要更好地理解C++的多态性,我们需要弄清楚函数覆盖的调用机制,因此,首先我们介绍一下函数的覆盖。
1. 函数的覆盖
我们先看一个例子:
例1- 1
#include
class animal
{
public:
void sleep()
{
cout < < "animal sleep " < }
void breathe()
{
cout < < "animal breathe " < }
};
class fish:public animal
{
public:
void breathe()
{
cout < < "fish bubble " < }
};
void main()
{
fish fh;
animal *pAn=&fh;
pAn-> breathe();
}
注意,在例1-1的程序中没有定义虚函数。考虑一下例1-1的程序执行的结果是什么?
答案是输出:animal breathe
在类fish中重写了breathe()函数,我们可以称为函数的覆盖。在main()函数中首先定义了一个fish对象fh,接着定义了一个指向animal的指针变量pAn,将fh的地址赋给了指针变量pAn,然后利用该变量调用pAn-> breathe()。许多学员往往将这种情况和C++的多态性搞混淆,认为fh实际上是fish类的对象,应该是调用fish类的breathe(),输出“fish bubble”,然后结果却不是这样。下面我们从两个方面来讲述原因。
1、 编译的角度
C++编译器在编译的时候,要确定每个对象调用的函数的地址,这称为早期绑定(early binding),当我们将fish类的对象fh的地址赋给pAn时,C++编译器进行了类型转换,此时C++编译器认为变量pAn保存就是animal对象的地址。当在main()函数中执行pAn-> breathe()时,调用的当然就是animal对象的breathe函数。
2、 内存模型的角度
我们给出了fish对象内存模型,如下图所示:
图1- 1 fish类对象的内存模型
我们构造fish类的对象时,首先要调用animal类的构造函数去构造animal类的对象,然后才调用fish类的构造函数完成自身部分的构造,从而拼接出一个完整的fish对象。当我们将fish类的对象转换为animal类型时,该对象就被认为是原对象整个内存模型的上半部分,也就是图1-1中的“animal的对象所占内存”。那么当我们利用类型转换后的对象指针去调用它的方法时,当然也就是调用它所在的内存中的方法。因此,出现图2.13所示的结果,也就顺理成章了。
2. 多态性和虚函数
正如很多学员所想,在例1-1的程序中,我们知道pAn实际指向的是fish类的对象,我们希望输出的结果是鱼的呼吸方法,即调用fish类的breathe方法。这个时候,就该轮到虚函数登场了。
前面输出的结果是因为编译器在编译的时候,就已经确定了对象调用的函数的地址,要解决这个问题就要使用迟绑定(late binding)技术。当编译器使用迟绑定时,就会在运行时再去确定对象的类型以及正确的调用函数。而要让编译器采用迟绑定,就要在基类中声明函数时使用virtual关键字(注意,这是必须的,很多学员就是因为没有使用虚函数而写出很多错误的例子),这样的函数我们称为虚函数。一旦某个函数在基类中声明为virtual,那么在所有的派生类中该函数都是virtual,而不需要再显示的声明为virtual。
下面修改例1-1的代码,将animal类中的breathe()函数声明为virtual,如下:
例1- 2
#include
class animal
{
public:
void sleep()
{
cout < < "animal sleep " < }
virtual void breathe()
{
cout < < "animal breathe " < }
};
class fish:public animal
{
public:
void breathe()
{
cout < < "fish bubble " < }
};
void main()
{
fish fh;
animal *pAn=&fh;
pAn-> breathe();
}
大家可以再次运行这个程序,你会发现结果是“fish bubble”,也就是根据对象的类型调用了正确的函数。
那么当我们将breathe()声明为virtual时,在背后发生了什么呢?
编译器在编译的时候,发现animal类中有虚函数,此时编译器会为每个包含虚函数的类创建一个虚表(即vtable),该表是一个一维数组,在这个数组中存放每个虚函数的地址。对于例1-2的程序,animal和fish类都包含了一个虚函数breathe(),因此编译器会为这两个类都建立一个虚表,如下图所示:
图1- 2 animal类和fish类的虚表
那么如何定位虚表呢?编译器另外还为每个类提供了一个虚表指针(即vptr),这个指针指向了对象的虚表。在程序运行时,根据对象的类型去初始化vptr,从而让vptr正确的指向所属类的虚表,从而在调用虚函数时,就能够找到正确的函数。对于例1-2的程序,由于pAn实际指向的对象类型是fish,因此vptr指向的fish类的vtable,当调用pAn-> breathe()时,根据虚表中的函数地址找到的就是fish类的breathe()函数。
正是由于每个对象调用的虚函数都是通过虚表指针来索引的,也就决定了虚表指针的正确初始化是非常重要的。换句话说,在虚表指针没有正确初始化之前,我们不能够去调用虚函数。那么虚表指针在什么时候,或者说在什么地方初始化呢?
答案是在构造函数中进行虚表的创建和虚表指针的初始化。还记得构造函数的调用顺序吗,在构造子类对象时,要先调用父类的构造函数,此时编译器只“看到了”父类,并不知道后面是否后还有继承者,它初始化父类的虚表指针,该虚表指针指向父类的虚表。当执行子类的构造函数时,子类的虚表指针被初始化,指向自身的虚表。对于例2-2的程序来说,当fish类的fh对象构造完毕后,其内部的虚表指针也就被初始化为指向fish类的虚表。在类型转换后,调用pAn-> breathe(),由于pAn实际指向的是fish类的对象,该对象内部的虚表指针指向的是fish类的虚表,因此最终调用的是fish类的breathe()函数。
要注意:对于虚函数调用来说,每一个对象内部都有一个虚表指针,该虚表指针被初始化为本类的虚表。所以在程序中,不管你的对象类型如何转换,但该对象内部的虚表指针是固定的,所以呢,才能实现动态的对象函数调用,这就是C++多态性实现的原理。
总结(基类有虚函数):
1、 每一个类都有虚表。
2、 虚表可以继承,如果子类没有重写虚函数,那么子类虚表中仍然会有该函数的地址,只不过这个地址指向的是基类的虚函数实现。如果基类3个虚函数,那么基类的虚表中就有三项(虚函数地址),派生类也会有虚表,至少有三项,如果重写了相应的虚函数,那么虚表中的地址就会改变,指向自身的虚函数实现。如果派生类有自己的虚函数,那么虚表中就会添加该项。
3、 派生类的虚表中虚函数地址的排列顺序和基类的虚表中虚函数地址排列顺序相同。
3. VC视频第三课this指针说明
我在论坛的VC教学视频版面发了帖子,是模拟MFC类库的例子写的,主要是说明在基类的构造函数中保存的this指针是指向子类的,我们在看一下这个例子:
例1- 3
#include
class base;
base * pbase;
class base
{
public:
base()
{
pbase=this;
}
virtual void fn()
{
cout < < "base " < }
};
class derived:public base
{
void fn()
{
cout < < "derived " < }
};
derived aa;
void main()
{
pbase-> fn();
}
我在base类的构造函数中将this指针保存到pbase全局变量中。在定义全局对象aa,即调用derived aa;时,要调用基类的构造函数,先构造基类的部分,然后是子类的部分,由这两部分拼接出完整的对象aa。这个this指针指向的当然也就是aa对象,那么我们main()函数中利用pbase调用fn(),因为pbase实际指向的是aa对象,而aa对象内部的虚表指针指向的是自身的虚表,最终调用的当然是derived类中的fn()函数。
在这个例子中,由于我的疏忽,在derived类中声明fn()函数时,忘了加public关键字,导致声明为了private(默认为private),但通过前面我们所讲述的虚函数调用机制,我们也就明白了这个地方并不影响它输出正确的结果。不知道这算不算C++的一个Bug,因为虚函数的调用是在运行时确定调用哪一个函数,所以编译器在编译时,并不知道pbase指向的是aa对象,所以导致这个奇怪现象的发生。如果你直接用aa对象去调用,由于对象类型是确定的(注意aa是对象变量,不是指针变量),编译器往往会采用早期绑定,在编译时确定调用的函数,于是就会发现fn()是私有的,不能直接调用。:)
许多学员在写这个例子时,直接在基类的构造函数中调用虚函数,前面已经说了,在调用基类的构造函数时,编译器只“看到了”父类,并不知道后面是否后还有继承者,它只是初始化父类的虚表指针,让该虚表指针指向父类的虚表,所以你看到结果当然不正确。只有在子类的构造函数调用完毕后,整个虚表才构建完毕,此时才能真正应用C++的多态性。换句话说,我们不要在构造函数中去调用虚函数,当然如果你只是想调用本类的函数,也无所谓。
4. 参考资料:
1、文章《在VC6.0中虚函数的实现方法》,作者:backer ,网址:
http://www.mybole.com.cn/bbs/dispbbs.asp?boardid=4&id=1012&star=1
2、书《C++编程思想》 机械工业出版社
5. 后记
本想再写详细些,发现时间不够,总是有很多事情,在加上水平也有限,想想还是以后再说吧。不过我相信,这些内容也能够帮助大家很好的理解了。也欢迎网友能够继续补充,大家可以鼓动鼓动backer,让他从汇编的角度再给一个说明,哈哈,别说我说的。
///另//
其实这里涉及到的一个概念就是C++ Object Model。从 我们可以看出,具体的实现是和具体的编译器相关的,而且随着时间的推移,同一个编译器也有所改变。我们所作的很多都是猜测,或者局限于具体的编译器,换个编译器可能就有所不同。
建议:如果想对C++ Object Model有全面的了解,看
如果想了解Visual C++是怎么实现C++ Object Model的,这里有一篇文章: ,文章的作者就是写Viual C++ Compiler的作者,应该比较权威。我用Visual C++测试了一下,具体的实现也确实和文章所说的一致。
一直搞不懂c++多态性是何意,今天偶遇一篇讲解,觉得不错,拿来研究研究。
多态性可以简单地概括为“一个接口,多种方法”,程序在运行时才决定调用的函数,它是面向对象编程领域的核心概念。多态(polymorphisn),字面意思多种形状。
C++多态性是通过虚函数来实现的,虚函数允许子类重新定义成员函数,而子类重新定义父类的做法称为覆盖(override),或者称为重写。(这里我觉得要补充,重写的话可以有两种,直接重写成员函数和重写虚函数,只有重写了虚函数的才能算作是体现了C++多态性)而重载则是允许有多个同名的函数,而这些函数的参数列表不同,允许参数个数不同,参数类型不同,或者两者都不同。编译器会根据这些函数的不同列表,将同名的函数的名称做修饰,从而生成一些不同名称的预处理函数,来实现同名函数调用时的重载问题。但这并没有体现多态性。
多态与非多态的实质区别就是函数地址是早绑定还是晚绑定。如果函数的调用,在编译器编译期间就可以确定函数的调用地址,并生产代码,是静态的,就是说地址是早绑定的。而如果函数调用的地址不能在编译器期间确定,需要在运行时才确定,这就属于晚绑定。
那么多态的作用是什么呢,封装可以使得代码模块化,继承可以扩展已存在的代码,他们的目的都是为了代码重用。而多态的目的则是为了接口重用。也就是说,不论传递过来的究竟是那个类的对象,函数都能够通过同一个接口调用到适应各自对象的实现方法。
最常见的用法就是声明基类的指针,利用该指针指向任意一个子类对象,调用相应的虚函数,可以根据指向的子类的不同而实现不同的方法。如果没有使用虚函数的话,即没有利用C++多态性,则利用基类指针调用相应的函数的时候,将总被限制在基类函数本身,而无法调用到子类中被重写过的函数。因为没有多态性,函数调用的地址将是一定的,而固定的地址将始终调用到同一个函数,这就无法实现一个接口,多种方法的目的了。
笔试的题目
#include class A { public: void foo() { printf("1"); } virtual void fuu() { printf("2"); } }; class B:public A { public: void foo() { printf("3"); } void fuu() { printf("4"); } }; int main() { A a; B b; A *p = &a; p->foo(); p->fuu(); p = &b; p->foo(); p->fuu(); return 0; } 第一个p->foo()和p->fuu()都很好理解,本身是基类指针,指向的又是基类对象,调用的都是基类本身的函数,因此输出结果就是1、2。
第二个p->foo()和p->fuu()则是基类指针指向子类对象,正式体现多态的用法,p->foo()由于指针是个基类指针,指向是一个固定偏移量的函数,因此此时指向的就只能是基类的foo()函数的代码了,因此输出的结果还是1。而p->fuu()指针是基类指针,指向的fuu是一个虚函数,由于每个虚函数都有一个虚函数列表,此时p调用fuu()并不是直接调用函数,而是通过虚函数列表找到相应的函数的地址,因此根据指向的对象不同,函数地址也将不同,这里将找到对应的子类的fuu()函数的地址,因此输出的结果也会是子类的结果4.
笔试的题目中还有一个另类测试方法。即
B *ptr = (B *)&a; ptr->foo(); ptr->fuu();
问这两调用的输出结果。这是一个用子类的指针去指向一个强制转换为子类地址的基类对象。结果,这两句调用的输出结果是3,2。
并不是很理解这种用法,从原理上来解释,由于B是子类指针,虽然被赋予了基类对象地址,但是ptr->foo()在调用的时候,由于地址偏移量固定,偏移量是子类对象的偏移量,于是即使在指向了一个基类对象的情况下,还是调用到了子类的函数,虽然可能从始到终都没有子类对象的实例化出现。
而ptr->fuu()的调用,可能还是因为C++多态性的原因,由于指向的是一个基类对象,通过虚函数列表的引用,找到了基类中foo()函数的地址,因此调用了基类的函数。由此可见多态性的强大,可以适应各种变化,不论指针是基类的还是子类的,都能找到正确的实现方法。
2.虚函数是一个成员函数,该成员函数在基类内部声明并且被派生类重新定义。
从本质上讲,虚函数实现了“一个接口,多种方法”的理念,而这种理念是多态性的基础!
如果基类和派生类都定义了"相同名称的成员函数",那么通过对象指针调用成员函数时,到底调用哪个函数,要根据该指针的原始类型而定,而不是视指针实际所指的对象类型而定。
如果用了虚函数,这些情况就不存在了。
虚函数的总结:
1.如果想在派生类中重新定义一个成员函数,那么就应该在基类中把该函数设为"virtual"。
2.以单一指令调用不同函数(这句话不好理解,下面会解释),这种性质就是"多态"。
3.虚函数是C++语言的多态性质和动态绑定的关键。
4.既然抽象类中的虚函数不打算被调用,我们就不应该定义它,应该把它设为纯虚函数(在函数声明后加上"=0"即可)。
5.拥有纯虚函数的类叫做抽象类,不能产生出对象实例,但是可以拥有指向抽象类的指针,以便于操作抽象类的各个派生类。
6.虚函数派生下去仍是虚函数,而且可以省略virtual关键词。
指针 数组 和 引用。
1 char word[][9]={}; 和 char * word[]{};相比,后者更紧凑和节省空间。
2 char word[9] 除了两种情况:sizeof()和 &运算外,程序中任何对数组名的引用等价与一个常量指针,该常量指针指向数组第一元素,并且类型匹配。sizeof()返回数组大小,&返回数组常量指针的地址,而非数组首元素地址。
3 char word[9] .数组的下标运算等价于间接引用。极端情况可以解释之中现象:2 [word]== *{2+word}==*{word+2}==word[2];
4 指针的间接引用操作比数组下标运算更有效率,因为下标运算每次都必有一次乘法运算。
5 char (*p)[5] 为一个指向有5个元素的字符数组的指针,因为【】运算比*运算优先级要高,所以加括号。相对应的声明方式为:
char* p[5]为一个指针数组,每个元素为一个字符指针。
6 char word[3][4];中 ,word为等价为一个 char(*)[4];同样对于多维数组的下标运算等价于对应的指针的解引用。
7 数组的声明必分配对应内存空间,指针声明则最多只分配指针内存空间,有时甚至连指针内存空间都不分配。
8 数组参数的传递仅仅传递的是 常量指针,与其他的变量的传递没有区别,即所谓的传值传递。但对应数组的操作,可以把他认为是传地址操作。这一点于指针有些许不同,在于指针有时需要而且可以改变自身。这一点尤其要区别于C++中的引用传递。
9 char word[3][4] 是C中多维数组声明方式。不同于一些常用的其他语言中的语法,char word[3,4]会被解释为 char word[4],因为中间会被认为是逗号表达式。
参考:《c和指针》
1 引用是C++中的概念,C中没有引用,而只有&操作,即取地址符,其必须作用于一个左值。
2 引用是变量的一个别名,即建立引用并不会导致新内存的分配,引用在初始化时必须存在一个对应的被引用的内存对象,且此引用关系建立后,引用不能再被改变,而所引用的变量是可以改变的。
3 引用在参数传递中使用,降低了传值传递的消耗。如果引用作为函数的返回值,那么函数可以作为一个左值来使用。这一点在C++的流操作部分很常见。
对于数组名和对数组名取地址
对于数组名和对数组名取地址
前些日子看了一个帖子,其中有个例子如下:
int a[5]={1,2,3,4,5};
int *p1=(int*)(&a+1);
int *p2=(int*)((int)a+1);
int *p3=(int*)(&a)+1;
// p3=p3+1;
printf("%x,%x,%x",p1[-1],*p2,p3[-1]);
执行结果为5,2000000,1。对于结果5还是比较纠结。看了一下网上的帖子和几本书,总结了一下。
首先说一下关于对数组名取地址:
关于对数组名取地址的问题,由于数组名是右值,本来&array 是不合法的,早期不少编译器就是指定&array 是非法的,但后来C89/C99认为数组符合对象的语义,对一个对象取地址是合理的,因此,从维护对象的完整性出发,也允许&array 。只不过,&array 的意义并非对一个数组名取地址,而是对一个数组对象取地址,也正因为如此,array 才跟&array 所代表的地址值一样,同时sizeof(array )应该跟sizeof(&array )一样,因为sizeof(&array )代表取一个数组对象的长度。
要注意到 array 和 &array 的类型是不同的。array为一个指针,而&array是指向数组int [100]的指针。array 相当于 &array[0],而 &array 是一个指向 int[100] 的指针,类型是 int(*)[100]。
另外从步长的角度分析这个问题
执行如下语句:
printf("array=%p, array+1=%p/n", array, array+1);
printf("&array=%p, &array+1=%p/n", &array, &array+1);
结果为:
array=0012FDF0, array+1=0012FDF4 //+sizeof(int)
&array=0012FDF0, &array+1=0012FF80 //+sizeof(&array)
在《C专家编程》书中关于数组一章P203,有如下解释:
无论指针还是数组,在连续的内存地址上移动时,编译器都必须计算每次前进的步长。
编译器自动把下标值调整到数组元素大小,对起始地址进行加法操作之前,编译器都会负责计算每次增加的步长,这就是为什么指针类型总是有类型限制,每个指针只能指向一种类型的原因所在,因为编译器需要知道对指针进行解除引用操作时应该取几个字节,以及每个小标的步长应取几个字节。
另外步长的自动调整还和上下语句相关:
int *p3=(int*)(&a);
p3=p3+1;
首先对P3指针变量赋初值,指向数组int [5]的指针,然后对指针进行加一的操作,其中P3定义为一个指向int类型的指针,因此最终P3的值等价P3+sizeof(int)
int *p3=(int*)(&array+1);
&array+1,步长为1,其中步长的长度和&array的类型匹配,即&array是指向数组int [100]的指针,所以&array+1等价为&array+sizeof(&array)
最终p1[-1]等价为*(P1-1),因此等价为第二个int [5]的数据首地址(并不存在第二个数组显然当前指针已经越界了,另外数组元素在内存中是连续存贮的)减去一个为sizeof(int)的步长,所以指向了第一个数组的最后1个元素。
关于edian大小端模式
最近看了一些关于大小端的帖子,顺便搜集和归纳了一下这方面的资料。
一、关于edian的由来:
端模式(Endian)的这个词出自《格列佛游记》。这本书根据将鸡蛋敲开的方法不同将所有的人分为两类,从大头头开始将鸡蛋敲
开的人被归为Big Endian,从小头开始将鸡蛋敲开的人被归为Littile Endian。小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。
在计算机中,Endian表示多字节数中各个字节在存储器中存放的顺序。也就是我们的字节存储的两种机制。
二、关于大小端模式
在了解大小端之前先了解一下数据的高低位:
如果我们有一个32位无符号整型0x12345678,那么高位是什么,低位又是什么呢?。在十进制中我们都说靠左边的是高位,靠右边的是低位,在其他进制也是如此。就拿0x12345678来说,从高位到低位的字节依次是0x12、0x34、0x56和0x78。有些书或
者文章中称低位字节为最低有效位LSB,高位字节为最高有效位MSB。
MSB:Most Significant Bit ------- 最高有效位
LSB:Least Significant Bit ------- 最低有效位
所谓的大端模式(Big-endian),是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中,这样的存储模式
有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
例如,对于一个32为的int整数变量据OX12345678 。该变量在内存中存储的地址从OX2000开始,其在内存中的存储如下:
地址 数据
0X2000 OX12
OX2001 OX34
0X2002 0X56
0X2003 0X78
所谓的小端模式(Little-endian),是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
例如,对于一个32为的int整数变量据OX12345678 。该变量在内存中存储的地址从OX2000开始,其在内存中的存储如下:
地址 数据
0X2000 OX78
OX2001 OX56
0X2002 0X34
0X2003 0X12
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小 端存储模式。
特别是在跨系统或者跨平台中实现字节的操作就需要弄明白两个系统或者平台所用的字节存贮的机制了。
小端模式和大端模式的优缺点
小端模式 :强制转换数据不需要调整字节内容。
大端模式 :符号位的判定固定为第一个字节。
那么在跨平台或网络程序中如何实现字节序的转换呢?这个通过C语言的移位操作很容易实现,例如下面的宏:
这个通过C语言的移位操作很容易实现
Big-Endian转换成Little-Endian如下:
#define BigtoLittle16(A) ((((uint16)(A) & 0xff00) >> 8) | /
(((uint16)(A) & 0x00ff) << 8))
#define BigtoLittle32(A) ((((uint32)(A) & 0xff000000) >> 24) | /
(((uint32)(A) & 0x00ff0000) >> 8) | /
(((uint32)(A) & 0x0000ff00) << 8) | /
(((uint32)(A) & 0x000000ff) << 24))
三、用代码进行检测
1:
#include
int check_edian(void)
{
int i = 0x1234;
char * p = (char*)&i;
if( p[0] == 0x34 && p[1] == 0x12 )
return 1;//系统是Little-Endian
return 0;//系统是Big-Endian
}
void main()
{
cout< }
如果小端方式(i占至少两个字节的长度)则i所分配的内存最小地址那个字节中就存着1,其他字节是0.大端的话则1在i的最高地址字节处存放,char是一个字节,所以强制将char型量p指向i则p指向的一定是i的最低地址,那么就可以判断p中的值是不是1来确定是
不是小端
2:
由于联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性就可以轻松地获得了CPU对内存采用Little-endian还是
Big-endian模式读写。
利用了union的空间分配原则。union空间必须足够大,以保存里面类型中的最大的一种,这些类型中的任何一种都可赋给union,但必
须保证是一致的,即读取的类型必须是最近一次存入的类型。 如果保存的类型与读取的类型不一致,其结果取决于具体的实现。
例如:
#include
int check_edian(void)
{
union {
unsigned int a;
unsigned char b;
}c;
c.a = 0x0001;
return (c.b == 1);
/*return 1 : little-endian, return 0:big-endian*/
}
void mian()
{
cout< }
这个解法涉及到Union的内存分配模式。
Union的大小为其内部所有变量的最大值,并且按照类型最大值的整数倍进行内存对齐.
