两个小例子带你词嵌入层学习入门——Keras版
转自:https://yq.aliyun.com/articles/221681
词嵌入提供了词的密集表示及其相对含义。最简单的理解就是:将词进行向量化表示,实体的抽象成了数学描述,就可以进行建模了。它们是对较简单的单词模型表示中使用的稀疏表示的改进。

Word嵌入可以从文本数据中学习,并在项目之间重用。它们也可以作为在文本数据上拟合神经网络的一部分。
在本教程中,你将学到如何使用Python与Keras来学习词嵌入。
完成本教程后,你将学会:
· 关于词嵌入的相关介绍,并且使用Keras通过嵌入层完成字嵌入。
· 如何在拟合神经网络时进行词嵌入。
· 如何将预先训练的词嵌入运用到神经网络中。
教程概述
本教程分为3部分; 他们是:
1. 词嵌入。
2. Keras嵌入层。
3. 学习嵌入的例子。
4. 使用预培训的GloVe嵌入示例。
1.词嵌入
词嵌入是使用密集向量表示来表示单词和文档的一类方法。这是对传统的袋型(bag-of-word)模型编码方案的改进,其中使用大的稀疏向量来表示每个单词或向量中的每个单词进行数字分配以表示整个词汇表。这些表示是稀疏的,因为词汇是广泛的,这样一个给定的单词或文档将由一个主要由零值组成的向量几何表示。
相反,在词嵌入中,词由密集向量表示,其中矢量表示单词投射到连续向量空间中。
一个单词在向量空间中的位置是从文本中学习的,并且基于使用该文本时的单词。在学习向量空间中的单词的位置称为嵌入位置。
从文本中学习词嵌入的两个流行方法包括:
· Word2Vec。
· GloVe。
除了这些精心设计的方法之外,词嵌入也可以作为深度学习模型的一部分。这可能是一种较慢的方法。
2.Keras嵌入层
Keras提供了一个嵌入层,可用于处理文本数据的神经网络。它要求输入数据进行整数编码,以便每个单词都由唯一的整数表示。该数据准备步骤可以使用提供有Keras的Tokenizer API来执行。
嵌入层使用随机权重初始化,并将学习所有数据集中词的嵌入。
它是一个灵活的层,可以以各种方式使用,如:
1.它可以单独使用来学习一个字嵌入,以后可以在另一个模型中使用。
2.它可以用作深度学习模型的一部分,其中嵌入与模型本身一起被学习。
3.它可以用于加载预训练的词嵌入模型,一种迁移学习。
嵌入层被定义为网络的第一个隐藏层。它必须指定3个参数:
它必须指定3个参数:
1.input_dim:这是文本数据中词汇的大小。例如,如果你的数据是整数编码为0-10之间的值,则词表的大小将为11个字。
2.output_dim:这是嵌入单词的向量空间的大小。它为每个单词定义了该层的输出向量的大小。例如,它可以是32或100甚至更大。根据你的问题来定。
3.input_length:这是输入序列的长度,正如你为Keras模型的任何输入层定义的那样。例如,如果你的所有输入文档包含1000个单词,则为1000。
例如,下面我们定义一个词汇量为200的嵌入层(例如,从0到199(包括整数)的整数编码单词),将词嵌入到32维的向量空间中,以及每次输入50个单词的输入文档。
e = Embedding(200, 32, input_length=50)
嵌入层的输出是一个二维向量,每个单词对应一个输入序列(输入文档)。如果希望连接密集层直接到嵌入层,必须首先压扁2D输出矩阵。
现在,我们来看看我们如何在实践中使用嵌入层。
3.学习嵌入的例子
我们定义一个小问题,我们有10个文本文档,每个文本文档都有一个关于学生作品的评论。这是一个简单的情绪分析问题,每个文本分类为正“1”或负“0”。
首先,我们将定义文档及其类标签。
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1,1,1,1,1,0,0,0,0,0]
接下来我们可以对每个文档进行整数编码,作为输入,嵌入层将具有整数序列。我们可以尝试其他更复杂的单词模型编码,如计数或TF-IDF。
Keras提供one_hot()函数,它创建每个单词的哈希值作为有效的整数编码。我们估计有50个词汇大小,这远远大于减少哈希函数碰撞概率所需的大小。如果你的词汇很多的话,我建议你使用这个函数。
# integer encode the documents
vocab_size = 50
encoded_docs = [one_hot(d, vocab_size) for d in docs]
print(encoded_docs)
序列具有不同的长度,并且Keras更喜欢被矢量化的所以输入具有相同的长度。我们将所有输入序列的长度设为4。再次,我们可以使用内置的Keras函数(在这种情况下为pad_sequences()来执行此操作。
# pad documents to a max length of 4 words
max_length = 4
padded_docs=pad_sequences(encoded_docs,maxlen=max_length, padding='post')
print(padded_docs)
我们现在可以将我们的嵌入层定义为神经网络模型的一部分。该嵌入具有50词汇及输入长度为4,我们将选择8尺寸的小嵌入空间。
该模型是一个简单的二进制分类模型。重要的是,嵌入层的输出将是4个向量,每个向量8个维度,每个单词一个。我们将其平坦化为一个32维度的向量,以传递到Dense输出层。
# fit the model
model.fit(padded_docs, labels, epochs=50, verbose=0)
# evaluate the model
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
print('Accuracy: %f' % (accuracy*100))
最后,我们可以训练和评估该分类模型。
# define the model
model = Sequential()
model.add(Embedding(vocab_size, 8, input_length=max_length))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary())
完整的代码清单如下:
from keras.preprocessing.text import one_hot
