《Effective-Ruby》读书笔记

本篇是在我接触了 Ruby 很短一段时间后有幸捧起的一本书,下面结合自己的一些思考,来输出一下自己的读书笔记
前言
学习一门新的编程语言通常需要经过两个阶段:
- 第一个阶段是学习这门编程语言的语法和结构,如果我们具有其他编程语言的经验,那么这个过程通常只需要很短的时间;
- 第二个阶段是深入语言、学习语言风格,许多编程语言在解决常见的问题时都会使用独特的方法,Ruby 也不例外。
《Effictive Ruby》就是一本致力于让你在第二阶段更加深入和全面的了解 Ruby,编写出更具可读性、可维护性代码的书,下面我就着一些我认为的重点和自己的思考来进行一些精简和说明
第一章:让自己熟悉 Ruby
第 1 条:理解 Ruby 中的 True
- 每一门语言对于布尔类型的值都有自己的处理方式,在 Ruby 中,除了 false 和 nil,其他值都为真值,包括数字 0 值。
- 如果你需要区分 false 和 nil,可以使用 nil? 的方式或 “==“ 操作符并将 false 作为左操作对象。
# 将 false 放在左边意味着 Ruby 会将表达式解析为 FalseClass#== 方法的调用(该方法继承自 Object 类)
# 这样我们可以很放心地知道:如果右边的操作对象也是 false 对象,那么返回值为 true
if false == x
...
end
# 换句话说,把 false 置为有操作对象是有风险的,可能不同于我们的期望,因为其他类可能覆盖 Object#== 方法从而改变下面这个比较
class Bad
def == (other)
true
end
end
irb> false == Bad.new
---> false
irb> Bad.new == false
---> true第 2 条:所有对象的值都可能为 nil
在 Ruby 中倡导接口高于类型,也就是说预期要求对象是某个给定类的实例,不如将注意力放在该对象能做什么上。没有什么会阻止你意外地把 Time 类型对象传递给接受 Date 对象的方法,这些类型的问题虽然可以通过测试避免,但仍然有一些多态替换的问题使这些经过测试的应用程序出现问题:
undefined method 'fubar' for nil:NilClass (NoMethodError)当你调用一个对象的方法而其返回值刚好是讨厌的 nil 对象时,这种情况就会发生···nil 是类 NilClass 的唯一对象。这样的错误会悄然逃过测试而仅在生产环境下出现:如果一个用户做了些超乎寻常的事。
另一种导致该结果的情况是,当一个方法返回 nil 并将其作为参数直接传给一个方法时。事实上存在数量惊人的方式可以将 nil 意外地引入你运行中的程序。最好的防范方式是:假设任何对象都可以为 nil,包括方法参数和调用方法的返回值。
# 最简单的方式是使用 nil? 方法
# 如果方法接受者(receiver)是 nil,该方法将返回真值,否则返回假值。
# 以下几行代码是等价的:
person.save if person
person.save if !person.nil?
person.save unless person.nil?
# 将变量显式转换成期望的类型常常比时刻担心其为 nil 要容易得多
# 尤其是在一个方法即使是部分输入为 nil 时也应该产生结果的时候
# Object 类定义了几种转换方法,它们能在这种情况下派上用场
# 比如,to_s 方法会将方法接受者转化为 string:
irb> 13.to_s
---> "13"
irb> nil.to_s
---> ""
# to_s 如此之棒的原因在于 String#to_s 方法只是简单返回 self 而不做任何转换和复制
# 如果一个变量是 string,那么调用 to_s 的开销最小
# 但如果变量期待 string 而恰好得到 nil,to_s 也能帮你扭转局面:
def fix_title (title)
title.to_s.capitalize
end这里还有一些适用于 nil 的最有用的例子:
irb> nil.to_a
---> []
irb> nil.to_i
---> 0
irb> nil.to_f
---> 0.0当需要同时考虑多个值的时候,你可以使用类 Array 提供的优雅的讨巧方式。Array#compact 方法返回去掉所有 nil 元素的方法接受者的副本。这在将一组可能为 nil 的变量组装成 string 时很常用。比如:如果一个人的名字由 first、middle 和 last 组成(其中任何一个都可能为 nil),那么你可以用下面的代码组成这个名字:
name = [first, middle, last].compact.join(" ")nil 对象的嗜好是在你不经意间偷偷溜进正在运行的程序中。无论它来自用户输入、无约束数据库,还是用 nil 来表示失败的方法,意味着每个变量都可能为 nil。
第 3 条:避免使用 Ruby 中古怪的 Perl 风格语法
- 推荐使用 String#match 替代 String#=~。前者将匹配信息以 MatchDate 对象返回,而非几个特殊的全局变量。
- 使用更长、更表意的全局变量的别名,而非其短的、古怪的名字(比如,用
$LOAD_PATH替代$:)。大多数长的名字需要在加载库 English 之后才能使用。 - 避免使用隐式读写全局变量 $_ 的方法(比如,Kernel#print、Regexp#~ 等)
# 这段代码中有两个 Perl 语法。
# 第一个:使用 String#=~ 方法
# 第二个:在上述代码中看起来好像是使用了一个全局变量 $1 导出第一个匹配组的内容,但其实不是...
def extract_error (message)
if message =~ /^ERROR:\s+(.+)$/
$1
else
"no error"
end
end
# 以下是替代方法:
def extract_error (message)
if m = message.match(/^ERROR:\s+(.+)$/)
m[1]
else
"no error"
end
end第 4 条:留神,常量是可变的
最开始接触 Ruby 时,对于常量的认识大概可能就是由大写字母加下划线组成的标识符,例如 STDIN、RUBY_VERSION。不过这并不是故事的全部,事实上,由大写字母开头的任何标识符都是常量,包括 String 或 Array,来看看这个:
module Defaults
NOTWORKS = ["192.168.1","192.168.2"]
end
def purge_unreachable (networks=Defaults::NETWORKS)
networks.delete_if do |net|
!ping(net + ".1")
end
end如果调用方法 unreadchable 时没有加参数的话,会意外的改变一个常量的值。在 Ruby 中这样做甚至都不会警告你。好在有一种解决这个问题的方法——freeze 方法:
module Defaults
NOTWORKS = ["192.168.1","192.168.2"].freeze
end加入你再想改变常量 NETWORKS 的值,purge_unreadchable 方法就会引入 RuntimeError 异常。根据一般的经验,总是通过冻结常量来阻止其被改变,然而不幸的是,冻结 NETWORKS 数组还不够,来看看这个:
def host_addresses (host, networks=Defaults::NETWORKS)
networks.map {|net| net << ".#{host}"}
end如果第二个参数没有赋值,那么 host_addresses 方法会修改数组 NETWORKS 的元素。即使数组 NETWORKS 自身被冻结,但是元素仍然是可变的,你可能无法从数组中增删元素,但你一定可以对存在的元素加以修改。因此,如果一个常量引用了一个集合,比如数组或者是散列,那么请冻结这个集合以及其中的元素:
module Defaults
NETWORKS = [
"192.168.1",
"192.168.2"
].map(&:freeze).freeze
end甚至,要达到防止常量被重新赋值的目的,我们可以冻结定义它的那个模块:
module Defaults
TIMEOUT = 5
end
Defaults.freeze第 5 条:留意运行时警告
- 使用命令行选项 ”-w“ 来运行 Ruby 解释器以启用编译时和运行时的警告。设置环境变量 RUBYOPT 为 ”-w“ 也可以达到相同目的。
- 如果必须禁用运行时的警告,可以临时将全局变量 $VERBOSE 设置为 nil。
# test.rb
def add (x, y)
z = 1
x + y
end
puts add 1, 2
# 使用不带 -w 参数的命令行
irb> ruby test.rb
---> 3
# 使用带 -w 参数的命令行
irb< ruby -w test.rb
---> test.rb:1: warning: parentheses after method name is interpreted as an argument list, not a decomposed argument
---> test.rb:2: warning: assigned but unused variable - z
---> 3第二章:类、对象和模块
第 6 条:了解 Ruby 如何构建集成体系
让我们直接从代码入手吧:
class Person
def name
...
