Flink1.14学习测试:将数据写入到Hive&Hdfs(二)
Flink1.14学习测试:将数据写入到Hive&Hdfs(二)
参考
- Kafka SQL 连接器 : https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/table/kafka/
- 标量函数(udf) : https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/functions/udfs/#%E6%A0%87%E9%87%8F%E5%87%BD%E6%95%B0
- Formats : https://nightlies.apache.org/flink/flink-docs-master/zh/docs/connectors/table/formats/overview/
接收Kafka数据并写入到Hive (实现思路一)
说明
消息结构(JSON格式)
{"name":"Fznjui","age":16,"gender":"女"}
Kafka表定义
Kafka Table配置jsonformat。Schema结构保持与消息内容结构一致,当消息接收到时即可直接转换。
自定义UDF函数
此处是因为中文分区目录HIve不识别,所以做个转换函数。
测试完整代码
import cn.hutool.core.io.resource.ResourceUtil
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.Expressions.{$, currentTimestamp, dateFormat}
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.api.{ApiExpression, DataTypes, FieldExpression, Schema, SqlDialect, TableDescriptor, call}
import org.apache.flink.table.catalog.hive.HiveCatalog
import org.apache.flink.table.functions.ScalarFunction
import java.util.concurrent.TimeUnit
object KafkaToHiveTest1 {
private val sourceTopic = "ly_test"
private val kafkaServers = "192.168.11.160:9092,192.168.11.161:9092,192.168.11.162:9092"
def main(args: Array[String]): Unit = {
//参数配置(flink参数获取工具类)
val parameterTool = ParameterTool.fromArgs(args)
//hive-site.xml 配置文件所在的目录 --hiveCfg xxx(目录全路径)
val hiveConfigDir = parameterTool.get("hiveCfgDir", ResourceUtil.getResource("hive/conf").getPath)
//环境配置
val env = StreamExecutionEnvironment.getExecutionEnvironment
//每个1s检查一次,精确一次
env.enableCheckpointing(TimeUnit.SECONDS.toMillis(1), CheckpointingMode.EXACTLY_ONCE)
//table api
val tableEnv = StreamTableEnvironment.create(env)
//配置hive元数据
val catalogName = "lyTest"
val hiveCatalog = new HiveCatalog(catalogName, "ly_test", hiveConfigDir)
tableEnv.registerCatalog(catalogName, hiveCatalog)
// 使用注册的 hive catalog
tableEnv.useCatalog(catalogName)
//kafka source
val sourceTable = "kafkaTable"
tableEnv.createTemporaryTable(sourceTable, TableDescriptor
.forConnector("kafka")
// 列与json结构对应
.schema(Schema.newBuilder()
.column("name", DataTypes.STRING())
.column("age", DataTypes.INT())
.column("gender", DataTypes.STRING())
.build())
.option("topic", sourceTopic)
.option("properties.bootstrap.servers", kafkaServers)
.option("properties.group.id", "KafkaToHiveTest1")
.option("scan.startup.mode", "latest-offset")
//json 内容 例: {"name":"Fznjui","age":16,"gender":"女"}
.option("format", "json")
.build())
//切换方言
tableEnv.getConfig.setSqlDialect(SqlDialect.HIVE)
//创建Hive分区表 (\u0024 = $ 为字符串模板 中的占位符)
val kafka_sink_hive = "kafka_sink_hive"
//noinspection SpellCheckingInspection
tableEnv.executeSql(
s"""
|create table if not exists $kafka_sink_hive (
| name string,
| age int,
| gender string,
| sink_date_time timestamp(9)
|) partitioned by (ymd string,sex string)
| stored as parquet
| tblproperties(
| 'partition.time-extractor.timestamp-pattern' = '\\u0024ymd 00:00:00',
| 'sink.partition-commit.policy.kind' = 'metastore'
| )
|""".stripMargin)
//切换方言
tableEnv.getConfig.setSqlDialect(SqlDialect.DEFAULT)
//将数据插入到 hive的测试表中
tableEnv.from(sourceTable)
.addColumns(currentTimestamp() as "now")
.select($"name", $"age", $"gender", $"now",
dateFormat($("now"), "yyyy-MM-dd") as "ymd",
//call 类型是 Expression 本身没有 as 设置别名的方式 此处 通过 强转 成 ApiExpression 后在设置别名
call(classOf[GenderConvert], $("gender")).asInstanceOf[ApiExpression] as "sex")
.executeInsert(kafka_sink_hive)
}
/**
* 将性别从中文转成英文
* udf (标量函数)
*/
class GenderConvert extends ScalarFunction {
def eval(gender: String): String = {
gender match {
case "男" => "boy"
case "女" => "girl"
case _ => "other"
}
}
}
}
运行结果

