【考研】830 + 848 暨大2012-2022真题易混易错题总结(一)
前言
以下题目,均源自于暨南大学 2012 - 2022 年的 830 + 848 真题。主要是对真题中易混易错题进行记录和总结。
分为三篇博文,此乃第一篇,真题是 2012 - 2017 年的。(第三篇待补充链接)
可搭配以下链接一起学习:
【考研】830 + 848 暨大2012-2022真题易混易错题总结(二)_住在阳光的心里的博客
【考研】《数据结构》知识点总结.pdf_考研-其它文档类资源-CSDN文库
【2023考研】数据结构常考应用典型例题(含真题)_住在阳光的心里的博客-CSDN博客
一、暨大 2012 - 2017 真题
1、(1)线性结构中元素之间存在 一对一 的关系,树形结构中元素之间存在 一对多 的关系。图型结构中元素之间存在 多对多 关系。
(2)根据数据元素之间关系的不同特性, 基本逻辑结构分为 集合结构 、 线性结构 、 树形结构和 图状结构 四种。
(3)计算机内部数据处理的基本单元是( B )。
A. 数据 B. 数据元素 C. 数据项 D. 数据库
解: 针对(3):注意辨别:
数据元素是数据的基本单位;
数据项是组成数据元素的、有独立含义的、不可分割的最小单位。
数据对象是性质相同的数据元素的集合,是数据的一个子集。
2、设使用的邻接表表示某有向图,则顶点
在表结点中出现的次数等于顶点
3、(1)带头结点的循环单链表 L 为空的条件是 L->next == L 。
(2)单循环链表的主要优点是 从任一结点出发可以访问整个链表 ;
4、循环队列中是否可以插入下一个元素( D )
A. 与曾经进行过多少次插入操作有关
B. 只与队尾指针的值有关,与队头指针的值无关
C. 只与数组大小有关,与队首指针和队尾指针的值无关
D. 与队头指针和队尾指针的值有关
5、(1)在散列表 (hash) 查找中,评判一个散列函数优劣的两个主要条件是:计算简单 和 散列之后得到的元素分布均匀。
(2)在哈希查找方法中,要解决两方面的问题,它们分别是 找出散列地址 及 解决地址冲突 。
6、线索二叉树的左线索指向 前驱结点 ,右线索指向 后继结点 。
7、有一个 100×90 的稀疏矩阵,非零元素有10,设每个整型数占 2 个字节,则用三元组表示该矩阵时,所需的字节数是 66 。
解:三元组只存储非零元素,记录了非零元素的行数,列数以及总元素个数。
所以,用三元组表示该矩阵时,所需的字节数是 10*3*2 + 3*2 = 66 。
8、B 和 B+ 树都能有效地支持随机查找,但 B 树 不支持顺序查找。
【补充】可搭配链接学习:【考研复习:数据结构】查找(不含代码篇)_住在阳光的心里的博客-CSDN博客
9、拓扑排序是按 AOE 网中每个结点事件的最早发生事件对结点进行排序。( X )
解:AOE 网是以边表示活动的网,一个带权的有向无环图,通常用来估算工程的完成时间,用以求关键路径。
AOV 网是一个有向无环图,求其拓扑排序的方法:
(1)从 AOV 网中选择一个没有前驱的顶点输出它;
(2)从 AOV 网中删去该顶点,并且删去所有以该顶点为尾的弧;
(3)重复上述两步,直到全部顶点都被输出,或 AOV 网中不存在没有前驱的顶点。
【注意】图的拓扑排序并不唯一。
【补充】有关拓扑排序具体的知识点,可参考以下链接:
【考研】数据结构考点——拓扑排序_住在阳光的心里的博客-CSDN博客
10、设计AOV-网拓扑排序的算法。
// 给出结构体
typedef struct arcnode{
int adjvex;
struct arcnode *next;
}arcnode;
typedef struct {
int vertex;
arcnode *firstarc;
}vexnode;
vexnode adjlist[max];
// 整体的算法代码
void toposort(int n){
int queue[max];
int front = 0, rear = 0;
int v, w, m;
arcnode *p;
m = 0;
for(v = 1; v <= n; v++)
if(adjlist[v].vertex == 0) {
rear = (rear+1)%max;
queue[rear] = v;
}
printf("the toposort: \n");
while(front != rear){
front = (front + 1)%max;
v = queue[front];
printf("%d ", v);
m++;
p = adjlist[v].firstarc;
while(p != NULL) {
w = p->adjvex;
adjlist[w].vertex--;
if(adjlist[w].vertex == 0){
rear = (rear+1)%max;
queue[rear] = w;
}
p = p->next;
}
}
if(m < n)
