1. MongoDB快速实战与基本原理
分布式技术MongoDB
- 1. MongoDB介绍
-
- 1.1 什么是MongoDB
- 1.2 MongoDB vs 关系型数据库
- 1.3 MongoDB的技术优势
- 1.4 MongoDB的应用场景
- 2. MongoDB快速开始
-
- 2.1 linux安装MorgoDB
- 2.2 Mongo shell使用
- 2.3 安全认证
- 3. 文档操作
-
- 3.1 插入
- 3.2 练习
-
- upsert
- replace语义
- findAndModify命令
- 3.3 删除文档
-
- 使用remove删除文档
- 使用delete删除文档
- 返回被删除文档
- 文档操作最佳时间
- 4. MongoDB数据模型
-
- 4.1 BSON协议与数据类型
-
- JSON
- BSON
- BSON的数据类型
- $type操作符
- 4.2 日期类型
- 4.3 ObjectId生成器
- 4.4 内嵌文档和数组
-
- 内嵌文档
- 数组
- 嵌套型的数组
- 4.5 固定集合
-
- 使用示例
- 5. WiredTiger读写模型详解
-
- 5.1 WiredTiger介绍
- 5.2 WiredTiger读写模型
-
- 读缓存
本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。
课程内容:
1.MongoDB优势及其应用场景分析
2.MongoDB安装&文档操作
3.MongoDB数据模型详解
4.MongoDB固定集合实战
5.基于WiredTiger存储引擎读写模型详解
MongoDB4.0之后支持复制集的多文档事务,4.2以后支持分片的事务。
1. MongoDB介绍
1.1 什么是MongoDB
MongoDB是一个文档数据库(以JSON为数据模型),由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。
文档来自于“JSON Document”,并非我们一般理解的PDF,WORD文档。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,数据格式是BSON,一种类似JSON的二进制形式的存储格式,简称Binary JSON,和JSON一样支持内嵌的文档对象和数组对象,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,还支持对数据建立索引。原则上 Oracle和MySQL能做的事情,MongoDB 都能做(包括ACID事务)。
MongoDB是一个开源OLTP数据库,它灵活的文档模型(JSON)非常适合敏捷式开发、高可用和水平扩展的大数据应用。
- OLTP: on-line Transaction Processing,联机(在线)事务处理
- OLAP: on-line Analytical Processing,联机(在线)分析处理
MongoDB在数据库总排名第5,仅次于Oracle、MySQL等RDBMS,在NoSQL数据库排名首位。从诞生以来,其项目应用广度、社区活跃指数持续上升。
1.2 MongoDB vs 关系型数据库
1. 概念
MongoDB概念与关系型数据库(RDBMS)非常类似:

-
数据库(database)︰最外层的概念,可以理解为逻辑上的名称空间,一个数据库包含多个不同名称的集合。
-
集合(collection):相当于SQL中的表,一个集合可以存放多个不同的文档。
-
文档(document) :一个文档相当于数据表中的一行,由多个不同的字段组成。
-
字段(field) :文档中的一个属性,等同于列(cotumn)。
-
索引(index) ︰独立的检索式数据结构,与SQL概念一致。
-
_id:每个文档中都拥有一个唯一的_id字段,相当于SQL中的主键(primary key)
-
视图(view):可以看作一种虚拟的(非真实存在的)集合,与SQL中的视图类似
从MongoDB3.4版本开始提供了视图功能,其通过聚合管道技术实现。 -
聚合操作($lookup) : MongoDB用于实现"类似"表连接(tablejoin)的聚合操作符。
尽管这些概念大多与SQL标准定义类似,但MongoDB与传统RDBMS仍然存在不少差异
包括:
- 半结构化,在一个集合中,文档所拥有的字段并不需要是相同的,而且也不需要对所用的字+段进行声明。因此,MongoDB具有很明显的半结构化特点。除了松散的表结构,文档还可以支持多级的嵌套、数组等灵活的数据类型,非常契合面向对象的编程模型。
- 弱关系,MongoDB没有外键的约束,也没有非常强大的表连接能力。类似的功能需要使用聚合管道技术来弥补。

1.3 MongoDB的技术优势
MongoDB基于灵活的JSON文档模型,非常适合敏捷式的快速开发。与此同时,其与生俱来的高可用、高水平扩展能力使得它在处理海量、高并发的数据应用时颇具优势。
- JSON结构和对象模型接近,开发代码量低
- JSON的动态模型意味着更容易响应新的业务需求
- 复制集提供99.999%高可用
- 分片架构支持海量数据和无缝扩容
简单直观:从错综复杂的关系模型到一目了然的对象模型

