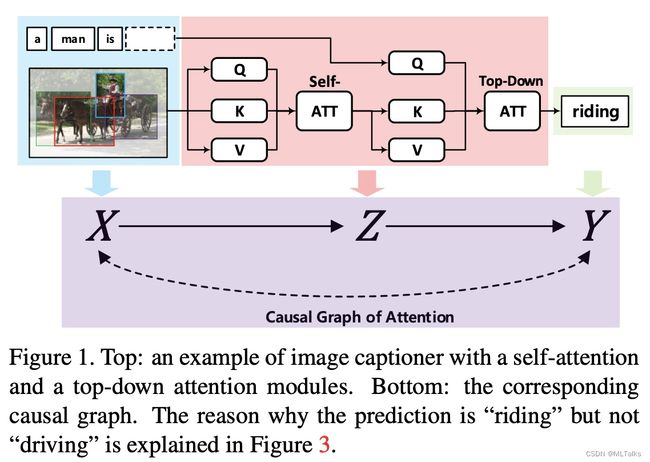
实际中由于训练数据中存在bias偏差会导致结果不对,比如下图,看图回答问题(在屏幕上显示的是什么运动),由于预训练数据中Sport+Man比Sport+Screen出现次数多的话,在回答时self-attn关注点会更注意Sport+Man(即下图红框部分,导致回答错误结果为跳舞)。为此这篇论文中提出了Causal Attention的方法。

2. 详细说明
2.1 因果推断confounder
在因果推断(causal inference)中有一个概念是confounder(也有叫Confounding factor), 中文意思是干扰因子,在因果推断中表示影响推导的不可知因素,举个例子如下,药物Drug会帮助恢复Recovery,但隐藏的因素是一个人的性别Gender可能会同时影响使用什么样的药物和恢复效果。这里的性别就是confounder。

这里的推断流程从 X → Y X \rightarrow Y X→Y 变为了 X ← Z → Y X \leftarrow Z \rightarrow Y X←Z→Y,用 P ( y ∣ d o ( x ) ) P(y|do(x)) P(y∣do(x)) 表示无偏估计的结果,也就是针对了相关的confounder因素进行了调整后的结果。公式表示如下,当且仅当没有confounder时, P ( y ∣ d o ( x ) ) = P ( y ∣ x ) P(y|do(x)) = P(y|x) P(y∣do(x))=P(y∣x) 。
P ( y ∣ d o ( x ) ) = ∑ z P ( y ∣ x , z ) P ( z ) \begin{gather*} P(y | do(x)) = \sum_zP(y|x, z) P(z) \end{gather*} P(y∣do(x))=z∑P(y∣x,z)P(z)
针对上面例子,对应的 P ( Y = r e c o v e r e d ∣ d o ( X = g i v e d r u g ) ) P(Y=recovered | do(X=give\ drug)) P(Y=recovered∣do(X=give drug)) 等于如下:
P ( Y = r e c o v e r e d ∣ d o ( X = g i v e d r u g ) ) = P ( Y = r e c o v e r e d ∣ X = g i v e d r u g , Z = m a l e ) P ( Z = m a l e ) + P ( Y = r e c o v e r e d ∣ X = g i v e d r u g , Z = f e m a l e ) P ( Z = f e m a l e ) \begin{gather*} P(Y=recovered | do(X=give\ drug)) = P(Y=recovered | X=give\ drug, Z=male) P(Z=male) + P(Y=recovered | X=give\ drug, Z=female) P(Z=female) \end{gather*} P(Y=recovered∣do(X=give drug))=P(Y=recovered∣X=give drug,Z=male)P(Z=male)+P(Y=recovered∣X=give drug,Z=female)P(Z=female)
在训练过程中数据bias就是由于cofounder(这里也被称为common sense的常识)引起的,如下图,C表示常识,常识存在多种,person can ride horse是常识中的一种, X表示通过person can ride horse产生的一个图片和对应的prompt(person can ride ___),M表示通过Faster-RCNN检测出来的物体object(person和horse), Y表示语言模型产生的推理结果person can ride horse。在训练中一个理想合法的推导是 X → M → Y X \rightarrow M \rightarrow Y X→M→Y,但实际中常识C也会对最终的结果Y有影响,即 X ← C → M → Y X \leftarrow C \rightarrow M \rightarrow Y X←C→M→Y。训练中计算的是按 P ( Y ∣ X ) P(Y|X) P(Y∣X),而实际中应该按 P ( Y ∣ d o ( X ) ) P(Y|do(X)) P(Y∣do(X)) 来计算。

