前端 js 之 浏览器工作原理 和 v8引擎 01
嘿,老哥,来了就别跑 !学完 ,不亏
文章目录
- 一、输入url 之后做了什么
- 二、简单了解下浏览器内核
- 三、浏览器渲染过程 (渲染引擎)
- 四、js 引擎
- 五、chrome
- 五、v8 引擎原理
- 八、浏览器性能优化
- 九、前端性能优化
- 关于浏览器的周边知识 (以下)
- 一、 浏览器 Chrome
- 二、 进程
- 三、协议
- 四、浏览器渲染
一、输入url 之后做了什么
我们再用百度都上网的时候,假设我们在地址栏输入我们想去的网址,然后就得到了我们想要的网站,输入url 之后做了什么呢?就可以执行到我们想要的目的?
是这样,我们在输入 url 之后,浏览器会通过 DNS 进行解析,得到对应的 ip 地址,换句话来说,得到对应的服务器地址。这时服务器会返回一个 index.html(一般情况下,或者main.index等),浏览器会根据这个入口文件,解析这个html,当我们遇到css文件,就会下载css 文件,遇到srcipt 文件 就会下载script 文件。把所有文件下载完毕之后浏览器内核再去解析文件
这是第一次读取,当我们第二次读取时,域名解析的 ip 会存在本地,浏览器可以直接读取浏览器缓存
二、简单了解下浏览器内核
浏览器可以分为两部分:
渲染引擎和js引擎, 渲染引擎 决定了浏览器该如何显示网页内容及页面的格式信息,渲染引擎是浏览器兼容性问题出现的根本原因;js 引擎 用来解释网页语法,并渲染到网页上。 由于 js引擎 越来越独立,浏览器内核偏向指向于 渲染引擎
渲染引擎:负责HTML解析、布局、渲染等相关的工作JS引擎:是一个专门处理JavaScript脚本的虚拟机,一般会附带在网页浏览器之中。
不同浏览器是有不同内核组成的
- Gecko:早期被 Netscape 和 Mozilla Firefox 浏览器浏览器使用
- Trident:由微软开发,被IE4~IE11浏览器使用,但是 Edge 浏览器已经转向 Blink
- Webkit:苹果基于KHTML开发、开源的,用于 Safari,Google Chrome在之前也在使用
- Blink:由Google 在KHTML 基础上开发的,是Webkit的一个分支,目前应用于Google Chrome、Edge、Opera等;
- …
三、浏览器渲染过程 (渲染引擎)

刚刚我们说到,各种文件下载下来之后,再由浏览器引擎进行解析,根据上附图,我们来看下渲染过程
- 我们都知道啊,index.html 是第一个被下载的,html 里面无非就是一些标签,这时就会通过我们的浏览器内核 parser 会将我们的html 解析成一个 Dom Tree
- 在解析dom 过程中,如果遇到 javaScript 标签,会停止解析html , 而去
加载执行js 代码,因为js 会对dom 进行一些操作的,比如新增一个节点。 ( 我们都知道js 是一个高级语言,cpu 是不认识的,那这就要用js引擎来执行 ) - 同样的道理,浏览器内核 parser 解析我们的css ,因为style 有很多规则,color ,display 等等,这些规则会应用到dom树上,通过html 和 css的结合,就会生成一个渲染树
- layout 是布局引擎,比如在设置了定位之后,布局引擎会根据浏览器页面大小进行处理,这时再生成新的渲染树
- 最后我们浏览器内核再进行绘制,进行展示
四、js 引擎
我们都知道 js 是一个高级语言,cpu 是不认识的 ,js 引擎 用来执行 js 代码
为啥?
高级的编程语言都是需要转成最终的机器指令来执行的- 事实上我们编写的JavaScript无论你交给浏览器或者Node执行,最后都是需要被
CPU执行的 - 但是CPU只认识自己的指令集 (实际上是
机器语言),才能被CPU所执行 - 所以我们需要
JavaScript引擎帮助我们将JavaScript代码翻译成CPU指令来执行
JavaScript引擎
- SpiderMonkey:第一款JavaScript引擎,由Brendan Eich开发(也就是JavaScript作者);
- Chakra:微软开发,用于IT浏览器;
- JavaScriptCore:WebKit中的JavaScript引擎,Apple公司开发;
- V8:Google开发的强大JavaScript引擎,也帮助Chrome从众多浏览器中脱颖而出;
- 等等…

