SQLServer从入门到高级(知识点)
SQLServer从入门到高级(知识点)
文章目录
- SQLServer从入门到高级(知识点)
-
- SQLServer最大限制
- 提高sql查询效率的方法
- 取值范围
- 删除重复行
- 随机抽取50条数据
- 1 sql语句执行顺序
- 2 基本类型
- 3 聚合函数
- 4 日期函数
-
- 4.1 取出日期
- 4.2 日期的加减
- 4.3 计算日期间隔
- 4.4 计算某一天有多少条记录(方法总结)
- 4.5 获取月初月末
- 5 行列转换(不常用!!)
-
- 5.1 行转列PIVOT
- 5.2 列转行UNPIVOT
- 6 字符串操作函数
-
- 6.1 字符串提取
- 6.2 字符串替换
- 6.3 字符串查找
- 6.4 字符串反转
- 6.5 去除空格
- 6.6 字符串大小写转换
- 7 数据备份
- 8 开窗函数OVER
-
- 8.1 定义
- 8.2 语法
- 8.3 开窗函数的分类
- 8.4 示例
- 9 数学函数
- 10 数据类型转换
-
- 10.1 CONVERT() 函数
- 10.2 CAST () 函数
- 11 流程控制语句
-
- 11.1 分支语句
- 11.2 循环语句
-
- 11.2.1 while
- 11.2.2 CURSOR循环
- 11.2.3 附加:游标
- 12 union与unionall 行合并
- 13 函数
- 14 存储过程
- 15 触发器
-
- insert
- delete
- update
- 16 数据库的基本操作
-
- 16.1 创建数据库
- 16.2 切换数据库
- 16.3 创建表
- 16.4 update and insert and delete中的多表连接
- 16.5 修改表结构
- 16.6 维护约束
- 16.7 查看表结构
- 16.8 delete和truncate 的区别
- 17 事务
-
- 17.1 介绍
- 17.2 语法
- 18 延迟函数
-
- 18.1 waitfor 定义
- 18.2 语法
- 18.3 参数
- 18.4 示例
-
- 18.4.1 使用 WAITFOR TIME
- 18.4.2 使用 WAITFOR DELAY
- 19 视图
- 20 封锁
-
- 20.1 封锁协议
- 20.2 活锁和死锁
-
- 20.2.1 活锁
- 20.2.2 死锁
- 21 拼接SQL
- 23 SQL Server 服务
- 24 SQL Server代理 or 计划任务 or 作业
-
- 24.1 介绍
- 24.2 创建作业
- 25 SQL Server分布式部署
- 26 SQL Server 跨库/服务器查询
SQLServer最大限制
1 每个数据库最多有20亿张表
2 每个表(视图)最多有1024列
3 表名和列名的最大长度位128个字符
4 一个对象最多可以有1000个分区
5 一个索引最多可以使用16列,且索引键最大为 900 字节
提高sql查询效率的方法
1、流水表,基础表 用连接去做 流水表 left join ji
2、 连接的效率 >> 子查询
取值范围
between 1 and 3 -----> [1, 3]
rand() -----> [0, 1)
top 30 -- 1-3包括第30条记录
删除重复行
- 方法一
delete from t_setlinfo
where id not in(
select MIN(id) -- id在此表中是自增列,主键
from t_setlinfo t
group by fixmedins_code,mdtrt_sn
)
根据fixmedins_code, mdtrt_sn两个唯一的字段分组确定重复的行,在每组重复的行中选出id值最小的那个,
最后删除掉除最小的这个id值(即删除重复的行,保留一行)
- 方法二
DELETE T
FROM
(
SELECT *
, DupRank = ROW_NUMBER() OVER (
PARTITION BY key_value
ORDER BY (SELECT NULL)
)
FROM original_table
) AS T
WHERE DupRank > 1
此脚本按给定顺序执行以下操作:
- 使用
ROW_NUMBER函数根据key_value(可能是以逗号分隔的一列或多列)对数据进行分区。 - 删除所有收到大于 1 的
DupRank值的记录。 此值指定记录是重复项。
由于 (SELECT NULL) 表达式的原因,脚本不会根据任何条件对分区数据进行排序。 如果删除重复项的逻辑需要根据其他列的排序顺序选择要删除和保留的记录,则可以使用 ORDER BY 表达式来执行此操作。
随机抽取50条数据
需求:从Question表中随机抽取50道题
select top 50 *
from Question
order by NEWID()
1 sql语句执行顺序
sql执行顺序为from——>where——>group by——>having——>select——>order by
2 基本类型
整形:smallint、 int、 bigint 、tining、bit
浮点型:real、float
字符型:char、 nchar、varchar、nvarchar、
日期:datetime、smalldatetime
图片:imag
货币类型:money、smallmoney
长文本:text 、ntext
numeric(10.2)意思是:保留十位有效数字精确到小数点后两位
-- char 定长, char(10) 无论存储的数据是否有10字节都会占10字节,不够自动空格补齐
-- varchar 变长,varchar(10)最多占用10个。 varchar存放字节的范围1-8000
-- text 长文本
-- NCHAR、NVARCHAR、NTEXT
NCHAR、NVARCHAR、NTEXT。它表示存储的是Unicode数据类型的字符。
我们知道字符中,英文字符只需要一个字节存储就足够了,但汉字众多,需要两个字节存储,英文与汉字同时存在时容易造成混乱,Unicode字符集就是为了解决字符集这种不兼容的问题而产生的,它所有的字符都用两个字节表示,即英文字符也是用两个字节表示。nchar、nvarchar的长度是在1到4000之间。
与char、varchar比较起来,nchar、nvarchar则最多存储4000个字符,不论是英文还是汉字;而char、varchar最多能存储8000个英文,4000个汉字。可以看出使用nchar、nvarchar数据类型时不用担心输入的字符是英文还是汉字,较为方便,但在存储英文时数量上有些损失。
3 聚合函数
sql中分组函数在使用时必须先进行分组,然后才能用,如果没有对数据进行分组,则默认整张表为一组。
分组函数:
- count()计数
- sum()求和
- avg()求平均
- max()
- min()
sqlserver函数:SqlServer函数_百度百科 (baidu.com)
4 日期函数
4.1 取出日期
-
year(RegisterDate) 取出年份
-
month(RegisterDate) 取出月份
-
day(RegisterDate) 取出日
-
datename(datepart, date-expression)
datepart类似,但返回值为nvarchar类型
-
datepart(datepart, date-expression)
日期/时间函数,返回表示日期/时间表达式指定部分的值的整数(int类型)。参数列表:
| Date Part | Abbreviations | Return Values |
|---|---|---|
| year | yyyy, yy | 0001-9999 |
| quarter | qq, q | 1-4 |
| month | mm, m | 1-12 |
| week | wk,ww | 1-53 |
| weekday | dw | 1-7 (Sunday,…,Saturday) |
| dayofyear | dy, y | 1-366 |
| day | dd, d | 1-31 |
| hour | hh | 0-23 |
| minute | mi,n | 0-59 |
| second | ss,s | 0-59 |
| millisecond | ms | 0-999 (with precision of 3) |
| microsecond | mcs | 0–999999 (with precision of 6) |
| nanosecond | ns | 0–999999999 (with precision of 9) |
| sqltimestamp | sts | SQL_TIMESTAMP: yyyy-mm-dd hh:mm:ss |
例如
-- 返回年
select datepart(YY, getdate()) -- 2023
select datepart(mm, getdate()) -- 2023
参考链接:第四十五章 SQL函数 DATEPART_yaoxin521123的博客-CSDN博客
4.2 日期的加减
- 对日期的加减dayteadd(month, +1, RegisterDate)
三个参数:要操作类型, 加多少天, 对谁加
dateadd函数:DateAdd(interval, number, date)返回的是一个日期数据,函数的三个形参都是必要。
interval表示时间的间隔可以是yy(表示年),mm(表示月),dd(表示日),qq(表示季度),ww(表示周);
number表示间隔的数值,正数表示日期数据date的未来,负数表示日期数据大特的从前。
date为日期数据,一般就是数据表里面的某个日期字段如birthday生日字段。
示例 Select dateadd(dd, 3, ‘2008-10-05’) 得到的结果就是2008-10-08.
