大数据之spark_spark sql的自定义函数
用户自定义函数
UDF:输入一行返回一行
UDTF:输入一行返回多行,类似于flatmap
UDAF:输入多行返回一行,类似于聚合函数
用户自定义UDF函数
UDF案例1
1.在sql语句中根据ip查询省市地址
package com.doit.spark.day11
import com.doit.spark.day11.Utils.ip2Long
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
object IPDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName(this.getClass().getSimpleName).master("local[*]").getOrCreate()
//先读取IP规则数据,直接使用spark.read.textFile读文件返回的是Dataset
val ipLines: Dataset[String] = spark.read.textFile(args(0))
//Dataset是比Dataframe范围更大的一种封装,它可以调用map函数以及sparkContext
import spark.implicits._
val ipRulesInDriver: Array[(Long, Long, String, String)] = ipLines.map(line => {
val fields = line.split("[|]")
val startNum = fields(2).toLong
val endNum = fields(3).toLong
val province = fields(6)
val city = fields(7)
(startNum, endNum, province, city)
}).sort().collect()//将全部的IP规则收集到Driver端
//按照IP地址的起始十进制排序(因为以后用二分法查找)
//将ip规则数据广播到Executor端,因为DataFrame是在Dviver端生成的,所以它也可以使用广播变量
val ipRulesInDrivered: Broadcast[Array[(Long, Long, String, String)]] = spark.sparkContext.broadcast(ipRulesInDriver)
val lines: Dataset[String] = spark.read.textFile(args(1))
//使用Dataset读取和处理日志数据,最后生成DataFrame
val dataFrame: DataFrame = lines.map(line => {
val arr: Array[String] = line.split("[|]")
val ip: String = arr(1)
ip
}).toDF("ip")
//自定义函数
val select_ip: String => String = (ip:String) => {
//将字符串的ip地址转成Long类型的
val lIp: Long = ip2Long(ip)
//取用Dviver端发送过来的广播变量
val ipRulesInDriveredArr: Array[(Long, Long, String, String)] = ipRulesInDrivered.value
//调用自定义的二分查找查询ip所属范围
val i: Int = Utils.binarySearch(ipRulesInDriveredArr, lIp)
var province = "未知"
if (i != -1){
val tuple: (Long, Long, String, String) = ipRulesInDriveredArr(i)
province = tuple._3+":"+tuple._4
}
province
}
//注册函数
spark.udf.register("select_ip",select_ip)
dataFrame.createTempView("v_ip")
spark.sql(
"""
|SELECT select_ip(ip) FROM v_ip
|
|""".stripMargin).show()
}
}
UDF案例2
定义一个请求高德地图的函数,输入经纬度,返回地址值
package cn._51doit.spark.day12
import com.alibaba.fastjson.JSON
import org.apache.http.client.methods.HttpGet
import org.apache.http.impl.client.HttpClients
import org.apache.http.util.EntityUtils
import scala.collection.mutable.ListBuffer
object MyUDFs {
val gps2Loc: (Double, Double) => String = (longitude, latitude) => {
var province = ""
var city = ""
var district = ""
var bizNames = ""
//根据出入的经纬度,查找地址信息
val httpclient = HttpClients.createDefault
//创建一个GetMethod
val httpGet = new HttpGet(s"https://restapi.amap.com/v3/geocode/regeo?key=高德地图的key&location=$longitude,$latitude")
//发送请求
val response = httpclient.execute(httpGet)
val entity = response.getEntity
if (response.getStatusLine.getStatusCode == 200) {
//获取请求的json字符串
val result = EntityUtils.toString(entity)
//转成json对象
val jsonObj = JSON.parseObject(result)
//转成json对象
//获取位置信息
val regeocode = jsonObj.getJSONObject("regeocode")
if(regeocode != null && !regeocode.isEmpty) {
val address = regeocode.getJSONObject("addressComponent")
//获取省市区、商圈信息
province = address.getString("province")
city = address.getString("city")
