ELK——Logstash filter的使用和Kibana应用
Logstash filter 的使用
Filter插件(过滤器插件)是Logstash功能强大的主要原因,它可以对Logstash Event进行丰富的处理,比如说解析数据、删除字段、类型转换等等,常见的有如下几个:
grok:正则匹配解析
date: 日期解析
dissect:分割符解析
mutate:对字段做处理,比如重命名、删除、替换等
json:按照json解析字段内容到指定字段中
geoip:增加地理位置数据
ruby: 利用ruby代码来动态修改Logstash Event
Grok插件
grok是一个十分强大的logstash filter插件,他可以通过正则解析任意文本,将非结构化日志数据解析成结构化和方便查询的结构内容,将其定义成我们平时容易理解的一些字段名称。他是目前logstash 中解析非结构化日志数据最好的方式。
使用grok filter需要在logstash的配置文件中加上这样的内容:
filter {
grok {
match => {
"message" => "grok_pattern"
}
}
}
这段代码中除了grok_pattern(grok表达式,[ˈpætərn]模式)以外都是logstash的关键字。grok_pattern部分需要使用者填充自己的解析方式。
grok_pattern由零个或多个%{SYNTAX:SEMANTIC}组成
其中SYNTAX是表达式的名字,即文本匹配的模式的名称,是由grok提供的,例如数字表达式的名字是NUMBER,IP地址表达式的名字是IP。
SEMANTIC表示解析出来的这个字符的名字,即为匹配的文本提供的标识符,由自己定义,例如IP字段的名字可以是client。【syntax [ˈsɪntæks]语法,semantic [sɪˈmæntɪk]语义】
对于下面这条日志:
192.168.10.3 GET /index.html 15824 0.043
可以这样解析:

将会得到这样的结果:
* client: 192.168.10.3
* method: GET
* request: /index.html
* bytes: 15824
* duration: 0.043
数字表达式的名字是NUMBER,%{NUMBER:duration}可以匹配数值类型,但是grok匹配出的内容都是字符串类型,可以通过在最后指定为int或者float来强制转换类型。%{NUMBER:duration:float}
data_type 目前只支持两个值:int 和 float。
grok提供了哪些SYNTAX?可以查看文件grok-patterns,它默认放在路径/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/目录下。
测试:创建一个测试配置文件,如test.conf,内容如下:
[root@elk01 ~]# vim /usr/local/logstash-7.3.0/config/test.conf
input {stdin{}}
filter {
grok {
match => {
"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
}
}
}
output {stdout{codec => rubydebug}}
使用test.conf启动一个logstash实例,通过键盘输入如下内容:
192.168.10.3 GET /index.html 15824 0.043
[root@elk01 ~]# logstash -f /usr/local/logstash-7.3.0/config/test.conf #之前有实例可以--path.data=换个路径

默认grok调用的是:
/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/这个目录下的正则
假设现在要匹配一个正则表达式为regexp的字符串,而grok预定义的SYNTAX都不满足,也可以自己定义一个SYNTAX。
