Task03基于鸢尾花iris数据集的逻辑回归分类实践
Task03 基于鸢尾花iris数据集的逻辑回归分类实践
一、学习内容概括
掌握基于鸢尾花数据集的逻辑回归分类预测。
学习地址、参考资料:
1.阿里云天池-AI训练营机器学习:https://tianchi.aliyun.com/specials/promotion/aicampml?invite_channel=1&accounttraceid=7df048c2ce194081b514fd2c8e9a3f00cqmm
2.Sklearn中文文档:http://www.scikitlearn.com.cn/
3.Matplotlib.pyplot:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.html#module-matplotlib.pyplot
4.Numpy手册:https://numpy.org/doc/stable/index.html
5.PandasAPI:https://pandas.pydata.org/pandas-docs/stable/reference/index.html
6.seaborn:http://seaborn.pydata.org/index.html
二、具体学习内容
1 库函数导入
## 基础函数库
import numpy as np
import pandas as pd
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns导入一些基础的函数库包括:numpy (Python进行科学计算的基础软件包),pandas(pandas是一种快速,强大,灵活且易于使用的开源数据分析和处理工具),matplotlib和seaborn绘图。
2 数据读取/载入
## 我们利用 sklearn 中自带的 iris 数据作为数据载入,并利用Pandas转化为DataFrame格式
from sklearn.datasets import load_iris
data = load_iris() #得到数据特征
iris_target = data.target #得到数据对应的标签
iris_features = pd.DataFrame(data=data.data, columns=data.feature_names)iris_features:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
| ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
150 rows × 4 columns
2.1 鸢尾花数据集介绍
7.2.2鸢尾花数据集:https://scikit-learn.org/stable/datasets/index.html#datasets
本次我们选择鸢花数据(iris)进行方法的尝试训练,该数据集一共包含5个变量,其中4个特征变量,1个目标分类变量。共有150个样本,目标变量为 花的类别 其都属于鸢尾属下的三个亚属,分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。包含的三种鸢尾花的四个特征,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm),这些形态特征在过去被用来识别物种。
| 变量 | 描述 |
|---|---|
| sepal length | 花萼长度(cm) |
| sepal width | 花萼宽度(cm) |
| petal length | 花瓣长度(cm) |
| petal width | 花瓣宽度(cm) |
| target | 鸢尾的三个亚属类别,'setosa'(0), 'versicolor'(1), 'virginica'(2) |
2.2 代码分析
2.2.1 sklearn.datasets.load_iris:鸢尾花数据集
参考资料:https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_iris.html#sklearn.datasets.load_iris
sklearn.datasets软件包嵌入了一些小型标准数据集,load_iris()函数加载并返回iris数据集。返回的数据集是一个类似字典的对象,本例的数据集实例放在iris变量中,数据集的数据存储在.data成员中,它是 n_samples,n_features 数组。在监督问题的情况下,数据对应的标签存储在.target成员中。另外,数据集iris的feature_names属性表示数据集列的名称。
2.2.2 Pandas.DataFrame:二维,大小可变,潜在异构的表格数据
参考资料:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html#pandas.DataFrame
相关代码:iris_features = pd.DataFrame(data=iris.data, columns=iris.feature_names)
类:class DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
data:数据。iris.data是(150,4)的数组,150是训练样本数,4是特征变量数。
columns:特征变量名/标签名。4个,分别是sepal length、sepal width、petal length、petal width。
3 数据信息简单查看
## 利用.info()查看数据的整体信息
iris_features.info()运行结果:
RangeIndex: 150 entries, 0 to 149
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
dtypes: float64(4)
memory usage: 4.8 KB
## 利用 .head() 头部.tail()尾部进行简单的数据查看
iris_features.head()运行结果:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
iris_features.tail()| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 145 | 6.7 | 3.0 | 5.2 | 2.3 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
## iris_target为数据对应的类别标签,共150个。其中0,1,2分别代表'setosa', 'versicolor', 'virginica'三种不同花的类别。
iris_target运行结果:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])## 利用value_counts函数查看每个类别数量
pd.Series(iris_target).value_counts()运行结果:
2 50
1 50
0 50
dtype: int643.1 pandas.Series:具有轴标签(包括时间序列)的一维ndarray。
相关代码:pd.Series(iris_target).value_counts()
class pandas.Series:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html#pandas.Series
类:class pandas.Series(data = None,index = None,dtype = None,name = None,copy = False,fastpath = False)
pd.Series(iris_target)运行结果:
0 0
1 0
2 0
3 0
4 0
..
