《动手学深度学习 Pytorch版》 9.1 门控循环单元(GRU)
我们可能会遇到这样的情况:
-
早期观测值对预测所有未来观测值具有非常重要的意义。
考虑一个极端情况,其中第一个观测值包含一个校验和,目标是在序列的末尾辨别校验和是否正确。在这种情况下,第一个词元的影响至关重要。我们希望有某些机制能够在一个记忆元里存储重要的早期信息。如果没有这样的机制,我们将不得不给这个观测值指定一个非常大的梯度, 因为它会影响所有后续的观测值。
-
一些词元没有相关的观测值。
例如,在对网页内容进行情感分析时, 可能有一些辅助HTML代码与网页传达的情绪无关。 我们希望有一些机制来跳过隐状态表示中的此类词元。
-
序列的各个部分之间存在逻辑中断。
例如,书的章节之间可能会有过渡存在, 或者证券的熊市和牛市之间可能会有过渡存在。 在这种情况下,最好有一种方法来重置我们的内部状态表示。
在学术界已经提出了许多方法来解决这类问题。其中最早的方法是“长短期记忆”(long-short-term memory,LSTM),将在 9.2节中讨论。门控循环单元(gated recurrent unit,GRU)是一个稍微简化的变体,通常能够提供同等的效果,并且计算的速度明显更快。由于门控循环单元更简单,我们从它开始解读。
9.1.1 门控隐状态
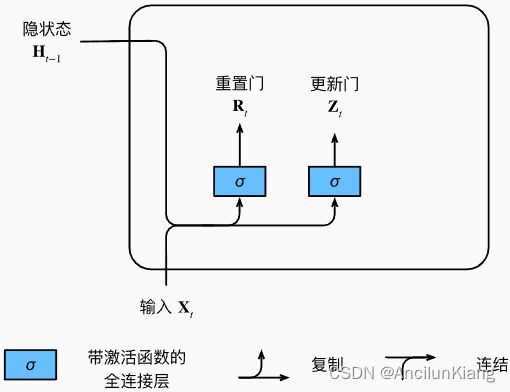
9.1.1.1 重置门和更新门
-
重置门(reset gate):控制“可能还想记住”的过去状态的数量,也就是控制旧状态的影响。
-
更新门(update gate):控制新状态中有多少个是旧状态的副本,也就是控制新状态的影响。
要点:
-
两个门是 ( 0 , 1 ) (0,1) (0,1) 区间中的向量,这样就可以进行凸组合。
-
输入由当前时间步的输入和前一时间步的隐状态给出
-
输出由使用sigmoid激活函数的两个全连接层给出
门控循环单元的数学表达如下:
R t = σ ( X t W x r + H t − 1 W h r + b r ) Z t = σ ( X t W x z + H t − 1 W h z + b z ) \begin{align} \boldsymbol{R}_t&=\sigma(\boldsymbol{X}_t\boldsymbol{W}_{xr}+\boldsymbol{H}_{t-1}\boldsymbol{W}_{hr}+b_r)\\ \boldsymbol{Z}_t&=\sigma(\boldsymbol{X}_t\boldsymbol{W}_{xz}+\boldsymbol{H}_{t-1}\boldsymbol{W}_{hz}+b_z)\\ \end{align} RtZt=σ(XtWxr+Ht−1Whr+br)=σ(XtWxz+Ht−1Whz+bz)
参数字典:
-
X t ∈ R n × d \boldsymbol{X}_t\in\R^{n\times d} Xt∈Rn×d 表示小批量输入
-
n n n 表示样本个数
-
n n n 表示输入个数
-
-
H t − 1 ∈ R n × h \boldsymbol{H}_{t-1}\in\R^{n\times h} Ht−1∈Rn×h 表示上一个时间步的隐状态
- h h h 表示隐藏单元个数
-
R t ∈ R n × h \boldsymbol{R}_t\in\R^{n\times h} Rt∈Rn×h 表示重置门
-
Z t ∈ R n × h \boldsymbol{Z}_t\in\R^{n\times h} Zt∈Rn×h 表示更新门
-
W x r , W x z ∈ R d × h \boldsymbol{W}_{xr},\boldsymbol{W}_{xz}\in\R^{d\times h} Wxr,Wxz∈Rd×h W h r , W h z ∈ R h × h \boldsymbol{W}_{hr},\boldsymbol{W}_{hz}\in\R^{h\times h} Whr,Whz∈Rh×h 表示权重参数
-
b r , b z ∈ R 1 × h b_r,b_z\in\R^{1\times h} br,bz∈R1×h 表示偏重参数
在求和过程中会触发广播机制。使用 sigmoid 函数将输入值转换到区间 ( 0 , 1 ) (0,1) (0,1)。
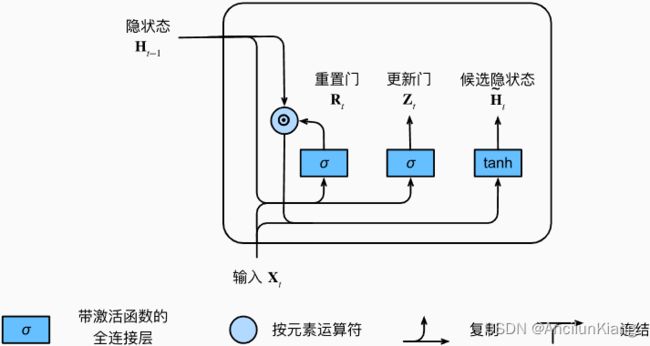
9.1.1.2 候选隐状态
将重置门 R t R_t Rt 与常规隐状态更新机制集成,得到在时间步 t t t 的候选隐状态(candidate hidden state) H t ~ ∈ R n × h \tilde{\boldsymbol{H}_t}\in\R^{n\times h} Ht~∈Rn×h:
H t ~ = t a n h ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) \tilde{\boldsymbol{H}_t}=tanh(\boldsymbol{X}_t\boldsymbol{W}_{xh}+(\boldsymbol{R}_t\odot\boldsymbol{H}_{t-1})\boldsymbol{W}_{hh}+\boldsymbol{b}_h) Ht~=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)
