类别感知目标计数:Class-aware Object Counting 论文笔记
类别感知目标计数:Class-aware Object Counting 论文笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 R-CNN
- 3.2 Context-aware crowd counting
- 3.3 Crowd FPN
- 四、方法
-
- 4.1 Multiclass density estimation network
- 4.2 Detection pipeline
- 4.3 Count estimation network
- 4.4 Loss functions
- 五、实验与讨论
-
- 5.1 Implementation details
- 5.2 Evaluation metrics
- 5.3 数据集
- 5.4 计数结果
- 5.5 Ablation Study
- 5.6 CEN variants
- 六、结论和展望
写在前面
开学归来,正式复工~
这是一篇多类别目标计数的文章,思路清晰,但公式表达的不是太好(有点云里雾里的),暂未开源。
- 论文链接:Class-aware Object Counting
- 代码链接:暂无
- 收录于 WACV 2022 workshop
一、Abstract
现有基于检测的模型非常适合类别感知目标计数以及低密度目标计数任务,但是在目标数量较多或者多类别目标的数量不同时,性能较差。因此本文基于检测的方法,提出了一种带有多类别密度估计分支的端到端网络。特别之处在于将所有分支预测的结果喂给一个连续的计数估计网络,从而预测出每个类别的数量。
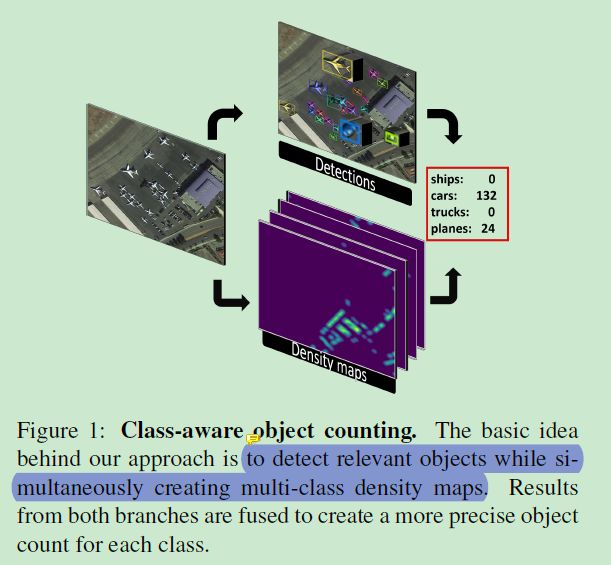 本文核心的idea:检测相关目标的同时建立多类别密度图,之后所有分支的结果融合来生成每个类别的精确计数结果。
本文核心的idea:检测相关目标的同时建立多类别密度图,之后所有分支的结果融合来生成每个类别的精确计数结果。
二、引言
首先指出目标计数的应用,包含交通监测、幸存人员检测、公众安全监管(防止多人聚集)、城市规划等。而为了解决这些问题,提出了人群计数(可以泛化到目标计数)任务,一般的解决方法有基于检测的、基于回归的以及基于密度估计的。
类比目标检测的发展,基于检测的方法有可以分为单阶段和双阶段检测。虽然基于目标检测的方法在低密度图像计数中表现很好,但是在稠密图像中的表现很差。
与上述基于检测的方法进行对比,虽然直接回归的方法更适合,但却不能充分利用空间分布信息。与之相反的是,基于密度估计的方法很受欢迎。该方法不是直接预测全局数量或者精确的位置,而是生成相关类别的密度图,之后对密度图进行统计即可进行全局计数。但是该方法易在稀疏场景上过度估计,因此在低密度计数中表现差些。
此外,最近所有的基于密度估计的方法均不适用于当前的多类别感知模型,最主要的问题在于各个类别密度上的变化较大。接下来作者指出多类别目标计数的工作较少,因此本文在DecidedNet的基础上提出了一种多类别密度估计网络。该网络可用于类别感知目标计数以及作为目标检测的基础结构。
本文贡献如下:
- 提出一种新颖的类别感知密度估计方法,能够整合到目标检测和实例分割模型中;
- 该方法包含了一个计数估计网络用于预测不同类别目标的数量,也可以用于验证目标检测的结果;
- 效果很好。

目前先进的目标计数方法一般关注于单类别计数,但是现实场景是待计数目标的尺寸和形状变化极大,同时包含了很多不相关的类别。
三、相关工作
3.1 R-CNN
回顾一下CNN的发展。
3.2 Context-aware crowd counting
[18] Weizhe Liu, Mathieu Salzmann, and Pascal Fua. Contextaware crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5099–5108, 2019.
