LINUX开源软件测试大乐,开源性能测试工具大比武
如果我们需要模拟如下的负载,那就要想想办法咯~ 这里抛砖引玉希望熟悉这块儿的小伙伴们可以分享下踩过的坑
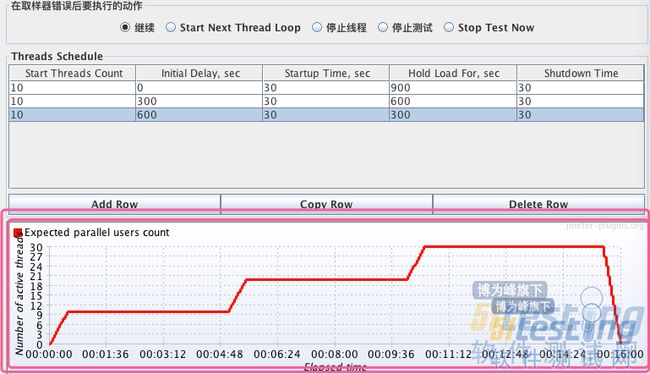
2.4.2 分布式执行
如果我们模拟高并发的场景,可能一台负载机是不够的这时候我们可以通过分布式压测来执行。Locust是master/slave架构,接下来我们一起看下如何使用locust进行分布式压测。
Step 1:启动master
locust -f scenario_on_web.py --master --host=https://testdingtalk3.xbongbong.com
--master参数表示当前机器(进程)的角色是master。
master不生成负载,它只负责任务调度和数据收集。
Step 2:启动slave
locust -f scenario_on_web.py --slave --master-host=192.168.10.175
--slave参数表示当前机器是locust的slave节点。
Step 3:设置压测数据
我们打开locust web来看下现在是什么情景,下图中显示当前locust服务有3台slave节点机器,我们设置模拟的虚拟用户总数会均分到这3台slave节点上。
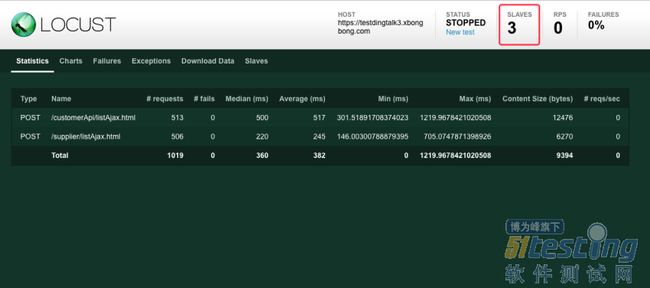
PS:需要注意的点是master和salve都需要有我们的脚本文件。
上面是以locust web服务的形式来执行压测,我们当然也可以通过non-web的方式来设置和执行压测场景。
非Web UI的方式执行locust时,我们经常会用到以下参数
locust -f scenario_on_web.py --no-web --host=https://testdingtalk3.xbongbong.com -c 10 -t 3m
--no-web:以非Web UI方式执行locust
-c:并发用户数
-t:执行时间
-r:每秒启动用户数
--expect-slave:期望的slave节点数(未达到期望节点数之前不执行压测)
以非Web UI方式执行分布式压测的命令如下:
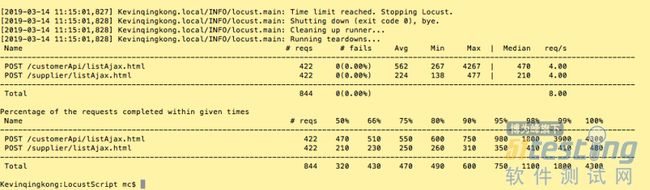
locust -f scenario_on_web.py --no-web --master -c 10 -t 2m -r 1--host=https://testdingtalk3.xbongbong.com --expect-slaves=3
三:Gatling
3.1 Gatling介绍
Gatling是一款基于Scala开发的高性能性能测试工具,它主要用于对服务器进行负载等测试,并分析和测量服务器的各种性能指标。Gatling主要用于测量基于HTTP的服务器,比如Web应用程序,RESTful服务等,它有商业版和开源免费版,本文将总结下开源免费版本gatling的实战。
Gatling的特点:
1.支持Akka Actors 和 Async IO,从而能达到很高的性能
2.支持实时生成Html动态轻量报表,从而使报表更易阅读和进行数据分析
3.支持DSL脚本,从而使测试脚本更易开发与维护
4.支持录制并生成测试脚本,从而可以方便的生成测试脚本
5.支持导入HAR(Http Archive)并生成测试脚本
6.支持Maven,Eclipse,IntelliJ等,以便于开发
7.支持Jenkins,以便于进行持续集成
8.支持插件,从而可以扩展其功能,比如可以扩展对其他协议的支持