举例中union分配的内存按照int分配4个字节,如果是小端模式则存放的方式为
地址A
------------------------------------
|A |A+1 |A+2 |A+3 | 地址
|0x01 |0x00 |0x00 |0x00 | int a;
-------------------------------------
|A | 地址
| c.b | char b;
---------
如果是大端如何存储c.a的呢?
地址A
------------------------------------------
|A |A+1 |A+2 |A+3 | 地址
|0x00 |0x00 |0x00 |0x01 | int a;
------------------------------------------
|A | 地址
| c.b | char b;
---------
因此就可以通过查看char b==1来判断大小端了。
覆盖,隐藏,重载
由于之前一直在用C编写代码,最近工作中需要用到C++编写代码,之前对C++中重写、重载、隐藏这3个概念不甚了解,为了整明白这三个概念的定义和作用的,花了半天时间在网上搜索了一些资料,看了一下关于C++方面的书(《C++ Primer plus》,《高质量C++编程指南》),算是对这三个概念有了一定的了解。
1、重载
重载就是简单的复用一个已经存在的名字,来操作不用的类型。这个名字可以是一个函数名,也可以是一个操作符。由于主要是针对函数的重载,所以对于操作符的重载在后续进行解释。
虽然可以通过默认参数的方式可以使用不同数据的参数可以调用同一个函数,但是对于不同参数类型的操作,可就是爱莫能助了。为了实现同一个函数来实现不同类型的操作,这就需要C++中的一个重要的特性:重载。
实现函数重载的主要条件是:
1)首先发生重载的函数需要在相同的作用域中;
2)函数名称需要相同;
3)函数的参数类型不相同;
4)与virtual关键字无关;
下面的示例中,Base类中的 getIndex(int x)和getIndex(float x)为相互重载,与virtual无关。当调用getIndex函数的时候根据传入的参数选择不同的函数进行执行。
#include
#include
using namespace std;
class Base
{
public:
virtual void getIndex(int x)
{
cout<<"Base x="< }
virtual void getIndex(float x)
{
cout<<"Base x="< }
};
class Derived:public Base
{
public:
virtual void Derived(string x)
{
cout<<"Derived x="< }
};
int main()
{
Base base_obj;
base_obj.getIndex(2.14f);//Base float x=2.14
base_obj.getIndex(214); //Base int x=214
return 0;
}
由于getIndex(int x)和getIndex(float x)为相互重载。其中base_obj.getIndex(2.14f)函数由于参数为float类型,因此调用getIndex(float x)输出Base float x=2.14,而base_obj.getIndex(214)函数参数为int类型,因此调用getIndex(int x),输出Base int x=214。
PS:对第一个条件进行说明,为什么只有在相同的作用域中才能形成重载?虽然Base类和 Derived类在同一个文件中,但是在各自类的作用范围中定义了处理不同类型的getIndex函数,只有Base类中的两个函数互为重载。而Derived中定义的getIndex,虽然函数参数为string,但由于在不同的作用范围中因此不能和Base类中的函数形成重载。
2、重写
有时候希望同一个方法在基类和派生类中表现不同的行为。也就是说通过不同的对象调用,来实现不同的功能。这就是面向对象中的多态,同一个方法在不同的上下文中表现出多种形态。重写的时候就引入了virtual,将需要在派生类中重写的函数在基类中声明为virtual类型的。
实现重写的特性
1)在基类中将需要重写的函数声明为virtual;
2)派生类类和基类中的函数的名称相同;
3)函数的参数类型相同;
4)在不同的作用范围中;(基类和派生类中)
#include
#include
using namespace std;
class Base
{
public:
virtual void getIndex(int x)
{
cout<<"Base int x="< }
virtual void getIndex(float x)
{
cout<<"Base float x="< }
};
class Derived:public Base
{
public:
void getIndex(float x)
{
cout<<"Derived x="< }
};
int main()
{
Derived derived_obj;
Derived *pd;
Base *pb;
pd = &derived_obj;
pb = &derived_obj;
pd->getIndex(2.14f);//Derived x=2.14
pb->getIndex(2.14f);//Derived x=2.14
return 0;
}
如上述代码,其中Derived类继承Base类,由于在Base类中的getIndex(float x)函数声明为virtual,并且基类和派生类中的函数名称、参数类型都相同,因此在派生类Derived中重写了父类中的函数。所以无论是通过指向基类还是派生类的指针调用,最终还是调用的派生类中定义的getIndex(float x),输出“Derived x=2.14”。
PS:如果需要在派生类中重现实现基类中的方法,通常将基类中的该方法声明为virtual,这样当最终访问的时候无论是通过指向基类的还是指向派生类的指针来调用该方法是,最终会根据对象类型来访问。如上述代码中pd,pb分别为指向派生类和基类的指针,但最终来选择getIndex函数的版本时,依据对象derived_obj的类型来选择方法的版本。
3)隐藏
隐藏通常是指函数或者类被同名的函数或者方法隐藏了。派生类中的函数屏蔽了基类的同名函数。
隐藏的条件:
1)基类和派生类中函数名称相同,但是参数的类型不同,无论基类中函数是否声明为virtual,派生类中的函数将屏蔽基类中定义的方法;
2)基类和派生类中函数名称相同,参数类型也相同,如果基类中函数未声明为vitrual,则派生类中的函数将屏蔽基类中定义的方法;
#include
#include
using namespace std;
class Base
{
public:
virtual void getIndex(int x)
{
cout<<"Base getindex x="< }
void printer(int x)
{
cout<<"Base print x="< }
};
class Derived:public Base
{
public:
virtual void getIndex(float x)
{
cout<<"Derived float x="< }
void printer(int x)
{
cout<<"Derived print x="< }
};
int main()
{
Derived derived_obj;
Derived *pd;
Base *pb;
pd = &derived_obj;
pb = &derived_obj;
pb->getIndex(2.14f);//Base getindex x=2
pd->getIndex(2.14f);//Derived float x=2.14
pb->printer(214);//Base print x=214
pd->printer(214);//Derived print x=214
return 0;
}
如上述代码中,在基类和派生类中getIndex函数虽然函数的名称相同和参数类型不同,但是由于在不同的作用范围中不能构成重载,因此Derived::getIndex屏蔽了Base::getIndex方法。由于参数类型不同,因此隐藏与基类中是否声明为virtual无关。
在基类和派生类中printer函数虽然函数的名称和函数的参数均相同,似乎和可以满足重写的条件,但是由于在基类中没有声明为virtual因此不能构成重写,所以Derived::getIndex屏蔽了Base::getIndex方法。
linux系统调用和库函数调用的区别
Linux下对文件操作有两种方式:系统调用(system call)和库函数调用(Library functions)。可以参考《Linux程序设计》(英文原版为《Beginning Linux Programming》,作者是Neil Matthew和Richard Stones)第三章: Working with files。系统调用实际上就是指最底层的一个调用,在linux程序设计里面就是底层调用的意思。面向的是硬件。而库函数调用则面向的是应用开发的,相当于应用程序的api,采用这样的方式有很多种原因,第一:双缓冲技术的实现。第二,可移植性。第三,底层调用本身的一些性能方面的缺陷。第四:让api也可以有了级别和专门的工作面向。
1、系统调用
系统调用提供的函数如open, close, read, write, ioctl等,需包含头文件unistd.h。以write为例:其函数原型为 size_t write(int fd, const void *buf, size_t nbytes),其操作对象为文件描述符或文件句柄fd(file descriptor),要想写一个文件,必须先以可写权限用open系统调用打开一个文件,获得所打开文件的fd,例如 fd=open(\"/dev/video\", O_RDWR)。fd是一个整型值,每新打开一个文件,所获得的fd为当前最大fd加1。Linux系统默认分配了3个文件描述符值:0-standard input,1-standard output,2-standard error。
系统调用通常用于底层文件访问(low-level file access),例如在驱动程序中对设备文件的直接访问。
系统调用是操作系统相关的,因此一般没有跨操作系统的可移植性。
系统调用发生在内核空间,因此如果在用户空间的一般应用程序中使用系统调用来进行文件操作,会有用户空间到内核空间切换的开销。事实上,即使在用户空间使用库函数来对文件进行操作,因为文件总是存在于存储介质上,因此不管是读写操作,都是对硬件(存储器)的操作,都必然会引起系统调用。也就是说,库函数对文件的操作实际上是通过系统调用来实现的。例如C库函数fwrite()就是通过write()系统调用来实现的。
这样的话,使用库函数也有系统调用的开销,为什么不直接使用系统调用呢?这是因为,读写文件通常是大量的数据(这种大量是相对于底层驱动的系统调用所实现的数据操作单位而言),这时,使用库函数就可以大大减少系统调用的次数。这一结果又缘于缓冲区技术。在用户空间和内核空间,对文件操作都使用了缓冲区,例如用fwrite写文件,都是先将内容写到用户空间缓冲区,当用户空间缓冲区满或者写操作结束时,才将用户缓冲区的内容写到内核缓冲区,同样的道理,当内核缓冲区满或写结束时才将内核缓冲区内容写到文件对应的硬件媒介。
2、库函数调用
标准C库函数提供的文件操作函数如fopen, fread, fwrite, fclose, fflush, fseek等,需包含头文件stdio.h。以fwrite为例,其函数原型为size_t fwrite(const void *buffer, size_t size, size_t item_num, FILE *pf),其操作对象为文件指针FILE *pf,要想写一个文件,必须先以可写权限用fopen函数打开一个文件,获得所打开文件的FILE结构指针pf,例如pf=fopen(\"~/proj/filename\", \"w\")。实际上,由于库函数对文件的操作最终是通过系统调用实现的,因此,每打开一个文件所获得的FILE结构指针都有一个内核空间的文件描述符fd与之对应。同样有相应的预定义的FILE指针:stdin-standard input,stdout-standard output,stderr-standard error。
库函数调用通常用于应用程序中对一般文件的访问。
库函数调用是系统无关的,因此可移植性好。
由于库函数调用是基于C库的,因此也就不可能用于内核空间的驱动程序中对设备的操作。
※函数库调用 VS 系统调用
|
函数库调用
|
系统调用
|
| 在所有的ANSI C编译器版本中,C库函数是相同的 |
各个操作系统的系统调用是不同的 |
| 它调用函数库中的一段程序(或函数) |
它调用系统内核的服务 |
| 与用户程序相联系 |
是操作系统的一个入口点 |
| 在用户地址空间执行 |
在内核地址空间执行 |
| 它的运行时间属于“用户时间” |
它的运行时间属于“系统”时间 |
| 属于过程调用,调用开销较小 |
需要在用户空间和内核上下文环境间切换,开销较大 |
| 在C函数库libc中有大约300个函数 |
在UNIX中大约有90个系统调用 |
| 典型的C函数库调用:system fprintf malloc |
典型的系统调用:chdir fork write brk; |
说说计算机中的异常
开篇
异常这个名词应该大家都不陌生,很多人都听说过。系统调用知道吧?其实系统调用也是一种异常。但是具体的什么是异常呢?他在计算机中有什么作用?他是如何工作,如何被我们利用的?我想很多人都还不都是很清楚。、
了解异常有诸多好处,可以让你更好的理解操作系统和应用程序的交互,更好的理解并发等。
所以今天就简单的来说一下异常。
注:本博文图片来源《Computer system-A Programmer's Perspective》
什么是异常
为了便于理解,我就不按照书本来了啊,异常可以这样理解:
计算机执行一个连续的指令序列,如:a1,a2,a3,,,ak,这些指令执行的时候是顺序执行的,相邻的两条指令ak,ak+1在存储中也是相邻的,也就是说他们是一个平滑的指令流。
而有时候这种指令流会发生突变,也就是说相邻执行的两条指令ak,ak+1在存储器中是不相邻的。造成这种突变的可能有:跳转,函数调用,返回等。今天我们所讨论的异常,也是造成这种指令流突变的原因之一。
所以异常可以认为是指令顺序执行的时候,突然跳转到别的地方执行指令。
现在就可以来看相对专业的说法了:异常是控制流中的突变,用来相应处理器状态中的某些变化。
可以通过下图来更好的理解上述内容:
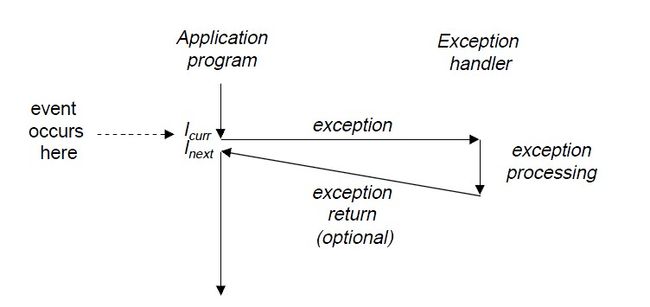
那么异常处理结束后计算机中的指令如何继续往下执行呢?根据触发异常的种类,会有三种情况:
1)处理程序将控制返回给当前指令I currr,即当事件发生时正执行的指令。
2)将控制返回给下一条指令,即如果没有发生异常的下一条指令。
3)终止发生异常的程序。
异常处理
现在应该基本搞懂什么是异常了吧,发生了异常,总不能就不管吧,呵呵,有异常总是要处理的。这个部分就简单的说一下异常处理。
按照上面所说的,异常是在指令顺序执行的时候由于某些突发情况指令跳到其他地方执行。注意上面说的是“跳到其他地方执行”所以说,异常处理也是通过固定的程序代码来实现的。至于具体的怎么实现,我们并不关心,这里要关注的是控制是如何从发生异常的程序跳转到处理程序的。
系统中为可能的每种异常都分配了一个唯一的非负数异常号。每个异常号记录了处理该异常的代码。这些数据被放在一个称为异常表的结构里,当系统初始化的时候会初始化这个表。所以当发生异常的时候,对应于异常表中的那个异常号,就能定位到具体的异常处理程序了。
下面是一个异常表:
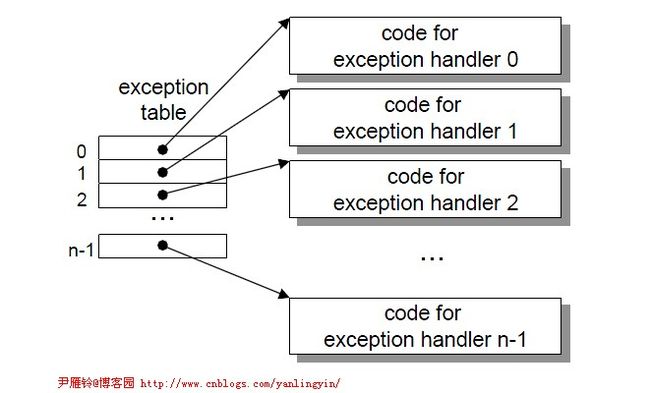
在系统运行时,如果发生一个异常,系统检测得到其异常号,通过异常号,就能确定要处理的异常,同时也确定了处理异常的程序地址。异常号是到异常表的一个索引,相当于一个异常号就对应于异常表中的一项。异常表的起始地址放在一个异常表基寄存器的特殊cpu寄存器里。下面是一个生成异常处理程序地址的过程:
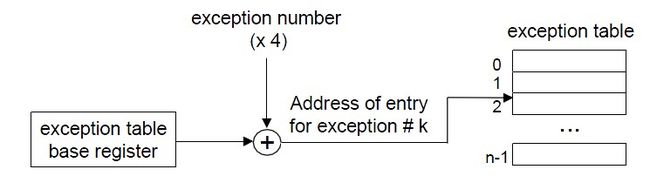
通过异常号和基址确定了异常表中的一个项,从而确定异常处理程序的地址。
异常的类别
什么?异常还有类别?。。。是的,在运行过程中会发生各种各样的异常,所以就把他们分为四类:中断(interrupt)陷阱(trap)故障(fault)终止(abort)
下面就简单的说一下吧:
中断:
中断是异步发生的,是来自处理器外部的I/O设备的信号的结果。为什么是异步呢?硬件中断不是由任何一条指令造成的,从这个意义上说是异步的。硬件中断的异常处理程序通常也叫中断处理程序。

如图中所示,中断处理程序完成时,他将控制返回给下一条指令(即如果没有发生中断,在控制流中当前指令之后的一条指令)结果是程序继续执行,就好像没发生中断一样。
陷阱和系统调用
系统调用应该很多人都知道,而且经常在用,其实系统调用也是异常的一种,他是”有意“的异常。
就像中断处理程序一样,陷阱处理程序将程序控制返回到下一条指令。陷阱最重要的作用是在用户程序和内核之间提供一个像过程调用一样的接口,叫做系统调用。
用户程序经常要像内核请求服务,比如读一个文件(read)创建一个进程(fork)加载以新的程序(execve)等。为了让用户程序实现这些功能,处理器提供了一条特殊的“system call n ”指令。执行system call 指令会导致一个到异常处理程序的陷阱,这个程序对参数n 进行解码,并调用适当的内核程序。
具体的过程如下图所示:
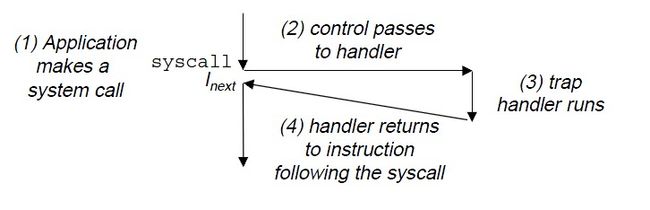
如图所示:陷阱处理程序将程序控制返回到下一条指令.
关于系统调用和函数调用的区别可参见前一篇文章:
linux系统调用和库函数调用的区别
故障:
故障由错误情况引起,它能够被故障处理程序修正。当故障发生时,处理器将控制转移给故障处理程序。如果能修复错误,返回到引起故障的指令,重新执行它,否则终止引起故障的程序(调用abort)。
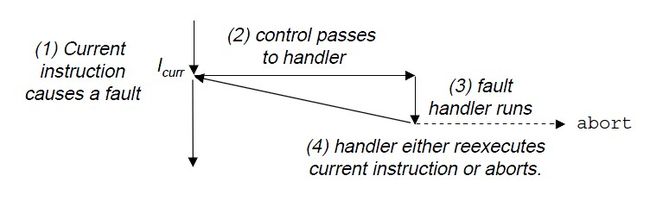
一个经典的故障处理程序是页缺异常。当引用到一个虚拟地址,而与该地址对应的物理页面不在存储器中,必须从磁盘中取出,就会发生故障。故障处理程序(这里是页缺处理程序)会将页面从磁盘中加载到内存中,把控制返回给引起故障的指令重新执行。当指令再次执行时,相应的物理页面已经在内存中了,指令便可以没有故障的运行。
终止:
终止是不可恢复的致命错误造成的结果,通常是一些硬件错误。终止处理程序不会吧控制返回给引起异常的程序,处理程序会将控制返回给一个abort,然后终止这个应用程序。

小结
这篇博文内容较少,理解起来也比较容易。异常在计算机中是很重要的一个概念,关于异常的东西还有很多需要学习。遇到不懂的东西,之前很喜欢google,把要搜的东西翻译为英文然后在美国的服务器搜,各种搜索。慢慢的觉得这种学习方式还是欠妥的,上网获取知识的速度确实是很快,可是知识的质量就参差不齐了,对于一个知识点的理解很难在网上找到满意的解(这个或许大家也感同身受吧)相反,看书获取知识相对慢一些,却能得到高质量的知识。所以当你对一系列的知识点模糊不清的时候,我觉的看书的最好的。当然了,看书得看经典书。何为经典书?我认为:1)在某方面的知识点全面。2)语言方面通俗易懂。3)合理的安排了学习顺序。
这篇博文参考了《深入理解计算机系统》,我是第二次看这个书,感觉还是很有收获。
数组和指针背后——内存角度
聊过数组和指针的区别,主要是对于数组和指针在内存中的访问方式加以区分,这篇博文则从更深层的角度剖析数组和指针的联系
如果你也对底层感兴趣、我向这篇文章会对你有所帮助,
什么时候数组和指针相同(When an Array Is a Pointer )
在实际应用中,他们可以互换的情形要大大多于不能互换的情形。首先再回顾一下声明和定义,(上一篇中有提到这里在深入一下)
声明本身还可以进一步分为三种情况:
1)外部数组的声明(external array)
2)数组的定义(它是声明的一种特殊情况,它分配内存空间,并可能提供一个初值)
3)函数参数的声明
所有作为函数参数的声明在编译时总是会转换为指针(指向数组第一个元素),而其他情况的声明,数组就是数组 ,指针就是指针
可以用如下的图来说明他们的关系:

稍微总结一下:
对于编译过程中数组会转化为指针的情况,数组和指针可以互换,比如:声明为函数参数的时候 fun(int a [])和fun(int *a )是等同的。因为编译的过程中fun(int a [])
中的数组会转化为指针形式,也就和fun(int *a )的效果一样了。
如果编译到时候数组不被当做指针处理,那么声明的时候不能等同。对于这种情况,数组和指针是不一样的的,在运行时的表示形式也不一样,并可能产生不同的代码。
对编译器而言,一个数组就是一个地址,一个指针就是地址的地址。
c语言标准对此做了如下说明:
1)An array name in an expression (in contrast with a declaration) is treated by the compiler as a pointer to the first element of the array
(paraphrase, ANSI C Standard, paragraph 6.2.2.1).
2)A subscript is always equivalent to an offset from a pointer (paraphrase,
ANSI C Standard, paragraph 6.3.2.1).
3)An array name in the declaration of a function parameter is treated by
the compiler as a pointer to the first element of the array (paraphrase, ANSI
C Standard, paragraph 6.7.1).
即:
1)表达式中的数组名(与声明不同)被编译器当做一个指向该数组第一个元素的指针
2)下标总是与偏移量相同
3)在函数参数的声明中,数组名被编译器当做指向该数组第一个元素的指针
我觉得有必要对上文中出现的“表达式”做一个解释
int arry[10]={,,,,,};
int a=arry[2];
那么第二句中的int a=arry[2];就是所谓的表达式中出现的数组名了,这个时候编译器会把数组名arry当做指向数组第一个元素的指针,也就是arry[0]的地址
下标总是与偏移量相同,也就是arry[2]中的下标2和arry[2]这个元素在内存中相对于第一个元素的偏移量也是2它们是相同的。这样就能解释用数组下标可以取得
相应的数组中的某个元素了。(当然,在内存中还要考虑步长因素)
有了上面的分析,下面的容易弄懂了
如果声明: int a[10] ,*p , i=2
那么我们可以通过下面的任一种方式来访问a[i](每一列为一组,共三种)
p=a; p=a; p=a+i;
p[i]; *(p+i); *p;
在表达式中,数组和指针是可以互换的, 因为它们在编译器里都是指针形式,并且都能进行去下标操作。
数组和指针的遍历
为了更好的理解,下面通过一个例子说明数组和指针的联系和区别。(有点难理解~哦)
将在内存访问的角度来讨论数组和指针遍历
数组遍历:
for(i=0;i<10;i++)
a[i]=0
遍历过程:
1)把a的左值放入寄存器R1(也就是把a的物理地址也即数组的首地址存入R1) 可提到循环外
2)把i 的左值放入R2,同上,就是吧i 的物理地址放入R2 可移到循环外
3)把 [R2] 的右值放入 R3 也就是把变量i 的大小放入R3,(这里有点汇编的味道)
4)如果需要,调整R3 的步长,把R1 +R3 的值放入R4 解释:R1为数组的首地址,R3为偏移量,所以R4 就是当前操作数的地址
5)把0放入 [R4]
注:上面的R1-R4 看看做是寄存器,符号 [n] 表示的是:内存地址为n的值
”可以移到循环外“说明它在整个过程中不会改变,比如数组的首地址,变量 i 地址
左值和右值的概念在上面链接给出的博文中有阐述
指针遍历:
p=a
for(i =0 ;i < 10 ; i ++)
*p++=0
遍历过程:
1)p 所指对象的大小放入R5 可移到循环外
2)左值 p 放入R1 可移到循环外
3)[R0]放入R1
4)0存到[ R1]
5) R5+R1的结果存入R1
6)R1 存到[R0]
其实,这两两种访问方式也可看做是对上一篇博客中的访问方式的一个更深的理解。
要操作一个变量就要得到这个变量的地址,取得地址的方式数组和指针的区别和联系。这里就不在啰嗦,有兴趣的朋友可以参见上一篇博文
http://www.cnblogs.com/yanlingyin/archive/2011/11/29/2268391.html
为什么C把数组形参当做指针
把作为形参的数组当做指针来考虑其实是出于效率考虑。C中,所有非数组形式的数据实参均为值传递形式,值传递也就是调用函数的时候,把实参
拷贝一份给调用函数,就是说函数操作的是实参的拷贝而不是实参本身。(所以值传递的时候如果在函数中改变参数值,等调用结束后对实际的实参没有
影响,因为值传递中函数操作的只是实参的一份拷贝而并不是实参本身)
而对于数组,如果每次执行函数都要拷贝整个数组的话,就会花费大量的时间和空间开销,所有对于数组,C开用的机制是告诉函数数组的首地址,直接对
数组进程操作。
了解C++的朋友对于这应该就能更好地理解了,C++中参数传递分为值传递和引用传递,有兴趣的可以自行查阅资料、这不是本文终点不在复数
数组和指针的可交换性总结:Arrays and Pointers Interchangeability Summary
1. An array access a[i] is always "rewritten" or interpreted by the compiler as a pointer access *(a+i);
2. Pointers are always just pointers; they are never rewritten to arrays. You can apply a
subscript to a pointer; you typically do this when the pointer is a function argument,
and you know that you will be passing an array in.
3. An array declaration in the specific context (only) of a function parameter can equally
be written as a pointer. An array that is a function argument (i.e., in a call to the
function) is always changed, by the compiler, to a pointer to the start of the array.
4. Therefore, you have the choice for defining a function parameter which is an array,
either as an array or as a pointer. Whichever way you define it, you actually get a
pointer inside the function.
5. In all other cases, definitions should match declarations. If you defined it as an array,
your extern declaration should be an array. And likewise for a pointer.
1)对于a [i]这种形式的访问数组,通常被解释为指针形式*(a + i) 也就是上文中所说的“表达式”的情形
2)指针就是指针,没有说指针转化为数组的情况,你可以用下标的形式去访问指针,但一般都是指针作为函数参数时,而且传入的是一个数组
3)在函数参数的声明中,数组可以看做指针,(也只有这种情况)
4)当把一个数组定义为函数参数时,可以定义为数组,也可以是指针
5)其他的所有情况,声明和定义必须匹配。如果定义了一个数组,在其他文件中对它也必须声明为数组。指针也一样。
参考资料:《expert c programming》
【知其所以然】语义"陷阱"---数组和指针
数组和指针经常出现于编程语言中、也许上课的时候老师也说过数组和指针有区别、参考书上也应该讲过,你是不是也不曾透彻的理清过?
这篇博文主要从内存和编译的角度指出了数组和指针在访问方式上的区别、至于他们在函数调用的区别、以及它们的联系将在下一篇中详细讨论。
为了说的清楚些、会先说一些基础的部分、如果你已经掌握大可跳过
What's a Declaration? What's a Definition? 声明和定义
c语言的对象必须有且只有一个定义,但可以有多个声明(extern)这里说的对象和面向对象中的对象没有关系。
A definition is the special kind of declaration that creates an object; a declaration indicates a name
that allows you to refer to an object created here or elsewhere。
定义是一种特殊的声明、它创建了一个对象;声明简单的说明了在其他地方创建的对象的名字,它允许你使用这个名字。
可以简单的这样理解:
声明Declaration:描述在其他地方创建的对象,并不分配内存。(可以出现在多个地方)
定义Definition:产生一个新的对象,并分配内存。(只能出现一次)
How Arrays and Pointers Are Accessed -数组和指针是如何访问的
数组和指针在内存中的访问方式是不一样的。这里先要注意一下“地址y”和“地址y的内容”的区别。“地址y”表示变量y在内存中的地址,而“地址y的内容”指的是
位于这个地址中的内容,也就是变量y的值。大多数编程语言中用同一个符号来表示这两个东西,而由编译器根据上下文环境判断它的含义。
以一个简答的赋值为例:

上文中的x指的是x所代表的地址,而y的含义是y的内容。
出现在赋值符号左边的值称为左值、赋值符号右边的称为右值。编译器为每个变量分配地址(左值)。这个地址在编译时可知且一直存在,而它的右值在运行时
才能知道。通俗的说:每个变量都有一个地址,这个地址在编译时可以知道,而地址里存储的内容(也就是变量的值)只有在运行时才能知道。如果需要用到变量
的值,(也就是已知地址存储的值)那么编译器发出指令从指定地址读入变量值并放入相应寄存器中。
这里的关键是地址在编译时可知、如果要对进行一些操作(比如说加上偏移量之类的)可以直接操作。相反、对于指针,必须在运行时取得它的地址,然后才能
对它进行接触引用操作。下图展示了对数组下标的引用:

这样我们就可以解释为什么extern char a[]和extern char a[100]相同的原因了。这两个什么都是表名a是一个数组,也就是一个内存地址,
数组内的字符可以由这个地址找到。
和上面不同的是,如果声明的是一个指针,如 extern char *p,它表示p指向一个字符,为了取得这个字符,必须知道地址p的内容,把它作为字符的地址
并从这个地址中取得这个字符。

如果是数组a[],那么可以直接用数组名来访问数组中的元素,因为它的内容就是第一个元素, 他的下一个地址也就对应了下一个数组元素的地址。
如果是指针*a,先要取出地址a的内容,再把它作为变量的地址并从这个地址中取得变量的内容。
数组和指针的其他区别:

定义指针时,编译器并不为它所指向的对象分配空间,只为指针本身分配空间。除非在定义同时付给一个指针一字符窜常量进行初始化。
如:char *p = "breadfruit";
一般情况下初始化指针时创建的字符串变量被定义为只读。如果试图修改就会出现未定义的行为。
这篇文章主要是从访问形式上对数组和指针的区别做了些小的总结,而对于数组和指针在函数调用中、已经更本质的区别、什么时候数组
和指针又是等同的、将在下一篇博文中给出。如果完全弄清楚了、对今后的编程也会有不小的帮助。
堆和栈的区别详解
前言:
在程序设计的时候、堆栈总是不可避免的会接触到、而对于堆和栈他们的区别、在程序运行时各自的作用,如何利用堆栈提高运行效率等
很多人都还了解的不够,今天google了很多文章,所以在这里作个完善总结,希望能给有心人些帮助。有不足的地方还希望能指出。
栈是随函数被调用时分配的空间
栈上分配的空间是临时的,在函数退出后将被系统释放,不会造成内存泄露,不得用delete或free操作,因为栈的空间小所以在栈上不能获得大量的内存块
,一般最大也就不到10M 堆是在整个进程的未分配空间中分配的内存,由malloc或new分配,一般必须由free或delete释放。堆上可以分配大量的内存,只要
你的机器吃得消。 一般来说,由new和malloc分配的内存都在堆上,全局变量也在堆上(但是不是new,malloc出来的也会自动清理)。函数内部的其
他变量和常量都在栈上。
c++内存格局通常分为:
全局数据区
代码区
栈区
堆区
堆和栈的比较
从堆和栈的功能和作用来通俗的比较,堆主要用来存放对象的,栈主要是用来执行程
序的.而这种不同又主要是由于堆和栈的特点决定的:
在编程中,例如C/C++中,所有的方法调用都是通过栈来进行的,所有的局部变量,形式参数都是从栈中分配内存空间的。实际上也不是什么分配,只是从栈顶向上用就行,
就好像工厂中的传送带(conveyor belt)一样,Stack Pointer会自动指引你到放东西的位置,你所要做的只是把东西放下来就行.退出函数的时候,修改栈指针就可以把栈中
的内容销毁这样的模式速度最快,当然要用来运行程序了.需要注意的是,在分配的时候,比如为一个即将要调用的程序模块分配数据区时,应事先知道这个数据区的大小,也就说
是虽然分配是在程序运行时进行的,但是分配的大小多少是确定的,不变的,而这个"大小多少"是在编译时确定的,不是在运行时.
堆是应用程序在运行的时候请求操作系统分配给自己内存,由于从操作系统管理的内存分配,所以在分配和销毁时都要占用时间,因此用堆的效率非常低.但是堆的优点在于
,编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要在堆里停留多长的时间,因此,用堆保存数据时会得到更大的灵活性。事实上,面向对象的多态性,堆内存
分配是必不可少的,因为多态变量所需的存储空间只有在运行时创建了对象之后才能确定.在C++中,要求创建一个对象时,只需用new命令编制相关的代码即可。执行这些代码时
会在堆里自动进行数据的保存.当然,为达到这种灵活性,必然会付出一定的代价:在堆里分配存储空间时会花掉更长的时间!这也正是导致效率低的原因,
堆和栈的区别(转)
一、预备知识—程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等
。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由
OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化
的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻
的另一块区域。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
二、例子程序
//main.cpp
?
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b; 栈
char s[] = "abc" ; 栈
char *p2; 栈
char *p3 = "123456" ; 123456\0在常量区,p3在栈上。
static int c =0; 全局(静态)初始化区
p1 = ( char *)malloc(10);
p2 = ( char *)malloc(20);
分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456" ); 123456\0放在常量区,编译器可能会将它与p3所指向的"12345
6"优化成一个地方。
}
|
二、堆和栈的理论知识
2.1申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟
空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
2.2
申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈
溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时
会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链
表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间
中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存
空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多
余的那部分重新放入空闲链表中。
2.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的
意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(
也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间
时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存
储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的
大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较
大。
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈
是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵
活。
2.5堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条
可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左
入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的
地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
#include
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读
到edx中,在根据edx读取字符,显然慢了。
2.7小结:
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了
就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但
是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自
由度大
程序的运行时 数据结构
这篇博文主要内容是程序运行时的数据结构,包括运行时程序中的不同部分如何分配内存、函数调用的内存实现、
还介绍了一个c独有的强大功能,一个被称为“展开堆栈”(unwinding stack)的技术
运行时 数据结构,中间的空格是特意留出的,
运行时可以认为是程序执行的一个状态,一般有编译时,运行时等,他们都是表示一个处理状态。
编程语言的的经典对立之一就是代码和数据的区别。代码和数据的区别也可认为是运行时和编译时的界限,编译器的绝大部分工作和翻译代码有关;必要的数据存储管理的绝大部分都在运行时进行。
如果你用过GCC,就会知道用GCC编译程序,都会得到一个默认名为“a.out”的文件。
简单说下“a.out”的由来吧:
他是assembler output(汇编程序输出)”的缩写形式。但是,他不是汇编程序输出,而是链接器输出。
这个名字曾被解释为:“新程序就绪,准备执行”它是链接器输出文件。
一般的说,可以认为连接器输出的是二进制文件,这个文件并不是杂乱无章的放在一起的,而是由一定的存放规律。比如说分类存放,这就涉及到了我们接下来要讨论的段的概念。
段
目标文件和可执行文件都可以有多种不同的格式,所有这些不同的格式都有一个概念,就是段(segments)。
就目标文件而言,段就是二进制文件的简单区域,里面保存了某种特定类型相关的所有信息。术语section也广泛使用,
他可看作是段的组成部分,一个段通常可以包含几个section
不过这里的段要注意和内存模型中的段区别开来,在内存模型中,段是内存模型设计的结果。
请看段的组成形式:
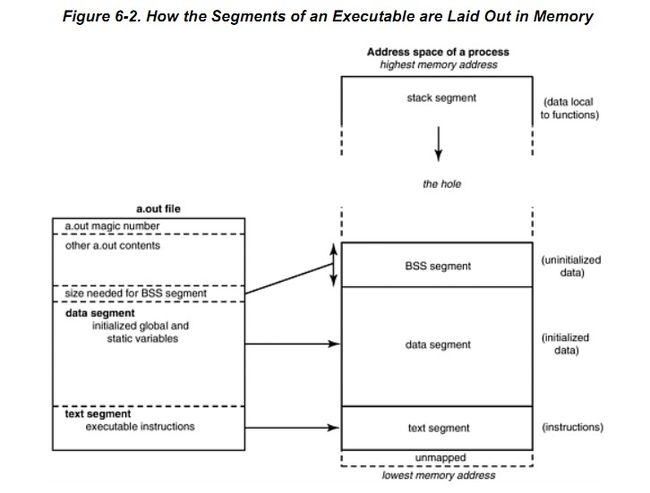
从上图中可以看出:a.out包含了magic number,它可以理解为一个标示符,一般是一些特殊的数字,所谓的特殊数字也就是有特别意义的,比如
#define FS_MSGIC 0x011954 它是kirk mckusick 的生日。~所以这里不用太注意。
下面的是a.out的其他内容,比如一些标示符等等。。其它的内容在下文有说明就不多说
操作系统对段的操作:
段可以方便的映射到链接器在运行时可以直接载入的对象中,载入器只是提取每个端的印象,直接将他们放入内存中。
从本质上说,端在执行过程的程序中是一块内存区域。
文本段(The text segment )包含程序的指令,链接器把指令直接从文件拷贝到内存中,以后就用管他,因为一般情况下下,文本区域是不会改变的,不论是大小还是内容。
数据段(The data segment)包含经过初始化的全局变量和静态变量以及他们的值。BSS段是未初始化的数据,大小可从可执行文件中得到,然后链接器得到这个大小的内存块。
紧跟在数段之后,包含数据段和BSS段的一般统称为数据区。这是因为,操作系统中,段是一块连续地址,所以相邻的端被结合。一般来讲,数据段在任
何进程中都是最大的段。
堆栈段(The stack segment)上图显示了一个即将执行的进程的内存布局,我们仍然需要一些存储空间,用于存放临时变量,临时数据,传递到函数中的参数等等(local variables, temporaries, parameter passing in function calls,)。
注意到虚拟地址空间的最低部分未被映射。它位于地址空间内,但为被赋予物理地址,所以对它的任何引用都是非法的。他用于捕捉使用空指针和小整形值的制造引用内存的情况。
When you take shared libraries into account, a process address space appears,
当考虑共享库时,进程的地址空间的样子如下图所示:

C运行时对a.out的操作
What the C Runtime Does with Your a.out
现在看一下c语言在运行时的数据结构是怎么样的,运行时数据结构一般有好几种,堆栈,活动记录,数据,(the stack, activation records, data, heap)堆等
下面将分别讨论,并分析他们所支持的语言特性:
The Stack Segment 堆栈段:
堆栈段包含一种单一的数据结构:堆栈。
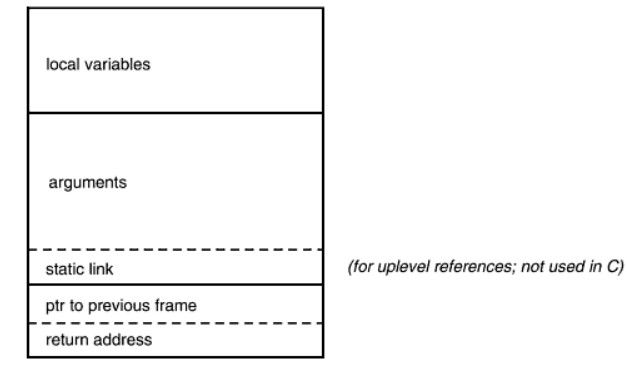
堆栈为函数内部声明的局部变量提供存储空间。
函数调用的时候,堆栈存储相关的一些维护信息。这些信息被称为堆栈结构(stack frame)也叫做过程活动记录(precedure activation record)稍后讨论。
堆栈也可以作为临时存储区,有时候进程需要一些临时存储空间,比如执行一个复杂的计算时,可以把结果压到堆栈中。
值得一提的是:除了递归调用之外,堆栈并非必须。
函数是怎么被调用的:过程活动记录(precedure activation record)
What Happens When a Function Gets Called
c运行时系统在他自己的地址空间内如何管理程序的呢?这里做一个简单的讨论。
c语言自动提供一种用于函数调用的功能:称作调用链( keeping track of the call chain)记录了哪些函数调用哪些函数,以及return执行后,控制将返回什么地方。
解决这个问题的经典机制就是堆栈中的过程活动记录,每一个函数调用都会产生一个过程记录。其实它就是一种数据结构,记录调用后返回调用点需要的全部信息。
如下图就是一个过程活动记录的结构,不同的编译器会有所差别,但目的都是记录调用后返回调用点的信息。
Astonishing C Fact!