end
end
class Customer < Person
...
end
irb> customer = Customer.new
---> #
irb> customer.superclass
---> Person
irb> customer.respond_to?(:name)
---> true 上面的代码几乎就和你预想的那样,当调用 customer 对象的 name 方法时,Customer 类会首先检查自身是否有这个实例方法,没有那么就继续搜索。
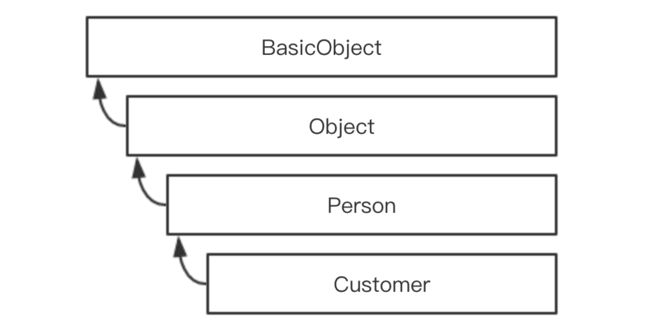
顺着集成体系向上找到了 Person 类,在该类中找到了该方法并将其执行。(如果 Person 类中没有找到的话,Ruby 会继续向上直到到达 BasicObject)
但是如果方法在查找过程中直到类树的根节点仍然没有找到匹配的办法,那么它将重新从起点开始查找,不过这一次会查找 method_missing 方法。
下面我们开始让事情变得更加有趣一点:
module ThingsWithNames
def name
...
end
end
class Person
include(ThingsWithNames)
end
irb> Person.superclass
---> Object
irb> customer = Customer.new
---> #
irb> customer.respond_to?(:name)
---> true 这里把 name 方法从 Person 类中取出并移到一个模块中,然后把模块引入到了 Person 类。Customer 类的实例仍然可以如你所料响应 name 方法,但是为什么呢?显然,模块 ThingsWithNames 并不在集成体系中,因为 Person 类的超类仍然是 Object 类,那会是什么呢?其实,Ruby 在这里对你撒谎了!当你 include 方法来将模块引入类时,Ruby 在幕后悄悄地做了一些事情。它创建了一个单例类并将它插入类体系中。这个匿名的不可见类被链向这个模块,因此它们共享了实力方法和常量。
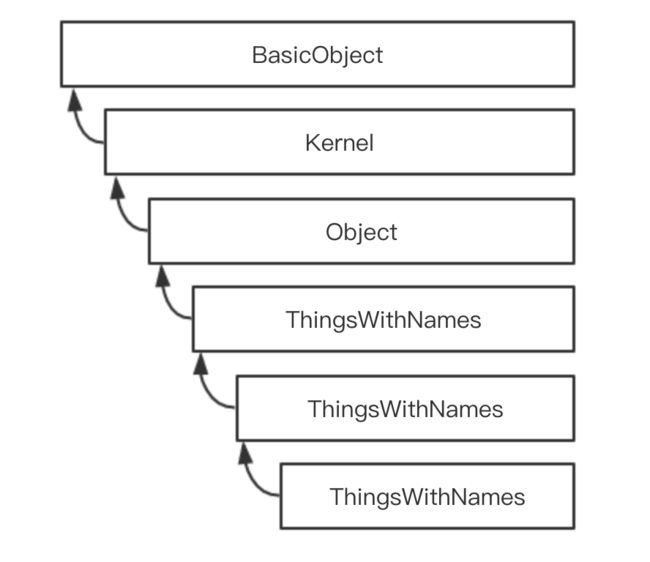
当每个模块被类包含时,它会立即被插入集成体系中包含它的类的上方,以后进先出(LIFO)的方式。每个对象都通过变量 superclass 链接,像单链表一样。这唯一的结果就是,当 Ruby 寻找一个方法时,它将以逆序访问访问每个模块,最后包含的模块最先访问到。很重要的一点是,模块永远不会重载类中的方法,因为模块插入的位置是包含它的类的上方,而 Ruby 总是会在向上检查之前先检查类本身。
(好吧······这不是全部的事实。确保你阅读了第 35 条,来看看 Ruby 2.0 中的 prepend 方法是如何使其复杂化的)
要点回顾:
- 要寻找一个方法,Ruby 只需要向上搜索类体系。如果没有找到这个方法,就从起点开始搜搜 method_missing 方法。
- 包含模块时 Ruby 会悄悄地创建单例类,并将其插入在继承体系中包含它的类的上方。
- 单例方法(类方法和针对对象的方法)存储于单例类中,它也会被插入继承体系中。
第 7 条:了解 super 的不同行为
- 当你想重载继承体系中的一个方法时,关键字 super 可以帮你调用它。
- 不加括号地无参调用 super 等价于将宿主方法的素有参数传递给要调用的方法。
- 如果希望使用 super 并且不向重载方法传递任何参数,必须使用空括号,即 super()。
- 当 super 调用失败时,自定义的 method_missing 方法将丢弃一些有用的信息。在第 30 条中有 method_missing 的替代解决方案。
第 8 条:初始化子类时调用 super
- 当创建子类对象时,Ruby 不会自动调用超类中的 initialize 方法。作为替代,常规的方法查询规则也适用于 initialize 方法,只有第一个匹配的副本会被调用。
- 当为显式使用继承的类定义 initialize 方法时,使用 super 来初始化其父类。在定义 initialize_copy 方法时,应使用相同的规则
class Parent
def initialize (name)
@name = name
end
end
class Child < Parent
def initialize (grade)
@grade = grade
end
end
# 你能看到上面的窘境,Ruby 没有提供给子类和其超类的 initialize 方法建立联系的方式
# 我们可以使用通用意义上的 super 关键字来完成继承体系中位于高层的办法:
class Child < Parent
def initialize (name, grade)
super(name) # Initialize Parent.