Gatling适用的场景包括:测试需求经常改变,测试脚本需要经常维护;测试环境的客户机性能不强,但又希望发挥硬件的极限性能;能对测试脚本进行很好的版本管理,并通过CI进行持续的性能测试;希望测试结果轻量易读等。
3.2 Gatling环境搭建
在https://gatling.io/download/页面点击下载。解压即可。
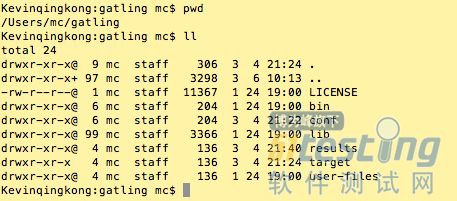
Bin:gatling的可执行文件。
Conf:gatling的配置文件
Lib:依赖的包
Result:存放测试结果
User-files:存放测试场景文件。
3.3 Gatling初体验
gatling自带的有个例子,我们进入到bin目录下执行gatling.sh执行测试。
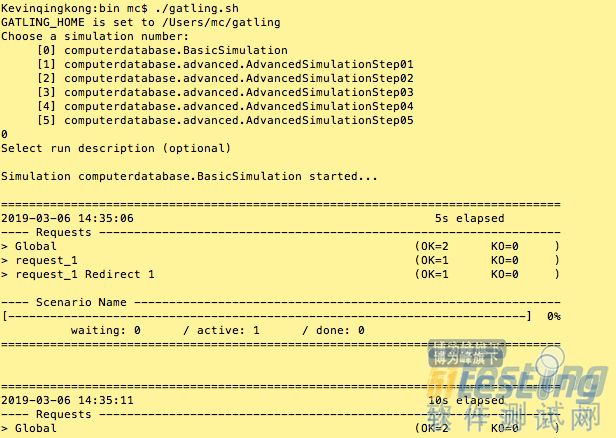
选择0,然后两次回车键开始执行压测。
我们不用关心什么时候执行完毕。执行完成后gatling会自动退出进程并生成报告。
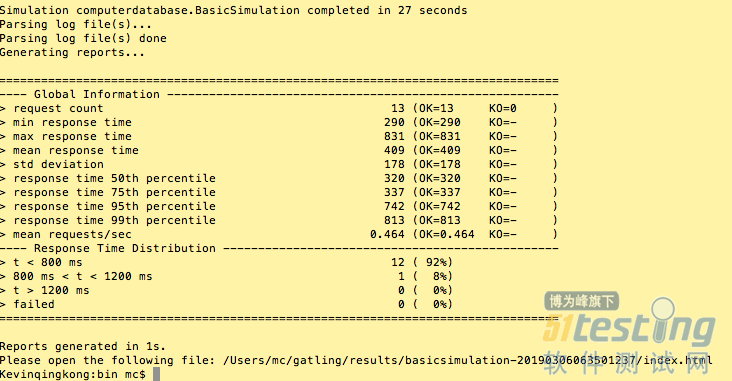
打开gatling
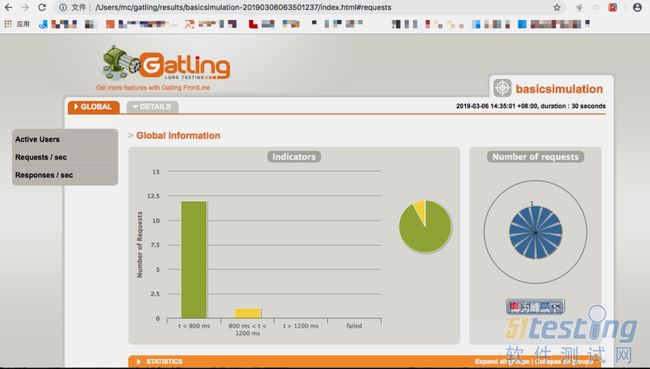
自动生成的报告
哇~简直是惊艳!非常详细且漂亮的报告
3.4 Gatling实战
gatling的脚本是Scala语言,我们可以使用IDEA安装Scala插件。也可以去Scala官网(https://www.scala-lang.org/download/)下载tar包。
我这里选择的是后者,将scala的tar包解压后配置一下环境变量
export SCALA_HOME=/Users/mc/scala
export PATH=$PATH:$SCALA_HOME/bin
执行source .bash_profile即可。
对于Scala语言的学习,本文就不总结了,小伙伴们自行学习吧~
使用IDEA开发Scala脚本时需要一些配置步骤,如下执行:
Step 1:配置maven(略过…)
Step2:安装IDEA(略过…)
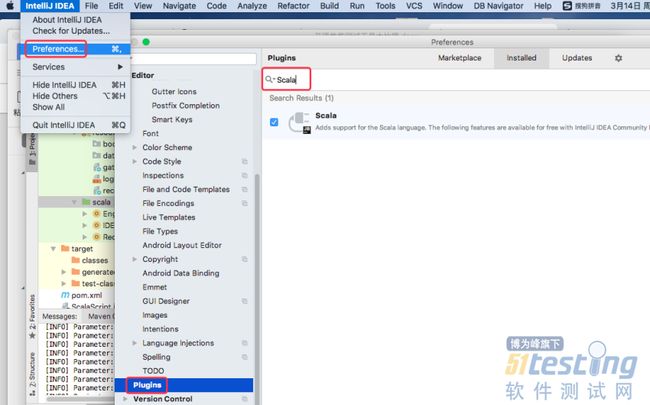
Step3:在IDEA的plugins界面中搜索Scala并安装
Step4:根据gatling模板创建gtling-scala项目
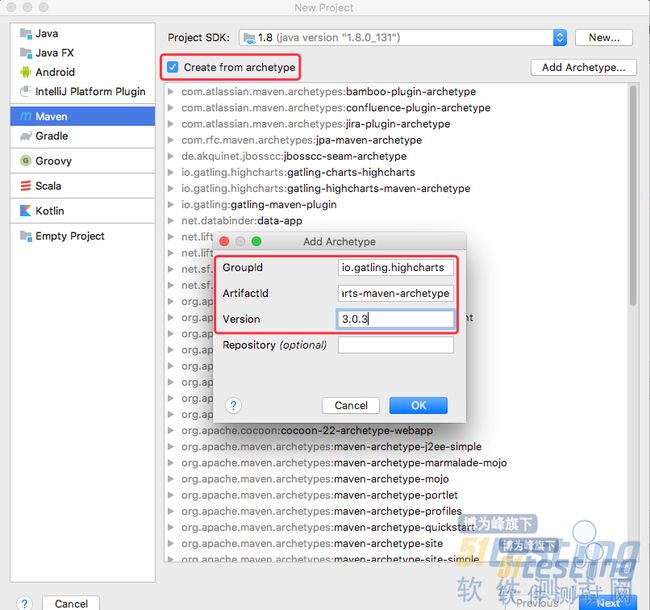
Group-id填写为:io.gatling.highcharts
ArtifactId填写为:gatling-highcharts-maven-archetype
Version填写为:3.0.3(请查看最新版本,当然目前最新是3.0.3)
模板工程生成后,工程目录结构如下:
脚本文件在src/test/scala目录下。
3.4.1 Gatling常用API
Gatling的脚本有3大部分组成:header,scenario,setUp。
Header:组装请求头。
Scenario:具体业务执行。
SetUp:设置执行场景。
import io.gatling.core.Predef._
import io.gatling.http.Predef._
class CustomerList extends Simulation {val httpProtocol = http.baseUrl("https://testdingtalk3.xbongbong.com")
.acceptHeader("text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
.doNotTrackHeader("1")
.acceptLanguageHeader("en-US,en;q=0.5")
.acceptEncodingHeader("gzip, deflate")