C语言中令人震惊的事实:
现在的多数编程语言都允许在函数内部定义函数,但C语言中所有函数都是在此法层次中的的最顶层 。
这个限制稍微简化了c编译器。对于前一种允许在内部定义函数的,(也即允许嵌套的过程语言)中,过程活动记录要包括一个指向外层活动记录的指针。这个
指针被称为静态链接(static link)它允许内层过程访问外层活动记录,因此也能访问外层的局部数据。这种类型的访问被称为上层引用。
下面的例子显示了程序执行在不同点是堆栈中过程活动记录的情况。

Static 和 Auto关键字详解
为什么不能从函数中返回一个指向该函数中局部变量的指针
char * favorite_fruit () {
char deciduous [] = "apple";
return deciduous;
}
进入 该函数的时候,自动为变量deciduous在堆栈中分配空间,当函数结束后变量不存在了,因为它所占的空间被堆栈回收了。可能在任何时候被覆盖,这样
返回的指针就指向一个不确定的堆栈空间,指针失去了有效性,被称为垂悬指针。
如果想反悔一个在函数内部定义的指针,声明为static就行。static的声明在数据段中而不是堆栈段中分配空间,当定义的变量退出函数是依然有效,下次进入函数
依然存在。
存储类型auto在实际中基本用不上,因为默认的声明就是auto。他表示“进入该块后自动分配内存”在函数内部什么的数据缺省就是这种分配
setjmp and longjmp
现在简单讨论一下sejmp和longjmp的用途,他们是通过操作过程活动记录实现的。它是c语言独有的强大机制。部分弥补了c语言有限的转移能力。这两个函数协同工作
• setjmp(jmp_buf j) must be called first. It says use the variable j to remember where
you are now. Return 0 from the call.
• longjmp(jmp_buf j,int i) can then be called. It says go back to the place that
the j is remembering. Make it look like you're returning from the original setjmp(), but
return the value of i so the code can tell when you actually got back here via longjmp().
Phew!
• The contents of the j are destroyed when it is used in a longjmp().
• setjmp(jmp_buf j)要先调用,它使用变量j记录现在 的位置,函数返回0;
longjmp(jmp_buf j ,int i)可以接着被调用它表示“回到J所记录的位置”,让程序看上去“好像什么都没发生一样”返回i让代码知道实际上是通过longjmp返回的
当使用longjmp()时,j的内容被销毁。
setjmp保存了一份程序计数器和当前栈顶的指针,还可以保存一些初值。longjmp返回到setjmp设置的地方,有效的转移控制并把状态重置到保存状态的时候。
这被称作“展开堆栈”因为你从堆栈中展开过程活动记录,直到取得保存在其中的值。
它和goto语句的区别:
A goto can't jump out of the current function in C (that's why this is a "longjmp"— you can
jump a long way away, even to a function in a different file).
You can only longjmp back to somewhere you have already been, where you did a setjmp,
and that still has a live activation record. In this respect, setjmp is more like a "come from"
statement than a "go to". Longjmp takes an additional integer argument that is passed back,
and lets you figure out whether you got here from longjmp or from carrying on from the
previous statement.
goto语句不能跳出c语言当前的函数
longjmp只能回到曾经到过的地方,(setjmp设置的地方)
下面给一个示例:
#include
jmp_buf buf;
#include
banana() {
printf("in banana()\n");
longjmp(buf, 1);
/*NOTREACHED*/
printf("you'll never see this, because I longjmp'd");
}
main()
{
if (setjmp(buf))
printf("back in main\n");
else {
printf("first time through\n");
banana();
}
}
输出结果:
% a.out
first time through
in banana()
back in main
setjmp/longjmp最大的用途在于恢复错误、只要还没从函数中返回,一旦发现一个不可恢复的错误,可以吧控制转移到主输入循环中。
希望能和更多的朋友交流、学习
先写这么多吧、有什么不正确的地方还望大家指出~
C++ 全局变量、局部变量、静态全局变量、静态局部变量的区别
全局变量、局部变量、静态全局变量、静态局部变量的区别
C++变量根据定义的位置的不同的生命周期,具有不同的作用域,作用域可分为6种:全局作用域,局部作用域,语句作用域,类作用域,命名空间作用域和文件作用域。
从作用域看:
全局变量具有全局作用域。全局变量只需在一个源文件中定义,就可以作用于所有的源文件。当然,其他不包含全局变量定义的源文件需要用extern 关键字再次声明这个全局变量。
静态局部变量具有局部作用域,它只被初始化一次,自从第一次被初始化直到程序运行结束都一直存在,它和全局变量的区别在于全局变量对所有的函数都是可见的,而静态局部变量只对定义自己的函数体始终可见。
局部变量也只有局部作用域,它是自动对象(auto),它在程序运行期间不是一直存在,而是只在函数执行期间存在,函数的一次调用执行结束后,变量被撤销,其所占用的内存也被收回。
静态全局变量也具有全局作用域,它与全局变量的区别在于如果程序包含多个文件的话,它作用于定义它的文件里,不能作用到其它文件里,即被static关键字修饰过的变量具有文件作用域。这样即使两个不同的源文件都定义了相同名字的静态全局变量,它们也是不同的变量。
从分配内存空间看:
全局变量,静态局部变量,静态全局变量都在静态存储区分配空间,而局部变量在栈里分配空间
全局变量本身就是静态存储方式, 静态全局变量当然也是静态存储方式。这两者在存储方式上并无不同。这两者的区别虽在于非静态全局变量的作用域是整个源程序,当一个源程序由多个源文件组成时,非静态的全局变量在各个源文件中都是有效的。 而静态全局变量则限制了其作用域, 即只在定义该变量的源文件内有效,在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域局限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其它源文件中引起错误。
1)、静态变量会被放在程序的静态数据存储区(数据段)(全局可见)中,这样可以在下一次调用的时候还可以保持原来的赋值。这一点是它与堆栈变量和堆变量的区别。
2)、变量用static告知编译器,自己仅仅在变量的作用范围内可见。这一点是它与全局变量的区别。
从以上分析可以看出, 把局部变量改变为静态变量后是改变了它的存储方式即改变了它的生存期。把全局变量改变为静态变量后是改变了它的作用域,限制了它的使用范围。因此static 这个说明符在不同的地方所起的作用是不同的。应予以注意。
Tips:
A.若全局变量仅在单个C文件中访问,则可以将这个变量修改为静态全局变量,以降低模块间的耦合度;
B.若全局变量仅由单个函数访问,则可以将这个变量改为该函数的静态局部变量,以降低模块间的耦合度;
C.设计和使用访问动态全局变量、静态全局变量、静态局部变量的函数时,需要考虑重入问题,因为他们都放在静态数据存储区,全局可见;
D.如果我们需要一个可重入的函数,那么,我们一定要避免函数中使用static变量(这样的函数被称为:带“内部存储器”功能的的函数)
E.函数中必须要使用static变量情况:比如当某函数的返回值为指针类型时,则必须是static的局部变量的地址作为返回值,若为auto类型,则返回为错指针。
-----------------------------------------------------------------------------------------------------------
static 全局变量:改变作用范围,不改变存储位置
static 局部变量:改变存储位置,不改变作用范围
静态函数 :在函数的返回类型前加上static关键字,函数即被定义为静态函数。静态函数与普通函数不同,它只能在声明它的文件当中可见,不能被其它文件使用。
如果在一个源文件中定义的函数,只能被本文件中的函数调用,而不能被同一程序其它文件中的函数调用,这种函数也称为内部函数。定义一个内部函数,只需在函数类型前再加一个“static”关键字即可。
野指针
什么是野指针?
一个母亲有两个小孩(两个指针),一个在厨房,一个在卧室,(属于不同的代码块,其生存期不同)母亲让在厨房的小孩带一块蛋糕(指针指向的对象)给在卧室的小孩,这样在卧室的孩子才肯写作业。但这个在厨房的小孩比较淘气,他在走出厨房时自己将蛋糕吃了,没能带出来。而在卧室的没有吃到蛋糕,所以不肯完成他的作业。结果母亲却不知道卧室的孩子没有吃到蛋糕,还以为作业完了。结果第二天她就被老师召唤到办公室了。事情麻烦了。
这样,那个在卧室的孩子就是野指针了,因为他没有得到应得的蛋糕,不能完成母亲交给他的作业。
这就是c中所讲的野指针。上面的小剧本不过演示了一种最基本的野指针的形成过程。更容易出现的情形是coder在编码时,大意之下使用了已经free过的指针。
对于年轻点的经验欠缺的coder来说是比较容易犯的错误,经验老到的程序员或者慎重采取成对编程的形式避免这种失误,或者使用引用计数器防止形成野指针。
总之,在c中,野指针也许性子野,但是控制起来也是有章可循。然而事情在c++中出现了变化。
coder们面临更大的麻烦了。c++程序员无可避免的要写很多这样那样的类。谁让c++是面向对象的呢?
我们在写类的时候难免要用new给类的数据成员分配内存。这本来没什么,动态分配内存是一种很常见的基本操作,我们在学数据结构时经常这么做,不是么?
但是伙计,事情并非这么简单。类是一种高级的用户自定义数据类型,看起来和结构、枚举这样的用户自定义类型没啥太大差别。如果你这样认为....?那你会死的很惨。类太复杂了,普通情况下使用类的对象并没有太大的问题,但是,当你要复制一个对象时,问题就来了。
比如我们知道,你要用一个对象初始化另一个对象时,c++是按位进行拷贝的,即在目标对象里创建了初始化对象的一个完全相同的拷贝。这在多数情况下已经足够了。但是,当你的类在创建时为每个对象分配内存,也就是说类中有new操作。当你的对象创建好后,类也为对象分配了一块内存。如果你用这个对象去初始化另一个对象时,被初始化的对象和初始化的对象完全一样。这意味着,他们使用同一块内存,而不是重新为被初始化的对象分配内存。
这样麻烦就大了。如果一个对象销毁了,那么分配的内存也就销毁了(别忘了,类是有析构函数的,它负责在对象销毁时,释放动态分配的内存。难道你说你不在类中写上析构部分?那么可怜的孩子,那你就走向了另一个深渊,当你的程序运行数小时之后,系统会告诉你,内存不够用了。想象一下把你的程序用在腾讯的服务器上),另一个对象就残缺不全了,这就像一对连体婴儿,他们共用了一部分器官,心脏或者肝脏。要救活一个,就牺牲了另一个。一个得病了,另一个也要遭殃。
可以说,这就是c++中更加变态的野指针。
什么?你说我不用对象初始化对象?那么我们会不会将一个对象作为变元传递给函数呢?我们很多时候都这样做。有时我们不得不将对象按值传递给一个函数,但是你要知道,按值传递是什么意思?它的意思就是,把实参的一个拷贝传递给函数。这和刚才的初始化没什么两样,按位拷贝,函数体内的对象与外面的对象共用一块内存,即便在函数中的对象没有对这块内存进行过操作,但是当函数结束时。。。。析构函数将会被调用......
还有一种与之相反的情况......, 当你想要把一个在函数内的对象值返回给外面的对象时,这时候,会自动产生一个临时对象,由它容纳函数的返回值,并在函数结束时把结果传给目标。那么这个临时对象迅速的被创建,并被迅速的释放。。。一块内存被释放了两次。其后果是不可预见的。
当你把一个对象的值赋给另一个对象时,如果你没有重载赋值运算符,那么也会导致按位拷贝。最终产生一个野指针(一个隐藏在类内的毒瘤),或者释放同一块内存多次。
看到了么?害怕了么?是不是感到C++到处都是陷阱呢?不但有陷阱,到处都是危险品。所有c中的疑难问题,到了c++就成了一般问题了。好了不废话了,我们继续讲讲解决之道。
对于最后的这种赋值的情况,我们只有通过重载赋值运算符才能解决,也就是避免按位拷贝。
至于前面的都属于初始化,概括下来就是三种情况:
1.当一个对象初始化另一个对象时,例如在声明中;
2.把所创建的对象拷贝(按值)传递给一个函数时;
3.生成临时对象时,最常见的就是函数的返回值。
解决初始化时的按位拷贝问题,我们通过创建拷贝构造函数来解决。
基本的拷贝构造函数形式为:
classname (const classname &o)
{
//body here
}
拷贝构造函数就是针对这个问题而设计的。
讨论二
野指针,也就是指向不可用内存区域的指针。通常对这种指针进行操作的话,将会使程序发生不可预知的错误。
“野指针”不是NULL指针,是指向“垃圾”内存的指针。人们一般不会错用NULL指针,因为用if语句很容易判断。但是“野指针”是很危险的,if语句对它不起作用。野指针的成因主要有两种:
(1)、指针变量没有被初始化。任何指针变量刚被创建时不会自动成为NULL指针,它的缺省值是随机的,它会乱指一气。所以,指针变量在创建的同时应当被初始化,要么将指针设置为NULL,要么让它指向合法的内存。
(2)、指针p被free或者delete之后,没有置为NULL,让人误以为p是个合法的指针。别看free和delete的名字恶狠狠的(尤其是delete),它们只是把指针所指的内存给释放掉,但并没有把指针本身干掉。通常会用语句if (p != NULL)进行防错处理。很遗憾,此时if语句起不到防错作用,因为即便p不是NULL指针,它也不指向合法的内存块。例:
char *p = (char *) malloc(100);
strcpy(p, “hello”);
free(p); // p 所指的内存被释放,但是p所指的地址仍然不变
if(p != NULL) // 没有起到防错作用
strcpy(p, “world”); // 出错
另外一个要注意的问题:不要返回指向栈内存的指针或引用,因为栈内存在函数结束时会被释放。
首先请诸位看以下一段“危险”的C++代码:
void function( void )
{
char* str = new char[100];
delete[] str;
// Do something
strcpy( str, "Dangerous!!" );
}
之所以说其危险,是因为这是一段完全合乎语法的代码,编译的时候完美得一点错误也不会有,然而当运行到strcpy一句的时候,问题就会出现,因为在这之前,str的空间已经被delete掉了,所以strcpy当然不会成功。对于这种类似的情况,在林锐博士的书中有过介绍,称其为“野指针”。
那么,诸位有没有见过安全的“野指针”呢?下面请看我的一段C++程序,灵感来自CSDN上的一次讨论。在此,我只需要C++的“类”,C++的其余一概不需要,因此我没有使用任何的C++标准库,连输出都是用printf完成的。
#include
class CTestClass
{
public:
CTestClass( void );
int m_nInteger;
void Function( void );
};
CTestClass::CTestClass( void )
{
m_nInteger = 0;
}
void CTestClass::Function( void )
{
printf( "This is a test function.\n" );
}
void main( void )
{
CTestClass* p = new CTestClass;
delete p;
p->Function();
}
OK,程序到此为止,诸位可以编译运行一下看看结果如何。你也许会惊异地发现:没有任何的出错信息,屏幕上竟然乖乖地出现了这么一行字符串:
This is a test function.
奇怪吗?不要急,还有更奇怪的呢,你可以把主函数中加上一句更不可理喻的:
((CTestClass*)NULL)->Function();
这仍然没有问题!!
我这还有呢,哈哈。现在你在主函数中这么写,倘说上一句不可理喻,那么以下可以叫做无法无天了:
int i = 888;
CTestClass* p2 = (CTestClass*)&i;
p2->Function();
你看到了什么?是的,“This is a test function.”如约而至,没有任何的错误。
你也许要问为什么,但是在我解答你之前,请你在主函数中加入如下代码:
printf( "%d, %d", sizeof( CTestClass ), sizeof( int ) );
这时你就会看到真相了:输出结果是——得到的两个十进制数相等。对,由sizeof得到的CTestClass的大小其实就是它的成员m_nInteger的大小。亦即是说,对于CTestClass的一个实例化的对象(设为a)而言,只有a.m_nInteger是属于a这个对象的,而a.Function()却是属于CTestClass这个类的。所以以上看似危险的操作其实都是可行且无误的。
现在你明白为什么我的“野指针”是安全的了,那么以下我所列出的,就是在什么情况下,我的“野指针”不安全:
(1)在成员函数Function中对成员变量m_nInteger进行操作;
(2)将成员函数Function声明为虚函数(virtual)。
以上的两种情况,目的就是强迫野指针使用属于自己的东西导致不安全,比如第一种情况中操作本身的m_nInteger,第二种情况中变为虚函数的Function成为了属于对象的函数(这一点可以从sizeof看出来)。
其实,安全的野指针在实际的程序设计中是几乎毫无用处的。我写这一篇文章,意图并不是像孔乙己一样去琢磨回字有几种写法,而是想通过这个小例子向诸位写明白C++的对象实例化本质,希望大家不但要明白what和how,更要明白why。李马二零零三年二月二十日作于自宅。
关于成员函数CTestClass::Function的补充说明 :
(1)这个函数是一个普通的成员函数,它在编译器的处理下,会成为类似如下的代码:
void Function( const CTestClass * this ) // ①
{
printf("This is a test function.\n");
}
那么p->Function();一句将被编译器解释为:
Function( p );
这就是说,普通的成员函数必须经由一个对象来调用(经由this指针激活②)。那么由上例的delete之后,p指针将会指向一个无效的地址,然而p本身是一个有效的变量,因此编译能够通过。并且在编译通过之后,由于CTestClass::Function的函数体内并未对这个传入的this指针进行任何的操作,所以在这里,“野指针”便成了一个看似安全的东西。
然而若这样改写CTestClass::Function:
void CTestClass::Function( void )
{
m_nInteger = 0;
}
那么它将会被编译器解释为:
void Function( const CTestClass * this )
{
this->m_nInteger = 0;
}
你看到了,在p->Function();的时候,系统将会尝试在传入的这个无效地址中寻找m_nInteger成员并将其赋值为0,剩下的我不用说了——非法操作出现了。
至于virtual虚函数,如果在类定义之中将CTestClass声明为虚函数:
class CTestClass
{
public:
// ...
virtual void Function( void );
};
那么C++在构建CTestClass类的对象模型时,将会为之分配一个虚函数表vptr(可以从sizeof看出来)。vptr是一个指针,它指向一个函数指针的数组,数组中的成员即是在CTestClass中声明的所有虚函数。在调用虚函数的时候,必须经由这个vptr,这也就是为什么虚函数较之普通成员函数要消耗一些成本的缘故。以本例而言,p->Function();一句将被编译器解释为:
(*p->vptr[1])( p ); // 调用vptr表中索引号为1的函数(即Function)③
上面的代码已经说明了,如果p指向一个无效的地址,那么必然会有非法操作。
备注:
①关于函数的命名,我采用了原名而没有变化。事实上编译器为了避免函数重载造成的重名情况,会对函数的名字进行处理,使之成为独一无二的名称。
②将成员函数声明为static,可以使成员函数不经由this指针便可调用。
③vptr表中,索引号0为类的type_info。
讨论三:
先上代码,传说中的腾讯笔试题:
#include 'stdafx.h'
#include
#include
using std::cout;
using std::endl;
class Test
{
public:
Test()
{
a = 9;
delete this;
}
~Test()
{
cout<<'destructor called!'< }
int a;
};
int _tmain(int argc, _TCHAR* argv[])
{
Test *mytest = new Test(); //mytest的值和this指针的值是一样一样的
cout<a< return 0;
}
请问运行结果如何?