快速:最简单快速的开发方式

灵活:快速响应业务变化

MongoDB优势:原生的高可用

MongoDB的优势:横向扩展能力

1.4 MongoDB的应用场景
从目前阿里云 MongoDB云数据库上的用户看,MongoDB的应用已经渗透到各个领域:
- 游戏场景,使用MongoDB存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新;
- 物流场景,使用MongoDB存储订单信息,订单状态在运送过程中会不断更新,以MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来;
- 社交场景,使用MongoDB存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能;
- 物联网场景,使用MongoDB存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析;
- 视频直播,使用MongoDB存储用户信息、礼物信息等;
- 大数据应用,使用云数据库MongoDB作为大数据的云存储系统,随时进行数据提取分析,掌握行业动态。l
国内外知名互联网公司都在使用MongoDB:

如何考虑是否选择MongoDB?
没有某个业务场景必须要使用MongoDB才能解决,但使用MongoDB通常能让你以更低的成本解决问题。如果你不清楚当前业务是否适合使用MongoDB,可以通过做几道选择题来辅助决策。

只要有一项需求满足就可以考虑使用MongoDB,匹配越多,选择MongoDB越合适。
2. MongoDB快速开始
2.1 linux安装MorgoDB
环境准备:
- linux系统: centos7
- 安装MongoDB社区版
下载MongoDB Community Server
下载地址: https://www.mongodb.com/try/download/community
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.4.9.tgz
tar -zxvf mongodb-linux-x86_64-rhel70-4.4.9.tgz
启动方式1:命令行启动
cd mongodb-linux-x86_64-rhel70-4.4.9/
bin/mongod --port=27017 --dbpath=/mongodb/data --logpath=/mongodb/log/mongodb.log --bind_ip=0.0.0.0 --fork

--dbpath :指定数据文件存放目录
--logpath :指定日志文件,注意是指定文件不是目录--logappend :使用追加的方式记录日志
--port:指定端口,默认为27017
--bind_ip:默认只监听localhost网卡--fork:后台启动
--auth:开启认证模式
启动方式2:配置文件启动
编辑/mongodb/conf/mongo.conf文件:
vim /mongodb/conf/mongo.conf
systemLog:
destination: file
path: /mongodb/log/mongod.log # log path
logAppend: true # 追加日志
storage:
dbPath: /mongodb/data # data directory
engine: wiredTiger # 存储引擎
journal: # 是否启用journal日志
enabled: true
net:
bindIp: 0.0.0.0
port: 27017 # port
processManagement:
fork: true # 后台启动
# -f 选项表示将使用配置文件启动mongodb
mongod -f /mongodb/conf/mongo.conf
关闭方式1:
mongod --port=27017 --dbpath=/mongodb/data --shutdown
关闭方式2:
# 进入mongo shell
use admin
db.shutdownServer()
2.2 Mongo shell使用
mongo是MongoDB的交互式JavaScript Shell界面,它为系统管理员提供了强大的界面,并为开发人员提供了直接测试数据库查询和操作的方法。
进入mongo shell:
bin/mongo --port=27017
# 或
bin/mongo localhost:27017
- - -port:指定端口,默认为27017
- - -host:连接的主机地址,默认127.0.0.1
mongo shell常用命令
mongo shell是基于JavaScript语法的,MongoDB使用了SpiderMonkey作为其内部的JavaScript解释器引擎,这是由Mozilla官方提供的JavaScript内核解释器,该解释器也被同样用于大名鼎鼎的Firefox浏览器产品之中。SpiderMonkey对ECMA Script标准兼容性非常好,可以支持ECMA Script6。可以通过下面的命令检查JavaScript解释器的版本:
| 命令 | 说明 |
|---|---|
| show dbs /show databases | 显示数据库列表 |
| use | 数据库名 切换数据库,如果不存在创建数据库 |
| db.dropDatabase() | 删除数据库 |
| show collections / show tables | 显示当前数据库的集合列表 |
| db.集合名.stats() | 查看集合详情 |
| db.集合名.drop() | 删除集合 |
| show users | 显示当前数据库的用户列表 |
| show roles | 显示当前数据库的角色列表 |
| show profile | 显示最近发生的操作 |
| load(“xxx.js”) | 执行一个JavaScript脚本文件 |
| exit / quit() | 退出当前shell |
| help | 查看mongodb支持哪些命令 |
| db.help() | 查询当前数据库支持的方法 |
| db.集合名.help() | 显示集合的帮助信息 |
| db.version() | 查看数据库版本 |
数据库操作(示例):
// 查看所有库
show dbs
// 切换到指定数据库,不存在则创建
use test
// 删除当前数据库
db.dropDatabase()
集合操作(示例):
// 查看集合
show collections
// 创建集合
db.createCollection("test")
// 删除集合
db.emp.drop()
创建集合语法
db.createCollection(name, options)
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 |
| size | 数值 | (可选)为固定集合指定一个最大值(以字节计)。如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
注意:当集合不存在时,向集合中插入文档也会创建集合