4.3 计算日期间隔
-
datediff函数: 计算两个时间的间隔
DateDiff(interval, date1, date2[, firstdayofweek[, firstweekofyear]]) 返回的是一个数值,这个数值表示date1和date2之间相隔时间间隔interval的数值。
interval表示时间间隔,可以是yy(表示年),mm(表示月),dd(表示日),qq(表示季度),ww(表示周),hh(表示小时),n(表示分钟),s(表示秒)
date1, date2是计算中进行计算的两个日期
Firstdayofweek 可选。指定一个星期的第一天的常数。如果未予指定,则以星期日为第一天。
firstweekofyear 可选。指定一年的第一周的常数。如果未予指定,则以包含 1 月 1 日的星期为第一周。
select datediff(year, 开始日期,结束日期); --两日期间隔年 select datediff(quarter, 开始日期,结束日期); --两日期间隔季 select datediff(month, 开始日期,结束日期); --两日期间隔月 select datediff(day, 开始日期,结束日期); --两日期间隔天 select datediff(week, 开始日期,结束日期); --两日期间隔周 select datediff(hour, 开始日期,结束日期); --两日期间隔小时 select datediff(minute, 开始日期,结束日期); --两日期间隔分 select datediff(second, 开始日期,结束日期); --两日期间隔秒
4.4 计算某一天有多少条记录(方法总结)
-- 计算某一天有多少条记录(方法总结)
-- 方法一 利用year,month,day函数
select * from test2 where YEAR(ftime)=2023 and month(ftime)=6 and day(ftime) = 16;
-- 方法二 利用字符串比较
select * from test2 where CONVERT(varchar(10),ftime, 120 ) = '2023-06-16';
-- 方法三 between and
select * from test2 where ftime between '2023-06-16' and '2023-06-17'
4.5 获取月初月末
declare @time1 datetime;
declare @time2 datetime;
declare @time3 datetime;
declare @time4 datetime;
set @time1 = DATEADD(mm,DATEDIFF(m,0,getdate())-1,0); -- 上月第一天
set @time2 = DATEADD(ms,-3,DATEADD(mm,DATEDIFF(m,0,getdate()),0)); -- 上月最后一天
set @time3 = cast(convert(date, DATEADD(day,DATEDIFF(d,0,getdate())-1,0), 23) as varchar)+' 00:00:00'; -- 昨天开始
set @time4 = cast(convert(date, DATEADD(day,DATEDIFF(d,0,getdate())-1,0), 23) as varchar)+' 23:59:59'; -- 昨天结束
select DATEADD(mm,DATEDIFF(m,0,getdate()),0); -- 本月第一天
select DATEADD(ms,-3,DATEADD(mm, DATEDIFF(m, -1, getdate()),0)); -- 本月最后一天
select @time1 上个月第一天, @time2 上个月最后一天, @time3 昨天开始, @time4 昨天结束
---------- 输出结果 ----------
-- 上个月第一天
2023-05-01 00:00:00.000
-- 上个月最后一天
2023-05-31 23:59:59.997
-- 昨天开始
2023-06-28 00:00:00.000
-- 昨天结束
2023-06-28 23:59:59.000
5 行列转换(不常用!!)
5.1 行转列PIVOT
PIVOT 操作可以将行数据转换为列,适用于已知列值的情况。它基于聚合函数对某一列进行分组,并将这些分组的结果作为新的列。下面是一个简单的示例:
SELECT *
FROM (
SELECT Column1, Column2
FROM TableName
) AS SourceTable
PIVOT (
SUM(Column2)
FOR Column1 IN (Value1, Value2, Value3) -- 列的取值列表
) AS PivotTable;
上述示例中,Column1 列的不同取值(Value1, Value2, Value3)会被转换为 PivotTable 的列。
完整语法:
table_source
PIVOT(
聚合函数(value_column)
FOR pivot_column
IN(<column_list>)
)
5.2 列转行UNPIVOT
UNPIVOT:UNPIVOT 操作与 PIVOT 相反,它可以将列数据转换为行。它将多个列合并为一列,并添加一个标识列来表示原始列名。以下是一个简单的示例:
sql
SELECT NewColumnName, Value
FROM TableName
UNPIVOT (
Value FOR NewColumnName IN (Column1, Column2, Column3) -- 要转换为行的列列表
) AS UnpivotTable;
在上述示例中,ColumnName 列将被展开为多行,并附加一个新的列 NewColumnName 来表示原始列名。
6 字符串操作函数
下标都是从1开始
6.1 字符串提取
- substring(目标字段, 开始位置, 长度)
6.2 字符串替换
- replace(字段, ‘a’, ‘b’) 将字段中的a替换成b
用于替换字符串中的子字符串 (可在指定位置插入字符串)
select replace('aaaa', 'a','b') --bbbb
-
STUFF(string, start, length, substring)
string - 作为子字符串替换目标的字符串表达式。
start - 替换的起点,指定为正整数。从字符串开头开始的字符数,从 1 开始计数。允许的值为 0 到字符 串的 长度。要追加字符,请指定 0 的开头和 0 的长度。空字符串或非数字值被视为 0。
length - 要替换的字符数,指定为正整数。要插入字符,请将长度指定为 0。要在开始后替换所有字符,请指定大于现有字符数的长度。空字符串或非数字值被视为 0。
substring - 一个字符串表达式,用于替换由其起始点和长度标识的子字符串。可以比它替换的子字符串更长或更短。可以是空字符串。
STUFF(str1,start,length,str2)
-- 第一步:删除str1中 从start未知开始,删除长度为length
-- 第二步:将str2添加到start位置
select stuff('abcdef',2,2,'123') -- a123def
select stuff('abcdef',2,0,'123') -- a123bcdef 当参数lenth=0时只执行添加,不删除
6.3 字符串查找
-
CHARINDEX ( expression1 , expression2 [ , start_location ] )
返回字符串中指定表达式的起始位
在expression2中找expression1的位置。最后一参数从expression2的第几个位置查找(可省略)
返回的位置从1开始
返回0时表示为找到示例:
select CHARINDEX(',', value, 2) -- 从value字段中的第二个位置开始找逗号,在value中的位置在哪
6.4 字符串反转
-
reverse(str)
str要反转的字符串
6.5 去除空格
- ltrim(‘字符串’)
去除字符串左边的空格
declare @test varchar(255) = ' hello admin '
select @test --' hello admin '
select len(@test)-- 14
select LTRIM(@test) -- 'hello admin '
select len(lTRIM(@test)) -- 11
-
rtrim(‘字符串’)
去除字符串右边的空格
declare @test varchar(255) = ' hello admin '