district = address.getString("district")
val lb = new ListBuffer[String]
//商圈数组(多个)
val businessAreas = address.getJSONArray("businessAreas")
for (i <- 0 until businessAreas.size()) {
val businessArea = try {
businessAreas.getJSONObject(i)
} catch {
case e: Exception => null
}
if(businessArea != null) {
val businessName = businessArea.getString("name")
val longitudeAndLatitude = businessArea.getString("location")
val fds = longitudeAndLatitude.split(",")
lb += businessName
}
}
//[a, b] = a|b
bizNames = lb.mkString("|")
}
s"$province,$city,$district,$bizNames"
} else {
null
}
}
}
package cn._51doit.spark.day12
import org.apache.spark.sql.SparkSession
object UDFDemo3 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
val df = spark.read
.json("data/order.log")
import org.apache.spark.sql.functions._
import spark.implicits._
df.rdd.takeOrdered()
df.where($"_corrupt_record" isNull).select(
$"oid",
$"cid",
$"money",
$"longitude",
$"latitude"
).createTempView("v_log")
spark.udf.register("gps2Loc", MyUDFs.gps2Loc)
spark.sql(
"""
|SELECT
| oid,
| cid,
| money,
| gps2Loc(longitude, latitude) loc
|FROM
| v_log
|""".stripMargin).show()
spark.stop()
}
}
UDF案例3
需求,有如下数据
id,name,age,height,weight,yanzhi,score
1,a,18,172,120,98,68.8
2,b,28,175,120,97,68.8
3,c,30,180,130,94,88.8
4,d,18,168,110,98,68.8
5,e,26,165,120,98,68.8
6,f,27,182,135,95,89.8
需要计算每一个人和其他人之间的余弦相似度(特征向量之间的余弦相似度)
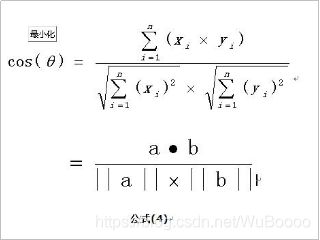
代码实现:
package cn.doitedu.sparksql.udf
import cn.doitedu.sparksql.dataframe.SparkUtil
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.UserDefinedFunction
import scala.collection.mutable
/**
* 用一个自定义函数实现两个向量之间的余弦相似度计算
*/
case class Human(id: Int, name: String, features: Array[Double])
object CosinSimilarity {
def main(args: Array[String]): Unit = {
val spark = SparkUtil.getSpark()
import spark.implicits._
import spark.sql
// 加载用户特征数据
val df = spark.read.option("inferSchema", true).option("header", true).csv("data/features.csv")
df.show()
/**
* +---+----+----+------+------+------+-----+
* | id|name| age|height|weight|yanzhi|score|
* +---+----+----+------+------+------+-----+
* | 1| a|18.0| 172.0| 120.0| 98.0| 68.8|
* | 2| b|28.0| 175.0| 120.0| 97.0| 68.8|
* | 3| c|30.0| 180.0| 130.0| 94.0| 88.8|
* | 4| d|18.0| 168.0| 110.0| 98.0| 68.8|
* | 5| e|26.0| 165.0| 120.0| 98.0| 68.8|
* | 6| f|27.0| 182.0| 135.0| 95.0| 89.8|
* | 7| g|19.0| 171.0| 122.0| 99.0| 68.8|
* +---+----+----+------+------+------+-----+
*/
// id,name,age,height,weight,yanzhi,score
// 将用户特征数据组成一个向量(数组)
// 方式1:
df.rdd.map(row => {
val id = row.getAs[Int]("id")
val name = row.getAs[String]("name")
val age = row.getAs[Double]("age")
val height = row.getAs[Double]("height")
val weight = row.getAs[Double]("weight")
val yanzhi = row.getAs[Double]("yanzhi")
val score = row.getAs[Double]("score")
(id, name, Array(age, height, weight, yanzhi, score))
}).toDF("id", "name", "features")
/**
* +---+----+--------------------+
* | id|name| features|
* +---+----+--------------------+
* | 1| a|[18.0, 172.0, 120...|