2.3 安全认证
创建管理员账号:
// 设置管理员用户名密码需要切换到admin库
use admin
// 创建管理员 roles为权限
db.createUser({user:"nanmian",pwd:"nanmian",roles:["root"]})
// 查看当前数据库所有用户信息
show users
// 显示可设置权限
show roles
// 显示所有用户
db.system.users.find()
常用权限:
| 权限名 | 描述 |
|---|---|
| read | 允许用户读取指定数据库 |
| readWrite | 允许用户读写指定数据库 |
| dbAdmin | 允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile |
| dbOwner | 允许用户在指定数据库中执行任意操作,增、删、改、查等 |
| userAdmin | 允许用户向system.users集合写入,可以在指定数据库里创建、删除和管理用户 |
| clusterAdmin | 只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限 |
| readAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的读权限 |
| readWriteAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的读写权限 |
| userAdminAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的userAdmin权限 |
| dbAdminAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限 |
| root | 只在admin数据库中可用。超级账号,超级权限 |
重新赋予用户权限
db.grantRolesToUser( "nanmian" , [
{ role: "clusterAdmin", db: "admin" } ,
{ role: "userAdminAnyDatabase", db: "admin"},
{ role: "userAdminAnyDatabase", db: "admin"},
{ role: "readWriteAnyDatabase", db: "admin"}
])
删除用户
db.dropUser("nanmian")
// 删除当前数据库所有用户
db.dropAllUser()
创建应用数据库用户
use appdb
db.createUser({user:"appdb",pwd:"nanmian",roles:["dbOwner"]})
注意:默认情况下,MongoDB不会启用鉴权,以鉴权模式启动MongoDB
mongod -f /mongodb/conf/mongo.conf --auth
启用鉴权之后,连接MongoDB的相关操作都需要提供身份认证。
mongo 127.0.0.1:27017 -u nanmian -p nanmian --authenticationDatabase=admin


3. 文档操作
3.1 插入
在MongoDB中,最常用的插入语法为insert()和save(),除此之外,3.2版本新增了db.collection.insertOne() 和 db.collection.insertMany()。不过insert()已涵盖这两个指令的功能。
3.2 练习



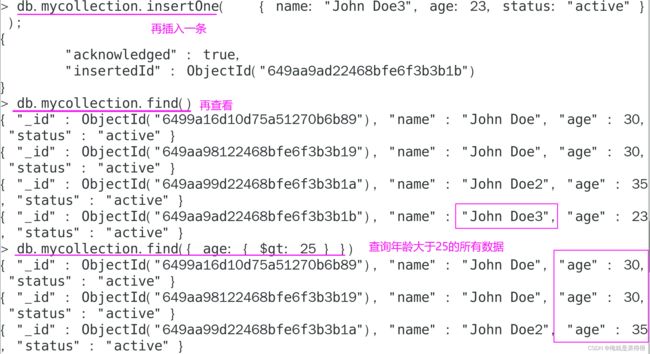

这个命令使用 db.collection.update() 函数更新了 age 字段的值为 30 的文档,并添加了一个新的 phone 字段。具体来说,命令使用了以下参数:
{age:30}用于指定更新的文档。在这个命令中,我们使用了{age:30}查询条件,选择了所有age字段的值为 30 的文档。{ $set: {phone:"159941687971"}}用于指定更新的操作。在这个命令中,我们使用了$set操作符,将phone字段的值设置为 “159941687971”。
执行命令后,MongoDB 返回了nMatched、nUpserted和nModified三个属性。其中,nMatched表示查找到的文档数量,nUpserted表示插入的文档数量,nModified表示更新的文档数量。
在执行命令后,可以使用db.collection.find()函数来检查更新后的文档。在这个例子中,经过更新后,mycollection集合中第一个文档的内容变为:
{
"_id": ObjectId("6499a16d10d75a51270b6b89"),
"name": "John Doe",
"age": 30,
"status": "active",
"email": "[email protected]",
"phone": "159941687971"
}
可以看到,新的 phone 字段已经被添加到了文档中。
下面还有一个age为30的文档,为什么没有更新?
这是因为在 MongoDB 中,db.collection.update() 函数默认只会更新一条匹配的文档。如果要更新多条文档,需要使用 {multi: true} 选项。
例如,如果要更新 age 字段的值为 30 的所有文档,并添加一个新的 phone 字段,可以使用以下命令:
db.mycollection.update({age:30},{$set:{phone:"159941687971"}}, {multi:true})
这个命令使用 {multi: true} 选项,将会更新所有 age 字段的值为 30 的文档,并添加一个新的 phone 字段。

update命令的选项配置较多
- updateOne:更新单个文档
- updateMany:更新多个文档
- replaceOne:替换单个文档
upsert
upsert是一种特殊的更新,其表现为如果目标文档不存在,则执行插入命令。
nMatched、nModified都为0,表示没有文档被匹配及更新,nUpserted=1提示执行了upsert动作

replace语义
update命令中的更新描述(update)通常由操作符描述,如果更新描述中不包含任何操作符,那么MongoDB会实现文档的replace语义

findAndModify命令
findAndModify兼容了查询和修改指定文档的功能,findAndModify只能更新单个文档
//将mycollection文档的年龄加1
db.mycollection.findAndModify({
query:{_id:ObjectId("6499a16d10d75a51270b6b89")},
update:{$inc:{age:1}}
})