@grade = grade
end
end第 9 条:提防 Ruby 最棘手的解析
这是一条关于 Ruby 可能会戏弄你的另一条提醒,要点在于:Ruby 在对变量赋值和对 setter 方法调用时的解析是有区别的!直接看代码吧:
# 这里把 initialize 方法体中的内容当做第 counter= 方法的调用也不是毫无道理
# 事实上 initialize 方法会创建一个新的局部变量 counter,并将其赋值为 0
# 这是因为 Ruby 在调用 setter 方法时要求存在一个显式接受者
class Counter
attr_accessor(:counter)
def initialize
counter = 0
end
...
end
# 你需要使用 self 充当这个接受者
class Counter
attr_accessor(:counter)
def initialize
self.counter = 0
end
...
end
# 而在你调用非 setter 方法时,不需要显式指定接受者
# 换句话说,不要使用不必要的 self,那会弄乱你的代码:
class Name
attr_accessor(:first, :last)
def initialize (first, last)
self.first = first
self.last = last
end
def full
self.first + " " + self.last # 这里没有调用 setter 方法使用 self 多余了
end
end
# 就像上面 full 方法里的注释,应该把方法体内的内容改为
first + " " + last第 10 条:推荐使用 Struct 而非 Hash 存储结构化数据
看代码吧:
# 假设你要对一个保存了年度天气数据的 CSV 文件进行解析并存储
# 在 initialize 方法后,你会获得一个固定格式的哈希数组,但是存在以下的问题:
# 1.不能通过 getter 方法访问其属性,也不应该将这个哈希数组通过公共接口向外暴露,因为其中包含了实现细节
# 2.每次你想在类内部使用该哈希时,你不得不回头来看 initialize 方法
# 因为你不知道CSV具体的对应是怎样的,而且当类成熟情况可能还会发生变化
require('csv')
class AnnualWeather
def initialize (file_name)
@readings = []
CSV.foreach(file_name, headers: true) do |row|
@readings << {
:date => Date.parse(row[2]),
:high => row[10].to_f,
:low => row[11].to_f,
}
end
end
end
# 使用 Struct::new 方法的返回值赋给一个常量并利用它创建对象的实践:
class AnnualWeather
# Create a new struct to hold reading data.
Reading = Struct.new(:date, :high, :low)
def initialize (file_name)
@readings = []
CSV.foreach(file_name, headers: true) do |row|
@readings << Reading.new(Date.parse(row[2]),
row[10].to_f,
row[11].to_f)
end
end
end
# Struct 类本身比你第一次使用时更加强大。除了属性列表,Struct::new 方法还能接受一个可选的块
# 也就是说,我们能在块中定义实例方法和类方法。比如,我们定义一个返回平均每月平均温度的 mean 方法:
Reading = Struct.new(:date, :high, :low) do
def mean
(high + low) / 2.0
end
end另外从其他地方看到了关于 Struct::new 的实践
- 考虑使用 Struct.new, 它可以定义一些琐碎的 accessors, constructor(构造函数) 和 comparison(比较) 操作。
# good
class Person
attr_reader :first_name, :last_name
def initialize(first_name, last_name)
@first_name = first_name
@last_name = last_name
end
end
# better
class Person < Struct.new(:first_name, :last_name)
end- 考虑使用 Struct.new,它替你定义了那些琐碎的存取器(accessors),构造器(constructor)以及比较操作符(comparison operators)。
# good
class Person
attr_accessor :first_name, :last_name
def initialize(first_name, last_name)
@first_name = first_name
@last_name = last_name
end
end
# better
Person = Struct.new(:first_name, :last_name) do
end- 要去 extend 一个 Struct.new - 它已经是一个新的 class。扩展它会产生一个多余的 class 层级 并且可能会产生怪异的错误如果文件被加载多次。
第 11 条:通过在模块中嵌入代码来创建命名空间
- 通过在模块中嵌入代码来创建命名空间
- 让你的命名空间结构和目录结构相同
- 如果使用时可能出现歧义,可使用 ”::” 来限定顶级常量(比如,::Array)
第 12 条:理解等价的不同用法
看看下面的 IRB 回话然后自问一下:为什么方法 equal? 的返回值和操作符 “==” 的不同呢?
irb> "foo" == "foo"
---> true
irb> "foo".equal?("foo")
---> false事实上,在 Ruby 中有四种方式来检查对象之间的等价性,下面来简单总个结吧:
- 绝不要重载 equal? 方法。该方法的预期行为是,严格比较两个对象,仅当它们同时指向内存中同一对象时其值为真(即,当它们具有相同的 object_id 时)
- Hash 类在冲突检查时使用 eql? 方法来比较键对象。默认实现可能和你的想像不同。遵循第 13 条建议之后再使用别名 eql? 来替代 “==” 书写更合理的 hash 方法
- 使用 “==” 操作符来测试两个对象是否表示相同的值。有些类比如表示数字的类会有一个粗糙的等号操作符进行类型转换
- case 表达式使用 “===“ 操作符来测试每个 when 语句的值。左操作数是 when 的参数,右操作数是 case 的参数
第 13 条:通过 "<=>" 操作符实现比较和比较模块
要记住在 Ruby 语言中,二元操作符最终会被转换成方法调用的形式,左操作数对应着方法的接受者,右操作数对应着方法第一个也是唯一的那个参数。
- 通过定义 "<=>" 操作符和引入 Comparable 模块实现对象的排序
- 如果左操作数不能与右操作数进行比较,"<=>" 操作符应该返回 nil
- 如果要实现类的 "<=>" 运算符,应该考虑将 eql? 方法设置为 "==" 操作符的别名,特别是当你希望该类的所有实例可以被用来作为哈希键的时候,就应该重载哈希方法
第 14 条:通过 protected 方法共享私有状态
- 通过 protected 方法共享私有状态
- 一个对象的 protected 方法若要被显式接受者调用,除非该对象与接受者是同类对象或其具有相同的定义该 protected 方法的超类
# Ruby 语言中,私有方法的行为和其他面向对象的编程语言中不太相同。Ruby 语言仅仅在私有方法上加了一条限制————它们不能被显式接受者调用
# 无论你在继承关系中的哪一级,只要你没有使用接受者,你都可以调用祖先方法中的私有方法,但是你不能调用另一个对象的私有方法
# 考虑下面的例子:
# 方法 Widget#overlapping? 会检测其本身是否和另一个对象在屏幕上重合
# Widget 类的公共接口并没有将屏幕坐标对外暴露,它们的具体实现都隐藏在了内部
class Widget
def overlapping? (other)
x1, y1 = @screen_x, @screen_y
x2, y2 = other.instance_eval {[@screen_x, @screen_y]}
...
end
end
# 可以定义一个暴露私有屏幕坐标的方法,但并不通过公共接口来实现,其实现方式是声明该方法为 protected
# 这样我们既保持了原有的封装性,也使得 overlapping? 方法可以访问其自身以及其他传入的 widget 实例的坐标
# 这正式设计 protected 方法的原因————在相关类之间共享私有信息
class Widget
def overlapping? (other)
x1, y1 = @screen_x, @screen_y
x2, y2 = other.screen_coordinates
...