select @test --' hello admin '
select rTRIM(@test) -- ' hello admin'
select len(rTRIM(@test)) -- 14
由此可知!函数len()计算长度时自动忽略最右边的空格。
6.6 字符串大小写转换
-
upper()
将所有小写字母转化为大写
select UPPER('saFAda') -- SAFADA
-
lower()
将所有大写字母转化为小写
select lower('SDSA飒') -- sdsa飒
7 数据备份
select into
select 字段 into newtable from 旧表 where 条件
将一个表中的数据导入到一个新的表中
8 开窗函数OVER
8.1 定义
开窗函数用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
开窗函数与聚合函数计算方式一样,开窗函数也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值。
开窗函数的语法为:over(partition by 列名1 order by 列名2 ),括号中的两个关键词partition by 和order by 可以只出现一个。over() 前面是一个函数,如果是聚合函数,那么order by 不能一起使用。
8.2 语法
窗函数的语法为:over(partition by 列名1 order by 列名2 ),括号中的两个关键词partition by 和order by 可以只出现一个。over() 前面是一个函数,如果是聚合函数,那么order by 不能一起使用。
格式: 函数名(列) OVER(选项)
开窗函数格式: 函数名(列) OVER(选项)
OVER 关键字表示把函数当成开窗函数而不是聚合函数。SQL 标准允许将所有聚合函数用做开窗函数,使用 OVER 关键字来区分这两种用法。
如果 OVER 关键字后的括号中的选项为空,则开窗函数会对结果集中的所有行进行聚合运算。
PARTITION BY 子句:
开窗函数的 OVER 关键字后括号中的可以使用 PARTITION BY 子句来定义行的分区来供进行聚合计算。与 GROUP BY 子句不同,PARTITION BY 子句创建的分区是独立于结果集的,创建的分区只是供进行聚合计算的,而且不同的开窗函数所创建的分区也不互相影响
ORDER BY子句:
开窗函数中可以在OVER关键字后的选项中使用ORDER BY子句来指定排序规则,而且有的开窗函数还要求必须指定排序规则。使用ORDER BY子句可以对结果集按照指定的排序规则进行排序,并且在一个指定的范围内进行聚合运算
8.3 开窗函数的分类
开窗函数分为两大类:排序开窗函数和聚合开窗函数
- 排序开窗函数
ROW_NUMBER、DENSE_RANK、RANK属于排名函数。
row_number() over(partition by 列名 order by 列名)
rank() over(partition by 列名 order by 列名) -- 值相同 编号也一样,不过会跳过一个编号
dense_rank() over(partition by 列名 order by 列名) -- 值相同 编号也一样,编号不跳过
排名开窗函数可以单独使用ORDER BY 语句,也可以和PARTITION BY同时使用。
PARTITION BY用于将结果集进行分组,开窗函数应用于每一组。
ORDER BY 指定排名开窗函数的顺序,在排名开窗函数中必须使用ORDER BY语句。
ROW_NUMBER()为每一组的行按顺序生成一个连续序号。
RANK()也为每一组的行生成一个序号,与ROW_NUMBER()不同的是如果按照ORDER BY的排序,如果有相同的值会生成相同的序号,并且接下来的序号是不连序的。例如两个相同的行生成序号2,那么接下来会生成序号4。
DENSE_RANK()和RANK()类似,不同的是如果有相同的序号,那么接下来的序号不会间断。也就是说如果两个相同的行生成序号2,那么接下来生成的序号还是3。
- 聚合开窗函数
很多聚合函数都可以用作窗口函数的运算,如SUM、AVG、MAX、MIN、COUNT。
聚合开窗函数只能使用PARTITION BY子句,ORDER BY不能与聚合开窗函数一同使用。
count(*) over(partition by 列名) -- 计算出每组的个数
max() over(partition by 列名 ) -- 取出每组中最大的数
min() over(partition by 列名 ) -- 取出每组中最小的数
sum() over(partition by 列名 ) -- 计算出每组的和
avg() over(partition by 列名 ) -- 计算出每组的平均值
- 其他。 以下开窗函数必须得有order by 子句,partition by子句可选。
-- first_value() over()和last_value() over()开窗函数必须含有order by 子句。partition by子句可选
first_value() over(partition by 列名 order by 列名) -- 取出每组中最小的那个数
last_value() over(partition by 列名 order by 列名) -- 取出每组中最大的那个数(但每次都是当前行到之前的行)
LAG() 函数和 LEAD() 函数是窗口函数,在 SQL 中用于获取当前行的前一行或后一行的值。它们常用于需要获取相邻行数据的情况
lag() over(partition by 列名 order by 列名)
lead() over(partition by 列名 order by 列名)
8.4 示例
- 表数据
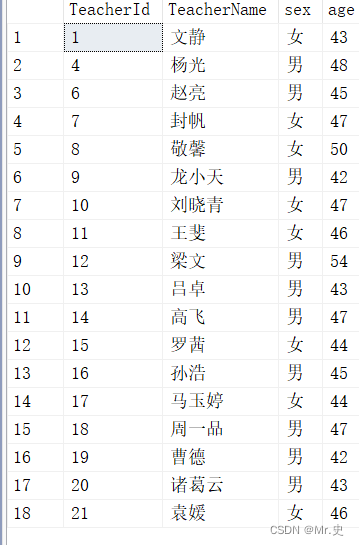
- 排序开窗函数
select sex
, age
, row_number() over(partition by sex order by age) rn
, rank() over(partition by sex order by age) rankN
, dense_rank() over(partition by sex order by age) drn
from #temp

- 聚合开窗函数
select sex
, age
, count(*) over(partition by Sex) 每组的个数 -- 计算出每组的个数
, max(age) over(partition by Sex) maxAge -- 取出每组中最大的数
, min(age) over(partition by Sex) minAge -- 取出每组中最小的数
, sum(age) over(partition by Sex) sumAge-- 计算出每组的和
, avg(age) over(partition by Sex) avgAge-- 计算出每组的平均值
from #temp

- 其他
select Sex
, age
, FIRST_VALUE(age)over(partition by sex order by age) firstValue -- 获得每组中的第一个值
, LAST_VALUE(age)over(partition by sex order by age) lastValue -- 获取当前行与之前行中的最后一个值
, LAG(age) over(partition by sex order by age) lagValue -- 获取当前值前一行的内容
, LEAD(age) over(partition by sex order by age) leadValue -- 获取当前值后一行的内容
from #temp

9 数学函数
-
ABS() 绝对值函数
-
CEILING ( numeric_expression )
返回大于或等于指定数值表达式的最小整数。
-- 向上取整 select ceiling(2.3) --3 select ceiling(3) --3 -
FLOOR ( numeric_expression )
返回小于或等于指定数值表达式的最大整数。
-- 向下取整 select floor(2.3) --2 select floor(2) -- 2 -
LOG ( float_expression [, base ] )
返回 SQL Server 中指定 float 表达式的自然对数。