printf("拓扑排序失败。");
}
11、在 AOE 网中,完成工程的最短时间是( A )。
A.从源点到汇点的最长路径的长度 B.从源点到汇点的最短路径的长度
C.最长的回路的长度 D.最短的回路的长度
12、在线索化二叉树中,T所指结点没有左子树的充要条件是( B )。
A.T->left = NULL B.T->ltag = 1
C.T->ltag = 1 且 T->left = Null D.以上都不对
13、单链表中设置头结点的作用是方便统一链表的插入和删除操作。
解:在《数据结构(第2版)》严蔚敏编著,单链表中设置头结点的作用,一是便于首元结点的处理,二是便于空表和非空表的统一处理。
14、n 阶对称矩阵可压缩存储到
个元素的空间中。( X )
解:应该为 n(n+1)/ 2。
15、下面是先序遍历二叉树的算法非递归算法,请在 ? 处填上适当内容,使其成为一个完整算法。
typedef struct BiTNode { // 结点结构 TElemType data; struct BiTNode *lchild, *rchild; // 左右孩子指针 }BiTNode, *BiTree; //采用二叉链表存储结构, Visit是对结点操作的应用函数 void PreOrderTraverse(BiTree T, Status(*Visit)(TElemType)) { InitStack(S); BiTree p = T; while( ? ){ if (p) { Visit(p->data); ?; p = p->lchild; } else { ?; p = ?; } } }
解:代码如下
typedef struct BiTNode { // 结点结构
TElemType data;
struct BiTNode *lchild, *rchild; // 左右孩子指针
}BiTNode, *BiTree;
//采用二叉链表存储结构, Visit是对结点操作的应用函数
void PreOrderTraverse(BiTree T, Status(*Visit)(TElemType)) {
InitStack(S);
BiTree p = T;
while(p != NULL || !EmptyStack(S)){ // p 不为空或栈 S 不为空
if (p) {
Visit(p->data);
push(S, p); //为了保留访问右子树的地址
p = p->lchild;
}
else {
Pop(S, p);
p = p->rchild;
}
}
}16、具有 n 个顶点的完全有向图的边数为( B ).
A. n(n-1)/2 B. n(n-1) C.
D.
解:见下表:
| 边数 | ||
| n 个顶点 | 完全有向图 | n(n-1) |
| 完全无向图 | n(n-1) /2 | |
17、已知一个图的邻接矩阵表示,删除所有从第 i 个结点出发的边的方法是 将矩阵第 i 行非零元素置为 0 或 第 i 行元素非零元素置为
。
解:将矩阵第 i 行非零元素置为 0:针对无权图。
第 i 行元素非零元素置为 :针对有权图。
18、向二叉排序树中插入一个新结点,需要比较的次数可能大于此二叉树的高度h。( X )
解:比较次数最大为树高。
19、散列法存储的思想是由关键字值决定数据的存储地址。( 对 )
解:此题说法算对,但有争议,准确来说,应该是由散列函数及 Hash 冲突处理方法决定数据的存储地址。
20、已知线性表中的元素按值递增有序排列,并以带头结点的单链表作存储结构。试编写算法 ,删除表中所有值大于 x 且小于 y 的元素(若表中存在这样的元素), 同时释放被删除结点空间。
解:代码如下:
//删除表中所有值大于 x 且小于 y 的元素(若表中存在这样的元素)
void Delete_list(LNode *head, int x, int y){
LNode *p, *q;
p = head;
while(p->next != NULL){
if(p->next->data > x && p->next->data < y){ //删除满足条件的元素
q = p->next;
p->next = q->next; //删除q
free(q);
}
p = p->next; //指针后移
}
}21、设计一个算法,求不带权无向连通图 G 中距离顶点 v 的最远顶点。
解:(1)算法思想:图 G 是不带权的无向连通图,一条边的长度为1,因此,求距离顶点 v 的最远的顶点,即求距离顶点 v 的边数最多的顶点。
利用广度优先遍历算法,从 v 出发进行广度遍历,类似于从顶点 v 出发一层层地向外扩展,到达 j, …,最后到达的一个顶点 k 即为距离 v 最远的顶点。
遍历时利用队列逐层暂存各个顶点,最后出队的一个顶点 k 即为所求。
(2)代码如下:
int Maxdist(AGragh *G, int v){
ArcNode *p;
int Qu[MAXV]; //循环队列
