容器技术---(三)kubernetes存储
Configmap配置管理
Configmap用于保存配置数据,以键值对形式存储;ConfigMap资源提供了向Pod注入配置数据的方法,旨在让镜像和配置文件解耦,以便实现镜像的可移植性和可复用性;典型的使用场景有:填充环境变量的值、设置容器内的命令行参数、填充卷的配置文件
创建ConfigMap的方式有4种:使用字面值创建、使用文件创建、使用目录创建、编写configmap的yaml文件创建
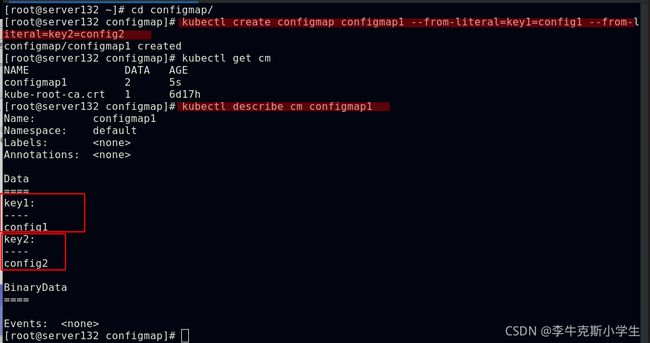
##使用字面值创建,键值对的方式

##使用文件创建,文件名为key,文件内容为值

##使用目录创建,文件名为key,文件内容为值

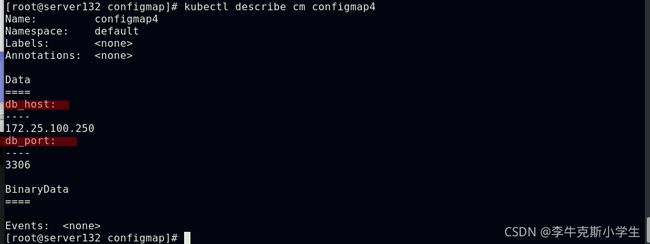
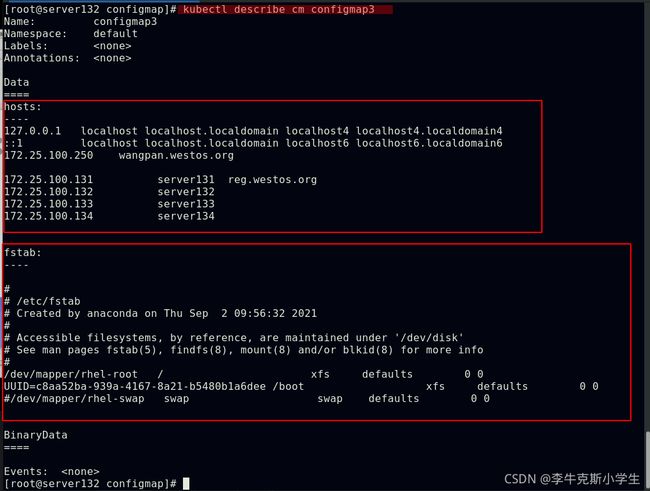
##使用yml文件创建
如何使用ConfigMap:通过环境变量的方式直接传递给pod、通过在pod的命令行下运行的方式、作为volume的方式挂载到pod内


##使用configmap设置环境变量


##直接传递configmap中的变量,不在yml文件中指定键值

##使用conigmap设置命令行参数

![]()
##kubectl describe pod pod4
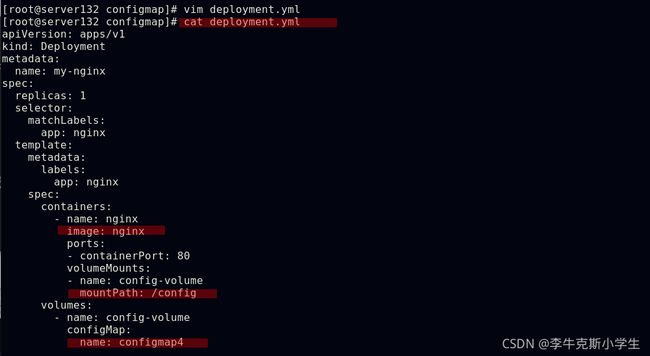

##通过数据卷使用configmap
configmap的热更新



##创建nginxconf的configmap并将其挂载到nginx的默认include目录下

##此时只能通过nginxconf这个configmap中定义的端口访问
![]()
##编辑nginxconf这个configmap将其端口修改为8080

##此时虽然容器内的文件内容会更新(有一定延迟),但是更新的设定并没有生效;需要手动触发Pod滚动更新, 这样才能再次加载nginx.conf配置文件

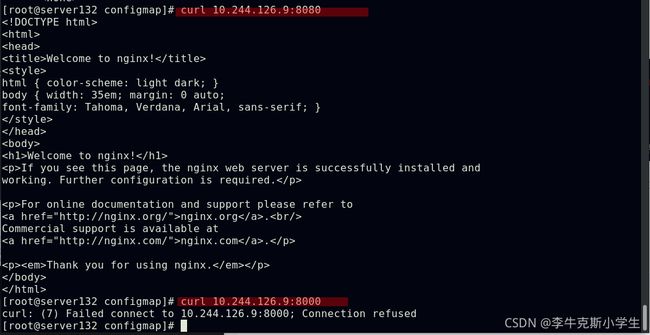
##configmap热更新后,并不会触发相关Pod的滚动更新,需要手动触发;通过修改“version/config”来手动触发Pod滚动更新,更新后的pod也会获取到新的IP;此种方式下使用configmap挂载的env环境变量是不会更新的

