论文笔记:No Provisioned Concurrency: Fast RDMA-codesigned Remote Fork for Serverless Computing 上
Serverless 论文笔记——No Provisioned Concurrency: Fast RDMA-codesigned Remote Fork for Serverless Computing 上
-
- ***MITOSIS主要Attributes
-
- 1. Startup efficiency 启动效率
- 2.State transfer efficiency 状态转移
- 1 Abstract 摘要
- 1 Introduction
-
- **贡献**
- 2 Background and Motivation
-
- 冷启动消耗 Coldstart performance cost.
-
- 1.缓存
- 2.Fork
- 3.C/R 检查点/恢复
- (Remote) state transfer cost
- 3 Remote Fork for Serverless Computing
-
- 1.高效(远程)功能启动
- 2.快速透明(远程)状态传输
- 挑战:远程分叉效率。
-
- 检查点容器内存。
- 复制检查点文件。
- 额外的恢复软件开销。
for Serverless Computing 上)
论文原文下载链接
项目工程查看连接
首先,先说一下这篇论文解决了什么问题
如果是初次接触Serverless的UUs,可以先看一下我之前的文章一文超通俗理解serverless,里面简要通俗地介绍了Serverless的一些特点,对本篇论文的阅读有一定帮助。
首选,这篇工作实现了结合RDMA 和 新的 fork 原语的MITOSIS,它:
***MITOSIS主要Attributes
1. Startup efficiency 启动效率
我们知道,由于Serveless的一大特性,就是启动start的时候产生装载,那么势必产生速度慢的问题,这篇工作就解决了这个问题。
他们给出的结果是:性能相当的情况下,MITOSIS启动比一般冷启动快几个数量级;而相当性能的热启动相比,同它的消耗又少几个数量级。
2.State transfer efficiency 状态转移
之前的文章提到Serverless无状态的特性,MITOSIS下,函数可以直接访问 pre-materialized 来自 fork 分叉 函数的状态。
使用真实世界的无服务器应用程序进行的广泛评估证实了 MITOSIS 在商品化的支持 RDMA 的集群上的功效和效率。并且它们认为,除了无服务器计算好的表现外,在容器迁移方面也可以运用
下面进行一些个顺序无脑的阅读:
1 Abstract 摘要
无服务器平台本质上面临着容器启动时间和配置的并发性(即缓存实例)之间的权衡,远程容器初始化的频繁需求进一步加剧了这种情况。
本文介绍了 MITOSIS,一种提供快速远程分叉的操作系统原语,它利用 RDMA 操作系统内核的深度代码设计。
通过利用 RDMA 的快速远程读取功能和跨无服务器容器的部分状态传输,MITOSIS 跨越了本地和远程容器 初始化 之间的性能鸿沟。
MITOSIS是第一个在一秒内跨多台机器从一个实例中分叉10000多个新容器的,同时允许新容器有效地传输分叉的,容器预物化状态(pre-materialized states)。
我们在Linux上实现了MITOSIS,并将其与FN(一种流行的无服务器平台)集成。在现实世界无服务器工作负载的负载峰值下,MITOSIS将函数尾部延迟(function tail latency 这里我没理解)降低了89%,内存使用量降低了几个数量级。对于需要状态传输的无服务器工作流,MITOSIS将其执行时间提高了86%(这里估计是表达歧义,理解意思就行)。
先略过intro and moti……
1 Introduction
贡献
• 问题:分析现有容器启动技术的性能资源配置权衡,以及功能之间的状态传输成本(§2)。
• MITOSIS:RDMA 共同设计的操作系统远程分支,无需预置并发即可在远程机器上快速启动容器,并实现高效的功能状态传输(§4-5)。
• 演示:在 Linux 上与 Fn 集成的实现(§6)以及对微基准测试和真实世界无服务器应用程序的评估证明了 MITOSIS 的有效性(§7)。
无服务器计算是一种新兴的云计算范式,得到了主要云提供商的支持,包括 AWS Lambda [23]、Azure Functions [90]、Google Server less [44]、阿里巴巴无服务器应用程序引擎 [30] 和华为云函数 [58]。 它的主要承诺之一是自动扩展——用户只提供无服务器功能,无服务器平台会自动分配计算资源(例如容器1)来执行它们。 自动缩放使服务器更少的计算变得经济:平台仅在执行功能时计费(空闲时间不收费)。