默认情况下,findAndModify会返回修改前的“旧"数据。如果希望返回修改后的数据,则可以指定new选项
findAndModify语义相近的命令如下:
- findOneAndUpdate:更新单个文档并返回更新前或更新后)的文档。
- findOneAndReplace:替换单个文档并返回替换前(或替换后)的文档。
3.3 删除文档
使用remove删除文档
- remove命令需要配合查询条件使用;
- 匹配查询条件的文档会被删除;
- 指定一个空文档条件会删除所有文档;
示例:
db.user.remove({age : 28})//删除age等于28的记录
db.user.remove({age: {$lt:25]})//删除age 小于25的记录
db.user.remove({})//删除所有记录
db.user.remove()//报错
remove命令会删除匹配条件的全部文档,如果希望明确限定只删除一个文档,则需要指定justOne参数,命令格式如下:
db.collection . remove(query , justOne)
例如:删除满足type:novel条件的首条记录
db.books.remove( {type : "novel" },true)
使用delete删除文档
官方推荐使用deleteOne()和deleteMany()方法删除文档,语法格式如下:
db.books.deleteMany (0)//删除集合下全部文档
db.books.deleteMany ({ type : "novel" })//删除 type等于 novel 的全部文档
db. books.deleteOne ({ type : "novel" })//删除 type等于novel的一个文档
注意: remove、deleteMany等命令需要对查询范围内的文档逐个删除,如果希望删除整个集合,则使用drop命令会更加高效
返回被删除文档
remove、deleteOne等命令在删除文档后只会返回确认性的信息,如果希望获得被删除的文档,则可以使用findOneAndDelete命令
db.books.findOneAndDelete({type : "novel"})
除了在结果中返回删除文档,findOneAndDelete命令还允许定义“删除的顺序",即按照指定顺序删除找到的第一个文档
db.books.findOneAndDelete({type : "novel"], {sort:{favCount:1}})
remove、deleteOne等命令只能按默认顺序删除,利用这个特性,findOneAndDelete可以实现队列的先进先出。
文档操作最佳时间
关于文档结构
- 防止使用太长的字段名(浪费空间)
- 防止使用太深的数组嵌套(超过2层操作比较复杂)
- 不使用中文,标点符号等非拉丁字母作为字段名
关于写操作
- update语句里只包括需要更新的字段
- 尽可能使用批量插入来提升写入性能
- 使用TTL自动过期日志类型的数据
4. MongoDB数据模型
思考:MongoDB为什么会使用BSON?
4.1 BSON协议与数据类型
JSON
JSON是当今非常通用的一种跨语言Web数据交互格式,属于ECMAScript标准规范的一个子集。JSON (JavaScript Object Notation, JS对象简谱)即JavaScript对象表示法,它是JavaScript对象的一种文本表现形式。
作为一种轻量级的数据交换格式,JSON的可读性非常好,而且非常便于系统生成和解析,这些优势也让它逐渐取代了XML标准在Web领域的地位,当今许多流行的Web应用开发框架,如SpringBoot都选择了JSON作为默认的数据编/解码格式。
JSON只定义了6种数据类型:
- string:字符串
- number:数值
- object: JS的对象形式,用{key:value}表示,可嵌套
- array:数组,JS的表示方式[value],可嵌套
- true/false:布尔类型
- null:空值
大多数情况下,使用JSON作为数据交互格式已经是理想的选择,但是JSON基于文本的解析效率并不是最好的,在某些场景下往往会考虑选择更合适的编/解码格式,一些做法如:
- 在微服务架构中,使用gRPC(基于Google的Protobuf)可以获得更好的网络利用率。
- 分布式中间件、数据库,使用私有定制的TCP数据包格式来提供高性能、低延时的计算能力。
BSON
BSON由10gen团队设计并开源,目前主要用于MongoDB数据库。BSON (Binary JSON)是二进制版本的JSON,其在性能方面有更优的表现。BSON在许多方面和JSON保持一致,其同样也支持内嵌的文档对象和数组结构。二者最大的区别在于JSON是基于文本的,而BSON则是二进制((字节流)编/解码的形式。在空间的使用上,BSON相比JSON并没有明显的优势。
MongoDB在文档存储、命令协议上都采用了BSON作为编/解码格式,主要具有如下优势:
- 类JSON的轻量级语义,支持简单清晰的嵌套、数组层次结构,可以实现模式灵活的文档结构。
- 更高效的遍历,BSON在编码时会记录每个元素的长度,可以直接通过seek操作进行元素的内容读取,相对JSON解析来说,遍历速度更快。
- 更丰富的数据类型,除了JSON的基本数据类型,BSON还提供了MongoDB所需的一些扩展类型,比如日期、二进制数据等,这更加方便数据的表示和操作。
BSON的数据类型
MongoDB中,一个BSON文档最大大小为16M,文档嵌套的级别不超过100
https://docs.mongodb.com/v4.4/reference/bson-types/
| Type | Number | Alias | Notes |
|---|---|---|---|
| Double | 1 | “double” | |
| String | 2 | “string” | |
| object | 3 | “object” | |
| Array | 4 | “array” | |
| Binary data | 5 | “binData” | 二进制数据 |
| Undefined | 6 | “undefined” | Deprecated. |
| Objectld | 7 | “objectld” | 对象ID,用于创建文档ID |
| Boolean | 8 | “bool” | |
| Date | 9 | “date” | |
| Null | 10 | “null” | |
| Regular Expression | 11 | “regex” | 正则表达式 |
| DBPointer | 12 | “dbPointer” | Deprecated. |
| JavaScript | 13 | “javascript” | |
| Symbol | 14 | “symbol” | Deprecated. |
| JavaScript code with scope | 15 | “javascriptWVithScope” | Deprecated in MongoDB 4.4. |
| 32-bit integer | 16 | “int” | |
| Timestamp | 17 | “timestamp” | |
| 64-bit integer | 18 | “long” | |
| Decimal128 | 19 | “decimal” | New in version 3.4. |
| Min key | -1 | “minKey” | 表示一个最小值 |
| Max key | 127 | “maxKey” | 表示一个最大值 |
$type操作符
$type操作符基于BSON类型来检索集合中匹配的数据类型,并返回结果。
db.books.find( { "title": {$type : 2}}) //或者
db. books.find({"title" : {$type : "string"}})