-- 示例1:无底数参数时,默认为自然对数是以 e 为底的对数,其中,e 是一个无理常量,约等于 2.718281828。 select log(2) -- 示例2:以2为底4的对数 select log(4,2) -- 示例3 另一个函数以10为底 log10() select log10(100) --2 ----备注:LOG10 和 POWER 函数互为反函数。 例如,10 ^ LOG10(n) = n 。 select power(10, log10(10)) --10 -
PI() 返回 PI 的常量值。
select PI() -- 3.14159265358979 -
POWER ( float_expression , y )
返回指定表达式的指定幂的值。
-
RAND ( [ seed ] )
返回一个介于 0 到 1(不包括 0 和 1)之间的伪随机 float 值。
-
ROUND ( numeric_expression , length [ ,function ] )
返回一个数值,舍入到指定的长度或精度。(
四舍五入)numeric_expression
是精确数值或近似数值数据类型类别的表达式。length
它是 numeric_expression 的舍入精度。 length 必须是 tinyint、smallint 或 int 类型的表达式 。如果 length 为正数,则将 numeric_expression 舍入到 length 指定的小数位数 。 如果 length 为负数,则将 numeric_expression 小数点左边部分舍入到 length 指定的长度。函数
要执行的操作的类型。 function 的数据类型必须是 tinyint、smallint 或 int 。如果 function 省略或其值为 0(默认值),则对 numeric_expression 进行舍入。 如果指定了 0 以外的值,则将截断 numeric_expression。-- length 为正数时 select ROUND(748.58, 1) -- 748.60 select ROUND(748.58, 2) -- 748.58 select ROUND(748.58, 0) -- 750.00 保留0位小数 -- length 为负数时 select ROUND(748.58, -1) -- 750.00 select ROUND(748.58, -2) -- 700.00 select ROUND(748.58, -3) -- 导致算术溢出,因为 748.58 默认为 decimal(5,2),它无法返回 1000.00。 -- round()函数默认最后一个参数为0,省略默认值。当指定除0之外的其他值时将会截断,不进行舍入 select round(748.58, 1) -- 748.60 select round(748.58, 1, 1) -- 748.50 -
SIGN ( numeric_expression )
返回指定表达式的正号 (+1)、零 (0) 或负号 (-1)。
select sign(90) -- 1 select sign(-90) -- -1 select sign(0) -- 0 -
SQRT ( float_expression )
返回指定浮点值的平方根。
select sqrt(100) -- 100开根号--> 10 -
SQUARE ( float_expression )
返回指定浮点值的平方。
select square(10) -- 10的平方--> 100 类似于power(10,2)
参考链接:数学函数 (Transact-SQL) - SQL Server | Microsoft Learn
10 数据类型转换
10.1 CONVERT() 函数
CONVERT() 函数,由一种数据类型转换为另一种数据类型。
语法:CONVERT ( data_type [ ( length ) ] , expression [ , style ] )
select convert(varchar(10), GETDATE(),120) -- 2023-07-18 datetime-->varchar
参考链接:Sqlserver的convert函数_sqlserver convert_你是我悟不出的禅的博客-CSDN博客
10.2 CAST () 函数
语法:CAST ( expression AS data_type [ ( length ) ] )
cast(123 as varchar(255)) -- '123' int-->varchar
11 流程控制语句
11.1 分支语句
语法:
if 判断条件
begin
语句
end
else
begin
语句
end
-- begin end 可省略
if 判断条件
begin
语句
end
else if 判断条件 -- 当第一个条件为true时,不再执行此处
begin
语句
end
else -- suo'yo
begin
语句
end
注意:若不写begin end 则之后if后面的一条语句起效
11.2 循环语句
11.2.1 while
语法:
declare @i int =1;
while (@i<10)
begin
循环题
-- 结束条件
set @i+=1;
end
11.2.2 CURSOR循环
CURSOR 是一种用于处理结果集的数据库对象,它提供了对结果集中每一行数据的逐行访问功能。使用 CURSOR 可以在需要按行处理数据时进行迭代。
CURSOR 循环的基本步骤如下:
- 声明和定义一个 CURSOR。
- 打开 CURSOR,并将结果集存储在其中。
- 使用 FETCH 语句获取结果集中的下一行数据。
- 在每次迭代中处理当前行的数据。
- 重复步骤 3 和 4,直到处理完所有行。
- 关闭 CURSOR。
这是 CURSOR 循环的一个简单示例:
DECLARE @name varchar(50)
-- 创建游标
DECLARE cursor_name CURSOR FOR
SELECT name FROM table_name
OPEN cursor_name
FETCH NEXT FROM cursor_name INTO @name
WHILE @@FETCH_STATUS = 0
BEGIN
-- 处理当前行的数据
FETCH NEXT FROM cursor_name INTO @name
END
CLOSE cursor_name
DEALLOCATE cursor_name
11.2.3 附加:游标
-- 创建游标 (scroll滚动游标,没有scroll则只能读取下一行,不能读取上一行)
declare mycur cursor scroll
for select number from test1 -- 对指向test1表
-- 打开游标
open mycur
-- 提取某一行
fetch first from mycur -- 第一行
fetch last from mycur -- 最后一行
fetch absolute 2 from mycur -- 提取第二行
fetch relative 2 from mycur -- 相对于此行的第二行
fetch next from mycur -- 下移一行
fetch prior from mycur -- 上 移一行
-- 关闭游标
close mycur
-- 删除游标
deallocate mycur
12 union与unionall 行合并
要求:1、两个查询中列的数量必须相同。
2、相应列的数据类型必须相同或兼容。
代码如下:
query_1
union
query_2
UNION与UNION ALL 。默认情况下,NUION运算符从结果集中删除所有重复的行。但是,如果要保留明确的行,则需要明确指定ALL关键字,代码如下
query_1
union all
query_2
UNION和ORDER BY。 要对 UNION 运算符返回的结果集进行排序,请将 ORDER BY 子句放在最后一个查询中
query_1
union
query_2
order by order_list
参考链接:SQL Server Union(并集)_sqlserver union_yue_tuo的博客-CSDN博客
13 函数
函数分为:(1)系统函数,(2)自定义函数
其中自定义函数又分为:(1)标量值函数 (返回单个值),(2)表值函数(返回查询结果)
函数的结构:
(1)标量值函数
drop function 函数名 -- 不需要又括号
create function 函数名(@参数1 参数类型, @参数2 参数类型) -- 参数可没有
return 返回类型 -- 定义这个函数需要返回什么类型
as
begin
函数体
return 返回结果 -- 结果的类型必须是上面定义的类型
end
go
-- 函数的调用
select 函数名()
(2)表值函数
drop function 函数名 -- 不需要又括号
create function 函数名(@参数1 参数类型, @参数2 参数类型) -- 参数可没有