五、chrome
十年前,你说浏览器就是IE , 有人会出来反对
现在,你说浏览器是Chrome ,最多有人纠正你
那 chrome 浏览器 为什么能占据 60% 的市场呢?
“基于多进程模型” 和 “V8 的高效快速”,还有 关于遵循的开源协议
关于进程 可以看看我在最下面写的 关于浏览器的周边知识 (以下)
五、v8 引擎原理
我们来看一下官方对V8引擎的定义:
- V8是用
C ++编写的Google开源高性能JavaScript 和 WebAssembly引擎,它用于 Chrome 和 Node.js 等。 - 它实现 ECMAScript 和 WebAssembly,并在 Windows 7 或更高版本,macOS 10.12+ 和使用 x64,IA-32,
ARM 或 MIPS 处理器的 Linux 系统上运行。 - V8 可以独立运行,也可以嵌入到任何 C ++ 应用程序中
(看的懂,看! 看不懂,没关系,接着看!!!)

先不要慌,稳住!老哥!别怕,不难
我们都知道,cpu 是执行我们的指令的,而高级语言是不能直接被 cpu 执行的,需要转化为低级语言才行,所以我们需要借助 js 引擎帮助我们把高级语言 " 翻译 " 为低级语言, 现在把你卡姿兰的大眼睛瞄到上个图,红色框框的就是v8 引擎做的事,v8 引擎 是目前性能最高的 js 引擎,先不用在意看不懂这件事,接着往下走
假设我这有一坨代码: const name = ‘haha’
-
看图,
-
parse 是解析,它包括
词法分析和语法分析 -
词法分析:生成一个数组 tokens: [ ],用来存放每个词的信息
对每个词进行分割, tokens: [ { type: ‘keyword’ , value:‘const’ } , { type: ‘indentifier’ , value:'name }]
会进行判断,比如 const , 会先定义他的类型是一个关键字(keyword),并且它的值为 const
包括等号,分号都会进行分析好处:我们把这些划分为一个个小对象,这样很容易进行语法分析
… -
语法分析: AST 抽象语法树根据语法分析之后我们进行语法分析,会生成一个 AST 抽象语法树
比如 ts 转化为 js :
ts ——> 通过ast 生成一个新的 ast ——> 改变之后生成新的代码 generate code ——> js代码好处:因为他是一个树形,有些属性值是固定的,这样我们很容易转成 es5代码、es6代码、字节码…非常好操作,这个操作是由 ignation 执行的,可以把 ignition 当成一个解释器, -
通过 ignition 我们可以转化为字节码,字节码也要经过处理变成汇编指令再得到结果,转化为字节码的好处就是可以
跨平台( 往下看ps ) -
v8 引擎之所以性能这么高,是因为他还有个库,trunboFan 用来收集信息,比如类型信息。对于执行频率高的函数的就保留
可以看下这个,就是一个模拟 AST 抽象语法树 https://astexplorer.net/
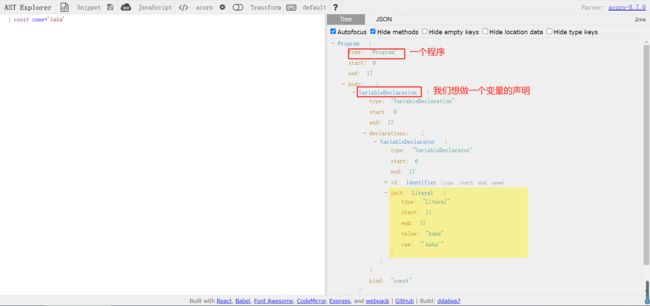
总结:
Parse 模块 会将 JavaScript 代码转换成 AST(抽象语法树),这是因为解释器并不直接认JavaScript代码,如果函数没有被调用,那么是不会被转换成AST的
Ignition 是一个解释器,会将 AST 转换成 ByteCode(字节码),同时会收集 TurboFan 优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);如果函数只调用一次,Ignition 会执行解释执行 ByteCode;
TurboFan 是一个编译器,可以将字节码编译为CPU可以直接执行的机器码;如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过 TurboFan 转换成优化的机器码,提高代码的执行性能; 但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化( 比如 sum 函数原来执行的是 number 类型,后来执行变成了 string 类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
ps : 我们都知道 AST 抽象语法树操作方便,为什么不直接转为机器码呢?是这样的,因为我们 js 代码可能跑在window系统的浏览器里,可能跑在iso 系统的浏览器,可能跑在linux 系统上的浏览器上面…跑的环境不一样,就会拥有不同的 cpu , 不同 cpu 又有着不一样的架构,执行的机器指令是不一样的,所以 字节码的好处就是可以跨平台
备注:
- 机器码:机器码就是cpu能够直接读取并运行的代码,用二进制编码表示,也叫做机器指令码。
- 字节码:字节码是一种中间状态的二进制代码,是由源码编译过来的,可读性没有源码高。而且cpu也不能够直接读取字节码,在java中,字节码需要经过JVM虚拟机转译成机器码之后,cpu才能够读取并运行
- 采用字节码的好处:比如java语言,通过字节码的方式,在一定程度在解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以java程序运行时比较高效,而且由于字节码并不专对于一种特定的机器,因此java程序无需重新编译便可以在多种不同的计算机上运行
- 什么是字节码文件?
字节码文件是经过编译器预处理过的一种文件,是JAVA执行文件的存在形式。
它本身是二进制文件,但是不可以被系统直接执行,而是需要虚拟机(JVM)解释执行。由于被预处理过,所以比一般的解释代码要快,但是仍然会比系统直接执行的慢
代码执行过程,可以看下我写的文章, 02
八、浏览器性能优化
加载时
- 减少http请求 (精灵图,文件的合并)
- 减少文件大小 (资源压缩,图片压缩,代码压缩)
- CDN (第三方库,大文件,大图)
- SSR 服务器端渲染,预渲染
- 懒加载
- 分包
- 减少dom操作,避免回流,文档碎片(一种虚拟的DOM节点,存在于内存中)
九、前端性能优化
缓存:客户端控制的强缓存策略
降低请求成本
- http dns 由客户端控制,隔一段时间主动请求dns获取域名ip,不走系统的dns
- tcp/tls 连接复用:减少请求数
- js.css打包到html
- js控制图片异步加载或者懒加载
- 小型图片使用精灵图
- 减少传输体积
- 懒加载:自定义属性data-src存放真正需要显示的图片路径
告辞!!!!