4.2 日期类型
MongoDB的日期类型使用UTC(Coordinated Universal Time)进行存储,也就是+0时区的时间。
db.dates.insert([{data1:Date()},{data2:new Date(),data3:ISODate()}])
db.dates.find().pretty()
使用new Date与ISODate最终都会生成ISODate类型的字段(对应于UTC时间)

4.3 ObjectId生成器
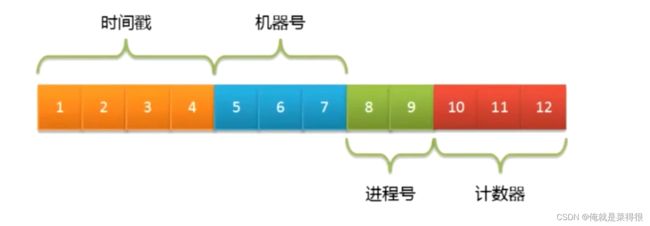
MongoDB集合中所有的文档都有一个唯一的_id字段,作为集合的主键。在默认情况下,_id字段使用Objectld类型,采用16进制编码形式,共12个字节。
为了避免文档的_id字段出现重复,Objectld被定义为3个部分:
- 4字节表示Unix时间戳(秒)。
- 5字节表示随机数(机器号+进程号唯一)。·
- 3字节表示计数器(初始化时随机)。
大多数客户端驱动都会自行生成这个字段,比如MongoDB Java Driver会根据插入的文档是否包含_id字段来自动补充Objectld对象。这样做不但提高了离散性,还可以降低MongoDB服务器端的计算压力。在Objectld的组成中,5字节的随机数并没有明确定义,客户端可以采用机器号、进程号来实现:
| 属性/方法 | 描述 |
|---|---|
| str | 返回对象的十六进制字符串表示。 |
| 0bjectId.getTimestamp() | 将对象的时间戳部分作为日期返回。 |
| 0bjectld.toString() | 以字符串文字""的形式返回JavaScript表示0bjectId(…)。 |
| 0bjectId.valueOf() | 将对象的表示形式返回为十六进制字符串。返回的字符串是str属性。 |
生成一个新的ObjectId
x=objectId()

4.4 内嵌文档和数组
内嵌文档
一个文档中可以包含作者的信息,包括作者名称、性别、家乡所在地,一个显著的优点是,当我们查询book文档的信息时,作者的信息也会一并返回。
db.books.insert({
title: "撒哈拉的故事",
author: {
name : "三毛",
gender:"女",
hometown :"重庆"
}
})

