Pandas模块的基础操作-学习笔记
基于pandas的一些金融常用基本操作
一、数据结构
1. 序列 Series
序列一般只有两列,一列是索引 index,一列是数据。
# 手动输入方式创建
return_series1 = pd.Series([0.003731, -0.001838, -0.003087, -0.024112], index=['中国石油', '工商银行', '上汽集团', '宝钢股份'])
# 通过数组生成序列
return_array = np.array([[0.003731, 0.021066, -0.004854, 0.006098, -0.00606],
[-0.001838, 0.001842, -0.016544, -0.003738, 0.003752],
[-0.003087, -0.000344, -0.033391, 0.007123, 0.004597],
[-0.024112, 0.011704, -0.029563, -0.01457, 0.016129]])
return_series2 = pd.Series(return_array[:,0], index=['中国石油', '工商银行', '上汽集团', '宝钢股份'])
2. 数据框 DataFrame
数据框的创建
date = ['2018-09-03', '2018-09-04', '2018-09-05', '2018-09-06', '2018-09-07']
stock = ['中国石油', '工商银行', '上汽集团', '宝钢股份']
return_dataframe = pd.DataFrame(data=return_array.T, index=date, columns=stock)
数据框导出成excel或csv等格式
如果导出csv格式有乱码,可以加上encoding=‘utf_8_sig’
return_dataframe.to_excel('xxx.xlsx')
return_dataframe.to_csv('费乱码.csv', encoding='utf_8_sig')
数据框导入
二、数据框的可视化
- 中文字体的可视化
必须输入这一步,否则会出现字体是方框。
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
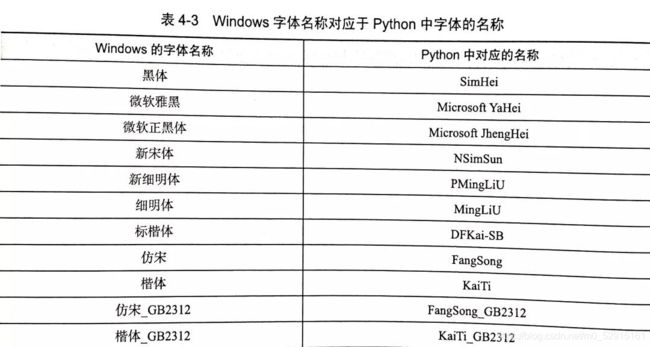
常用字体对应名称
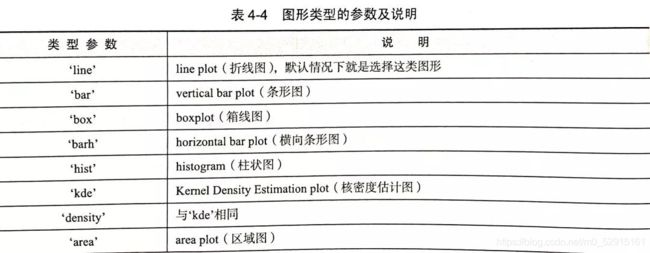
2. 可视化的函数及参数

需要注意的是,中文字符前加一个 u
HS300_excel1.plot(kind='line', subplots=True, sharex=True, sharey=True, layout=(2,2), figsize=(10,8),
title=u'2018年沪深300 指数走势图', grid=True, fontsize=13)

三、数据框内部的操作
- 数据框基本性质
index 和 columns 查看列名和行名
HS300_excel1.index
HS300_excel1.columns