.userAgentHeader("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36")
val headers_10 = Map("Content-Type" -> "application/x-www-form-urlencoded")
val business_process=scenario("业务流压测")
.exec(http("钉钉扫码登录").get("/user/autoLogin.do?t=63t42AXnCd6hCEdQl+dOZCXVIiwZVkRhX60J7lPXpv+xZt3tvEB1sT/ld8xQ0FUp7iqSfah+CNgNbYzcwW1d9Q==&nonce=jmymnp"))
.pause(1, 5).exec(http("客户列表").post("/customerApi/listAjax.html").body(StringBody("{\"sign\": \"c8fb3b2bdb32400069161840f55a525f707ae04abefccaf03a46da6072805099\", \"JSESSIONID\": \"fu9f7l5zt5pc4ca85g8fkqqtp41vhbtz\", \"frontDev\": \"0\", \"platfrom\": \"web\", \"params\": {\"corpid\":\"dinga93c84f4d89688bf35c2f4657eb6378f\",\"nowUserId\":\"030917160122954929\",\"templateId\":175,\"page\":1,\"pageSize\":20,\"belongerType\":\"0\",\"isMain\":1,\"treeType\":\"\",\"pid\":\"\",\"nameLike\":\"\",\"nameLikeType\":\"\",\"isArchived\":0,\"child\":\"customer\",\"categoryId\":\"\"}}")).check(status.is(200)))
.pause(1, 5)
.exec(http("合同列表").post("/contractApi/listAjax.html").check(status.is(200)))
setUp(business_process.inject(constantUsersPerSec(10).during(100)).protocols(httpProtocol))}
header部分常用的api如下:
baseurl:设置域名
acceptHeader:请求头的accept。
acceptLanguageHeader:请求头中的Language
acceptEncodingHeader:请求头的编码
Scenario部分常用的api:
exec:执行(发送请求)
body:设置请求报文的body
post:模拟http(s)的post方法
get:模拟http(s)的get方法
headers:设置请求头信息
formParam:设置请求报文的body部分(以表单形式)
feed:提供后续请求的参数(参数化时使用)
check:检查响应报文内容(类似断言)
during:模拟压测时长
setUp部分常用api:
setUp部分是模拟用户使用场景的设置。
先来看下Gatling中所有的场景模拟:
setUp(
scenario.inject(
// 在一段时间内不做任何事情
nothingFor(4 seconds),
// 一次性启动指定数量的虚拟用户数
atOnceUsers(10),
// 5秒内启动10个虚拟用户