然而,冷启动(即为每个功能从头开始启动容器)是快速自动缩放的关键挑战,因为启动时间(超过 100 毫秒)可能比临时无服务器功能的执行时间高几个数量级 [37 , 93, 118]。 加速冷启动已成为学术界和工业界的热门话题 [41, 119, 93, 17, 100, 37, 20]。 他们中的大多数人通过预配置的并发来求助于一种“热启动”形式,例如,从缓存的容器中启动容器。
但是,在将功能扩展到分布式设置时,它们需要大量资源,例如,每台机器都应部署许多缓存容器。
不幸的是,将功能扩展到多台机器是很常见的,因为单台机器的功能容量有限,无法及时处理负载峰值。 考虑从 Azure Functions [100] 的真实跟踪中采样的两个函数。 函数 9a3e4e 的请求频率可以激增到每分钟超过 15 万次调用,在一分钟内增加了 33,000 倍(参见图 1 的顶部)。 为避免拖延大量新到达的函数调用,平台应立即在多台机器上启动足够的容器(参见图 1 的底部)。 由于无服务器工作负载的不可预测性,平台决定热启动缓存实例的数量具有挑战性。 因此,此类资源“天下没有免费的午餐”:商业平台需要用户预留并为其付费以获得更好的性能(即更短的响应时间),例如 AWS Lambda Provisioned Concurrency [12]。
更糟糕的是,在单独容器中运行的依赖函数无法直接传输状态。 相反,他们必须求助于消息传递或云存储来进行状态传输,这具有数据序列化/反序列化、内存复制和存储堆栈开销。 最近的报告显示,这些可能占函数执行时间的 95% [71、53]。 不幸的是,在函数之间传输状态在无服务器工作流中很常见——一种将函数组合成更复杂应用程序的机制 [4, 2]。 尽管最近的研究 [71] 通过在同一容器中共同定位本地功能来绕过本地状态传输(即在同一台机器上运行的功能)的此类开销,但仍不清楚如何在远程设置中这样做。
我们认为:
远程分叉——像本地分叉一样跨机器分叉容器——是一种很有前途的原语,可以实现高效的函数启动和快速的函数状态共享。
首先,fork 机制已被证明在单台机器上启动容器的性能和资源使用方面都很有效:一个缓存的容器足以在 1 毫秒的时间内启动多个容器 [17、37、36]。 通过将 fork 机制扩展到远程,一个活动容器足以在所有机器上高效地启动多个容器。
其次,远程分叉提供远程函数之间透明的中间状态共享——分叉创建的容器中的代码可以透明地绕过消息传递或云存储来访问分叉容器的预物化状态。
现有工作
然而,最先进的系统只能通过检查点/恢复技术 (C/R) [7, 114] 实现保守的远程分叉。 我们的分析表明,它们对于无服务器计算效率不高,即,由于将父容器的内存检查点放入文件、通过网络传输文件以及通过分布式文件系统访问文件的成本,它们甚至比冷启动慢( §3). 即使我们利用现代互连(即 RDMA)来降低这些成本,检查点和分布式文件访问的软件开销仍然使 C/R 未能充分利用 RDMA 的低延迟和高吞吐量。
我们展示了 MITOSIS,这是一种操作系统原语,通过与 RDMA 深度协同设计来提供快速远程分叉。 关键的见解是操作系统可以通过支持 RDMA 的 NIC (RNIC) [112] 直接访问远程机器上的物理内存,这要归功于通过远程操作系统和远程 CPU,速度非常快。 因此,我们可以通过将子容器的虚拟内存映射到其父容器的物理内存来模拟本地fork来实现远程fork,而无需对内存进行检查点操作。 子容器可以使用 RNIC 以写时复制的方式直接读取父内存,绕过传统 C/R 引入的软件堆栈(例如,分布式文件系统)。
将 RDMA 用于内核的远程分叉带来了几个新的挑战(§4.1):(1)快速且可扩展的 RDMA 支持连接建立,(2)父容器物理内存的高效访问控制和(3)高效的父容器生命周期 规模化管理。 MITOSIS 通过 (1) 改进高级 RDMA 功能(即 DCT [1]),(2) 提出一种新的基于连接的内存访问控制方法来应对这些挑战,该方法专为远程分叉而设计,以及 (3) 共同设计容器生命周期管理 在无服务器平台的帮助下。 我们还介绍了包括广义精益容器 [93] 在内的技术,以减少远程分叉的容器化开销。 总之,我们表明远程分叉可以在用于无服务器计算的商品 RNIC 上变得高效、可行和实用。
我们在 Linux 上实现了 MITOSIS,其核心功能以 Rust 编写为可加载内核模块。 它可以在 0.86 秒内在 5 台机器上远程分叉 10、000 个容器。 MITOSIS 与主流容器(例如 runC [13])完全兼容,可以与现有的基于容器的无服务器平台无缝集成。 为了证明效率和功效,我们将 MITOSIS 与 Fn [120](一种流行的开源无服务器平台)集成在一起。 在实际无服务器工作负载的负载峰值下,MITOSIS 将峰值函数的第 99 个百分位延迟减少了 89%,内存使用量降低了几个数量级。 对于需要状态传输的真实世界服务器较少的工作流(即 FINRA [14]),MITOSIS 将其执行时间减少了 86%。
2 Background and Motivation
冷启动消耗 Coldstart performance cost.