与常规隐状态更新机制公式相比, R t \boldsymbol{R}_t Rt 和 H t − 1 \boldsymbol{H}_{t-1} Ht−1 的元素相乘可以减少以往状态的影响。
-
当重置门 R t R_t Rt 中的项接近 1 时,就恢复一个如常规隐状态更新机制公式中的普通的循环神经网络。
-
对于重置门 R t R_t Rt 中所有接近 0 的项,候选隐状态是以 X t X_t Xt 作为输入的多层感知机的结果。因此,任何预先存在的隐状态都会被重置为默认值。
9.1.1.3 隐状态
上述的计算结果只是候选隐状态,接下来仍然需要结合更新门的效果。这一步确定新的隐状态 H t ∈ R n × h \boldsymbol{H}_t\in\R^{n\times h} Ht∈Rn×h 在多大程度上来自旧的状态 H t − 1 \boldsymbol{H}_{t-1} Ht−1 和新的候选状态 H t ~ \tilde{\boldsymbol{H}_t} Ht~。更新门 Z t \boldsymbol{Z}_t Zt 仅需要在 H t − 1 \boldsymbol{H}_{t-1} Ht−1 和 H t ~ \tilde{\boldsymbol{H}_t} Ht~ 之间进行按元素的凸组合就可以实现这个目标。这就得出了门控循环单元的最终更新公式:
H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H t ~ \boldsymbol{H}_t=\boldsymbol{Z}_t\odot\boldsymbol{H}_{t-1}+(1-\boldsymbol{Z}_t)\odot\tilde{\boldsymbol{H}_t} Ht=Zt⊙Ht−1+(1−Zt)⊙Ht~
-
每当更新门 Z t Z_t Zt 接近 1 时,模型就倾向只保留旧状态。此时,来自 X t X_t Xt 的信息基本上被忽略,从而有效地跳过了依赖链条中的时间步。
-
当 Z t Z_t Zt 接近 0 时,新的隐状态 H t H_t Ht 就会接近候选隐状态 H t ~ \tilde{\boldsymbol{H}_t} Ht~。
这些设计可以帮助我们处理循环神经网络中的梯度消失问题,并更好地捕获时间步距离很长的序列的依赖关系。例如,如果整个子序列的所有时间步的更新门都接近于 1,则无论序列的长度如何,在序列起始时间步的旧隐状态都将很容易保留并传递到序列结束。
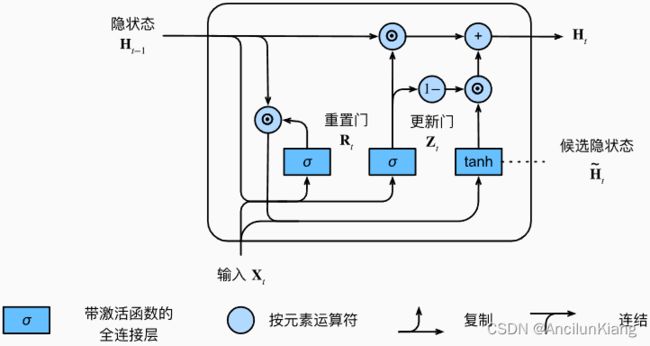
总之,门控循环单元具有以下两个显著特征:
-
重置门有助于捕获序列中的短期依赖关系;
-
更新门有助于捕获序列中的长期依赖关系。
9.1.2 从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) # 读取时间机器数据集
9.1.2.1 初始化模型参数
def get_params(vocab_size, num_hiddens, device): # 初始化模型参数
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
9.1.2.2 定义模型
def init_gru_state(batch_size, num_hiddens, device): # 隐状态初始化
return (torch.zeros((batch_size, num_hiddens), device=device), )
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state # 优雅,逗号解包
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z) # 更新门运算 @符号做哈达玛积
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r) # 重置门运算
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h) # 候选隐状态
H = Z * H + (1 - Z) * H_tilda # 隐状态计算
Y = H @ W_hq + b_q # 预测值计算
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
9.1.2.3 训练预测
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
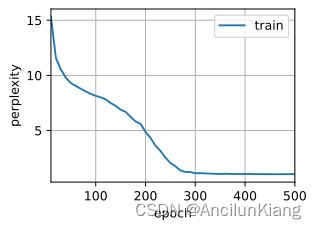
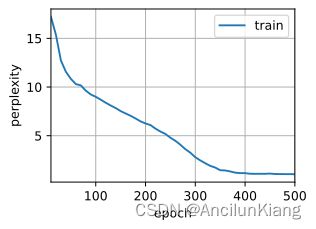
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
perplexity 1.0, 32229.1 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
traveller with a slight accession ofcheerfulness really thi
9.1.3 简洁实现
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device)
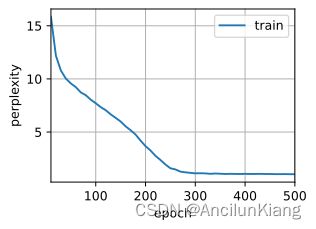