3.3 Crowd FPN
[20] Andreas Michel, Jonas Mispelhorn, Fabian Schenkel, Wolfgang Gross, and Wolfgang Middelmann. An approach to improve detection in scenes with varying object densities in remote sensing. In Lorenzo Bruzzone, Francesca Bovolo, and Emanuele Santi, editors, Image and Signal Processing for Remote Sensing XXVI, volume 11533, pages 107 – 113. International Society for Optics and Photonics, SPIE, 2020.
四、方法
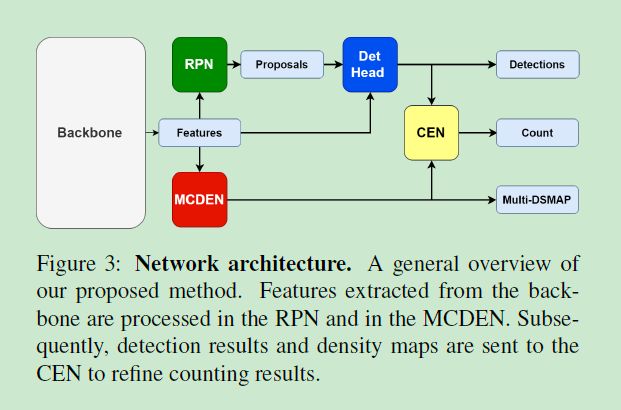
本文提出的方法由多类别密度估计网络 multi-class density estimation Network (MCDEN) 和检测通道组成,之后这两者的输出作为计数估计网络 count estimation network (CEN) 的输入。
根据 Fig. 3,利用 FPN 作为 backbone 提取不同感受野和语义水平的特征图,然后分别送入到含有 RPN 的检测管道中(包含NMS,boxhead,可选的 maskhead) 以及带有密度估计分支的 MCDEN 中,MCDEN 输出类别感知的密度图。两条支路的将结果作为 CEN 的输入来预测每个类别的数量。
4.1 Multiclass density estimation network

模型的输入为一系列的训练图像 { I i } 1 ≤ i ≤ N {\{}I_i{\}}_{1\le i \le N} {Ii}1≤i≤N 和相关联的 GT 密度图 { D i , j g t } 1 ≤ j ≤ c {\{}D_{i,j}^{gt}{\}}_{1\le j \le c} {Di,jgt}1≤j≤c,其中 c c c 为不同的目标类别。设计模型以使得对于每一个目标类别,由参数 θ \theta θ 学习的映射 F j \mathcal F_{j} Fj 可以估计出 c c c 的密度图 { D i , j g t } {\{}D_{i,j}^{gt}{\}} {Di,jgt}。而 F j \mathcal F_{j} Fj 可以通过最小化 GT 和预测的 L 2 L_2 L2 之间的正则化距离得到,用公式表示为:
D i , j est ( I i ) = F j ( I i , θ ) D_{i, j}^{\text {est }}\left(I_{i}\right)=\mathcal{F}_{j}\left(I_{i}, \theta\right) Di,jest (Ii)=Fj(Ii,θ)
下面是具体流程:首先 FPN 输出 4 个相关联的特征图 f s f_s fs,缩放因子为 s ∈ 1 4 , 1 8 , 1 16 , 1 32 s \in {\frac{1}{4},\frac{1}{8},\frac{1}{16},\frac{1}{32}} s∈41,81,161,321,用公式表示为:
f s = { I b i ( F F P N , s 4 ( I ) ) I b i ( F F P N , s 3 ( I ) ) F F P N , s 2 ( I ) F d ( F F P N , s 1 ( I ) ) f_{s}=\left\{\begin{array}{c} \mathcal{I}_{b i}\left(\mathcal{F}_{\mathrm{FPN}, s_{4}}(I)\right) \\ \mathcal{I}_{b i}\left(\mathcal{F}_{\mathrm{FPN}, s_{3}}(I)\right) \\ \mathcal{F}_{\mathrm{FPN}, s_{2}}(I) \\ \mathcal{F}_{d}\left(\mathcal{F}_{\mathrm{FPN}, s_{1}}(I)\right) \end{array}\right. fs=⎩⎪⎪⎨⎪⎪⎧Ibi(FFPN,s4(I))Ibi(FFPN,s3(I))FFPN,s2(I)Fd(FFPN,s1(I))其中 I b i \mathcal{I}_{b i} Ibi 为双线性插值的上采样, F d \mathcal{F}_{d} Fd 为下采样操作。同时为了增加尺度感知能力,有:
δ l = s l − s 1 l ∈ { 2 , 3 , 4 } \delta_{l}=s_{l}-s_{1} \quad l \in\{2,3,4\} δl=sl−s1l∈{2,3,4}其中 δ \delta δ 记为对比特征,对于每一个对比特征,有
w l = F s a l ( δ l , θ s a l ) w_{l}=\mathcal{F}_{s a}^{l}\left(\delta_{l}, \theta_{s a}^{l}\right) wl=Fsal(δl,θsal)
