Mysql牛客SQL语句练习
一、核心关键点的使用
1、Mysql排序
mysql默认采用升序的排序——ASC,如果要使用降序排序则使用DESC
select t.title,avg(s.salary) as avg
from titles t
inner join salaries s on t.emp_no = s.emp_no
group by t.title
order by avg desc;
2、窗口函数的使用
窗口函数是在Mysql之后版本出现的,可以理解为他可以在数据流的过程中对数据进行处理。处理过程中可以按照一定的规则对数据进行分组与排序从而生成我们想要的数据结构。不过在使用的过程中发现通过窗口函数生成的字段,在where中并不能使用,之后再通过一次子查询的形式方能使用排序形成的结果。这个现象按理说也很好的说明窗口函数是对where后者group by子句处理后的结果进行操作,因此按照SQL语句的运行顺序,窗口函数一般放在select子句中。
rank:如果order by的名词相同会使用相同的名词并且占用后边的名词;存在名词重复就必然存在断层
dense_rank:如果名次相同,会使用相同的名词但是不会占用下面的名词;排名会有重复但是不会有断层
row_number:这里会直接忽略重复的排名,直接延伸下去,既没有断层也没有重复;是不是有点像我们学校有时候那种不讲道理的排名呀
select emp_no,salary,
ROW_NUMBER() over (order by salary DESC) as row_rank,
DENSE_RANK() over (order by salary DESC) as den_rank,
RANK() over (order by salary DESC) as ra_rank
from salaries

在over中还可以使用分组的概念,但是这个分组并不会减少行数这是他与group by的一个区别
查询每个学生成绩最高的两个科目
这里我们使用的是专有的窗口函数,这里的分组可以看到他实际上是根据排序号之后再进行排名的
SELECT *
FROM (SELECT*,row_number() over (PARTITION BY 姓名 ORDER BY 成绩 DESC) AS ranking
FROM test1) AS newtest
WHERE ranking<=2;
除过使用专有的窗口函数我们还可以使用聚合函数来作为窗口函数,记录的是到当前行的排名,聚合函数的一个值。因为如果order by的列是相同的,那么聚合函数就是加上了他们的值之后的聚合函数结果,他们会是相同的
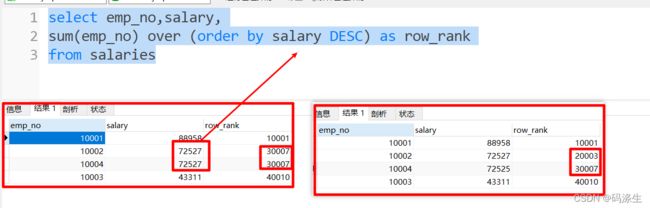
窗口函数还有一个用法就是,拍完序之后将数据集再作为一个子查询,在外面一层的查询中利用聚合函数来取得一些与排名大小有关的数据行。同时也可以考虑在一个select中多次使用窗口函数。
3、limit使用
select * from table limit m,n
其中m是指记录开始的index,从0开始,表示第一条记录n是指从第m+1条开始,取n条。
4、判断体的使用
-
三元运算符
select if(btype = 1,'奖金为10%','奖金超过10%') as mes from emp_bonus;
-
case语句
select em.emp_no,em.first_name,em.last_name,
eb.btype,asl.salary,
case eb.btype when 1 then 0.1*asl.salary when 2 then 0.2*asl.salary else 0.3*asl.salary end bonus
from employees em
left join emp_bonus eb on eb.emp_no = em.emp_no
left join salaries asl on em.emp_no = asl.emp_no
where to_date = DATE('9999-01-01')
-
非空判断
select ifnull(null,2)
-
else if判断体
❓这条语句不知道为什么执行不成功,就很纳闷;是因为数据库的原因吗
select IF btype = 1 THEN '奖金为10%' ELSEIF btype = 2 THEN '奖金为20%' ELSE '奖金为30%' END IF as mes from emp_bonus;
二、查询实例
1、查询薪资第二高低的人(不能使用order by)
在拿到这个题的时候第一反应是使用窗口函数结合排名来进行但是,窗口函数的排名还是需要用到order by关键字段的,排序能想到的就是通过使用聚合函数max、min来一步一步抹除了。
建表语句为:
drop table if exists `employees` ;
drop table if exists `salaries` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
INSERT INTO salaries VALUES(10004,74057,'2001-11-27','9999-01-01');
查询语句:
select em.emp_no,asl.salary,em.last_name,em.first_name
from employees em
inner join salaries asl on em.emp_no = asl.emp_no
where asl.salary = (
select max(salary) as sec_max
from salaries
where salary<(
select max(salary) as salary from salaries
)
limit 1
)
2、聚合函数的嵌套使用
建表语句
drop table if exists email;
drop table if exists user;
CREATE TABLE `email` (
`id` int(4) NOT NULL,
`send_id` int(4) NOT NULL,
`receive_id` int(4) NOT NULL,
`type` varchar(32) NOT NULL,
`date` date NOT NULL,
PRIMARY KEY (`id`));
CREATE TABLE `user` (
`id` int(4) NOT NULL,
`is_blacklist` int(4) NOT NULL,
PRIMARY KEY (`id`));
INSERT INTO email VALUES
(1,2,3,'completed','2020-01-11'),
(2,1,3,'completed','2020-01-11'),
(3,1,4,'no_completed','2020-01-11'),
(4,3,1,'completed','2020-01-12'),
(5,3,4,'completed','2020-01-12'),
(6,4,1,'completed','2020-01-12');
INSERT INTO user VALUES
(1,0),
(2,1),
(3,0),
(4,0);
题目分析
筛选出每个日期中正常与正常用户发送邮件失败的概率,在实现的过程中一个关键的难点就是如何按日期进行分组的同时统计邮件总数以及发送不成功的邮件数。按照日期分组并且统计邮件数这是常规操作,主要的一点就是有如何同时统计出不成功的数,并进行计算。如果不考虑性能与优雅的话只需要多套几层就可以实现这个功能,但明显这并不是出题者的本意。网上的一个实现是结合判断体同时使用嵌套的聚合函数。
select email.date, round(
sum(case email.type when'completed' then 0 else 1 end)*1.0/count(email.type),3
) as p
from email
join user as u1 on (email.send_id=u1.id and u1.is_blacklist=0)
join user as u2 on (email.receive_id=u2.id and u2.is_blacklist=0)
group by email.date order by email.date;