return @retult table -- @result 返回结果集的名字
( -- 定义这个函数需要返回什么类型
id varchar(11)
, name varchar(11)
)
as
begin
insert into @restult
select * from test1
return -- 结果的结果集
end
go
-- 函数的调用
select * from 函数名(@参数1, @参数2)
-- 简化版
-- 缺陷: 函数体内只能有return+sql
create function 函数名(@参数1 参数类型, @参数2 参数类型) -- 参数可没有
return table
as
return
select * from test1
go
-- 函数的调用
select * from 函数名(@参数1, @参数2)
14 存储过程
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。在数据量特别庞大的情况下利用存储过程能达到倍速的效率提升。
存储过程模板:
-- 1、没有输入输出参数的存储过程
-- 自定义的存储过程的名字
if (exists (select * from sys.objects where name = 'pro_name'))
drop proc pro_name
go
create proc pro_name
as
begin
-- sql语句
end
-- 执行
exec pro_name
-- 2、有输入没有输出参数的存储过程
if (exists (select * from sys.objects where name = 'pro_name'))
drop proc pro_name
go
create proc pro_name
-- 设置变量类型以及变量名字,可设置默认值
@param_name param_type [=default_value],
@param_name1 param_type [=default_value],
as
begin
sql语句
end
go
-- 执行
exec pro_name 参数1,参数2;
-- 2、有输入有输出参数的存储过程
if (exists (select * from sys.objects where name = 'pro_name'))
drop proc pro_name
go
create proc pro_name
-- 设置变量类型以及变量名字,可设置默认值
@param_name param_type [=default_value],
@param_name1 param_type [=default_value] output -- 将要输出的参数加上output
as
begin
sql语句
-- 也可利用return返回
return 1; -- 但return返回的值必须是整数
end
go
-- 执行
exec pro_name 参数1,参数2 output; -- 此处也要加上output,若不加参数2只要输入功能没有输出功能
-- 可以定义一个变量进行接受
declare @pwd nvarchar(11) = '12345'
exec pro_name 'songsong',@pwd output;
select @pwd
例如
-- 创建存储过程
if (exists (select * from sys.objects where name = 'USP_GetAllUser'))
drop proc USP_GetAllUser
go
create proc USP_GetAllUser
@UserId int =1,
@username = 'tom'
as
-- 不显示日志
set nocount on;
begin
select * from UserInfo where Id=@UserId
end
go
-- 执行存储过程
exec dbo.USP_GetAllUser 2;
常见的存储过程
-- 数据库的操作
exec sp_databases; -- 查看所有数据库
exec sp_helpdb; -- 查询数据库信息
exec sp_helpdb 数据名; -- 查询指定数据库信息
exec sp_renamedb '旧库名', '新库名'; -- 更改数据库名称
-- 表的操作
exec sp_tables; -- 查询当前数据库的所有表
exec sp_help 表名; -- 返回表的所有信息
exec sp_rename '旧名', '新名'; -- 修改表、索引、列的名称
exec sp_columns 表名; -- 查看列
exec sp_helpIndex 表名; -- 查看索引
exec sp_helpConstraint 表名; -- 约束
-- 存储过程的操作
exec sp_stored_procedures; -- 当前环境的所有存储
exec sp_helptext '存储过程'; -- 查看存储过程源码
exec sp_defaultdb ‘旧库名’, ‘新库名’; -- 更改登录名的默认数据库
15 触发器
触发器(trigger)是SQL server 提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如当对一个表进行操作( insert,delete, update)时就会激活它执行。触发器经常用于加强数据的完整性约束和业务规则等。 触发器可以从 DBA_TRIGGERS ,USER_TRIGGERS 数据字典中查到。SQL3的触发器是一个能由系统自动执行对数据库修改的语句。
触发器可以查询其他表,而且可以包含复杂的SQL语句。它们主要用于强制服从复杂的业务规则或要求。例如:您可以根据客户当前的帐户状态,控制是否允许插入新订单。
触发器也可用于强制引用完整性,以便在多个表中添加、更新或删除行时,保留在这些表之间所定义的关系。然而,强制引用完整性的最好方法是在相关表中定义主键和外键约束。如果使用数据库关系图,则可以在表之间创建关系以自动创建外键约束。
触发器与存储过程的唯一区别是触发器不能执行EXECUTE语句调用,而是在用户执行Transact-SQL语句时自动触发执行。
此外触发器是逻辑电路的基本单元电路,具有记忆功能,可用于二进制数据储存,记忆信息等。
触发器有如下作用:
- 可在写入数据表前,强制检验或转换数据。
- 触发器发生错误时,异动的结果会被撤销。
- 部分数据库管理系统可以针对数据定义语言(DDL)使用触发器,称为DDL触发器。
- 可依照特定的情况,替换异动的指令 (INSTEAD OF)。
SQL Server 包括三种常规类型的触发器:DML 触发器、DDL 触发器和登录触发器。
示例:
-
insert
create trigger tri_insert
on student
after insert 触发时间 {before | after} -- view 中是 instead of
as
-- inserted 表
go
-
delete
create trigger tri_delete
on student
delete
as
-- deleted表 存放更新之前的数据
go
-
update
create trigger tri_update
on student
for update
as
-- inserted 表存放更新之后的数据
-- deleted 存放更新之前的数据
-- 注意!!!没有updated表
go
16 数据库的基本操作
16.1 创建数据库
-- 如果存在databaseName则删除,
-- 所有的数据库都存放在sys.databases数据库中
if exists(select * from sys.databases where name = 'databaseName')
drop database databaseName -- 删除数据库
-- 创建数据库
create database databaseName
on -- 数据库文件
(
name = 'databaseName', -- 逻辑名称
filename = 'D:\databaseName.mdf', -- 物理路径和名称
size = 5MB, -- 文件的初始大小
filegrowth = 2MB -- 文件增长方式可以写大小,也可以是百分比
)
log on -- 日志文件
(
name = 'databaseName_log', -- 逻辑名称
filename = 'D:\databaseName_log.ldf', -- 物理路径和名称
size = 5MB, -- 文件的初始大小
filegrowth = 2MB -- 文件增长方式可以写大小,也可以是百分比
)
创建数据库简写
create databse databaseName
