FLink学习笔记:10-Flink 的状态一致性与容错机制
文章目录
- 一致性级别
- 端到端(end-to-end)状态一致性
-
- Sink端实现方式
-
- 幂等写入
- 事务性(Transactional)写入
- 不同Source和Sink的一致性保证
- Flink Checkpoint
-
- Flink的checkpoint的生成算法图解
- Savepoints
- Flink开启checkpoint的API操作
-
- FLink的状态后端
-
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
一致性级别
在流处理中,一致性可以分为如下3个级别:
- at-most-once:这种级别是正确性最没有保障的,故障发生后,结果有可能丢失
- at-least-once:这表示计数结果至少被计算一次,有可能多算,但是绝对不可能少算。
- exactly-once:系统保证在发生故障恢复后得到的计算结果与正确值完全一致。
端到端(end-to-end)状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是在Flink的内部保证的;然后在实际的应用中,流处理应用除了流处理器以外还包含了数据源和输出到持久化系统。

端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的链条,每一个组件都保证了自己的一致性,整个端到端的一致性级别取决于所有组件中的一致性最弱的组件。具体可以划分为:
- Flink内部保证:依赖checkpoint机制
- Source端:需要外部数据源支持数据的重放,保证故障发生时数据不会缺失
- Sink端:需要保证故障恢复时,结果不会重复写入。
Sink端实现方式
对于Sink端的实现,有两种具体的方式:
幂等写入
幂等写入指的是一个操作可以重复的执行多次,但是只导致一次结果更改,也就是说后面重复执行就不起作用了。比如HTTP中的DELETE方法,执行一次或者多次导致的结果都一样,即需要被删除的对象被删除。
具有幂等操作的SINK端组件有Redis,ElasticSearch,Mongodb等等。
事务性(Transactional)写入
需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。
对于事务性写入,具体又有两种实现方式:
- 预写日志(WAL)
预写日志:先将结果缓存起来,等到checkpoint完成后一次性写入到外部的Sink组件中,缺点就是效率比较低。数据量大时,写入到外部系统需要一定的时间,从而导致一定的延迟。
- 两阶段提交 (2PC)。
两阶段提交指的是,对于每一个checkpoint,Sink任务会开启一个事务,结果实时的更新到外部的Sink组件中,但是不提交事务,对于外部用户是不可见的;等到checkpoint完成后,再提交事务,从而大大提升数据的写入效率。
DataStream API 提供了 GenericWriteAheadSink 模板类和 TwoPhaseCommitSinkFunction 接口,可以方便地实现这两种方式的事务性写入。
不同Source和Sink的一致性保证

Flink Checkpoint
- Flink故障恢复机制的核心就是应用状态的一致性检查点。
- 有状态流应用的一致检查点,其实就是所有任务的状态,在某一个时间点的一份快照;这个时间点应该是所有任务都恰好处理完成一个相同的数据输入数据的时候。
假如我们有一个任务,需要统计奇数偶数求和。Flink从Kafka中读取数据对奇数和偶数分别求和操作,将操作结果写入到Sink中。其中source任务,算子任务以及Sink任务的并行度都是2,如下图所示:

那么我们应该怎样保存checkpoint呢?最直观的方式,我们可能想到的就是暂停所有的任务操作,生成一个快照,将当前所有任务的状态保存起来。
如下图所示,checkpoint中保存的内容如下:

如上图所示:此时Source1任务的保存的偏移量是3,source2任务的偏移量也是3,Source1中的数据2正在发送给下游的偶数求和任务,数据3正在发送给奇数求和的任务,此时都还没有完成求和计算;Source2中的数据1和3正在发送给奇数求和的任务。如果暂停所有任务,保存当前所有任务的快照,那么存放到checkpoint中的数据就如图中所示,任务1中的Sourcestate是3,KeyedState是1;任务2中的SourceState是3,KeyedState是2。假如此时系统崩溃,需要重启恢复,那么从checkpoint中读取到的数据是[3、1]和[3、2]