其中 F s a l \mathcal{F}_{s a}^{l} Fsal 为 1 × 1 1\times1 1×1 卷积层的输出,之后跟着一个sigmoid和尺度感知操作。最终,对尺度感知特征和对比特征进行逐元素乘法操作,并将它们与特征图 f s 1 f_{s 1} fs1 逐通道拼接,有:
f I = [ f s 1 ∣ ∑ l = 2 4 ω l ⊙ s l ] f_{I}=\left[f_{s_{1}} \mid \sum_{l=2}^{4} \omega_{l} \odot s_{l}\right] fI=[fs1∣l=2∑4ωl⊙sl]
之后,对于每一个类别 c c c,利用一个特定的解码器网络 F dc \mathcal F_{\text {dc}} Fdc,有:
D c e s t = { F d c , 1 ( f I ) ⋮ F d c , j ( f I ) ⋮ F d c , c ( f I ) D_{c}^{\mathrm{est}}=\left\{\begin{array}{c} \mathcal{F}_{\mathrm{dc}, 1}\left(f_{I}\right) \\ \vdots \\ \mathcal{F}_{\mathrm{dc}, j}\left(f_{I}\right) \\ \vdots \\ \mathcal{F}_{\mathrm{dc}, c}\left(f_{I}\right) \end{array}\right. Dcest=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧Fdc,1(fI)⋮Fdc,j(fI)⋮Fdc,c(fI)解码器由多个膨胀卷积序列组成,之后接上正则化和 ReLU \text{ReLU} ReLU 激活函数。
4.2 Detection pipeline
检测管道主要源于 Mask R-CNN,需要注意的是,本文添加了一个可选的 maskhead,作用是估计潜在目标的分割掩码。(吐槽一下,这本来就是Mask R-CNN上的)
4.3 Count estimation network

对于某个目标类别 j j j 有:
C E N j = F stage 2 ( B j est + λ res ⋅ I b i ( F stage 1 ( D j est ) ) ) \mathrm{CEN}_{j}=\mathcal{F}_{\text {stage } 2}\left(B_{j}^{\text {est }}+\lambda_{\text {res }} \cdot \mathcal{I}_{b i}\left(\mathcal{F}_{\text {stage } 1}\left(D_{j}^{\text {est }}\right)\right)\right) CENj=Fstage 2(Bjest +λres ⋅Ibi(Fstage 1(Djest )))
其中 F stage 1 \mathcal{F}_{\text {stage } 1} Fstage 1 和 F stage 2 \mathcal{F}_{\text {stage } 2} Fstage 2 分别是 Fig. 4 中的两个操作,分别由全卷积层和多层全连接层组成。 I b i \mathcal{I}_{b i} Ibi 是有着固定输出尺寸 c × ϵ c\times\epsilon c×ϵ 的双线性插值。 ϵ \epsilon ϵ 为训练中可调的超参数, c c c 是目标类别的数量。 B e s t \mathcal B_{est} Best 和 D e s t \mathcal D_{est} Dest 分别为检测管道和密度估计管道的输出结果。 λ r e s ∈ [ 0 , 1 ] \lambda_{res}\in[0,1] λres∈[0,1] 为尺度调整因子,记为:
λ res , j = ∑ x = 1 X ∑ y = 1 Y ( F stage1 ( D j est ( x , y ) ) ∑ x = 1 X ∑ y = 1 Y I b i ( F stage 1 ( D j est ( x , y ) ) ) \lambda_{\text {res }, j}=\frac{\sum_{x=1}^{X} \sum_{y=1}^{Y}\left(\mathcal{F}_{\text {stage1 }}\left(D_{j}^{\text {est }}(x, y)\right)\right.}{\sum_{x=1}^{X} \sum_{y=1}^{Y} \mathcal{I}_{b i}\left(\mathcal{F}_{\text {stage } 1}\left(D_{j}^{\text {est }}(x, y)\right)\right)} λres ,j=∑x=1X∑y=1YIbi(Fstage 1(Djest (x,y)))∑x=1X∑y=1Y(Fstage1 (Djest (x,y))其中 x , y x,y x,y 为给定长宽为 X × Y X\times Y X×Y 的图像上的像素坐标。