自定义SYNTAX方式有两种:
1)直接在grok里面使用自定义表达式
语法格式:(?
?
例如:定制化字段,取出想要的字段
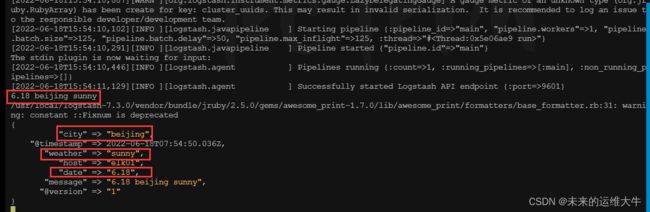
“6.18 beijing sunny”,然后取出每一个字段
编辑test.conf文件,内容如下:
[root@elk01 ~]# vim /usr/local/logstash-7.3.0/config/test.conf
input {stdin{}}
filter {
grok {
match => {
"message" => "(?\d+\.\d+)\s+(?\w+)\s+(?\w+)"
}
}
}
output {stdout{codec => rubydebug}} 运行logstash,输入“6.18 beijing sunny”内容,并查看输出结果
[root@elk01 ~]# logstash -f /usr/local/logstash-7.3.0/config/test.conf --path.data=/aa
(2)自定义表达式文件
在某个目录下创建一个文件,文件名自定义,如在/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/目录下创建正则表达式文件test
将目录加入grok路径: patterns_dir => "./patterns"
将想要增加的正则表达式写入,格式:SYNTAX_NAME regexp
使用方法和使用默认SYNTAX相同:%{SYNTAX_NAME:SEMANTIC}
例如:使用grok自定义正则去匹配下边的日志
10.173.28.112 2018-11-22 16:30:58 GET /AUTO/users/loginSuccess.do 200 46112 0.075
在/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/
目录下创建正则表达式文件test,内容如下:
[root@elk01 ~]# vim /usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/test #简单的
USER_IPADDRESS ([0-9\.]+)\s+
DATETIME ([0-9\-]+\s[0-9\:]+)\s+
METHOD ([A-Z]+)\s+
URL ([\/A-Za-z0-9\.]+)\s+
STATUS ([0-9]+)\s+
REQUEST_SEND ([0-9]+)\s+
REQUEST_TIME ([0-9\.]+)
编辑logstash配置文件test.conf文件,内容如下:
[root@elk01 ~]# vim /usr/local/logstash-7.3.0/config/test.conf
input {stdin{}}
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{USER_IPADDRESS:user_ip} %{DATETIME:date} %{METHOD:method} %{URL:url} %{STATUS:status} %{REQUEST_SEND:request_send} %{REQUEST_TIME:request_time}" }
}
}
output {stdout{codec => rubydebug}}
进入/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/目录下
运行logstash程序:查看输出结果

总结:
grok是通过系统预定义的正则表达式或者通过自己定义正则表达式来匹配日志中的各个值。
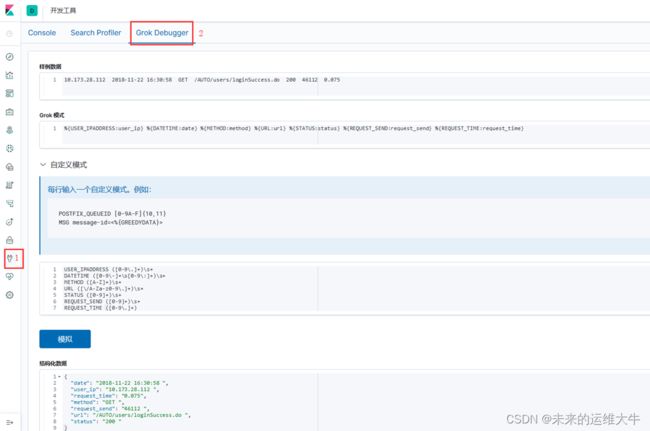
正则解析式比较容易出错,建议先调试,kibana提供了grok debbuger