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.embeddings import Embedding
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1,1,1,1,1,0,0,0,0,0]
# integer encode the documents
vocab_size = 50
encoded_docs = [one_hot(d, vocab_size) for d in docs]
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
# define the model
model = Sequential()
model.add(Embedding(vocab_size, 8, input_length=max_length))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary())
# fit the model
model.fit(padded_docs, labels, epochs=50, verbose=0)
# evaluate the model
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
print('Accuracy: %f' % (accuracy*100))
运行示例首先打印整数编码的文档:
[[6, 16], [42, 24], [2, 17], [42, 24], [18], [17], [22, 17], [27, 42], [22, 24], [49, 46, 16, 34]]
然后打印每个文档的填充版本,使其均匀一致:
[[ 6 16 0 0]
[42 24 0 0]
[ 2 17 0 0]
[42 24 0 0]
[18 0 0 0]
[17 0 0 0]
[22 17 0 0]
[27 42 0 0]
[22 24 0 0]
[49 46 16 34]]
定义网络后,我们可以看到,如预期的那样,嵌入层的输出是4×8矩阵,并且由Flatten层压缩到32维向量。
______________________________________________________________
Layer (type) Output Shape Param #
===========================================================
embedding_1 (Embedding) (None, 4, 8) 400
______________________________________________________________
flatten_1 (Flatten) (None, 32) 0
______________________________________________________________
dense_1 (Dense) (None, 1) 33
===========================================================
Total params: 433
Trainable params: 433
Non-trainable params: 0
最后,查看训练模型的准确性,表明它完美地学习了训练数据集:
Accuracy: 100.000000
你可以将学习的权重从“嵌入”层中保存到文件中,以备以后在其他模型中使用。
你也可以使用此模型来对在测试数据集中看到的具有相同种类词汇表的其他文档进行分类。
接下来,我们来看看在Keras中加载一个预先训练的词嵌入。
4.使用预培训的GloVe嵌入示例
自然语言处理领域中常见的是学习,保存和汇嵌入。例如,GloVe方法背后的研究人员根据公共领域许可证在其网站上提供了一套预先训练有素的词汇嵌入。
· GloVe:Word表示的全局向量
嵌入式最小的包是822Mb,称为“glove.6B.zip”。它被训练在十万个词汇(词)的数据集上,词汇量为四十万字。有几种不同的嵌入矢量大小,包括50,100,200和300维。
你可以下载此嵌入式集合,此示例来自Keras项目中的示例:
pretrained_word_embeddings.py
下载和解压缩后,你将看到一些文件,其中之一是“glove.6B.100d.txt”,其中包含一个100维版本的嵌入。
如果你认真看文件,则会在每行上看到令牌(单词),后跟权重(100个数字)。例如,下面是嵌入的ASCII文本文件的第一行,显示“the”的嵌入。
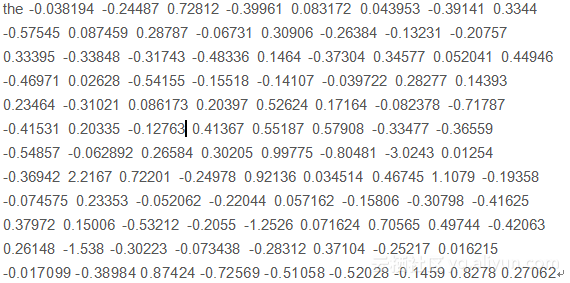
如前一节所述,第一步是定义,将其编码为整数,然后将序列设置为相同的长度。
在这种情况下,我们需要能够将单词映射到整数以及整数到单词。
Keras提供了一个标记生成器类,可以配合训练数据,可以将文本转换为序列,通过调用texts_to_sequences()的方法标记生成器的类,并提供访问字的字典映射到整数在word_index属性。
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1,1,1,1,1,0,0,0,0,0]
# prepare tokenizer
t = Tokenizer()
t.fit_on_texts(docs)
vocab_size = len(t.word_index) + 1
# integer encode the documents
encoded_docs = t.texts_to_sequences(docs)
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
接下来,我们需要将整个GloVe字嵌入文件作为字嵌入数组的字典加载到内存中。
# load the whole embedding into memory
embeddings_index = dict()
f = open('glove.6B.100d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Loaded %s word vectors.' % len(embeddings_index))