2.2 Causal Attention公式表示
之前的attention机制可以看成是一个前向的因果推理图(X->Z->Y)。基于这个图Causal Attention中把attention拆为两部分,一个是选择器(selector),用于从数据X中选择合适的知识Z;另一个是推理器(predictor),通过选择的Z去探索推理结果Y。
以VQA为例,训练集是已知的,也就是计算的可观测的P(Y|X), Z表示训练中已有的知识,由于Z可以看成是从X中抽样出来一部分数据,所以计算的部分也叫为IS-Sampling。公式如下:
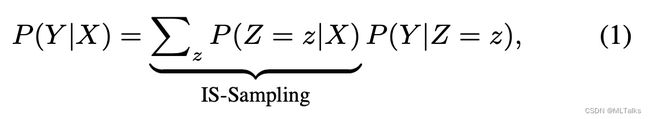
在训练过程中抽样的数据集存在潜在的偏差(bias),即Z <- X <-> Y, 需要进行修正,Z和Y之前的因果影响表示为 P ( Y ∣ d o ( Z ) ) P(Y|do(Z)) P(Y∣do(Z)), X -> Z的这部分可以通过对X进行拆解为多个不同的 { x } \{x\} {x} 来表示,公式如下, x表示可能的输入,这里叫做CS-Samping。

最终公式(2)代入公式(1)得到如下结果:

2.3 Causal Attention网络实现
P ( Y ∣ Z , X ) P(Y|Z,X) P(Y∣Z,X) 使用一个softmax层进行计算;如公式(3)所示,为了计算 P ( Y ∣ d o ( X ) ) P(Y|do(X)) P(Y∣do(X)) 要对X和Z进行采样,但是前向代价过大,所以采用了Normalized Weighted Geometric Mean (NWGM) 的近似方法,近似后公式如下, f ( ⋅ ) 、 h ( ⋅ ) f(\cdot)、h(\cdot) f(⋅)、h(⋅) 表示把输入X进行embedding后成为两个query set。

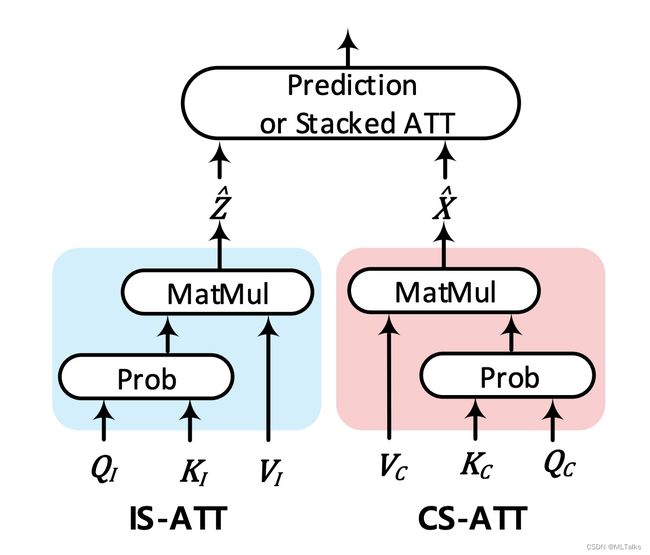
使用attention进行表示上述计算的话,In-Sample attention (IS-ATT)的结果 Z ^ \hat{Z} Z^如下, K I 和 V I K_I 和 V_I KI和VI来自当前的输入样本,如RoI的特征; Q I Q_I QI自于 h ( X ) h(X) h(X),在top-down attention中 q I q_I qI为上下文的embedding,在self-attention中 q I q_I qI也是RoI的特征。