使用Grok Filter插件编辑解析nginx日志
grok作为一个logstash的过滤插件,支持根据正则表达式解析文本日志行。在生产环境中,nginx日志格式往往使用的是自定义的格式,我们需要把logstash中的message结构化后再存储,方便kibana的搜索和统计,因此需要对message进行解析。
Grok插件使用详解:
Grok filter plugin | Logstash Reference [7.3] | Elastic
本文采用grok过滤器,使用match正则表达式解析,根据自己的log_format定制。
Nginx日志格式
log_format配置如下:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log main; #注释取消
$remote_addr变量:记录了客户端的IP地址(普通情况下)。
$remote_user变量:当nginx开启了用户认证功能后,此变量记录了客户端使用了哪个用户进行了认证。
$time_local变量:记录了当前日志条目的时间。
$request变量:记录了当前http请求的方法、url和http协议版本。
$status变量:记录了当前http请求的响应状态,即响应的状态码,比如200、404等响应码,都记录在此变量中。
$body_bytes_sent变量:记录了nginx响应客户端请求时,发送到客户端的字节数,不包含响应头的大小。
$http_referer变量:记录了当前请求是从哪个页面过来的,比如你点了A页面中的超链接才产生了这个请求,那么此变量中就记录了A页面的url。
$http_user_agent变量:记录了客户端的软件信息,比如,浏览器的名称和版本号。
$http_x_forwarded_for变量:简称XFF头,它代表客户端,也就是HTTP的请求端真实的IP,只有在通过了HTTP 代理或者负载均衡服务器时才会添加该项。
对应的日志如下:
编写正则表达式
logstash中默认存在一部分正则让我们来使用,在如下的文件中我们可以看到:
/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns
基本定义在grok-patterns中,我们可以使用其中的正则,当然并不是所有的都适合nginx字段,这时就需要我们自定义正则,然后通过指定patterns_dir来调用。
同时在写正则的时候可以使用Grok Debugger或者Grok Comstructor工具来帮助我们更快的调试。在不知道如何使用logstash中的正则的时候也可使用Grok Debugger的Descover(https://grokdebug.herokuapp.com/)来自动匹配。
我这里编写了一个符合这台nginx服务器的日志过滤器:
[root@elk01 ~]# cd /usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/
[root@elk01 patterns]# vim nginx-access
NGINXACCESS %{IP:clientip} - (%{USERNAME:user}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:request_method} %{NOTSPACE:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:status:int} %{NUMBER:body_sent:int} \"-\" \"%{GREEDYDATA:agent}\" \"-\"编写logstash配置文件
Logstash基本格式 input >> codec >> filter >> codec >> output ,codec用于文字编码格式转换。
配置logstash
[root@elk01 ~]# vim /usr/local/logstash-7.3.0/config/http_logstash.conf