##也可以在更改了configmap配置内容后通过删除控制下的pod以达到pod的热更新(此种更新方式延迟最低)
Secret配置管理
Secret对象类型用来保存敏感信息,例如密码、OAuth令牌和ssh key;敏感信息放在secret中比放在Pod的定义或者容器镜像中来说更加安全和灵活
Pod可以用两种方式使用secret:作为volume中的文件被挂载到pod中的一个或者多个容器里;当 kubelet为pod拉取镜像时使用
Secret的类型:
Service Account:Kubernetes自动创建包含访问API凭据的secret,并自动修改pod以使用此类型的secret
Opaque:使用base64编码存储信息,可以通过base64 --decode解码获得原始数据,因此安全性弱,Opaque类型的Secret其value为base64编码后的值
kubernetes.io/dockerconfigjson:用于存储docker registry的认证信息

![]()

##serviceaccout创建时Kubernetes会默认创建对应的secret,对应的secret会自动挂载到Pod的 /var/run/secrets/kubernetes.io/serviceaccount目录中

##每个namespace下有一个名为default的默认的ServiceAccount对象


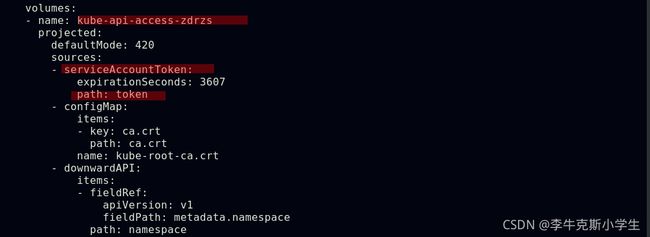
##ServiceAccount里有一个名为Tokens的可以作为Volume一样被Mount到Pod里的Secret,当Pod启动时这个Secret会被自动Mount到Pod的指定目录下,用来协助完成Pod中的进程访问API Server时的身份鉴权过程

##从文件中创建secret
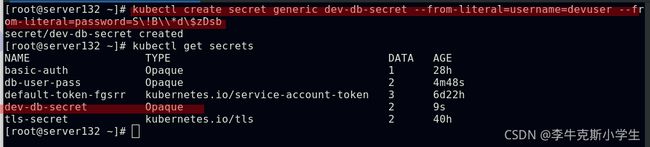
##从字面值创建secret,密码具有特殊字符时需要使用 \ 字符对其进行转义

##从yaml文件创建secret

##默认情况下kubectl describe secret为了安全不会显示密码的内容

##可以通过以上方式查看


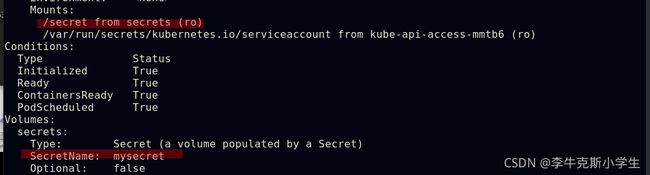
##将secrect通过volume挂载到pod中


##向指定路径映射secret的键值


##将Secret设置为环境变量
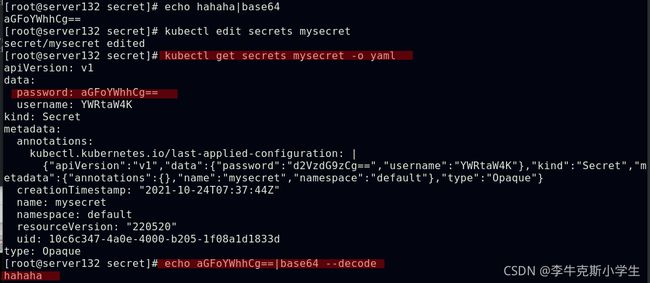

##环境变量读取Secret很方便,但无法支撑Secret动态更新
![]()