Cross-Sample attention (CS-ATT)的结果 X ^ \hat{X} X^如下, K C 和 V C K_C 和 V_C KC和VC来自训练集中的其他样本, Q C Q_C QC自于 f ( X ) f(X) f(X)。

对应的网络图如下:
2.4 Causal Attention在堆叠attention网络中的应用
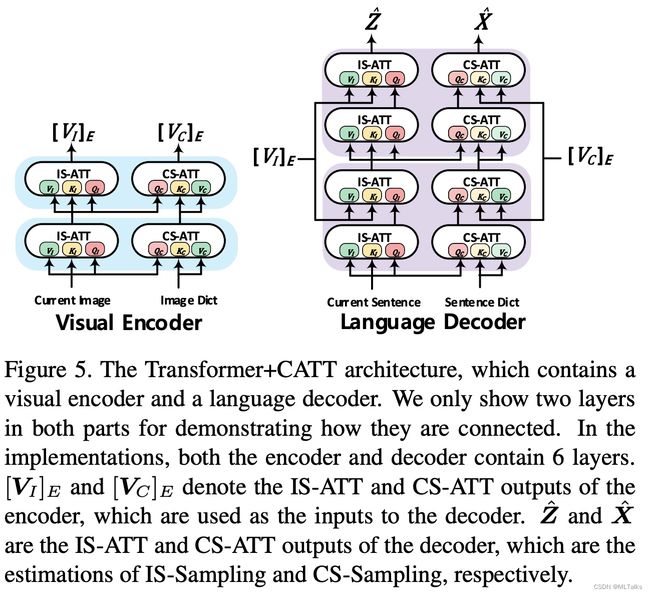
2.4.1 Transformer+CATT
在transformer中encoder和decoder实现如下图, [ V I ] E [V_I]_E [VI]E 和 [ V C ] E [V_C]_E [VC]E分别表示为IS-ATT和CS-ATT的encoder输出, Z ^ \hat{Z} Z^和 X ^ \hat{X} X^表示IS-ATT和CS-ATT的decoder输出。
2.4.2 LXMERT+CATT
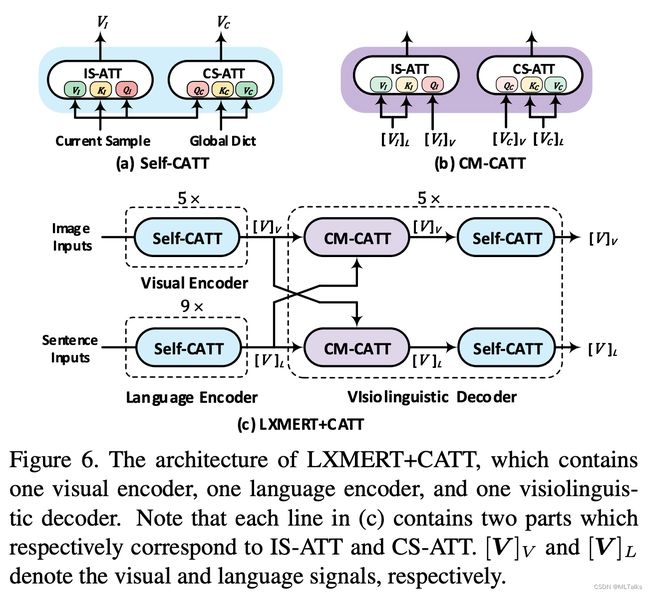
3. 参考
- Causal Attention for Vision-Language Tasks
- 论文笔记:Causal Attention for Vision-Language Tasks
- LXMERT: Learning Cross-Modality Encoder Representations from Transformers
- LXMERT
- Confounding
- Confounders: machine learning’s blindspot