试着写几个opencv的程序
一、认识opencv
OpenCV(Open Source Computer Vision Library)是一个开源计算机视觉库,旨在提供丰富的图像处理和计算机视觉功能,以帮助开发者构建视觉应用程序。OpenCV最初由英特尔开发,现在由社区维护和支持。它支持多个编程语言,包括C++、Python、Java等,使其在各种平台上广泛应用。
以下是OpenCV的主要特点和功能:
-
图像处理:OpenCV提供了一系列强大的图像处理功能,包括图像加载、保存、裁剪、缩放、旋转、滤波、边缘检测、直方图均衡化等。
-
计算机视觉算法:OpenCV包括许多计算机视觉算法,如目标检测、特征提取、对象跟踪、人脸识别、图像分割、立体视觉等。这些功能可用于构建图像分析、模式识别和机器视觉应用。
-
机器学习集成:OpenCV与机器学习库(如scikit-learn、TensorFlow等)集成紧密,可以用于训练和部署机器学习模型,例如分类、回归和聚类任务。
-
摄像机和视频处理:OpenCV支持摄像机捕获和视频处理,可以用于实时视频分析、跟踪和处理。
-
多平台支持:OpenCV可以在多个操作系统上运行,包括Windows、Linux、macOS和Android。它还支持多个编程语言,使得开发者可以根据自己的需求选择最合适的语言。
-
优化和加速:OpenCV经过优化,可以充分利用硬件加速功能,如CPU、GPU和FPGA,以提高性能。
-
开源社区:OpenCV有一个庞大的开源社区,提供了大量的文档、教程和支持,使开发者能够快速入门和解决问题。
-
跨平台图形用户界面(GUI):OpenCV还包括一个简单的跨平台GUI库,用于创建图形用户界面,以便用户与视觉应用程序交互。
OpenCV已经被广泛应用于各种领域,包括机器视觉、自动驾驶、医学图像处理、安全监控、图像检索、虚拟现实等。无论是学术研究、工业应用还是个人项目,OpenCV都是一个强大的工具,用于解决各种视觉问题。无论你是初学者还是专业开发者,OpenCV都提供了强大的工具和资源,可以帮助你在计算机视觉领域取得成功
参考博客:图像处理 OpenCV简介_落花雨时的博客-CSDN博客
提问:用python使用opencv好还是用c++使用opencv好?
选择使用Python还是C++来使用OpenCV取决于你的项目需求、个人偏好和性能要求等因素。以下是一些考虑因素:
使用Python的优势:
易学易用:Python是一门容易学习和使用的语言,特别适合初学者。它的语法简洁,代码可读性高。
丰富的库和生态系统:Python有大量的库和框架,涵盖了各种领域,包括科学计算、机器学习、图像处理等。对于计算机视觉任务,有许多与OpenCV结合使用的库,如NumPy、Pillow、scikit-image等。
快速原型开发:Python具有快速原型开发的优势,你可以快速测试和迭代图像处理算法,而不需要编写大量的模板代码。
社区支持:Python有一个庞大的社区,你可以轻松地找到教程、文档和社区支持。
使用C++的优势:
性能:C++通常比Python更快,特别适合需要高性能的图像处理任务,如实时计算机视觉应用或大规模图像处理。
低级控制:C++提供了对底层硬件的更好控制,适合开发需要与硬件交互的应用程序。
OpenCV原生支持:OpenCV的主要版本是用C++编写的,因此在C++中使用OpenCV可以直接利用OpenCV的功能和性能。
多线程和并行处理:C++更容易实现多线程和并行处理,可以加速计算密集型图像处理任务。
综合考虑这些因素,如果你的项目对性能要求较高,或者需要与硬件交互,那么使用C++可能更合适。另一方面,如果你希望快速原型开发、代码可读性高,或者在机器学习和数据分析方面有需求,那么Python可能更适合。有时候,也可以将两者结合使用,例如使用C++编写性能关键的部分,然后使用Python进行高级封装和可视化。
最终的选择取决于你的具体项目需求和你自己的编程经验。
提问:c++和c区别在哪?