##kubernetes.io/dockerconfigjson用于存储docker registry的认证信息



##在集群节点都成功登陆镜像仓库并拥有认证时,在yml文件中的pod未指定镜像拉取secret,此pod依然显示镜像拉取失败





##在集群节点都登出镜像仓库并移除认证时,在yml文件中的pod指定镜像拉取secret,此pod则能成功运行
Volumes配置管理
容器中的文件在磁盘上是临时存放的,这给容器中运行的特殊应用程序带来一些问题,首先,当容器崩溃时,kubelet将重新启动容器,容器中的文件将会丢失,因为容器会以干净的状态重建;其次,当在一个Pod中同时运行多个容器时,常常需要在这些容器之间共享文件;Kubernetes抽象出 Volume对象来解决这两个问题
Kubernetes卷具有明确的生命周期,与包裹它的Pod相同;因此,卷比Pod中运行的任何容器的存活期都长,在容器重新启动时数据也会得到保留;当一个Pod不再存在时,卷也将不再存在;也许更重要的是,Kubernetes可以支持许多类型的卷,Pod也能同时使用任意数量的卷
卷不能挂载到其他卷,也不能与其他卷有硬链接;Pod中的每个容器必须独立地指定每个卷的挂载位置
Kubernetes 支持下列类型的卷:
awsElasticBlockStore 、azureDisk、azureFile、cephfs、cinder、configMap、csi、downwardAPI、emptyDir、fc (fibre channel)、flexVolume、flocker gcePersistentDisk、gitRepo(deprecated)、glusterfs、hostPath、iscsi、local、 nfs、persistentVolumeClaim、projected、portworxVolume、quobyte、rbd scaleIO、secret、storageos、vsphereVolume
更多卷的信息详见官网
卷 | Kubernetesvolume abstraction solves both of these problems. -- Container 中的文件在磁盘上是临时存放的,这给 Container 中运行的较重要的应用 程序带来一些问题。问题之一是当容器崩溃时文件丢失。kubelet 会重新启动容器, 但容器会以干净的状态重启。 第二个问题会在同一 Pod 中运行多个容器并共享文件时出现。 Kubernetes 卷(Volume) 这一抽象概念能够解决这两个问题。阅读本文前建议你熟悉一下 Pods。背景 Docker 也有 卷(Volume) 的概念,但对它只有少量且松散的管理。 Docker 卷是磁盘上或者另外一个容器内的一个目录。 Docker 提供卷驱动程序,但是其功能非常有限。Pod can use any number of volume types simultaneously. Ephemeral volume types have a lifetime of a pod, but persistent volumes exist beyond the lifetime of a pod. When a pod ceases to exist, Kubernetes destroys ephemeral volumes; however, Kubernetes does not destroy persistent volumes. https://kubernetes.io/zh/docs/concepts/storage/volumes/emptyDir卷
https://kubernetes.io/zh/docs/concepts/storage/volumes/emptyDir卷
当Pod指定到某个节点上时,首先创建的是一个emptyDir卷,并且只要Pod在该节点上运行,卷就一直存在;就像其名称表示的那样,卷最初是空的;尽管Pod中的容器挂载emptyDir卷的路径可能相同也可能不同,但是这些容器都可以读写emptyDir卷中相同的文件;当Pod因为某些原因被从节点上删除时,emptyDir卷中的数据也会永久删除
emptyDir的使用场景:缓存空间,例如基于磁盘的归并排序;为耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行;在Web服务器容器服务数据时,保存内容管理器容器获取的文件
默认情况下,emptyDir卷存储在支持该节点所使用的介质上,这里的介质可以是磁盘或SSD或网络存储,这取决于您的环境;但是,您可以将emptyDir.medium字段设置为"Memory",以告诉Kubernetes为您安装tmpfs(基于内存的文件系统);虽然tmpfs速度非常快,但是要注意它与磁盘不同,tmpfs在节点重启时会被清除,并且您所写入的所有文件都会计入容器的内存消耗,受容器内存限制约束

##以内存为介质创建空卷



##同一pod中的两个容器共享挂载卷
emptyDir卷缺点:不能及时禁止用户使用内存;虽然过1-2分钟kubelet会将Pod挤出,但是这个时间内,其实对node还是有风险的;影响kubernetes调度,因为empty dir并不涉及node的resources,这样会造成Pod“偷偷”使用了node的内存,但是调度器并不知晓;用户不能及时感知到内存不可用
hostPath卷
hostPath卷能将主机节点文件系统上的文件或目录挂载到Pod中,虽然这不是大多数Pod需要的,但是它为一些应用程序提供了强大的逃生舱
hostPath卷的一些用法:运行一个需要访问Docker引擎内部机制的容器,挂载/var/lib/docker路径;在容器中运行cAdvisor时,以hostPath方式挂载 /sys;允许Pod指定给定的hostPath在运行Pod之前是否应该存在,是否应该创建以及应该以什么方式存在
除了必需的path属性之外,用户可以选择性地为hostPath卷指定type

hostPath卷的缺点:具有相同配置(例如从podTemplate创建)的多个Pod会由于节点上文件的不同而在不同节点上有不同的行为;当Kubernetes按照计划添加资源感知的调度时,这类调度机制将无法考虑由hostPath使用的资源;基础主机上创建的文件或目录只能由root用户写入;您需要在特权容器中以root身份运行进程,或者修改主机上的文件权限以便容器能够写入hostPath卷

##创建DirectoryOrCreate类型的hostPath卷并挂载


##会在pod调度的节点上创建被挂载的目录
nfs卷

##配置nfs以共享文件

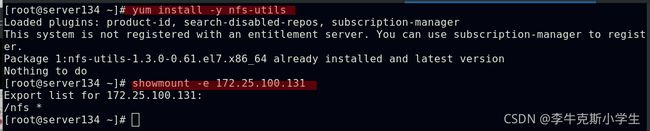
##集群中所有参与调度节点安装nfs组件

##创建nfs卷并挂载

##此时挂载点目录下无文件,因此无法访问到nginx容器的测试页面

##在挂载点创建测试文件时,访问pod得到挂载点下的测试文件内容
持久卷PV与持久卷声明PVC
PersistentVolume是集群内,由管理员提供的网络存储的一部分,就像集群中的节点一样,PV也是集群中的一种资源,它也像Volume一样,是一种volume插件,但是它的生命周期却是和使用它的Pod相互独立的;PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节
PersistentVolumeClaim是用户的一种存储请求,它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源;Pod能够请求特定的资源(如CPU和内存),PVC能够请求指定的大小和访问的模式(可以被映射为一次读写或者多次只读)
有两种PV提供的方式:静态和动态
静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,这些存储对于集群用户是可用的,它们存在于Kubernetes API中,并可用于存储使用
动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC,这种供给基于StorageClass
PVC与PV的绑定是一对一的映射,没找到匹配的PV,那么PVC会无限期处于unbound即未绑定状态
PV使用:
Pod使用PVC就像使用volume一样;集群检查PVC,查找绑定的PV,并映射PV给Pod,对于支持多种访问模式的PV,用户可以指定想用的模式;一旦用户拥有了一个PVC,并且PVC被绑定,那么只要用户还需要,PV就一直属于这个用户;用户调度Pod,通过在Pod的volume块中包含PVC来访问PV
PV释放:
当用户使用PV完毕后,他们可以通过API来删除PVC对象,当PVC被删除后,对应的PV就被认为是已经是“released”了,但还不能再给另外一个PVC使用,前一个PVC的属于还存在于该PV中,必须根据策略来处理掉
PV回收:
PV的回收策略告诉集群,在PV被释放之后集群应该如何处理该PV;当前,PV可以被Retained(保留)、Recycled(再利用)或者Deleted(删除);保留允许手动地再次声明资源,对于支持删除操作的PV卷,删除操作会从Kubernetes中移除PV对象,还有对应的外部存储(如AWS EBS、GCE PD、Azure Disk或者Cinder volume);动态供给的卷总是会被删除