若不进行对数据库的参数进行设置,则所需参数都将被设为默认值。(可从右键数据库–> 属性 --> 文件)中找到
16.2 切换数据库
-- 切换数据库
use 数据库名
16.3 创建表
-- 判断表是否存在
if exists(select * from sys.objects where name = 'tableName' and type = ‘U’) -- U代表用户定义的表
--or
-- 如果test表存在,则删除
IF OBJECT_ID('test', 'U') IS NOT NULL
DROP TABLE test;
create table tableName
( 字段名1 数据类型 primary key identity(1,1), -- identity(1,1) 自动增长,初始值1 步长为1
字段名2 数据类型 not null, -- 设置为非空
字段名3 数据类型 default('男') check(字段名2='男'or 字段名2='女'), -- 只可以选择 这两个值
-- default 为设置默认值
字段名2 decimal(12,2) -- 数字总长度为12, 2保留两位小数 check(字段3>=1000 and 字段3<=10000)
字段名3 数据类型 unique, -- 唯一
字段名3 数据类型 references 表2(字段) -- 添加外键字段
)
16.4 update and insert and delete中的多表连接
- update
-- 需求: 从test1表中更新test2表中的内容
-- SQL92语法
update t2 set t2.name = t1.name from test1 t1, test2 t2 where t1.id = t2.id
or
-- SQL95语法
update t2 set t2.name = t1.name
from test1 t1
join test2 t2
on t1.id = t2.id
where 其他条件
-- 同时更新多个字段语法
update tableName set 字段1='', 字段2='' where 条件
- insert
-- 需求: 将test1中的内容插入到test2表中
-- 1、插入部分字段
insert into test2(id, name) select id, name from test1
-- 2、所有内容都插入进去
insert into test2 select * from test1 -- where 当然后面也可跟where进行筛选
- delete
-- 需求: 将test1中的内容插入到test2表中 删除test1表中 存在test2表内的id数
delete t1 from test1 t1, test2 t2 where t1.id = t2.id
16.5 修改表结构
-- 新增列
alter table 表名 add 字段1 数据类型,字段1 数据类型
-- 删除列
alter table 表名 drop column 字段1
-- 修改列
alter table 表名 alter column 字段 数据类型
16.6 维护约束
-- 删除约束
alter table 表名 drop constraint 约束名
-- 添加约束(check约束)
alter table 表名 add constraint 约束名 check(表达式)
-- 添加约束(主键约束)
alter table 表名 add constraint 约束名 primary key(列名)
-- 添加约束(唯一性约束)
alter table 表名 add constraint 约束名 unique(列名)
-- 添加约束(默认值约束)
alter table 表名 add constraint 约束名 default 默认值 for 列名
-- 添加约束(约束)
alter table 表名 add constraint 约束名 foreign key(列名) references 关联表名(列名(主键))
16.7 查看表结构
-- 查看表结构
sp_help table_name
sp_columns table_name
-- 查询某表中的主键是那个
EXEC sp_pkeys @table_name='查询的表名'
16.8 delete和truncate 的区别
1 语法区别:truncate table tabName delete from tableName。
2 选择删除,delete可以使用where条件进行选择性删除数据,而truncate却不可以。
3 删除全部表数据:使用delete删除数据,自增列会进行记录(会在之前已经删除的数据的基础上进行递增),使用truncate会从递增起始值 开始重新递增。
4 删除效率上,truncate要比delete快。因为truncate删除的时候不需要检索数据。
5 TRUNCATE TABLE 速度更快,使用的系统资源和事务日志资源更少。
参考链接:TRUNCATE TABLE (Transact-SQL) - SQL Server | Microsoft Learn
17 事务
17.1 介绍
事务(Transaction)是数据库管理系统(DBMS)的一个基本操作,它是一组操作的集合,这组操作要么全部执行,要么全部不执行。事务的ACID特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。这四个特性简称为ACID特性。
(1)原子性
事务是数据库的逻辑工作单位,事务中包括的诸多操作要么都做,要么都不做。
(2)一致性
事务执行的结必须是使数据库从一个一致性状态变到另一个一致性状态。因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。
(3)隔离性
一个事务执行不能被其他事务干扰。即一个事务的内部操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能互相干扰。
(4)持久性
持久性也称为永久性,指一个事务一旦提交,他对数据库中数据的改变就应该是永久性的。
事务是单个工作单元。 如果某一事务成功,则在该事务中进行的所有数据修改均会提交,成为数据库中的永久组成部分。 如果事务遇到错误且必须取消或回滚,则所有数据修改均被清除。
SQL Server 以下列事务模式运行:
-
自动提交事务
每条单独的语句都是一个事务。 -
显式事务
每个事务均以 BEGIN TRANSACTION 语句显式开始,以 COMMIT 或 ROLLBACK 语句显式结束。 -
隐式事务
在前一个事务完成时新事务隐式启动,但每个事务仍以 COMMIT 或 ROLLBACK 语句显式完成。 -
批处理级事务
只能应用于多个活动结果集 (MARS),在 MARS 会话中启动的 Transact-SQL 显式或隐式事务变为批处理级事务。 当批处理完成时没有提交或回滚的批处理级事务自动由 SQL Server 进行回滚。
17.2 语法
17.2.1 使用T-SQL语句设置事务:
begin transaction
-- T-SQL
commit transaction
or
BEGIN TRAN T1;
COMMIT TRAN T1;
begin transaction
-- T-SQL
rollback transaction -- 回滚事务
17.2.2 嵌套事务
BEGIN TRAN T1;
UPDATE table1 ...;
BEGIN TRAN M2 WITH MARK;
UPDATE table2 ...;
SELECT * from table1;
COMMIT TRAN M2;
UPDATE table3 ...;
COMMIT TRAN T1;
17.2.3 commit和rollback结合
--------------方式一----------------
-- GOTO语句
Begin TRANSACTION
语句1;
If @@error<>0 Goto error
语句2;
If @@error<>0 Goto error
Commit TRANSACTION
Return
error:
Rollback TRANSACTION
--------------方式二----------------
-- 根据@@ERROR返回值判断是否回滚数据
-- 当出现错误时 @@ERROR错误代码,否则返回0
use tempdb
GO
CREATE TABLE ValueTable ([value] INT);
GO
DECLARE @TransactionName VARCHAR(20) = 'Transaction1';
declare @flag int =0
BEGIN TRAN @TransactionName