C++和C是两种编程语言,它们在很多方面相似,但也有一些重要的区别。以下是C++和C之间的一些主要区别:
面向对象编程 (OOP) 支持:
- C++是一种支持面向对象编程的语言,它允许使用类和对象来组织代码和数据,以及使用封装、继承和多态等概念。
- C语言不支持面向对象编程,它是一种过程式编程语言,代码通常由函数组成,没有类和对象的概念。
类和对象:
- 在C++中,你可以创建类来定义自定义数据类型,然后使用类创建对象。这允许你将数据和相关的操作封装在一起。
- 在C中,没有类和对象的概念,数据和函数通常是分开的。
函数重载:
- C++支持函数重载,这意味着你可以在同一个作用域内定义多个同名函数,但它们的参数列表不同。编译器根据参数列表的不同来选择正确的函数。
- C语言不支持函数重载。
运算符重载:
- C++允许运算符重载,这意味着你可以自定义类的运算符行为。
- C语言不支持运算符重载。
标准模板库 (STL):
- C++提供了STL,它包括各种数据结构和算法,如向量、链表、队列、堆栈、排序和搜索算法等,这些都可以在标准库中直接使用。
- C语言没有STL,通常需要手动实现这些数据结构和算法,或使用第三方库。
异常处理:
- C++支持异常处理,允许程序在发生错误时抛出和捕获异常。
- C语言通常使用错误码和条件语句来处理错误,而不是异常机制。
内存管理:
- C++提供了
new和delete运算符来进行动态内存分配和释放,但也需要程序员手动管理内存。- C语言同样提供了动态内存分配函数如
malloc和free,但没有C++中的类似new和delete的运算符。总之,C++在C的基础上引入了面向对象编程和许多其他高级特性,使得它更适合开发大型、复杂的应用程序,而C语言更接近底层硬件,通常用于编写系统级的、性能关键的代码。选择使用哪种语言通常取决于项目的需求和开发目标。
二、4h上手C++版OpenCV



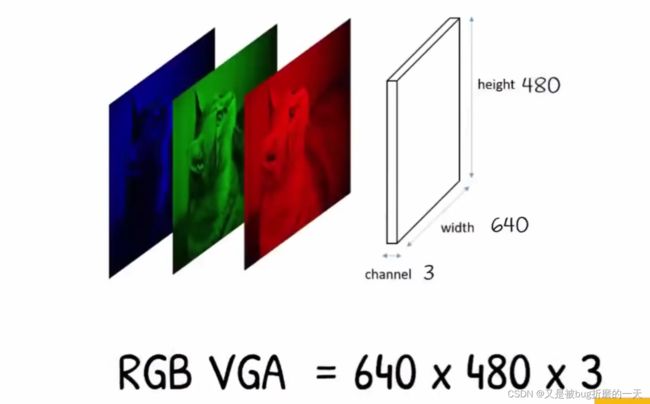
如果我们想要更细节的图像,可以增加这些格子(像素)的数量,

VGA HD FHD 4K代表固定数量的格子(像素)

二进制图像(两个层次)
 也意味着有254个灰度图
也意味着有254个灰度图
对于彩色图像,有三个灰度图像,分别代表了是红,绿,蓝的强度(RGB),将这些叠加起来就构成了彩色图像

单通道图像:
- 单通道图像也称为灰度图像。它们只包含一个灰度通道,每个像素只有一个灰度值,表示亮度信息。
- 在单通道图像中,颜色信息是缺失的,因此图像通常是黑白的,只包含灰度级别。
- 单通道图像常用于需要仅考虑亮度而不考虑颜色的应用,如图像分割、图像增强、边缘检测等。
多通道图像:
- 多通道图像包括多个颜色信息通道。最常见的是三通道图像,其中包含红色、绿色和蓝色三个通道。
- 三通道图像也称为彩色图像,因为它们可以显示多种颜色。
- 除了RGB图像,还有其他多通道图像格式,如RGBA(包含透明通道)、CMYK(用于印刷)、HSL(色相、饱和度、亮度)等。
- 多通道图像广泛用于图像和视频处理中,可以表示和处理各种颜色信息。
总的来说,单通道图像包含灰度信息,而多通道图像包含多个颜色信息通道,可以呈现多种颜色。在图像处理中,您根据具体的任务和需求选择使用单通道或多通道图像,并选择合适的颜色空间进行处理。例如,RGB颜色空间用于普通彩色图像,而灰度图像常用于某些特定任务。
Chapter1:读取图片、视频、和摄像头(Read Images Videos and Webcams)
#include
#include
#include
#include
using namespace cv;
using namespace std;
//导入图像 Importing Images//
//
//int main() {
// string path = "Resources/test.png";
// Mat img = imread(path);
// imshow("Image", img);
// waitKey(0); //0表示图片会一直显示不关闭
// return 0;
//}
///导入视频
//void main() {
//
// string path = "Resources/test_video.mp4";
// VideoCapture cap(path);
// Mat img;
//
// while (true) {
//
// cap.read(img);
// imshow("Image",img);
// waitKey(1);//1毫秒的意思,如果想要让视频播放速度变慢,这里可以将1毫秒换成20毫秒
//
// }
//}
/网络摄像头 webcam/
void main() {
VideoCapture cap(0);
Mat img;
while (true) {
cap.read(img);
imshow("Image",img);
waitKey(1);//1毫秒的意思,如果想要让视频播放速度变慢,这里可以将1毫秒换成20毫秒
}
} Chapter2:基本函数功能(Basic Function)
#include
#include
#include
#include
using namespace cv;
using namespace std;
//Basic Function//
int main() {
string path = "Resources/test.png";
Mat img = imread(path);
Mat imgGray, imgBlur, imgCanny, imgDil, imgErode;
cvtColor(img, imgGray, COLOR_BGR2GRAY);//将原始图像转变成灰度图像
//接下来添加高斯模糊
GaussianBlur(imgGray, imgBlur, Size(7, 7),5,0);//将7,7换成3,3后可以明显看出图像模糊的不那么明显
//Canny 边缘检测算法
Canny(imgBlur, imgCanny, 25, 75);//50,150可以看出边缘不是很清楚,将参数调成25,75,边缘更清楚了
//膨胀图像边缘
Mat kernel = getStructuringElement(MORPH_RECT, Size(5, 5));//增大参数,膨胀的会多,减小参数,膨胀的会晓
dilate(imgCanny, imgDil, kernel);
//侵蚀
erode(imgDil, imgErode, kernel);
imshow("Image", img);
imshow("Image Gray", imgGray);
imshow("Image Blur", imgBlur);//显示模糊后的图像
imshow("Image Canny", imgCanny);
imshow("Image Dilation", imgDil);//显示膨胀后的边缘图像
imshow("Image Erode", imgErode);
waitKey(0); //0表示图片会一直显示不关闭
return 0;
} Chapter3:调整大小和裁剪(Resize and Crop)
#include
#include
#include
#include
using namespace cv;
using namespace std;
//Resize and Crop //
void main() {
string path = "Resources/test.png";
Mat img = imread(path);
Mat imgResize,imgCrop;
//cout << img.size() << endl; //输出图像的大小为768(宽)×559(高)
//resize(img, imgResize, Size(640, 480));//将大小调整至640×480
resize(img, imgResize, Size(),0.5,0.5);//将图像宽度和高度分别按照0.5,0.5的比例缩小
Rect roi(200, 100, 300, 300);
imgCrop = img(roi);
imshow("Image", img);
imshow("Image Resize", imgResize);
imshow("Image imgCrop", imgCrop);
waitKey(0); //0表示图片会一直显示不关闭
} Chapter4:绘制形状和文本(Drawing Shapes and Text)
#include
#include
#include
#include
using namespace cv;
using namespace std;
//Draw Shapes and Text //
void main() {
//Blank Image
Mat img(512, 512, CV_8UC3, Scalar(255, 255, 255));//三个参数分别代表bgr中的blue,green,red
//定义空白图像的颜色时通常采用Scalar标量来定义,255,0,0代表blue,255,0,255代表紫色,255,255,255代表白色,0,0,0代表褐色
//circle(img, Point(256, 256), 155,Scalar(0, 69, 255),10);//10这个参数是厚度,可以写也可以不写
circle(img, Point(256, 256), 155, Scalar(0, 69, 255),FILLED);
//rectangle(img, Point(130, 226),Point(382, 286), Scalar(255, 255, 255), 3);
//两个point分别指代的是矩形的左上角和右下角顶点的位置,3是边缘的厚度
rectangle(img, Point(130, 226), Point(382, 286), Scalar(255, 255, 255), FILLED);
//显示出的是一个白色填充的矩形
line(img, Point(130, 296), Point(382, 296), Scalar(255, 255, 255), 2);//如果将296换成450,将会是一条斜线
//写入文字
putText(img, "I am Superman!!!", Point(150, 262), FONT_HERSHEY_DUPLEX,0.75, Scalar(0, 69, 255), 1.5);
imshow("Image", img);
waitKey(0); //0表示图片会一直显示不关闭
} Chapter5:扭曲透视(Warp Perspective)
#include
#include
#include
#include
using namespace cv;
using namespace std;
//Warp Images(对图像进行几何变换)//
float w = 250, h = 350;
Mat matrix, imgWarp;
void main() {
string path = "Resources/cards.jpg";
Mat img = imread(path);
Point2f src[4] = { {529,142},{771,190},{405,395},{674,457} };
Point2f dst[4] = { {0.0f,0.0f},{w,0.0f},{0.0f,h},{w,h} };
matrix = getPerspectiveTransform(src, dst);//
warpPerspective(img, imgWarp, matrix,Point(w,h));//执行透视变换(Perspective Transformation)操作
for (int i = 0; i < 4; i++) {
circle(img,src[i], 10, Scalar(0, 0, 255), FILLED);
}
imshow("Image", img);
imshow("Image Warp", imgWarp);
waitKey(0); //0表示图片会一直显示不关闭
} Chapter6:颜色检测(Color Detection)
#include
#include
#include
#include
using namespace cv;
using namespace std;
// Color Detection //
Mat imgHSV,mask;
int hmin = 0, smin = 0, vmin = 0;
int hmax = 179, smax = 255, vmax = 255;
void main() {
string path = "Resources/shapes.png";
Mat img = imread(path);
cvtColor(img, imgHSV, COLOR_BGR2HSV);//BGR 彩色图像转换为 HSV 色彩空间,色调 (H)、色度 (S) 和亮度 (V)
namedWindow("Trackbars", (640, 200));
//创建一个名为"TrackBars"的窗口(跟踪栏)。这个窗口通常用于创建可调节参数(trackbars)的用户界面,
//指定窗口的大小为(640, 200)像素,以便用户可以通过拖动滑块来调整参数的值。
createTrackbar("Hue Min","Trackbars",&hmin,179);
//在名为"Trackbars"的窗口中创建一个名为"Hue Min"的滑块控件,并将其与一个名为"hmin"的变量关联起来。
//滑块允许的最大值是179,通常情况下,这是因为"Hue"通道的取值范围是0到179(通常表示色相角度)。
createTrackbar("Hue Max", "Trackbars", &hmax, 179);
createTrackbar("Sat Min", "Trackbars", &smin, 255);
createTrackbar("Sat Max", "Trackbars", &smax, 255);
createTrackbar("Val Min", "Trackbars", &vmin, 255);
createTrackbar("Val Max", "Trackbars", &vmax, 255);
while (true) {
Scalar lower(hmin,smin,vmin);
Scalar upper(hmax, smax, vmax);
inRange(imgHSV,lower,upper,mask);
imshow("Image", img);
imshow("Image HSV", imgHSV);
imshow("Image MASK", mask);
waitKey(1);
}
} Chapter7:形状/轮廓检测(Shapes/Contour Detection)
#include
#include
#include
#include
using namespace cv;
using namespace std;
//Images//
Mat imgGray, imgBlur, imgCanny, imgDil, imgErode;
void getContours(Mat imgDil,Mat img) {
vector> contours;
vector hierarchy;
findContours(imgDil, contours, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
//drawContours(img, contours, -1, Scalar(255, 0, 255), 10);
vector> conPoly(contours.size());
vectorboundRect(contours.size());
for (int i = 0; i < contours.size(); i++) {
int area = contourArea(contours[i]);
cout << area << endl;
string objectType;
if (area > 1000) {
float peri = arcLength(contours[i],true);
/*arcLength:这是一个用于计算轮廓周长的函数。它的参数是一个轮廓,以及一个布尔值,用于指示轮廓是否闭合。
如果将第二个参数设置为 true,则表示轮廓是闭合的(即起点和终点相连),
如果设置为 false,则表示轮廓是开放的。*/
approxPolyDP(contours[i], conPoly[i], 0.02 * peri, true);
/*approxPolyDP 函数,它的作用是对给定的轮廓(contour)进行多边形近似(Approximation)。
contours[i]:这表示你要近似的轮廓,即第 i 个轮廓。
conPoly[i]:这是一个用于存储多边形近似结果的变量,通常是一个包含多边形顶点坐标的数据结构,例如数组或列表。
approxPolyDP 函数会将近似的多边形的顶点坐标存储在 conPoly[i] 中。
0.02 * peri:这是近似精度的参数。它控制了多边形近似与原始轮廓之间的相似度。在这里,它被设置为轮廓周长的2%(0.02乘以 peri),这意味着多边形近似会尽量保持原始轮廓的形状,但允许一定的近似误差。
true:这是一个布尔值参数,指示多边形近似是否要考虑轮廓是否闭合。如果设置为 true,则表示轮廓是闭合的,多边形近似也会尝试保持闭合性质。
*/
cout << conPoly[i].size() << endl;//输出多边形顶点坐标有几个
boundRect[i] = boundingRect(conPoly[i]);
/*boundingRect(conPoly[i]):这行代码用于计算多边形 conPoly[i] 的最小边界矩形(bounding rectangle)。
这个最小边界矩形是一个矩形,它完全包围了多边形,使得矩形的边与多边形的边平行。
这个矩形由一个左上角点的坐标(x,y)和矩形的宽度和高度组成。
这个函数会返回这个最小边界矩形,并将其存储到 boundRect[i] 中。之后你可以使用 boundRect[i] 来访问这个矩形的信息,
比如左上角坐标、宽度和高度
*/
int objCor = (int)conPoly[i].size();
if (objCor == 3){objectType = "Tri"; }
if (objCor == 4) {
float asRatio = (float)boundRect[i].width / (float)boundRect[i].height;
cout << asRatio << endl;
if (asRatio > 0.9 && asRatio < 1.1) { objectType = "Square"; }
else { objectType = "Rect"; }
}
if (objCor > 4) { objectType = "Circle"; }
drawContours(img, conPoly, i, Scalar(255, 0, 255), 2);
//rectangle(img, boundRect[i].tl(), boundRect[i].br(), Scalar(0, 255, 0), 5);
//putText(img, objectType, { boundRect[i].x,boundRect[i].y - 5 }, FONT_HERSHEY_PLAIN, 1, Scalar(0, 69, 255), 2);
}
}
}
void main() {
string path = "Resources/shapes.png";
Mat img = imread(path);
//Preprocessing
cvtColor(img, imgGray, COLOR_BGR2GRAY);
GaussianBlur(imgGray,imgBlur,Size(3,3),3,0);
Canny(imgBlur, imgCanny, 25, 75);
Mat kernel = getStructuringElement(MORPH_RECT,Size(3,3));
dilate(imgCanny, imgDil, kernel);
getContours(imgDil,img);
imshow("Image", img);
/*imshow("Image Gray", imgGray);
imshow("Image Blur", imgBlur);
imshow("Image Canny", imgCanny);
imshow("Image Dil", imgDil);*/
waitKey(0);
} Chapter8:人脸检测(Face Detection)
#include
#include
#include
#include
#include
/*"Load cascade"(加载级联)是一个在计算机视觉和图像处理中常见的术语。
它通常指的是加载一个级联分类器(Cascade Classifier)模型,用于目标检测或物体识别任务。
级联分类器是一种基于机器学习的方法,用于识别图像中的特定对象或目标。级联分类器通常由多个级别(级联)组成,
每个级别都是一个分类器,用于逐步筛选图像中的区域以识别目标。
每个级别的分类器都可以是基于Haar特征、HOG特征、深度神经网络等不同的技术。
"Load cascade" 意味着将事先训练好的级联分类器模型加载到计算机程序中,
以便在输入图像上执行目标检测。加载后,程序可以使用该级联分类器来检测图像中的特定物体或对象,并返回检测结果,
通常是物体的位置和/或标签。
在常见的应用中,级联分类器常用于人脸检测、行人检测、车辆检测等任务。
加载级联分类器模型是执行这些任务的重要步骤之一,因为它包含了训练好的模型参数,可以用来快速且准确地识别图像中的目标。
*/
using namespace cv;
using namespace std;
人脸检测//
int main() {
string path = "Resources/OIP.jpg";
Mat img = imread(path);
Mat imgGray, imgBlur, imgCanny, imgDil;
//编写级联分类器
CascadeClassifier faceCascade;
faceCascade.load("Resources/haarcascade_frontalface_default.xml");
/*XML是一个级联分类器模型文件,用于人脸检测任务。
这个文件包含了一个基于Haar特征的级联分类器,经过训练可以识别图像中的前视人脸。
OpenCV(一个广泛使用的计算机视觉库)和其他计算机视觉工具通常提供了这种类型的级联分类器模型文件,
以便开发人员可以在自己的应用程序中使用它们来实现人脸检测功能。通过加载这个模型文件,
开发人员可以快速在图像或视频流中检测人脸,并获取人脸的位置信息,从而进行进一步的处理或识别任务。
*/
if (faceCascade.empty()) { cout << "XML file not loaded " << endl;}
vector faces;
//使用人脸级联点检测多尺度方法
faceCascade.detectMultiScale(img, faces, 1.1, 10);
for (int i = 0; i < faces.size(); i++)
{
rectangle(img,faces[i].tl(),faces[i].br(), Scalar(255,0, 255),2);
}
cvtColor(img, imgGray, COLOR_BGR2GRAY);//将原始图像转变成灰度图像
//接下来添加高斯模糊
GaussianBlur(imgGray, imgBlur, Size(7, 7), 5, 0);//将7,7换成3,3后可以明显看出图像模糊的不那么明显
//Canny 边缘检测算法
Canny(imgBlur, imgCanny, 25, 75);//50,150可以看出边缘不是很清楚,将参数调成25,75,边缘更清楚了
//膨胀图像边缘
Mat kernel = getStructuringElement(MORPH_RECT, Size(5, 5));//增大参数,膨胀的会多,减小参数,膨胀的会晓
dilate(imgCanny, imgDil, kernel);
imshow("Image", img);
//imshow("Image Gray", imgGray);
//imshow("Image Blur", imgBlur);//显示模糊后的图像
//imshow("Image Canny", imgCanny);
//imshow("Image Dilation", imgDil);//显示膨胀后的边缘图像
waitKey(0); //0表示图片会一直显示不关闭
return 0;
}
后续以后用到了再补上
Project1:(Virtual Painter)
Project2:(Document Scanner)
Project3:(License Plate Detector)