##创建共享子目录


##创建不同容量和访问模式的两个pv
访问模式:ReadWriteOnce(RWO)==该volume只能被单个节点以读写的方式映射;ReadOnlyMany(ROX)==该volume可以被多个节点以只读方式映射;ReadWriteMany(RWX)==该volume可以被多个节点以读写的方式映射
回收策略:Retain==保留,需要手动回收;Recycle==回收,自动删除卷中数据;Delete==删除,相关联的存储资产,如AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷都会被删除
当前只有NFS卷和HostPath卷支持回收利用,AWS EBS、GCE PD、Azure Disk、OpenStack Cinder卷支持删除操作
状态:Available==空闲的资源,未绑定给PVC;Bound==绑定给了某个PVC;Released==PVC已经删除了,但是PV还没有被集群回收;Failed==PV在自动回收中失败了
命令行可以显示PV绑定的PVC名称

##创建pvc,pvc会根据文件中定义的存储类、容量需求和访问模式匹配到合适的pv进行绑定

##pod中挂载pv

##在挂载点创建nginx的测试文件

##访问pod得到挂载点下测试文件内容


##删除pvc,先前被绑定的pv的状态由bound->released->available;挂载卷中数据被删除(recycle的回收策略)

##pvc在未找到合适的pv进行绑定的情况下会一直处于pending状态
StorageClass提供了一种描述存储类(class)的方法,不同的class可能会映射到不同的服务质量等级和备份策略或其他策略等;每个StorageClass都包含provisioner、parameters和reclaimPolicy字段, 这些字段会在StorageClass需要动态分配PersistentVolume时会使用到
StorageClass的属性:
Provisioner(存储分配器):用来决定使用哪个卷插件分配PV,该字段必须指定,可以指定内部分配器,也可以指定外部分配器;外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等
Reclaim Policy(回收策略):通过reclaimPolicy字段指定创建的PersistentVolume的回收策略,回收策略包括:Delete或者Retain,没有指定默认为Delete
更多属性查看
存储类 | Kubernetes https://kubernetes.io/zh/docs/concepts/storage/storage-classes/NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,其本身不提供NFS存储,需要外部先有一套NFS存储服务
https://kubernetes.io/zh/docs/concepts/storage/storage-classes/NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,其本身不提供NFS存储,需要外部先有一套NFS存储服务
PV以 ${namespace}-${pvcName}-${pvName} 的命名格式提供(在NFS服务器上);PV回收的时候以 archieved-${namespace}-${pvcName}-${pvName} 的命名格式(在NFS服务器上);nfs-client-provisioner源码地址:https://github.com/kubernetes-incubator/external-storage/tree/master/nfs-client

##配置授权,编写yaml文件并应用,创建yaml文件中指定的namespace

##部署NFS Client Provisioner

##创建NFS存储类


##创建pvc,NFS服务端共享目录下会自动创建一个子目录以作映射挂载


##删除上述pvc时,共享目录下自动创建的pv卷也被删除(因为class.yml文件中设定archiveOnDelete=false)
默认的StorageClass将被用于动态的为没有特定storage class需求的PersistentVolumeClaims配置存储(只能有一个默认StorageClass);如果没有默认的StorageClass,PVC也没有指定storageClassName的值,那么意味着它只能够跟storageClassName也是空的PV进行绑定

##配置默认的StorageClass


##不指定存储类创建pvc,依然可以绑定到pv


##删除pvc后pv可以保存(因class.yml文件中设置了archiveOnDelete=true)
StatefulSet控制器
StatefulSet是用来管理有状态应用的工作负载API对象
StatefulSet用来管理Deployment和扩展一组Pod,并且能为这些Pod提供序号和唯一性保证
和Deployment相同的是,StatefulSet管理了基于相同容器定义的一组Pod,但和Deployment不同的是,StatefulSet为它们的每个Pod维护了一个固定的ID;这些Pod是基于相同的声明来创建的,但是不能相互替换:无论怎么调度,每个Pod都有一个永久不变的ID
StatefulSet和其他控制器使用相同的工作模式,在StatefulSet对象中定义你期望的状态,然后StatefulSet的控制器就会通过各种更新来达到那种你想要的状态
StatefulSets对于需要满足以下一个或多个需求的应用程序很有价值:
稳定的、唯一的网络标识符
稳定的、持久的存储
有序的、优雅的部署和缩放
有序的、自动的滚动更新
在上面,稳定意味着Pod调度或重调度的整个过程是有持久性的;如果应用程序不需要任何稳定的标识符或有序的部署、删除或伸缩,则应该使用由一组无状态的副本控制器提供的工作负载来部署应用程序,比如Deployment或者ReplicaSet可能更适用于无状态应用的部署需要