rampUsers(10) over(5 seconds),
// 保持20个并发虚拟用户数,持续15分钟
constantUsersPerSec(20) during(15 minutes),
// 在20个并发虚拟用户基数上随机递减,持续15分钟
constantUsersPerSec(20) during(15 minutes) randomized,
// 在10分钟内,虚拟用户数从10递增到20
rampUsersPerSec(10) to 20 during(10 minutes),
// 在10分钟内,虚拟用户数从10上升到20(随机增加虚拟用户数)
rampUsersPerSec(10) to 20 during(10 minutes) randomized,
// 下面这两个。。。理解不了。。。
splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy(10 minutes),
splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedByatOnceUsers(30),
).protocols(httpConf) )
3.4.3 分布式执行
非常抱歉,Gatling不支持分布式执行~
四:wrk
4.1 wrk环境搭建
wrk的仓库地址是:https://github.com/wg/wrk
我使用的是Mac,所以只能以Mac OS来说明下wrk的搭建了。
brew install wrk
4.2 wrk初体验
安装好wrk后,咱们先看下wrk支持的参数吧,wrk回车键即可。
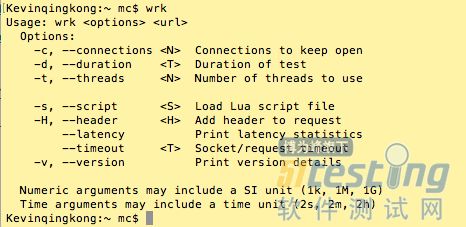
-c:保持的链接数。
-d:压测时长。
-t:压测时使用的线程数。
-s:lua脚本文件路径。
-H:--header 请求头
--latency 输出响应延迟信息
--timeout 请求超时时长
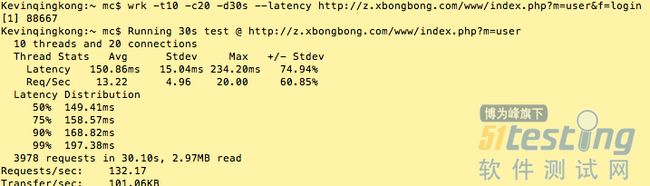
模拟get请求:
wrk -t10 -c20 -d30s --latency http://z.xbongbong.com/www/index.php?m=user&f=login
wrk的高级用法是使用Lua脚本实现set_up/running/stop三大部分的自定义,因为水平有限,这里我就不班门弄斧了。
五:Jmeter
Jmeter这里我就不多写什么了,之前笔者写过Jmeter实战的文章,感兴趣的小伙伴们可以下载第50期的《51测试天地》期刊http://www.51testing.com/html/33/n-3958933.html这里下载~不但有Jmeter实战还有其他优秀的同学们分享的各种测试topic~
六:工具对比选型
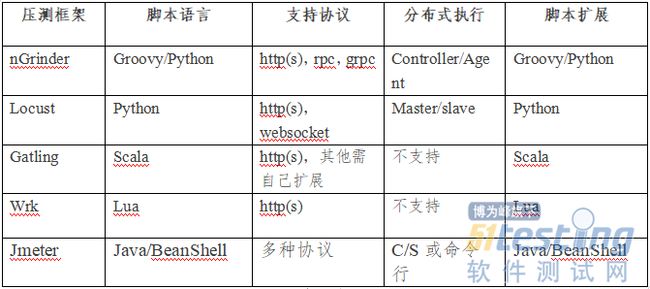
想使用界面操作的形式对我的系统做性能测试,并且希望测试数据有良好的可视化展示方式:建议使用Jmeter工具
性能基准测试:建议使用wrk工具
对系统模拟复杂场景的性能测试;建议使用locust工具
压测的同时,监控服务器性能指标:建议使用Jmeter工具
使用匀速请求的方式,对系统进行性能测试;建议使用Jmeter或locust
体验编程的乐趣,自己编写脚本进行性能测试;Jmeter:使用Java请求,自由扩展。locust,使用Python语言编写脚本。
把玩了这么多,我个人比较推崇的是Locust和Jmeter,当然需要根据小伙伴们的实际情况略加考虑~
......
查看更多精彩内容,请点击下载:
版权声明:本文出自《51测试天地》第五十三期。51Testing软件
33/3<123