input{
kafka {
codec => "json" #指明codec为json,因为logstash从kafka读取的日志是json格式
bootstrap_servers => "192.168.10.6:9092"
client_id => "nginx_logs"
group_id => "nginx_logs"
consumer_threads => 5
auto_offset_reset => "latest"
decorate_events => true
topics => "nginx_logs"
}
}
filter {
grok {
patterns_dir => "/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns"
match => { "message" => "%{NGINXACCESS}" }
remove_field => "message" #过滤后丢弃原有信息
}
}
output {
stdout {
codec => "rubydebug"
}
elasticsearch {
hosts => [ "192.168.10.4:9200" ]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
}注:remove_field的用法也是很常见的,他的作用就是去重,在前面的例子中你也看到了,不管是我们要输出什么样子的信息,都是有两份数据,即message里面是一份,NGINXACCESS里面也有一份,这样子就造成了重复,过滤的目的就是筛选出有用的信息,重复的不要。
重启logstash
[root@elk01 ~]# nohup logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf --path.data=/tmp & #后台运行
输出结果如下:
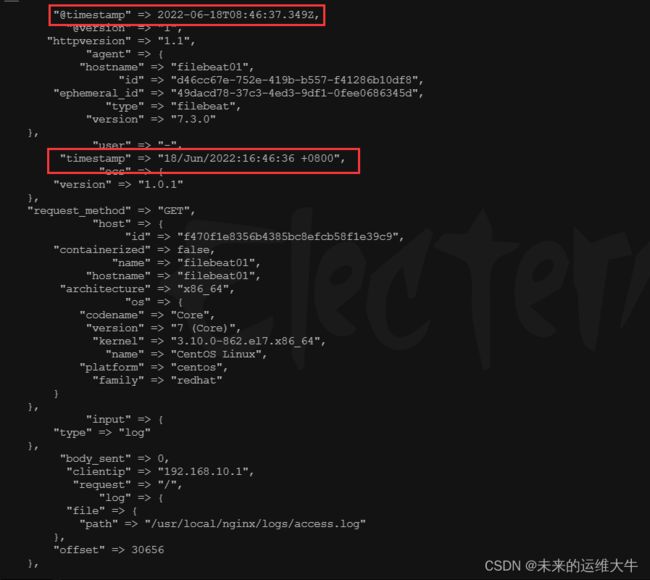
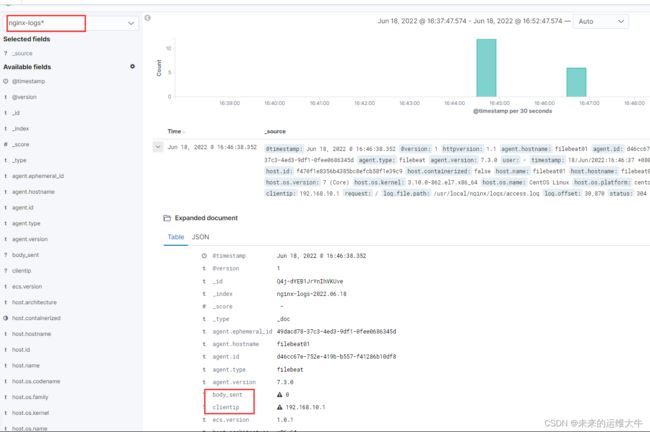
打开kibana页面,查看日志数据:
date插件
在上面我们有个例子中用到了timestamp字段,表示日志生成的时间。但是在显示的时候除了显示你指定的timestamp外,还有一行是@timestamp信息,这两个时间是不一样的,Logstash会给收集到的每条日志自动打上时间戳(即@timestamp,表示系统当前时间),但是这个时间戳记录的是input接收数据的时间,而不是日志生成的时间(因为日志生成时间与input接收的时间肯定不同),两个时间并不是一回事,在ELK的日志处理系统中,@timestamp字段会被elasticsearch用到,用来标注日志的生产时间,如此一来,日志生成时间就会发生混乱,要解决这个问题,需要用到另一个插件,即date插件,这个时间插件用来转换日志记录中的时间字符串,变成Logstash::Timestamp对象,然后转存到@timestamp字段里面。
接下来我们在logstash配置文件中配置一下:
[root@elk01 ~]# vim /usr/local/logstash-7.3.0/config/http_logstash.conf
input{
kafka {
codec => "json"
bootstrap_servers => "192.168.10.6:9092"
client_id => "nginx_logs"
group_id => "nginx_logs"
consumer_threads => 5
auto_offset_reset => "latest"
#decorate_events => true
topics => "nginx_logs"
}
}
filter {
grok {
patterns_dir => "/usr/local/logstash-7.3.0/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns"
