Happens-Before保证线程可见
前言
熟悉 Java 并发编程的都知道,JMM(Java 内存模型) 中的 happen-before规则,该规则定义了 Java 多线程操作的有序性和可见性,防止了编译器重排序对程序结果的影响。
按照官方的说法:
当一个变量被多个线程读取并且至少被一个线程写入时,如果读操作和写操作没有 happens-before 关系,则会产生数据竞争问题。
要想保证
操作 B的线程看到操作 A的结果(无论A和B是否在一个线程),那么在A和B之间必须满足 HB 原则,如果没有,将有可能导致重排序。当缺少 HB 关系时,就可能出现重排序问题。
happens-before有哪些规则?
happens-before关系主要强调两个有冲突的动作之间的顺序,以及定义数据争用的发生时间。
- 程序顺序规则:某个线程中的每个动作都happens-before该线程中该动作后面的动作。
- 监视器锁规则:某个管程(对象锁)上的unlock动作happens-before同一个管程上后续的lock动作。
- volatile变量规则:对某个volatile字段的写操作happens-before每个后续对该volatile字段的读操作。
- Join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
- 传递性:如果某个动作a happens-before动作b,且b happens-before动作c,则有a happens-before c。
- start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作。
- 程序中断规则:对线程interrupted()方法的调用先行于被中断线程的代码检测到中断时间的发生。
- 对象finalize规则:一个对象的初始化完成(构造函数执行结束)先行于发生它的finalize()方法的开始。
然后,再换个角度解释 happens-before:当一个操作 A happens-before 操作 B,那么,操作 A 对共享变量的操作结果对操作 B 都是可见的。同时,如果操作 B happens-before 操作 C,那么操作 A 对共享变量的操作结果对操作 B 都是可见的。
而实现可见性的原理则是 cache protocol 和 memory barrier。通过缓存一致性协议和内存屏障实现可见性。
如何实现同步?
在 Doug Lea 著作 《Java Concurrency in Practice》中,有下面的描述:
由于happens-before的排序功能很强大,因此有时候可以“借助(Piggyback)”现有同步机制的可见性属性。这需要将happens-before的程序顺序规则与其他某个顺序规则(通常是监视器或volatile变量规则)结合起来,从而对某个未被锁保护的变量的访问操作进行排序。这项技术由于对语句的顺序非常敏感,因此很容易出错。它是一项高级技术,并且只有当需要最大限度地提升某些类(例如ReetrantLock)的性能时,才应该使用这项技术。
书中提到:通过组合happens-before 的一些规则,可以实现对某个未被锁保护变量的可见性。但由于这个技术对语句的顺序很敏感,因此容易出错。
下面,将演示如何通过 volatile 规则和程序次序规则实现对一个变量同步。
/**
* 两个线程间隔打印出 0 – 100 的数字
**/
class ThreadPrintDemo {
static int num = 0;
static volatile boolean flag = false;
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
for (; 100 > num; ) {
if (!flag && (num == 0 || ++num % 2 == 0)) {
System.out.println(num);
flag = true;
}
}
}
);
Thread t2 = new Thread(() -> {
for (; 100 > num; ) {
if (flag && (++num % 2 != 0)) {
System.out.println(num);
flag = false;
}
}
}
);
t1.start();
t2.start();
}
}
这个 num 变量没有使用 volatile,会有可见性问题,即:t1线程更新了num,t2线程无法感知。
其实刚开始也是这么认为的,但最近通过研究 HB 规则,发现去掉 num 的 volatile 修饰也是可以的。
我们分析一下,如下图所示:
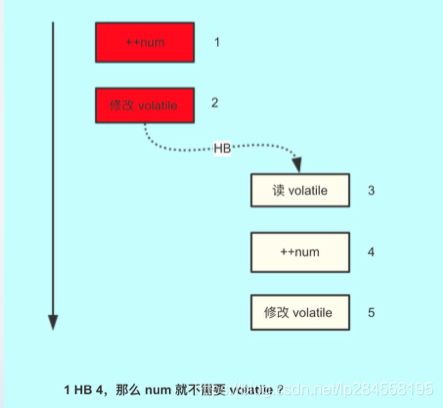
我们分析这个图:
- 首先,红色和黄色表示不同的线程操作。
- 红色线程对 num 变量做 ++,然后修改了 volatile 变量,这个是符合程序顺序规则的。也就是 1 happens-before 2.