end
protected
def screen_coordinates
[@screen_x, @screen_y]
end
end第 15 条:优先使用实例变量而非类变量
- 优先使用实例变量(@)而非类变量(@@)
- 类也是对象,所以它们拥有自己的私有实例变量集合
第三章:集合
第 16 条:在改变作为参数的集合之前复制它们
在 Ruby 中多数对象都是通过引用而不是通过实际值来传递的,当将这种类型的对象插入容器时,集合类实际存储着该对象的引用而不是对象本身。
(值得注意的是,这条准则是个例如:Fixnum 类的对象在传递时总是通过值而不是引用传递)
这也就意味着当你把集合作为参数传入某个方法并进行修改时,原始集合也会因此被修改,有点间接,不过很容易看到这种情况的发生。
Ruby 语言自带了两个用来复制对象的方法:dup 和 clone。
它们都会基于接收者创建新的对象,但是与 dup 方法不同的是,clone 方法会保留原始对象的两个附加特性。
首先,clone 方法会保留接受者的冻结状态。如果原始对象的状态是冻结的,那么生成的副本也会是冻结的。而 dup 方法就不同了,它永远不会返回冻结的对象。
其次,如果接受这种存在单例方法,使用 clone 也会复制单例类。由于 dup 方法不会这样做,所以当使用 dup 方法时,原始对象和使用 dup 方法创建的副本对于相同消息的响应可能是不同的。
# 也可以使用 Marshal 类将一个集合及其所持有的元素序列化,然后再反序列化: irb> a = ["Monkey", "Brains"] irb> b = Marshal.load(Marshal.dump(a)) irb> b.each(&:upcasel); b.first ---> "MONKEY" irb> a.last ---> "Brains"
第 17 条:使用 Array 方法将 nil 及标量对象转换成数组
- 使用 Array 方法将 nil 及标量对象转换成数组
- 不要将哈希传给 Array 方法,它会被转化成一个嵌套数组的集合
# 考虑下面这样一个订披萨的类:
class Pizza
def initialize (toppings)
toppings.each do |topping|
add_and_price_topping(topping)
end
end
end
# 上面的 initialize 方法期待的是一个 toppings 数组,但我们能传入单个 topping,甚至是在没有 topping 对象的时候直接传入 nil
# 你可能会想到使用可变长度参数列表来实现它,并将参数类型改为 *topping,这样会把所有的参数整合成一个数组。
# 尽管这样做可以让我们传入单个 topping 对象,担当传入一组对象给 initialize 方法的时候必须使用 "*" 显式将其拓展成一个数组。
# 所以这样做仅仅是拆东墙补西墙罢了,一个更好的解决方式是将传入的参数转换成一个数组,这样我们就明确地知道我要做的是什么了
# 先对 Array() 做一些探索:
irb> Array('Betelgeuse')
---> ["Betelgeuse"]
irb> Array(nil)
---> []
irb> Array(['Nadroj', 'Retep'])
---> ["Nadroj", "Retep"]
irb> h = {pepperoni: 20,jalapenos: 2}
irb> Array(h)
---> [[:pepperoni, 20], [:jalapenos, 2]]
# 如果你想处理一组哈希最好采用第 10 条的建议那样
# 回答订披萨的问题上:
# 经过一番改造,它现在能够接受 topping 数组、单个 topping,或者没有 topping(nil or [])
class Pizza
def initialize (toppings)
Array(toppings).each do |topping|
add_and_price_topping(topping)
end
end
...
end第 18 条:考虑使用集合高效检查元素的包含性
(书上对于这一条建议的描述足足有 4 页半,但其实可以看下面结论就ok,结尾有实例代码)
- 考虑使用 Set 来高效地检测元素的包含性
- 插入 Set 的对象必须也被当做哈希的键来用
- 使用 Set 之前要引入它
# 原始版本
class Role
def initialize (name, permissions)
@name, @permissions = name, permissions
end
def can? (permission)
@permissions.include?(permission)
end
end
# 版本1.0:使用 Hash 替代 Array 的 Role 类:
# 这样做基于两处权衡,首先,因为哈希只存储的键,所以数组中的任何重复在转换成哈希的过程中都会丢失。
# 其次,为了能够将数组转换成哈希,需要将整个数组映射,构建出一个更大的数组,从而转化为哈希。这将性能问题从 can? 方法转移到了 initialize 方法
class Role
def initialize (name, permissions)
@name = name
@permissions = Hash[permissions.map {|p| [p, ture]}]
end
def can? (permission)
@permissions.include?(permission)
end
end
# 版本2.0:引入 Set:
# 性能几乎和上一个哈希版本的一样
require('set')
class Role
def initialize (name, permissions)
@name, @permissions = name, Set.new(permissions)
end
def can? (permission)
@permissions.include?(permission)
end
end
# 最终的例子
# 这个版本自动保证了集合中没有重复的记录,且重复条目是很快就能被检测到的
require('set')
require('csv')
class AnnualWeather
Reading = Struct.new(:date, :high, :low) do
def eql? (other) date.eql?(other.date); end
def hash; date.hash; end
end
def initialize (file_name)
@readings = Set.new
CSV.foreach(file_name, headers: true) do |row|
@readings << Reading.new(Date.parse(row[2]),
row[10].to_f,
row[11].to_f)
end
end
end第 19 条:了解如何通过 reduce 方法折叠集合
尽管可能有点云里雾里,但还是考虑考虑先食用代码吧:
# reduce 方法的参数是累加器的起始值,块的目的是创建并返回一个适用于下一次块迭代的累加器
# 如果原始集合为空,那么块永远也不会被执行,reduce 方法仅仅是简单地返回累加器的初始值
# 要注意块并没有做任何赋值。这是因为在每个迭代后,reduce 丢弃上次迭代的累加器并保留了块的返回值作为新的累加器
def sum (enum)
enum.reduce(0) do |accumulator, element|
accumulator + element
end
end
# 另一个快捷操作方式对处理块本身很方便:可以给 reduce 传递一个符号(symbol)而不是块。
# 每个迭代 reduce 都使用符号作为消息名称发送消息给累加器,同时将当前元素作为参数
def sum (enum)
enum.reduce(0, :+)
end
# 考虑一下把一个数组的值全部转换为哈希的键,而它们的值都是 true 的情况:
Hash[array.map {|x| [x, true]}]
# reduce 可能会提供更加完美的方案(注意此时 reduce 的起始值为一个空的哈希):
array.reduce({}) do |hash, element|
hash.update(element => true)
end
# 再考虑一个场景:我们需要从一个存储用户的数组中筛选出那些年龄大于或等于 21 岁的人群,之后我们希望将这个用户数组转换成一个姓名数组
# 在没有 reduce 的时候,你可能会这样写:
users.select {|u| u.age >= 21}.map(&:name)
# 上面这样做当然可以,但并不高效,原因在于我们使用上面的语句时对数组进行了多次遍历
# 第一次是通过 select 筛选出了年龄大于或等于 21 岁的人,第二次则还需要映射成只包含名字的新数组
# 如果我们使用 reduce 则无需创建或遍历多个数组:
users.reduce([]) do |names, user|
names << user.name if user.age >= 21
names
end引入 Enumerable 模块的类会得到很多有用的实例方法,它们可用于对对象的集合进行过滤、遍历和转化。其中最为常用的应该是 map 和 select 方法,这些方法是如此强大以至于在几乎所有的 Ruby 程序中你都能见到它们的影子。
像数组和哈希这样的集合类几乎已经是每个 Ruby 程序不可或缺的了,如果你还不熟悉 Enumberable 模块中定义的方法,你可能已经自己写了相当多的 Enumberable 模块已经具备的方法,知识你还不知道而已。
Enumberable 模块
戳开 Array 的源码你能看到 include Enumberable 的字样(引入的类必须实现 each 方法不然报错),我们来简单阐述一下 Enumberable API:
irb> [1, 2, 3].map {|n| n + 1} ---> [2, 3, 4] irb> %w[a l p h a b e t].sort ---> ["a", "a", "b", "e", "h", "l", "p", "t"] irb> [21, 42, 84].first ---> 21上面的代码中:
- 首先,我们使用了流行的 map 方法遍历每个元素,并将每个元素 +1 处理,然后返回新的数组;
- 其次,我们使用了 sort 方法对数组的元素进行排序,排序采用了 ASCII 字母排序
- 最后,我们使用了查找方法 select 返回数组的第一个元素
reduce 方法到底干了什么?它为什么这么特别?在函数式编程的范畴中,它是一个可以将一个数据结构转换成另一种结构的折叠函数。
让我们先从宏观的角度来看折叠函数,当使用如 reduce 这样的折叠函数时你需要了解如下三部分:
- 枚举的对象是 reduce 消息的接受者。某种程度上这是你想转换的原始集合。显然,它的类必须引入 Enumberable 模块,否则你无法对它调用 reduce 方法;
- 块会被源集合中的每个元素调用一次,和 each 方法调用块的方式类似。但和 each 不同的是,传入 reduce 方法的块必须产生一个返回值。这个返回值代表了通过当前元素最终折叠生成的数据结构。我们将会通过一些例子来巩固这一知识点。
- 一个代表了目标数据结构起始值的对象,被称为累加器。每一次块的调用都会接受当前的累加器值并返回新的累加器值。在所有元素都被折叠进累加器后,它的最终结构也就是 reduce 的返回值。
此时了解了这三部分你可以回头再去看一看代码。
试着回想一下上一次使用 each 的场景,reduce 能够帮助你改善类似下面这样的模式:
hash = {}
array.each do |element|
hash[element] = true
end第 20 条:考虑使用默认哈希值
我确定你是一个曾经在块的语法上徘徊许久的 Ruby 程序员,那么请告诉我,下面这样的模式在代码中出现的频率是多少?