match => { "message" => "%{NGINXACCESS}" }
#match => { "message" => "%{COMBINEDAPACHELOG}" }
remove_field => "message"
}
date { #跟grok同一级,左对齐
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
}
output {
stdout {
codec => "rubydebug"
}
elasticsearch {
hosts => [ "192.168.10.4:9200" ]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
}
重启

注意:时区偏移量需要用一个字母Z来转换。还有这里的“dd/MMM/yyyy”,你发现中间是三个大写的M,没错,这里确实是三个大写的M,我尝试只写两个M的话,转换失败。
启动一下我们看看效果:
[root@elk01 ~]# nohup logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf --path.data=/tmp &
在kibana中查看
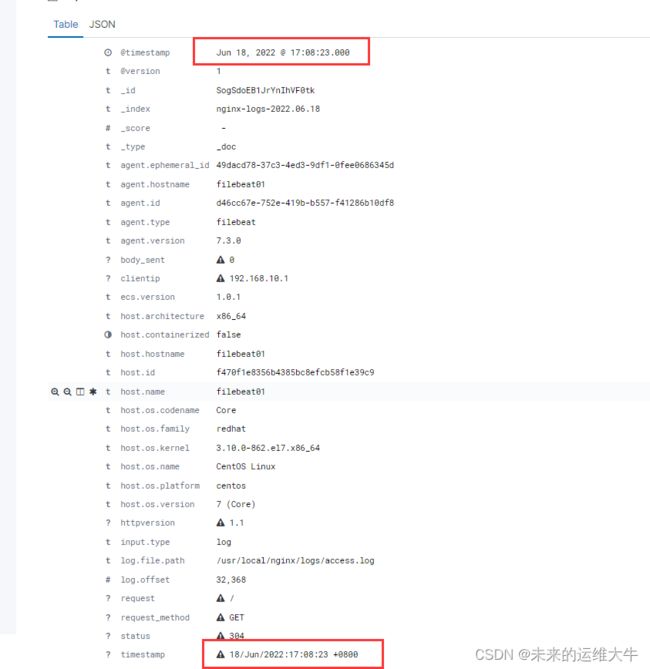
会发现@timestamp时间转换成功。
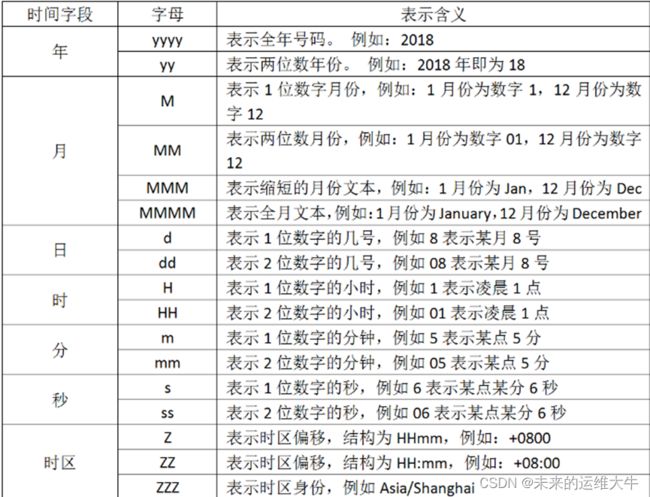
如果你要解析你的时间,你要使用字符来代替,用于解析日期和时间文本的语法使用字母来指示时间(年、月、日、时、分等)的类型。以及重复的字母来表示该值的形式。在上面看到的"dd/MMM/yyy:HH:mm:ss Z",他就是使用这种形式,我们列出字符的含义:
Geoip Filter
geoip是常见的免费的IP地址归类查询库,geoip可以根据IP地址提供对应的地域信息,包括国别,省市,经纬度等等,此插件对于可视化地图和区域统计非常有用。
该geoip插件配置要求指定包含IP地址来查找源字段的名称。在此示例中,该clientip字段包含IP地址。
由于过滤器是按顺序进行评估,确保该geoip部分是在grok配置文件之后,无论是grok和geoip部分嵌套在内部filter部分。
[root@elk01 ~]# vim /usr/local/logstash-7.3.0/config/http_logstash.conf
在filter中date后面添加:
geoip { #注意跟上面一样要同级左对齐
source => "clientip"
}
[root@elk01 ~]# nohup logstash -f /usr/local/logstash-7.3.0/config/http_logstash.conf --path.data=/tmp &
插入测试数据:
[root@filebeat01 ~]# date #获取当前日期
[root@filebeat01 ~]# echo '61.135.169.125 - - [18/Jun/2022:17:21:02 +0800] "GET /index.html HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0" "-"'>> /usr/local/nginx/logs/access.log
测试结果:
[root@elk01 ~]#cat nohup.out

kibana上面
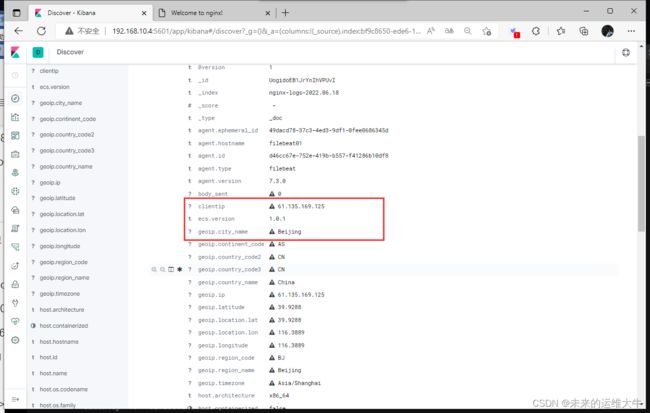
发现解析到的IP地址是中国,北京。成功了。
Logstash支持的插件
除了上面提供的grok,geoip,date插件外,官方还提供了很多logstash过滤插件,点击插件,里面有每个插件的详细解释。请查看连接:
https://www.elastic.co/guide/en/logstash/7.3/filter-plugins.html