查看分区
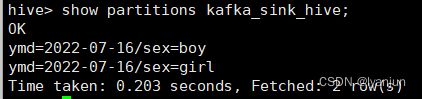
查看HDFS对应的目录

接收Kafka数据并写入到Hive (实现思路二)
本质上练习在上一步已经结束了,此处主要还是为了测试自定义udtf(表值函数)函数。目的:使用自定义udtf函数解析数据随后入库。(茴字到底有几种写法?)
测试完整代码
import cn.hutool.core.date.DateUtil
import cn.hutool.core.io.resource.ResourceUtil
import cn.hutool.json.JSONUtil
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.annotation.DataTypeHint
import org.apache.flink.table.api.Expressions.{$, dateFormat}
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.api.{DataTypes, FieldExpression, Schema, SqlDialect, TableDescriptor, call}
import org.apache.flink.table.catalog.hive.HiveCatalog
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Row
import java.util.Date
import java.util.concurrent.TimeUnit
object KafkaToHiveTest2 {
private val sourceTopic = "ly_test"
private val kafkaServers = "192.168.11.160:9092,192.168.11.161:9092,192.168.11.162:9092"
def main(args: Array[String]): Unit = {
//参数配置(flink参数获取工具类)
val parameterTool = ParameterTool.fromArgs(args)
//hive-site.xml 配置文件所在的目录 --hiveCfg xxx(目录全路径)
val hiveConfigDir = parameterTool.get("hiveCfgDir", ResourceUtil.getResource("hive/conf").getPath)
//环境配置
val env = StreamExecutionEnvironment.getExecutionEnvironment
//每个1s检查一次,精确一次
env.enableCheckpointing(TimeUnit.SECONDS.toMillis(1), CheckpointingMode.EXACTLY_ONCE)
//table api
val tableEnv = StreamTableEnvironment.create(env)
//配置hive元数据
val catalogName = "lyTest"
val hiveCatalog = new HiveCatalog(catalogName, "ly_test", hiveConfigDir)
tableEnv.registerCatalog(catalogName, hiveCatalog)
// 使用注册的 hive catalog
tableEnv.useCatalog(catalogName)
//kafka source
val sourceTable = "kafkaTable"
tableEnv.createTemporaryTable(sourceTable, TableDescriptor
.forConnector("kafka")
// 列与json结构对应
.schema(Schema.newBuilder()
.column("message", DataTypes.STRING())
.build())
.option("topic", sourceTopic)
.option("properties.bootstrap.servers", kafkaServers)
.option("properties.group.id", "KafkaToHiveTest2")
.option("scan.startup.mode", "latest-offset")
//json 内容 例: {"name":"Fznjui","age":16,"gender":"女"}
.option("format", "raw")
.build())
//切换方言
tableEnv.getConfig.setSqlDialect(SqlDialect.HIVE)
//创建Hive分区表 (\u0024 = $ 为字符串模板 中的占位符)
val kafka_sink_hive = "kafka_sink_hive"
//noinspection SpellCheckingInspection
tableEnv.executeSql(
s"""
|create table if not exists $kafka_sink_hive (
| name string,
| age int,
| gender string,
| sink_date_time timestamp(9)
|) partitioned by (ymd string,sex string)
| stored as parquet
| tblproperties(
| 'partition.time-extractor.timestamp-pattern' = '\\u0024ymd 00:00:00',
| 'sink.partition-commit.policy.kind' = 'metastore'
| )
|""".stripMargin)
//切换方言
tableEnv.getConfig.setSqlDialect(SqlDialect.DEFAULT)
//将数据插入到 hive的测试表中
tableEnv.from(sourceTable)
.joinLateral(call(classOf[ParseJsonConvert], $("message")))
.select($"name", $"age", $"gender", $"now",
//分区字段
dateFormat($("now"), "yyyy-MM-dd") as "ymd", $"sex")
.executeInsert(kafka_sink_hive)
}
/**
* 将性别从中文转成英文
* udtf (表值函数)
*/
class ParseJsonConvert extends TableFunction[Row] {
//在此处直接解析转换
@DataTypeHint(value = "Row" )
def eval(message: String): Unit = {
val json = JSONUtil.parse(message)
val name = json.getByPath("name", classOf[String])
val age = json.getByPath("age", classOf[java.lang.Integer])
val gender = json.getByPath("gender", classOf[String])
val sex = gender match {
case "男" => "boy"
case "女" => "girl"
case _ => "other"
}
//当前日期 + 一天 (此处为了和之前数据错开 好看到测试结果 无实际意义)
val localDateTime = DateUtil.offsetDay(new Date(), 1).toLocalDateTime
collect(Row.of(name, age, gender, localDateTime, sex))
}
}
}
运行结果

查看分区
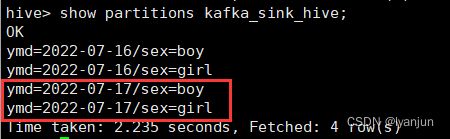
查看HDFS对应的目录