def frequency (array)
array.reduce({}) do |hash, element|
hash[element] ||= 0 # Make sure the key exists.
hash[element] += 1 # Then increment it.
hash # Return the hash to reduce.
end
end这里特地使用了 "||=" 操作符以确保在修改哈希的值时它是被赋过值的。这样做的目的其实也就是确保哈希能有一个默认值,我们可以有更好的替代方案:
def frequency (array)
array.reduce(Hash.new(0)) do |hash, element|
hash[element] += 1 # Then increment it.
hash # Return the hash to reduce.
end
end看上去还真是那么一回事儿,但是小心,这里埋藏着一个隐蔽的关于哈希的陷阱。
# 先来看一下这个 IRB 会话:
irb> h = Hash.new(42)
irb> h[:missing_key]
---> 42、
irb> h.keys # Hash is still empty!
---> []
irb> h[:missing_key] += 1
---> 43
irb> h.keys # Ah, there you are.
---> [:missing_key]
# 注意,当访问不存在的键时会返回默认值,但这不会修改哈希对象。
# 使用 "+=" 操作符的确会像你想象中那般更新哈希,但并不明确,回顾一下 "+=" 操作符会展开成什么可能会很有帮助:
# Short version:
hash[key] += 1
# Expands to:
hash[key] = hash[key] + 1
# 现在赋值的过程就很明确了,先取得默认值再进行 +1 的操作,最终将其返回的结果以同样的键名存入哈希
# 我们并没有以任何方式改变默认值,当然,上面一段代码的默认值是数字类型,它是不能修改的
# 但是如果我们使用一个可以修改的值作为默认值并在之后使用了它情况将会变得更加有趣:
irb> h = Hash.new([])
irb> h[:missing_key]
---> []
irb> h[:missing_key] << "Hey there!"
---> ["Hey there!"]
irb> h.keys # Wait for it...
---> []
irb> h[:missing_key]
---> ["Hey there!"]
# 看到上面关于 "<<" 的小骗局了吗?我从没有改变哈希对象,当我插入一个元素之后,哈希并么有改变,但是默认值改变了
# 这也是 keys 方法提示这个哈希是空但是访问不存在的键时却反悔了最近修改的值的原因
# 如果你真想插入一个元素并设置一个键,你需要更深入的研究,但另一个不明显的副作用正等着你:
irb> h = Hash.new([])
irb> h[:weekdays] = h[:weekdays] << "Monday"
irb> h[:months] = h[:months] << "Januray"
irb> h.keys
---> [:weekdays, :months]
irb> h[:weekdays]
---> ["Monday", "January"]
irb> h.default
---> ["Monday", "Januray"]
# 两个键共享了同一个默认数组,多数情况你并不想这么做
# 我们真正想要的是当我们访问不存在的键时能返回一个全新的数组
# 如果给 Hash::new 一个块,当需要默认值时这个块就会被调用,并友好地返回一个新创建的数组:
irb> h = Hash.new{[]}
irb> h[:weekdays] = h[:weekdays] << "Monday"
---> ["Monday"]
irb> h[:months] = h[:months] << "Januray"
---> ["Januray"]
irb> h[:weekdays]
---> ["Monday"]
# 这样好多了,但我们还可以往前一步。
# 传给 Hash::new 的块可以有选择地接受两个参数:哈希本身和将要访问的键
# 这意味着我们如果想去改变哈希也是可的,那么当访问一个不存在的键时,为什么不将其对应的值设置为一个新的空数组呢?
irb> h = Hash.new{|hash, key| hash[key] = []}
irb> h[:weekdays] << "Monday"
irb> h[:holidays]
---> []
irb> h.keys
---> [:weekdays, :holidays]
# 你可能发现上面这样的技巧存在着重要的不足:每当访问不存在的键时,块不仅会在哈希中创建新实体,同时还会创建一个新的数组
# 重申一遍:访问一个不存在的键会将这个键存入哈希,这暴露了默认值存在的通用问题:
# 正确的检查一个哈希是否包含某个键的方式是使用 hash_key? 方法或使用它的别名,但是深感内疚的是通常情况下默认值是 nil:
if hash[key]
...
end
# 如果一个哈希的默认值不是 nil 或者 false,这个条件判断会一直成功:将哈希的默认值设置成非 nil 可能会使程序变得不安全
# 另外还要提醒的是:通过获取其值来检查哈希某个键存在与否是草率的,其结果也可能和你所预期的不同
# 另一种处理默认值的方式,某些时候也是最好的方式,就是使用 Hash#fetch 方法
# 该方法的第一个参数是你希望从哈希中查找的键,但是 fetch 方法可以接受一个可选的第二个参数
# 如果指定的 key 在当前的哈希中找不到,那么取而代之,fetch 的第二个参数会返回
# 如果你省略了第二个参数,在你试图获取一个哈希中不存在的键时,fetch 方法会抛出一个异常
# 相比于对整个哈希设置默认值,这种方式更加安全
irb> h = {}
irb> h[:weekdays] = h.fetch(:weekdays, []) << "Monday"
---> ["Monday"]
irb> h.fetch(:missing_key)
keyErro: key not found: :missing_key所以看过上面的代码框隐藏的内容后你会发现:
- 如果某段代码在接受哈希的非法键时会返回 nil,不要为传入该方法的哈希使用默认值
- 相比使用默认值,有些时候用 Hash#fetch 方法能更加安全
第 21 条:对集合优先使用委托而非继承
这一条也可以被命名为“对于核心类,优先使用委托而非继承”,因为它同样适用于 Ruby 的所有核心类。
Ruby 的所有核心类都是通过 C语言 来实现的,指出这点是因为某些类的实例方法并没有考虑到子类,比如 Array#reverse 方法,它会返回一个新的数组而不是改变接受者。
猜猜如果你继承了 Array 类并调用了子类的 reverse 方法后会发生什么?