常见的回答,程序会报错,通不过编译。或者说编译通过,运行时报错,因为居然Test类的构造函数删除了this指针,相当于调用了Test类的析构函数,对象不再存在,所以访问成员变量a的时候出错。
实际的结果是,程序可以通过编译,运行时不报错,只不过打印出a的值不是9,而是内存中一个随机垃圾值。
如果想让程序运行时出错,可以这样写main函数:
Test mytest;
cout< return 0;
这样mytest是局部对象,内存在栈上分配,delete this试图释放栈上的内存,因此会报错。
下面的代码演示了这种情况。
int a = 6;
delete &a; //运行时报错
继续上面的讨论,野指针是指在delete了一个指向动态对象的指针后,没有及时置为NULL,如果对该指针进行解除引用,就会产生垃圾值。
一个铁的纪律,彻底杜绝野指针(这道题没办法,this不能做左值,况且即使改了this,mytest也是改不了的,不再考虑范围)delete了一个指向动态对象的指针后,及时置为NULL。相应的,对指针进行解除引用前,判断指针是否为NULL。
C++语言学习之STL 的组成
STL有三大核心部分:容器(Container)、算法(Algorithms)、迭代器(Iterator),容器适配器(container adaptor),函数对象(functor),除此之外还有STL其他标准组件。通俗的讲:
容器:装东西的东西,装水的杯子,装咸水的大海,装人的教室……STL里的容器是可容纳一些数据的模板类。
算法:就是往杯子里倒水,往大海里排污,从教室里撵人……STL里的算法,就是处理容器里面数据的方法、操作。
迭代器:往杯子里倒水的水壶,排污的管道,撵人的那个物业管理人员……STL里的迭代器:遍历容器中数据的对象。对存储于容器中的数据进行处理时,迭代器能从一个成员移向另一个成员。他能按预先定义的顺序在某些容器中的成员间移动。对普通的一维数组、向量、双端队列和列表来说,迭代器是一种指针。
下面让我们来看看专家是怎么说的:
容器(container):容器是数据在内存中组织的方法,例如,数组、堆栈、队列、链表或二叉树(不过这些都不是STL标准容器)。STL中的容器是一种存储T(Template)类型值的有限集合的数据结构,容器的内部实现一般是类。这些值可以是对象本身,如果数据类型T代表的是Class的话。
算法(algorithm):算法是应用在容器上以各种方法处理其内容的行为或功能。例如,有对容器内容排序、复制、检索和合并的算法。在STL中,算法是由模板函数表现的。这些函数不是容器类的成员函数。相反,它们是独立的函数。令人吃惊的特点之一就是其算法如此通用。不仅可以将其用于STL容器,而且可以用于普通的C++数组或任何其他应用程序指定的容器。
迭代器(iterator):一旦选定一种容器类型和数据行为(算法),那么剩下唯一要他做的就是用迭代器使其相互作用。可以把达代器看作一个指向容器中元素的普通指针。可以如递增一个指针那样递增迭代器,使其依次指向容器中每一个后继的元素。迭代器是STL的一个关键部分,因为它将算法和容器连在一起。
下面我将依次介绍STL的这三个主要组件。
1. 容器
STL中的容器有队列容器和关联容器,容器适配器(congtainer adapters:stack,queue,priority queue),位集(bit_set),串包(string_package)等等。
在本文中,我将介绍list,vector,deque等队列容器,和set和multisets,map和multimaps等关联容器,一共7种基本容器类。
队列容器(顺序容器):队列容器按照线性排列来存储T类型值的集合,队列的每个成员都有自己的特有的位置。顺序容器有向量类型、双端队列类型、列表类型三种。
u 基本容器——向量
向量(vector容器类):#include ,vector是一种动态数组,是基本数组的类模板。其内部定义了很多基本操作。既然这是一个类,那么它就会有自己的构造函数。vector 类中定义了4中种构造函数:
· 默认构造函数,构造一个初始长度为0的空向量,如:vector v1;
· 带有单个整形参数的构造函数,此参数描述了向量的初始大小。这个构造函数还有一个可选的参数,这是一个类型为T的实例,描述了各个向量种各成员的初始值;如:vector v2(n,0); 如果预先定义了:n,他的成员值都被初始化为0;
· 复制构造函数,构造一个新的向量,作为已存在的向量的完全复制,如:vector v3(v2);
· 带两个常量参数的构造函数,产生初始值为一个区间的向量。区间由一个半开区间[first,last) 来指定。如:vector v4(first,last)
下面一个例子用的是第四种构造方法,其它的方法读者可以自己试试。
- //程序:初始化演示
- #include
- #include
- #include
- using namespace std;
-
- int ar[10] = { 12, 45, 234, 64, 12, 35, 63, 23, 12, 55 };
- char* str = "Hello World";
-
- int main()
- {
- vector <int> vec1(ar, ar+10); //first=ar,last=ar+10,不包括ar+10
- vector < char > vec2(str,str+strlen(str)); //first=str,last= str+strlen(str),
- cout<<"vec1:"<
- //打印vec1和vec2,const_iterator是迭代器,后面会讲到
- //当然,也可以用for (int i=0; i
- //size()是vector的一个成员函数
- for(vector<int>::const_iterator p=vec1.begin();p!=vec1.end(); ++p)
- cout<<*p;
- cout<<'/n'<<"vec2:"<
- for(vector< char >::const_iterator p1=vec2.begin();p1!=vec2.end(); ++p1)
- cout<<*p1;
- cout<<'/n';
- return 0;
- }
为了帮助理解向量的概念,这里写了一个小例子,其中用到了vector的成员函数:begin(),end(),push_back(),assign(),front(),back(),erase(),empty(),at(),size()。
- #include
- #include
- using namespace std;
-
- typedef vector<int> INTVECTOR;//自定义类型INTVECTOR
- //测试vector容器的功能
-
- int main()
- {
- //vec1对象初始为空
- INTVECTOR vec1;
- //vec2对象最初有10个值为6的元素
- INTVECTOR vec2(10,6);
- //vec3对象最初有3个值为6的元素,拷贝构造
- INTVECTOR vec3(vec2.begin(),vec2.begin()+3);
- //声明一个名为i的双向迭代器
- INTVECTOR::iterator i;
- //从前向后显示vec1中的数据
- cout<<"vec1.begin()--vec1.end():"<
- for (i =vec1.begin(); i !=vec1.end(); ++i)
- cout << *i << " ";
- cout << endl;
- //从前向后显示vec2中的数据
- cout<<"vec2.begin()--vec2.end():"<
- for (i =vec2.begin(); i !=vec2.end(); ++i)
- cout << *i << " ";
- cout << endl;
- //从前向后显示vec3中的数据
- cout<<"vec3.begin()--vec3.end():"<
- for (i =vec3.begin(); i !=vec3.end(); ++i)
- cout << *i << " ";
- cout << endl;
- //测试添加和插入成员函数,vector不支持从前插入
- vec1.push_back(2);//从后面添加一个成员
- vec1.push_back(4);
- vec1.insert(vec1.begin()+1,5);//在vec1第一个的位置上插入成员5
- //从vec1第一的位置开始插入vec3的所有成员
- vec1.insert(vec1.begin()+1,vec3.begin(),vec3.end());
- cout<<"after push() and insert() now the vec1 is:" <
- for (i =vec1.begin(); i !=vec1.end(); ++i)
- cout << *i << " ";
- cout << endl;
- //测试赋值成员函数
- vec2.assign(8,1); // 重新给vec2赋值,8个成员的初始值都为1
- cout<<"vec2.assign(8,1):" <
- for (i =vec2.begin(); i !=vec2.end(); ++i)
- cout << *i << " ";
- cout << endl;
- //测试引用类函数
- cout<<"vec1.front()="<//vec1第零个成员
- cout<<"vec1.back()="<//vec1的最后一个成员
- cout<<"vec1.at(4)="<//vec1的第五个成员
- cout<<"vec1[4]="<
- //测试移出和删除
- vec1.pop_back();//将最后一个成员移出vec1
- vec1.erase(vec1.begin()+1,vec1.end()-2);//删除成员
- cout<<"vec1.pop_back() and vec1.erase():" <
- for (i =vec1.begin(); i !=vec1.end(); ++i)
- cout << *i << " ";
- cout << endl;
- //显示序列的状态信息
- cout<<"vec1.size(): "<//打印成员个数
- cout<<"vec1.empty(): "<//清空
- }
push_back()是将数据放入vector(向量)或deque(双端队列)的标准函数。Insert()是一个与之类似的函数,然而它在所有容器中都可以使用,但是用法更加复杂。end()实际上是取末尾加一,以便让循环正确运行--它返回的指针指向最靠近数组界限的数据。
在Java里面也有向量的概念。Java中的向量是对象的集合。其中,各元素可以不必同类型,元素可以增加和删除,不能直接加入原始数据类型。
u 双端队列(qeque容器类):
deque(读音:deck,意即:double queue,#include)容器类与vector类似,支持随机访问和快速插入删除,它在容器中某一位置上的操作所花费的是线性时间。与vector不同的是,deque还支持从开始端插入数据:push_front()。此外deque也不支持与vector的capacity()、reserve()类似的操作。
- #include
- #include
- using namespace std;
-
- typedef deque<int> INTDEQUE;//有些人很讨厌这种定义法,呵呵
-
- //从前向后显示deque队列的全部元素
- void put_deque(INTDEQUE deque, char *name)
- {
- INTDEQUE::iterator pdeque;//仍然使用迭代器输出
- cout << "The contents of " << name << " : ";
- for(pdeque = deque.begin(); pdeque != deque.end(); pdeque++)
- cout << *pdeque << " ";//注意有 "*"号哦,没有"*"号的话会报错
- cout<
- }
-
- //测试deqtor容器的功能
- int main()
- {
- //deq1对象初始为空
- INTDEQUE deq1;
- //deq2对象最初有10个值为6的元素
- INTDEQUE deq2(10,6);
- //声明一个名为i的双向迭代器变量
- INTDEQUE::iterator i;
- //从前向后显示deq1中的数据
- put_deque(deq1,"deq1");
- //从前向后显示deq2中的数据
- put_deque(deq2,"deq2");
- //从deq1序列后面添加两个元素
- deq1.push_back(2);
- deq1.push_back(4);
- cout<<"deq1.push_back(2) and deq1.push_back(4):"<
- put_deque(deq1,"deq1");
- //从deq1序列前面添加两个元素
- deq1.push_front(5);
- deq1.push_front(7);
- cout<<"deq1.push_front(5) and deq1.push_front(7):"<
- put_deque(deq1,"deq1");
- //在deq1序列中间插入数据
- deq1.insert(deq1.begin()+1,3,9);
- cout<<"deq1.insert(deq1.begin()+1,3,9):"<
- put_deque(deq1,"deq1");
- //测试引用类函数
- cout<<"deq1.at(4)="<
- cout<<"deq1[4]="<
- deq1.at(1)=10;
- deq1[2]=12;
- cout<<"deq1.at(1)=10 and deq1[2]=12 :"<
- put_deque(deq1,"deq1");
- //从deq1序列的前后各移去一个元素
- deq1.pop_front();
- deq1.pop_back();
- cout<<"deq1.pop_front() and deq1.pop_back():"<
- put_deque(deq1,"deq1");
- //清除deq1中的第2个元素
- deq1.erase(deq1.begin()+1);
- cout<<"deq1.erase(deq1.begin()+1):"<
- put_deque(deq1,"deq1");
- //对deq2赋值并显示
- deq2.assign(8,1);
- cout<<"deq2.assign(8,1):"<
- put_deque(deq2,"deq2");
- }
上面我们演示了deque如何进行插入删除等操作,像erase(),assign()是大多数容器都有的操作。关于deque的其他操作请参阅其他书籍。
u 表(List容器类)
List(#include)又叫链表,是一种双线性列表,只能顺序访问(从前向后或者从后向前),图2是list的数据组织形式。与前面两种容器类有一个明显的区别就是:它不支持随机访问。要访问表中某个下标处的项需要从表头或表尾处(接近该下标的一端)开始循环。而且缺少下标预算符:operator[]。
图2
同时,list仍然包涵了erase(),begin(),end(),insert(),push_back(),push_front()这些基本函数,下面我们来演示一下list的其他函数功能。merge():合并两个排序列表;splice():拼接两个列表;sort():列表的排序。
- #include
- #include
- #include
- using namespace std;
-
- void PrintIt(list<int> n)
- {
- for(list<int>::iterator iter=n.begin(); iter!=n.end(); ++iter)
- cout<<*iter<<" ";//用迭代器进行输出循环
- }
-
- int main()
- {
- list<int> listn1,listn2; //给listn1,listn2初始化
- listn1.push_back(123);
- listn1.push_back(0);
- listn1.push_back(34);
- listn1.push_back(1123); //now listn1:123,0,34,1123
- listn2.push_back(100);
- listn2.push_back(12); //now listn2:12,100
- listn1.sort();
- listn2.sort(); //给listn1和listn2排序
- //now listn1:0,34,123,1123 listn2:12,100
- PrintIt(listn1);
- cout<
- PrintIt(listn2);
- listn1.merge(listn2); //合并两个排序列表后,listn1:0,12,34,100,123,1123
- cout<
- PrintIt(listn1);
- }
上面并没有演示splice()函数的用法,这是一个拗口的函数。用起来有点麻烦。图3所示是splice函数的功能。将一个列表插入到另一个列表当中。list容器类定义了splice()函数的3个版本:
splice(position,list_value);
splice(position,list_value,ptr);
splice(position,list_value,first,last);
list_value是一个已存在的列表,它将被插入到源列表中,position是一个迭代参数,他当前指向的是要进行拼接的列表中的特定位置。
图3
listn1:123,0,34,1123 listn2:12,100
执行listn1.splice(find(listn1.begin(),listn1.end(),0),listn2);之后,listn1将变为:123,12,100,34,1123。即把listn2插入到listn1的0这个元素之前。其中,find()函数找到0这个元素在listn1中的位置。值得注意的是,在执行splice之后,list_value将不复存在了。这个例子中是listn2将不再存在。
第二个版本当中的ptr是一个迭代器参数,执行的结果是把ptr所指向的值直接插入到position当前指向的位置之前.这将只向源列表中插入一个元素。
第三个版本的first和last也是迭代器参数,并不等于list_value.begin(),list_value.end()。First指的是要插入的列的第一个元素,last指的是要插入的列的最后一个元素。
如果listn1:123,0,34,1123 listn2:12,43,87,100 执行完以下函数之后
listn1.splice(find(listn1.begin(),listn1.end(),0),++listn2.begin(),--listn2.end());
listn1:123,43,87,0,34,1123 listn2:12,100
以上,我们学习了vector,deque,list三种基本顺序容器,其他的顺序容器还有:slist,bit_vector等等。
u 集和多集(set 和multiset 容器类):
一个集合(#include)是一个容器,它其中所包含的元素的值是唯一的。这在收集一个数据的具体值的时候是有用的。集合中的元素按一定的顺序排列,并被作为集合中的实例。如果你需要一个键/值对(pair)来存储数据,map(也是一个关联容器,后面将马上要讲到)是一个更好的选择。一个集合通过一个链表来组织,在插入操作和删除操作上比向量(vector)快,但查找或添加末尾的元素时会有些慢。
在集中,所有的成员都是排列好的。如果先后往一个集中插入:12,2,3,123,5,65 则输出该集时为:2,3,5,12,65,123
集和多集的区别是:set支持唯一键值,set中的值都是特定的,而且只出现一次;而multiset中可以出现副本键,同一值可以出现多次。
Set和multiset的模板参数:
template
第一个参数key是所存储的键的类型,第二个参数是为排序值而定义的比较函数的类型,第三个参数是被实现的存储分配符的类型。在有些编译器的具体实现中,第三个参数可以省略。第二个参数使用了合适形式的迭代器为键定义了特定的关系操作符,并用来在容器中遍历值时建立顺序。集的迭代器是双向,同时也是常量的,所以迭代器在使用的时候不能修改元素的值。
Set定义了三个构造函数:
默认构造函数:
explicit set(const Compare&=compare());
如:set > set1;
less是一个标准类,用于形成降序排列函数对象。升序排列是用greater。通过指定某一预先定义的区间来初始化set对象的构造函数:
template set(InputIterator, InputIterator,/ const Compare&=compare());
如:set >set2(vector1.begin(),vector1.end());
复制构造函数:
set(const set);
如:set >set3(set2);
下面我们来看一个简单的集和多集的插入例程:
- #include
- #include
- using namespace std;
-
- int main()
- {
- set<int> set1;
- for(int i=0; i<10; ++i)
- set1.insert(i);
- for(set<int>::iterator p=set1.begin();p!=set1.end();++p)
- cout<<*p<<"";
- if(set1.insert(3).second)//把3插入到set1中
- //插入成功则set1.insert(3).second返回1,否则返回0
- //此例中,集中已经有3这个元素了,所以插入将失败
- cout<<"set insert success";
- else
- cout<<"set insert failed";
- int a[] = {4, 1, 1, 1, 1, 1, 0, 5, 1, 0};
- multiset<int> A;
- A.insert(set1.begin(),set1.end());
- A.insert(a,a+10);
- cout<
- for(multiset<int>::iterator p=A.begin();p!=A.end();++p)
- cout<<*p<<" ";
- return 0;
- }
u 映射和多重映射(map 和multimap)
映射和多重映射(#include
下面的例程说明了map中键与值的关系。
#include
#include
using namespace std;
int main()
{
map > map1;
map >::iterator mapIter;
//char 是键的类型,int是值的类型
//下面是初始化,与数组类似
//也可以用map1.insert(map >::value_type(''c'',3));
map1['c']=3;
map1['d']=4;
map1['a']=1;
map1['b']=2;
for(mapIter=map1.begin();mapIter!=map1.end();++mapIter)
cout<<" "<<(*mapIter).first<<": "<<(*mapIter).second;
//first对应定义中的char键,second对应定义中的int值
//检索对应于d键的值是这样做的:
map >::const_iterator ptr;
ptr=map1.find('d');
cout<<'/n'<<" "<<(*ptr).first<<" 键对应于值:"<<(*ptr).second;
return 0;
}
从以上例程中,我们可以看到map对象的行为和一般数组的行为类似。Map允许两个或多个值使用比较操作符。下面我们再看看multimap:
- #include
- #include
- #include
- using namespace std;
-
- int main()
- {
- multimap >mulmap;
- multimap >::iterator p;
- //初始化多重映射mulmap:
- typedef multimap >::value_type vt;
- typedef string s;