1.缓存
[63,64,120,41,119,93,17,100]。
通过缓存完成的容器(例如,通过Docker暂停[8])而不是
回收它们,未来的函数可以重用缓存的函数(例如,通过Docker解包),几乎不需要启动成本(小于1ms)。然而,缓存会消耗大量内存资源:缓存实例的资源配置数量(O(n))应与并发函数的数量(n)相匹配,因为暂停的容器只能取消使用一旦考虑到函数调用数量的不可预测性(例如,图1中的负载峰值),开发人员或平台很难决定需要多少缓存实例。因此,缓存不可避免地面临快速启动和低资源调配之间的权衡,从而导致巨大的缓存未命中。
2.Fork
[37,17,36]
缓存的容器(父级)可以调用fork系统调用(而不是解包)来启动新的container(子级)。由于可以多次调用fork,因此每台机器只需要一个缓存实例就可以派生新的容器。因此,fork将缓存容器的资源配置从O(n)减少到O(m),其中m是需要启动函数的机器的数量。然而,它仍然与机器数量(m)成比例,因为fork不能推广到分布式设置。
3.C/R 检查点/恢复
C/R从存储在文件中,它只需要O(1)个资源(文件)即可启动,因为如果需要,文件可以通过网络传输。虽然C/R在资源使用方面是最佳的,但它比Caching和fork慢了几个数量级
我的理解是,缓存方法是牺牲内存,保时间,检查点/恢复是牺牲时间,保内存,但是fork方法是通过调用的方法,做好机器的容器父子级关系,每个机器缓存一个实例就行,通过父级调用子级,这样就能减少部分的资源占用,O(n)–>O(m)。
(Remote) state transfer cost
在无服务器工作流中,在功能之间传输状态是常见的[36,17,94,64,4,2]。工作流是描述函数之间的生产者-消费者关系的图形。考虑真实世界的例子FINRA[14] 如图2所示。它是一个金融应用程序,根据交易(投资组合)和市场(市场)数据验证交易。上游函数(产生状态的函数),即fetchPortfolioData和fetchMarketData 首先从外部源读取数据。然后,它们将结果传递给许多下游函数(消耗状态的函数),即运行AuditRules以同时处理它们以获得更好的性能。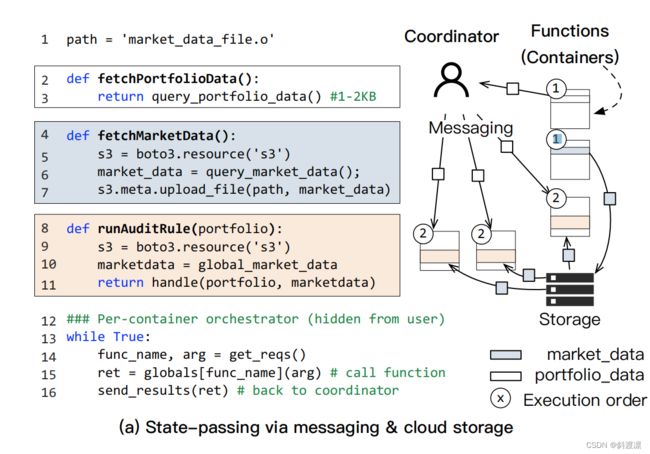
在不同容器中运行的函数只能通过消息传递通过网络复制状态或在云存储服务中交换状态来传递状态。图3(a)显示了在AWS Lambda上运行FINRA的简化代码。对于小状态传输(小于32KB,例如,Portfolio),Lambda将状态放在协调器和函数容器之间交换的消息中[124]。对于大型(市场),功能必须与S3 Lambda的云存储服务进行交换。
通过消息和云存储传输状态不可避免地会面临数据串行化、内存副本和云存储堆栈的开销,这会导致高达1000倍的速度下降[53,71]。为了解决这个问题,现有工作提出了无服务器优化的消息传递原语(messaging primitives )[17] primitives 这篇论文连接 或专用存储系统[107,69,95],但没有一个提到的开销能被完全消除[71]。Facastlane[71]将函数与线程放在同一个容器中,这样它就可以通过共享内存访问来传递这些开销。但是,线程不能推广到分布式设置。如果上游和下游功能在不同的机器上,Facastlane会回退到消息传递。
3 Remote Fork for Serverless Computing
这篇工作展示了远程分叉寻址的以下两个好处:
之前章节当中提到的问题。
1.高效(远程)功能启动