B e s t \mathcal B_{est} Best 和 D e s t \mathcal D_{est} Dest 之后喂入CEN:首先 D e s t \mathcal D_{est} Dest 经过一个 32 核滤波器的 2D 卷积,之后跟着一个 batch正则化和 ReLU \text{ReLU} ReLU 激活函数,重复该操作,这样再通一个 c c c 滤波器的 2D卷积即为输出。接着用另外一组 batch正则化和 ReLU \text{ReLU} ReLU 激活函数处理,最终的结果插值为一个维度为 c × ϵ c \times\epsilon c×ϵ 的矩阵,之后经一个尺度因子 λ r e s \lambda_{res} λres 和一个裁剪操作输出。
此外,对于每一个类别 j j j,来自于检测通道计算的目标将会保存为向量 v ∈ N c v\in\mathbb N^{c} v∈Nc,将此向量与之前得到的检测结果 B j est B_{j}^{\text{est}} Bjest 拼接然后喂给一个 2 层稠密层的序列,经过 batch正则化和 ReLU \text{ReLU} ReLU 激活,再经过一个稠密层可得到每个类别估计的数量。
4.4 Loss functions
L = L d e t + 1 c ∑ j = 1 c L d s , j + L c e n L=L_{\mathrm{det}}+\frac{1}{c} \sum_{j=1}^{c} L_{\mathrm{ds}, \mathrm{j}}+L_{\mathrm{cen}} L=Ldet+c1j=1∑cLds,j+Lcen
其中 L d e t L_{\mathrm{det}} Ldet 为检测损失, L d s L_{\mathrm{ds}} Lds为密度损失, L c e n L_{\mathrm{cen}} Lcen 为 CEN 损失。 L d s , j L_{\mathrm{ds}, \mathrm{j}} Lds,j 通过聚合所有目标类别 c c c 和一个训练图像 I ′ ∈ I I\prime\in I I′∈I 的 batch_size N ′ < N N\prime< N N′<N 的 L 2 L^2 L2 正则化计算得到,记为:
L d s = 1 2 N ′ ∑ i = 1 N ′ ∥ D i g t − D i e s t ∥ 2 L_{\mathrm{ds}}=\frac{1}{2 N^{\prime}} \sum_{i=1}^{N^{\prime}}\left\|D_{i}^{\mathrm{gt}}-D_{i}^{\mathrm{est}}\right\|^{2} Lds=2N′1i=1∑N′∥∥Digt−Diest∥∥2而
L c e n = λ c e n 2 N ′ ∑ i = 1 N ′ ∥ D i g t − D i e s t ∥ 2 D i g t L_{\mathrm{cen}}=\frac{\lambda_{\mathrm{cen}}}{2 N^{\prime}} \sum_{i=1}^{N^{\prime}} \frac{\left\|D_{i}^{\mathrm{gt}}-D_{i}^{\mathrm{est}}\right\|^{2}}{D_{i}^{\mathrm{gt}}} Lcen=2N′λceni=1∑N′Digt∥∥Digt−Diest∥∥2其中 λ c e n ∈ [ 0 , 1 ] \lambda_{\mathrm{cen}}\in[0,1] λcen∈[0,1] 是为了降低 L cen L_{\text{cen}} Lcen 而设置的常量,除以 2 N ′ 2N\prime 2N′ 则是为了平衡样本类别数量高低的影响。
五、实验与讨论
5.1 Implementation details
ResNet50,Faster R-CNN 和 Mask R-CNN 作为目标检测和实例分割管道,增加了候选proposals的数量,将 NMS 过滤的数量提升到 2K,此外,每幅图像的可能检测到的目标为 1K 个。 λ cen = 0.2 \lambda_{\text{cen}}=0.2 λcen=0.2, ϵ = 128 \epsilon=128 ϵ=128, α = 3 ⋅ 1 0 − 3 \alpha=3\cdot 10^{-3} α=3⋅10−3,在 50 个 epoch 之后, α \alpha α 逐步减小为 1 0 − 3 10^{-3} 10−3。采用 AdamW 优化器,衰减因子为 1 0 − 4 10^{-4} 10−4。GT密度图利用 geometry adaptive Gaussian kernel [33] 从 box 坐标中得到。
[33] Yingying Zhang, Desen Zhou, Siqin Chen, Shenghua Gao, and Yi Ma. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 589–597, 2016.