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
perplexity 1.0, 182698.8 tokens/sec on cuda:0
time traveller with a slight accession ofcheerfulness really thi
travelleryou can show black is white by argument said filby
练习
(1)假设我们只想使用时间步 t ′ t' t′ 的输入来预测时间步 t > t ′ t>t' t>t′ 的输出。对于每个时间步,重置门和更新门的最佳值是什么?
不会。
(2)调整和分析超参数对运行时间、困惑度和输出顺序的影响。
分别修改各个参数试试、
def test(Hyperparameters): # [batch_size, num_steps, num_hiddens, lr, num_epochs]
train_iter_now, vocab_now = d2l.load_data_time_machine(Hyperparameters[0], Hyperparameters[1])
gru_layer_now = nn.GRU(len(vocab_now), Hyperparameters[2])
net_now = d2l.RNNModel(gru_layer_now, len(vocab_now))
net_now = model.to(device)
d2l.train_ch8(net_now, train_iter_now, vocab_now, Hyperparameters[3], Hyperparameters[4], d2l.try_gpu())
Hyperparameters_lists = [
[64, 35, 256, 1, 500], # 加批量大小
[32, 64, 256, 1, 500], # 加时间步
[32, 35, 512, 1, 500], # 加隐藏单元数
[32, 35, 256, 0.5, 500], # 减半学习率
[32, 35, 256, 1, 200] # 减轮数
]
for Hyperparameters in Hyperparameters_lists:
test(Hyperparameters)
perplexity 1.0, 194760.4 tokens/sec on cuda:0
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filby
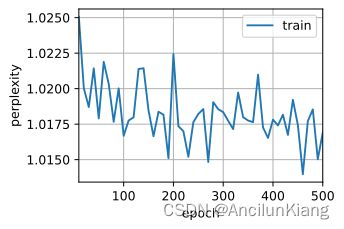
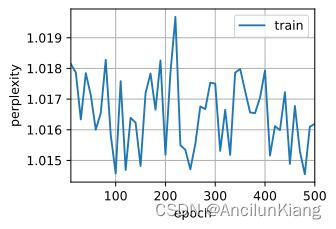
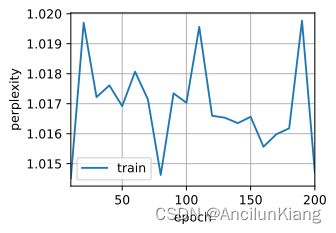
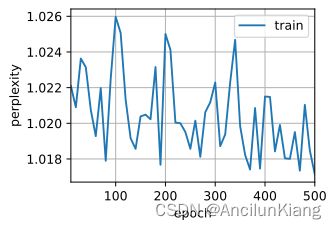
(3)比较 rnn.RNN 和 rnn.GRU 的不同实现对运行时间、困惑度和输出字符串的影响。
batch_size2, num_steps2 = 32, 35
train_iter2, vocab2 = d2l.load_data_time_machine(batch_size2, num_steps2)
vocab_size2, num_hiddens2, device = len(vocab2), 256, d2l.try_gpu()
num_epochs2, lr2 = 500, 1
num_inputs2 = vocab_size2
gru_layer2 = nn.GRU(num_inputs2, num_hiddens2)
net_GRU = d2l.RNNModel(gru_layer2, len(vocab2))
net_GRU = model.to(device)
d2l.train_ch8(net_GRU, train_iter2, vocab2, lr2, num_epochs2, device)
perplexity 1.0, 196633.4 tokens/sec on cuda:0
time traveller for so it will be convenient to speak of himwas e
traveller with a slight accession ofcheerfulness really thi
rnn_layer = nn.RNN(len(vocab2), num_hiddens2)
net_RNN = d2l.RNNModel(rnn_layer, vocab_size=len(vocab2))
net_RNN = net_RNN.to(device)
d2l.train_ch8(net_RNN, train_iter2, vocab2, lr2, num_epochs2, device)
perplexity 1.3, 190636.6 tokens/sec on cuda:0
time traveller held in his hand was a glitteringmetallic framewo
travellerisctallerasced fo the onther fite dok you know hom
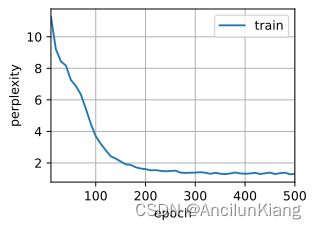
(4)如果仅仅实现门控循环单元的一部分,例如,只有一个重置门或一个更新门会怎样?