| Plugin |
Description |
Github repository |
| aggregate |
Aggregates information from several events originating with a single task |
logstash-filter-aggregate |
| alter |
Performs general alterations to fields that the |
logstash-filter-alter |
| bytes |
Parses string representations of computer storage sizes, such as "123 MB" or "5.6gb", into their numeric value in bytes |
logstash-filter-bytes |
| cidr |
Checks IP addresses against a list of network blocks |
logstash-filter-cidr |
| cipher |
Applies or removes a cipher to an event |
logstash-filter-cipher |
| clone |
Duplicates events |
logstash-filter-clone |
| csv |
Parses comma-separated value data into individual fields |
logstash-filter-csv |
| date |
Parses dates from fields to use as the Logstash timestamp for an event |
logstash-filter-date |
| de_dot |
Computationally expensive filter that removes dots from a field name |
logstash-filter-de_dot |
| dissect |
Extracts unstructured event data into fields using delimiters |
logstash-filter-dissect |
| dns |
Performs a standard or reverse DNS lookup |
logstash-filter-dns |
| drop |
Drops all events |
logstash-filter-drop |
| elapsed |
Calculates the elapsed time between a pair of events |
logstash-filter-elapsed |
| elasticsearch |
Copies fields from previous log events in Elasticsearch to current events |
logstash-filter-elasticsearch |
| environment |
Stores environment variables as metadata sub-fields |
logstash-filter-environment |
| extractnumbers |
Extracts numbers from a string |
logstash-filter-extractnumbers |
| fingerprint |
Fingerprints fields by replacing values with a consistent hash |
logstash-filter-fingerprint |
| geoip |
Adds geographical information about an IP address |
