Python每日一练(数据分析篇新题库)——第42天:排序、函数
文章目录
- 1. 某店铺消费最多的前三名用户
- 2. 按照等级递增序查看牛客网用户信息
- 3. 某店铺用户消费特征评分
- 4. 筛选某店铺最有价值用户中消费最多前5名
- 《100天精通Python》专栏推荐白嫖80g Python全栈视频
1. 某店铺消费最多的前三名用户
描述: 现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
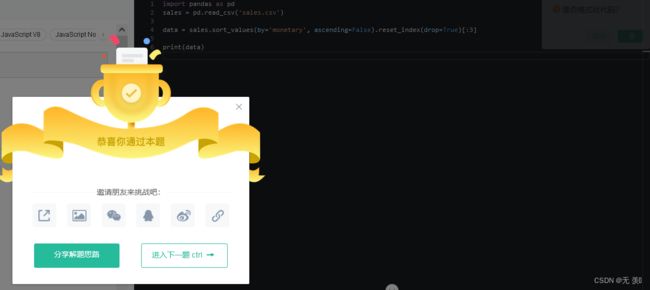
请你统计消费金额最多的前3名用户。
实现代码:
import pandas as pd
sales = pd.read_csv('sales.csv')
data = sales.sort_values(by='monetary', ascending=False).reset_index(drop=True)[:3]
print(data)
运行结果:
2. 按照等级递增序查看牛客网用户信息
描述: 现有一个Nowcoder.csv文件,记录了牛客网的部分用户的个人信息,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
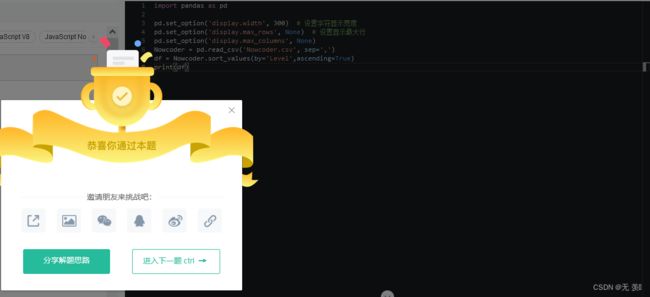
牛牛在查看这些数据的时候,等级都是混乱的,他想按照1-7级的递增序查看这些用户数据,你能帮他输出一下吗?
实现代码:
import pandas as pd
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
df = Nowcoder.sort_values(by='Level',ascending=True)
print(df)
运行结果:
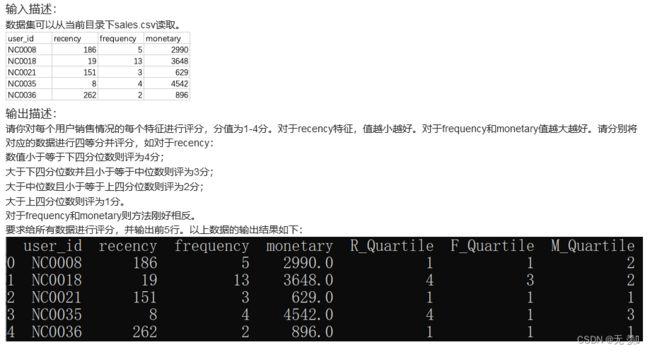
3. 某店铺用户消费特征评分
描述: 现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你分别对每个用户的每个消费特征进行评分。
实现代码:
import pandas as pd
sales = pd.read_csv('sales.csv')
# 按照结果要求转换类型
sales[['monetary']] = sales[['monetary']].astype('float32')
# 求百分位
des = sales[['recency', 'frequency', 'monetary']].describe().loc['25%':'75%']
# 计算RFM
sales['R_Quartile'] = sales['recency'].apply(lambda x: 4 if x <= des.iloc[0,0] else (3 if x <= des.iloc[1,0] else (2 if x <= des.iloc[2,0] else 1)))
sales['F_Quartile'] = sales['frequency'].apply(lambda x: 1 if x <= des.iloc[0,1] else (2 if x <= des.iloc[1,1] else (3 if x <= des.iloc[2,1] else 4)))
sales['M_Quartile'] = sales['monetary'].apply(lambda x: 1 if x <= des.iloc[0,2] else (2 if x <= des.iloc[1,2] else (3 if x <= des.iloc[2,2] else 4)))
#
print(sales.head())
运行结果:
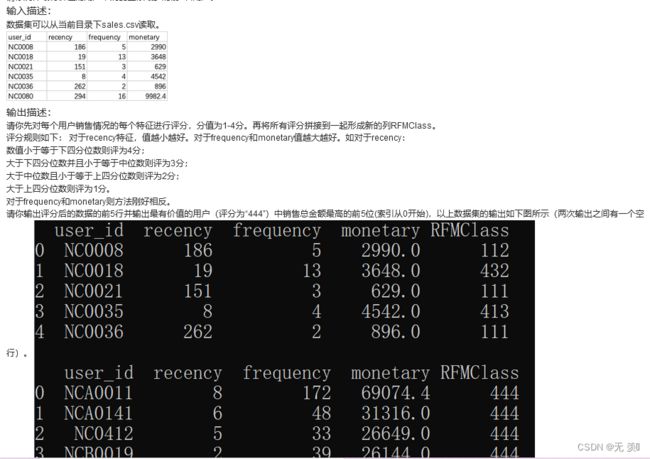
4. 筛选某店铺最有价值用户中消费最多前5名
描述: 现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你统计最有价值的用户中消费金额最多的前5名用户。
实现代码:
import pandas as pd
sales = pd.read_csv('sales.csv')
# 按照结果要求转换类型
sales[['monetary']] = sales[['monetary']].astype('float32')
# 求百分位
des = sales[['recency', 'frequency', 'monetary']].describe().loc['25%':'75%']
# 计算RFM
R = sales['recency'].apply(lambda x: 4 if x <= des.iloc[0,0] else (3 if x <= des.iloc[1,0] else (2 if x <= des.iloc[2,0] else 1))).astype('str')
F = sales['frequency'].apply(lambda x: 1 if x <= des.iloc[0,1] else (2 if x <= des.iloc[1,1] else (3 if x <= des.iloc[2,1] else 4))).astype('str')
M = sales['monetary'].apply(lambda x: 1 if x <= des.iloc[0,2] else (2 if x <= des.iloc[1,2] else (3 if x <= des.iloc[2,2] else 4))).astype('str')
# 合并RFM
sales['RFMClass'] = R+F+M
#
print(sales.head())
# 筛选444用户
sales1 = sales[sales['RFMClass'] == '444'].sort_values(by='monetary', ascending=False).reset_index(drop=True)
#
print(sales1.head())
运行结果:
《100天精通Python》专栏推荐白嫖80g Python全栈视频
《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)!
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等