* | 2| b|[28.0, 175.0, 120...|
* | 3| c|[30.0, 180.0, 130...|
*/
// 方式2:
df.rdd.map({
case Row(id: Int, name: String, age: Double, height: Double, weight: Double, yanzhi: Double, score: Double)
=> (id, name, Array(age, height, weight, yanzhi, score))
})
.toDF("id", "name", "features")
// 方式3: 直接利用sql中的函数array来生成一个数组
df.selectExpr("id", "name", "array(age,height,weight,yanzhi,score) as features")
import org.apache.spark.sql.functions._
df.select('id, 'name, array('age, 'height, 'weight, 'yanzhi, 'score) as "features")
// 方式4:返回case class
val features = df.rdd.map({
case Row(id: Int, name: String, age: Double, height: Double, weight: Double, yanzhi: Double, score: Double)
=> Human(id, name, Array(age, height, weight, yanzhi, score))
})
.toDF()
// 将表自己和自己join,得到每个人和其他所有人的连接行
val joined = features.join(features.toDF("bid","bname","bfeatures"),'id < 'bid)
joined.show(100,false)
/**
* +---+----+--------------------------------+---+-----+--------------------------------+
* |id |name|features |bid|bname|bfeatures |
* +---+----+--------------------------------+---+-----+--------------------------------+
* |1 |a |[18.0, 172.0, 120.0, 98.0, 68.8]|2 |b |[28.0, 175.0, 120.0, 97.0, 68.8]|
* |1 |a |[18.0, 172.0, 120.0, 98.0, 68.8]|3 |c |[30.0, 180.0, 130.0, 94.0, 88.8]|
* |1 |a |[18.0, 172.0, 120.0, 98.0, 68.8]|4 |d |[18.0, 168.0, 110.0, 98.0, 68.8]|
* |1 |a |[18.0, 172.0, 120.0, 98.0, 68.8]|5 |e |[26.0, 165.0, 120.0, 98.0, 68.8]|
* |1 |a |[18.0, 172.0, 120.0, 98.0, 68.8]|6 |f |[27.0, 182.0, 135.0, 95.0, 89.8]|
* |1 |a |[18.0, 172.0, 120.0, 98.0, 68.8]|7 |g |[19.0, 171.0, 122.0, 99.0, 68.8]|
* |2 |b |[28.0, 175.0, 120.0, 97.0, 68.8]|3 |c |[30.0, 180.0, 130.0, 94.0, 88.8]|
* |2 |b |[28.0, 175.0, 120.0, 97.0, 68.8]|4 |d |[18.0, 168.0, 110.0, 98.0, 68.8]|
* |2 |b |[28.0, 175.0, 120.0, 97.0, 68.8]|5 |e |[26.0, 165.0, 120.0, 98.0, 68.8]|
* |2 |b |[28.0, 175.0, 120.0, 97.0, 68.8]|6 |f |[27.0, 182.0, 135.0, 95.0,
*/
// 定义一个计算余弦相似度的函数
// val cosinSim = (f1:Array[Double],f2:Array[Double])=>{ /* 余弦相似度 */ }
// 开根号的api: Math.pow(4.0,0.5)
val cosinSim = (f1:mutable.WrappedArray[Double], f2:mutable.WrappedArray[Double])=>{
val fenmu1 = Math.pow(f1.map(Math.pow(_,2)).sum,0.5)
val fenmu2 = Math.pow(f2.map(Math.pow(_,2)).sum,0.5)
val fenzi = f1.zip(f2).map(tp=>tp._1*tp._2).sum
fenzi/(fenmu1*fenmu2)
}
// 注册到sql引擎: spark.udf.register("cosin_sim",consinSim)
spark.udf.register("cos_sim",cosinSim)
joined.createTempView("temp")
// 然后在这个表上计算两人之间的余弦相似度
sql("select id,bid,cos_sim(features,bfeatures) as cos_similary from temp").show()
// 可以自定义函数简单包装一下,就成为一个能生成column结果的dsl风格函数了
val cossim2: UserDefinedFunction = udf(cosinSim)
joined.select('id,'bid,cossim2('features,'bfeatures) as "cos_sim").show()
spark.close()
}
}
用户自定义聚合函数UDAF
弱类型的DataFrame和强类型的Dataset都提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min()。
除此之外,用户可以设定自己的自定义UDAF聚合函数。
UDAF的编程模板(spark3.0之前):
/**
* 用户自定义UDAF入门示例:求薪资的平均值
*/
object MyAvgUDAF extends UserDefinedAggregateFunction{
// 函数输入的字段schema(字段名-字段类型)
override def inputSchema: StructType = ???