当将FORK原语推广到远程设置时,单个父容器足以在集群中启动后续的child容器,类似于C/R(参见表1)。我们认为 O(1)资源配置对于开发人员/租户来说是可取的,因为他们只需要指定是否需要用于热启动的资源,而不需要指定多少(例如,用于分叉的机器数量或用于缓存的缓存实例[12])。
2.快速透明(远程)状态传输
FORK原语基本上桥接了父容器和子容器的地址空间。传输的状态在父内存中预先具体化,因此孩子可以通过共享内存抽象无缝地访问它们,而无需数据序列化、零拷贝(用于只读访问4)和云存储成本。同时,FORK原语中的写时复制 关于共享内存和“写时复制,刚补了Linux这点内容,如果不会可以看这个,写的很清楚”语义避免了传统分布式共享内存系统中昂贵的内存一致性协议[75,57]。
图3(b)给出了使用fork在FINRA中传输市场数据的具体示例(见图2)。假设所有函数都打包在同一个容器中(通常在无服务器平台中找到),并且容器有一个协调器将函数请求分派给用户实现的函数(第11-14行)。
我们进一步认为,向协调器发出请求的协调器是分叉感知的(§6.1):基于工作流图中的函数依赖关系(例如,图2),它将在必要时请求协调器分叉子级(第12行)。管弦乐队完成获取MarketData(第13行)后,它分叉(第15–16行)运行下游函数(runAuditRule),后者可以直接访问父级预先具体化的global_market_data(第8行)。
挑战:远程分叉效率。
据我们所知,现有容器只能通过基于C/R 检查点/恢复 的方法远程分叉[105,32]。要分叉子级,父级首先通过将其状态(例如,寄存器值和内存页)复制到文件来检查其状态,然后使用远程文件副本(见图5(a)中的CRIU local)或分布式文件系统(见图5中的CRIU-remote)将文件传输给子级。收到文件后,子级通过从检查点文件加载容器状态来恢复父级的执行。注意,C/R可以按需加载一些状态(即,内存页)以获得更好的性能[117]。
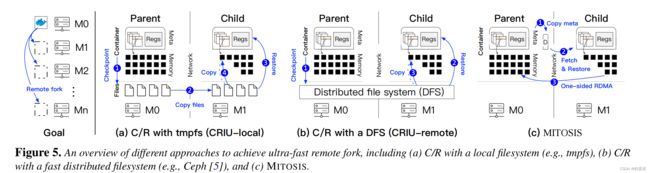
不幸的是,基于C/R的远程分叉对于无服务器计算不够有效。图4(a)显示了使用CRIU[7](Linux上最先进的C/R)在远程机器上执行无服务器功能的执行时间(经过仔细优化,详细信息请参见§7),以实现CRIU本地和CRIU远程。合成函数随机触及整个父级的内存。我们观察到,如果远程分叉访问1 GB远程内存,它甚至可以比coldstart慢2.7倍。我们将其归因于以下一个或多个问题。
检查点容器内存。
CRIU使用本地或分布式文件系统分别需要9毫秒(分别为518毫秒)和15.5毫秒(分别是590毫秒)的时间来检查父容器的1 MB(分别为1 GB)内存。开销主要是将内存复制到文件中:与本地分叉不同,孩子的操作系统驻留在另一台机器上,因此缺乏对父内存页的直接内存访问能力。
复制检查点文件。
对于CRIU本地,对于1 MB–1 GB的映像,将整个文件从父级传输到子级分别需要11–734毫秒(而执行时间为0.61–570毫秒)。整个文件副本通常是不必要的,因为无服务器函数通常访问父容器的部分状态[117](另请参见图16(b))。
额外的恢复软件开销。
CRIU-remote支持按需文件传输:它只在页面错误时读取所需的远程文件页面。然而,执行时间比CRIU本地时间长1.3–3.1倍,因为每个页面故障都需要DFS请求来读取页面:DFS延迟(100µs)远高于本地文件访问。更重要的是,由于软件开销,延迟远高于一次网络往返时间(3µs)。
CRIU惰性迁移[6]也支持按需传输。然而,它没有针对RDMA进行优化,并且比我们评估的python hello函数的CRIU remote(210毫秒对42毫秒)慢了几个数量级。
未完见下篇…………