logstash-filter-geoip |
| grok |
Parses unstructured event data into fields |
logstash-filter-grok |
| http |
Provides integration with external web services/REST APIs |
logstash-filter-http |
| i18n |
Removes special characters from a field |
logstash-filter-i18n |
| java_uuid |
Generates a UUID and adds it to each processed event |
core plugin |
| jdbc_static |
Enriches events with data pre-loaded from a remote database |
logstash-filter-jdbc_static |
| jdbc_streaming |
Enrich events with your database data |
logstash-filter-jdbc_streaming |
| json |
Parses JSON events |
logstash-filter-json |
| json_encode |
Serializes a field to JSON |
logstash-filter-json_encode |
| kv |
Parses key-value pairs |
logstash-filter-kv |
| memcached |
Provides integration with external data in Memcached |
logstash-filter-memcached |
| metricize |
Takes complex events containing a number of metrics and splits these up into multiple events, each holding a single metric |
logstash-filter-metricize |
| metrics |
Aggregates metrics |
logstash-filter-metrics |
| mutate |
Performs mutations on fields |
logstash-filter-mutate |
| prune |
Prunes event data based on a list of fields to blacklist or whitelist |
logstash-filter-prune |
| range |
Checks that specified fields stay within given size or length limits |
logstash-filter-range |
| ruby |
Executes arbitrary Ruby code |
logstash-filter-ruby |
| sleep |
Sleeps for a specified time span |
logstash-filter-sleep |
| split |
Splits multi-line messages into distinct events |
logstash-filter-split |
| syslog_pri |
Parses the |
logstash-filter-syslog_pri |
| threats_classifier |
Enriches security logs with information about the attacker’s intent |
logstash-filter-threats_classifier |
| throttle |