这个过程很慢。接下来,我们需要为训练数据集中的每个单词创建一个嵌入矩阵。我们可以通过枚举Tokenizer.word_index中的所有唯一的字,并从加载的GloVe嵌入中定位嵌入权重向量。
# create a weight matrix for words in training docs
embedding_matrix = zeros((vocab_size, 100))
for word, i in t.word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
现在我们可以像以前那样定义我们的模型,训练和评估。
关键区别是嵌入层可以用GloVe字嵌入权重进行迁移。我们选择了100维版本,因此嵌入层必须用output_dim定义为100。最后,我们不更新此模型中学习的单词权重,因此我们将将模型的可训练属性设置为False。
e= Embedding(vocab_size, 100, weights=[embedding_matrix], input_length=4, trainable=False)
完整的工作示例如下所示:
from numpy import asarray
from numpy import zeros
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Embedding
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1,1,1,1,1,0,0,0,0,0]
# prepare tokenizer
t = Tokenizer()
t.fit_on_texts(docs)
vocab_size = len(t.word_index) + 1
# integer encode the documents
encoded_docs = t.texts_to_sequences(docs)
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
# load the whole embedding into memory
embeddings_index = dict()
f = open('../glove_data/glove.6B/glove.6B.100d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Loaded %s word vectors.' % len(embeddings_index))
# create a weight matrix for words in training docs
embedding_matrix = zeros((vocab_size, 100))
for word, i in t.word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
# define model
model = Sequential()
e = Embedding(vocab_size, 100, weights=[embedding_matrix], input_length=4, trainable=False)
model.add(e)
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary())
# fit the model
model.fit(padded_docs, labels, epochs=50, verbose=0)
# evaluate the model
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
print('Accuracy: %f' % (accuracy*100))
这运行起来时间可能会很长。运行结果:
[[6, 2], [3, 1], [7, 4], [8, 1], [9], [10], [5, 4], [11, 3], [5, 1], [12, 13, 2, 14]]
[[ 6 2 0 0]
[ 3 1 0 0]
[ 7 4 0 0]
[ 8 1 0 0]
[ 9 0 0 0]
[10 0 0 0]
[ 5 4 0 0]
[11 3 0 0]
[ 5 1 0 0]
[12 13 2 14]]
Loaded 400000 word vectors.
______________________________________________________________
Layer (type) Output Shape Param #
===========================================================
embedding_1 (Embedding) (None, 4, 100) 1500
______________________________________________________________
flatten_1 (Flatten) (None, 400) 0
______________________________________________________________
dense_1 (Dense) (None, 1) 401
===========================================================
Total params: 1,901
Trainable params: 401
Non-trainable params: 1,500
______________________________________________________________
Accuracy: 100.000000
在实践中,我鼓励你尝试使用固定的预训练嵌入学习,因为它涉及到的东西更全面。
进一步阅读
如果你想了解更深入,本部分将提供有关该主题的更多资源。
1.Word嵌入维基百科
2.Keras嵌入层API
3.在2016年的Keras模型中使用预先训练的词嵌入
4.在Keras中使用预先训练的GloVe嵌入的示例
5.GloVe嵌入
6.词汇嵌入及其与分布式语义模型的连接概述,2016年
7.2014年深度学习,NLP和表示