6.3 Elasticsearch(三)使用 Kibana 操作 ES
文章目录
- 1.环境准备
-
- 1.1 下载 Kibana 镜像
- 1.2 启动 Kibana 容器
- 1.3 Kibana汉化
- 2.索引、分片和副本
-
- 2.1 索引
- 2.2 索引分片
- 2.3 索引副本
- 2.4 创建索引
- 3.映射(数据结构)
-
- 3.1 字段的数据类型
- 3.2 创建映射
- 3.3 查看映射
- 4.添加文档
- 5.修改文档
-
- 5.1 PUT
- 5.2 POST
- 6.删除
-
- 6.1 删除文档
- 6.1 清空
- 6.2 删除索引
1.环境准备
Kibana 是ES操作的API工具,后续我们使用API操作ES进行增删改查操作,都需要依赖Kibana 进行,否则不会有自动提示等信息;
1.1 下载 Kibana 镜像
docker pull kibana:7.9.3
1.2 启动 Kibana 容器
docker run \
-d \
--name kibana \
--net es-net \
-p 5601:5601 \
-e ELASTICSEARCH_HOSTS='["http://node1:9200","http://node2:9200","http://node3:9200"]' \
--restart=always \
kibana:7.9.3
1.3 Kibana汉化
docker exec -it kibana bash
echo -e "\ni18n.locale: \"zh-CN\"">>/usr/share/kibana/config/kibana.yml
exit
docker restart kibana
启动后,浏览器访问 Kibana,进入 Dev Tools:http://192.168.64.181:5601/:
- 如果显示not ready 需要等待一会刷新再次进入
- 如果等待很久,刷新都无法进入,那么hend插件,删除所有
.kibana开头的索引,并重启kibana,再次访问

2.索引、分片和副本
2.1 索引
Elasticsearch索引用来存储我们要搜索的数据,以倒排索引结构进行存储。
例如,要搜索商品数据,可以创建一个商品数据的索引,其中存储着所有商品的数据,供我们进行搜索:
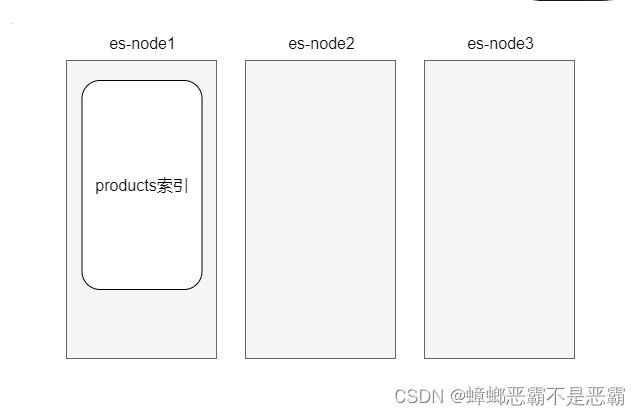
当索引中存储了大量数据时,大量的磁盘io操作会降低整体搜索新能,这时需要对数据进行分片存储。
2.2 索引分片
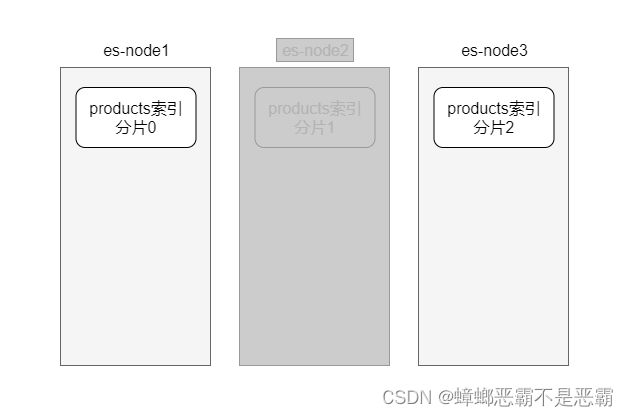
在一个索引中存储大量数据会造成性能下降,这时可以对数据进行分片存储。
每个节点上都创建一个索引分片,把数据分散存放到多个节点的索引分片上,减少每个分片的数据量来提高io性能:

每个分片都是一个独立的索引,数据分散存放在多个分片中,也就是说,每个分片中存储的都是不同的数据。搜索时会同时搜索多个分片,并将搜索结果进行汇总。
如果一个节点宕机分片不可用,则会造成部分数据无法搜索:
为了解决这一问题,可以对分片创建多个副本来解决。
2.3 索引副本
对分片创建多个副本,那么即使一个节点宕机,其他节点中的副本分片还可以继续工作,不会造成数据不可用:
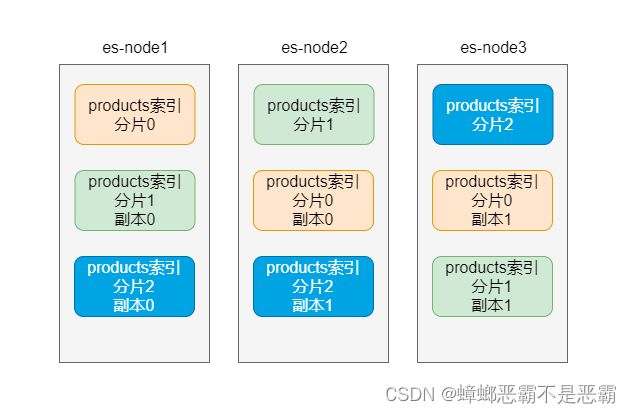
分片的工作机制:
- 主分片的数据会复制到副本分片
- 搜索时,以负载均衡的方式工作,提高处理能力
- 主分片宕机时,其中一个副本分片会自动提升为主分片
下面我们就以上图的结构来创建 products 索引
2.4 创建索引
创建一个名为 products 的索引,用来存储商品数据。
分片和副本参数说明:
number_of_shards:分片数量,默认值是 5number_of_replicas:副本数量,默认值是 1
我们有三个节点,在每个节点上都创建一个分片。每个分片在另两个节点上各创建一个副本。
# 创建索引,命名为 products
PUT /products
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}

用索引名称过滤,查看 products 索引:
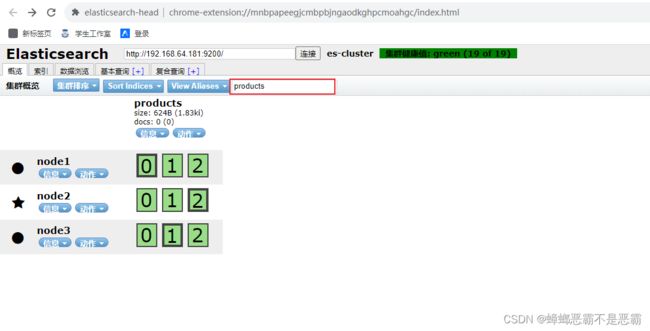
如图所示,粗边框为主分片,细边框为副本分片;当然我们不一定一定使用Kibana去执行,只是使用Kibana完成命令会有相关提示,也可以通过Postman等工具执行http的PUT请求:http://192.64.181:9200/products,以json数据格式发送相关数据即可;
此时,每个服务器下都有1个主分片,2个副分片;同时,0,1,2三个分片,每个分片在三个服务器中也都有1个主分片,2个副分片;
3.映射(数据结构)
类似于数据库表结构,索引数据也被分为多个数据字段,并且需要设置数据类型和其他属性。
映射,是对索引中字段结构的定义和描述。
3.1 字段的数据类型
常用类型:
- 数字类型:
- byte、short、integer、long
- float、double
- unsigned_long:无符号的,只有正数没有负数的长整型;
- 字符串类型:
- text : 只有text类型会进行分词
- keyword : 不会进行分词,适用于email、主机地址、邮编等
- 日期和时间类型:
- date
类型参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
3.2 创建映射
映射指的是映射数据结构,存储数据时,我们需要设置都有哪些字段,并且每个字段都是什么数据类型;我们在 products 索引中创建映射。
分词器设置:
analyzer:文档存储时使用的分词器;在索引中添加文档时,text类型通过指定的分词器分词后,再插入倒排索引;search_analyzer:搜索内容使用的分词器;使用关键词检索时,使用指定的分词器对关键词进行分词;
使用关键词查询时,优先使用 search_analyzer 设置的分词器,如果 search_analyzer 不存在则使用 analyzer 分词器;所以search_analyzer可以不设置,但analyzer必须设置(在text类型下);
# 定义mapping,数据结构
PUT /products/_mapping
{
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"category": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"price": {
"type": "float"
},
"city": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"barcode": {
"type": "keyword"
}
}
}

映射参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html
3.3 查看映射
设置完成后,可以在head插件的索引信息中查看映射关系(注意,head插件不会主动刷新,需要手动刷新查看最新数据):

也可以使用命令GET /products/_mapping查看:

4.添加文档
添加的文档会有一个名为_id的文档id,这个文档id可以自动生成,也可以手动指定,通常可以使用数据的id作为文档id。
# 添加文档
PUT /products/_doc/10033
{
"id":"10033",
"title":"SONOS PLAY:5(gen2) 新一代PLAY:5无线智能音响系统 WiFi音箱家庭,潮酷数码会场",
"category":"潮酷数码会场",
"price":"3980.01",
"city":"上海",
"barcode":"527848718459"
}
PUT /products/_doc/10034
{
"id":"10034",
"title":"天猫魔盒 M13网络电视机顶盒 高清电视盒子wifi 64位硬盘播放器",
"category":"潮酷数码会场",
"price":"398.00",
"city":"浙江杭州",
"barcode":"522994634119"
}
PUT /products/_doc/10035
{
"id":"10035",
"title":"BOSE SoundSport耳塞式运动耳机 重低音入耳式防脱降噪音乐耳机",
"category":"潮酷数码会场",
"price":"860.00",
"city":"浙江杭州",
"barcode":"526558749068"
}
PUT /products/_doc/10036
{
"id":"10036",
"title":"【送支架】Beats studio Wireless 2.0无线蓝牙录音师头戴式耳机",
"category":"潮酷数码会场",
"price":"2889.00",
"city":"上海",
"barcode":"37147009748"
}
PUT /products/_doc/10037
{
"id":"10037",
"title":"SONOS PLAY:1无线智能音响系统 美国原创WiFi连接 家庭桌面音箱",
"category":"潮酷数码会场",
"price":"1580.01",
"city":"上海",
"barcode":"527783392239"
}
也可以自动生成 _id 值:
POST /products/_doc
{
"id":"10027",
"title":"vivo X9前置双摄全网通4G美颜自拍超薄智能手机大屏vivox9",
"category":"手机会场",
"price":"2798.00",
"city":"广东东莞",
"barcode":"541396973568"
}
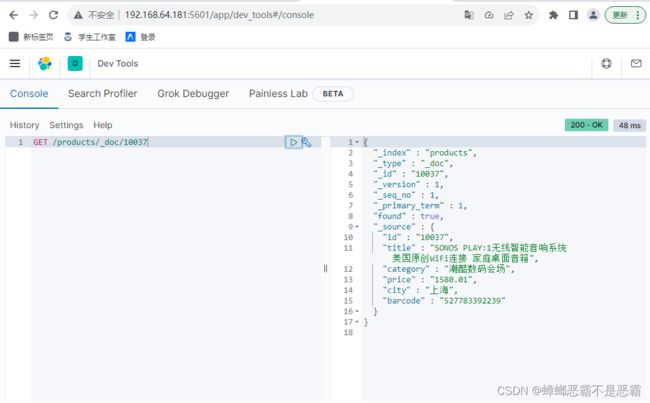
查看文档:
GET /products/_doc/10037
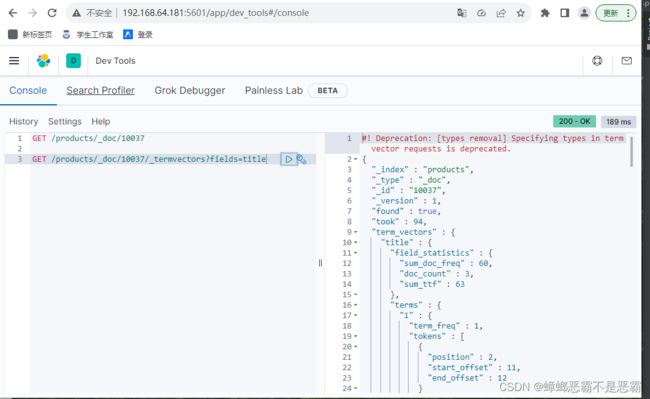
查看指定文档title字段的分词结果:
GET /products/_doc/10037/_termvectors?fields=title
5.修改文档
底层索引数据无法修改,修改数据实际上是先删除再重新添加。
两种修改方式:
- PUT:对文档进行完整的替换
- POST:可以修改一部分字段
5.1 PUT
修改价格字段的值:
# 修改文档 - 替换
PUT /products/_doc/10037
{
"id":"10037",
"title":"SONOS PLAY:1无线智能音响系统 美国原创WiFi连接 家庭桌面音箱",
"category":"潮酷数码会场",
"price":"9999.99",
"city":"上海",
"barcode":"527783392239"
}
查看文档:
GET /products/_doc/10037
但是如果我们只给价格一个字段,修改完成后,其他字段都会变为空字段,只剩价格一个字段有值;
5.2 POST
修改价格和城市字段的值:
# 修改文档 - 更新部分字段
POST /products/_update/10037
{
"doc": {
"price":"8888.88",
"city":"深圳"
}
}
查看文档:
GET /products/_doc/10037
POST请求需要访问_update更新路径,可以只输入我们想要修改的值;
6.删除
6.1 删除文档
DELETE /products/_doc/10037
删除单个文档,指定文档的ID即可;
6.1 清空
POST /products/_delete_by_query
{
"query": {
"match_all": {}
}
}
_delete_by_query指删除所有查询到的文档,然后给定的值就是match_all查询所有文档;
6.2 删除索引
# 删除 products 索引
DELETE /products
可以尝试用不同的分片和副本值来重新创建 products 索引