查询三毛的作品
db.books.find({"author.name":"三毛"})
![]()
修改三毛的家乡所在地
db.books.updateOne({"author.name":"三毛"},{$set:{"author.hometown":"重庆/台湾"}})

数组
除了作者信息,文档中还包含了若干个标签,这些标签可以用来表示文档所包含的一些特征,如豆瓣读书中的标签(tag)
豆瓣成员常用的标签(共2202个)··
三毛、撒哈拉的故事、旅行、随笔、散文、爱情、文学、台湾
增加tags标签

如果想按照tags查询:

如果只想显示两列:
![]()
如果只想显示tags里面的某几个,可以使用切片

数组末尾追加元素,可以使用$push操作符
db.books.updateOne({"author.name":"三毛"},{$push: {tags :"猎奇"}})

$push操作符可以配合其他操作符,一起实现不同的数组修改操作,比如和$each操作符配合可以用于添加多个元素
db.books.updateOne(
{"author.name":"三毛"},
{$push:{tags:{ $each:["伤感", "想象力","厉害"]}}}
)

如果加上$slice操作符,那么只会保留经过切片后的元素
db.books.updateOne(
{ "author.name":"三毛" },
{ $push: { tags: { $each:["伤感", "想象力", "厉害"] } } }
)
根据元素查询
#会查出所有包含伤感的文档
db.books.find( {tags:"伤感"})
#会查出所有同时包含"伤感","想象力"的文档
db.books.find({tags:{$all:["伤感","想象力"]}})
嵌套型的数组
数组元素可以是基本类型,也可以是内嵌的文档结构
{
tags :[
{tagKey : xxx,tagValue : xx××},
{tagKey : xxx,tagValue : xxxX}
]
}
这种结构非常灵活,一个很适合的场景就是商品的多属性表示
一个商品可以同时包含多个维度的属性,比如尺码、颜色、风格等,使用文档可以表示为:
db.goods.insertMany([
{
name: "羽绒服",
tags: [
{ tagKey: "size", tagValue: ["M", "L", "XL", "XXL", "XXXL"] },
{ tagKey: "color", tagValue: ["黑色", "宝蓝"] },
{ tagKey: "style", tagValue: ["韩风"] }
]
},
{
name: "羊毛衫",
tags: [
{ tagKey: "size", tagValue: ["L", "XL", "XXL"] },
{ tagKey: "color", tagValue: ["蓝色", "杏色"] },
{ tagKey: "style", tagValue: ["韩风"] }
]
}
])


以上的设计是一种常见的多值属性的做法,当我们需要根据属性进行检索时,需要用到$elementMatch操作符:
#筛选出color=黑色的商品信息
db.goods.find({
tags: {
$elemMatch: {
tagKey: "color",
tagValue: "黑色"
}
}
})

如果进行组合式的条件检索,则可以使用多个$elemMatch操作符:
#筛选出color=蓝色,并且size=XL的商品信息
db.goods.find({
tags:{
$all:[
{$elemMatch:{tagKey:"color",tagValue:"黑色"}},
{$elemMatch:{tagKey:"size",tagValue:"XL"}}
]
}
})

4.5 固定集合
固定集合(capped collection)是一种限定大小的集合,其中capped是覆盖、限额的意思。跟普通的集合相比,数据在写入这种集合时遵循FIFO原则。可以将这种集合想象为一个环状的队列,新文档在写入时会被插入队列的末尾,如果队列已满,那么之前的文档就会被新写入的文档所覆盖。通过固定集合的大小,我们可以保证数据库只会存储“限额"的数据,超过该限额的旧数据都会被丢弃。

使用示例
创建固定集合
db.createCollection("logs", { capped: true, size: 4096, max: 10 })
- max:指集合的文档数量最大值,这里是10条
- size:指集合的空间占用最大值,这里是4096字节(4KB)
![]()
这两个参数会同时对集合的上限产生影响。也就是说,只要任一条件达到阈值都会认为集合已经写满。其中size是必选的,而max则是可选的。
可以使用collection.stats命令查看文档的占用空间
db.logs.stats()

测试
尝试在这个集合中插入15条数据,再查询会发现,由于文档数量上限被设定为10条,前面插入的5条数据已经被覆盖了
for(var i=0 ; i<15 ; i++){
db.logs.insert({t : "row- "+i} )
}

优势与限制
固定集合在底层使用的是顺序IO操作,而普通集合使用的是随机I/O。顺序I/O在磁盘操作上由于寻道次数少而比随机I/O要高效得多,因此固定集合的写入性能是很高的。此外,如果按写入顺序进行数据读取,也会获得非常好的性能表现。
但它也存在一些限制,主要有如下5个方面:
无法动态修改存储的上限,如果需要修改max或size,则只能先执行collection.drop命令,将集合删除后再重新创建。无法删除已有的数据,对固定集合中的数据进行删除将会得到如下错误:

- 对已有数据进行修改,新文档大小必须与原来的文档大小一致,否则不允许更新:

![]()
- 默认情况下,I固定集合只有一个_id索引,而且最好是按数据写入的顺序进行读取。当然,也可以添加新的索引,但这会降低数据写入的性能。
- 固定集合不支持分片,同时,在MongoDB4.2版本中规定了事务中也无法对固定集合执行写操作。
适用场景
固定集合很适合用来存储一些"临时态"的数据。“临时态"意味着数据在一定程度上可以被丢弃。同时,用户还应该更关注最新的数据,随着时间的推移,数据的重要性逐渐降低,直至被淘汰处理。
一些适用的场景如下:
- 系统日志,这非常符合固定集合的特征,而日志系统通常也只需要一个固定的空间来存放日志。在MongoDB内部,副本集的同步日志(oplog)就使用了固定集合。
- 存储少量文档,如最新发布的TopN条文章信息。得益于内部缓存的作用,对于这种少量文档的查询是非常高效的。
使用固定集合实现FIFO队列
在股票实时系统中,大家往往最关心股票价格的变动。而应用系统中也需要根据这些实时的变化数据来分析当前的行情。倘若将股票的价格变化看作是一个事件,而股票交易所则是价格变动事件的"发布者",股票APP、应用系统则是事件的“消费者"。这样,我们就可以将股票价格的发布、通知抽象为一种数据的消费行为,此时往往需要一个消息队列来实现该需求。
结合业务场景:利用固定集合实现存储股票价格变动信息的消息队列
- 创建stock_queue消息队列,其可以容纳10MB的数据
db.createCollection( "stock_queue" , {capped : true,size:10485760})

- 定义消息格式
{
timestamped : new Date(),
stock : "MongoDB Inc",
price: 20.33
}
- timestamp指股票动态消息的产生时间。
- stock指股票的名称。
- price指股票的价格,是一个Double类型的字段。
为了能支持按时间条件进行快速的检索,比如查询某个时间点之后的数据,可以为timestamp添加索引
db.stock_queue.createIndex({timestamped: 1})

3.构建生产者,发布股票动态
模拟股票的实时变动
function pushEvent(){
while(true){
db.stock_queue.insert( {
timestamped : new Date( ),
stock: "MongoDB Inc",
price: 100*Math.random (1000)
});
print ( "publish stock changed");
sleep( 1000 ) ;
}
}
执行pushEvent函数,此时客户端会每隔1秒向stock_queue中写入一条股票信息
pushEvent()

- 构建消费者,监听股票动态
对于消费方来说,更关心的是最新数据,同时还应该保持持续进行“拉取",以便知晓实时发生的变化。根据这样的逻辑,可以实现一个listen函数
function listen() {
var cursor = db.stock_queue.find({ timestamped: { $gte: new Date() } }).tail();
while (true) {
if (cursor.hasNext()) {
print(JSON.stringify(cursor.next(), null, 2));
}
sleep(1000);
}
}
find操作的查询条件被指定为仅查询比当前时间更新的数据,而由于采用了读取游标的方式,因此游标在获取不到数据时并不会被关闭,这种行为非常类似于Linux中的tail-f命令。在一个循环中会定时检查是否有新的数据产生,一旦发现新的数据(cursor.hasNext()=true),则直接将数据打印到控制台。
执行这个监听函数,就可以看到实时发布的股票信息
listen()

5. WiredTiger读写模型详解
5.1 WiredTiger介绍
MongoDB从3.0开始引入可插拔存储引擎的概念。目前主要有MMAPV1、WiredTiger存储引擎可供选择。在3.2版本之前MMAPV1是默认的存储引擎,其采用linux操作系统内存映射技术,但一直饱受诟病;3.4以上版本默认的存储引擎是wiredTiger,相对于MMAPV1其有如下优势:
- 读写操作性能更好,WiredTiger能更好的发挥多核系统的处理能力;
- MMAPV1引擎使用表级锁,当某个单表上有并发的操作,吞吐将受到限制。WiredTiger使用文档级锁,由此带来并发及吞吐的提高
- 相比MMAPV1存储索引时WiredTiger使用前缀压缩,更节省对内存空间的损耗;
- 提供压缩算法,可以大大降低对硬盘资源的消耗,节省约60%以上的硬盘资源;
5.2 WiredTiger读写模型
读缓存
理想情况下,MongoDB可以提供近似内存式的读写性能。Wired Tiger引擎实现了数据的二级缓存,第一层是操作系统的页面缓存,第二层则是引擎提供的内部缓存。