INSERT INTO ValueTable VALUES(1), (2);
set @flag = @@ERROR
INSERT INTO ValueTable VALUES(3),(4);
set @flag = @@ERROR
if (@flag > 0)
ROLLBACK tran @TransactionName;
else
commit tran @TransactionName
SELECT [value] FROM ValueTable;
DROP TABLE ValueTable;
--------------方式三----------------
-- try catch 语句
begin tran
BEGIN TRY
INSERT INTO ValueTable VALUES(5), (6);
commit tran
END TRY
BEGIN CATCH
rollback tran
END CATCH
参考链接:事务 (Transact-SQL) - SQL Server | Microsoft Learn
18 延迟函数
waitfor delay
18.1 waitfor 定义
阻止执行批处理、存储过程或事务,直到已过指定时间或时间间隔,或者指定语句发生修改或至少返回一行为止。
18.2 语法
WAITFOR
{
DELAY 'time_to_pass'
| TIME 'time_to_execute'
| [ ( receive_statement ) | ( get_conversation_group_statement ) ]
[ , TIMEOUT timeout ]
}
18.3 参数
DELAY
可以继续执行批处理、存储过程或事务之前必须经过的指定时段,最长可为 24 小时。
‘time_to_pass’
等待的时段。 time_to_pass 可以以“datetime”数据格式指定,也可以指定为局部变量。 不能指定日期;因此,不允许指定“datetime”值的日期部分。 time_to_pass 将被格式化为 hh:mm[[:ss].mss]。
TIME
指定的运行批处理、存储过程或事务的时间。
‘time_to_execute’
WAITFOR 语句完成的时间。 可以使用“datetime”数据格式指定 time_to_execute,也可以将其指定为局部变量。 不能指定日期;因此,不允许指定“datetime”值的日期部分。 time_to_execute 将被格式化为 hh:mm[[:ss].mss],并且可以选择包括 1900-01-01 的日期。
receive_statement
有效的 RECEIVE 语句。
get_conversation_group_statement
有效的 GET CONVERSATION GROUP 语句。
TIMEOUT timeout
指定消息到达队列前等待的时间(以毫秒为单位)。
18.4 示例
18.4.1 使用 WAITFOR TIME
下面的示例在晚上 10:20 (22:20) 在 msdb 数据库中执行 sp_update_job 存储过程。
EXECUTE sp_add_job @job_name = 'TestJob';
BEGIN
WAITFOR TIME '22:20';
EXECUTE sp_update_job @job_name = 'TestJob',
@new_name = 'UpdatedJob';
END;
GO
18.4.2 使用 WAITFOR DELAY
以下示例在两小时的延迟后执行存储过程。
BEGIN
WAITFOR DELAY '02:00';
EXECUTE sp_helpdb;
END;
GO
参考链接:WAITFOR (Transact-SQL) - SQL Server | Microsoft Learn
19 视图
视图是一个虚拟表,其内容由查询定义。 视图在数据库中并不是以数据值存储集形式存在,除非是索引视图。视图通常用来集中、简化和自定义每个用户对数据库的不同认识。对视图进行修改,会影响源数据。
视图类型:用户定义视图、索引视图、分区视图、系统视图。
视图的操作
只能在当前数据库中创建视图。视图最多可以包含 1,024 列。
权限:要求在数据库中具有 CREATE VIEW 权限,并具有在其中创建视图的架构的 ALTER 权限。
create view view_Name
as
-- 查询语句
go
-- 查询视图
select * from view_Name
-- 修改视图
alter view view_Name
as
-- 查询语句
go
-- 重命名视图
drop view view_Name
create view view_NewName
as
-- 查询语句
go
-- 删除视图
DROP VIEW IF EXISTS view_Name;
参考链接:视图 - SQL Server | Microsoft Learn
20 封锁
封锁是实现并发控制的一个非常重要的技术。所谓的封锁就是事务T在对某个数据对象例如表、记录等操作之前,先向系统发出请求,对其加锁。加锁后事务T就对该该数据库对象有了一定的控制,在事务T释放它的锁之前,其他事务不能更新此数据对象。
确切的控制由封锁的类型决定。基本的封锁类型有两种:排他锁(exclusive locks,简称X锁)和共享锁(share locks,简称S锁)。
排他锁又称为写锁。若事务T对数据对象A加上X锁,则只允许T读取完和修改完A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁为止。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A。
共享锁又称为读锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁为止。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
20.1 封锁协议
在运用X锁和S锁这两种基本锁对数据对象加锁时,还需要约定一些规则。例如何时申请S锁或X锁、持锁时间、何时释放等。这些规则称为封锁协议。
1 一级封锁协议是指,事务T在修改事务R之前必须先对其加X锁,直到事务结束才释放。事务的结束包括正常结束(commit)和非正常结束(rollback)。
2 二级封锁协议是指,在一级封锁协议的基础上增加事务T在读取数据R之前必须先对其加S锁,读完后即可释放S锁。
3 三级封锁协议是指,在一级封锁协议的基础上增加事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。
| X 锁 | S 锁 | 一致性保证 | |||||
|---|---|---|---|---|---|---|---|
| 操作结束释放 | 事务结束释放 | 操作结束释放 | 事务结束释放 | 不丢失修改 | 不读‘脏’数据 | 可重复读 | |
| 一级封锁协议 | √ | √ | |||||
| 二级封锁协议 | √ | √ | √ | √ | |||
| 三级封锁协议 | √ | √ | √ | √ | √ | ||
20.2 活锁和死锁
和操作系统一样,封锁的方法可能引起活锁和死锁等问题。
20.2.1 活锁
如果事务T1封锁了数据R,事务T2又请求封锁R,于是T2等待,T3也请求封锁R,当T1释放了R上的封锁之后系统首先批准了T3的请求,T2仍然继续等待;然后T4又请求封锁R,当T3释放R上的封锁之后系统又批准了T4的请求……T2可能永远等待,这就是活锁的情形。
避免活锁的简单方法是采用先来先服务的策略。
20.2.2 死锁
如果事务T1封锁了数据R1,T2封锁了数据R2,然后T1又请求封锁R2,因T2已封锁了R2,于是T1等待T2释放R2上的锁;接着T2又申请封锁R1,因T1已封锁了R1,T2也只能等待T1释放R1上的锁。这样就出现了T1在等待T2,而T2又在等待T1的局面,T1和T2两个事务永远不能结束,形成死锁。
20.2.2.1 死锁的预防
(1)一次封锁法
一次封锁法要求每个事务必须一次将所有要使用的数据全部加锁,否则就不能继续执行。
(2)顺序封锁法
顺序封锁法是预先对数据对象规定一个封锁顺序,所有事务都按这个顺序实施封锁。
以上两种方法虽然都可以有效的防止死锁,但也存在一些问题。我们并不常用。可见操作系统中预防死锁的方法并不太适合数据库的特点,因此数据库管理系统在解决死锁的问题上普遍采用的是诊断并解除死锁的方法。
20.2.2.2 查找死锁
-- 查看当前库中有哪些表是发生死锁
SELECT request_session_id
spid,OBJECT_NAME(resource_associated_entity_id)tableName
FROM
sys.dm_tran_locks
WHERE resource_type='OBJECT'
