大数据 | 实验一:大数据系统基本实验 | MapReduce 初级编程
文章目录
- 实验目的
- 实验平台
- 实验内容
-
- 编程实现文件的合并和去重
- 编程实现对输入文件的排序
- 对指定的表格进行信息挖掘
实验目的
1)通过实验掌握基本的 MapReduce 编程方法。
2)掌握用 MapReduce 解决一些常见的数据处理问题,包括数据去重、数据排序和数据挖掘等。
实验平台
1)操作系统:Linux;
2)Hadoop 版本:3.2.2;
实验内容
编程实现文件的合并和去重


package hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Merge
{
//这段代码输出的结果是原始输入数据的全部内容作为key,value为空的键值对。
public static class Map extends Mapper<Object, Text, Text, Text>
{
//在Map类中定义了一个静态变量text,并将其类型设置为Text。
private static Text text = new Text();
//map方法中的参数分别表示输入数据的键、值和上下文对象
//上下文对象可以用于向输出写入数据。
public void map(Object key, Text value, Context context) throws IOException,InterruptedException
{
//将输入的value数据赋值给text变量
text = value;
//text作为key,一个空的Text对象作为value输出。
context.write(text, new Text(""));
}
}
//简单地将Mapper输出的所有键值对的key提取出来作为Reducer的输出。
public static class Reduce extends Reducer<Text, Text, Text, Text>
{
// reduce方法中的参数分别表示输入数据的键、值集合和上下文对象
//上下文对象可以用于向输出写入数据。
public void reduce(Text key, Iterable<Text> values, Context context ) throws IOException,InterruptedException
{
//将输入的key作为key,一个空的Text对象作为value输出
context.write(key, new Text(""));
//因为这里没有对values集合进行处理
//所以values中的数据会被忽略掉,只有输入的key被输出。
}
}
public static void main(String[] args) throws Exception
{
//首先创建一个Configuration对象,用于存储Hadoop集群中的一些配置信息。
Configuration conf = new Configuration();
//设置Hadoop集群的默认文件系统为hdfs://localhost:9000。
conf.set("fs.default.name","hdfs://localhost:9000");
//接着检查输入参数是否正确
//需要传入两个参数,第一个是输入数据路径,第二个是输出结果路径。
String[] otherArgs = new String[]{"input","output"};
if (otherArgs.length != 2)
{ //如果参数不满足要求,则输出错误提示并退出程序。
System.err.println("Usage: wordcount " 编程实现对输入文件的排序
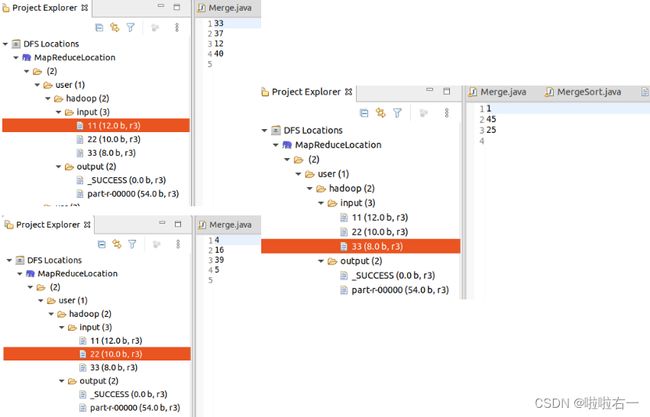

package hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MergeSort
{
//这段代码将输入的文本数据中的每一个整数作为键,对应的出现次数设置为1作为值
public static class Map extends Mapper<Object, Text, IntWritable, IntWritable>
{
private static IntWritable data = new IntWritable();
public void map(Object key, Text value, Context context) throws
IOException,InterruptedException
{
//输入的key是偏移量,value是那个数值
//首先将输入数据从Text类型转换为String类型,并赋值给text变量。
String text = value.toString();
//然后将text转换为Int类型,并将其封装到IntWritable对象中,赋值给data变量。
data.set(Integer.parseInt(text));
//将data作为输出key,new IntWritable(1)作为输出值value写入上下文中
context.write(data, new IntWritable(1));
}
}
//在进入reduce之前会有一个partition的过程,但因为我们现在电脑配置的datenode只有一个,所以最后其实都会就进入那一个dateNode。
public static class Partition extends Partitioner<IntWritable, IntWritable>
{
public int getPartition(IntWritable key, IntWritable value, int num_Partition)
{
//getPartition方法的三个参数分别表示输入键、输入值和分区数。
int Maxnumber = 65223;
//首先定义了一个最大数字Maxnumber,并根据分区数计算出每个分区的边界bound
//即将Maxnumber均匀地分为num_Partition个部分
int bound = Maxnumber/num_Partition+1;
//接着获取当前输入键的整数值keynumber
int keynumber = key.get();
for (int i = 0; i<num_Partition; i++)
{
//然后遍历所有分区,通过比较keynumber与边界值的大小关系,找到它应该属于的分区。
if(keynumber<bound * (i+1) && keynumber>=bound * i)
{
//如果找到了对应的分区,则返回该分区的编号i;
//否则,如果在所有分区中都没有找到对应的分区,则返回-1,表示出错。
return i;
}
}
return -1;
}
}
//对Map类输出的中间结果按键值排序,为每个键值对添加一个唯一的序号,并将排序后的结果作为最终输出结果。
//在本例中,输出结果是一个序号与整数对应的列表。
public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>
{
//Reduce的泛型参数分别表示输入键、输入值、输出键和输出值的类型。
private static IntWritable line_num = new IntWritable(1);
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException
{
//遍历Iterable类型的values参数,将其按照key值排序后输出。
for(IntWritable val : values)
{
//这里的排序是自动排序
//使用context.write方法将line_num作为输出键,key作为输出值写入上下文中。
context.write(line_num, key);
//每输出一个键值对,line_num的值就加1,以保证输出的键值对具有唯一的序号。
line_num = new IntWritable(line_num.get() + 1);
}
//这里for循环的意义就是避免去重,让key相同的都能遍历输出。
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String[] otherArgs = new String[]{"input","output"};
if (otherArgs.length != 2)
{
System.err.println("Usage: wordcount " 对指定的表格进行信息挖掘

package hdfs;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class map
{
//用于输出标题
public static int time = 0;
//“child_name”、“parent_name”和“relation_type”作为键值对输出到Context对象中。
public static class Map extends Mapper<Object, Text, Text, Text>
{
public void map(Object key, Text value, Context context)
throws IOException,InterruptedException
{
String child_name = new String();
String parent_name = new String();
String relation_type = new String();
String line = value.toString();
int i = 0;
while(line.charAt(i) != ' ')
{//将输入的每一行文本数据以空格为分隔符
i++;
}
//将第一个部分作为子节点名称,第二个部分作为父节点名称,以及一个关系类型组成的字符串
String[] values = {line.substring(0,i),line.substring(i+1)};
if(values[0].compareTo("child") != 0)
{
//如果“child_name”不等于“child”(就不是标题)
//key是父亲,1
child_name = values[0];
parent_name = values[1];
relation_type = "1";
context.write(new Text(values[1]),
new Text(relation_type+"+"+child_name+"+"+parent_name));
//key是孩子,2
relation_type = "2";
context.write(new Text(values[0]),
new Text(relation_type+"+"+child_name+"+"+parent_name));
}
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text>
{
public void reduce(Text key, Iterable<Text> values,Context context)
throws IOException,InterruptedException
{
if(time == 0)
{
//用于标题
context.write(new Text("grand_child"), new Text("grand_parent"));
time++;
}
int grand_child_num = 0; //用于在数组里插入
String grand_child[] = new String[10];//孙辈的数组
int grand_parent_num = 0; //用于在数组里插入
String grand_parent[]= new String[10];//祖辈的数组
Iterator ite = values.iterator();
while(ite.hasNext())
{
String record = ite.next().toString();
int len = record.length();
int i = 2; //i=0是relation_type,i=1是“+”
if(len == 0) continue;
char relation_type = record.charAt(0);
String child_name = new String();
String parent_name = new String();
while(record.charAt(i) != '+')
{ //child,从2开始
child_name = child_name + record.charAt(i);
i++;
}
i=i+1; //一个加号
while(i<len)
{ //"childname+"后面的内容
parent_name = parent_name+record.charAt(i);
i++;
}
if(relation_type == '1')
{ //父亲,就取孩子的名字,就是孙辈的名字
grand_child[grand_child_num] = child_name;
grand_child_num++;
}
else
{//孩子,就取父亲的名字,就是祖辈的名字
grand_parent[grand_parent_num] = parent_name;
grand_parent_num++;
}
}
if(grand_parent_num != 0 && grand_child_num != 0 )//全排列
{
for(int m = 0;m<grand_child_num;m++)
{
for(int n=0;n<grand_parent_num;n++)
{
context.write(new Text(grand_child[m]), new Text(grand_parent[n]));
//对每一行进行reduce
}
}
}
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.default.name","hdfs://localhost:9000");
String[] otherArgs = new String[]{"input","output"};
if (otherArgs.length != 2)
{
System.err.println("Usage: wordcount " 补充学习博客:MapReduce编程规范及示例编写