去掉更新门根本不带收敛的;去掉重置门还行,甚至更平滑了。
# 删除更新门
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
def get_params_change1(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
# W_xz, W_hz, b_z = three()
W_xr, W_hr, b_r = three()
W_xh, W_hh, b_h = three()
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
params = [W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
def init_gru_state_change1(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
def gru_change1(inputs, state, params):
# W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
# Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
# H = Z * H + (1 - Z) * H_tilda
Y = H_tilda @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model_change1 = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params_change1,
init_gru_state_change1, gru_change1)
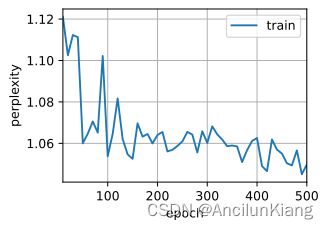
d2l.train_ch8(model_change1, train_iter, vocab, lr, num_epochs, device)
perplexity 10.0, 45023.4 tokens/sec on cuda:0
time travellere the the the the the the the the the the the the
travellere the the the the the the the the the the the the
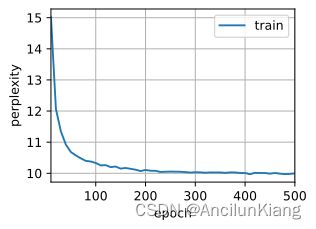
# 删除重置门
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
def get_params_change2(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three()
# W_xr, W_hr, b_r = three()
W_xh, W_hh, b_h = three()
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
params = [W_xz, W_hz, b_z, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
def init_gru_state_change2(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
def gru_change2(inputs, state, params):
# W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
W_xz, W_hz, b_z, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
# R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
# H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H_tilda = torch.tanh((X @ W_xh) + (H @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H_tilda @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model_change2 = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params_change2,
init_gru_state_change2, gru_change2)
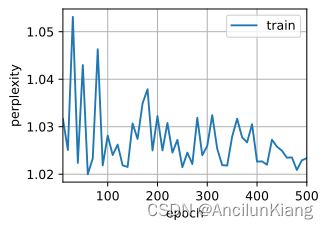
d2l.train_ch8(model_change2, train_iter, vocab, lr, num_epochs, device)
perplexity 1.0, 38633.7 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
traveller with a slight accession ofcheerfulness really thi