MSQL系列(五) Mysql实战-索引最左侧匹配原则分析及实战
Mysql实战-索引最左侧匹配原则分析及实战
前面我们讲解了索引的存储结构,B+Tree的索引结构,以及索引最左侧匹配原则,Explain的用法,今天我们来实战一下 最左侧匹配原则
1.联合索引最左侧匹配原则
联合索引有一个最左侧匹配原则
最左匹配原则指的是,当使用联合索引进行查询时,MySQL会优先使用最左边的列进行匹配,然后再依次向右匹配。
假设我们有一个表,包含三个列:A、B、C
创建联合索引(A,B,C) 等同于创建了索引 A, 索引 (A,B), 索引 (A,B,C)
- 我们使用(A,B,C)这个联合索引进行查询时,MySQL会先根据列A进行匹配
- 再根据列B进行匹配,最后再根据列C进行匹配。
- 如果我们只查询了(A,B)这两个列,而没有查询列C,那么MySQL只会使用(A,B)这个前缀来进行索引匹配,而不会使用到列C
- 如果我们要查询 了(B,C)这两个列,而没有查询列A,那么MySQL索引就会失效,导致找不到索引,因为最左侧匹配原理
- 所以 我们应该尽量把最常用的列放在联合索引的最左边,这样可以提高查询效率
2.实战
新建表结构 user, user_info
#新建表结构 user
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`id_card` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '身份证ID',
`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户名字',
`age` int NOT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'
- id 主键id列
- id_card 身份证id
- user_name 用户姓名
- age 年龄
先插入测试数据, 插入 5条测试数据
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (1, '11', 'aa', 10);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (2, '22', 'bb', 20);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (3, '33', 'cc', 30);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (4, '44', 'dd', 40);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (5, '55', 'ee', 50);
2.1 创建 id_card,user_name,age的索引列
alter table user add index idx_card_name_age(id_card,user_name,age);
创建索引成功
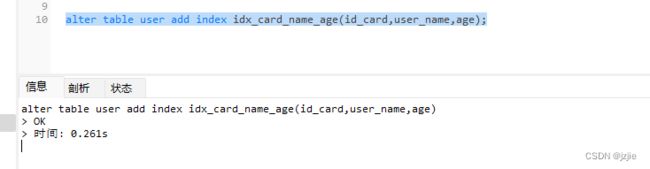
我们现在user表只有一个新建的索引

2.2. 查B,C列信息
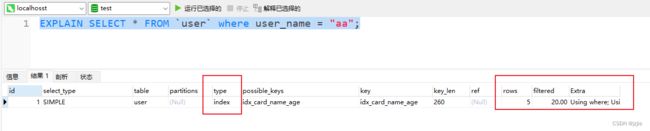
- (A,B,C)的联合索引, 单纯的查B, 或者查BC是无法用到索引的,走的是全部索引扫描type=index类型
查询user_name, 查询语句中没有id_card
EXPLAIN SELECT * FROM `user` where user_name = "aa";
执行结果
- (A,B,C)的联合索引, 单纯的查C,同样的结果,走的是全部索引扫描type=index类型
查询age,查询语句中没有id_card
EXPLAIN SELECT * FROM `user` where age = 10;
执行结果

- (A,B,C)的联合索引, 查BC,同样的结果,走的是全部索引扫描type=index类型
查询user_name 和 age,查询语句中没有id_card
EXPLAIN SELECT * FROM `user` where user_name = "aa" and age = 10;
执行结果

2.3查询A列的相关信息
上面我们看到了只要查询语句中不包含A的字段信息,所有的索引全都不生效,扫描全部索引信息,这不是我们想要的
这也就是最左侧匹配原则导致的,所以我们在查询的时候,一定要从最左侧开始查询,也就是查询语句一定要有A查询条件,否则索引不生效
- (A,B,C)的联合索引, 查A,type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
只查询 id_card 字段
EXPLAIN SELECT * FROM `user` where id_card = "11" ;
执行结果

- (A,B,C)的联合索引, 查A,B列,相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
查询 id_card 及 user_name 字段
EXPLAIN SELECT * FROM `user` where id_card = "11" and user_name = "aa" ;
执行结果

- (A,B,C)的联合索引, 查A,C列,相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=20% ,过滤占比 20%,意思是所有的5索引数据,找到了1条数据
效率不算高,也不建议这样使用
查询 id_card 及 age 字段
EXPLAIN SELECT * FROM `user` where id_card = "11" and user_name = "aa" ;
执行结果

- (A,B,C)的联合索引, 查A,B,C 列,相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
查询 id_card 及 user_name 及age 字段
EXPLAIN SELECT * FROM `user` where id_card = "11" and user_name = "aa" and age =10 ;
执行结果