// 聚合过程中,用于存储局部聚合结果的schema
// 比如求平均薪资,中间缓存(局部数据薪资总和,局部数据人数总和)
override def bufferSchema: StructType = ???
// 函数的最终返回结果数据类型
override def dataType: DataType = ???
// 你这个函数是否是稳定一致的?(对一组相同的输入,永远返回相同的结果),只要是确定的,就写true
override def deterministic: Boolean = true
// 对局部聚合缓存的初始化方法
override def initialize(buffer: MutableAggregationBuffer): Unit = ???
// 聚合逻辑所在方法,框架会不断地传入一个新的输入row,来更新你的聚合缓存数据
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = ???
// 全局聚合:将多个局部缓存中的数据,聚合成一个缓存
// 比如:薪资和薪资累加,人数和人数累加
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = ???
// 最终输出
// 比如:从全局缓存中取薪资总和/人数总和
override def evaluate(buffer: Row): Any = ???
核心要义:
聚合是分步骤进行: 先局部聚合,再全局聚合
局部聚合(update)的结果是保存在一个局部buffer中的
全局聚合(merge)就是将多个局部buffer再聚合成一个buffer
最后通过evaluate将全局聚合的buffer中的数据做一个运算得出你要的结果
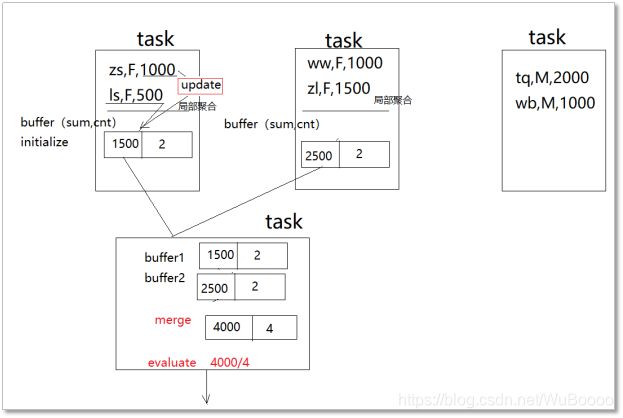
案例1:
id,sal,department
1,500,a
2,1000,a
3,2000,a
4,1000,b
5,550,c
6,600,b
7,700,c
8,800,b
用自定义函数求每个部门薪水的平均值
代码实现(spark3.0之前):
package com.doit.spark.day11
import org.apache.spark.sql.{DataFrame, SparkSession}
object AggFunctionDemo1{
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder().appName(this.getClass().getSimpleName).master("local[*]").getOrCreate()
val dataFrame: DataFrame = sparkSession.read
.option("header", "true")
.option("inferSchema", "true")
.csv("D:\\每日总结\\视频\\spark\\spark-day11\\资料\\sal.csv")
dataFrame.createTempView("v_sal")
//注册自定义的MyAvgFunction函数
sparkSession.udf.register("my_avg",MyAvgFunction)
sparkSession.sql(
"""
|SELECT department,my_avg(sal) FROM v_sal GROUP BY department
|
|""".stripMargin).show()
}
}
package com.doit.spark.day11
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, IntegerType, StructField, StructType}
object MyAvgFunction extends UserDefinedAggregateFunction{
//输入数据的类型
override def inputSchema: StructType = StructType(List(
StructField("in",DoubleType)
))
//中间要缓存的数据类型,因为需要求平均值,所以需要一个总数和一个总个数
override def bufferSchema: StructType = StructType(List(
StructField("sum",DoubleType),StructField("count",IntegerType)
))
//返回的数据类型
override def dataType: DataType = DoubleType
//输入的类型和返回的类型是否一样
override def deterministic: Boolean = true
//初始值
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0)=0.0//薪水的初始值
buffer(1)=0 //员工的数量初始值
}
//在每一个分区内局部聚合的方法,每一个组,每处理一条数据调用一次该方法
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getDouble(0) + input.getDouble(0) //历史薪水加输入的每条薪水
buffer(1) = buffer.getInt(1) + 1 //每来一条数据加1
}
//全局聚合是调用的函数
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getDouble(0) + buffer2.getDouble(0)
buffer1(1) = buffer1.getInt(1) + buffer2.getInt(1)
}
//计算最终结果的方法
override def evaluate(buffer: Row): Any = {
buffer.getDouble(0) / buffer.getInt(1)
}
}
代码实现(spark3.0之后):
package com.doit.spark.day11
import java.util.concurrent.{Executor, Executors}