Throttles the number of events |
logstash-filter-throttle |
| tld |
Replaces the contents of the default message field with whatever you specify in the configuration |
logstash-filter-tld |
| translate |
Replaces field contents based on a hash or YAML file |
logstash-filter-translate |
| truncate |
Truncates fields longer than a given length |
logstash-filter-truncate |
| urldecode |
Decodes URL-encoded fields |
logstash-filter-urldecode |
| useragent |
Parses user agent strings into fields |
logstash-filter-useragent |
| uuid |
Adds a UUID to events |
logstash-filter-uuid |
| xml |
Parses XML into fields |
logstash-filter-xml |
Kibana应用
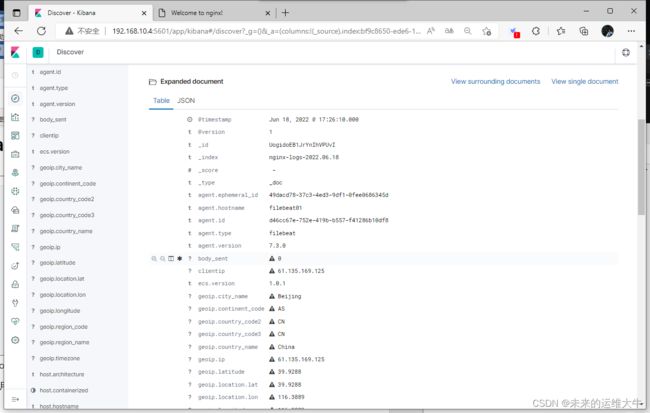
kibana中discover里查看,发现grok解析后的字段前面带有问号,点击后提示这个字段未做索引,不能用于visualize和discover的搜索。
解决方法:
Kibana界面中点击management中的index patterns,找到之前创建的index:
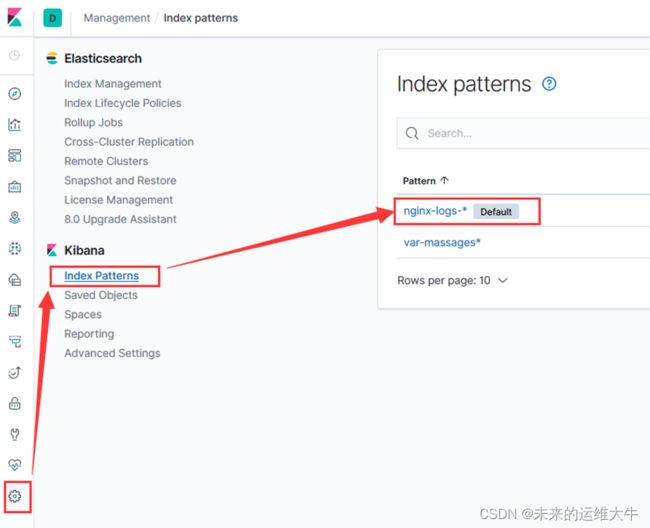
单击”nginx-logs-*” 进入index,单击刷新按钮
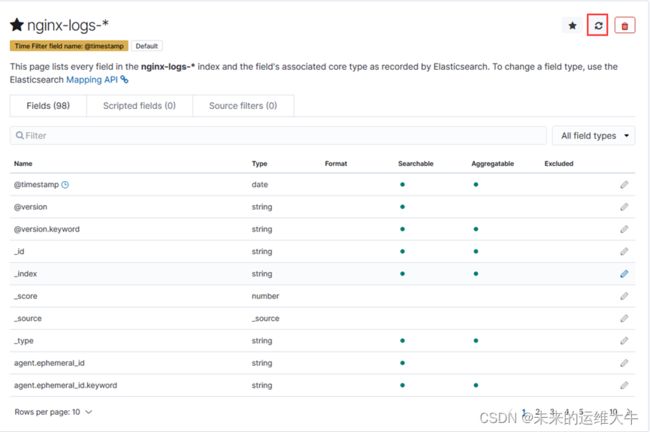
刷新后字段就被索引上了,之后便可正常使用此字段了。以后再通过logstash添加新字段时,需要在这边刷新以更新状态。
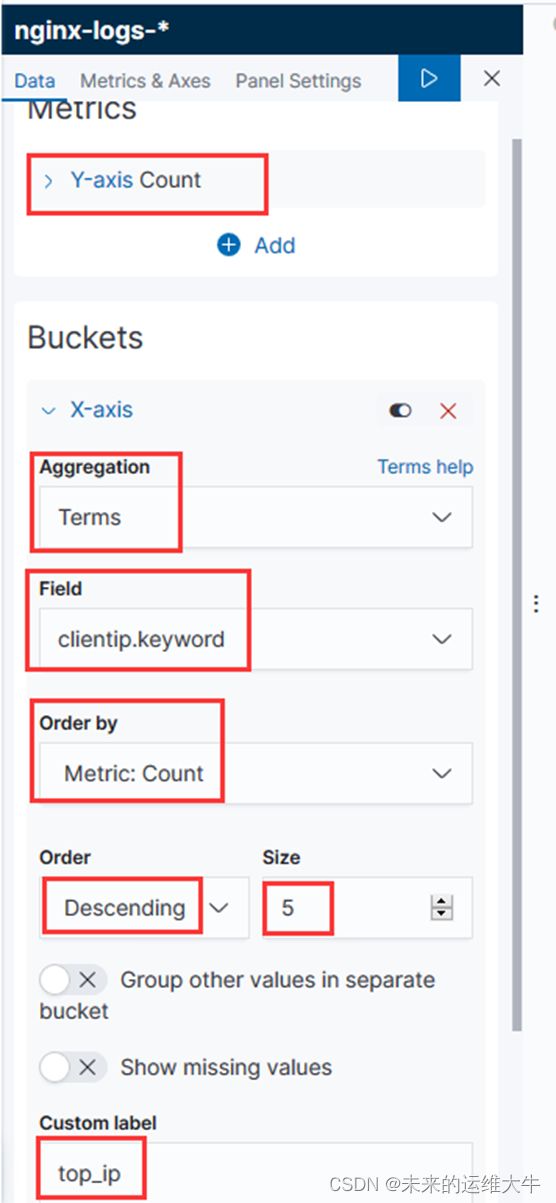
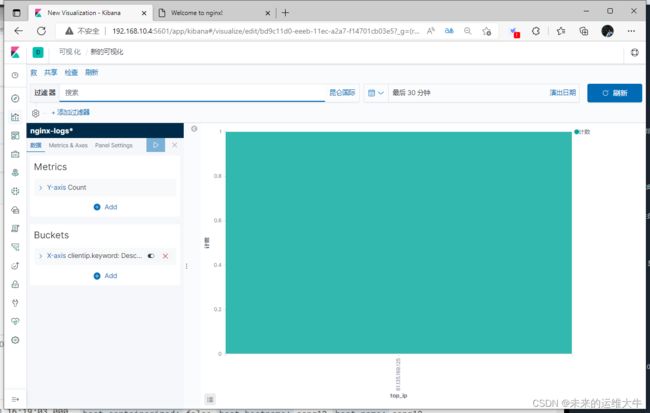
IP访问TOP5

选择柱形图
选择一个源(这里我选择的是nginx-logs-*源)
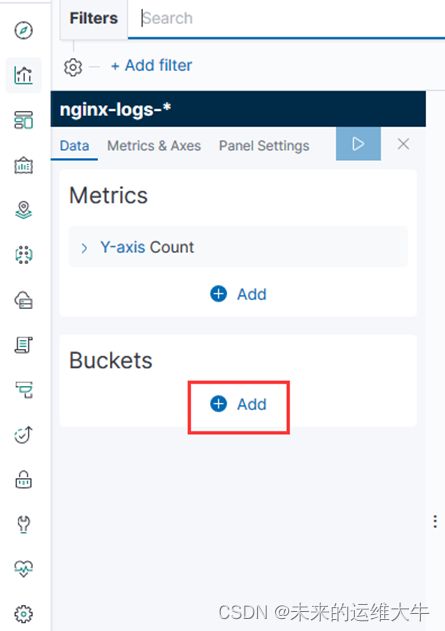
添加X轴,以clientip为排序字段
PV
选择metric

默认统计总日志条数,即为PV数

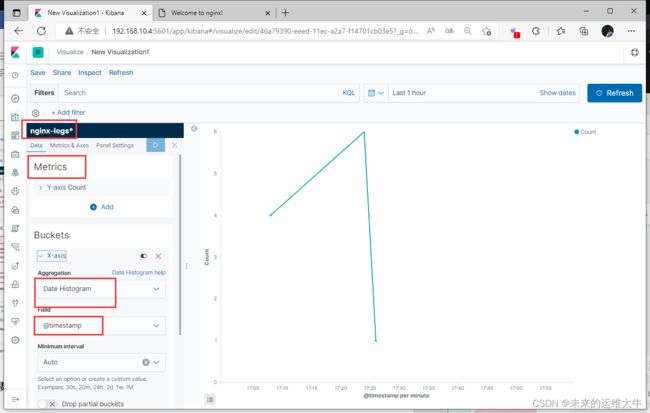
实时流量
选择线条图
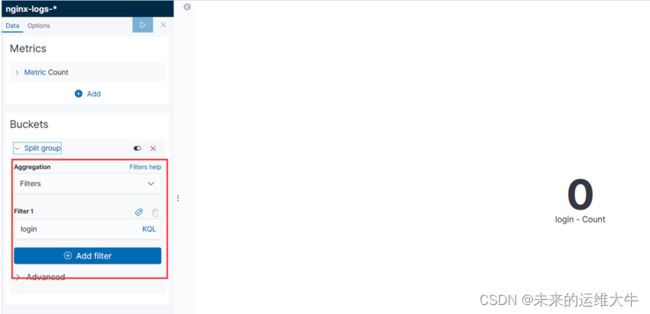
登录次数
选择metric
过滤login关键字,并做count统计
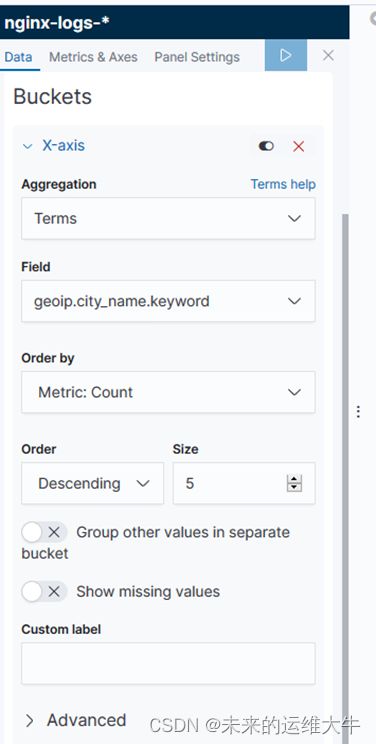
访问地区
选择柱形图

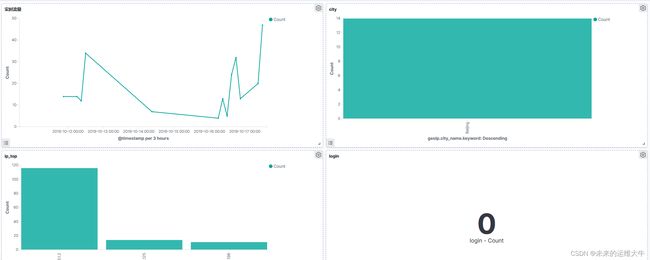
Dashboard展示
IP访问Top5:每日客户端IP请求数最多的前五个(可分析出攻击者IP)
PV:每日页面访问量
全球访问图:直观的展示用户来自哪个国家哪个地区
实时流量:根据@timestamp字段来展示单位时间的请求数(可根据异常峰值判断是否遭遇攻击)
登陆次数:通过过滤request中login的访问记录,粗略估算出进行过登陆的次数
访问地区:展示访问量最多的国家或地区
需展示其他指标,可进行自由发挥
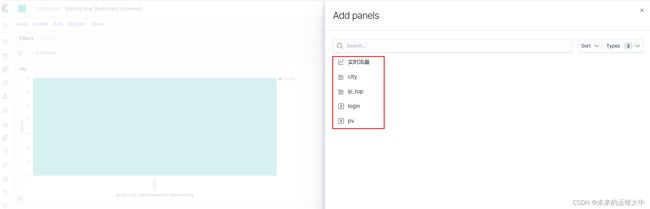
点击dashoard
单击create new dashboard

依次添加刚才创建的Visualizations(可视化)到dashboard中