浏览器的事件循环机制
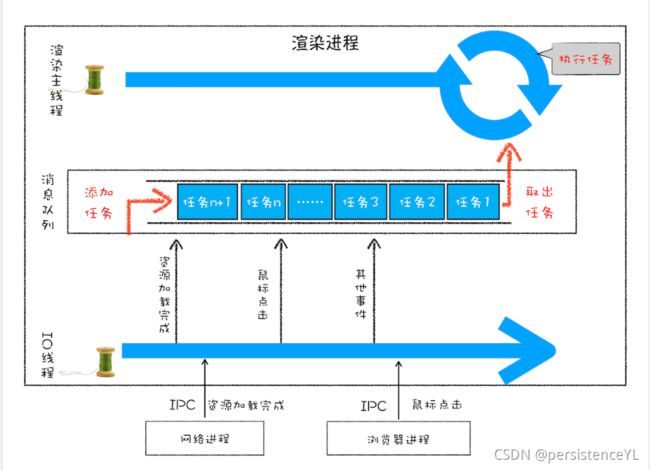
每个渲染进程都有一个主线程,并且主线程非常繁忙,既要处理 DOM,又要计算样式,还要处理布局,同时还需要处理 JavaScript 任务以及各种输入事件。要让这么多不同类型的任务在主线程中有条不紊地执行,这就需要一个系统来统筹调度这些任务,这个统筹调度系统就是我们今天要讲的消息队列和事件循环系统。
一、事件循环
所谓的事件循环机制其实可以这么理解,当 JS 引擎去执行 JS 代码的时候会从上至下按顺序执行,当遇到异步任务的,就会交由浏览器的其他线程去执行,如果是setTimeout/setInterval 定时异步任务,浏览器的渲染进程就会开一个定时器触发线程去执行,当定时时间一到,就会通知事件触发线程将定时器的回调方法推送至事件任务队列的一个宏任务队列的列尾,等待 JS 引擎执行完同步任务后,再从事件任务队列中从头取出要执行的回调方法。其他异步任务也是这么一个流程。这就是所谓的 事件循环。
要想在线程运行过程中,能接收并执行新的任务,就需要采用事件循环机制,如果需要接收其他进程发送来的任务需要引入消息队列
渲染进程的主线程和子线程之间是子线程将任务添加到消息队列。
其他进程发送来的任务是渲染进程的I/O线程接收其他进程的消息,然后添加到消息队列,由主线程的事件循环系统执行。
消息队列机制并不是太灵活,为了适应效率和实时性,引入了微任务。
消息队列的内容为宏任务,每一个宏任务都会有一个自己的微任务队列,执行完一个宏任务之后不会马上去执行下一个宏任务,而且是查看微任务队列中是否有要执行的微任务,执行完微任务再去执行下一个宏任务。
二、执行顺序(原链接)
event loop它的执行顺序:
一开始整个脚本作为一个宏任务执行
执行过程中同步代码直接执行,宏任务进入宏任务队列,微任务进入微任务队列
当前宏任务执行完出队,检查微任务列表,有则依次执行,直到全部执行完
执行浏览器UI线程的渲染工作
检查是否有Web Worker任务,有则执行
执行完本轮的宏任务,回到2,依此循环,直到宏任务和微任务队列都为空
微任务包括:MutationObserver、Promise.then()或catch()、Promise为基础开发的其它技术,比如fetch API、V8的垃圾回收过程、Node独有的process.nextTick。
宏任务包括:script 、setTimeout、setInterval 、setImmediate 、I/O 、UI rendering。
注意⚠️:在所有任务开始的时候,由于宏任务中包括了script,所以浏览器会先执行一个宏任务,在这个过程中你看到的延迟任务(例如setTimeout)将被放到下一轮宏任务中来执行。
三、事件循环的例子(原链接)
如果我们在浏览器控制台中运行’foo’函数,是否会导致堆栈溢出错误?
function foo() {
setTimeout(foo, 0); // 是否存在堆栈溢出错误?
};
答案是不会溢出,原因与浏览器的事件循环机制有关
当我们说“浏览器是 JS 的家”时我真正的意思是浏览器提供运行时环境来执行我们的JS代码。
浏览器的主要组件包括调用堆栈,事件循环**,任务队列和Web API**。 像setTimeout,setInterval和Promise这样的全局函数不是JavaScript的一部分,而是 Web API 的一部分。 JavaScript 环境的可视化形式如下所示:

事件循环(Event loop)不断地监视任务队列(Task Queue),并按它们排队的顺序一次处理一个回调。每当调用堆栈(call stack)为空时,Event loop获取回调并将其放入堆栈(stack )(箭头3)中进行处理。请记住,如果调用堆栈不是空的,则事件循环不会将任何回调推入堆栈。
所以这个就是为什么加了setTimeout之后不会出现栈溢出的情况。
另外还有个问题
就是如何解决下面这个代码栈溢出的情况
function runStack (n) {
if (n === 0) return 100;
return runStack( n- 2);
}
runStack(50000)
除了使用setTimeout外,在一个大佬那看到可以使用一个蹦床函数来解决
function runStack (n) {
if (n === 0) return 100;
return runStack.bind(null, n- 2); // 返回自身的一个版本
}
// 蹦床函数,避免递归
function trampoline(f) {
while (f && f instanceof Function) {
f = f();
}
return f;
}
trampoline(runStack(1000000))
这个代码就类似于调用一个函数,先把trampoline函数压入到方法调用栈中,然后执行trampoline函数中代码的时候需要调用runStack函数,然后又把runStack压入到函数调用栈中,runStack执行完之后又马上将其弹出栈,因此不会出现栈内有很多函数的情况,所以不会出现栈溢出。