【elasticsearch】elasticsearch7.x集群搭建
目录
一、服务器情况
二、安装前准备
1、下载es
2、配置服务器免密登录
3、升级jdk
三、安装es集群
(一)master服务器的操作
1、将es上传到Linux并解压
2、创建数据、日志存储文件夹
3、配置config/elasticsearch.yml
4、配置jvm
5、创建es用户
6、赋权限
7、修改配置文件
8、启动服务
9、启动验证
(二)slaves服务器的操作
四、遇到的问题
一、服务器情况
这里使用三台服务器,安装部署es集群。其中安装的es7.9.0版本需要jdk11。这里在centos7服务器上安装。
| 服务器 | 安装es版本 | jdk版本 | linux系统 |
| master | 7.9.0 | 11 | Centos7 |
| slaves1 | 7.9.0 | 11 | Centos7 |
| slaves2 | 7.9.0 | 11 | Centos7 |
二、安装前准备
1、下载es
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.0-linux-x86_64.tar.gz
官网也可以其他版本下载:Download Elasticsearch | Elastic
2、配置服务器免密登录
Linux_SSH免密登录
3、升级jdk
jdk11下载地址:https://repo.huaweicloud.com/java/jdk/11+28/jdk-11_linux-x64_bin.tar.gz
# 编辑文件
vim /etc/profile
# 配置内容
export JAVA_HOME=/usr/lib/jvm/jdk-11
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 保存
source /etc/profile三、安装es集群
(一)master服务器的操作
1、将es上传到Linux并解压
将下载好的es上传到Linux的/opt/softWare/estacsearch文件夹下并解压:
tar -zxvf elasticsearch-7.9.0-linux-x86_64.tar.gz
解压之后的文件夹为:elasticsearch-7.9.0
![]()
2、创建数据、日志存储文件夹
在Linux的/opt/softWare/estacsearch文件夹下创建数据和日志存储文件夹:
mkdir logs
mkdir data
3、配置config/elasticsearch.yml
# 集群名称
cluster.name: my-application
# 节点名称,仅仅是描述名称,用于在日志中区分
node.name: node-1
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
# 数据的存放路径
path.data: /opt/softWare/elasticsearch/data
# 日志的存放路径
path.logs: /opt/softWare/elasticsearch/logs
# 当前节点的IP地址
network.host: 192.168.xxx.xxx
# 对外提供服务的端口,9300为集群服务的端口
http.port: 9200
transport.tcp.port: 9300
transport.tcp.compress: true
# 集群每个节点IP地址。
discovery.seed_hosts: ["192.168.xxx.xxx:9300", "192.168.xxx.xxx:9300","192.168.xxx.xxx:9300"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# 为了避免脑裂,集群节点数最少为 半数+1
discovery.zen.minimum_master_nodes: 2
#只要指定数量的节点加入集群,就开始进行恢复
gateway.recover_after_nodes: 2
gateway.recover_after_time: 5m
#要求必须有多少个节点在集群中,当加入集群中的节点数量达到这个期望数值之后,每个node的local shard的恢复就会理解开始,默认的值是0,也就是不会做任何的等待
gateway.expected_nodes: 2
#查询结果在分片上找到的条目超过了限定的10000个,官网限制在10000是为了其性能考虑的。需要调大search.max_buckets这个参数。
search.max_buckets: 90000000
#es的查询参数限制,默认是限制只能传入1024个参数
indices.query.bool.max_clause_count: 10240
#将阻止主副本分片被分配到同一台物理机,提高可用性。
cluster.routing.allocation.same_shard.host: true
#ES默认开启了内存地址锁定,为了避免内存交换提高性能。但是Centos6不支持SecComp功能,启动会报错,Centos7支持
bootstrap.memory_lock: true
#设置是否压缩tcp传输时的数据,默认为false,不压缩。
#transport.tcp.compress: true
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"
4、配置jvm
配置config/jvm.options文件,一般默认。也可以根据物理内存的实际情况设置,一般设置物理内存的一半。如果太小会导致Elasticsearch刚刚启动就立刻停止。太大会拖慢系统本身。
-Xms2g
-Xmx2g
5、创建es用户
由于安全的考虑,elasticsearch不允许使用root用户来启动,所以需要创建一个新的用户,并为这个账户赋予相应的权限来启动elasticsearch集群。创建的时候要在root用户下创建。
useradd elk
6、赋权限
将es安装目录赋予创建的新用户权限。这里data和logs都在安装目录下,可以直接对一个目录赋权限。如果日志和数据目录在其他位置也要单独赋权限。
chown -R elk:elk /opt/softWare/elasticsearch
7、修改配置文件
vim /etc/sysctl.conf
vm.max_map_count=655360 #末尾添加一行#保存加载参数
sysctl -p
8、启动服务
先切换到elk目录下:
su elk
再进入bin目录下启动es
./elasticsearch
也可后台启动
nohup ./elasticsearch &
9、启动验证
http://192.168.xxx.xx:9200/
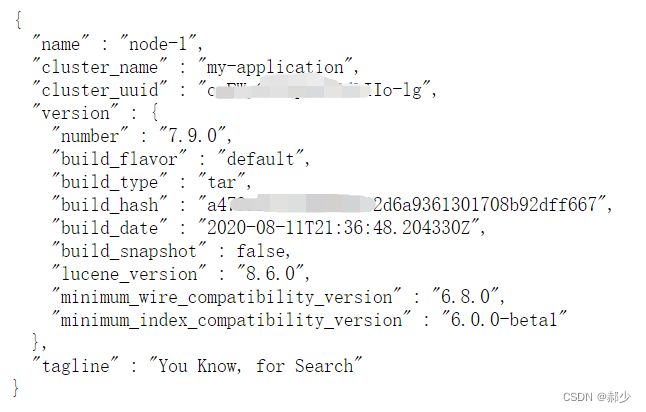
(二)slaves服务器的操作
slaves1和slaves2的操作步骤基本和master上的操作一样,唯一不同的就是config/elasticsearch.yml里面的几个配置项。
三台机器不同配置项如下,其他配置项都相同。
node.name: node-1 #master
node.name: node-2 #slaves1
node.name: node-3 #slaves2network.host: 192.168.xxx.xxx #master的ip
network.host: 192.168.xxx.xxx #slaves1的ip
network.host: 192.168.xxx.xxx #slaves2的ip
四、遇到的问题
问题一:进程内存锁定失败
ERROR: [1] bootstrap checks failed
[1]: memory locking requested for elasticsearch process but memory is not locked
解决办法:修改/etc/security/limits.conf文的件内容,取消限制
elk soft memklock unlimited
elk hard memlock unlimited
注意:这里的elk为自己创建的es用户。
问题二:
[1]: max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
解决办法:编辑 /etc/security/limits.conf,追加以下内容:
* soft nofile 65536
* hard nofile 65536
问题三:
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:编辑 /etc/sysctl.conf,追加以下内容:
vm.max_map_count=655360
保存后执行:
sysctl -p