int front = 0,rear = 0; //队列的头、尾指针
int visited[MAXV]; //初始化访问数组
int i, j, k;
for(i = 0; i < G->n; i++)
visited[i] = 1; //初始化访问标志数组
rear++;
Qu[rear] = v; //顶点v进队
visited[v] = 1; //顶点v已访问
while(front != rear){
front = (front + 1)%MAXV;
k = Qu[front]; //顶点k出队
p = G->adjlist[k].firstarc; //找到第一个邻节点
while(p != NULL) { //所有未访问过的相邻点进队
j = p->adjvex; //邻接点为顶点j
if(visited[j] == 0){ //若j未访问过
visited[j] == 1;
rear = (rear + 1)%MAXV; //进队
Qu[rear]=j;
}
p = p->nextarc; //找下一个邻接点
}
}
return k;
}
22、(1)设有一个无向图 G =(V,E)和 G’ =(V’,E’),如果 G’ 为 G 的生成树,则下面不正确的说法是( B )。
A.G’ 为 G 的子图 B.G’ 为 G 的连通分量
C.G’ 为 G 的极小连通子图且 V’ = V D.G’ 为 G 的一个无环子图
(2)对于一个具有 n 个顶点的无向连通图,它包含的连通分量的个数为( B )。
A. 0 B.1 C. n D. n+1
解:(1)连通图的生成树,是极小连通子图,
连通分量,是指无向图中的极大连通子图。
【补充】
在无向图中,若从顶点 v1 到顶点 v2 有路径,则称顶点 v1 和顶点 v2 是连通的,若图 G 中任意两个顶点都是连通的,称 G 是连通图。
在有向图中,若对于每一对 ![]() ,从
,从  到 和从 到 都存在路径,称 G 是强连通图。有向图中的极大强连通子图称为有向图的强连通分量。
到 和从 到 都存在路径,称 G 是强连通图。有向图中的极大强连通子图称为有向图的强连通分量。
23、 平衡二叉树的平均查找长度是
。
解: 平衡二叉树中每个结点的查找长度与树高是同一个数量级,为 。
24、对于 n 个记录(假设每个记录含 d 个关键字)进行链式基数排序,总共需要进行 d 趟分配和收集。
解:例如:若关键字是十进制表示的数字,且范围在 [0,999] 内,则可以把每一个十进制数字看成由三个关键字组成 (K0, K1, K2),其中 K0 是百位数,K1 是十位数,K2 是个位数。
25、在 n 个顶点的无向图中,若边数 > n - 1,则该图必是连通图。 ( 错 )
解:在 n 个结点的无向图中,若该图是连通图,则其边数大于等于 n - 1。
在 n 个结点的无向图中,若边数大于 (n-2)(n-1)/2,则该图必是连通图。
26、具有 n 个结点的二叉排序树有多种,其中树高最小的二叉排序树是最佳的。( 对 )
解:树高最小的二叉排序树查找,类似于二分查找,时间复杂度为 。最坏情况下是单支树,树的深度为其平均查找长度 (n+1)/2 (和顺序查找相同),时间复杂度是 O(n)。
27、对小根堆进行层次遍历可以得到一个有序序列。( 错 )
解:堆只要求根结点值大于(或小于)孩子结点的值,且是完全二叉树。对一个堆按层次遍历,不一定能得到一个有序序列。
28、设有一组关键字(71, 23, 73, 14, 55, 89, 33, 43, 48),采用哈希函数:H(key) = key %10,采用开放地址的二次探测再散列方法解决冲突,试在散列地址空间中对该关键字序列 ( 按从左到右的次序 ) 构造哈希表,并计算在查找概率相等的前提下,成功查找的平均查找长度。
解:首先要了解二次探测法的增量序列  的取值 :
的取值 :
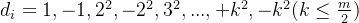
注意:二次探测处理冲突时,散列表的表长要满足 4j + 3 的形式,由 H(key) = key %10 可知,表长不应该是10,而是11。(这是平方探测法处理冲突的时候的要求,不是所有散列表的要求。)
哈希函数:H(key) = key %10,所以
71 % 10 = 1,比较次数为1
23 % 10 = 3,比较次数为1
73 % 10 = 3,冲突,则 (73 + 1 )% 10 = 4,比较次数为2
14 % 10 = 4,冲突,则 (14 + 1 )% 10 = 5,比较次数为2
55 % 10 = 5,冲突,则 (55 + 1 )% 10 = 6,比较次数为2
89 % 10 = 9,比较次数为1
33 % 10 = 3,冲突,则 (33 + 1 )% 10 = 4,冲突,则 (33 - 1 )% 10 = 2,比较次数为3
43 % 10 = 3,冲突,则 (43 + 1 )% 10 = 4,冲突,则 (43 - 1 )% 10 = 2,冲突,则 (43 + 4 )% 10 = 7,比较次数为4
