【C++】STL:stack/queue/priority_queue/deque
来喽,STL的栈和队列!
文章目录
- 1.Stack
-
- 1.1 容器适配器
- 1.2 模拟实现
- 2.queue
-
- 2.1 模拟实现
- 3.priority_queue
-
- 3.1 make_heap
- 3.2 函数接口
- 3.3 仿函数
- 3.4 模拟实现
- 4.deque
-
- 4.1存储结构
- 结语
1.Stack
栈是一个遵循LIFO规则的容器,即后进先出(last in first out)。后放入容器内的数据会先出来。
如果你不太理解栈的性质,可以先看看我写的C语言栈的博客【链接】
打开Cplusplus一看,栈的函数肉眼可见的少。这和我们C语言实现的功能基本是一样的。

它甚至没有拷贝构造!
1.1 容器适配器
等会,这个container是什么玩意?
别急,先让我们来看看栈的类定义
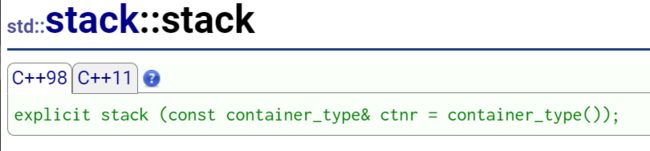
std::stack
template <class T, class Container = deque<T> > class stack;
和之前不同的是,这里出现了container,和一个我们好像没有接触过的deque
搜索后得知,deque也是一种容器,被称为双端队列

- 那么栈为什么需要一个容器呢?
实际上,栈不是直接写出来的代码,而是借用了deque这个容器,进行封装后的结果。
意思就是,栈其实是解用了别人的代码!
比如deque有头插头删,尾插尾删。而我们的栈只需要尾插尾删,那么我们包装一下deque,只提供尾插尾删的函数,不就成了栈了?

1.2 模拟实现
直接这么说可能有点干巴巴,我们直接上代码!
template<class T, class Container = deque<T>>
class stack {
public:
size_t size()const {
return _con.size();
}
const T& top() {
return _con.back();
}
void push(const T& val) {
_con.push_back(val);
}
void pop() {
_con.pop_back();
}
bool empty() {
return _con.empty();
}
private:
Container _con;
};
以上便是栈的模拟实现代码!
What?这就结束了?——甚至写的比我们C语言版本的栈更少!

本质上,我们只需要创建一个Container的对象 _con,再借助这个对象的函数进行封装,就完成了一个栈!
因为模板里面默认传入的是deque,所以这里用的便是deque的函数了。这就好比函数传入了一个缺省值。你可以将deque换成其他有尾插尾删函数的容器,比如vector
测试一下,莫得问题!

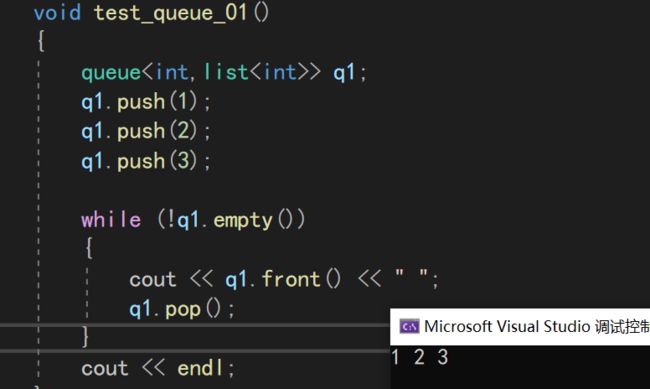
2.queue
和栈不同,队列遵循FIFO,即先进先出(first in first out)

同样的,我们只需要包装一下容器,即可完成模拟实现
std::queue
template <class T, class Container = deque<T> > class queue;
2.1 模拟实现
template<class T, class Container = deque<T>>
class queue {
public:
size_t size()const{
return _con.size();
}
const T& front(){
return _con.front();
}
const T& back(){
return _con.back();
}
void push(const T& val){
_con.push_back(val);
}
void pop(){
_con.pop_front();
}
bool empty(){
return _con.empty();
}
private:
Container _con;
};
需要注意的是,队列就不能用vector来当作容器辣!因为vector头插删的效率很低,需要挪动数据。我们可以使用list来当作容器
当然,你可以把头插头删改成insert和erase,但是那样没有意义,依旧拖慢了效率
因为栈和队列压根不支持迭代器,自然也没有迭代器失效问题!
了解完相对简单的栈和队列之后,我们可以直接来看看优先级队列
3.priority_queue
优先级队列和queue同属于头文件
template <class T, class Container = vector<T>,
class Compare = less<typename Container::value_type> > class priority_queue;
- 那么它和普通的队列有什么不同呢?
优先级队列是一个堆,且默认是大堆
如果你不知道堆是什么,可以看看我之前C语言数据结构的博客【链接】
简单说来,堆的堆顶(这里是第一个数据)一直保持着最大值或者最小值。每一次插入、删除操作,都需要向上、向下重新调整容器内元素的位置
3.1 make_heap
这里简单说一下另外一个函数make_heap,这个函数可以通过迭代器区间,将区间内的数据调整为一个堆。