145 2
146 2
147 2
148 2
149 2
Length: 150, dtype: int64Series.value_counts:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.value_counts.html#pandas.Series.value_counts
方法:Series.value_counts(normalize = False,sort = True,升序= False,bins = None,dropna = True)返回一个包含唯一值计数的系列Series。生成的对象将按降序排列,以便第一个元素是最频繁出现的元素。
## 对于特征进行一些统计描述
iris_features.describe()运行结果:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| count #该列的非NA/空观测值的数量 | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean #该列的均值 | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std #该列的标准差 | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min #该列的最小值 | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% #上四分位数 | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% #中位数 | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% #下四分位数 | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max #该列的最大值 | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
3.2 pandas.DataFrame.describe:生成描述性统计信息,信息包括总结数据集分布的集中趋势,离散度和形状(不包括NaN值)的统计量。
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.describe.html#pandas.DataFrame.describe
方法:DataFrame.describe(percentiles=None, include=None, exclude=None, datetime_is_numeric=False)
4 可视化描述
## 合并标签和特征信息
iris_all = iris_features.copy() ##进行浅拷贝,防止对于原始数据的修改
iris_all['target'] = iris_targetiris_features是150行x4列,iris_all拷贝后又增加一列target,iris_target是含150个标签值的一维数组,现在iris_all是150行x5列。
#特征与标签组合的散点可视化
sns.pairplot(data=iris_all, diag_kind='hist', hue='target')
plt.show()运行结果:
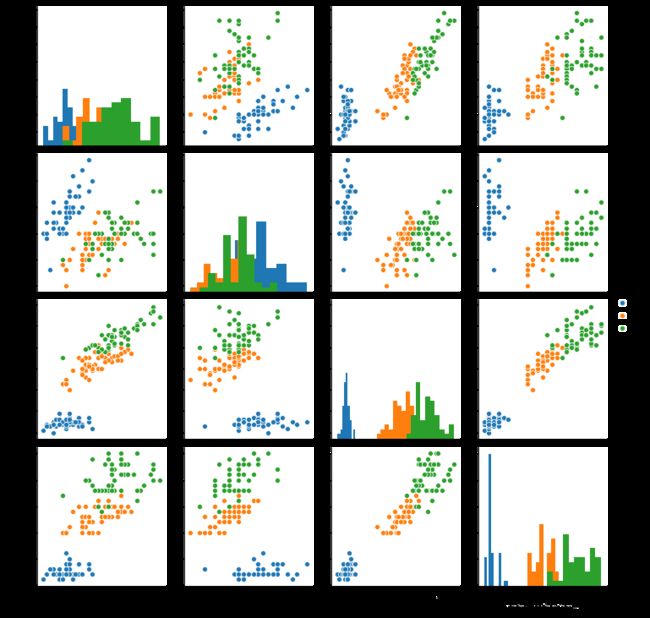
Seaborn是基于matplotlib的Python数据可视化库。它提供了用于绘制引人入胜且内容丰富的统计图形的高级界面。
4.1 seaborn.pairplot:在数据集中绘制成对关系。默认情况下,此函数将创建一个轴网格,以便每个数值变量将在单行的y轴和单列的x轴之间共享。这个seaborn下对pairplot的解释现在还看不懂,但没关系,先从代码入手。
http://seaborn.pydata.org/generated/seaborn.pairplot.html?highlight=pairplot#seaborn.pairplot
相关代码:sns.pairplot(data=iris_all, diag_kind='hist', hue='target')
方法:seaborn.pairplot(data, *, hue=None, hue_order=None, palette=None, vars=None, x_vars=None, y_vars=None, kind='scatter', diag_kind='auto', markers=None, height=2.5, aspect=1, corner=False, dropna=False, plot_kws=None, diag_kws=None, grid_kws=None, size=None)
data:pandas.DataFrame格式。
diag_kind:描绘对角子图的图样,可选{'auto','hist','kde',无}。
hue:data中的可变变量名,这里根据可变变量target的值控制数据点映射到不同的颜色,所以有3种颜色。
看完代码,发现只是明白了不同颜色代表不同标签类别,以及4个特征变量两两组合搭成了一个轴网络,还是看不懂图形的意义,y轴的数值表示什么?柱状图表示什么意义?特征变量两两组合代表着什么?这些散点的分布又是什么意义?这些无法从代码中看懂,于是去搜索了pairplot,看了一些资料,比如:https://zhuanlan.zhihu.com/p/98729226,下面解释下此图:
pairplot图对角线上是各个属性的直方图(分布图),而非对角线上是两个不同属性之间的相关图。
直方图的意义以左上角那张图为例来解释,x轴的取值是5、6、7、8,那是因为iris_all数据里的sepal length属性值普遍分布在4.3cm(min)到7.9cm(max)之间,这个信息是通过上面的iris_features.describe()函数知道的;y轴的取值分布原因与x轴是一样的。知道了两个轴的意义,那此直方图的意义就是表明了所有训练样本在(花萼长度)变化上的分布,从图中可以分析出,sepal length属性值越大,我们的训练样本的标签值就越趋向于2,也就是说花萼长度越长,这个鸢尾花是维吉尼亚鸢尾(标签值为2)的概率越大。
相关图的意义是可以看到两个不同的属性之间的相关关系,有的关系不甚明显,有的关系显而易见,比如petal width(花瓣宽)与petal length(花瓣长)两个属性之间有明显的相关关系,点的分布呈现正相关状。
总之,从上面的pairplot图可以看出,在2D情况下不同的特征组合对于不同类别的花的散点分布情况,以及大概的区分能力。
## 绘制箱型图
for col in iris_features.columns:
sns.boxplot(x='target', y=col, saturation=0.5, palette='pastel', data=iris_all)
plt.title(col)
plt.show()运行结果:
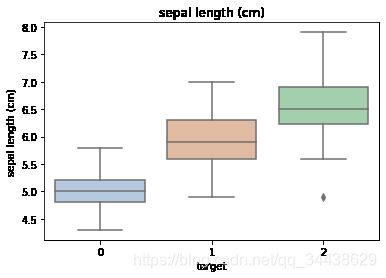

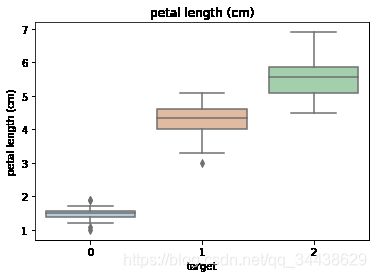
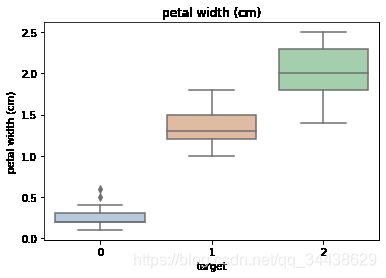
4.2 sns.boxplot:绘制箱形图以显示类别的分布。箱形图以有助于比较变量之间或分类变量各个级别之间比较的方式显示定量数据的分布。该框显示数据集的四分位数,而晶须延伸以显示其余分布。这些话是seaborn.boxplot的注解,目前看不懂,没关系,先继续往下看,从代码入手。
http://seaborn.pydata.org/generated/seaborn.boxplot.html?highlight=boxplot#seaborn.boxplot
相关代码:sns.boxplot(x='target', y=col, saturation=0.5, palette='pastel', data=iris_all)
方法:seaborn.boxplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, ax=None, **kwargs)
x,y两个分类变量,用于提供数据的输入,变量名分别作为箱型图的x轴名和y轴名。格式可以是data中的可变变量名,也可以是变量名。
x:这里输入了target,只有3个不同的取值,所以x轴有3类0、1、2。
y:这里输入了col,col取于iris_features.columns,也就是col为数据的4个特征变量名之一,每个特征作一张图,y轴名就是col值。
Q:我们知道了根据数据的列数作出4个箱型图,知道了x轴、y轴的名字,知道x轴表示标签的类别,那这里的y轴依据什么划分的呢?那些数字代表着什么意思?
A:这个问题,肯定是要从箱型图的概念里找了,所以我们应该搞懂什么是箱型图,它是什么样式的?
A:百度百科对箱型图的定义如下:https://baike.baidu.com/item/%E7%AE%B1%E5%BD%A2%E5%9B%BE/10671164?fr=aladdin,箱型图的图片:

可以看到,箱型图里涉及到一组数据的上边缘、下边缘、中位数和两个四分位数等术语,这应该是属于统计学中的概念,我们或许不懂,但上面iris_features的描述函数有给出上四分位数25%、中位数50%、下四分位数75%的相应数值,我们很容易想到,y轴就是根据这些来定值的。知道了这个概念,再去看上面seaborn.boxplot的注解,就很清晰了。至于这些提到的统计概念,可以后续去学习,这里先放过。
saturation:饱和的意思,float型数据,用于设置颜色的饱和度比例,饱和度比例是基于输入颜色来说的,想要绘图颜色与输入颜色规格完全匹配则设为1,大型色块通常看起来略带不饱和的颜色会更好看,所以这里设置成0.5,这里的输入颜色指的是palette值。
palette:调色板的意思,用于设置hue变量不同级别的颜色,格式可以是把hue的不同级别映射到matplotlib颜色的字典,如本代码中的设置的'pastel'就是matplotlib颜色字典。
data:DataFrame数据
hue:这里的hue值没有给,默认是none,根据上面链接里的参考示例,我猜测hue是在已有x,y两个分类变量的基础上再分类,形成一个嵌套分组。当不设置hue时,每一类只有一个箱型图,且palette值就根据x和y两个分类变量来控制数据点映射到不同的颜色。(这里是一个猜测,待验证)
总之,我们只需要知道我们绘制的箱型图是为了得到不同类别(标签为0、1、2)在不同特征上(4个特征)的分布差异情况就可以了。
#########未完待续##########
5 利用逻辑回归模型在二分类上进行训练和预测
6 利用逻辑回归模型在三分类(多分类)上进行训练和预测
三、学习问题和解决方法记录
四、学习总结