# 是的,LikeArray#reverse 返回了 Array 实例而不是 LikeArray 实例
# 但你不应该去责备 Array 类,在文档中有写的很明白会返回一个新的实例,所以达不到你的预期是很自然的
irb> class LikeArray < Array; end
irb> x = LikeArray.new([1, 2, 3])
---> [1, 2, 3]
irb> y = x.reverse
---> [3, 2, 1]
irb> y.class
---> Array当然还不止这些,集合上的许多其他实例方法也是这样,集成比较操作符就更糟糕了。
比如,它们允许子类的实例和父类的实例相比较,这说得通嘛?
irb> LikeArray.new([1, 2, 3]) == [1, 2, 3,]
---> true继承并不是 Ruby 的最佳选择,从核心的集合类中继承更是毫无道理的,替代方法就是使用“委托”。
让我们来编写一个基于哈希但有一个重要不同的类,这个类在访问不存在的键时会抛出一个异常。
实现它有很多不同的方式,但编写一个新类让我们可以简单的重用同一个实现。
与继承 Hash 类后为保证正确而到处修修补补不同,我们这一次采用委托。我们只需要一个实例变量 @hash,它会替我们干所有的重活:
# 在 Ruby 中实现委托的方式有很多,Forwardable 模块让使用委托的过程非常容易
# 它将一个存有要代理的方法的链表绑定到一个实例变量上,它是标准库的一部分(不是核心库),这也是需要显式引入的原因
require('forwardable')
class RaisingHash
extend(Forwardable)
include(Enumerbale)
def_delegators(:@hash, :[], :[]=, :delete, :each,
:keys, :values, :length,
:empty?, :hash_key?)
end(更多的探索在书上.这里只是简单给一下结论.感兴趣的童鞋再去看看吧!)
所以要点回顾一下:
- 对集合优先使用委托而非继承
- 不要忘记编写用来复制委托目标的 initialize_copy 方法
- 编写 freeze、taint 以及 untaint 方法时,先传递信息给委托目标,之后调用 super 方法。
第四章:异常
第 22 条:使用定制的异常而不是抛出字符串
- 避免使用字符串作为异常,它们会被转换成原生的 RuntimeError 对象。取而代之,创建一个定制的异常类
- 定制的异常类应该继承自 StandardError,且类名应该以 "Error" 结尾
- 当为一个工程创建了不止一个异常类时,从创建一个继承自 StandardError 的基类开始。其他的异常类应该继承自该定制的基类
- 如果你对你的定制异常类编写了 initialize 方法,务必确保其调用了 super 方法,最好在调用时以错误信息作为参数
- 在 initialize 方法中设置错误信息时,请牢记:如果在 raise 方法中再度设置错误信息会覆盖原本在 initialize 中设置的那一条
class TemperatureError < StandardError
attr_reader(:temperature)
def initialize(temperature)
@temperature = temperature
super("invalid temperature: #@temperature")
end
end第 23 条:捕获可能的最具体的异常
- 只捕获那些你知道如何恢复的异常
- 当捕获异常时,首先处理最特殊的类型。在异常的继承关系中位置越高的,越应该排在 rescue 链的后面
- 避免捕获如 StandardError 这样的通用异常。如果你已经这么做了,就应该想想你真正想做的是不是可以通过 ensure 语句来实现
- 在异常发生的情况下,从 resuce 语句中抛出的异常将会替换当前异常并离开当前的作用域
第 24 条:通过块和 ensure 管理资源
- 通过 ensure 语句来释放任何已获得的资源
- 通过在类方法上使用块和 ensure 语句将资源管理的逻辑抽离出来
- 确保 ensure 语句中使用的变量已经被初始化过了
第 25 条:通过临近的 end 退出 ensure 语句
- 避免在 ensure 语句中显式使用 return 语句,这意味着方法体内存在着某些错误的逻辑
- 同样,不要在 ensure 语句中直接使用 throw,你应该将 throw 放在方法主体内
- 当执行迭代时,不要在 ensure 语句中执行 next 或 break。仔细想想在迭代内到底需不需要 begin 块。将关系反转或许更加合理,就是将迭代放在 begin 块中
- 一般来说,不要再 ensure 语句中改变控制流,在 rescue 语句中完成这样的工作,你的意图会更加清晰
第 26 条:限制 retry 次数,改变重试频率并记录异常信息
- 永远不要无条件 retry,要把它看做代码中的隐式循环;在代码块的外围定义重试次数,当超出最大重试次数时重新抛出异常
- retry 时记录具有审计作用的异常信息,如果重试有问题的代码解决不了问题,需要追根溯源地去了解异常是如何发生的
- 当在 retry 之前使用延时时,需要考虑增加延时避免加剧问题
第 27 条:throw 比 raise 更适合用来跳出作用域
- 在复杂的流程控制中,可以考虑使用 throw 和 raise,这种方法一个额外的好处是可以把一个对象传递到上层调用栈并作为 catch 的最终返回值
- 尽量使用简单的方法来控制程序结果,可以通过方法调用和 return 重写 catch 和 throw
第五章:元编程
第 28 条:熟悉 Ruby 模块和类的钩子方法
- 所有的钩子方法都需要被定义为单例方法
- 添加、删除、取消定义方法的钩子方法参数是方法名,而不是类名,如果需要,使用 self 去获取类的信息
- 定义 singleton_method_added 会出发自身
- 不要覆盖 extend_object、append_features 和 prepend_features 方法,使用 extended、included 和 prepended 替代
第 29 条:在类的钩子方法中执行 super 方法
- 在类的钩子方法中执行 super 方法
第 30 条:推荐使用 define_method 而非 method_missing
- define_method 优于 method_missing
- 如果必须使用 method_missing,最好也定义 respond_to_missing? 方法
第 31 条:了解不同类型的 eval 间的差异
- 使用 instance_eval 和 instance_exec 定义的单例方法
- class_eval、module_eval、class_exec 和 module_exec 方法只可以被模块或者方法使用。通过这些定义的方法都是实例方法
第 32 条:慎用猴子补丁
- 尽管 refinement 已经不再是实验性的功能,它仍然有可能被修改得更加成熟
- 在不同的语法作用域,在使用 refinement 之前必须先激活它
第 33 条:使用别名链执行被修改的方法
- 在设置别名链时,需要确保别名是独一无二的
- 必要的时候要考虑提供一个撤销别名链的方法