- mulmap.insert(vt(s("Tom "),s("is a student")));
- mulmap.insert(vt(s("Tom "),s("is a boy")));
- mulmap.insert(vt(s("Tom "),s("is a bad boy of blue!")));
- mulmap.insert(vt(s("Jerry "),s("is a student")));
- mulmap.insert(vt(s("Jerry "),s("is a beatutiful girl")));
- mulmap.insert(vt(s("DJ "),s("is a student")));
- //输出初始化以后的多重映射mulmap:
- for(p=mulmap.begin();p!=mulmap.end();++p)
- cout<<(*p).first<<(*p).second<
- //检索并输出Jerry键所对应的所有的值
- cout<<"find Jerry :"<
- p=mulmap.find(s("Jerry "));
- while((*p).first=="Jerry ")
- {
- cout<<(*p).first<<(*p).second<
- ++p;
- }
- return 0;
- }
在map中是不允许一个键对应多个值的,在multimap中,不支持operator[],也就是说不支持map中允许的下标操作。
2. 算法(algorithm):
#inlcude
STL中算法的大部分都不作为某些特定容器类的成员函数,他们是泛型的,每个算法都有处理大量不同容器类中数据的使用。值得注意的是,STL中的算法大多有多种版本,用户可以依照具体的情况选择合适版本。中在STL的泛型算法中有4类基本的算法:
变序型队列算法:可以改变容器内的数据;
非变序型队列算法:处理容器内的数据而不改变他们;
排序值算法:包涵对容器中的值进行排序和合并的算法,还有二叉搜索算法、通用数值算法。(注:STL的算法并不只是针对STL容器,对一般容器也是适用的。)
变序型队列算法:又叫可修改的序列算法。这类算法有复制(copy)算法、交换(swap)算法、替代(replace)算法、删除(clear)算法,移动(remove)算法、翻转(reverse)算法等等。这些算法可以改变容器中的数据(数据值和值在容器中的位置)。
下面介绍2个比较常用的算法reverse()和copy()。
- #include
- #include
- #include
- //下面用到了输出迭代器ostream_iterator
- using namespace std;
-
- int main()
- {
- int arr[6]={1,12,3,2,1215,90};
- int arr1[7];
- int arr2[6]={2,5,6,9,0,-56};
- copy(arr,(arr+6),arr1);//将数组aar复制到arr1
- cout<<"arr[6] copy to arr1[7],now arr1: "<
- for(int i=0;i<7;i++)
- cout<<" "<
- reverse(arr,arr+6);//将排好序的arr翻转
- cout<<'/n'<<"arr reversed ,now arr:"<
- copy(arr,arr+6,ostream_iterator<int>(cout, " "));//复制到输出迭代器
- swap_ranges(arr,arr+6,arr2);//交换arr和arr2序列
- cout<<'/n'<<"arr swaped to arr2,now arr:"<
- copy(arr,arr+6,ostream_iterator<int>(cout, " "));
- cout<<'/n'<<"arr2:"<
- copy(arr2,arr2+6,ostream_iterator<int>(cout, " "));
- return 0;
- }
revese()的功能是将一个容器内的数据顺序翻转过来,它的原型是:
template
void reverse(Bidirectional first, Bidirectional last);
将first和last之间的元素翻转过来,上例中你也可以只将arr中的一部分进行翻转:
reverse(arr+3,arr+6); 这也是有效的。First和last需要指定一个操作区间。
Copy()是要将一个容器内的数据复制到另一个容器内,它的原型是:
Template
OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result);
它把[first,last-1]内的队列成员复制到区间[result,result+(last-first)-1]中。泛型交换算法:
Swap()操作的是单值交换,它的原型是:
template
void swap(T& a,T& b);
swap_ranges()操作的是两个相等大小区间中的值,它的原型是:
template
ForwardIterator2swap_ranges(ForwardIterator1 first1,ForwardIterator1 last1, ForwardIterator1 first2);
交换区间[first1,last1-1]和[first2, first2+(last1-first1)-1]之间的值,并假设这两个区间是不重叠的。
非变序型队列算法,又叫不可修改的序列算法。这一类算法操作不影响其操作的容器的内容,包括搜索队列成员算法,等价性检查算法,计算队列成员个数的算法。我将用下面的例子介绍其中的find(),search(),count():
- #include
- #include
- #include
- using namespace std;
-
- int main()
- {
- int a[10]={12,31,5,2,23,121,0,89,34,66};
- vector<int> v1(a,a+10);
- vector<int>::iterator result1,result2;//result1和result2是随机访问迭代器
- result1=find(v1.begin(),v1.end(),2);
- //在v1中找到2,result1指向v1中的2
- result2=find(v1.begin(),v1.end(),8);
- //在v1中没有找到8,result2指向的是v1.end()
- cout<//3-0=3或4-1=3,屏幕结果是3
- cout<
- int b[9]={5,2,23,54,5,5,5,2,2};
- vector<int> v2(a+2,a+8);
- vector<int> v3(b,b+4);
- result1=search(v1.begin(),v1.end(),v2.begin(),v2.end());
- cout<<*result1<
- //在v1中找到了序列v2,result1指向v2在v1中开始的位置
- result1=search(v1.begin(),v1.end(),v3.begin(),v3.end());
- cout<<*(result1-1)<
- //在v1中没有找到序列v3,result指向v1.end(),屏幕打印出v1的最后一个元素66
- vector<int> v4(b,b+9);
- int i=count(v4.begin(),v4.end(),5);
- int j=count(v4.begin(),v4.end(),2);
- cout<<"there are "<" members in v4 equel to 5"<
- cout<<"there are "<" members in v4 equel to 2"<
- //计算v4中有多少个成员等于 5,2
- return 0;
- }
find()的原型是:
template
InputIterator find(InputIterator first, InputIterator last, const EqualityComparable& value);
其功能是在序列[first,last-1]中查找value值,如果找到,就返回一个指向value在序列中第一次出现的迭代,如果没有找到,就返回一个指向last的迭代(last并不属于序列)。
search()的原型是:
template
ForwardIterator1 search(ForwardIterator1 first1, ForwardIterator1 last1, ForwardIterator2 first2, ForwardIterator2 last2);
其功能是在源序列[first1,last1-1]查找目标序列[first2,last2-1]如果查找成功,就返回一个指向源序列中目标序列出现的首位置的迭代。查找失败则返回一个指向last的迭代。
Count()的原型是:
template
iterator_traits::difference_type count(InputIterator first,
InputIterator last, const EqualityComparable& value);
其功能是在序列[first,last-1]中查找出等于value的成员,返回等于value得成员的个数。
排序算法(sort algorithm):这一类算法很多,功能强大同时也相对复杂一些。这些算法依赖的是关系运算。在这里我只介绍其中比较简单的几种排序算法:sort(),merge(),includes()
- #include
- #include
- using namespace std;
-
- int main()
- {
- int a[10]={12,0,5,3,6,8,9,34,32,18};
- int b[5]={5,3,6,8,9};
- int d[15];
- sort(a,a+10);
- for(int i=0;i<10;i++)
- cout<<" "<
- sort(b,b+5);
- if(includes(a,a+10,b,b+5))
- cout<<'/n'<<"sorted b members are included in a."<
- else
- cout<<"sorted a dosn`t contain sorted b!";
- merge(a,a+10,b,b+5,d);
- for(int j=0;j<15;j++)
- cout<<" "<
- return 0;
- }
sort()的原型是:
template
void sort(RandomAccessIterator first, RandomAccessIterator last);
功能是对[first,last-1]区间内的元素进行排序操作。与之类似的操作还有:partial_sort(), stable_sort(),partial_sort_copy()等等。
merge()的原型是:
template
OutputIterator merge(InputIterator1 first1, InputIterator1 last1,InputIterator2 first2, InputIterator2 st2,OutputIterator result);
将有序区间[first1,last1-1]和[first2,last2-1]合并到[result, result + (last1 - first1) + (last2 - first2)-1]区间内。
Includes()的原型是:
template
bool includes(InputIterator1 first1, InputIterator1 last1, InputIterator2 first2, InputIterator2 last2);
其功能是检查有序区间[first2,last2-1]内元素是否都在[first1,last1-1]区间内,返回一个bool值。
通用数值算法(generalized numeric algorithms):这一类算法还不多,涉及到专业领域中有用的算术操作,独立包涵于头文件中。
STL中的算法大都有多种版本,常见的版本有以下4中:
默认版本,假设给出了特定操作符;
一般版本,使用了成员提供的操作符;
复制版本,对原队列的副本进行操作,常带有 _copy 后缀;
谓词版本,只应用于满足给定谓词的队列成员,常带有 _if 后缀;
以上我们学习了STL容器和算法的概念,以及一些简单的STL容器和算法。在使用算法处理容器内的数据时,需要从一个数据成员移向另一个数据成员,迭代器恰好实现了这一功能。下面我们来学习STL迭代器 。
3. 迭代器(itertor):
#include
迭代器实际上是一种泛化指针,如果一个迭代器指向了容器中的某一成员,那么迭代器将可以通过自增自减来遍历容器中的所有成员。迭代器是联系容器和算法的媒介,是算法操作容器的接口。在运用算法操作容器的时候,我们常常在不知不觉中已经使用了迭代器。
STL中定义了6种迭代器:
输入迭代器,在容器的连续区间内向前移动,可以读取容器内任意值;
输出迭代器,把值写进它所指向的队列成员中;
前向迭代器,读取队列中的值,并可以向前移动到下一位置(++p,p++);
双向迭代器,读取队列中的值,并可以向前向后遍历容器;
随机访问迭代器, vector::iterator,list::iterator等都是这种迭代器 ;
流迭代器,可以直接输出、输入流中的值;
实际上,在前面的例子中,我们不停的在用迭代器。下面我们用几个例子来帮助理解这些迭代器的用法。
下面的例子用到了输入输出迭代器:
- #include
- #include
- #include
- #include
- #include
- using namespace std;
-
- int main()
- {
- vector v1;
- ifstream file("Text1.txt");
- if(file.fail())
- {
- cout<<"open file Text1.txt failed"<
- return 1;
- }
- copy(istream_iterator(file),istream_iterator(),inserter(v1,v1.begin()));
- copy(v1.begin(),v1.end(),ostream_iterator(cout," "));
- cout<
- return 0;
- }
这里用到了输入迭代器istream_iterator,输出迭代器ostream_iterator。程序完成了将一个文件输出到屏幕的功能,先将文件读入,然后通过输入迭代器把文件内容复制到类型为字符串的向量容器内,最后由输出迭代器输出。Inserter是一个输入迭代器的一个函数(迭代器适配器),它的使用方法是:
inserter (container ,pos);
container是将要用来存入数据的容器,pos是容器存入数据的开始位置。上例中,是把文件内容存入(copy())到向量v1中。
4. STL的其他标准组件
函数对象(functor或者funtion objects)
#include
函数对象又称之为仿函数。函数对象将函数封装在一个对象中,使得它可作为参数传递给合适的STL算法,从而使算法的功能得以扩展。可以把它当作函数来使用。用户也可以定义自己的函数对象。下面让我们来定义一个自己的函数对象.
- #include
- using namespace std;
-
- struct int_max{
- int operator()(int x,int y){return x>y?x:y; }
- };//operator() 重载了"()", (int x,int y)是参数列表
-
- int main()
- {
- cout<
- return 0;
- }
这里的int_max()就是一个函数对象,struct关键字也可以用class来代替,只不过struct默认情况下是公有访问权限,而class定义的是默认私有访问权限。下面我们来定义一个STL风格的函数对象:
- #include
- #include
- using namespace std;
-
- struct adder : public unary_function<double, void>
- {
- adder() : sum(0) {}
- double sum;
- void operator()(double x) { sum += x; }
- };
-
- int main()
- {
- double a[5]={0.5644,1.1,6.6,8.8,9.9};
- vector<double> V(a,a+5);
- adder result = for_each(V.begin(), V.end(), adder());
- cout << "The sum is " << result.sum << endl;
- return 0;
- }
在这里,我们定义了一个函数对象adder(),这也是一个类,它的基类是unary_function函数对象。unary_function是一个空基类,不包涵任何操作或变量。只是一种格式说明,它有两个参数,第一个参数是函数对象的使用数据类型,第二个参数是它的返回类型。基于它所定义的函数对象是一元函数对象。(注:用关键字struct或者class定义的类型实际上都是"类")
STL内定义了各种函数对象,否定器、约束器、一元谓词、二元谓词都是常用的函数对象。函数对象对于编程来说很重要,因为他如同对象类型的抽象一样作用于操作。
适配器(adapter)
适配器是用来修改其他组件接口的STL组件,是带有一个参数的类模板(这个参数是操作的值的数据类型)。STL定义了3种形式的适配器:容器适配器,迭代器适配器,函数适配器。
容器适配器:包括栈(stack)、队列(queue)、优先(priority_queue)。使用容器适配器,stack就可以被实现为基本容器类型(vector,dequeue,list)的适配。可以把stack看作是某种特殊的vctor、deque或者list容器,只是其操作仍然受到stack本身属性的限制。queue和priority_queue与之类似。容器适配器的接口更为简单,只是受限比一般容器要多;
迭代器适配器:修改为某些基本容器定义的迭代器的接口的一种STL组件。反向迭代器和插入迭代器都属于迭代器适配器,迭代器适配器扩展了迭代器的功能;
函数适配器:通过转换或者修改其他函数对象使其功能得到扩展。这一类适配器有否定器(相当于"非"操作)、帮定器、函数指针适配器。
堆栈与函数调用
1) 在栈上创建。在执行函数时,函数内局部变量的存储单元都在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,一般使用寄存器来存取,效率很高,但是分配的内存容量有限。
2) 从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete来释放内存。动态内存的生存期由程序员自己决定,使用非常灵活。
3) 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
4) 文字常量分配在文字常量区,程序结束后由系统释放。
5)程序代码区。
经典实例:(代码来自网络高手,没有找到原作者)
 Code
Code
#i nclude <string>
int a=0; //全局初始化区
char *p1; //全局未初始化区
void main()
{
int b;//栈
char s[]="abc"; //栈
char *p2; //栈
char *p3="123456"; //123456/0在常量区,p3在栈上。
static int c=0; //全局(静态)初始化区
p1 = (char*)malloc(10);
p2 = (char*)malloc(20); //分配得来得10和20字节的区域就在堆区。
strcpy(p1,"123456"); //123456/0放在常量区,编译器可能会将它与p3所向"123456/0"优化成一个地方。
}
二 三种内存对象的比较
栈对象的优势是在适当的时候自动生成,又在适当的时候自动销毁,不需要程序员操心;而且栈对象的创建速度一般较堆对象快,因为分配堆对象时,会调用operator new操作,operator new会采用某种内存空间搜索算法,而该搜索过程可能是很费时间的,产生栈对象则没有这么麻烦,它仅仅需要移动栈顶指针就可以了。但是要注意的是,通常栈空间容量比较小,一般是1MB~2MB,所以体积比较大的对象不适合在栈中分配。特别要注意递归函数中最好不要使用栈对象,因为随着递归调用深度的增加,所需的栈空间也会线性增加,当所需栈空间不够时,便会导致栈溢出,这样就会产生运行时错误。
堆对象创建和销毁都要由程序员负责,所以,如果处理不好,就会发生内存问题。如果分配了堆对象,却忘记了释放,就会产生内存泄漏;而如 果已释放了对象,却没有将相应的指针置为NULL,该指针就是所谓的“悬挂指针”,再度使用此指针时,就会出现非法访问,严重时就导致程序崩溃。但是高效的使用堆对象也可以大大的提高代码质量。比如,我们需要创建一个大对象,且需要被多个函数所访问,那么这个时候创建一个堆对象无疑是良好的选择,因为我们通过在各个函数之间传递这个堆对象的指针,便可以实现对该对象的共享,相比整个对象的传递,大大的降低了对象的拷贝时间。另外,相比于栈空间,堆的容量要大得多。实际上,当物理内存不够时,如果这时还需要生成新的堆对象,通常不会产生运行时错误,而是系统会使用虚拟内存来扩展实际的物理内存。
静态存储区。所有的静态对象、全局对象都于静态存储区分配。关于全局对象,是在main()函数执行前就分配好了的。其实,在main()函数中的显示代 码执行之前,会调用一个由编译器生成的_main()函数,而_main()函数会进行所有全局对象的的构造及初始化工作。而在main()函数结束之 前,会调用由编译器生成的exit函数,来释放所有的全局对象。比如下面的代码:
| void main(void)
{
… …// 显式代码
} |
实际上,被转化成这样:
| void main(void)
{
_main(); //隐式代码,由编译器产生,用以构造所有全局对象
… … // 显式代码
… …
exit() ; // 隐式代码,由编译器产生,用以释放所有全局对象
} |
除了全局静态对象,还有局部静态对象通和class的静态成员,局部静态对象是在函数中定义的,就像栈对象一样,只不过,其前面多了个static关键字。局部静态对象的生命期是从其所在函数第一次被调用,更确切地说,是当第一次执行到该静态对象的声明代码时,产生该静态局部对象,直到整个程序结束时,才销毁该对象。class的静态成员的生命周期是该class的第一次调用到程序的结束。
三 函数调用与堆栈
1)编译器一般使用栈来存放函数的参数,局部变量等来实现函数调用。有时候函数有嵌套调用,这个时候栈中会有多个函数的信息,每个函数占用一个连续的区域。一个函数占用的区域被称作帧()。同时栈是线程独立的,每个线程都有自己的栈。例如下面简单的函数调用:
另外函数堆栈的清理方式决定了当函数调用结束时由调用函数或被调用函数来清理函数帧,在VC中对函数栈的清理方式由两种:
| |
参数传递顺序 |
谁负责清理参数占用的堆栈 |
| __stdcall |
从右到左 |
被调函数 |
| __cdecl |
从右到左 |
调用者 |
2) 有了上面的知识为铺垫,我们下面细看一个函数的调用时堆栈的变化:
代码如下:
Code
int Add(int x, int y)
{
return x + y;
}
void main()
{
int *pi = new int(10);
int *pj = new int(20);
int result = 0;
result = Add(*pi,*pj);
delete pi;
delete pj;
}
对上面的代码,我们分为四步,当然我们只画出了我们的代码对堆栈的影响,其他的我们假设它们不存在,哈哈!
第一,int *pi = new int(10); int *pj = new int(20); int result = 0; 堆栈变化如下:
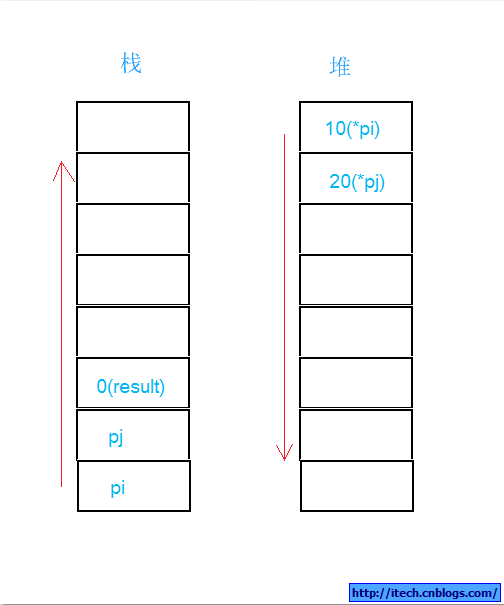
第二,Add(*pi,*pj);堆栈如下:
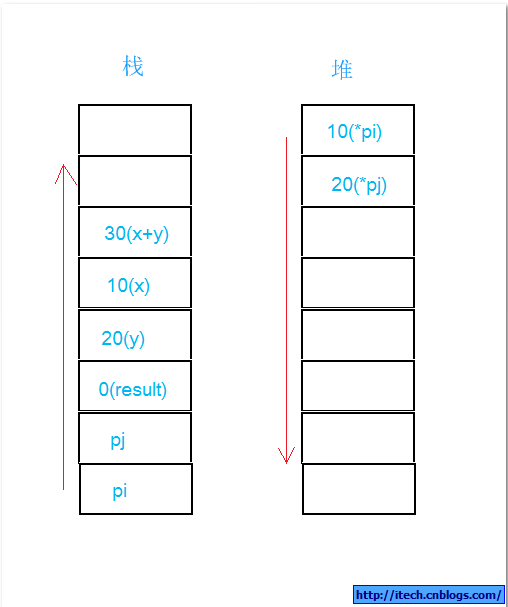
第三,将Add的结果给result,堆栈如下:

第四,delete pi; delete pj; 堆栈如下:

第五,当main()退出后,堆栈如下,等同于main执行前,哈哈!