在文档介绍里面可以看到,最后一行提到了优先级队列就是自动调用make_heap函数来维护自己堆的属性的
![]()
3.2 函数接口
优先级队列本质上还是一个队列,它提供的函数也很少
不同的是,这里的top堆顶指的是容器中首个元素,pop也是移除堆顶元素

3.3 仿函数

注意这里出现了第三个模板参数,Compare
这是一个仿函数,其就是一个类,但是仿照了函数的调用方式
想做到这一点,我们需要重载()操作符
//仿函数,重载()操作符
template<class T>
struct less {
bool operator()(const T& a, const T& b)const
{
return a < b;
}
};
//大于比较
template<class T>
struct greater{
bool operator()(const T& a, const T& b)const
{
return a > b;
}
};
比如这里的less和greater就是两个仿函数,优先级队列需要用它来进行比较。这样我们就可以快速在大堆和小堆直接进行切换。
它们的使用方式和函数是一样的!不过在使用之前,我们需要先创建一个对象
less func;
func(1,2);
库函数中的less和greater都在

- std库中优先级队列默认传的less小于比较,为大堆!
- 我们可以手动传入greater,即可变成小堆
3.4 模拟实现
在3.3中,我们已经实现出了库函数中的less和greater这两个仿函数,接下来我们只需要包装一下优先级队列的接口,即可使用!
template <class T, class Container = vector<T>,class Compare = less<T> >
class priority_queue
{
public:
size_t size()const {
return _con.size();
}
const T& top() {
return _con[0];
}
bool empty() {
return _con.empty();
}
//向上调整
void AdjustUp(size_t child)
{
Compare comFunc;
while (child > 0)
{
size_t parent = (child - 1) / 2;
if (comFunc(_con[parent],_con[child]))//小堆,小的数据往上调
{
std::swap(_con[parent], _con[child]);
child = parent;
}
else
{
return;
}
}
}
//向下调整
void AdjustDown(size_t parent)
{
Compare comFunc;
size_t child = parent * 2 + 1;//左孩子
while (child < _con.size())
{
//找左右孩子中小的那一个
if (child + 1 < _con.size() && comFunc(_con[child], _con[child + 1]))
{//如果左孩子大于右孩子,则选择右孩子
child++;
}
if (comFunc(_con[parent],_con[child]))
{
std::swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
return;
}
}
}
//因为是优先级队列,所以需要进行调整
//默认情况下第一个元素始终是最大元素
void push(const T& val)
{
_con.push_back(val);
AdjustUp(_con.size() - 1);
}
void pop()
{
assert(!_con.empty());
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
AdjustDown(0);
}
private:
Container _con;
};
这里需要注意的便是adjustdown/up这两个用来维持堆属性的调整函数,你可以看我之前的博客,里面有关于这部分的详细解释!回到上面
先来测试一下默认大堆的属性

可以看到,打印出来的数据是按从大到小顺序存放的!
如果我们显示传入greatre仿函数,就会变成从小到大

同时,即便我们pop了一部分数据,也不会影响堆的属性

优先级队列在一部分地方可以用于帮我们找到一段数据中的topK和第n个最大/小的数据
比如下面这道leetcode OJ题目215. 数组中的第K个最大元素
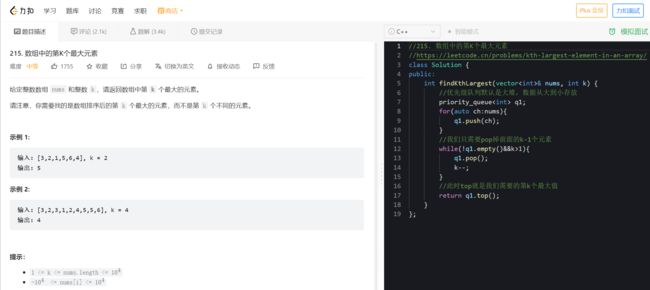
我们只需要pop掉前面的K-1个元素,这时候的堆顶就是我们需要的第K个最大值
4.deque
前面已经提到了deque这个容器,它拥有的库函数和vector很相似,这里我们不关注如何使用这个容器,而是来谈谈这个“双端队列”相比于vector/list有没有什么优势
std::deque
template < class T, class Alloc = allocator<T> > class deque;
4.1存储结构
deque最特殊的就是它的存储结构了。它并不是一个连续的结构,也不像链表一样每个数据都有自己的单独节点
这个是百度百科上找到的一张图片

https://www.cnblogs.com/yifengs/p/15190416.html
其实deque有点类似二维数组,其中有一个头指针指向队列头,一个尾指针指向队列尾部。主数组“中控器”存放的则是这些数组的指针。注:每一个数组的容量大小都是一样的,所以存放在中间的数组一定是满的!

这样我们就避免了list节点分散,需要多次开空间,无法随机访问的缺陷;又可以灵活快速地进行头插头删操作,而不需要挪动数据。
当然,deque的随机访问性能肯定不如数据连续存储的vector,其更适合下面的场景:
- 需要高性能的头插头删,尾插尾删
- 偶尔需要进行随机访问
结语
关于栈和队列的部分到这里就结束辣!
我们还认识了双端队列deque,以及让其作为容器的模拟实现操作
有任何问题,欢迎评论提出!