第 34 条:支持多种 Proc 参数数量
- 与弱 Proc 对象不同,在参数数量不匹配时,强 Proc 对象会抛出 ArgumentError 异常
- 可以使用 Proc#arity 方法得到 Proc 期望的参数数量,如果返回的是正数,则意味着有多少参数是必须的。如果返回的是负数,则意味着 Proc 有些参数是可选的,可以通过 "~" 来得到有多少是必须参数
第 35 条:使用模块前置时请谨慎思考
- prepend 方法在使用时对类体系机构的影响是:它将模块插入到接受者之前。这和 include 方法有很大不同:include 则是将模块插入到接受者和其超类之间
- 与 included 和 extended 模块钩子一样,前置模块也会出发 prepended 钩子
第六章:测试
第 36 条:熟悉单元测试工具 MiniTest
- 测试方法需要以 "test_" 作为前缀
- 简短的测试更容易理解,也更容易维护
- 使用合适的断言方法生成更易读的出错信息
- 断言(Assertion)和反演(refutation)的文档在 MiniTest::Assertions 中
第 37 条:熟悉 MiniTest 的需求测试
- 使用 describe 方法创建测试类,使用 it 定义测试用例
- 虽然在需求说明测试中,断言仍然可用,但是更推荐使用注入到 Object 中的期望方法
- 在 MiniTest::Expectations 模块中,可以找到关于期望方法更详细的文档
第 38 条:使用 Mock 模拟特定对象
- 使用 Mock 来隔离外部系统的不稳定因素
- Mock 或者替换没有被测试过得方法,有可能会让这些被 Mock 的代码在生产环境中出现问题
- 请确保在测试方法代码的最后调用了 MiniTest::Mock#verity 方法
第 39 条:力争代码被有效测试过
- 使用模糊测试和属性测试工具,帮助测试代码的快乐路径和异常路径。
- 测试覆盖率工具会给你一种虚假的安全感,因为被执行过的代码不代表这行代码是正确的
- 在编写特性的同时就加上测试,会让测试容易得多
- 在你开始寻找导致 bug 的根本原因之前,先写一个针对该 bug 的测试
尽可能多地自动化你的测试
第七章:工具与库
第 40 条:学会使用 Ruby 文档
- ri 工具用来读取文档,rdoc 工具用来生成文档
- 使用命令行选项 "-d doc" 来为 RI 工具制定在 "doc" 路径下查找文档
运行 rdoc 时,后面跟上命令行选项 "-f ri" 来为 RI 工具生成文档。另外,用 "-f darkfish" 来生成 HTML 格式的文档(自己测试过..对于大型项目生成的 HTML 文档不是很友好..) - 完整的 RDoc 文档可以在 RDoc::Markup 类中找到(使用 RI 查阅)
第 41 条:认识 IRB 的高级特性
- 在 IRB::ExtendCommandBundle 模块,或者一个会被引入 IRB::ExtendCommandBundle 中的模块中自定义 IRB 命令
- 利用下划线变量("")来获取上一个表达式的结果(例如,last_elem = )
- irb 命令可以用来创建一个新的会话,并将当前的评估上下文改变成任意对象
考虑 Pry gem 作为 IRB 的替代品
第 42 条:用 Bundler 管理 Gem 依赖
- 在加载完 Bundler 之后,使用 Bundler.require 会牺牲一点点灵活性,但是可以加载 Gemfile 中所有的 gem
- 当开发应用时,在 Gemfile 中列出所有的 gem,然后把 Gemfile.lock 添加到版本控制系统中
- 当打包 RubyGem,在 gem 规格文件中列出 gem 所有依赖,但不要把 Gemfile.lock 添加到你的版本系统中
第 43 条:为 Gem 依赖设定版本上限
- 忽略掉版本上限需求相当于你说了你可以支持未来所有的版本
- 相对于悲观版本操作符,更加倾向于使用明确的版本范围
- 当公布发布一个 gem 时,指明依赖包的版本限制要求,在安全的范围内越宽越好,上限可以扩展到下一个主要发布版本之前
第八章:内存管理与性能
第 44 条:熟悉 Ruby 的垃圾收集器
扩展阅读:
Ruby GC 自述 · Ruby China
Ruby 2.1:RGenGC
垃圾收集器是个复杂的软件工程。从很高的层次看,Ruby 垃圾收集器使用一种被称为 标记-清除(mark and sweep)的过程。(熟悉 Java 的童鞋应该会感到一丝熟悉)
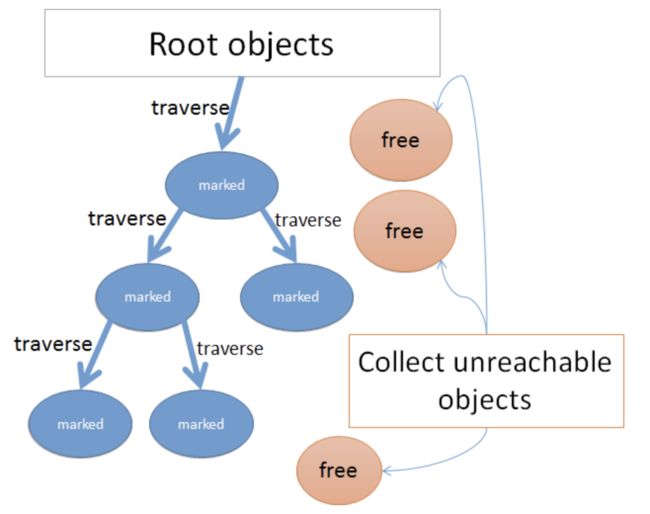
首先,遍历对象图,能被访问到的对象会被标记为存活的。接着,任何未在第一阶段标记过的对象会被视为垃圾并被清楚,之后将内存释放回 Ruby 或操作系统。
遍历整个对象图并标记可访问对象的开销太大。Ruby 2.1 通过新的分代式垃圾收集器对性能进行了优化。对象被分为两类,年轻代和年老代。
分代式垃圾收集器基于一个前提:大多数对象的生存时间都不会很长。如果我们知道了一个对象可以存活很久,那么就可以优化标记阶段,自动将这些老的对象标记为可访问,而不需要遍历整个对象图。
如果年轻代对象在第一阶段的标记中存活了下来,那么 Ruby 的分代式垃圾收集器就把它们提升为年老代。也就是说,他们依然是可访问的。
在年轻代对象和年老代对象的概念下,标记阶段可以分为两种模式:主要标记阶段(major)和次要标记阶段(minor)。
在主要标记阶段,所有的对象(无论新老)都会被标记。该模式下,垃圾收集器不区分新老两代,所以开销很大。
次要标记阶段,仅仅考虑年轻代对象,并自动标记年老代对象,而不检查能否被访问。这意味着年老代对象只会在主要标记阶段之后才会被清除。除非达到了一些阈值,保证整个过程全部作为主要标记之外,垃圾收集器倾向于使用次要标记。
垃圾收集器的清除阶段也有优化机制,分为两种模式:即使模式和懒惰模式。
在即使模式中,垃圾收集器会清除所有的未标记的对象。如果有很多对象需要被释放,那这种模式开销就很大。
因此,清除阶段还支持懒惰模式,它将尝试释放尽可能少的对象。
每当 Ruby 中创建一个新对象时,它可能尝试触发一次懒惰清除阶段,去释放一些空间。为了更好的理解这一点,我们需要看看垃圾收集器如何管理存储对象的内存。(简单概括:垃圾收集器通过维护一个由页组成的堆来管理内存。页又由槽组成。每个槽存储一个对象。)
我们打开一个新的 IRB 会话,运行如下命令:
`IRB``> ``GC``.stat`
`---> {``:count``=>``9``, ``:heap_length``=>``126``, ...}`GC::stat 方法会返回一个散列,包含垃圾收集器相关的所有信息。请记住,该散列中的键以及它们对应垃圾收集器的意义可能在下一个版本发生变化。
好了,让我们来看一些有趣的键:
| 键名 | 说明 |
|---|---|
| count | 垃圾收集器运行的总次数 |
| major_gc_count | 主要模式下的运行次数 |
| minor_gc_count | 次要模式下的运行次数 |
| total_allocated_object | 程序开始时分配的对象总数 |
| total_freed_object | Ruby 释放的对象总数。与上面之差表示存活对象的数量,这可以通过 heap_live_slot 键来计算 |
| heap_length | 当前堆中的页数 |