- (A,B,C)的联合索引, 查C,A,B 列,查询语句乱序, 看下查询结果,依旧是相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
查询 id_card 及 user_name 及age 字段, 查询条件的乱序,不会影响到索引的信息
EXPLAIN SELECT * FROM `user` where age =10 and user_name = "aa" and id_card = "11" ;
执行结果

- (A,B,C)的联合索引, 查C,A,B 列,查询语句乱序, 看下查询结果,依旧是相同的结果, type=ref类型使用了索引,索引扫描行数rows=1,只扫描了一行,精确查找, filtered=100%,过滤占比百分百,效率很高
查询 id_card 及 user_name 及age 字段, 查询条件的乱序,不会影响到索引的信息
EXPLAIN SELECT * FROM `user` where age =10 and user_name = "aa" and id_card = "11" ;
执行结果
3. 如何知道具体用了那个索引?
我们可以通过 explain key_len计算到底使用了那个索引字段
通过刚才的验证,我们了解不同的索引,使用的ken_len长度不同,到底这个key_len如何计算,我们如何知道到底用了那个索引?
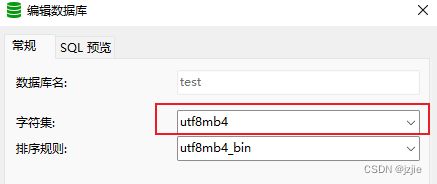
首先看下数据库编码类型 utf8mb4 编码方式
然后 看下表结构
id_card notNull
user_name 允许null
age 允许null

然后开始计算 ken_len的长度
- 字符集编码: 字符 如 utf8mb4 = 4 ,utf8 = 3, gbk = 2, latin1 = 1, 数字int =4位
- 列是否为空: NULL(+1),NOT NULL(+0)
- 列类型为字符: varchar(+2), char(+0)
到底如何计算key_len呢? key_len = (字段长度)* 编码格式 + (notNull/null)+ 列类型, 我们看下是否真的是这样
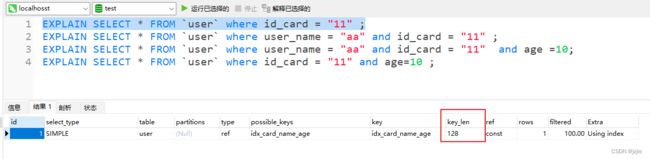
EXPLAIN SELECT * FROM `user` where id_card = "11" ;
使用了 id_card 单个字段的索引
key_len
= (char(32)) 4 + (notNull)0 + (char)0
= 324 +0 +0 = 128
EXPLAIN SELECT * FROM `user` where user_name = "aa" and id_card = "11" ;
使用了 id_card 和 user_name 2个字段的索引, user_name允许为null +1,
key_len
= (char(32)) * 4 + (notNull)0 + (char)0 + (char(32)) 4 + (Null)1 + (char)0
= 324 + 32*4 +1 = 257

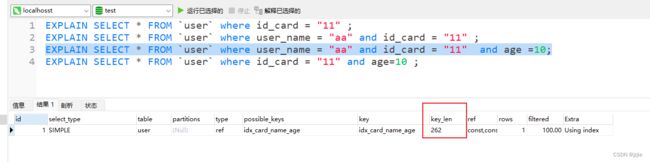
EXPLAIN SELECT * FROM `user` where user_name = "aa" and id_card = "11" and age =10;
使用了 id_card 和 user_name 及 age 三个字段的索引, user_name允许为null +1, age允许为null +1, age类型为int,占4位
key_len
= (char(32)) * 4 + (notNull)0 + (char)0 + (char(32)) 4 + (Null)1 + (char)0 + (int)4 + (Null)1 + (int)0
= 324 + 32*4 +1 + 5= 262
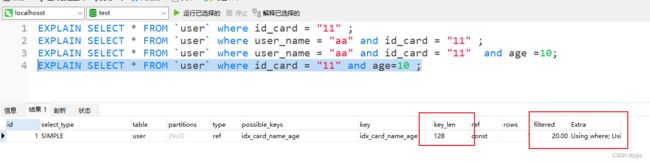
没有用到某个字段的索引,ken_len不会计算它的长度,比如A,C列的查询 id_card和age的查询,不会用到age的索引,只用到了id_card,key_len只会计算 id_card的长度
EXPLAIN SELECT * FROM `user` where id_card = "11" and age=10 ;
key_len = (char(32)) * 4 + (notNull)0 + (char)0 = 128, 只用到了id_card的索引信息
至此,我们了解了联合索引的最左侧匹配原则,也知道了如何去优化查询语句,才能使用到索引,并且知道了key_len分析具体使用了那些索引