v8性能高的原因:
-
编译器优化:v8引擎使用了即时编译(Just-in-Time Compilation)技术,将JavaScript代码转换为本地机器码,以提高执行速度。它包括解析、分析和优化代码的过程,以便生成高效的机器码。
-
内存管理:v8引擎使用了高效的内存管理机制,如垃圾回收器(Garbage Collector),用于自动管理内存的分配和释放。它能够及时回收不再使用的内存,避免内存泄漏和过度消耗。
-
即时优化:v8引擎还具有即时优化功能,它会在代码执行过程中动态地优化性能。例如,它会根据运行时的上下文信息进行内联优化,将函数调用内联到调用处,避免了函数调用的开销。
-
多线程支持:v8引擎通过使用多线程技术,如并行编译和并行垃圾回收等,提高了执行效率。它可以同时处理多个任务,并充分利用多核处理器的计算能力
关于浏览器的周边知识 (以下)
先说两个概念,互联网 internet 泛指具有互通的计算机网络;因特网 Internet 是基于TCP/IP 协议族的最大的计算机网络;万维网 web (word wide web) 是基于互联网,由超链接和统一资源标识符(连接)的文件和其他资源的全球集合
万维网由三个部分构成 :
- 统一资源标识符 URI (由一个字符串来表示抽象的或者物理的资源)
- 超文本标记语言 html ( 超文本:含有指向其他资源链接的文本;标记语言:通过一些标签包裹的元素,这些标记会被浏览器识别为超链接或者文本段等)
- 超文本传输协议 http (传输 html 的一个协议)
URL 和 URI 的区别:
- URL 统一资源 定位 符
- URI 统一资源 标识 符
- 这样说吧, URI 是一个抽象的地址,URL 是一个具体的地址
抽象的地址:安徽省亳州市
具体的地址:安徽省亳州市利辛县汝集镇 223号 - 所以说 URL 是 URI 的子集
- 再举个例子:
http://www.csdn.net 是一个服务器地址,但是没有具体到文件是什么类型 (URI)
http://www.csdn.net/image/logo.gif 这就是一个很具体的地址 (URL)
一、 浏览器 Chrome
浏览器可以分为两部分:
渲染引擎和js引擎, 渲染引擎 决定了浏览器该如何显示网页内容及页面的格式信息;js 引擎 用来解释网页语法,并渲染到网页上。 由于 js引擎 越来越独立,浏览器内核偏向指向于 渲染引擎
渲染引擎:负责HTML解析、布局、渲染等相关的工作JS引擎:是一个专门处理JavaScript脚本的虚拟机,一般会附带在网页浏览器之中。
-
十年前,你说浏览器就是IE , 有人会出来反对
现在,你说浏览器是Chrome ,最多有人纠正你 -
那 chrome 浏览器 为什么能占据 60% 的市场呢?
基于多进程模型和V8引擎的高效快速
关于V8引擎的原理 可以看看我 前端 js 之 浏览器工作原理 和 v8引擎 01 这篇文章。
二、 进程
进程是一个程序的运行实例,当我们启动一个程序时,那么操作系统会创建一块内存给代码和运行时的数据使用,并且创建一个线程来处理任务。这个环境就是叫做进程
线程:它是进程的 一个执行任务 或者可以叫做控制单元,负责当前进程中程序的执行。一个进程至少有一个线程,一个进程也可以运行多个线程。
- 多个线程之间可以进行数据共享,
- 进程关闭后内存会正确回收,
- 但是如果一个线程发生崩溃,整个进程就会崩溃,
不同进程之间的内容相互隔离,进程通信需要依靠 IPC ( 进程间通讯机制 )

