Write-Ahead Log(PostgreSQL 14 Internals翻译版)
日志
如果发生停电、操作系统错误或数据库服务器崩溃等故障,RAM中的所有内容都将丢失;只有写入磁盘的数据才会被保留。要在故障后启动服务器,必须恢复数据一致性。如果磁盘本身已损坏,则必须通过备份恢复来解决相同的问题。
理论上,您可以始终保持磁盘上的数据一致性。但在实践中,这意味着服务器必须不断地将随机页面写入磁盘(尽管顺序写入更便宜),而且这种写入的顺序必须保证在任何特定时刻都不会损害一致性(这很难实现,特别是在处理复杂的索引结构时)。
就像大多数数据库系统一样,PostgreSQL使用了不同的方法。
当服务器运行时,一些当前数据仅在RAM中可用,将其写入永久存储器被推迟。因此,在服务器操作期间,存储在磁盘上的数据总是不一致的,因为页面永远不会一次刷新。但是在RAM中发生的每个更改(例如在缓冲区缓存中执行的页面更新)都被记录下来:PostgreSQL创建一个日志条目,其中包含在需要时重复此操作所需的所有基本信息。
与页面修改相关的日志条目必须在被修改的页面本身之前写入磁盘。因此,该日志的名称为:预写日志(write-ahead log)或WAL。这个要求保证了在发生故障的情况下,PostgreSQL可以从磁盘读取WAL条目并重放它们以重复已经完成的操作,这些操作的结果仍然在RAM中,并且在崩溃之前没有将其保存到磁盘中。
保持预写日志通常比将随机页面写入磁盘更有效。WAL条目构成连续的数据流,甚至可以由HDD处理。此外,WAL条目通常小于页面大小。
在发生故障时,需要记录所有可能破坏数据一致性的操作。具体来说,在WAL中记录了以下动作:
- 在缓冲缓存中执行的页面修改——因为写操作被延迟
- 事务提交和回滚—因为状态更改发生在CLOG缓冲区中,而不会立即将其转移到磁盘
- 文件操作(比如在添加或删除表时创建和删除文件和目录)——因为这些操作必须与数据更改同步
以下操作不被记录:
- UNLOGGED表的操作
- 对临时表的操作——因为它们的生命周期受到生成它们的会话的限制
在PostgreSQL 10之前,哈希索引也不被记录。它们的唯一目的是将哈希函数与不同的数据类型相匹配。
除了崩溃恢复之外,WAL还可以用于从备份和复制中进行时间点恢复。
WAL结构
逻辑结构
谈到它的逻辑结构,我们可以将WAL描述为可变长度的日志条目流。每个条目包含一些关于特定操作的数据,前面有一个标准头。除其他事项外,头文件提供以下信息:
- 和条目有关于的事务ID
- 解释条目的资源管理器
- 检测数据损坏的校验和
- 条目长度
- 对前一个WAL条目的引用
WAL通常是向前读取的,但是一些实用程序(如pg_rewind)可能会向后扫描它。
WAL数据本身可以具有不同的格式和含义。例如,它可以是一个页片段,它必须在指定的偏移量处替换页的某些部分。相应的资源管理器必须知道如何解释和重放特定的条目。表、各种索引类型、事务状态和其他实体都有单独的管理器。
WAL文件占用服务器共享内存中的特殊缓冲区。WAL使用的缓存大小由wal_buffers参数定义。默认情况下,自动选择该大小为总缓冲区缓存大小的1/32。
WAL缓存与缓冲区缓存非常相似,但它通常以环形缓冲区模式运行:新条目添加到其头部,而旧条目从尾部开始保存到磁盘。 如果WAL缓存太小,则执行磁盘同步的频率将超出必要的范围。
在低负载情况下,插入位置(缓冲区的头部)几乎总是与已经保存到磁盘的条目的位置(缓冲区的尾部)相同:

在PostgreSQL之前,所有函数名都包含XLOG缩写而不是WAL。
为了引用一个特定的条目,PostgreSQL使用一个特殊的数据类型:pg_lsn(日志序列号,LSN)。它表示从WAL开始到条目的64位字节偏移量。LSN表示为两个32位的十六进制数,中间用斜杠分隔。
创建一个表:

启动一个事务并记录WAL插入位置的LSN:

现在运行一些任意命令,例如,更新一行:
![]()
页面修改在RAM中的缓冲缓存中执行。此更改记录在WAL页面中,也记录在RAM中。因此,插入LSN被提前:

为了确保修改后的数据页严格在相应的WAL条目之后被刷新到磁盘,页头存储了与该页相关的最新WAL条目的LSN。你可以使用pageinspect查看LSN:

整个数据库集群只有一个WAL,并且不断向其添加新条目。由于这个原因,存储在页面中的LSN可能比前一段时间pg_current_wal_insert_lsn函数返回的LSN要小。但是如果系统中什么都没有发生,这些数字将是相同的。
现在提交事务:
![]()
提交操作也被记录,插入LSN再次更改:

提交更新CLOG页面中的事务状态,这些页面保存在它们自己的缓存中。CLOG缓存通常在共享内存中占用128页。为了确保在相应的WAL条目之前不会将CLOG页面刷新到磁盘,还必须跟踪CLOG页面的最新WAL条目的LSN。但是这些信息存储在RAM中,而不是页面本身。
在某个时刻,WAL条目将被写入磁盘;然后就可以从缓存中驱逐CLOG和数据页。如果必须更早地驱逐它们,则会发现它,并且会先将WAL条目强制写入磁盘。
如果您知道两个LSN位置,则可以通过简单地从一个位置减去另一个位置来计算它们之间的WAL条目的大小(以字节为单位)。你只需要将它们强制转换为pg_lsn类型:

在本例中,与UPDATE和COMMIT操作相关的WAL条目占用了大约100个字节。
您可以使用相同的方法来估计特定工作负载在单位时间内生成的WAL条目的数量。检查点设置将需要这些信息。
物理结构
在磁盘上,WAL作为单独的文件或段存储在PGDATA/pg_wal目录中。它们的大小由只读的wal_segment_size参数显示。
对于高负载系统,增加段大小是有意义的,因为它可以减少开销,但是这个设置只能在集群初始化期间修改(initdb --wal-segsize)。
WAL条目进入当前文件,直到空间用完;然后,PostgreSQL启动一个新文件。
我们可以知道一个特定的条目位于哪个文件中,以及从文件开始的偏移量:
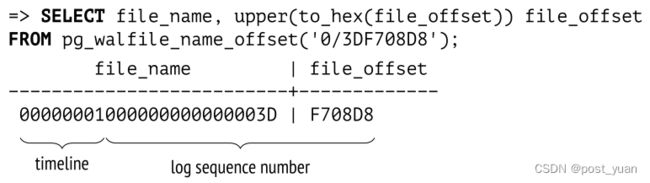
文件名由两部分组成。最高的8个十六进制数字定义了用于从备份中恢复的时间线,而其余的数字表示最高的LSN位(最低的LSN位显示在file_offset字段中)。
要查看当前的WAL文件,可以调用以下函数:


现在,让我们使用pg_waldump实用程序查看新创建的WAL条目的头,该实用程序可以根据LSN范围(如本例中所示)和特定事务ID过滤WAL条目。
应该使用postgres操作系统用户启动pg_waldump实用程序,因为它需要访问磁盘上的WAL文件。

这里我们可以看到两个条目的标题。
第一个是由Heap资源管理器处理的HOT_UPDATE操作。blkref字段显示了更新后的堆页的文件名和页ID:

第二个条目是由事务资源管理器监督的COMMIT操作。
检查点
在失败后恢复数据一致性(即执行恢复),PostgreSQL必须往前重放WAL,并将代表丢失的更改的条目应用到相应的页面。为了找出丢失的内容,将存储在磁盘上的页面的LSN与WAL条目的LSN进行比较。但我们应该从什么时候开始复苏呢?如果我们开始得太晚,在此之前写入磁盘的页面将无法接收到所有更改,这将导致不可逆转的数据损坏。从头开始是不现实的:不可能存储如此庞大的潜在数据量,也不可能接受如此长的恢复时间。我们需要一个逐渐向前移动的检查点,这样可以安全地从该点开始恢复并删除所有以前的WAL条目。
创建检查点最直接的方法是定期挂起所有系统操作,并将所有脏页强制放到磁盘上。这种方法当然是不可接受的,因为系统将挂起一段不确定但相当重要的时间。
由于这个原因,检查点随着时间的推移而分散,实际上构成了一个间隔。检查点的执行是由一个叫做checkpointer的特殊后台进程执行的。
-
检查点开始。 checkpointer进程将可以立即写入的所有内容刷新到磁盘:CLOG事务状态、子事务的元数据和一些其他结构。
-
检查点执行。 检查点执行的大部分时间都花在将脏页刷新到磁盘上。首先,在检查点开始时已脏的所有缓冲区的标头中设置一个特殊标记。由于不涉及I/O操作,因此它发生得非常快。然后checkpointer进程遍历所有缓冲区并将标记的缓冲区写入磁盘。它们的页面不会从缓存中被驱逐:它们只是被写下来,因此使用量和pin计数可以忽略。页面按照其ID的顺序进行处理,以尽可能避免随机写入。为了更好地实现负载平衡,PostgreSQL 在不同的表空间之间进行切换 (因为它们可能位于不同的物理设备上)。后端也可以将带标签的缓冲区写入磁盘——如果它们先到达的话。在任何情况下,缓冲区标记都在此阶段被删除,因此出于检查点的目的,每个缓冲区将只被写入一次。当然,当检查点正在进行时,仍然可以在缓冲缓存中修改页面。但是由于新的脏缓冲区没有标记,checkpointer将忽略它们。
-
检查点完成。 当检查点开始时所有脏的缓冲区都被写入磁盘时,就认为检查点完成了。从现在开始(但不是更早!),检查点的起点将被用作恢复的新起点。不再需要在此之前编写的所有WAL条目。

最后,checkpointer创建一个与检查点完成相对应的WAL条目,指定检查点的起始LSN。 由于检查点在启动时不记录任何日志,因此该LSN可以属于任何类型的WAL条目。
PGDATA/global/pg_control文件也得到更新,以引用最新完成的检查点。 (在此过程结束之前,pg_control将保留前一个检查点。)

为了一劳永逸地弄清楚哪些点在哪里,让我们看一个简单的例子。我们将使几个缓存页面变脏:

现在让我们手动完成检查点。所有脏页都将刷新到磁盘;由于系统中没有发生任何事情,因此不会出现新的脏页:

让我们看看检查点是如何反映在WAL中的:
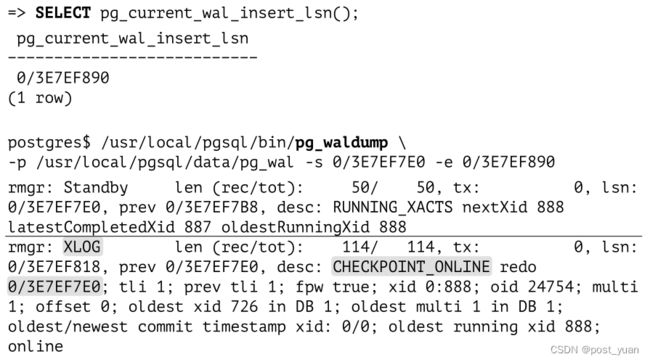
最新的WAL条目与检查点完成(CHECKPOINT_ONLINE)有关。 这个检查点的起始LSN在redo后面指定;这个位置对应于检查点开始时最近插入的WAL条目。
同样的信息也可以在pg_control文件中找到:
