十七、文件(2)
本章概要
- 文件系统
- 路径监听
- 文件查找
- 文件读写
文件系统
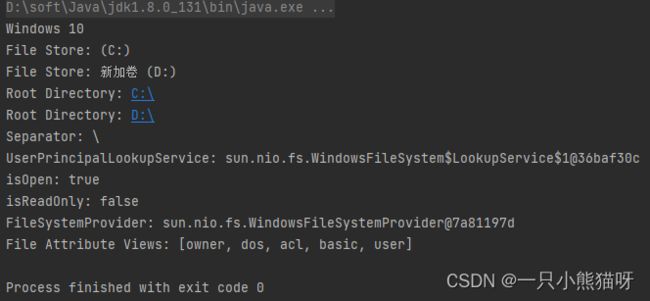
为了完整起见,我们需要一种方法查找文件系统相关的其他信息。在这里,我们使用静态的 FileSystems 工具类获取"默认"的文件系统,但你同样也可以在 Path 对象上调用 getFileSystem() 以获取创建该 Path 的文件系统。你可以获得给定 URI 的文件系统,还可以构建新的文件系统(对于支持它的操作系统)。
import java.nio.file.*;
public class FileSystemDemo {
static void show(String id, Object o) {
System.out.println(id + ": " + o);
}
public static void main(String[] args) {
System.out.println(System.getProperty("os.name"));
FileSystem fsys = FileSystems.getDefault();
for (FileStore fs : fsys.getFileStores()) {
show("File Store", fs);
}
for (Path rd : fsys.getRootDirectories()) {
show("Root Directory", rd);
}
show("Separator", fsys.getSeparator());
show("UserPrincipalLookupService",
fsys.getUserPrincipalLookupService());
show("isOpen", fsys.isOpen());
show("isReadOnly", fsys.isReadOnly());
show("FileSystemProvider", fsys.provider());
show("File Attribute Views",
fsys.supportedFileAttributeViews());
}
}
一个 FileSystem 对象也能生成 WatchService 和 PathMatcher 对象,将会在接下来两章中详细讲解。
路径监听
通过 WatchService 可以设置一个进程对目录中的更改做出响应。在这个例子中,delTxtFiles() 作为一个单独的任务执行,该任务将遍历整个目录并删除以 .txt 结尾的所有文件,WatchService 会对文件删除操作做出反应:
PathWatcher.java
import java.io.IOException;
import java.nio.file.*;
import static java.nio.file.StandardWatchEventKinds.*;
import java.util.concurrent.*;
public class PathWatcher {
static Path test = Paths.get("test");
static void delTxtFiles() {
try {
Files.walk(test)
.filter(f ->
f.toString()
.endsWith(".txt"))
.forEach(f -> {
try {
System.out.println("deleting " + f);
Files.delete(f);
} catch (IOException e) {
throw new RuntimeException(e);
}
});
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws Exception {
Directories.refreshTestDir();
Directories.populateTestDir();
Files.createFile(test.resolve("Hello.txt"));
WatchService watcher = FileSystems.getDefault().newWatchService();
test.register(watcher, ENTRY_DELETE);
Executors.newSingleThreadScheduledExecutor()
.schedule(PathWatcher::delTxtFiles,
250, TimeUnit.MILLISECONDS);
WatchKey key = watcher.take();
for (WatchEvent evt : key.pollEvents()) {
System.out.println("evt.context(): " + evt.context() +
"\nevt.count(): " + evt.count() +
"\nevt.kind(): " + evt.kind());
System.exit(0);
}
}
}
RmDir.java
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
import java.io.IOException;
public class RmDir {
public static void rmdir(Path dir) throws IOException {
Files.walkFileTree(dir, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
Files.delete(file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
Files.delete(dir);
return FileVisitResult.CONTINUE;
}
});
}
}
Directories.java
import java.util.*;
import java.nio.file.*;
public class Directories {
static Path test = Paths.get("test");
static String sep = FileSystems.getDefault().getSeparator();
static List<String> parts = Arrays.asList("foo", "bar", "baz", "bag");
static Path makeVariant() {
Collections.rotate(parts, 1);
return Paths.get("test", String.join(sep, parts));
}
static void refreshTestDir() throws Exception {
if (Files.exists(test)) {
RmDir.rmdir(test);
}
if (!Files.exists(test)) {
Files.createDirectory(test);
}
}
public static void main(String[] args) throws Exception {
refreshTestDir();
Files.createFile(test.resolve("Hello.txt"));
Path variant = makeVariant();
// Throws exception (too many levels):
try {
Files.createDirectory(variant);
} catch (Exception e) {
System.out.println("Nope, that doesn't work.");
}
populateTestDir();
Path tempdir = Files.createTempDirectory(test, "DIR_");
Files.createTempFile(tempdir, "pre", ".non");
Files.newDirectoryStream(test).forEach(System.out::println);
System.out.println("*********");
Files.walk(test).forEach(System.out::println);
}
static void populateTestDir() throws Exception {
for (int i = 0; i < parts.size(); i++) {
Path variant = makeVariant();
if (!Files.exists(variant)) {
Files.createDirectories(variant);
Files.copy(Paths.get("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\Directories.java"),
variant.resolve("File.txt"));
Files.createTempFile(variant, null, null);
}
}
}
}
delTxtFiles() 中的 try 代码块看起来有些多余,因为它们捕获的是同一种类型的异常,外部的 try 语句似乎已经足够了。然而出于某种原因,Java 要求两者都必须存在(这也可能是一个 bug)。还要注意的是在 filter() 中,我们必须显式地使用 f.toString() 转为字符串,否则我们调用 endsWith() 将会与整个 Path 对象进行比较,而不是路径名称字符串的一部分进行比较。
一旦我们从 FileSystem 中得到了 WatchService 对象,我们将其注册到 test 路径以及我们感兴趣的项目的变量参数列表中,可以选择 ENTRY_CREATE,ENTRY_DELETE 或 ENTRY_MODIFY(其中创建和删除不属于修改)。
因为接下来对 watcher.take() 的调用会在发生某些事情之前停止所有操作,所以我们希望 deltxtfiles() 能够并行运行以便生成我们感兴趣的事件。为了实现这个目的,我通过调用 Executors.newSingleThreadScheduledExecutor() 产生一个 ScheduledExecutorService 对象,然后调用 schedule() 方法传递所需函数的方法引用,并且设置在运行之前应该等待的时间。
此时,watcher.take() 将等待并阻塞在这里。当目标事件发生时,会返回一个包含 WatchEvent 的 Watchkey 对象。展示的这三种方法是能对 WatchEvent 执行的全部操作。
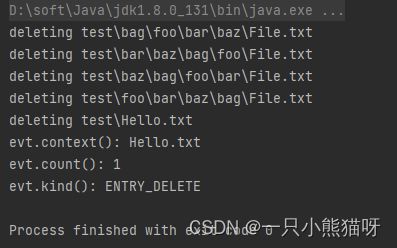
查看输出的具体内容。即使我们正在删除以 .txt 结尾的文件,在 Hello.txt 被删除之前,WatchService 也不会被触发。你可能认为,如果说"监视这个目录",自然会包含整个目录和下面子目录,但实际上:只会监视给定的目录,而不是下面的所有内容。如果需要监视整个树目录,必须在整个树的每个子目录上放置一个 Watchservice。
import java.io.IOException;
import java.nio.file.*;
import static java.nio.file.StandardWatchEventKinds.*;
import java.util.concurrent.*;
public class TreeWatcher {
static void watchDir(Path dir) {
try {
WatchService watcher =
FileSystems.getDefault().newWatchService();
dir.register(watcher, ENTRY_DELETE);
Executors.newSingleThreadExecutor().submit(() -> {
try {
WatchKey key = watcher.take();
for (WatchEvent evt : key.pollEvents()) {
System.out.println(
"evt.context(): " + evt.context() +
"\nevt.count(): " + evt.count() +
"\nevt.kind(): " + evt.kind());
System.exit(0);
}
} catch (InterruptedException e) {
return;
}
});
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws Exception {
Directories.refreshTestDir();
Directories.populateTestDir();
Files.walk(Paths.get("test"))
.filter(Files::isDirectory)
.forEach(TreeWatcher::watchDir);
PathWatcher.delTxtFiles();
}
}

在 watchDir() 方法中给 WatchSevice 提供参数 ENTRY_DELETE,并启动一个独立的线程来监视该Watchservice。这里我们没有使用 schedule() 进行启动,而是使用 submit() 启动线程。我们遍历整个目录树,并将 watchDir() 应用于每个子目录。现在,当我们运行 deltxtfiles() 时,其中一个 Watchservice 会检测到每一次文件删除。
文件查找
到目前为止,为了找到文件,我们一直使用相当粗糙的方法,在 path 上调用 toString(),然后使用 string 操作查看结果。事实证明,java.nio.file 有更好的解决方案:通过在 FileSystem 对象上调用 getPathMatcher() 获得一个 PathMatcher,然后传入您感兴趣的模式。模式有两个选项:glob 和 regex。glob 比较简单,实际上功能非常强大,因此您可以使用 glob 解决许多问题。如果您的问题更复杂,可以使用 regex,这将在接下来的 Strings 一章中解释。
在这里,我们使用 glob 查找以 .tmp 或 .txt 结尾的所有 Path:
import java.nio.file.*;
public class Find {
public static void main(String[] args) throws Exception {
Path test = Paths.get("test");
Directories.refreshTestDir();
Directories.populateTestDir();
// Creating a *directory*, not a file:
Files.createDirectory(test.resolve("dir.tmp"));
PathMatcher matcher = FileSystems.getDefault()
.getPathMatcher("glob:**/*.{tmp,txt}");
Files.walk(test)
.filter(matcher::matches)
.forEach(System.out::println);
System.out.println("***************");
PathMatcher matcher2 = FileSystems.getDefault()
.getPathMatcher("glob:*.tmp");
Files.walk(test)
.map(Path::getFileName)
.filter(matcher2::matches)
.forEach(System.out::println);
System.out.println("***************");
Files.walk(test) // Only look for files
.filter(Files::isRegularFile)
.map(Path::getFileName)
.filter(matcher2::matches)
.forEach(System.out::println);
}
}
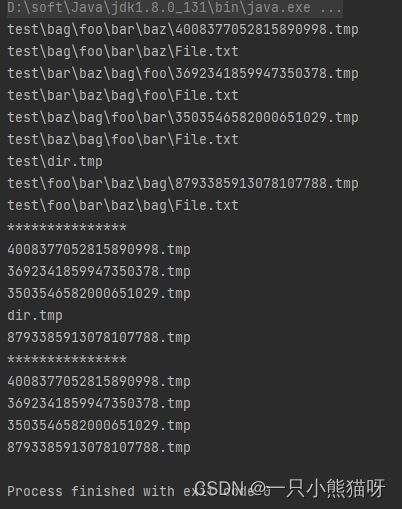
在 matcher 中,glob 表达式开头的 **/ 表示“当前目录及所有子目录”,这在当你不仅仅要匹配当前目录下特定结尾的 Path 时非常有用。单 * 表示“任何东西”,然后是一个点,然后大括号表示一系列的可能性—我们正在寻找以 .tmp 或 .txt 结尾的东西。您可以在 getPathMatcher() 文档中找到更多详细信息。
matcher2 只使用 *.tmp,通常不匹配任何内容,但是添加 map() 操作会将完整路径减少到末尾的名称。
注意,在这两种情况下,输出中都会出现 dir.tmp,即使它是一个目录而不是一个文件。要只查找文件,必须像在最后 files.walk() 中那样对其进行筛选。
文件读写
此时,我们可以对路径和目录做任何事情。 现在让我们看一下操纵文件本身的内容。
如果一个文件很“小”,也就是说“它运行得足够快且占用内存小”,那么 java.nio.file.Files 类中的实用程序将帮助你轻松读写文本和二进制文件。
Files.readAllLines() 一次读取整个文件(因此,“小”文件很有必要),产生一个List。 对于示例文件,我们将重用streams/Cheese.dat:
ListOfLines.java
import java.nio.file.*;
public class ListOfLines {
public static void main(String[] args) throws Exception {
Files.readAllLines(Paths.get("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\Cheese.dat"))
.stream()
.filter(line -> !line.startsWith("//"))
.map(line ->
line.substring(0, line.length() / 2))
.forEach(System.out::println);
}
}
Cheese.dat
// streams/Cheese.dat
Not much of a cheese shop really, is it?
Finest in the district, sir.
And what leads you to that conclusion?
Well, it's so clean.
It's certainly uncontaminated by cheese.

跳过注释行,其余的内容每行只打印一半。 这实现起来很简单:你只需将 Path 传递给 readAllLines() (以前的 java 实现这个功能很复杂)。readAllLines() 有一个重载版本,包含一个 Charset 参数来存储文件的 Unicode 编码。
Files.write() 被重载以写入 byte 数组或任何 Iterable 对象(它也有 Charset 选项):
import java.util.*;
import java.nio.file.*;
public class Writing {
static Random rand = new Random(47);
static final int SIZE = 1000;
public static void main(String[] args) throws Exception {
// Write bytes to a file:
byte[] bytes = new byte[SIZE];
rand.nextBytes(bytes);
Files.write(Paths.get("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\bytes.dat"), bytes);
System.out.println("bytes.dat: " + Files.size(Paths.get("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\bytes.dat")));
// Write an iterable to a file:
List<String> lines = Files.readAllLines(
Paths.get("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\Cheese.dat"));
Files.write(Paths.get("Cheese.txt"), lines);
System.out.println("Cheese.txt: " + Files.size(Paths.get("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\Cheese.txt")));
}
}
Cheese.txt
// streams/Cheese.dat
Not much of a cheese shop really, is it?
Finest in the district, sir.
And what leads you to that conclusion?
Well, it's so clean.
It's certainly uncontaminated by cheese.

我们使用 Random 来创建一个随机的 byte 数组; 你可以看到生成的文件大小是 1000。
一个 List 被写入文件,任何 Iterable 对象也可以这么做。
如果文件大小有问题怎么办? 比如说:
- 文件太大,如果你一次性读完整个文件,你可能会耗尽内存。
- 您只需要在文件的中途工作以获得所需的结果,因此读取整个文件会浪费时间。
Files.lines() 方便地将文件转换为行的 Stream:
import java.nio.file.*;
public class ReadLineStream {
public static void main(String[] args) throws Exception {
Files.lines(Paths.get("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\ReadLineStream.java"))
.skip(5)
.findFirst()
.ifPresent(System.out::println);
}
}

这对本章中第一个示例代码做了流式处理,跳过 5 行,然后选择下一行并将其打印出来。
Files.lines() 对于把文件处理行的传入流时非常有用,但是如果你想在 Stream 中读取,处理或写入怎么办?这就需要稍微复杂的代码:
import java.io.*;
import java.nio.file.*;
import java.util.stream.*;
public class StreamInAndOut {
public static void main(String[] args) {
try (
Stream<String> input =
Files.lines(Paths.get("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\StreamInAndOut.java"));
PrintWriter output =
new PrintWriter("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\StreamInAndOut.txt")
) {
input.map(String::toUpperCase)
.forEachOrdered(output::println);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
输出文件内容:
PACKAGE COM.EXAMPLE.TEST;// FILES/STREAMINANDOUT.JAVA
IMPORT JAVA.IO.*;
IMPORT JAVA.NIO.FILE.*;
IMPORT JAVA.UTIL.STREAM.*;
PUBLIC CLASS STREAMINANDOUT {
PUBLIC STATIC VOID MAIN(STRING[] ARGS) {
TRY (
STREAM INPUT =
FILES.LINES(PATHS.GET("D:\\ONJAVA\\TEST\\SRC\\MAIN\\JAVA\\COM\\EXAMPLE\\TEST\\STREAMINANDOUT.JAVA"));
PRINTWRITER OUTPUT =
NEW PRINTWRITER("D:\\ONJAVA\\TEST\\SRC\\MAIN\\JAVA\\COM\\EXAMPLE\\TEST\\STREAMINANDOUT.TXT")
) {
INPUT.MAP(STRING::TOUPPERCASE)
.FOREACHORDERED(OUTPUT::PRINTLN);
} CATCH (EXCEPTION E) {
THROW NEW RUNTIMEEXCEPTION(E);
}
}
}
因为我们在同一个块中执行所有操作,所以这两个文件都可以在相同的 try-with-resources 语句中打开。PrintWriter 是一个旧式的 java.io 类,允许你“打印”到一个文件,所以它是这个应用的理想选择。如果你看一下 StreamInAndOut.txt,你会发现它里面的内容确实是大写的。