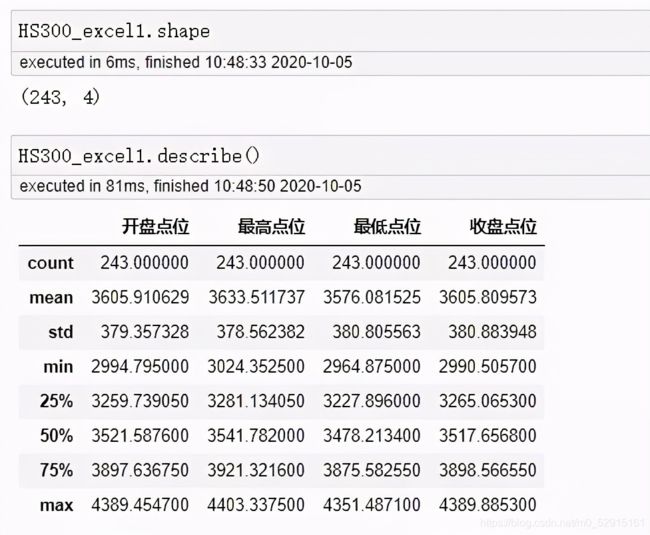
shape 和 describe
HS300_excel1.shape #返回数组形状
HS300_excel1.describe() #返回数组个数均值等信息
切片 切片操作左闭右开
# 切第8行-13行,第2、3列
HS300_excel1.iloc[7:13, 1:3]
条件筛选切片
# 筛选收盘价大于4300的数据
HS300_excel1[HS300_excel1['收盘点位']>=4300]
排序
按行索引大小排序 sort_index函数
- False代表降序大==>小,axis=0是行索引排序
- axis=1则是列索引排序
# 按照行索引排序
HS300_excel1.sort_index(ascending=False, axis=0)
以某列数值大小为依据排序
参数同理False为降序
# 以收盘 开盘价为依据,排序
HS300_excel1.sort_values(by=['收盘点位', '开盘点位']) #排序两个则传入列表
4. 数据框的修改
修改列名
HS300_colchange = HS300_excel1.rename(columns={'收盘点位': '收盘价格_改'})
缺失值的处理
一种是删除,即删除有缺失值的行 另一种是填补,将特定值(或前值后值)替换缺失
stock_dropna = stock.dropna() #任意列有空删除整行数据
stock_fillna = stock.fillna(value=0) #缺失值补0
stock_fillna = stock.fillna(method='ffill') #前值补缺
stock_fillna = stock.fillna(method='bfill') # 后值补缺
四、数据框之间的操作
1. concat拼接
pd.concat([数据1,数据2,数据3·····], axis=0 或 1)
HS300_new = pd.concat([HS300_excel1, HS300_excel2], axis=0) #按行,上下拼接 stock_new = pd.concat([stock2, stock],axis=1) # 按列,左右拼接
2. merge拼接
left_index=True 意味着左侧数据按照index进行拼接,右侧同理。如果左右index不完全一致,左右都是True则拼接相同项,相当于inner。如果left_index是False,则需要left_on 给一个对比项才能拼。
pd.merge(left=stock_4, right=stock2, left_index=True, right_index=True)
3. join 拼接
问题在于只能按照某个索引进行拼接,默认根据两个数据的index进行拼接
> `stock.join(stock2, on='日期')`
五、主要统计函数
- 常用静态统计函数



2. 移动窗口与动态统计函数
时间点的数据往往波动较大,因此某一时间点的数据通常不能很好的反馈数据本身的特性,因此就需要用一段时间区间的数据进行描述。即提升数据可靠性,将某个点的取值扩大到包含这个点的一段区间,并用区间进行判断,这个区间就是窗口。
数据框.rolling(window=窗口数, axis=0 或 1).统计量函数(axis=0 或 1)
移动平均
HS300_meanclose = HS300_new['收盘点位'].rolling(window=20).mean() # 20日平均的序列
HS300_meanclose.plot(figsize=(15, 12), title=u'2016-2018年沪深300指数走势', grid=True, fontsize=12)

移动方差(波动率)
HS300_rollingstd = HS300_new['收盘点位'].rolling(window=60).std() # 60天移动方差
HS300_rollingstd.plot(figsize=(10,7), title=u'2016-2018年沪深300指数波动率的走势', grid=True, fontsize=12)

移动相关系数
变量之间的相关系数也会随时间变化,特别是一些特殊时期许多原本相关性很低的变量呈现高相关性。
HS300_rollingcorr = HS300_new.rolling(window=30).corr().dropna()
HS300_rollingcorr.head(20)
为了帮助小伙伴们能够更好更方便的学习,少走弯路,这边也为小伙伴们准备了一套python从入门到实践的习资料,希望可以帮助到你们的学习!**
扫码备注77:即可领取哦