##创建headless服务

##创建statefulset控制器,pod按顺序启动并为pod分配了编号


##statefulset控制器下pod的按顺序创建和回收
StatefulSet将应用状态抽象成了两种情况:
拓扑状态:应用实例必须按照某种顺序启动;新创建的Pod必须和原来Pod的网络标识一样
存储状态:应用的多个实例分别绑定了不同存储数据
StatefulSet给所有的Pod进行了编号,编号规则是:$(statefulset名称)-$(序号)并且从0开始
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照“名字+编号”的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,即Pod对应的DNS记录

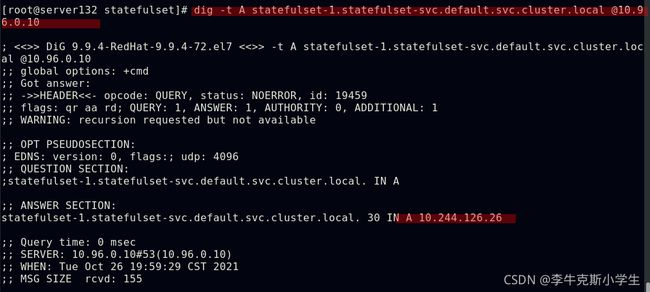
PV和PVC的设计,使得StatefulSet对存储状态的管理成为了可能

##重新创建statefulset控制器,并挂载pv

##StatefulSet会为每一个Pod分配并创建一个同样编号的PVC,这样kubernetes就可以通过PersistentVolume机制为这个PVC绑定对应的PV,从而保证每一个Pod都拥有一个独立的Volume

##挂载点会自动创建pv,基于之前我们做过的动态分配存储


##测试挂载效果




##statefulset的扩容与缩容,因在之前实验中的class.yml文件中设定archiveOnDelete=true,故这些pv卷得以保存

##回收pod并重新创建后,访问对应的pod可得到原来对应挂载卷的内容
使用statefullset部署mysql主从集群
运行一个有状态的应用程序 | Kuberneteshttps://kubernetes.io/zh/docs/tasks/run-application/run-replicated-stateful-application/
实验步骤:
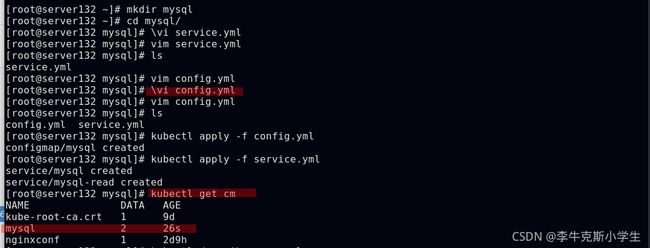

##创建configmap和service对象


##准备镜像

##创建statefulset






##测试效果;statefulset将最先启动的mysql-0作为mysql的master端,后启动的mysql-1作为slave端
kubernetes调度
调度器通过kubernetes的watch机制来发现集群中新创建且尚未被调度到Node上的Pod;调度器会将发现的每一个未调度的Pod调度到一个合适的Node上来运行
kube-scheduler是Kubernetes集群的默认调度器,是集群控制面的一部分,并且其在设计上是允许用户自研一个调度组件并替换原有的kube-scheduler
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局域性、负载间的干扰等等
默认策略:
调度策略 | Kuberneteshttps://kubernetes.io/zh/docs/reference/scheduling/policies/调度框架:
调度框架 | KubernetesFEATURE STATE: Kubernetes 1.19 [stable] 调度框架是面向 Kubernetes 调度器的一种插件架构, 它为现有的调度器添加了一组新的“插件” API。插件会被编译到调度器之中。 这些 API 允许大多数调度功能以插件的形式实现,同时使调度“核心”保持简单且可维护。 请参考调度框架的设计提案 获取框架设计的更多技术信息。框架工作流程 调度框架定义了一些扩展点。调度器插件注册后在一个或多个扩展点处被调用。 这些插件中的一些可以改变调度决策,而另一些仅用于提供信息。每次调度一个 Pod 的尝试都分为两个阶段,即 调度周期 和 绑定周期。调度周期和绑定周期 调度周期为 Pod 选择一个节点,绑定周期将该决策应用于集群。 调度周期和绑定周期一起被称为“调度上下文”。调度周期是串行运行的,而绑定周期可能是同时运行的。如果确定 Pod 不可调度或者存在内部错误,则可以终止调度周期或绑定周期。 Pod 将返回队列并重试。扩展点 下图显示了一个 Pod 的调度上下文以及调度框架公开的扩展点。 在此图片中,“过滤器”等同于“断言”,“评分”相当于“优先级函数”。一个插件可以在多个扩展点处注册,以执行更复杂或有状态的任务。 scheduling framework extension points -- 调度框架扩展点 队列排序 队列排序插件用于对调度队列中的 Pod 进行排序。 队列排序插件本质上提供 less(Pod1, Pod2) 函数。 一次只能启动一个队列插件。前置过滤 前置过滤插件用于预处理 Pod 的相关信息,或者检查集群或 Pod 必须满足的某些条件。 如果 PreFilter 插件返回错误,则调度周期将终止。https://kubernetes.io/zh/docs/concepts/scheduling-eviction/scheduling-framework/nodeName是节点选择约束的最简单方法,但一般不推荐;如果nodeName在PodSpec中指定了,则它优先于其他的节点选择方法;使用nodeName来选择节点的一些限制:
如果指定的节点不存在
如果指定的节点没有资源来容纳pod,则pod调度失败
云环境中的节点名称并非总是可预测或稳定的