5.2 Evaluation metrics
平均绝对误差:
M A E j = 1 N ∑ i = 1 N ∣ Q i , j e s t − Q i , j g t ∣ \mathrm{MAE}_{j}=\frac{1}{N} \sum_{i=1}^{N}\left|Q_{i, j}^{e s t}-Q_{i, j}^{g t}\right| MAEj=N1i=1∑N∣∣Qi,jest−Qi,jgt∣∣其中 N N N 为测试图像的数量
均方绝对误差:
RMSE j = 1 N ∑ i = 1 N ( Q i , j e s t − Q i , j g t ) 2 \operatorname{RMSE}_{j}=\sqrt{\frac{1}{N} \sum_{i=1}^{N}\left(Q_{i, j}^{e s t}-Q_{i, j}^{g t}\right)^{2}} RMSEj=N1i=1∑N(Qi,jest−Qi,jgt)2其中 Q i , j e s t Q_{i, j}^{e s t} Qi,jest 为第 i i i 幅图像中对于一个类别 j j j 的相关目标的估计数量, Q i , j g t Q_{i, j}^{g t} Qi,jgt 为对应的 GT。此外,还有 m M A E = 1 c ∑ j = 1 c M A E j \mathrm{mMAE}=\frac{1}{c} \sum_{j=1}^{c} \mathrm{MAE}_{j} mMAE=c1∑j=1cMAEj 和 m R M S E = 1 c ∑ j = 1 c R M S E j \mathrm{mRMSE}=\frac{1}{c} \sum_{j=1}^{c} \mathrm{RMSE}_{j} mRMSE=c1∑j=1cRMSEj ,其中 Q e s t Q^{est} Qest 是每个分支单独计算的结果。在检测管道中, Q e s t , d e t Q^{est,det} Qest,det 是通过计算检测的数量得到的, Q e s t , d s Q^{est,ds} Qest,ds 是通过整合密度分支中估计的密度图上的像素得到的。最终 CEN的输出为:
Q e s t , c e n = C E N e s t Q^{est,cen}=CEN^{est} Qest,cen=CENest
5.3 数据集
目前并不存在公开的带有高度变化的多类别目标计数数据集,因此,利用下列常见的目标检测数据集:
- Visdrone-Det:10209张图像,10个类别,训练集6471,验证集548,评估所用测试开发集1610。
- iSaid:源于DOTA数据集,2806张高分辨率图像,有655451个目标实例,15个类别。分辨率800x800,本文仅利用其中能移动的类别:’ship’, ’car’, ’truck’, and ’plane’。

5.4 计数结果
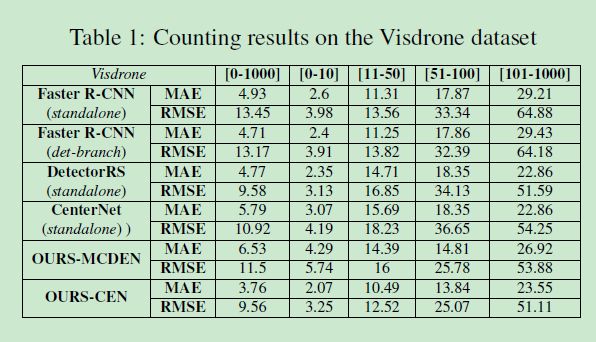

5.5 Ablation Study

5.6 CEN variants

六、结论和展望
本文提出了一种联合密度估计和目标检测的方法用于多类别目标感知计数。实验表明了在高密度图像中,密度分支的性能大于检测分支的性能,反之亦然。此外,本文表明了如何融合多个分支来提高估计的性能。同时作者认为需要有一个合适的多变的多类别目标计数数据集来推动目标计数的进步。
写在后面
淦了一下午,终于码完字了。论文思路还是简单的,可惜没有公开源码,最后的实验部分有点看不明白,需要反复阅读原文才能窥探一二。