48 % 10 = 8,比较次数为1
所以,由二次探测处理冲突得:
| 地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| key | 71 | 33 | 23 | 73 | 14 | 55 | 43 | 48 | 89 | ||
| 比较次数 | 1 | 3 | 1 | 2 | 2 | 2 | 4 | 1 | 1 |
成功查找的平均查找长度 ASL = (1 + 1 + 2 + 2 + 2 + 1 + 3 + 4 + 1) / 9 = 17/9。
29、已知序列(142, 543, 123, 65, 453, 879, 572, 434, 111, 242, 811, 102)。采用堆排序对该序列作升序排序,请给出初始堆以及第一趟排序的结果。
解:首先分析:
采用堆排序对该序列作升序排序,所以是要构造大根堆。
初始堆是堆,要满足大根堆或小根堆的要求。 所以将关键字序列用层序排列成二叉树后,调整为大根堆后,才是初始堆。
见下图:

30、实现对一个不带头结点的单链表 L 进行就地(不增加额外存储空间)逆置。
解:(1)算法思想:
因为单链表不带头结点,所以从第一个结点开始,将第 2 个结点及之后的结点依次采用头插法插在第一个结点的前面。见下图:

(2)代码如下:
typedef int DataType;
typedef struct {
DataType data;
struct Node *next;
}Node;
typedef Node *LinkList;
//链表“就地逆置”
LinkList Reverse(LinkList L){
LinkList p, q;
if (!L) return; //链表为空返回
p = L->next;
q = L->next;
L->next = NULL;
while(q){
q = q->next;
p->next = L; //头插法
L = p;
p = q;
}
return L;
}
【补充】
(1)当链表带头结点时,将头结点插入,再从第一个结点开始,依次前插入到头结点的后面(头插法),直到最后一个结点为止。见下图:

代码如下:
//带头结点的单链表“就地逆置”
LinkList Reverse(LinkList L){
LNode *p, *r;
p = L->next; //从第一个元素结点开始
L->next = NULL; //将头结点置空
while(p != NULL){
r = p->next; //暂存 p 的后继
p->next = L->next; //头插法
L->next = p;
p = r;
}
return L;
}31、设有一组初始记录关键字序列(K1,K2,…,Kn),要求设计一个算法能够在O(n)的时间复杂度内将线性表划分成两部分,其中左半部分的每个关键字均小于Ki,右半部分的每个关键字均大于等于Ki。
解:此题实际上是考查快速排序。
以 Ki 作为枢轴,第一趟排序后,刚好能满足将线性表划分成两部分,其中左半部分的每个关键字均小于 Ki,右半部分的每个关键字均大于等于 Ki 。且时间复杂度为 ,刚好满足小于 O(n) 的条件。
代码如下:
//假设关键字都是存储在数组 a 中
void division(int a[], int low, int high, int ki){
while(low < high){
while(low < high && a[high] > ki)
high--;
if(low < high){
a[low] = a[high]
low++;
}
while(low < high && a[low] < ki)
low++;
if(low < high){
a[high] = a[low]
high--;
}
a[low] = ki; //枢轴归位
}
}
32、顺序表查找指的是在顺序存储结构上进行查找。( 错 )
解:顺序存储指的就是数组之类的数据结构,但是顺序表并不一定是用数组实现的,在链表上也可以实现顺序查找。
33、由树转化成二叉树,该二叉树的右子树不一定为空。( 错 )
解:由树转化成二叉树,该二叉树的右子树一定为空。见下图:

34、设二叉排序树中关键字由1至1000的整数组成,现要查找关键字为 363 的结点,下面的关键字序列哪个不可能是在二叉树中查到的序列?说明原因。(5分)
(1)51, 250, 501, 390, 320, 340, 382, 363
(2)24,877, 125, 342, 501, 623, 421, 363
解: 对于能够是在二叉排序树中查到的序列,其主要是左孩子结点 ≤ 根节点 ≤ 右孩子,由于 501 > 421, 501 > 363,在 623 之后,是不可能再次查找到 421 的,所以第二个序列不可能。见下图:

35、针对二叉树,回答以下问题:
(1)具有 n 个结点的二叉树的最小深度是多少?最大深度是多少?(4分)
(2)具有 n 个结点的完全二叉树中有多少个叶子结点?有多少个度为 2 的结点?(4分)
(3)具有
个叶子结点的完全二叉树中共有多少个结点?(4分)
解:(1) 最小深度:  或
或 ![]()
最大深度:n
(2)当完全二叉树最后一个非叶子结点的编号为 ![]() (从 1 开始编号),即非叶子结点数有
(从 1 开始编号),即非叶子结点数有 ![]()
,所以可知叶子结点数为:![]() ,度为 2 的结点:
,度为 2 的结点:![]()
(3)因为是完全二叉树,所以度数为1的结点的个数为 0,或者是1。
由公式:
结点总数 = 度为 2 的结点数 + 度为 1 的结点数 + 度为 0 的结点数
度为 2 的结点数 = 度为 0 的结点数 - 1
可知:
![]()
![]()
36、一个有向图 G 采用邻接表存储结构的拓扑排序算法。
解:代码如下:
typedef struct VNode{
VertexType data;
ArcNode *firstarc;
}VNode, AdjList[MAX_VERTEX_NUM];
typedef struct ArcNode{
int adjvex;
struct ArcNode *nextarc;
InfoType *info;
}ArcNode;
typedef struct {
AdjList vertices;
int vexnum, arcnum;
int kind;
} ALGraph;
//有向图 G 采用邻接表存储结构。若G无回路,则输出G的顶点的一个拓扑序列并返回OK,否则返回ERROR。
Status TopologicalSort(ALGraph G){
int indegree[vexnum];
FindInDegree(G, indegree); //对各顶点求入度indegree [0..vexnum-1]
InitStack(S);
for(i = 0; i < G.vexnum; ++i){
if(indegree[i] == 0)
Push(S, i);
}
count = 0;
while(!IsEmpty(S)){
Pop(S, i);
printf(i, G.vertices[i].data);
++count;
for(p = G.vertices[i].firstarc; p; p = p->nextarc){
k = p->adjvex;
if(!(--indegree[k]))
Push(S, v);
}
}
if(count < G.vexnum) return ERROR;
else return OK;
}//TopologicalSort
37、已知 n 个顶点的带权图用邻接矩阵表示,试编写算法实现用 kruskal 算法构造最小生成树。
解:算法思想:基于贪心算法,代码如下:
void kruskal(Graph G){
int i, m, n, p1, p2;
int length;
int index = 0; // rets数组的索引
int vends[MAX]={0}; // 用于保存"已有最小生成树"中每个顶点在该最小树中的终点。
EData rets[MAX]; // 结果数组,保存kruskal最小生成树的边
EData *edges; // 图对应的所有边
// 获取"图中所有的边"
edges = get_edges(G);
// 将边按照"权"的大小进行排序(从小到大)
sorted_edges(edges, G.edgnum);
for (i = 0; i < G.edgnum; i++){
p1 = get_position(G, edges[i].start); // 获取第i条边的"起点"的序号
p2 = get_position(G, edges[i].end); // 获取第i条边的"终点"的序号
m = get_end(vends, p1); // 获取p1在"已有的最小生成树"中的终点
n = get_end(vends, p2); // 获取p2在"已有的最小生成树"中的终点
// 如果m!=n,意味着"边i"与"已经添加到最小生成树中的顶点"没有形成环路
if (m != n){
vends[m] = n; // 设置m在"已有的最小生成树"中的终点为n
rets[index++] = edges[i]; // 保存结果
}
}
free(edges);
// 统计并打印"kruskal最小生成树"的信息
length = 0;
for (i = 0; i < index; i++)
length += rets[i].weight;
printf("Kruskal=%d: ", length);
for (i = 0; i < index; i++)
printf("(%c,%c) ", rets[i].start, rets[i].end);
printf("\n");
}