##使用nodename方式创建pod,pod被准确调度到server133主机

##当指定pod调度到不存在于集群中nodename的节点上时,pod会调度失败

##可以通过此方式将pod调度到集群的master节点上
nodeSelector是节点选择约束的最简单推荐形式

##以nodeselector的方式调度pod

##为节点添加nodeselector定义的标签后,pod成功被调度至此节点;调度成功后的pod不会因为当前节点标签的更改而驱离pod

##此调度策略比较高效和精准
亲和与反亲和
官方解释:
将 Pod 分配给节点 | KubernetesPod so that it can only run on particular set of Node(s). There are several ways to do this, and the recommended approaches all use [label selectors](/docs/concepts/overview/working-with-objects/labels/) to facilitate the selection. Generally such constraints are unnecessary, as the scheduler will automatically do a reasonable placement (e.g. spread your pods across nodes so as not place the pod on a node with insufficient free resources, etc.) but there are some circumstances where you may want more control on a node where a pod lands, for example to ensure that a pod ends up on a machine with an SSD attached to it, or to co-locate pods from two different services that communicate a lot into the same availability zone.https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/nodeSelector提供了一种非常简单的方法来将pod约束到具有特定标签的节点上;亲和与反亲和功能极大地扩展了表达约束的类型
此类规则是“软” / “偏好”,而不是硬性要求,因此,如果调度器无法满足该要求,仍然会调度该pod
你可以使用节点上的pod的标签来约束,而不是使用节点本身的标签,来允许哪些pod可以或者不可以被放置在一起
1、节点亲和:
requiredDuringSchedulingIgnoredDuringExecution===必须满足 preferredDuringSchedulingIgnoredDuringExecution===倾向满足
IgnoreDuringExecution表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod

##删除应用当前目录下的所有资源文件

##node亲和性中的硬需求测试

##IgnoreDuringExecution参数保证Pod在运行期间不会由于node的标签变化而停止运行或迁移;因在文件中定义的selector键值有两对即disktype=ssh或disktype=fc,所有节点拥有其中任一一对键值的标签即可被调度

##node亲和性中的软需求测试

##pod被调度到了具有文件中定义的偏好标签的节点上

##当所有节点都不满足文件中定义的软需求时,pod仍然后被随机调度到满足硬需求的任意节点上
nodeaffinity还支持多种规则匹配条件的配置
In:label的值在列表内
NotIn:label的值不在列表内
Gt:label的值大于设置的值,不支持Pod亲和性
Lt:label的值小于设置的值,不支持pod亲和性
Exists:设置的label存在
DoesNotExist:设置的label不存在
2、pod亲和性和反亲和性
podAffinity主要解决POD可以和哪些POD部署在同一个拓扑域中的问题(拓扑域用主机标签实现,可以是单个主机,也可以是多个主机组成的cluster、zone等)
podAntiAffinity主要解决POD不能和哪些POD部署在同一个拓扑域中的问题;它们处理的是Kubernetes集群内部POD和POD之间的关系
Pod间亲和与反亲和在与更高级别的集合(例如ReplicaSets、StatefulSets、Deployments等)一起使用时,它们可能更加有用,可以轻松配置一组应位于相同定义拓扑(例如,节点)中的工作负载
Pod间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度

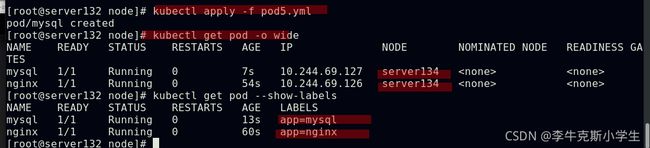
##定义pod的亲和性使此pod与具有app=nginx标签的pod调度至同一台集群节点

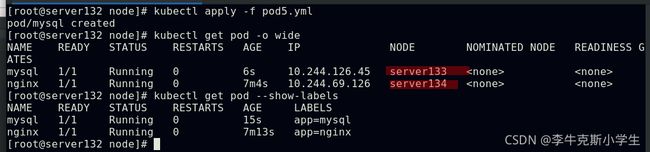
##定义pod的反亲和性使此pod不与具有app=nginx标签的pod调度至同一台集群节点
3、Taints污点
官方文档:
污点和容忍度 | KubernetesPods that *attracts* them to a set of nodes (either as a preference or a hard requirement). _Taints_ are the opposite -- they allow a node to repel a set of pods. -- 节点亲和性 是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点 (这可能出于一种偏好,也可能是硬性要求)。 污点(Taint)则相反——它使节点能够排斥一类特定的 Pod。容忍度(Toleration)是应用于 Pod 上的,允许(但并不要求)Pod 调度到带有与之匹配的污点的节点上。污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod,是不会被该节点接受的。概念 您可以使用命令 kubectl taint 给节点增加一个污点。比如,kubectl taint nodes node1 key1=value1:NoSchedule 给节点 node1 增加一个污点,它的键名是 key1,键值是 value1,效果是 NoSchedule。 这表示只有拥有和这个污点相匹配的容忍度的 Pod 才能够被分配到 node1 这个节点。https://kubernetes.io/zh/docs/concepts/scheduling-eviction/taint-and-toleration/NodeAffinity节点亲和性,是Pod上定义的一种属性,使Pod能够按我们的要求调度到某个Node上,而Taints则恰恰相反,它可以让Node拒绝运行Pod,甚至驱逐Pod
Taints(污点)是Node的一个属性,设置了Taints后,Kubernetes是不会将Pod调度到这个Node上的,于是Kubernetes就给Pod设置了个属性Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去