| heap_live_slot 和 heap_free_slot | 表示全部页中被使用的槽数和未被使用的槽数 |
| old_object | 年老代的对象数量,在次要标记阶段不会被处理。年轻代的对象数量可以用 heap_live_slot 减去 old_object 来获得 |
该散列中还有几个有趣的数字,但在介绍之前,让我们来学习垃圾收集器的最后一个要点。还记得对象是存在槽中的吧。Ruby 2.1 的槽大小为 40 字节,然而并不是所有的对象都是这么大。
比如,一个包含 255 个字节的字符串对象。如果对象的大小超过了槽的大小,Ruby 就会额外向操作系统申请一块内存。
当对象被销毁,槽被释放后,Ruby 会把多余的内存还给操作系统。现在让我们看看 GC::stat 散列中的这些键:
| 键名 | 说明 |
|---|---|
| malloc_increase | 所有超过槽大小的对象所占用的总比特数 |
| malloc_limit | 阈值。如果 malloc_increase 的大小超过了 malloc_limit,垃圾收集器就会在次要模式下运行。一个 Ruby 应用程序的生命周期里,malloc_limit 是被动调整的。它的大小是当前 malloc_increase 的大小乘以调节因子,这个因子默认是 1.4。你可以通过环境变量 RUBY_GC_MALLOC_LIMIT_GROWTH_FACTOR 来设定这个因子 |
| oldmalloc_increase 和 oldmalloc_limit | 是上面两个对应的年老代值。如果 oldmalloc_increase 的大小超过了 oldmalloc_limit,垃圾收集器就会在主要模式下运行。oldmalloc_limit 的调节因子more是 1.2。通过环境变量 RUBY_GC_OLDMALLOC_LIMIT_GROWTH_FACTOR 可以设定它 |
作为最后一部分,让我们来看针对特定应用程序进行垃圾收集器调优的环境变量。
在下一个版本的 Ruby 中,GC::stat 散列中的值对应的环境变量可能会发生变化。好消息是 Ruby 2.2 将支持 3 个分代,Ruby 2.1 只支持两个。这可能会影响到上述变量的设定。
有关垃圾收集器调优的环境变量的权威信息保存在 "gc.c" 文件中,是 Ruby 源程序的一部分。
下面是 Ruby 2.1 中用于调优的环境变量(仅供参考):
| 环境变量名 | 说明 |
|---|---|
| RUBY_GC_HEAP_INIT_SLOTS | 初始槽的数量。默认为 10k,增加它的值可以让你的应用程序启动时减少垃圾收集器的工作效率 |
| RUBY_GC_HEAP_FREE_SLOTS | 垃圾收集器运行后,空槽数量的最小值。如果空槽的数量小于这个值,那么 Ruby 会申请额外的页,并放入堆中。默认值是 4096 |
| RUBY_GC_HEAP_GROWTH_FACTOR | 当需要额外的槽时,用于计算需要增加的页数的乘数因子。用已使用的页数乘以这个因子算出还需要增加的页数、默认值是 1.8 |
| RUBY_GC_HEAP_GROWTH_MAX_SLOTS | 一次添加到堆中的最大槽数。默认值是0,表示没有限制。 |
| RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR | 用于计算出发主要模式垃圾收集器的门限值的乘数因子。门限由前一次主要清除后年老代对象数量乘以该因子得到。该门限与当前年老代对象数量成比例。默认值是 2.0。这意味着如果年老代对象在上次主要标记阶段过后的数量翻倍的话,新一轮的主要标记过程将被出发。 |
| RUBY_GC_MALLOC_LIMIT | GC::stat 散列中 malloc_limit 的最小值。如果 malloc_increase 超过了 malloc_limit 的值,那么次要模式垃圾收集器就会运行一次。该设定用于确保 malloc_increase 不会小于特定值。它的默认值是 16 777 216(16MB) |
| RUBY_GC_MALOC_LIMIT_MAX | 与 RUBY_GC_MALLOC_LIMIT 相反的值,这个设定保证 malloc_limit 不会变得太高。它可以被设置成 0 来取消上限。默认值是 33 554 432(32MB) |
| RUBY_GC_MALLOC_LIMIT_GROWTH_FACTOR | 控制 malloc_limit 如何增长的乘数因子。新的 malloc_limit 值由当前 malloc_limit 值乘以这个因子来获得,默认值为 1.4 |
| RUBY_GC_OLDMALLOC_LIMIT | 年老代对应的 RUBY_GC_MALLOC_LIMIT 值。默认值是 16 777 216(16MB) |
| RUBY_GC_OLDMALLOC_LIMIT_MAX | 年老代对应的 RUBY_GC_MALLOC_LIMIT_MAX 值。默认值是 134 217 728(128MB) |
| RUBY_GC_OLDMALLOC_LIMIT_GROWTH_FACTOR | 年老代对应的 RUBY_GC_MALLOC_LIMIT_GROWTH_FACTOR 值。默认值是 1.2 |
第 45 条:用 Finalizer 构建资源安全网
- 最好使用 ensure 子句来保护有限的资源。
- 如果必须要在 ensure 子句外报录一个资源(resource),那么就给它创建一个 finalizer(终结方法)
- 永远不要再这样一个绑定中创建 finalizer Proc,该绑定引用了一个注定会被销毁的对象,这会造成垃圾收集器无法释放该对象
- 记住,finalizer 可能在一个对象销毁后以及程序终止前的任何时间被调用
第 46 条:认识 Ruby 性能分析工具
- 在修改性能差的代码之前,先使用性能分析工具收集性能相关的信息。
- 在 ruby-prof gem 和 Ruby 自带的标准 profile 库之间,选择前者,因为前者更快而且可以提供多种不同的报告。
- 如果使用 Ruby 2.1 或者更新的版本,应该考虑使用 stackprof gem 和 memory_profiler gem。
第 47 条:避免在循环中使用对象字面量
- 将循环中的不会变化的对象字面量变成常量。
- 在 Ruby 2.1 及更高的版本中冻结字符串字面量,相当于把它作为常量,可以被整个运行程序共享。
第 48 条:考虑记忆化大开销计算
- 考虑提供一个方法通过将缓存的变量职位 nil 来重置记忆化。
- 确保时钟认真考虑过这些由记忆化而跳过副作用所导致的后果。
- 如果不希望调用者修改缓存的变量,那应该考虑让被记忆化的方法返回冻结对象。
- 先用工具分析程序的性能,再考虑是否需要记忆化。
总结
周末学习了两天才勉强看完了一遍,对于 Ruby 语言的有一些高级特性还是比较吃力的,需要自己反反复复的看才能理解一二。不过好在也是有收获吧,没有白费自己的努力,特地总结一个精简版方便后面的童鞋学习。
另外这篇文章最开始是使用公司的文档空间创建的,发现 Markdown 虽然精简易于使用,但是功能性上比一些成熟的写文工具要差上很多,就比如对代码的支持吧,用公司的代码块还支持自定义标题、显示行号、是否能缩放、主题等一系列自定义的东西,写出来的东西也更加友好...
按照惯例黏一个尾巴:
欢迎转载,转载请注明出处!
简书ID:@我没有三颗心脏
github:wmyskxz