-- sys.dm_exec_requests DMV 提供了有关在 SQL Server 中运行的所有进程的详细信息。使用下面列出的 sql语句,将返回阻塞的进程。
select * from sys.dm_exec_requests
WHERE blocking_session_id <> 0;
-- sys.dm_os_waiting_tasks DMV 返回有关正在等待资源的任务的信息。要查看数据,用户应对实例具有 SQL Server 系统管理员或 VIEW SERVER STATE 权限。
select session_id,wait_duration_ms,wait_type,blocking_session_id
from sys.dm_os_waiting_tasks
WHERE blocking_session_id <> 0
21 拼接SQL
declare @temp nvarchar(255) = 'select * from [dbo].[t_f02]'+ 'where crid = 2'
-- 方式一
exec(@temp)
-- 方式二(推荐使用)
-- 注意该存储过程的参数必须为'ntext/nchar/nvarchar'
exec sp_executesql @temp
这两个语句都可以用于执行动态 SQL。不过,它们在实现上有一些区别。
exec(@temp)是 T-SQL 中的 EXECUTE 语句的简写形式,它可以用来执行包含动态 SQL 代码的字符串变量。这种方式会直接执行字符串中的 SQL 代码,没有参数化和预编译的过程。因此,如果字符串中包含用户提供的输入,存在 SQL 注入的风险。exec sp_executesql @temp是一个存储过程 sp_executesql 的调用方式,它也可以用来执行动态 SQL。这种方式相对更安全,它支持参数化查询并可以预编译 SQL 语句,从而提高执行效率并防止 SQL 注入攻击。参数化查询可以通过传递参数值来代替字符串插值,从而减少了潜在的安全风险。
总结来说,推荐使用 exec sp_executesql @temp 这种方式来执行动态 SQL
23 SQL Server 服务
主要服务:
1 SQL Server (MSSQLSERVER)
提供数据的存储、处理和受控访问,并提供快速的事务处理(一个关系数据库管理系统 (RDBMS),用于管理和存储数据)。
2 SQL Full-text Filter Daemon Launcher (MSSQLSERVER)
用于启动全文筛选器后台程序进程的服务,该进程将为 SQL Server 全文搜索执行文档筛选和断字。禁用此服 务将使 SQL Server 的全文搜索功能不可用(是 SQL Server 中的一个全文索引服务,用于提高全文搜索的性能和准确性)。
3 SQL Server Integration Services 15.0
为 SSIS 包的存储和执行提供管理支持(SSIS 是 SQL Server 提供的一种数据集成服务,可以用于数据导入、数据转换、数据清理、数据加载等任务)。
4 SQL Server Analysis Services (MSSQLSERVER)
为商业智能应用程序提供联机分析处理(OLAP)和数据挖掘功能(是 SQL Server 提供的一种多维数据分析服务,用于创建和分析数据仓库中的多维数据模型)。
5 SQL Server Browser
将 SQL Server 连接信息提供给客户端计算机(是 SQL Server 中的一个网络服务,用于帮助客户端应用程序查找 SQL Server 实例的网络地址和端口号)。
6 SQL Server 代理 (MSSQLSERVER):执行作业、监视 SQL Server、激发警报,以及允许自动执行某些管 理任务(SQL Server 提供的一种任务调度服务,用于执行自动化任务和定期作业)。
7 SQL Server VSS Writer:提供用于通过 Windows VSS 基础设施备份/还原 Microsoft SQL Server 的接 口。
其他服务:
8 SQL Server Analysis Services CEIP (MSSQLSERVER):CEIP service for Sql Server Analysis Services
9 **SQL Server Integration Services CEIP service 15.0 CEIP **:service for Sql server Integration Services
10 SQL Server Integration Services Scale Out Master 15.0:SQL Server Integration Services Scale Out的 Scale Out Master。
11 SQL Server Integration Services Scale Out Worker 15.0:SQL Server Integration Services Scale Out 的 Scale Out Worker。
12 SQL Server CEIP service (MSSQLSERVER):CEIP service for Sql server
13 SQL Server Distributed Replay Client:与 Distributed Replay 控制器一起工作的一台或多台 Distributed Replay 客户端计算机,用来模拟 SQL Server 实例上的并发工作负荷。
14 SQL Server Distributed Replay Controller:提供多个 Distributed Replay 客户端计算机上的跟踪重播 业务流程。
24 SQL Server代理 or 计划任务 or 作业
24.1 介绍
SQL Server 代理是一项 Microsoft Windows 服务,它在执行计划的管理任务,这些任务 SQL Server 中被称为“作业”。SQL Server 代理使用 SQL Server 存储作业信息。 作业包含一个或多个作业步骤。 每个步骤都有自己的任务。例如,备份数据 库。
SQL Server 代理可以按照计划运行作业,也可以在响应特定事件时运行作业,还可以根据需要运行作业。 例如,如果希望在每个工作日下班后备份公司的所有服务器,就可以使该任务自动执行。 安排备份在星期一到星期五 22:00 之后运行。 如果备份遇到问题,SQL Server 代理可记录该事件并通知你。
默认情况下,SQL Server 安装后 SQL Server 代理服务处于禁用状态,除非用户明确选择自动启动该服务。
作业是 SQL Server 代理执行的一系列指定操作。 使用作业能够定义可一次或多次运行的,并且可以监视其成功或失败状态的管理任务。 一个作业可在一台本地服务器或者多台远程服务器上运行。
24.2 创建作业
1 首先在创建作业之前需要开启SQLServer 代理服务,右键—>启动
2 启动完成后,我们会看到一下页面。
3 右键新建作业,选择常规
4 进行下一步,选择步骤。
在此步骤内你可以新建多个作业步骤,对步骤调整顺序依次执行。

5 新建作业步骤,建立一个删除表的步骤为例。
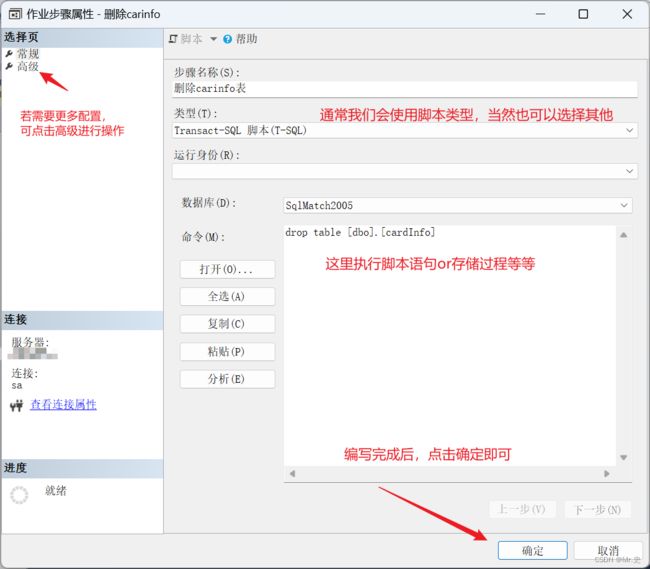
6 选择计划,新建计划,这里规定我们的作业在何时执行,通常我们会选择重复执行,例如:在每周六晚23:00执行计划。

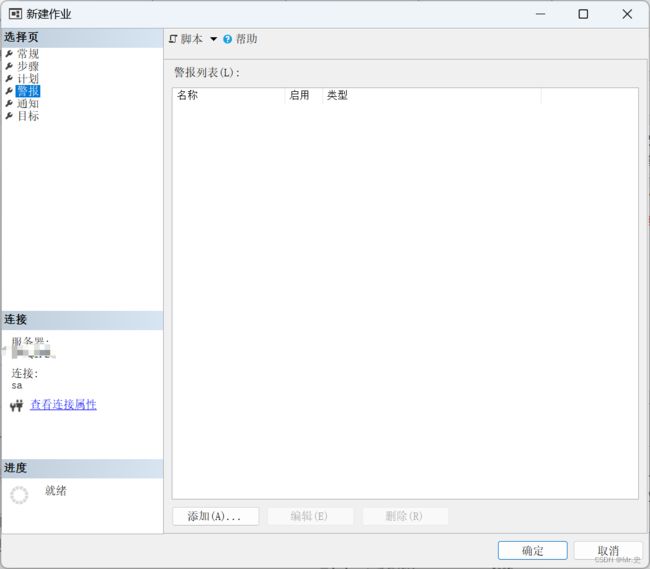
7 警告
添加警告,当作业出现错误时,要执行哪些操作。(因当前示例太过简单,这里我们不做设置)
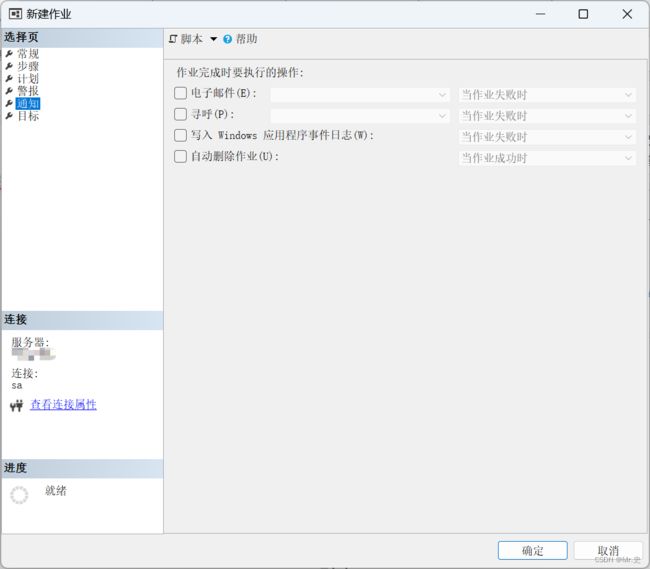
8 通知
即作业完成时我们需要做的操作。
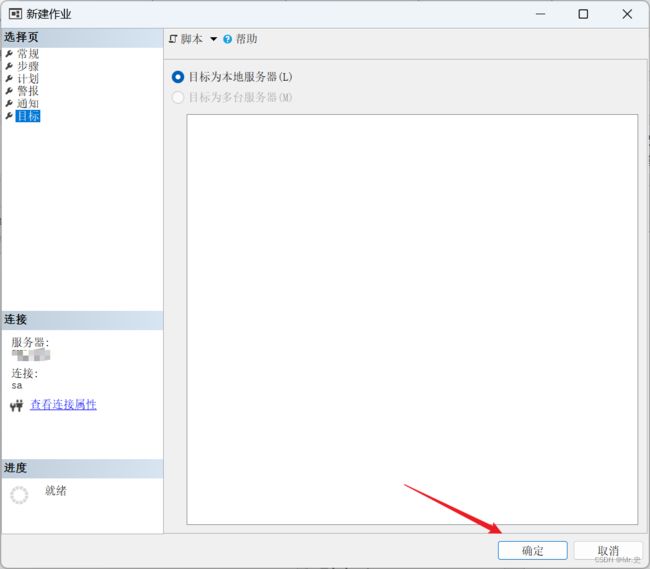
9 目标
选择此作业要执行的服务器。
10 到此为止,一个作业便创建完成,最后检查一下,作业是否启用。
启用后,作业将会在指定时间执行作业。
参考链接:SQL Server 代理 - SQL Server Agent | Microsoft Learn
参考链接:初识SQL Server代理&作业_sql server 作业_MelonSuika的博客-CSDN博客
25 SQL Server分布式部署
参考链接:部署高可用性 SQL Server 大数据群集 - Deploy SQL Server Big Data Cluster with high availability | Microsoft Learn
26 SQL Server 跨库/服务器查询
此篇内容过长,已拆分出来。
参考链接:SQL Server 跨库/服务器查询_Mr.史的博客-CSDN博客