##集群节点的master不参与调度是因为其上有Taints,而worker节点没有此污点

##为集群中的server133主机打上污点后,后续pod都会被调度至没有污点的server134主机上


##给server134节点主机也打上污点后,原来运行在其上面的pod会被驱离

##在pod清单文件中配置污点容忍后,server134主机其上又可以重新运行pod
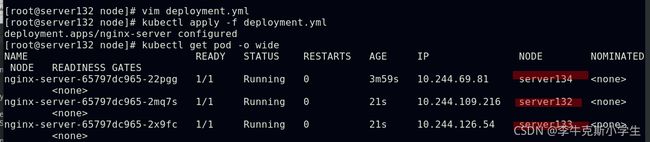
##扩展pod副本达到一定数量后,集群中所有主机的污点都被容忍,即这些副本可以运行在集群所有节点上
其中effect(可理解为污点类型)可取值:NoSchedule、PreferNoSchedule、NoExecute
NoSchedule:POD不会被调度到标记为Taints的节点
PreferNoSchedule:NoSchedule的软策略版本
NoExecute:一旦Taint生效,如该节点内正在运行的POD没有对应Tolerate设置,会直接被驱逐
tolerations中定义的key、value、effect要与node上设置的Taint保持一致:如果operator是Exists ,value可以省略;如果operator是Equal,则key与value之间的关系必须相等;如果不指定operator属性,则默认值为Equal
还有两个特殊值:当不指定key,再配合Exists就能匹配所有的key与value,可以容忍所有污点;当不指定effect,则匹配所有的effect

##删除node污点
影响Pod调度的指令还有:cordon、drain、delete,后期创建的pod都不会被调度到该节点上,但操作的暴力程度不一样
cordon停止调度:影响最小,只会将node调为SchedulingDisabled,新创建的pod不会被调度到该节点,节点原有pod不受影响,仍正常对外提供服务

drain驱逐节点:首先驱逐node上的pod,在其他节点重新创建,然后将节点调为SchedulingDisabled


delete删除节点:最暴力的一个,首先驱逐node上的pod,在其他节点重新创建,然后从master节点删除该node,master失去对其控制,如要恢复调度,需进入node节点重启kubelet服务(基于node的自注册功能以恢复使用)

![]()

kubernetes访问控制
官方文档传送门
访问 API | Kubernetes关于 Kubernetes 如何实现和控制 API 访问的介绍性材料,可阅读 控制 Kubernetes API 的访问。参考文档: 身份认证 使用启动引导令牌来执行身份认证 准入控制器 动态准入控制 鉴权与授权 基于角色的访问控制 基于属性的访问控制 节点鉴权 Webhook 鉴权 证书签名请求 包含 CSR 的批复 和证书签名 服务账号 开发者指南 管理文档https://kubernetes.io/zh/docs/reference/access-authn-authz/


Authentication(认证)
认证方式现共有8种,可以启用一种或多种认证方式,只要有一种认证方式通过,就不再进行其它方式的认证;通常启用X509 Client Certs和Service Accout Tokens两种认证方式
Kubernetes集群有两类用户:由Kubernetes管理的Service Accounts(服务账户)和(Users Accounts)普通账户,kubernetes中账号的概念不是我们理解的账号,它并不真的存在,只是形式上存在
Authorization(授权)
必须经过认证阶段,才到授权请求,根据所有授权策略匹配请求资源属性,决定允许或拒绝请求;授权方式现共有6种,AlwaysDeny、AlwaysAllow、ABAC、RBAC、Webhook、Node;默认集群强制开启RBAC(Role-Based Access Control / 基于角色的访问控制)
Admission Control(准入控制)
用于拦截请求的一种方式,运行在认证、授权之后,是权限认证链上的最后一环,对请求API资源对象进行修改和校验
访问kubernetes的API Server的客户端主要分为两类:
kubectl:用户家目录中的.kube/config里面保存了客户端访问API Server的密钥相关信息,这样当用kubectl访问kubernetes时,它就会自动读取该配置文件,向API Server发起认证,然后完成操作请求
pod:Pod中的进程需要访问API Server,如果是人去访问或编写的脚本去访问,这类访问使用的账号为UserAccount;而Pod自身去连接API Server时,使用的账号是ServiceAccount,生产中后者使用居多
kubectl向apiserver发起的命令,采用的是http方式,其实就是对URL发起增删改查的操作


以上两种api的区别是:api它是一个特殊链接,只有在核心v1群组中的对象才能使用;apis它是一般API访问的入口固定格式名
UserAccount与serviceaccount:
用户账户是针对人而言的、服务账户是针对运行在pod中的进程而言
用户账户是全局性的,其名称在集群各namespace中都是全局唯一的,未来的用户资源不会做namespace隔离,服务账户是namespace隔离的
通常情况下,集群的用户账户可能会从企业数据库进行同步,其创建需要特殊权限,并且涉及到复杂的业务流程;服务账户创建的目的是为了更轻量,允许集群用户为了具体的任务创建服务账户 (即权限最小化原则)

##创建serviceaccount,此时k8s为用户自动生成认证信息,但没有授权
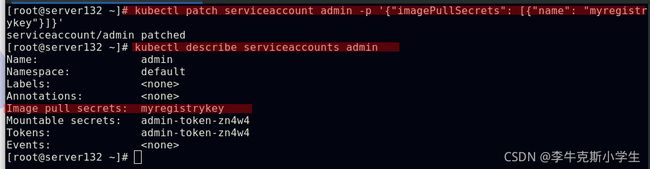
##添加镜像拉取secrets到serviceaccount中