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{DataFrame, Encoder, Encoders, SparkSession}
object AggFunctionDemo1{
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder().appName(this.getClass().getSimpleName).master("local[*]").getOrCreate()
val dataFrame: DataFrame = sparkSession.read
.option("header", "true")
.option("inferSchema", "true")
.csv("D:\\每日总结\\视频\\spark\\spark-day11\\资料\\sal.csv")
dataFrame.createTempView("v_sal")
//spark3.0之后直接可new Aggregator来自定义函数
//三个参数类型,分别为输入类型,中间值类型,和返回值类型
val avgAgg = new Aggregator[Double,(Double,Int),Double] {
//初始值
override def zero: (Double, Int) = (0.0,0)
//局部聚合方法
override def reduce(b: (Double, Int), a: Double): (Double, Int) = {
(b._1 + a,b._2 + 1 )
}
//全局聚合的方法
override def merge(b1: (Double, Int), b2: (Double, Int)): (Double, Int) = {
(b1._1 + b2._1,b2._2+b2._2)
}
//最终的计算方法
override def finish(reduction: (Double, Int)): Double = {
reduction._1 / reduction._2
}
//中间结果的Encoder
override def bufferEncoder: Encoder[(Double, Int)] = {
Encoders.tuple(Encoders.scalaDouble,Encoders.scalaInt)
}
//返回结果的encoder
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
//要使用udaf,需要先导入隐式参数
import org.apache.spark.sql.functions._
sparkSession.udf.register("my_avg",udaf(avgAgg))
sparkSession.sql(
"""
|SELECT department,my_avg(sal) FROM v_sal GROUP BY department
|
|""".stripMargin).show()
}
}
用自定义函数求几何平均值
package com.doit.spark.day11
import java.util.concurrent.{Executor, Executors}
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{DataFrame, Encoder, Encoders, SparkSession}
object AggFunctionDemo1{
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder().appName(this.getClass().getSimpleName).master("local[*]").getOrCreate()
val dataFrame: DataFrame = sparkSession.read
.option("header", "true")
.option("inferSchema", "true")
.csv("D:\\每日总结\\视频\\spark\\spark-day11\\资料\\sal.csv")
dataFrame.createTempView("v_sal")
//spark3.0之后直接可new Aggregator来自定义函数
//三个参数类型,分别为输入类型,中间值类型,和返回值类型
val avgAgg = new Aggregator[Double,(Double,Int),Double] {
//初始值
override def zero: (Double, Int) = (1.0,0)
//局部聚合方法
override def reduce(b: (Double, Int), a: Double): (Double, Int) = {
(b._1 * a,b._2 + 1 )
}
//全局聚合的方法
override def merge(b1: (Double, Int), b2: (Double, Int)): (Double, Int) = {
(b1._1 * b2._1,b2._2+b2._2)
}
//最终的计算方法
override def finish(reduction: (Double, Int)): Double = {
Math.pow(reduction._1, 1/reduction._2.toDouble)
}
//中间结果的Encoder
override def bufferEncoder: Encoder[(Double, Int)] = {
Encoders.tuple(Encoders.scalaDouble,Encoders.scalaInt)
}
//返回结果的encoder
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
//要使用udaf,需要先导入隐式参数
import org.apache.spark.sql.functions._
sparkSession.udf.register("my_avg",udaf(avgAgg))
sparkSession.sql(
"""
|SELECT department,my_avg(sal) FROM v_sal GROUP BY department
|
|""".stripMargin).show()
}
}