在 chrome 浏览器诞生之前,大多数浏览器都是单进程
- 单进程的所有功能模块都在同一个进程中运行的,如果有一个产生问题,整个进程都会跟着崩溃,必须对浏览器进行重启;
- 因为页面所有的功能都在一个进程中,当一个页面卡住时,所有页面都会卡住,所以卡也是一个问题;
- 因为所有页面都在一个进程中,单个页面的数据因为代码编写问题而出现内存泄漏,在关闭页面时,泄露的内存并不会进行回收会导致浏览器会越用越卡;
- 插件和渲染线程拥有很高的权限。插件和渲染线程中包括各种脚本代码,而这些脚本代码通常是由第三方编写的,如果有恶意插件或者网站可以通过权限来读取本地数据
所以 chrome 浏览器采用 多进程架构
- 每个页面有单独渲染进程和插件进程
- 每个页面的渲染进程和插件进程都放进沙箱内,让他们不能获取系统权限
- 权限问题统一交给浏览器的主线程来操作
- 不同进程之间通过 IPC 来传输数据
浏览器是多进程的: 在浏览器中,每打开一个tab页面,其实就是新开了一个进程,在这个进程中,还有ui渲染线程,js引擎线程,http请求线程等。 所以,浏览器是一个多进程的

一个浏览器的进程

- 浏览器进程: 负责页面的展示,用户的交互,管理子进程还有提供存储功能
- 网络进程 : 下载网络资源
- GPU进程:绘制网页和UI界面
- 渲染引擎:js引擎 和 排版引擎
- 插件引擎: 扶着加载和运行页面上的插件
三、协议
协议:保证了通信双方都可以识别的一种约定的数据格式
通过计算机网络可以使多台计算机实现连接,但是位于同一个网络中的计算机
在进行连接和通信时必须要遵守一定的规则,就像比在道路中行驶的汽车要遵守交通规则。在计算机网络中,这些连接和通信的规则被称为网络通信协议,它对数据的传输格式、传输速率、传输步骤等做了统一规定,通信双方必须同时遵守才能完成数据交互。
协议类型
- 互联网协议:基于IP协议的一个体系架构,想要进行数据的传输,每个主机都要有特定的 ip 地址
- ip协议,通过dns 进行域名解析,找到对应的网址,并进行缓存
- http 超文本传输协议:规定传输包的数据格式
- 通过tcp/ip 发送到网络中
- udp ,通过端口号访问指定程序,但是不能保证对方确定接受到
- tcp(传输控制协议) 解决了udp 传输不可靠问题,增加了重传机制,tcp协议是面对连接的,传输前会和目标设备进行连接,传输完成后断开
http 请求流程:
我们通过URL 请求服务器,服务器会返回给我们网页数据文件,那之间的流程是怎样的呢?

当我们发送请求时,浏览器会找有没有上次请求缓存的文件,如果有且文件没有过期,就会直接使用不再请求,减少了服务器的压力,而且可以快速加载。
如果没有,通过http 做应用层协议( http 协议规定传输包的数据格式),通过 TCP/IP 把他们发送到发送到网络中,发送之前会通过 DNS 通过域名查找到对应的服务器地址,查找到以后对他们进行缓存,如果输入的域名没有加端口号会默认加 80;完成以后为 TCP 建立连接,三次握手四次挥手,就可以正式发送我们的 HTTP ,接下来就是服务端接收到请求并返回数据。

四、浏览器渲染
渲染流程:

我们都知道网页的三件套: html css javascript
- html 超文本标记语言,由各种标签组成,标签可以代表元素类型,html 是网页的骨架
- css 层叠样式表,可以赋予网页各种好看的样式,排版
- js 给网页赋予各种逻辑,让网页变得具有交互性
- 因为网页不能识别html , 需要通过 html 解析器转化为dom树,供后续的步骤使用 (网络进程加载多少数据,解析器就会解析多少数据,网络进程会实时把获取的数据传递给渲染进程,由解析器解析 )
- …
- 看我正篇吧,比较详细