①编译器在后台为每个包含虚函数的类产生一个静态函数指针数组(虚函数表vtbl),在这个类或者它的基类中定义的每一个虚函数都有一个相应的函数指针。
②每个包含虚函数的类的每一个实例包含一个不可见的数据成员vptr(虚函数指针),这个指针被构造函数自动初始化,指向类的vtbl(虚函数表)
③当客户调用虚函数的时候,编译器产生代码反指向到vptr,索引到vtbl中,然后在指定的位置上找到函数指针,并发出调用。
2、揭密晚绑定的秘密
编译器到底做了什么实现的虚函数的晚绑定呢?我们来探个究竟。
编译器对每个包含虚函数的类创建一个表(称为V TA B L E)。在V TA B L E中,编译器放置特定类的虚函数地址。在每个带有虚函数的类中,编译器秘密地置一指针,称为v p o i n t e r(缩写为V P T R),指向这个对象的V TA B L E。通过基类指针做虚函数调用时(也就是做多态调用时),编译器静态地插入取得这个V P T R,并在V TA B L E表中查找函数地址的代码,这样就能调用正确的函数使晚捆绑发生。为每个类设置V TA B L E、初始化V P T R、为虚函数调用插入代码,所有这些都是自动发生的,所以我们不必担心这些。利用虚函数,这个对象的合适的函数就能被调用,哪怕在编译器还不知道这个对象的特定类型的情况下。(《C++编程思想》)
那我们来看看编译器是怎么建立VPTR指向的这个虚函数表的。先看下面两个类:
class base
{
public:
void bfun(){}
virtual void vfun1(){}
virtual int vfun2(){}
private:
int a;
}
class derived : public base
{
public:
void dfun(){}
virtual void vfun1(){}
virtual int vfun3(){}
private:
int b;
}
两个类VPTR指向的虚函数表(VTABLE)分别如下:
base类
——————
VPTR——> |&base::vfun1 |
——————
|&base::vfun2 |
——————
derived类
———————
VPTR——> |&derived::vfun1 |
———————
|&base::vfun2 |
———————
|&derived::vfun3 |
———————
每当创建一个包含有虚函数的类或从包含有虚函数的类派生一个类时,编译器就为这个类创建一个VTABLE,如上图所示。在这个表中,编译器放置了在这个类中或在它的基类中所有已声明为virtual的函数的地址。如果在这个派生类中没有对在基类中声明为virtual的函数进行重新定义,编译器就使用基类的这个虚函数地址。(在derived的VTABLE中,vfun2的入口就是这种情况。)然后编译器在这个类中放置VPTR。当使用简单继承时,对于每个对象只有一个VPTR。VPTR必须被初始化为指向相应的VTABLE,这在构造函数中发生。
一旦VPTR被初始化为指向相应的VTABLE,对象就"知道"它自己是什么类型。但只有当虚函数被调用时这种自我认知才有用。
VPTR常常位于对象的开头,编译器能很容易地取到VPTR的值,从而确定VTABLE的位置。VPTR总指向VTABLE的开始地址,所有基类和它的子类的虚函数地址(子类自己定义的虚函数除外)在VTABLE中存储的位置总是相同的,如上面base类和derived类的VTABLE中vfun1和vfun2的地址总是按相同的顺序存储。编译器知道vfun1位于VPTR处,vfun2位于VPTR+1处,因此在用基类指针调用虚函数时,编译器首先获取指针指向对象的类型信息(VPTR),然后就去调用虚函数。如一个base类指针pBase指向了一个derived对象,那pBase->vfun2()被编译器翻译为 VPTR+1 的调用,因为虚函数vfun2的地址在VTABLE中位于索引为1的位置上。同理,pBase->vfun3()被编译器翻译为 VPTR+2的调用。这就是所谓的晚绑定。
我们来看一下虚函数调用的汇编代码,以加深理解。
void test(base* pBase)
{
pBase->vfun2();
}
int main(int argc, char* argv[])
{
derived td;
test(&td);
return 0;
}
derived td;编译生成的汇编代码如下:
mov DWORD PTR _td$[esp+24], OFFSET FLAT:??_7derived@@6B@ ; derived::`vftable'
由编译器的注释可知,此时PTR _td$[esp+24]中存储的就是derived类的VTABLE地址。
test(&td);编译生成的汇编代码如下:
lea eax, DWORD PTR _td$[esp+24]
mov DWORD PTR __$EHRec$[esp+32], 0
push eax
call ?test@@YAXPAVbase@@@Z ; test
调用test函数时完成了如下工作:取对象td的地址,将其压栈,然后调用test。
pBase->vfun2();编译生成的汇编代码如下:
mov ecx, DWORD PTR _pBase$[esp-4]
mov eax, DWORD PTR [ecx]
jmp DWORD PTR [eax+4]
首先从栈中取出pBase指针指向的对象地址赋给ecx,然后取对象开头的指针变量中的地址赋给eax,此时eax的值即为VPTR的值,也就是 VTABLE的地址。最后就是调用虚函数了,由于vfun2位于VTABLE的第二个位置,相当于 VPTR+1,每个函数指针是4个字节长,所以最后的调用被编译器翻译为 jmp DWORD PTR [eax+4]。如果是调用pBase->vfun1(),这句就该被编译为 jmp DWORD PTR [eax]。
overload 与override的区别
C++的方法Overload机制只能在一个类内部扩展方法名的用途,这一点与Java不同,需要注意,下面自己写了一个小程序以展示,其中顺便也提到了OverRide。
为什么提到OverRide呢,其实我觉得这两者都是用Open-Close原理在语言设计上的具体应用,一个在横向上扩展某个函数名的用途,一个在纵向上扩展某个函数签名的用途。
代码如下,VC++2005验证过:
类型声明代码LoadRide.h如下:
#pragma once
class Base{
public:
int A(int);
int A(char*);
virtual int B(int);
virtual int B(char*);
char C(float);
};
class LoadRide:public Base
{
public:
LoadRide(void);
~LoadRide(void);
char A(float); //这里打开,Base的两个A方法就被遮盖了
virtual int B(int);
};
实体定义代码LoadRide.cpp如下:
#include "LoadRide.h"
#include
int Base::A(int j){
printf("您对Base::int@A@int输入了int值:%i /n",j);
return j;
}
int Base::A(char* c){
printf("您对Base::int@A@char*输入了指针,它指向地址:%p /n",c);
//c++; //危险,这个函数的使用者很可能输入一个引用进来
return *c;
}
int Base::B(int j){
printf("您对Base::int@B@int输入了int值:%i /n",j);
return j;
}
int Base::B(char* c){
printf("您对Base::int@B@char*输入了指针,指向地址:%p /n",c);
//c++; //危险,这个函数的使用者很可能输入一个引用进来
return *c;
}
LoadRide::LoadRide(void)
{
}
LoadRide::~LoadRide(void)
{
}
char LoadRide::A(float f){
printf("您对LoadRide::int@C@char*输入了浮点数:%f /n",f);
return 'c';
}
char Base::C(float f){
printf("您对Base::int@C@char*输入了浮点数:%f /n",f);
return 'c';
}
int LoadRide::B(int j){
printf("您对LoadRide::int@B@int输入了int值:%i /n",j);
return j;
}
int main(){
LoadRide o;
Base* pb = &o ;
LoadRide* pl = &o;
char c = 'c';
//子类一旦用了函数名A,不论什么参数返回值,父类的A们就不能再直接调用了
//printf("%i /n", o.A(&c));
//printf("%i /n", o.A('c'));
printf("%i /n", pb->A(&c)); //但是被遮住的A却可以用父类类型的指针调用;
//printf("%i /n", pl->A(&c)); //被遮住的A们不能用子类类型的指针调用;
printf("%i /n", o.C(1.0));
printf("%i /n", pb->B(&c));
printf("%i /n", pb->B('c')); //并不是指针类型而是所指向实际对象类型来判断具体成员
pb = &(static_cast(o)); //要调用其它父类或子类override成员,要转换对象类型
printf("%i /n", pb->B('c'));
getchar();
//static_cast可以往父类cast,如果调用了子类成员,编译器会报错
//dynamic_cast只能往成员更多的子类去cast,因为运行期间必须保证对象访问的成员都存在
}
运行结果如下:
您对Base::int@A@char*输入了指针,它指向地址:0013FF33
99
您对Base::int@C@char*输入了浮点数:1.000000
99
您对Base::int@B@char*输入了指针,指向地址:0013FF33
99
您对LoadRide::int@B@int输入了int值:99
99
您对Base::int@B@int输入了int值:99
99
虚函数表解析
对C++ 了解的人都应该知道虚函数(Virtual Function)是通过一张虚函数表(Virtual Table)来实现的。简称为V-Table。在这个表中,主是要一个类的虚函数的地址表,这张表解决了继承、覆盖的问题,保证其容真实反应实际的函数。这样,在有虚函数的类的实例中这个表被分配在了这个实例的内存中,所以,当我们用父类的指针来操作一个子类的时候,这张虚函数表就显得由为重要了,它就像一个地图一样,指明了实际所应该调用的函数。
这里我们着重看一下这张虚函数表。C++的编译器应该是保证虚函数表的指针存在于对象实例中最前面的位置(这是为了保证取到虚函数表的有最高的性能——如果有多层继承或是多重继承的情况下)。 这意味着我们通过对象实例的地址得到这张虚函数表,然后就可以遍历其中函数指针,并调用相应的函数。
听我扯了那么多,我可以感觉出来你现在可能比以前更加晕头转向了。 没关系,下面就是实际的例子,相信聪明的你一看就明白了。
假设我们有这样的一个类:
class Base {
public:
virtual void f() { cout << "Base::f" << endl; }
virtual void g() { cout << "Base::g" << endl; }
virtual void h() { cout << "Base::h" << endl; }
};
按照上面的说法,我们可以通过Base的实例来得到虚函数表。 下面是实际例程:
typedef void(*Fun)(void);
Base b;
Fun pFun = NULL;
cout << "虚函数表地址:" << (int*)(&b) << endl;
cout << "虚函数表 — 第一个函数地址:" << (int*)*(int*)(&b) << endl;
// Invoke the first virtual function
pFun = (Fun)*((int*)*(int*)(&b));
pFun();
实际运行经果如下:(Windows XP+VS2003, Linux 2.6.22 + GCC 4.1.3)
虚函数表地址:0012FED4
虚函数表 — 第一个函数地址:0044F148
Base::f
通过这个示例,我们可以看到,我们可以通过强行把&b转成int *,取得虚函数表的地址,然后,再次取址就可以得到第一个虚函数的地址了,也就是Base::f(),这在上面的程序中得到了验证(把int*强制转成了函数指针)。通过这个示例,我们就可以知道如果要调用Base::g()和Base::h(),其代码如下:
(Fun)*((int*)*(int*)(&b)+0); // Base::f()
(Fun)*((int*)*(int*)(&b)+1); // Base::g()
(Fun)*((int*)*(int*)(&b)+2); // Base::h()
这个时候你应该懂了吧。什么?还是有点晕。也是,这样的代码看着太乱了。没问题,让我画个图解释一下。如下所示:
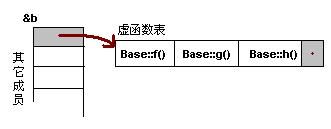
注意:在上面这个图中,我在虚函数表的最后多加了一个结点,这是虚函数表的结束结点,就像字符串的结束符“/0”一样,其标志了虚函数表的结束。这个结束标志的值在不同的编译器下是不同的。在WinXP+VS2003下,这个值是NULL。而在Ubuntu 7.10 + Linux 2.6.22 + GCC 4.1.3下,这个值是如果1,表示还有下一个虚函数表,如果值是0,表示是最后一个虚函数表。
下面,我将分别说明“无覆盖”和“有覆盖”时的虚函数表的样子。没有覆盖父类的虚函数是毫无意义的。我之所以要讲述没有覆盖的情况,主要目的是为了给一个对比。在比较之下,我们可以更加清楚地知道其内部的具体实现。
一般继承(无虚函数覆盖)
下面,再让我们来看看继承时的虚函数表是什么样的。假设有如下所示的一个继承关系:
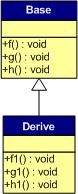
请注意,在这个继承关系中,子类没有重载任何父类的函数。那么,在派生类的实例中,其虚函数表如下所示:
对于实例:Derive d; 的虚函数表如下:
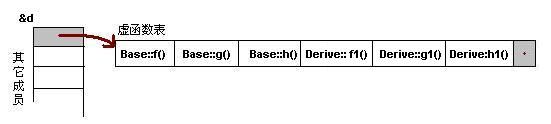
我们可以看到下面几点:
1)虚函数按照其声明顺序放于表中。
2)父类的虚函数在子类的虚函数前面。
我相信聪明的你一定可以参考前面的那个程序,来编写一段程序来验证。
一般继承(有虚函数覆盖)
覆盖父类的虚函数是很显然的事情,不然,虚函数就变得毫无意义。下面,我们来看一下,如果子类中有虚函数重载了父类的虚函数,会是一个什么样子?假设,我们有下面这样的一个继承关系。

为了让大家看到被继承过后的效果,在这个类的设计中,我只覆盖了父类的一个函数:f()。那么,对于派生类的实例,其虚函数表会是下面的一个样子:
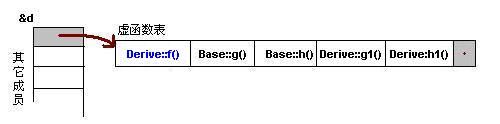
我们从表中可以看到下面几点,
1)覆盖的f()函数被放到了虚表中原来父类虚函数的位置。
2)没有被覆盖的函数依旧。
这样,我们就可以看到对于下面这样的程序,
Base *b = new Derive();
b->f();
由b所指的内存中的虚函数表的f()的位置已经被Derive::f()函数地址所取代,于是在实际调用发生时,是Derive::f()被调用了。这就实现了多态。
多重继承(无虚函数覆盖)
下面,再让我们来看看多重继承中的情况,假设有下面这样一个类的继承关系。注意:子类并没有覆盖父类的函数。
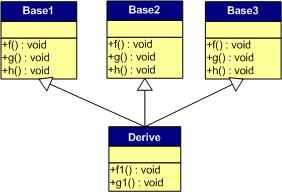
对于子类实例中的虚函数表,是下面这个样子:

我们可以看到:
1) 每个父类都有自己的虚表。
2) 子类的成员函数被放到了第一个父类的表中。(所谓的第一个父类是按照声明顺序来判断的)
这样做就是为了解决不同的父类类型的指针指向同一个子类实例,而能够调用到实际的函数。
多重继承(有虚函数覆盖)
下面我们再来看看,如果发生虚函数覆盖的情况。
下图中,我们在子类中覆盖了父类的f()函数。
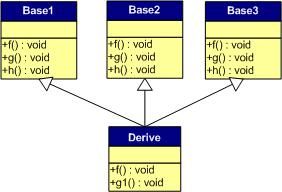
下面是对于子类实例中的虚函数表的图:

我们可以看见,三个父类虚函数表中的f()的位置被替换成了子类的函数指针。这样,我们就可以任一静态类型的父类来指向子类,并调用子类的f()了。如:
Derive d;
Base1 *b1 = &d;
Base2 *b2 = &d;
Base3 *b3 = &d;
b1->f(); //Derive::f()
b2->f(); //Derive::f()
b3->f(); //Derive::f()
b1->g(); //Base1::g()
b2->g(); //Base2::g()
b3->g(); //Base3::g()
安全性
每次写C++的文章,总免不了要批判一下C++。这篇文章也不例外。通过上面的讲述,相信我们对虚函数表有一个比较细致的了解了。水可载舟,亦可覆舟。下面,让我们来看看我们可以用虚函数表来干点什么坏事吧。
一、通过父类型的指针访问子类自己的虚函数
我们知道,子类没有重载父类的虚函数是一件毫无意义的事情。因为多态也是要基于函数重载的。虽然在上面的图中我们可以看到Base1的虚表中有Derive的虚函数,但我们根本不可能使用下面的语句来调用子类的自有虚函数:
Base1 *b1 = new Derive();
b1->f1(); //编译出错
任何妄图使用父类指针想调用子类中的未覆盖父类的成员函数的行为都会被编译器视为非法,所以,这样的程序根本无法编译通过。但在运行时,我们可以通过指针的方式访问虚函数表来达到违反C++语义的行为。(关于这方面的尝试,通过阅读后面附录的代码,相信你可以做到这一点)
二、访问non-public的虚函数
另外,如果父类的虚函数是private或是protected的,但这些非public的虚函数同样会存在于虚函数表中,所以,我们同样可以使用访问虚函数表的方式来访问这些non-public的虚函数,这是很容易做到的。
如:
class Base {
private:
virtual void f() { cout << "Base::f" << endl; }
};
class Derive : public Base{
};
typedef void(*Fun)(void);
void main() {
Derive d;
Fun pFun = (Fun)*((int*)*(int*)(&d)+0);
pFun();
}
结束语
C++这门语言是一门Magic的语言,对于程序员来说,我们似乎永远摸不清楚这门语言背着我们在干了什么。需要熟悉这门语言,我们就必需要了解C++里面的那些东西,需要去了解C++中那些危险的东西。不然,这是一种搬起石头砸自己脚的编程语言。
在文章束之前还是介绍一下自己吧。我从事软件研发有十个年头了,目前是软件开发技术主管,技术方面,主攻Unix/C/C++,比较喜欢网络上的技术,比如分布式计算,网格计算,P2P,Ajax等一切和互联网相关的东西。管理方面比较擅长于团队建设,技术趋势分析,项目管理。欢迎大家和我交流,我的MSN和Email是:[email protected]
附录一:VC中查看虚函数表
我们可以在VC的IDE环境中的Debug状态下展开类的实例就可以看到虚函数表了(并不是很完整的)
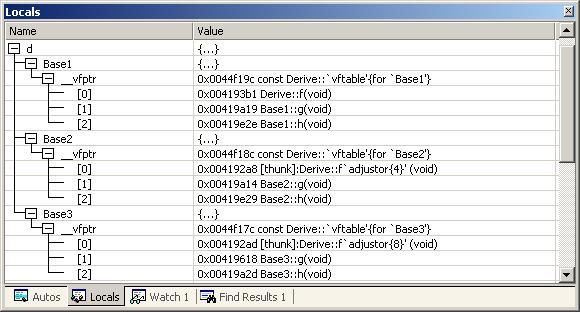
附录 二:例程
下面是一个关于多重继承的虚函数表访问的例程:
#include
using namespace std;
class Base1 {
public:
virtual void f() { cout << "Base1::f" << endl; }
virtual void g() { cout << "Base1::g" << endl; }
virtual void h() { cout << "Base1::h" << endl; }
};
class Base2 {
public:
virtual void f() { cout << "Base2::f" << endl; }
virtual void g() { cout << "Base2::g" << endl; }
virtual void h() { cout << "Base2::h" << endl; }
};
class Base3 {
public:
virtual void f() { cout << "Base3::f" << endl; }
virtual void g() { cout << "Base3::g" << endl; }
virtual void h() { cout << "Base3::h" << endl; }
};
class Derive : public Base1, public Base2, public Base3 {
public:
virtual void f() { cout << "Derive::f" << endl; }
virtual void g1() { cout << "Derive::g1" << endl; }
};
typedef void(*Fun)(void);
int main()
{
Fun pFun = NULL;
Derive d;
int** pVtab = (int**)&d;
//Base1's vtable
//pFun = (Fun)*((int*)*(int*)((int*)&d+0)+0);
pFun = (Fun)pVtab[0][0];
pFun();
//pFun = (Fun)*((int*)*(int*)((int*)&d+0)+1);
pFun = (Fun)pVtab[0][1];
pFun();
//pFun = (Fun)*((int*)*(int*)((int*)&d+0)+2);
pFun = (Fun)pVtab[0][2];
pFun();
//Derive's vtable
//pFun = (Fun)*((int*)*(int*)((int*)&d+0)+3);
pFun = (Fun)pVtab[0][3];
pFun();
//The tail of the vtable
pFun = (Fun)pVtab[0][4];
cout<
//Base2's vtable
//pFun = (Fun)*((int*)*(int*)((int*)&d+1)+0);
pFun = (Fun)pVtab[1][0];
pFun();
//pFun = (Fun)*((int*)*(int*)((int*)&d+1)+1);
pFun = (Fun)pVtab[1][1];
pFun();
pFun = (Fun)pVtab[1][2];
pFun();
//The tail of the vtable
pFun = (Fun)pVtab[1][3];
cout<
//Base3's vtable
//pFun = (Fun)*((int*)*(int*)((int*)&d+1)+0);
pFun = (Fun)pVtab[2][0];
pFun();
//pFun = (Fun)*((int*)*(int*)((int*)&d+1)+1);
pFun = (Fun)pVtab[2][1];
pFun();
pFun = (Fun)pVtab[2][2];
pFun();
//The tail of the vtable
pFun = (Fun)pVtab[2][3];
cout<
return 0;
}
C++开发必看 四种强制类型转换的总结
C风格的强制类型转换(Type Cast)很简单,不管什么类型的转换统统是:
C++风格的类型转换提供了4种类型转换操作符来应对不同场合的应用。
const_cast,字面上理解就是去const属性。
static_cast,命名上理解是静态类型转换。如int转换成char。
dynamic_cast,命名上理解是动态类型转换。如子类和父类之间的多态类型转换。
reinterpreter_cast,仅仅重新解释类型,但没有进行二进制的转换。
4种类型转换的格式,如:
TYPE B = static_cast(TYPE)(a)
const_cast
去掉类型的const或volatile属性。
struct SA {
int i;
};
const SA ra;
// ra.i = 10; // 直接修改const类型,编译错误
SA & rb = const_cast < SA &> (ra);
rb.i = 10 ;
static_cast
类似于C风格的强制转换。无条件转换,静态类型转换。用于:
1. 基类和子类之间转换:其中子类指针转换成父类指针是安全的;但父类指针转换成子类指针是不安全的。(基类和子类之间的动态类型转换建议用dynamic_cast)
2. 基本数据类型转换。enum, struct, int, char, float等。static_cast不能进行无关类型(如非基类和子类)指针之间的转换。
3. 把空指针转换成目标类型的空指针。
4. 把任何类型的表达式转换成void类型。
5. static_cast不能去掉类型的const、volitale属性(用const_cast)。
int n = 6 ;
double d = static_cast < double > (n); // 基本类型转换
int * pn = & n;
double * d = static_cast < double *> ( & n) // 无关类型指针转换,编译错误
void * p = static_cast < void *> (pn); // 任意类型转换成void类型
dynamic_cast
有条件转换,动态类型转换,运行时类型安全检查(转换失败返回NULL):
1. 安全的基类和子类之间转换。
2. 必须要有虚函数。
3. 相同基类不同子类之间的交叉转换。但结果是NULL。
class BaseClass {
public :
int m_iNum;
virtual void foo(){};
// 基类必须有虚函数。保持多台特性才能使用dynamic_cast
};
class DerivedClass: public BaseClass {
public :
char * m_szName[ 100 ];
void bar(){};
};
BaseClass * pb = new DerivedClass();
DerivedClass * pd1 = static_cast < DerivedClass *> (pb);
// 子类->父类,静态类型转换,正确但不推荐
DerivedClass * pd2 = dynamic_cast < DerivedClass *> (pb);
// 子类->父类,动态类型转换,正确
BaseClass * pb2 = new BaseClass();
DerivedClass * pd21 = static_cast < DerivedClass *> (pb2);
// 父类->子类,静态类型转换,危险!访问子类m_szName成员越界
DerivedClass * pd22 = dynamic_cast < DerivedClass *> (pb2);