此时Source1接下来从数据源中读取的数据是4,Source2任务读取的也是4,然后进行求和运算,这时我们就会发现,之前未处理完的数据被丢失了,导致结果计算错误。
那么如何避免这一错误的产生呢?我们首先想到的就是保存更多的信息,Flink的source任务保存当前的偏移量,以及每一个数据的处理状态,这样理论上来说确实是可以实现的,但是有一个缺陷就是需要保存的庞大的信息,这样对于Flink的性能来说也有非常大的影响。
所以Flink生成checkpoint的时间点应当恰好是所有任务都处理完一个相同的数据输入的时候。也就是说,如果上述任务source1和source2从数据源获取数据3完毕,偶数求和将source1发送的数据2处理完毕,奇数求和任务计算完source1发送的数据3和source2发送的数据1和3,也就以为着下游所有的任务都处理完毕了偏移量是3以前的数据。这个时间点所有的任务链的状态恰好都能保持同步。如下图所示:

如上图所示,如果系统这时发生故障,从checkpooint恢复的时候,只需要从checkpoint读取各自的状态值,就可以恢复到故障之前的处理状态,所有的数据都能够像故障发生前一样被正确的处理。为了实现这一目标,Flink引入了barriers机制。
Flink的checkpoint的生成算法图解
- 1、Jobmanager周期性的向每个source任务发送一条带有新检查点ID的指令,通过这种方式来启动检查点。
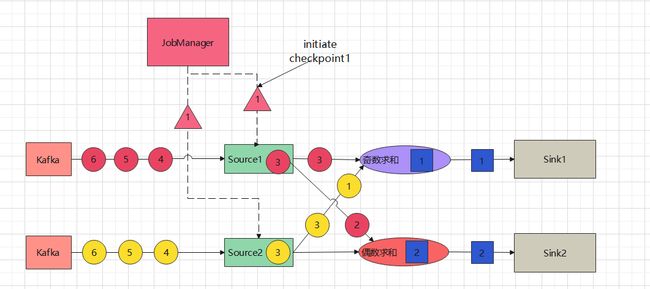
-
2、Source任务收到指令后将他们的状态(偏移量)写入到checkpoint,并向下游发出一个检查点barrier,这些barrier附加在数据之后发送给下游任务,如图中的三角形
-
3、状态后端在source任务的状态存入到checkpoint后,会通知source任务,source任务就会向jobmananger报告检查点已完成,此时source任务的checkpoint指令完成
-
4、下游任务在收到barrier之前,不需要暂停,继续做自己的任务,如奇数求和任务完成了对source1发来数据3的计算,偶数求和任务完成了source1发来的数据2的运算。

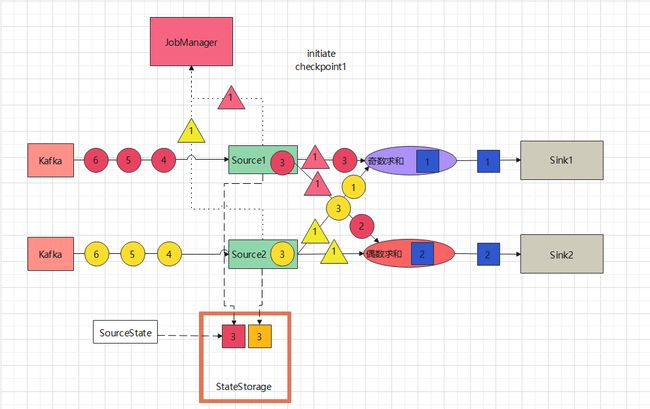
-
5、偶数求和任务收到了source1和source2发来的barrier后,说明在checkpoint点之前的数据都已经处理完毕,于是将自己的状态“4”写入到statestorge中。收到statestorage写入成功的确认信息后向jobManager报告checkpoint已完成。并向下游发送一条barrier数据,通知下游写checkpoint操作。
-
6、而这时奇数求和任务只是收到了source1发送过来的barrier,说明source1的checkpoint之前的数据全部处理完毕,这时候只能等待source2发送过来的barrier,不再处理source1发送过来的数据