- 红色线程对 volatile 的写happens-before 黄色线程对 volatile 的读,也就是 2 happens-before 3.
- 黄色线程读取 volatile 变量,然后对 num 变量做 ++,符合程序顺序规则,也就是 3 happens-before 4.
- 根据传递性规则,1 肯定 happens-before 4. 所以,1 的修改对 4来说都是可见的。
注意:happens-before 规则保证上一个操作的结果对下一个操作都是可见的。所以,上面的小程序中,线程 A 对 num 的修改,线程 B 是完全感知的 —— 即使 num 没有使用 volatile 修饰。
这样,我们就借助 happens-before 原则实现了对一个变量的同步操作,也就是在多线程环境中,保证了并发修改共享变量的安全性。并且没有对这个变量使用 Java 的原语:volatile 和 synchronized 和 CAS(假设算的话)。
这可能看起来不安全(实际上安全),也好像不太容易理解。因为这一切都是 happens-before 底层的 cache protocol 和 memory barrier 实现的。
其他规则实现同步
1. 利用线程终结规则实现:
static int a = 1;
public static void main(String[] args) {
Thread tb = new Thread(() -> {
a = 2;
});
Thread ta = new Thread(() -> {
try {
tb.join();
} catch (InterruptedException e) {
//NO
}
System.out.println(a);
});
ta.start();
tb.start();
}
2. 利用线程 start 规则实现:
static int a = 1;
public static void main(String[] args) {
Thread tb = new Thread(() -> {
System.out.println(a);
});
Thread ta = new Thread(() -> {
tb.start();
a = 2;
});
ta.start();
}
这两个操作,也可以保证变量 a 的可见性。
确实有点颠覆之前的观念。之前的观念中,如果一个变量没有被 volatile 修饰或 final 修饰,那么他在多线程下的读写肯定是不安全的(因为会有缓存),导致读取到的不是最新的。
然而,通过借助 happens-before,我们可以实现。
总结
虽然本文标题是通过 happen-before 实现对共享变量的同步操作,但主要目的还是更深刻的理解 happen-before,理解他的 happen-before 概念其实就是保证多线程环境中,上一个操作对下一个操作的有序性和操作结果的可见性。
同时,通过灵活的使用传递性规则,再对规则进行组合,就可以将两个线程进行同步— 实现指定的共享变量不使用原语也可以保证可见性。虽然这好像不是很易读,但也是一种尝试。
关于如何组合使用规则实现同步,Doug Lea 在 JUC 中给出了实践。
例如老版本的 FutureTask 的内部类 Sync(已消失),通过 tryReleaseShared 方法修改 volatile 变量,tryAcquireShared 读取 volatile 变量,这是利用了 volatile 规则;
通过在 tryReleaseShared 之前设置非 volatile 的 result 变量,然后在 tryAcquireShared 之后读取 result 变量,这是利用了程序次序规则。
从而保证 result 变量的可见性。和我们的第一个例子类似:利用程序次序规则和 volatile 规则实现普通变量可见性。
而 Doug Lea 自己也说了,这个“借助”技术非常容易出错,要谨慎使用。但在某些情况下,这种“借助”是非常合理的。
实际上,BlockingQueue 也是“借助”了 happen-before 的规则。还记得 unlock 规则吗?当 unlock 发生后,内部元素一定是可见的。
而类库中还有其他的操作也“借助”了 happen-before 原则:并发容器,CountDownLatch,Semaphore,Future,Executor,CyclicBarrier,Exchanger 等。
总而言之,言而总之:
happen-before 原则是JMM的核心所在,只有满足了happens-before原则才能保证有序性和可见性,否则编译器将会对代码重排序。happen-before甚至将lock和volatile也定义了规则。
通过适当的对 happen-before规则的组合,可以实现对普通共享变量的正确使用。
参考链接:https://www.01hai.com/note/av144549