##此时集群中的调度节点均无法拉取镜像仓库中私有项目的镜像资源


##在pod中调用serviceaccount;将认证信息添加到serviceAccount中要比直接在Pod指定imagePullSecrets要安全很多
创建useraccount:

##准备创建用户所需的集群文件username.key、username.csr、username.crt

##创建test用户账户

##将test用户添加至集群中,admin用户可以成功get到pod

##将集群当前使用用户切换为test,发现其无法查看到运行的pod;这是因为此时test用户只是通过认证,但还没有权限操作集群资源,需要继续添加授权

##切换集群当前使用用户为admin,对test用户进行授权
RBAC(Role Based Access Control):基于角色访问控制授权
允许管理员通过Kubernetes API动态配置授权策略,RBAC就是用户通过角色与权限进行关联;RBAC只有授权,没有拒绝授权,所以只需要定义允许该用户做什么即可;RBAC包括四种类型:Role、ClusterRole、RoleBinding、ClusterRoleBinding
RBAC的三个基本概念
Subject:被作用者,它表示k8s中的三类主体---user、group、serviceAccount
Role:角色,它其实是一组规则,定义了一组对Kubernetes API对象的操作权限
RoleBinding:定义了“被作用者”和“角色”的绑定关系
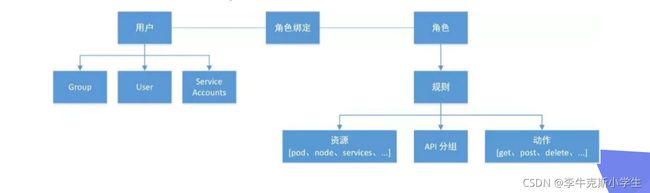
Role和ClusterRole:Role是一系列的权限的集合,Role只能授予单个namespace中资源的访问权限;ClusterRole跟 Role类似,但是可以在集群中全局使用


##创建权限集合对象myrole
RoleBinding和ClusterRoleBinding:RoleBinding是将Role中定义的权限授予给用户或用户组,它包含一个subjects列表(users、groups、serviceAccounts),并引用该Role;RoleBinding是对某个namespace内授权,ClusterRoleBinding适用在集群范围内使用

##创建rolebinding,将以上创建的role中权限授予给test用户

##切换至test用户进行测试

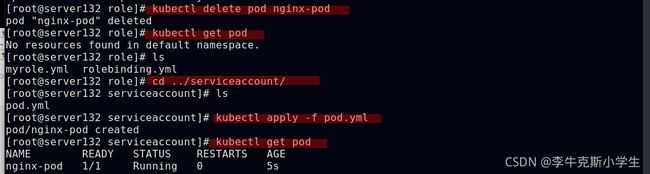
##可以看到test用户除了myrole中指定的pod资源权限外,对其他资源均无任何权限


##创建clusterrole

##创建rolebinding,将以上创建的clusterrole中权限授予给test用户

##可以看到在访问资源时不能跨namespace


##创建rolebinding,将以上创建的clusterrole中权限授予给test用户


##可以看到此时访问授权资源时可以跨namespace
服务账户的自动化
服务账户准入控制器(Service account admission controller)
如果该pod没有ServiceAccount设置,将其ServiceAccount设为default;保证pod所关联的ServiceAccount存在,否则拒绝该pod;如果pod不包含ImagePullSecrets设置,那么将ServiceAccount中的ImagePullSecrets信息添加到pod中;将一个包含用于API访问的token的volume添加到pod中;将挂载于/var/run/secrets/kubernetes.io/serviceaccount的volumeSource添加到pod下的每个容器中
Token 控制器(Token controller)
检测服务账户的创建,并且创建相应的Secret以支持API访问;检测服务账户的删除,并且删除所有相应的服务账户Token Secret;检测Secret的增加,保证相应的服务账户存在,如有需要,为Secret增加token;检测Secret的删除,如有需要,从相应的服务账户中移除引用
服务账户控制器(Service account controller)
服务账户管理器管理各命名空间下的服务账户,并且保证每个活跃的命名空间下存在一个名为“default”的服务账户
Kubernetes还拥有用户组(Group)的概念:
ServiceAccount对应内置“用户”的名字是:system:serviceaccounts:
而用户组所对应的内置名字是:system:serviceaccounts:

##表示mynamespace命名空间中所有ServiceAccount
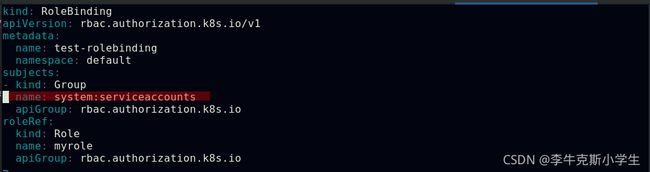
##表示整个系统中所有命名空间下的ServiceAccount
Kubernetes还提供了四个预先定义好的ClusterRole来供用户直接使用:cluster-amdin、admin、edit、view
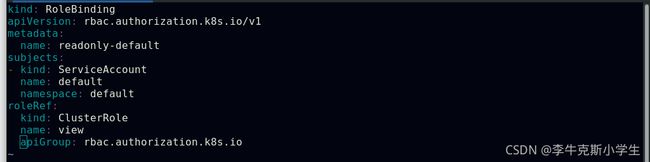
##最佳实践