- 7、奇数计算求和任务继续处理source2发送过来的数据1,并完成计算;偶数求和任务可以不受影响的继续处理source1和source2发送过来的数据;source1和source2任务可以继续从数据源读取数据

- 8、奇数计算求和任务继续处理source2发送过来的数据3、并完成计算;偶数求和任务继续计算source1和source2发送过来的数据4,并完成计算;相互之间并行且互不影响;source1和source2继续从数据源读取数据;只是奇数求和计算任务不再处理从source1发送过来的数据。求和计算任务计算完毕后,将计算结果写入到下游的Sink,注意此时只是预写入,并未提交事务。(两阶段提交 (2PC)。)

- 9、奇数计算任务收到了source2发送过来的barrier后,触发写checkpoint操作,将自己的状态8写入到Statestorage中,收到写成功的确认后,向Jobmanager报告自己的checkpoint已经写入完毕。
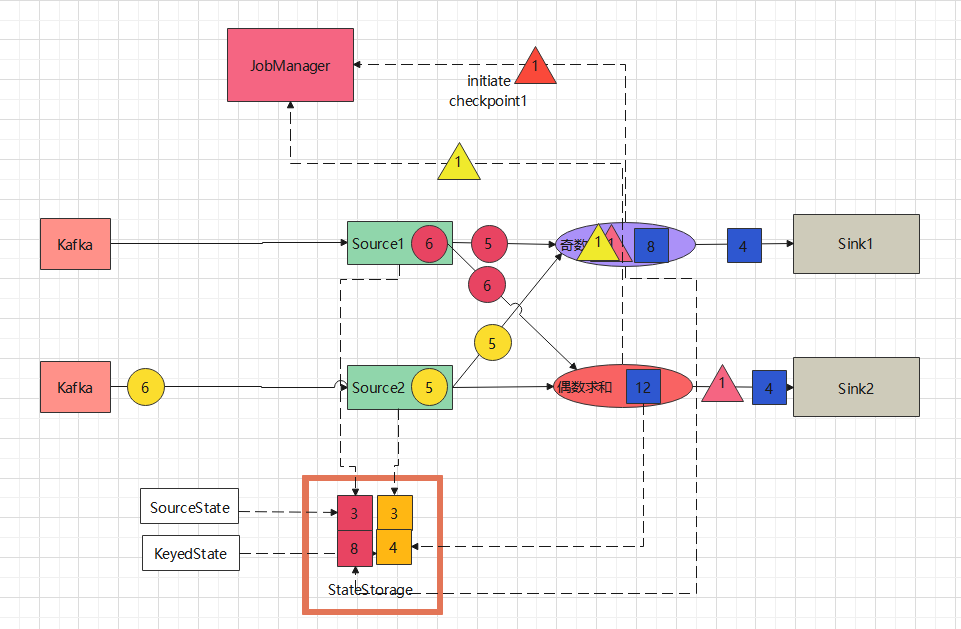
-
10、奇数计算任务确认checkpoint写完毕后,向下游发送一条barrier,通知下游写checkpoint操作。