// 父类->子类,动态类型转换,安全的。结果是NULL
reinterpreter_cast
仅仅重新解释类型,但没有进行二进制的转换:
1. 转换的类型必须是一个指针、引用、算术类型、函数指针或者成员指针。
2. 在比特位级别上进行转换。它可以把一个指针转换成一个整数,也可以把一个整数转换成一个指针(先把一个指针转换成一个整数,在把该整数转换成原类型的指针,还可以得到原先的指针值)。但不能将非32bit的实例转成指针。
3. 最普通的用途就是在函数指针类型之间进行转换。
4. 很难保证移植性。
int doSomething(){ return 0 ;};
typedef void ( * FuncPtr)();
// FuncPtr is 一个指向函数的指针,该函数没有参数,返回值类型为 void
FuncPtr funcPtrArray[ 10 ];
// 10个FuncPtrs指针的数组 让我们假设你希望(因为某些莫名其妙的原因)把一个指向下面函数的指针存入funcPtrArray数组:
funcPtrArray[ 0 ] = & doSomething;
// 编译错误!类型不匹配,reinterpret_cast可以让编译器以你的方法去看待它们:funcPtrArray
funcPtrArray[ 0 ] = reinterpret_cast < FuncPtr > ( & doSomething);
// 不同函数指针类型之间进行转换
总 结
去const属性用const_cast。
基本类型转换用static_cast。
多态类之间的类型转换用daynamic_cast。
不同类型的指针类型转换用reinterpreter_cast。
我们都知道,无论是用那种程序设计语言,通过强制类型转换函数 ,每个函数都可以强制将一个表达式转换成某种特定数据类型。下面介绍C++中的强制类型转换函数。
标准c++中主要有四种强制转换类型运算符:
1 static_cast
用法:static_cast < type-id > ( expression )
该运算符把expression转换为type-id类型,但没有运行时类型检查来保证转换的安全性。它主要有如下几种用法:
①用于类层次结构中基类和子类之间指针或引用的转换。
进行上行转换(把子类的指针或引用转换成基类表示)是安全的;
进行下行转换(把基类指针或引用转换成子类表示)时,由于没有动态类型检查,所以是不安全的。
②用于基本数据类型之间的转换,如把int转换成char,把int转换成enum。这种转换的安全性也要开发人员来保证。
③把空指针转换成目标类型的空指针。
④把任何类型的表达式转换成void类型。
注意:static_cast不能转换掉expression的const、volitale、或者__unaligned属性。
2 dynamic_cast
用法:dynamic_cast < type-id > ( expression )
该运算符把expression转换成type-id类型的对象。Type-id必须是类的指针、类的引用或者void *;
如果type-id是类指针类型,那么expression也必须是一个指针,如果type-id是一个引用,那么expression也必须是一个引用。
dynamic_cast主要用于类层次间的上行转换和下行转换,还可以用于类之间的交叉转换。
在类层次间进行上行转换时,dynamic_cast和static_cast的效果是一样的;
在进行下行转换时,dynamic_cast具有类型检查的功能,比static_cast更安全。
class B{
public:
int m_iNum;
virtual void foo();
};
class D:public B{
public:
char *m_szName[100];
};
void func(B *pb){
D *pd1 = static_cast(pb);
D *pd2 = dynamic_cast(pb);
}
在上面的代码段中,如果pb指向一个D类型的对象,pd1和pd2是一样的,并且对这两个指针执行D类型的任何操作都是安全的;
但是,如果pb指向的是一个B类型的对象,那么pd1将是一个指向该对象的指针,对它进行D类型的操作将是不安全的(如访问m_szName),
而pd2将是一个空指针。
另外要注意:B要有虚函数,否则会编译出错;static_cast则没有这个限制。
这是由于运行时类型检查需要运行时类型信息,而这个信息存储在类的虚函数表(
关于虚函数表的概念,详细可见)中,只有定义了虚函数的类才有虚函数表,
没有定义虚函数的类是没有虚函数表的。
另外,dynamic_cast还支持交叉转换(cross cast)。如下代码所示。
class A{
public:
int m_iNum;
virtual void f(){}
};
class B:public A{
};
class D:public A{
};
void foo(){
B *pb = new B;
pb->m_iNum = 100;
D *pd1 = static_cast(pb); //compile error
D *pd2 = dynamic_cast(pb); //pd2 is NULL
delete pb;
}
在函数foo中,使用static_cast进行转换是不被允许的,将在编译时出错;而使用 dynamic_cast的转换则是允许的,结果是空指针。
3 reinterpret_cast
用法:reinterpret_cast (expression)
type-id必须是一个指针、引用、算术类型、函数指针或者成员指针。
它可以把一个指针转换成一个整数,也可以把一个整数转换成一个指针(先把一个指针转换成一个整数,
在把该整数转换成原类型的指针,还可以得到原先的指针值)。
该运算符的用法比较多。
(static_cast .与. reinterpret_cast比较,见下面 )
4 const_cast
用法:const_cast (expression)
该运算符用来修改类型的const或volatile属性。除了const 或volatile修饰之外, type_id和expression的类型是一样的。
常量指针被转化成非常量指针,并且仍然指向原来的对象;
常量引用被转换成非常量引用,并且仍然指向原来的对象;常量对象被转换成非常量对象。
Voiatile和const类试。举如下一例:
class B{
public:
int m_iNum;
}
void foo(){
const B b1;
b1.m_iNum = 100; //comile error
B b2 = const_cast(b1);
b2. m_iNum = 200; //fine
}
上面的代码编译时会报错,因为b1是一个常量对象,不能对它进行改变;
使用const_cast把它转换成一个常量对象,就可以对它的数据成员任意改变。注意:b1和b2是两个不同的对象。
== ===========================================
== dynamic_cast .vs. static_cast
== ===========================================
class B { ... };
class D : public B { ... };
void f(B* pb)
{
D* pd1 = dynamic_cast(pb);
D* pd2 = static_cast(pb);
}
If pb really points to an object of type D, then pd1 and pd2 will get the same value. They will also get the same value if pb == 0.
If pb points to an object of type B and not to the complete D class, then dynamic_cast will know enough to return zero. However, static_cast relies on the programmer’s assertion that pb points to an object of type D and simply returns a pointer to that supposed D object.
即dynamic_cast可用于继承体系中的向下转型,即将基类指针转换为派生类指针,比static_cast更严格更安全。dynamic_cast在执行效率上比static_cast要差一些,但static_cast在更宽上范围内可以完成映射,这种不加限制的映射伴随着不安全性。static_cast覆盖的变换类型除类层次的静态导航以外,还包括无映射变换、窄化变换(这种变换会导致对象切片,丢失信息)、用VOID*的强制变换、隐式类型变换等...
== ===========================================
== static_cast .vs. reinterpret_cast
== ================================================
reinterpret_cast是为了映射到一个完全不同类型的意思,这个关键词在我们需要把类型映射回原有类型时用到它。我们映射到的类型仅仅是为了故弄玄虚和其他目的,这是所有映射中最危险的。(这句话是C++编程思想中的原话)
static_cast 和 reinterpret_cast 操作符修改了操作数类型。它们不是互逆的; static_cast 在编译时使用类型信息执行转换,在转换执行必要的检测(诸如指针越界计算, 类型检查). 其操作数相对是安全的。另一方面;reinterpret_cast 仅仅是重新解释了给出的对象的比特模型而没有进行二进制转换, 例子如下:
int n=9; double d=static_cast < double > (n);
上面的例子中, 我们将一个变量从 int 转换到 double。 这些类型的二进制表达式是不同的。 要将整数 9 转换到 双精度整数 9,static_cast 需要正确地为双精度整数 d 补足比特位。其结果为 9.0。而reinterpret_cast 的行为却不同:
int n=9;
double d=reinterpret_cast (n);
这次, 结果有所不同. 在进行计算以后, d 包含无用值. 这是因为 reinterpret_cast 仅仅是复制 n 的比特位到 d, 没有进行必要的分析.
因此, 你需要谨慎使用 reinterpret_cast.
- const_cast,
- reinterpret_cast,
- static_cast,
- dynamic_cast等等。
1)static_cast(a)
将地址a转换成类型T,T和a必须是指针、引用、算术类型或枚举类型。
表达式static_cast(a), a的值转换为模板中指定的类型T.在运行时转换过程中,不进行类型检查来确保转换的安全性。
例子:
- class B { ... };
- class D : public B { ... };
- void f(B* pb, D* pd)
- {
- D* pd2 = static_cast(pb);
- ...
- }
- class B { ... };
- class D : public B { ... };
- void f(B* pb, D* pd)
- {
- D* pd2 = static_cast(pb);
- B* pb2 = static_cast(pd);
- ...
- }
- class B { ... };
- class D : public B { ... };
- void f(B* pb, D* pd)
- {
- D* pd2 = static_cast(pb);
- B* pb2 = static_cast(pd);
- ...
- }
2)dynamic_cast(a)
完成类层次结构中的提升。T必须是一个指针、引用或无类型的指针。a必须是决定一个指针或引用的表达式。
表达式dynamic_cast(a) 将a值转换为类型为T的对象指针。如果类型T不是a的某个基类型,该操作将返回一个空指针。
例子:
- class A { ... };
- class B { ... };
- void f()
- {
- A* pa = new A;
- B* pb = new B;
- void* pv = dynamic_cast(pa);
-
- ...
- pv = dynamic_cast(pb);
-
- }
3)const_cast(a)
去掉类型中的常量,除了const或不稳定的变址数,T和a必须是相同的类型。
表达式const_cast(a)被用于从一个类中去除以下这些属性:const, volatile, 和 __unaligned.
例子:
- class A { ... };
- void f()
- {
- const A *pa = new A;
- A *pb;
-
- pb = const_cast(pa);
- ...
- }
- class A { ... };
- void f()
- {
- const A *pa = new A;
- A *pb;
-
- pb = const_cast(pa);
- ...
- }
- class A { ... };
- void f()
- {
- const A *pa = new A;
- A *pb;
-
- pb = const_cast(pa);
- ...
- }
4)reinterpret_cast(a)
任何指针都可以转换成其它类型的指针,T必须是一个指针、引用、算术类型、指向函数的指针或指向一个类成员的指针。
表达式reinterpret_cast(a)能够用于诸如char* 到 int*,或者One_class* 到 Unrelated_class*等类似这样的转换,因此可能是不安全的。
例子:
- class A { ... };
- class B { ... };
- void f()
- {
- A* pa = new A;
- void* pv = reinterpret_cast(pa);
-
- ...
- }
不过,C++中也存在一些弱类型,希望不要用强制类型转换。希望通过本文的介绍能够给你带来帮助。
C++操作符的重载
在表达式中,我们常会用到各种操作符(运算符),例如1+3和4*2。然而,这些操作符只能用于C++内置的一些基本数据类型。如果我们自己编写一个复数类,它也会有加减法的操作,那么它能否摆脱一串冗长的函数名,而享用加号呢?
在第六章我们学到过,函数是可以重载的,即同名函数针对不同数据类型的参数实现类似的功能。在C++中,操作符也是可以重载的,同一操作符对于不同的自定义数据类型可以进行不同的操作。
作为成员函数
在我们学习操作符重载前,我们先看看原先这个复数类是如何定义的:(程序16.3.1)
//complex.h
#include
using namespace std;
class Complex//声明一个复数类
{
public:
Complex(Complex &a);//拷贝构造函数
Complex(double r=0,double i=0);
void display();//输出复数的值
void set(Complex &a);
Complex plus(Complex a);//复数的加法
Complex minus(Complex a); //复数的减法
Complex plus(double r); //复数与实数相加
Complex minus(double r); //复数与实数相减
private:
double real;//复数实部
double img;//复数虚部
};
Complex::Complex(Complex &a)
{
real=a.real;
img=a.img;
}
Complex::Complex(double r,double i)
{
real=r;
img=i;
}
void Complex::display()
{
cout <=0?"+":"") <![]() }
}
void Complex::set(Complex &a)
{
real=a.real;
img=a.img;
}
Complex Complex::plus(Complex a)
{
Complex temp(a.real+real,a.img+img);
return temp;
}
Complex Complex::minus(Complex a)
{
Complex temp(real-a.real,img-a.img);
return temp;
}
Complex Complex::plus(double r)
{
Complex temp(real+r,img);
return temp;
}
Complex Complex::minus(double r)
{
Complex temp(real-r,img);
return temp;
}
//main.cpp
#include "complex.h"
#include
using namespace std;
int main()
{
Complex a(3,2),b(5,4),temp;
temp.set(a.plus(b));//temp=a+b
temp.display();
cout < temp.set(a.minus(b));//temp=a-b
temp.display();
cout < return 0;
}
运行结果:
8+6i
-2-2i
虽然程序16.3.1已经实现了复数的加减法,但是其表达形式极为麻烦,如果有复数a、b、c和d,要计算a+b-(c+d)将会变得非常复杂。如果不是调用函数,而是使用操作符的话,就会直观得多了。
声明一个操作符重载的语句格式为:
返回值类型operator 操作符(参数表);
事实上,在声明和定义操作符重载的时候,我们可以将其看作函数了,只不过这个函数名是一些操作符。在声明和定义操作符重载时需要注意以下几点:
- 操作符只能是C++中存在的一些操作符,自己编造的操作符是不能参与操作符重载的。另外,“::”(域解析操作符)、“.”(成员操作符)、“……?……:……”(条件操作符)和sizeof等操作符不允许重载。
- 参数表中罗列的是操作符的各个操作数。重载后操作数的个数应该与原来相同。不过如果操作符作为成员函数,则调用者本身是一个操作数,故而参数表中会减少一个操作数。(请对比程序16.3.2与程序16.3.3)
- 各个操作数至少要有一个是自定义类型的数据,如结构或类。
- 尽量不要混乱操作符的含义。如果把加号用在减法上,会使程序的可读性大大下降。
下面我们把操作符作为成员函数,来实现复数的加减法:(程序16.3.2)
//complex.h
#include
using namespace std;
class Complex//声明一个复数类
{
public:
Complex(Complex &a);
Complex(double r=0,double i=0);
void display();
void operator =(Complex a);//赋值操作
Complex operator +(Complex a);//加法操作
Complex operator -(Complex a);//减法操作
Complex operator +(double r);//加法操作
Complex operator -(double r);//减法操作
private:
double real;
double img;
};
//未定义的函数与程序16.3.1相同
void Complex::operator =(Complex a)
{
real=a.real;
img=a.img;
}
Complex Complex::operator +(Complex a)
{
Complex temp(a.real+real,a.img+img);
return temp;
}
Complex Complex::operator -(Complex a)
{
Complex temp(real-a.real,img-a.img);
return temp;
}
Complex Complex::operator +(double r)
{
Complex temp(real+r,img);
return temp;
}
Complex Complex::operator -(double r)
{
Complex temp(real-r,img);
return temp;
}
//main.cpp
#include "complex.h"
#include
using namespace std;
int main()
{
Complex a(3,2),b(5,4),c(1,1),d(4,2),temp;
temp=a+b;//这样的复数加法看上去很直观
temp.display();
cout < temp=a-b;
temp.display();
cout < temp=a+b-(c+d);//可以和括号一起使用了
temp.display();
cout < return 0;
}
运行结果:
8+6i
-2-2i
3+3i
以上程序的main.cpp中,复数的加法表达得非常简洁易懂,与程序16.3.1相比有了很大的进步。并且,我们发现使用了括号以后,可以更方便地描述各种复杂的运算。 操作符在重载之后,结合性和优先级是不会发生变化的,符合用户本来的使用习惯。
作为友元
前面我们把操作符作为成员函数,实现了复数的加减法。如果我们把操作符作为普通的函数重载,则需要将其声明为友元。这时,参数表中的操作数个数应该与操作符原来要求的操作数个数相同。
下面我们来看一下,用友元和操作符重载来实现复数的加减法:(程序16.3.3)
//complex.h
#include //由于VC编译器存在问题,这里使用标准的写法居然无法通过编译
class Complex
{
public:
Complex(Complex &a);
Complex(double r=0,double i=0);
void display();
friend Complex operator +(Complex a,Complex b);//作为友元
friend Complex operator -(Complex a,Complex b);
friend Complex operator +(Complex a,double r);
friend Complex operator -(Complex a,double r);
private:
double real;
double img;
};
//未定义的函数与程序16.3.1相同
Complex operator +(Complex a,Complex b)
{
Complex temp(a.real+b.real,a.img+b.img);
return temp;
}
Complex operator -(Complex a,Complex b)
{
Complex temp(a.real-b.real,a.img-b.img);
return temp;
}
Complex operator +(Complex a,double r)
{
Complex temp(a.real+r,a.img);
return temp;
}
Complex operator -(Complex a,double r)
{
Complex temp(a.real-r,a.img);
return temp;
}
//main.cpp
#include "complex.h"
#include //由于VC编译器存在问题,这里使用标准的写法无法通过编译
int main()
{
Complex a(3,2),b(5,4),c(1,1),d(4,2),temp;
temp=a+b;
temp.display();
cout < temp=a-b;
temp.display();
cout < temp=a+b-(c+d);
temp.display();
cout < return 0;
}
运行结果:
8+6i
-2-2i
3+3i
在上面这个程序中,加号和减号操作符由成员函数变成了友元函数。细心的读者可能注意到了,那个赋值操作符的定义跑哪儿去了?
事实上,赋值操作符有点类似于默认拷贝构造函数,也具有默认的对象赋值功能。所以即使没有对它进行重载,也能使用它对对象作赋值操作。但是如果要对赋值操作符进行重载,则必须将其作为一个成员函数,否则程序将无法通过编译。
在操作符重载中,友元的优势尽显无遗。特别是当操作数为几个不同类的对象时,友元不失为一种良好的解决办法。
又见加加和减减
在第五章我们学习了增减量操作符,并且知道它们有前后之分。那么增减量操作符是如何重载的呢?同样是一个操作数,它又是如何区分前增量和后增量的呢?
前增量操作符是“先增后赋”,在操作符重载中我们理解为先做自增,然后把操作数本身返回。后增量操作符是“先赋后增”,在这里我们理解为先把操作数的值返回,然后操作数自增。 所以,前增量操作返回的是操作数本身,而后增量操作返回的只是一个临时的值。
在C++中,为了区分前增量操作符和后增量操作符的重载,规定后增量操作符多一个整型参数。这个参数仅仅是用于区分前增量和后增量操作符,不参与到实际运算中去。
下面我们就来看看,如何重载增量操作符:(程序16.3.4)
//complex.h
#include //由于VC编译器存在问题,这里使用标准的写法无法通过编译
class Complex
{
public:
Complex(Complex &a);
Complex(double r=0,double i=0);
void display();
friend Complex operator +(Complex a,Complex b);
friend Complex operator -(Complex a,Complex b);
friend Complex operator +(Complex a,double r);
friend Complex operator -(Complex a,double r);
friend Complex& operator ++(Complex &a);//前增量操作符重载
friend Complex operator ++(Complex &a,int); //后增量操作符重载
private:
double real;
double img;
};
//未定义的函数与程序16.3.3相同
Complex& operator ++(Complex &a)
{
a.img++;
a.real++;
return a;//返回类型为Complex的引用,即返回操作数a本身
}
Complex operator ++(Complex &a,int)//第二个整型参数表示这是后增量操作符
{
Complex temp(a);
a.img++;
a.real++;
return temp;//返回一个临时的值
}
//main.cpp
#include "complex.h"
#include //由于VC编译器存在问题,这里使用标准的写法无法通过编译
int main()
{
Complex a(2,2),b(2,4),temp;
temp=(a++)+b;
temp.display();
cout < temp=b-(++a);
temp.display();
cout < a.display();
cout < return 0;
}
运行结果:
4+6i
-2+0i
4+4i