读写数据时的流程如下:
- 数据库发起Buffer l/O读操作,由操作系统将磁盘数据页加载到文件系统的页缓存区。
- 引擎层读取页缓存区的数据,进行解压后存放到内部缓存区。
- 在内存中完成匹配查询,将结果返回给应用。
MongoDB为了尽可能保证业务查询的“热数据"能快速被访问,其内部缓存的默认大小达到了内存的一半,该值由wiredTigerCacheSize参数指定,其默认的计算公式如下:
wiredTigerCacheSize=Math.max((RAM/2-1GB),256MB)
MongoDB是B树的变种,B+树
MongoDB底层使用的是B+树来实现数据的存储和索引。B+树是一种常用的树状数据结构,它支持高效地插入、删除和查找操作,同时还能保持数据的有序性,使得范围查询等操作变得更加高效。B+树还具有较好的局部性原理,能够很好地适应现代计算机存储结构。 在MongoDB中,每个集合都对应一个B+树索引,用于支持集合的查询操作。在查询过程中,MongoDB会使用B+树索引来高效地定位符合查询条件的文档,并返回查询结果。B+树索引的使用使得MongoDB在处理大量数据时仍能够保持良好的查询性能和响应速度。
MySQL底层使用的是B+树来实现数据的存储和索引。B+树是一种高效的数据结构,它支持高效地插入、删除和查找操作,同时还能保持数据的有序性,使得范围查询等操作变得更加高效。B+树还具有较好的局部性原理,能够很好地适应现代计算机存储结构。 在MySQL中,每个索引都对应一棵B+树,用于支持表的查询操作。在查询过程中,MySQL会使用B+树索引来高效地定位符合查询条件的行,并返回查询结果。B+树索引的使用使得MySQL在处理大量数据时仍能够保持良好的查询性能和响应速度。
写缓存
当数据发生写入时,MongoDB并不会立即持久化到磁盘上,而是先在内存中记录这些变更,之后通过CheckPoint机制将变化的数据写入磁盘。为什么要这么处理?主要有以下两个原因:
- 如果每次写入都触发一次磁盘I/O,那么开销太大,而且响应时延会比较大。
- 多个变更的写入可以尽可能进行IO合并,降低资源负荷。
思考: MongoDB会丢数据吗?
MongoDB单机下保证数据可靠性的机制包括以下两个部分:
checkPoint(检查点)机制
快照(snapshot))描述了某一时刻(point-in-time)数据在内存中的一致性视图,而这种数据的一致性是WiredTiger通过MVCC(多版本并发控制)实现的。当建立CheckPoint时,WiredTiger会在内存中建立所有数据的一致性快照,并将该快照覆盖的所有数据变化一并进行持久化((fsync)。成功之后,内存中数据的修改才得以真正保存。默认情况下,MongoDB每60s建立一次CheckPoint,在检查点写入过程中,上一个检查点仍然是可用的。这样可以保证一旦出错,MongoDB仍然能恢复到上一个检查点。
Journal日志
Journal是一种预写式日志 (write ahead log)机制,主要用来弥补CheckPoint机制的不足。如果开启了Journal日志,那么Wired Tiger会将每个写操作的redo日志写入Journal缓冲区,该缓冲区会频繁地将日志持久化到磁盘上。默认情况下,Journal缓冲区每100ms执行一次持久化。此外,Journal日志达到100MB,或是应用程序指定journal: true,写操作都会触发日志的持久化。一旦MongoDB发生宕机,重启程序时会先恢复到上一个检查点,然后根据Journal日志恢复增量的变化。由于Journal日志持久化的间隔非常短,数据能得到更高的保障,如果按照当前版本的默认配置,则其在断电情况下最多会丢失100ms的写入数据。

WiredTiger写入数据的流程:
- 应用向MongoDB写入数据(插入、修改或删除)。
- 数据库从内部缓存中获取当前记录所在的页块,如果不存在则会从磁盘中加载(Buffer lO)
- WiredTiger开始执行写事务,修改的数据写入页块的一个更新记录表,此时原来的记录仍然保持不变。
- 如果开启了Journal日志,则在写数据的同时会写入条Journal日志(Redo Log)。该日志在最长不超过100ms之后写入磁盘
- 数据库每隔60s执行一次CheckPoint操作,此时内存中的修改会真正刷入磁盘。
Journal日志的刷新周期可以通过参数storage.journal.commitIntervalMs指定,MongoDB 3.4及以下版本的默认值是50ms,而3.6版本之后调整到了100ms。由于Journal日志采用的是顺序/O写操作,频繁地写入对磁盘的影响并不是很大。
CheckPoint的刷新周期可以调整storage.syncPeriodSecs参数(默认值60s),在MongoDB 3.4及以下版本中,当Journal日志达到2GB时同样会触发CheckPoint行为。如果应用存在大量随机写入,则CheckPoint可能会造成磁盘VO的抖动。在磁盘性能不足的情况下,问题会更加显著,此时适当缩短CheckPoint周期可以让写入平滑一些。