-
11、Sink2收到偶数求和任务发送过来的barrier后,触发写checkpoint操作,将自己的状态4写入到stateStorage中,收到写入成功的确认后,想Jobmanager报告自己的checkpoint已经写入完毕,同时向外部Sink组件提交事务,数据真正写入到外部Sink组件
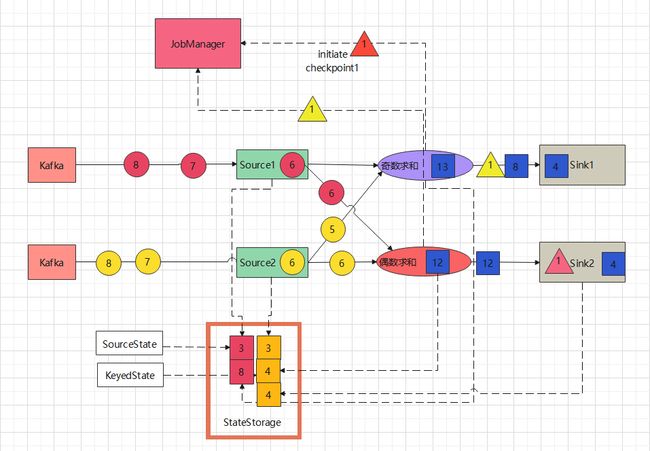
-
12、Sink1预写入数据8到外部系统后收到了奇数求和任务发送过来的barrier,触发checkpoint写机制,将自己的状态8写入到stateStorage中,收到写入成功的确认后,向Jobmanager报告自己的checkpoint已经写入完毕,同时向外部Sink组件提交事务,数据真正写入到外部Sink组件

- 13、至此整个ID为1的checkpoint写入全部完毕,所有任务继续执行,直至Jobmanager发出下一个checkpoint的写入指令。
由以上整个图解过程中我们不难发现,Flink采用的这种checkpoint算法机制的效率远远高于暂停任务写checkpoint的方式,这种方式也更加合理高效,能够保持结果的正确性。从而达到exactly-once这一目标。
Savepoints
- Flink 还提供了可以自定义的镜像保存功能,就是保存点(savepoints)
- 原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认 为就是具有一些额外元数据的检查点
- Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地 触发创建操作
- 保存点是一个强大的功能。除了故障恢复外,保存点可以用于:有计划 的手动备份,更新应用程序,版本迁移,暂停和重启应用,等等
Flink开启checkpoint的API操作
checkpoint默认是不开启的,由程序员在代码中显式开启
常见操作代码如下:
package com.hjt.yxh.hw.checkpoint
import java.util.concurrent.TimeUnit
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.runtime.state.memory.MemoryStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.common.time.Time
object CheckPointTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new MemoryStateBackend())
//JobManager 给Source发送barrier的周期
env.enableCheckpointing(600L, CheckpointingMode.AT_LEAST_ONCE)
env.getCheckpointConfig.setCheckpointingMode(
CheckpointingMode.AT_LEAST_ONCE)
env.getConfig.setAutoWatermarkInterval(500L)
env.getCheckpointConfig.setCheckpointTimeout(60000L)
//最大的并行的checkpoint,默认是1个
env.getCheckpointConfig.setMaxConcurrentCheckpoints(2)
//两次checkpoint之间的最小的间歇时间
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500L)
//至少容忍多少次checkpoint失败
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(3)
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,10000L))
env.setRestartStrategy(RestartStrategies.failureRateRestart(5,Time.of(5,TimeUnit.SECONDS),Time.of(10,TimeUnit.SECONDS)))
}
}
FLink的状态后端
MemoryStateBackend
内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储 在 TaskManager 的 JVM 堆上;而将 checkpoint 存储在 JobManager 的内存中。
- 代码:
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new MemoryStateBackend())
FsStateBackend
将 checkpoint 存到远程的持久化文件系统(FileSystem)上。而对于本地状态, 跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上
- 代码:
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new FsStateBackend("file:///tmp/checkpoints"))
RocksDBStateBackend
将所有状态序列化后,存入本地的 RocksDB 中存储。 注意:RocksDB 的支持并不直接包含在 flink 中,需要引入依赖:
- 依赖:
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-statebackend-rocksdb_2.12artifactId>
<version>1.10.1version>
dependency>
- 代码:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val checkpointPath: String = ???
val backend = new RocksDBStateBackend(checkpointPath)